«Новая позиция» больших данных в рамках тренда больших моделей: полное сотрудничество между большими моделями и корпоративными данными

Автор | Лу Дунсюэ
Благодаря постоянному развитию больших данных, искусственного интеллекта, облачных вычислений и других технологий большие модели стали неотъемлемой частью системы корпоративных данных. В условиях появления больших моделей корпоративные системы данных сталкиваются с новыми проблемами и возможностями. Например, обучение больших моделей требует большого объема данных, а сбор, очистка и обработка данных требуют много времени и рабочей силы. В то же время обучение больших моделей требует высокопроизводительных вычислительных ресурсов, что требует крупных инвестиций со стороны предприятий, а обучение и вывод больших моделей требуют мощных алгоритмов и вычислительных возможностей, что еще больше увеличивает техническую сложность и стоимость.
Однако тенденция больших моделей также открывает новые возможности для корпоративных систем данных. Предприятиям необходимо расширить свои возможности в области управления данными, их хранения, безопасности данных, интеграции данных, анализа и анализа данных, а также бизнес-приложений, чтобы справиться с проблемами и возможностями, возникающими в связи с тенденцией больших моделей, и добиться цифровой трансформации. С этой целью доктор Хэ Чанхуа, имеющий многолетний практический опыт в области управления данными, выступил на только что завершившемся Глобальном саммите архитекторов ArchSummit. В 2023 году (станция Шэньчжэнь) он поделился «Размышлениями о корпоративных системах данных в условиях тенденции больших моделей». Он начал с отраслевого опыта, такого как «популярность больших моделей породила новое измерение в обработке данных», «новые требования к ним». обработки данных в эпоху больших моделей. Они разделили четыре аспекта: «Оковы традиционной архитектуры данных», «Тенденция развития корпоративной обработки данных в эпоху больших моделей» и «Дальновидный взгляд на эволюцию архитектура корпоративных данных» и экспортировал множество замечательных представлений.

Доктор Хэ Чанхуа, доктор философии Стэнфордского университета, основатель и генеральный директор Shuding Technology. Ранее он занимал должность руководителя отдела вычислительного интеллекта и главного архитектора вычислительного хранилища в Ant Group, до 2017 года работал в Кремниевой долине в таких интернет-компаниях, как Google и Airbnb; В своей прошлой карьере Хэ Чанхуа руководил разработкой интеллектуальных систем принятия решений в реальном времени, баз данных с распределенными графами финансового уровня, механизмов распределенных вычислений нового поколения, логических хранилищ данных нового поколения и архитектур поисковых систем нового поколения.
Доктор. Вначале он использовал MATLAB для написания нескольких очень простых нейронных сетей, затем познакомился с глубоким обучением, когда работал в Google, и у него было все больше и больше приложений в бизнесе. Позже он создал несколько моделей для крупномасштабных поисковых рекомендаций и. обучение графам в эпоху Ant. Некоторые работы прошли полный процесс разработки нейронных сетей.
1 В процессе внедрения больших моделей на предприятиях к «системам данных» предъявляются три основных требования:
Концепция Shuding Technology, созданная Хэ Чанхуа, заключается в том, чтобы «сделать интеллектуальный анализ данных таким же простым, как вода и электричество». Он надеется, что интеллектуальный анализ данных может быть по-настоящему внедрен на предприятии. По сути, это очень высокий порог. Быстрое развитие больших моделей за последние шесть месяцев сильно потрясло отрасль. Компания Shuding Technology также недавно кое-что проделала с большими моделями, исследуя, как полностью взаимодействовать с большими моделями с корпоративными данными, чтобы по-настоящему раскрыть потенциал больших моделей. ., может раскрыть ценность больших данных.
Многие люди говорят, что если большие модели будут продолжать развиваться бесконечно и станут достаточно большими, предприятия смогут помещать в них все данные, и нынешние основные системы вычислений и хранения данных больше не будут нужны в будущем. Компания Shuding Technology так не считает: большие модели не могут заменить роль систем обработки и хранения данных. На самом деле, чтобы принять правильное решение, большие модели требуют глубокого взаимодействия с корпоративными данными. Потому что масштаб этих данных (особенно структурированных данных) намного превышает масштаб больших моделей, а принятие решений на основе данных часто требует точных расчетов.
Чтобы все могли более четко понять потребности предприятия, в своем выступлении доктор Хе представил процесс внедрения крупных моделей внутри предприятия, процитировав иллюстрацию из A16Z, известного инвестиционного института: «На самом деле, многие фреймворки в отрасли теперь имеют именно эту модель. Вы можете видеть, что в маленьком квадрате справа находится только большая модель, а другой контент на самом деле составляет очень большую часть всей ссылки».
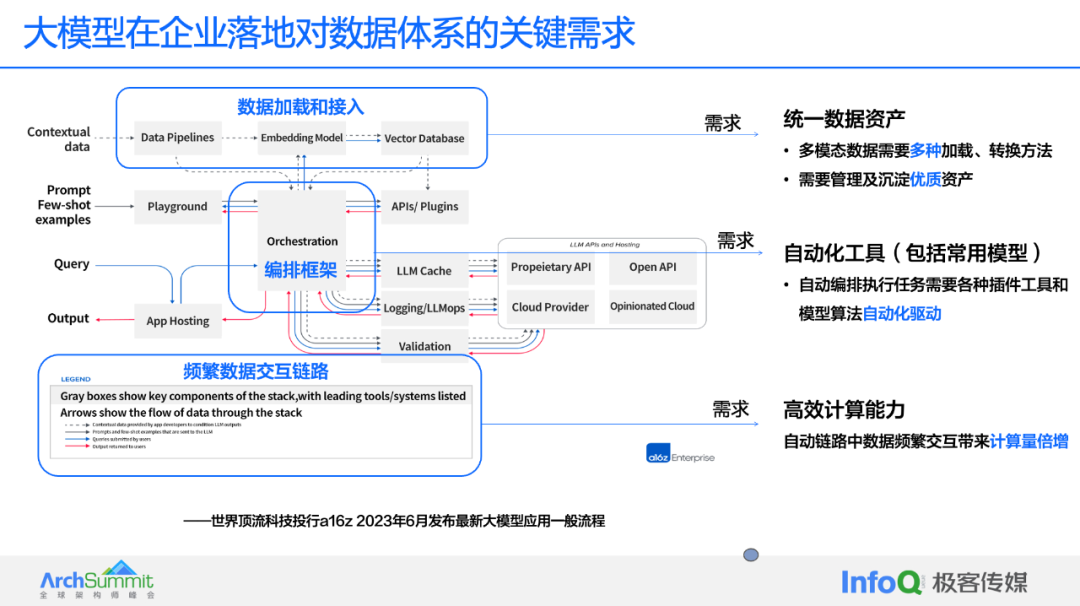
Рисунок: Общий процесс применения большой модели.
Первая часть процесса — это загрузка и доступ к данным. Все мы знаем, что при построении больших моделей необходимо использовать данные. Большие модели могут получать большое количество различных данных, но к системе данных предприятия выдвигается очень важное требование, то есть данные должны быть единым высокого уровня. Качественные активы могут представлять собой мультимодальные данные в нескольких форматах или могут требовать четкого определения родословной, что требует очень строгих требований.
Вторая часть — это структура оркестровки. На самом деле, когда только вышла большая модель, никто не думал об этом пути, но потом все увидели, что OpenAI выпустила свои ПЛАГИНЫ, которые могут вызывать ваши функции. После внесения некоторых предложений с помощью большой модели вызовите функцию ПЛАГИНЫ, чтобы по-настоящему реализовать ее функцию. Самое важное здесь — это количество автоматизированных инструментов для анализа данных, моделей и даже углубленного анализа атрибуции. Короче говоря, все это — единственный способ перейти к интеллектуальным корпоративным приложениям.
Кроме того, мы также видим, что большие модели очень часто взаимодействуют с данными. Доктор Хе привел пример: «Когда предприятие хочет принять решение, оно надеется использовать четкий отчет, позволяющий просмотреть изменения в объеме транзакций за последние три месяца, чтобы определить, как скорректировать бизнес в будущем. по-настоящему большая модель может принимать больше решений, чем человек». Для хорошего принятия решений она может просмотреть 10 показателей, затем выполнить сравнения и выполнить несколько итераций и, наконец, найти оптимальный показатель. В этом случае вы можете видеть, что Модель расчета требует роста вычислений на порядок».
По этому процессу мы можем судить,Унифицированные ресурсы данных, инструменты автоматизации и эффективные вычислительные возможности — это три основных требования, с которыми большие модели столкнутся на предприятии.。
Столкнувшись с этими тремя основными требованиями, существующая система данных в настоящее время сталкивается со многими проблемами в этом отношении, и различные решения, включая промежуточные платформы данных, нелегко решить. В информатике есть поговорка: если вы обнаружите, что проблему трудно решить, вы можете добавить уровень косвенности, поэтому компания Shuding Technology решила использовать технологию виртуализации данных для решения этой проблемы. На самом деле, виртуализация данных не является новой концепцией, но подход Shutop Technology по-прежнему весьма отличается и инновационный по сравнению с нынешней отраслью. Мы можем взглянуть на архитектурную схему «технологии интеллектуальной виртуализации данных» Shutop Technology:
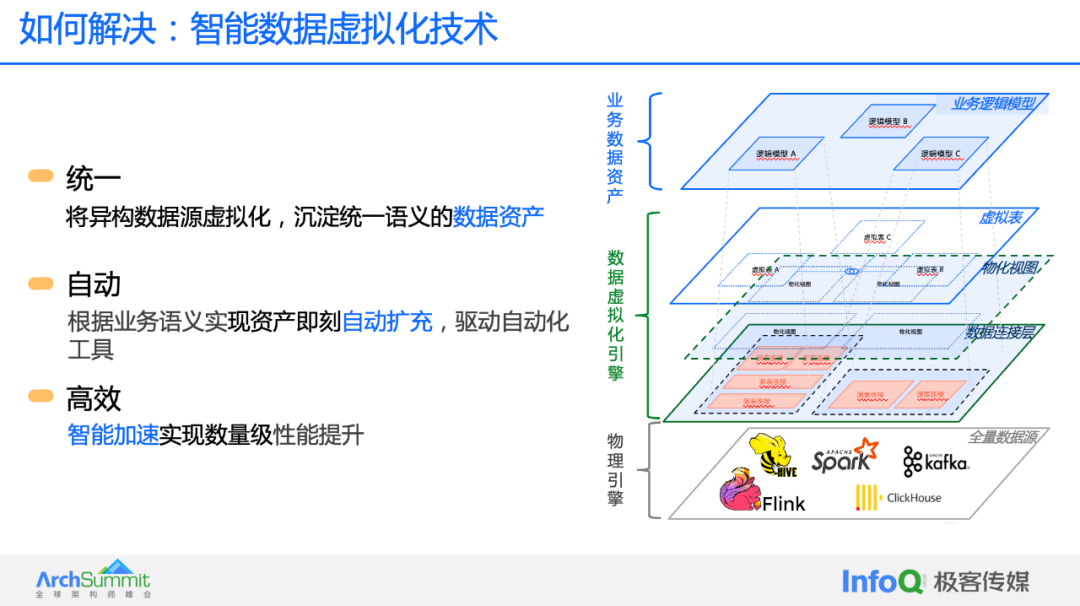
Рисунок: Технология интеллектуальной виртуализации данных
В порядке снизу вверх давайте сначала посмотрим на первый уровень, который представляет собой некоторые из нынешних основных систем данных. Существуют различные механизмы, которые вычисляют и хранят данные в системе. Второй уровень подключения к данным эквивалентен определению виртуального подключения к данным, которое может быть подключено к внешнему физическому уровню. После этого уровня виртуализации фактически «мои данные» — это сами данные, и они отделены от источника данных. В сочетании с тем, что сейчас существует множество механизмов, которые могут это делать, например Presto, инструменты объединения данных и т. д., компания Shuding Technology считает, что над этим уровнем должен быть более высокий уровень виртуализации данных.
Например, некоторые виртуальные таблицы данных, создаваемые предприятиями, обычно представляют собой процесс моделирования данных, и пользователи будут напрямую использовать эти таблицы данных. В то же время на верхнем уровне предприятия могут строить несколько виртуальных таблиц более высокого уровня на основе бизнес-модели. Послойно видно, что весь процесс построения — это фактически полная семантика данных, и он не предполагает участия. любые системные изменения или изменения. Обработка любой промежуточной таблицы.
Эта концепция и архитектура кажутся очень простыми, но основной проблемой всей системы является вычислительная мощность. Как мы все знаем, причина, по которой большие данные развивались на протяжении всей истории, заключается в том, что объем данных слишком велик, что требует мощных вычислительных мощностей, промежуточных результатов, непрерывной обработки слой за слоем и т. д. В механизме виртуализации Shutop Technology все эти технические детали реализации реализуются с помощью интеллектуальных средств, таких как автоматическое создание материализованных представлений и автоматическая проверка источника данных, что очень эффективно. Он включает в себя полный набор технических функций, таких как организация виртуальных таблиц, автоматические материализованные источники крови и автоматическая оптимизация. Мы называем это механизмом виртуализации данных. Поскольку у большинства предприятий уже есть хранилище данных или озеро данных или, по крайней мере, некоторые источники данных, основанные на существующей архитектуре данных предприятия, механизм виртуализации данных находится между источником данных и потребителем данных. Это предоставит потребителям виртуальное представление данных для потребления. Потребителям нужно будет обращать внимание только на бизнес-семантику данных, и им не нужно обращать внимание на «конкретное расположение» данных и «какой механизм использовать». и «как получить к нему доступ». В то же время пользователи также включают некоторые эксплуатационные модели поведения, тесно связанные с глубоким обучением и большими моделями. Когда большие модели вызывают данные, будет более эффективно вызывать данные через интерфейс механизма виртуализации.
2 «Механизм виртуализации данных» эффективно решит бизнес-задачи предприятия.
Потребности предприятия были уточнены, так как же решить эти потребности? Компания Shuding Technology предлагает решение — технологию виртуализации данных. Столкнувшись с тремя бизнес-потребностями предприятия, Shuding Technology также предложила собственные трехмерные решения.
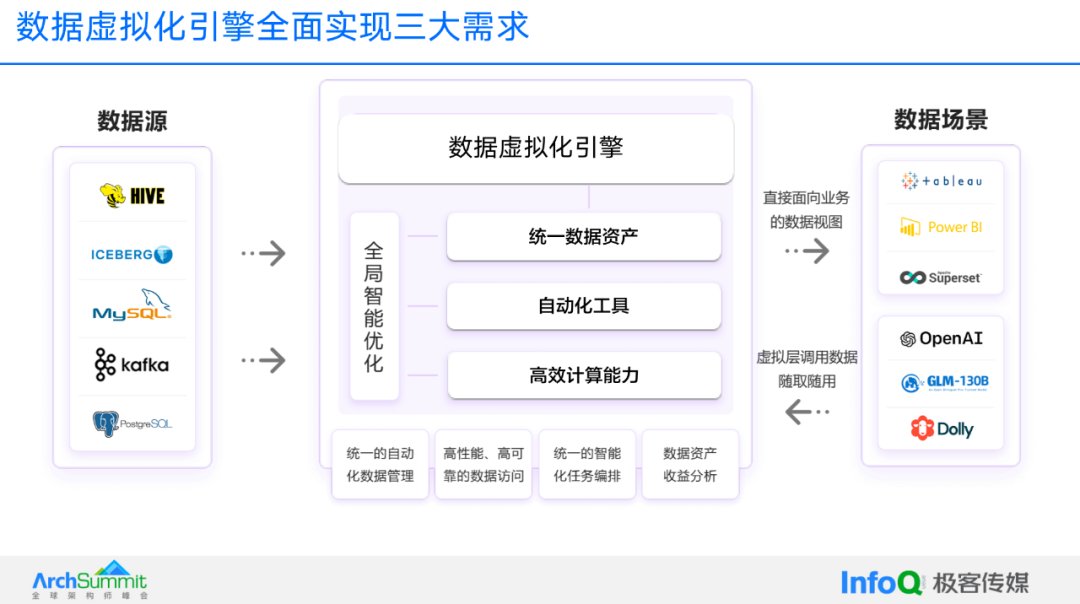
Рисунок: Технология виртуализации данных решает три основные задачи
Во-первых, унифицируйте ресурсы данных。Доступ к виртуальной таблице легко получить, используя семантику виртуальной таблицы.данныересурсы,Определить виртуальную таблицу,map Затем внешний источник данных формирует виртуальные данные, а другая работа выполняется внутри механизма виртуализации. Среди них механизм виртуализации имеет встроенные процессы преобразования формата, ускорения и предварительной обработки внешних данных.
Когда пользователи используют данные виртуальных таблиц, если им нужно добавить новые таблицы или получить новые ресурсы данных, они могут очень быстро добавить виртуальные таблицы. Поскольку механизм виртуализации автоматизирует анализ и выполнение, все источники данных можно отслеживать. Как только полный или частичный SQL обращается к одним и тем же данным, механизм виртуализации объединяет их, и активы будут однозначно определены определенной семантикой SQL, поэтому там. не будет никаких неоднозначных активов.
Во-вторых, внедрите инструменты автоматизации на основе данных.。существовать OpenAI В большой модели можно выполнить множество соединений. ПЛАГИНЫ, включая функции поддержки, выпущенные позже, могут помочь вам бронировать билеты и подключаться к сторонним приложениям. Все они принадлежат к большой экосистеме. Когда мы фокусируемся на сценарии принятия решений внутри предприятия, инструменты автоматизации часто должны управляться данными, и механизм виртуализации может предоставить им мощные возможности.
Возьмем пример сценария интеллектуальной операции. Например, если пользователь хочет найти действующую группу клиентов для выпуска новой кредитной карты, большая модель сообщит вам, основываясь на собственных знаниях, что «средняя ежедневная сумма транзакции составляет разделены на определенные периодические интервалы. Этот сигнал может оказаться очень полезным. Я поищу его в системе данных. В ходе этого процесса мы обнаружим, что в общей таблице функций такой функции нет, но есть еще одна функция, называемая «средняя ежедневная сумма транзакции». В соответствии с обычным процессом нам нужно попросить инженера по обработке данных помочь обработать «. средняя ежедневная сумма транзакции» «Разделите» эту новую функцию, после обработки ее необходимо объединить в таблицу, а затем отправить эту таблицу в систему онлайн-сервиса, и мой инструмент модели сможет получить к ней доступ, прежде чем она сможет работать.
Но в системе механизма виртуализации это действие может выполняться автоматически, быстро получать новые функции и принимать более эффективные решения. Все данные можно автоматически и гибко расширять и обрабатывать в соответствии с потребностями больших моделей, что является ключевым шагом в реализации автоматизации на основе данных. Если вся связь автоматизирована и нет необходимости вручную обрабатывать новые функции, действительно можно добиться эффекта большой модели.
В-третьих, эффективная вычислительная мощность。Можете ли вы быть удовлетворены?предприятиенуждаться,Основная суть — «достаточно эффективный расчет».,Включает предварительный расчет. Доступ к базовым данным через виртуальную таблицу,Может ли он достичь таких же или даже лучших результатов, чем предыдущая ручная обработка? об этом,Shuding Technology имеет два основных направления:
- Интеллектуальное ускорение, аналитический SQL могут оптимизировать материализованные представления.
Материализованные представления на самом деле являются старой темой в базах данных, но поскольку базы данных включают в себя транзакции, этот аспект не отражает революционных изменений в базах данных. Однако в области анализа больших данных он действительно может быть революционным. Технология материализованного представления по существу решает ручной процесс ETL.
Shudian Technology в настоящее время решает эту проблему поэтапно. В настоящее время очистка данных осуществляется посредством ручной обработки и ручного создания DWD, а затем автоматически генерируется материализованное представление. Однако по мере прохождения этапа эффект от полной автоматизации будет очень велик. . Хороший. Для пользователей основной частью прямого потребления является виртуальная широкая таблица. Нет необходимости знать, являются ли базовые данные данными реального времени или пакетными данными, какой механизм существует и какой тип хранилища используется для обработки. чувствует себя очень хорошо для пользователей.
- По-настоящему простой в использовании и эффективный «компьютерный шасси для хранения данных».
Фактически, такие концепции виртуализации, как фабрика данных, остановились на первом шаге и не смогли сделать еще один шаг вперед. Компания Shuding Technology считает, что в ее системе отсутствует очень важное звено — реальное хранилище. Здесь хранится эффективный кэш, доступный в KV, графовом и других форматах. Кроме того, производительность хранилища также является критически важной характеристикой, но нам нужно использовать SSD для хранения, чтобы достичь почти такой же производительности, как и у памяти.
Кроме того, доктор Хе сказал, что в дополнение к трем вышеперечисленным аспектам, оптимизация вычислительного механизма также очень важна - компания Shuding Technology считает, что основные возможности механизма должны быть объединены. Они проведут некоторые предварительные внешние расчеты. данные сформировать промежуточную таблицу и поместить ее в эффективное хранилище, а индексы будут установлены в эффективное хранилище. Кроме того, при необходимости внешние данные будут считаны напрямую. В данном случае возможности движка заключаются в том, что предприятие может быстро получить внешние данные и объединить их в конечный результат. Это также самая мощная способность Shuding Technology на данный момент. Например, некоторые механизмы хороши для пакетной и инкрементальной обработки, и их возможности можно полностью повторно использовать для ее вызова.
Согласно соответствующей статистике, после вышеупомянутой полной «интеллектуальной оптимизации стека технологий» замкнутого цикла по сравнению с основными продуктами производительность запроса данных может быть улучшена более чем в 10 раз.
3 «Окончательное будущее» больших моделей и корпоративных данных: полное сотрудничество
В прошлом большие данные и искусственный интеллект сталкивались с проблемой: несмотря на то, что они обладают мощными возможностями и их легко продемонстрировать, возможность их широкого использования в различных сценариях всегда была проблемой. Доктор Хе считает, что это ключевое условие для оценки того, являются ли большие языковые модели разрушителями этой промышленной революции. Только когда большие языковые модели смогут широко использоваться в различных сценариях, можно будет по-настоящему продемонстрировать их потенциал и ценность.
Это означает, что после того, как предприятие развертывает большую модель, ключевым вопросом становится создание саморазвивающейся структуры больших моделей. Самоитеративная среда приложений больших моделей может помочь предприятиям создавать приложения больших моделей на основе их собственных систем данных, позволяя предприятиям интегрироваться. данные с большими моделями могут достичь максимальной ценности при полной координации.
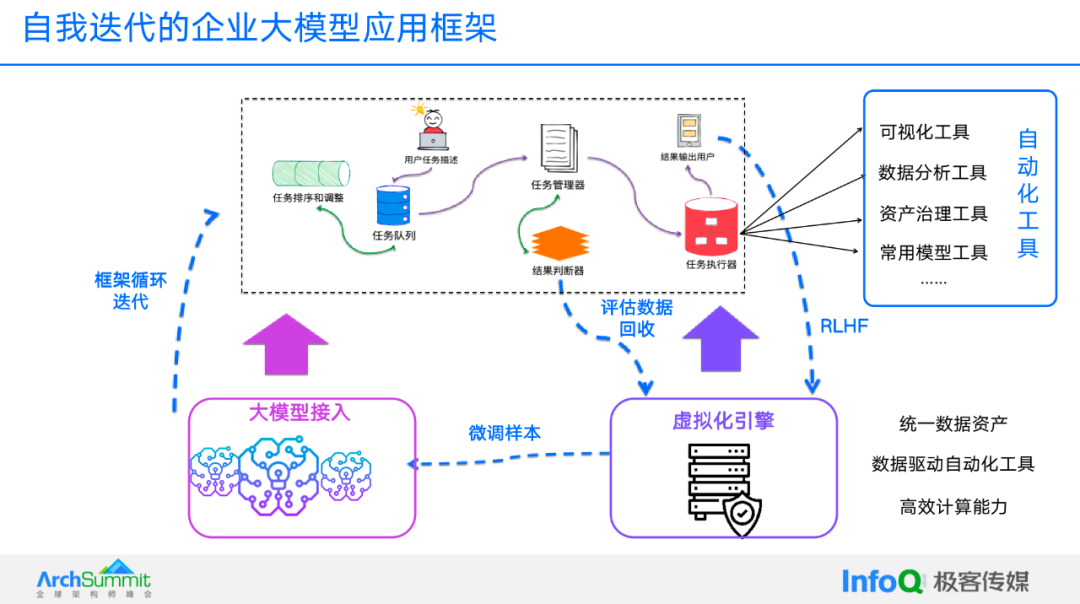
Рисунок: Самоитерационная структура приложения большой модели предприятия.
Что касается полного взаимодействия между большими моделями и корпоративными данными, Shuding Technology также провела множество исследований - самоитеративную среду приложений для больших корпоративных моделей. Фреймворк можно подключать к различным крупным моделям, разлагать проблемы пользователя на ряд задач и назначать выполнение. Выполнение задач требует использования данных. Механизм виртуализации унифицированно управляет ресурсами данных и обеспечивает эффективные вычисления. В процессе выполнения выполняется оценка, и результаты возвращаются пользователю. Отзывы включают в себя маркировку и штрафы. -настроенные образцы Механизм виртуализации управляет данными и передает их обратно в большую модель для обработки. В этой системе большие модели играют роль логического рассуждения, что является одной из наиболее редких ее способностей. Стоит также отметить, что, столкнувшись с корпоративным спросом на «большие модели, действующие как функции базы знаний», предприятия могут полностью использовать эту систему данных для организации. По сравнению с другими методами, она работает в режиме реального времени, и можно сказать, что она работает в режиме реального времени. что, пока она может, взаимодействуя с логическими возможностями больших моделей, эта система может предоставлять предприятиям более качественные услуги.
Однако, глядя на все текущие сценарии применения больших моделей, многие люди задаются вопросом, «стоит ли задуматься о точке зрения доктора Хе: «Что касается будущего больших моделей, особенно внутри предприятия, то и то, и другое». одновременно необходимы большие модели и корпоративные данные. Нам нужно полностью сотрудничать между ними, чтобы действительно помочь реализовать интеллектуальное принятие решений в широком спектре бизнес-сценариев».
Текущее видение Shutop Technology заключается в идеальной реализации «полного сотрудничества между большими моделями и корпоративными данными». Как сказал доктор Хе в эксклюзивном интервью InfoQ после своего выступления: «Я надеюсь, что предприятия смогут полностью интегрировать данные через наши продукты». При правильном управлении и использовании его можно глубоко скоординировать с большими моделями, чтобы предоставить предприятиям возможности интеллектуального принятия бизнес-решений».
Ниже прилагается видеозапись интервью доктора Хе с InfoQ после его выступления. Вы можете поближе познакомиться с наблюдениями доктора Хе о «разработке крупных моделей и управлении корпоративными данными»:
http://mpvideo.qpic.cn/0bc3eeaamaaajuadckwb45sfaiodayqqabqa.f10002.mp4?



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
