Новая парадигма для точной настройки больших моделей: когда LoRA встречается с Министерством экологии
Автор: Сэм Ешьте больше зеленых овощей, степень бакалавра компьютерных наук Пекинского университета/инженер-алгоритм на квазибольшом заводе Заявление: Эта статья предназначена только для распространения. Авторские права принадлежат оригинальному автору. Нарушающие права личные сообщения будут удалены! https://zhuanlan.zhihu.com/p/683637455 Редактор: Highland Barley AI
введение
Когда LoRA встретится с Министерством экологии, какая искра возникнет?

Слева: исходная версия LoRA, веса плотные, все параметры активированы для каждой выборки. Справа: LoRA в сочетании со структурой смешанных экспертов (MoE), каждый слой вставляет несколько параллельных весов LoRA (т. е. в моделях MoE Multiple Experts). модуль маршрутизации (Маршрутизатор) выводит вероятность активации каждого эксперта, чтобы решить, какие модули LoRA активировать.
Из-за чрезмерного использования видеопамяти при полной настройке большой модели LoRA, Адаптера, IA3 这些Эффективная точная настройка параметров(Parameter-Efficient Метод настройки (сокращенно PEFT) стал стандартом точной настройки крупных моделей для учреждений и исследователей с ограниченными ресурсами. Общая идея метода PEFT состоит в том, чтобы заморозить основные параметры большой модели и ввести небольшое количество обучаемых параметров в качестве модулей адаптации для обучения, чтобы сэкономить затраты на видеопамять и хранилище параметров при тонкой настройке модели.
Традиционно,LoRAПараметры этого типа модуля адаптации такие же, как и основные параметры.плотныйиз,Процесс вывода по каждому образцу требует использования всех параметров. недавно,Чтобы преодолеть узкое место в эффективности параметров плотной модели, исследователи в целом,начинатьсосредоточиться наподобие Mistral, DeepDeek Эксперты по смесям, представленные Министерством экологии (Mixure of Experts,МО для краткости) Модель каркасная. в рамках этой структуры,Модельиз某个模块(нравитьсяTransformerиз某个FFNслой)会存在多组形状相同из权重(называетсяэксперт),Есть еще одинмодуль маршрутизации(Router)принять необработанный ввод、Вывод каждогоэкспертиз激活权重,Окончательный результат:
- • нравиться果是мягкая маршрутизация,Выведите взвешенную сумму результатов каждого эксперта;
- • нравиться果是дискретная маршрутизация,Прямо сейчасMistral、DeepDeek Разреженное смешивание, использованное экспертом МО (Sparse МЭ) архитектуры, то Топ-К (К фиксированный гиперпараметры,То есть количество активируемых каждый раз экспертов,Если веса, отличные от 1 или 2), сбрасываются до нуля.,Добавьте вес и сумму.
В архитектуре MoE степень активации параметра каждого эксперта зависит от веса маршрутизации, определяемого данными, так что параметры каждого эксперта могут фокусироваться на типе данных, с которым он хорошо справляется. В случае дискретной маршрутизации экспертам, чьи веса маршрутизации находятся за пределами TopK, даже не нужно рассчитывать, что значительно снижает вычислительные затраты на вывод, обеспечивая при этом общую емкость параметров.
Так,Для уже вышедшего тренинга PEFT плотныйбольшой Модель,Можно ли применить идею МЧС? недавно,Автор сосредоточился на исследовательском сообществе и начал сочетать метод PEFT, представленный LoRA, с структурой MoE.,предложенныйMoV, MoLORA, LoRAMOE и MOLA等新изPEFTметод,По сравнению с исходной версией LORA эффективность тонкой настройки большой модели была еще больше улучшена.
В этой статье будут интерпретированы три типичных произведения. Ниже приводится версия, которую слишком долго читать:
- • МОВ и МОЛОРА [1]: Предложенная в сентябре 2023 года первая работа, объединяющая PEFT и МО, МОВ. и МОЛОРА соответственно IA3 和LORAизMOEВерсия,Принять мягкую маршрутизацию на уровне токена (взвешенный совокупный результат всех экспертов). Автор нашел,SFT для T5 big Модель на 3B и 11B,MoV использует только менее 1% обучаемых параметров для достижения того же эффекта, что и полная точная настройка.,Значительно лучше, чем LoRA при той же настройке обучаемых параметров.
- • LoRAMOE [2]: Предложено в декабре 2023 года в MoLORA. На основании [1] для решения проблемы забывания катастрофы при тонкой настройке большой Модели Ло РАэксперт на той же позиции разделен на две группы, каждая из которых отвечает за сохранение мировых весов в предтренировочных весах. . знания и тонкая настройка для изучения новых задач, и для этой цели предназначена новая потеря балансировки нагрузки.
- • MOLA [3]:вырос в2024Год2луна,Использовать дискретную маршрутизацию (каждый раз активировать только маршрутизацию с весом топ-2 экспертов),И обнаружил, что установка одинакового количества экспертов на каждом слое неоптимальна.,Увеличьте количество экспертов высокого уровня и уменьшите количество экспертов нижнего уровня.,При условии, что количество обучаемых параметров остается неизменным,,Значительно улучшить эффект тонкой настройки LLaMa-2.
MoV и MoLORA: PEFT впервые встречается с Министерством экологии история начинается
Диссертация: Толкание Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning
Ссылка: https://arxiv.org/abs/2309.05444.В этой работе впервые предлагается комбинация метода PEFT типа LoRA и структуры MoE для достижения MoV ( IA3изMOE)версия иMoLORA(LORAизMOE)Версия,Было обнаружено, что производительность MoV выше, чем у оригинального LORA при том же наборе обучаемых параметров.,Очень близко к полной настройке параметров. Обзор IA3 Конструкция модуля адаптации, то есть выходные данные первого полностью связанного слоя Трансформатора K, V и FFN, умножаются поточечно на обучаемый вектор. lk,lv,lff :
softmax(dkQ(lk⊙KT))(lv⊙V);(lff⊙γ(W1x))W2.
Затем MOV копирует каждый из этих обучаемых векторов. n параметры (n — количество экспертов) и добавьте модуль маршрутизации для приема скрытого вектора, первоначально выдаваемого K/V/FFN. xhidden , выведите вес активации каждого эксперта и получите вероятность активации каждого эксперта после прохождения softmax. s , просуммируйте каждый обучаемый вектор, используя его в качестве веса (а затем добавьте его к исходной версии IA3 Аналогичным образом умножьте суммированную векторную точку на скрытый вектор исходного вывода). Схема следующая:
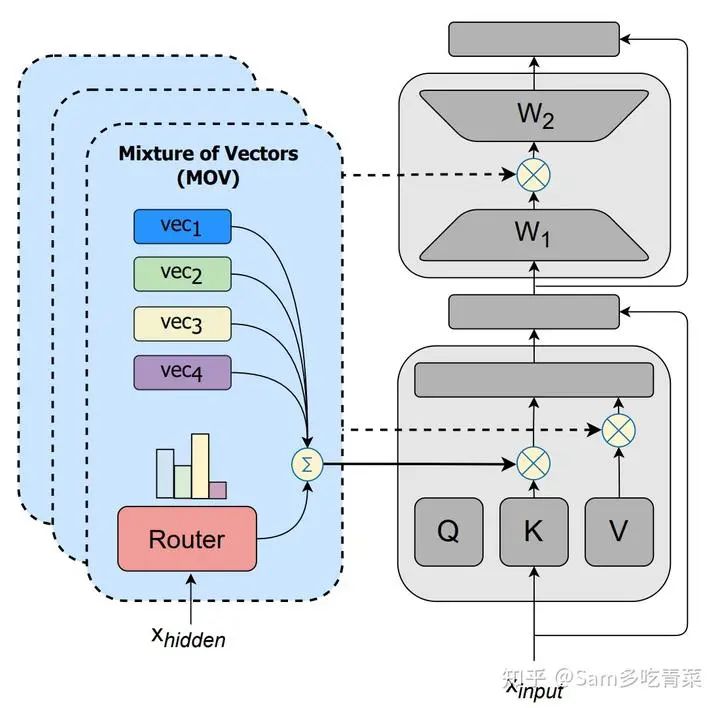
Принципиальная схема метода MOV, цитата из статьи [1].
Экспериментальная часть, автор в Паблике Pool of На наборе данных Prompts инструкция выполнила точную настройку модели T5 с размером параметра от 770M до 11B, за 8 удерживаемых Протестируйте на имеющемся тестовом наборе. Экспериментальные методы тонкой настройки включают полную тонкую настройку, оригинальную версию. IA3 и ЛОРА, МОВ и МОЛОРА. Судя по результатам испытаний, производительность MoV значительно лучше, чем у MoLORA и оригинальной версии. IA3 и ЛОРА. Например, количество экспертов n=10 MoV-10 использует только 0,32% параметров модели 3B для достижения того же эффекта, что и полная тонкая настройка, что значительно лучше, чем такое же количество обучаемых параметров. IA3 и LORA, в то время как MoV-30 (60,61) с использованием обучаемых параметров 0,68% даже превосходит полную точную настройку.
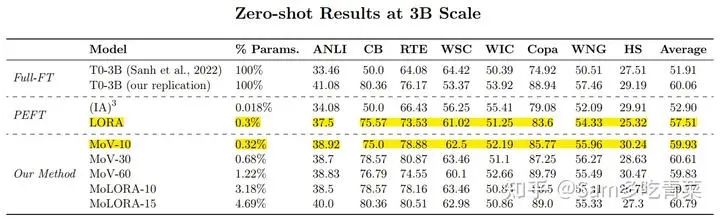
Результаты испытаний модели 3В показывают, что средняя точность (59,93) MoV-10 при использовании всего 0,32% обучаемых параметров близка к полному объему тонкой настройки (60,06), что значительно лучше исходной версии LORA (57,71) с использованием 0,3% обучаемых параметров. MoV-30 (60,61) с использованием обучаемых параметров 0,68% даже превосходит полную точную настройку.
Кроме того, автор также проанализировал экспертность экспертов (то есть степень зависимости каждой задачи от нескольких конкретных экспертов), показав распределение вероятностей маршрутизации каждого эксперта в последнем слое FFN штрафа MOV-5. -тюнингованная модель 770М:
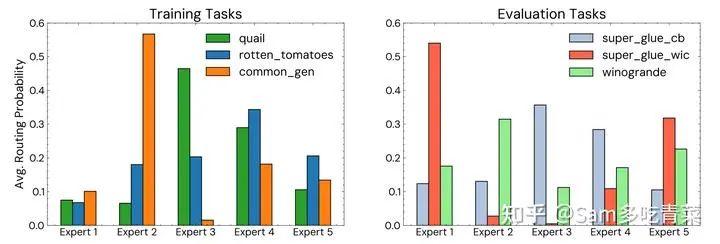
Распределение вероятностей маршрутизации. Левая часть — это задачи, которые модель видела в обучающем наборе, а правая — задачи, которые модель не видела в тестовом наборе.
Видно, что независимо от того, видела ли модель данные задачи или нет, в большинстве задач есть 1-2 эксперта с особым фокусом, занимающие большую часть значений вероятности активации, что указывает на то, что MoV, реализация MoE, достигла экспертной специализации.
LoRAMOE: экспертная группа LoRA, Предтренировочные знания запоминаются прочнее
Бумага: ЛОРАМОЭ: Revolutionizing Mixture of Experts for Maintaining World Knowledge in Language Model Alignment
Ссылка: https://arxiv.org/abs/2312.09979.Эта статья является работой группы НЛП Фуданьского университета.,Мотивация исследования – решитьПроблема аварийного забывания во время тонкой настройки больших моделей.。
Автор нашел,По мере увеличения объема используемых данных,SFTобучение приведет кПараметры модели значительно отличаются от параметров предварительного обучения.,预训练阶段学习到измировые знания(world знания) постепенно забывается. Хотя способность модели следовать инструкциям улучшается и ее производительность на обычных тестовых наборах увеличивается, производительность задач контроля качества, требующих этих мировых знаний, значительно падает:
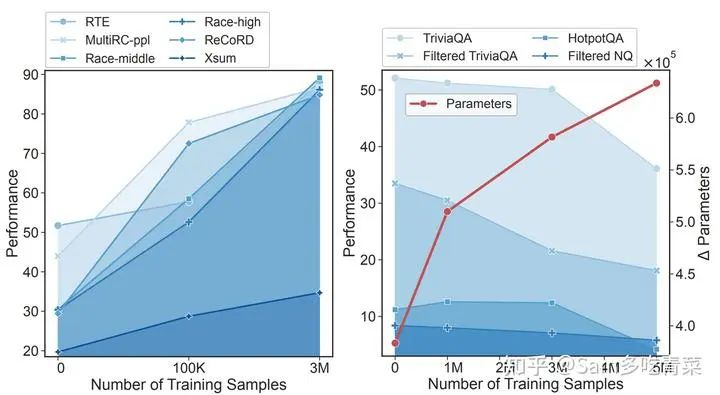
Слева показана производительность на обычном наборе тестов, не требующем мировых знаний, а справа — производительность на наборе тестов QA, требующем мировых знаний. Горизонтальная ось — это объем данных SFT, а красная линия — это объем данных SFT. степень изменения параметров модели.
Решение, предложенное автором:
- • часть данных:присоединитьсяworld Репрезентативность набора данных знаний CBQA, замедление Модель на мировые забывчивость знаний;
- • часть модели:к(1)уменьшать Модель Изменения параметров、(2)Изоляциямировые Параметры знаний и знаний о новых задачах являются руководящей идеологией. Метод LoRAMoE разработан на основе идеи MoLORA, изложенной в предыдущей статье, а LoRAэксперт разделен на две группы. Одну группу можно обрабатывать, сохраняя параметры предварительного обучения (). и мировые знания相关из)Задача,Набор новых задач, возникающих при изучении SFT,Как показано ниже:

Чтобы хорошо подготовить таких групповых экспертов, дать возможность двум группам экспертов выполнять свои обязанности между группами (выполнять два типа задач соответственно) и сбалансировать нагрузку внутри группы, автор разработал метод, названный локализованным. balancing механизм ограничений балансировки нагрузки contraint. В частности, предположим Q — матрица важности, выдаваемая модулем маршрутизации, Qn,m Представляет собой первый n Эксперты против. m Вес обучающих выборок, I определены для автора и Q Матрицы одинаковой формы:
In,m={1+δ,Typee(n)=Types(m).1−δ,Typee(n)=Types(m)⋅1
в δ — фиксированное значение от 0 до 1 (суперпараметр, контролирующий дисбаланс двух групп экспертов), Typee(n) для первого Типы n экспертов (пусть группа, ответственная за сохранение предтренировочных знаний, равна 0, а группа, ответственная за изучение новых задач, — 1), Types(m) для первого m Тип выборки (предположим, CBQA, представляющий знания перед обучением, равен 0, а другие данные SFT — 1). потери при балансировке нагрузки Llbc определяется как использование I взвешенная матрица важности Z=I∘Q Дисперсия, разделенная на среднее значение:
Llbc=μ(Z)σ2(Z).
Цель такого проектирования потерь состоит в том, чтобы для любого типа обучающей выборки две группы экспертных групп LoRA I Значения равны, оптимизация Llbc То есть дисперсия веса маршрутизации внутри группы уменьшается, чтобы сбалансировать нагрузку внутри группы между двумя группами экспертов, предполагая, что экспертная группа A лучше справляется с текущим типом данных, чем ее; I Значение больше, чем у эксперта другой группы B, вес активации A на начальном этапе обучения значительно больше, чем у B, и у A больше возможностей обучения для такого рода данных, модуль маршрутизации В процессе обучения я постепенно стал более склонен к такого родаданныевыбиратьA组изэксперт。Этот вид“Сильные становятся сильнее”из极化现象是MoE领域из经典问题,См. классический документ sMoE «Сложная смесь экспертов» [4] Объяснение этого вопроса.
Таким образом, даже если на этапе вывода нет информации типа данных I, значение маршрутизации Q для этих данных будет значительно больше, чем соответствующее значение B. Это достигает цели, заключающейся в том, что две группы экспертов выполняют свои соответствующие задачи. обязанности.
В экспериментальной части автор настроил LLaMA-2-7B на данных SFT, смешанных с CBQA и рядом наборов данных последующих задач, и сравнил производительность полного SFT, обычного LORA и LoRAMoE, предложенного автором. Результаты показывают, что LoRAMoE эффективно преодолевает проблему катастрофического забывания в процессе SFT большой модели, демонстрируя наилучшую производительность при выполнении задач контроля качества, требующих мировых знаний (нижняя половина таблицы ниже), и среднюю производительность при выполнении других задач, более тесно связанных с данные обучения SFT в основном эквивалентны модели, обученной SFT:

МОЛА: Для координации и повышения эффективности необходимо больше экспертов на старших уровнях ближе к конечному результату.
Диссертация: Высшая Layers Need More LoRA Experts
Ссылка: https://arxiv.org/pdf/2402.08562.pdf.Данная работа подлежитMoEПредыдущая работа в этой области[5]发现изСлишком много экспертов может легко привести к снижению производительности.из现象之启发,Было задано два вопроса:
- • 现有PEFT+MoEиз微调метод是否存在эксперт冗余из问题?
- • нравиться何在不同Количество экспертов распределяется между средними уровнями?
Чтобы ответить на вопрос 1, автор обучил LoRA+MoE с 5 экспертами на каждом уровне (базовая модель — LLaMa-2 7B с 32 уровнями). Механизм маршрутизации использует дискретную маршрутизацию Top-2 и рассчитывает самовнимание каждого. Среднее значение нормы Фробениуса разницы между каждой парой экспертных весов в каждой группе Q, K, V и O визуализируется следующим образом:
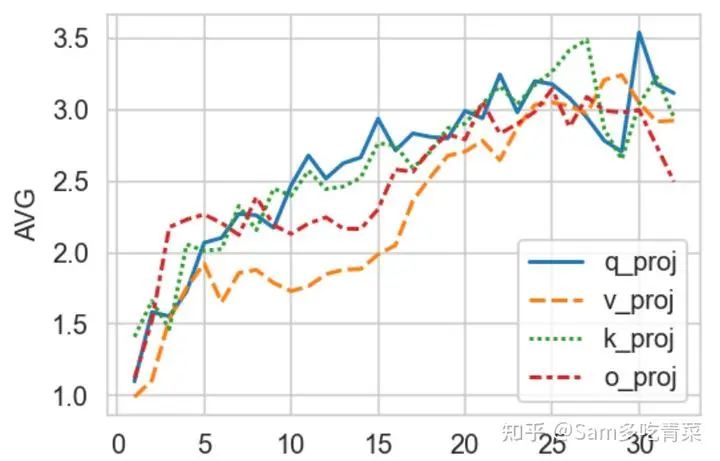
Горизонтальная ось — количество слоев модели, а вертикальная ось — степень разницы между экспертными весами.
Это можно увидеть,Чем выше количество слоев (приблизительно ближе к выходному концу),Чем больше разница между экспертом,Разница между экспертом низкого уровня очень мала,Внизу Большой Модели имеется избыточность весов LoRAэксперта.。Это наблюдение естественным образом приводит к вопросу2答案из猜想:Нужно больше экспертов наверху,При бюджетном ограничении сумма количества экспертов на каждом уровне фиксирована.,Часть первого этажа следует перенести на верхний этаж.,Если поместить это в оригинальное название:
Higher Layers Need More Experts
Чтобы проверить это предположение,Автор предлагает четыре варианта метода деления чисел эксперта, которые серьезно отличаются производительностью.,它们统называетсяMoLA(MoE-LoRA with Layer-wise Expert Распределение), соответственно:
- • MoLA-△: равносторонний треугольник.,Есть много нижних слоев,Количество высотных зданий невелико;
- • MoLA-▽: перевернутый треугольник, меньше нижнего слоя и больше верхнего слоя;
- • MoLA-▷◁: форма песочных часов, больше на концах и меньше в середине;
- • MoLA-□: Квадрат, равномерное распределение по умолчанию.

Четыре способа разделить количество экспертов между разными промежуточными уровнями.
В конкретной реализации автор делит 32 слоя LLaMA на 4 группы от низкого к высокому, а именно слои 1-8, 9-16, 17-24, 25-32. Общее количество экспертов в четырех вышеуказанных методах деления равны. Конкретные подразделения:
- • MoLA-△:8-6-4-2
- • MoLA-▽:2-4-6-8;
- • MoLA-▷◁: 8-2-2-8;
- • MoLA-□:5-5-5-5。
Механизм маршрутизации представляет собой маршрутизацию Top-2 на уровне токена, а потери балансировки нагрузки добавляются во время обучения. Ранг LoRA MoLA = 8, а ранг LoRA в базовом методе равен 64 (количество обучаемых параметров немного больше, чем у четырех вышеупомянутых MoLA, что соответствует версии MOLA-□ 8-8-8-8). Наборы оценочных данных представляют собой модели поездов MPRC, RTE, COLA, ScienceQA, CommenseQA и OenBookQA при двух настройках:
- • Настройка 1: точная настройка модели непосредственно на обучающем наборе каждого набора данных;
- • Настройка 2: сначала выполните SFT для команды OpenOrac, следующего за набором данных, а затем выполните точную настройку модели для обучающего набора каждого набора данных.
Как видно из следующих экспериментальных результатов, при настройке 1 MoLA-▽ достиг наилучшей производительности методов типа PEFT на большинстве наборов данных, намного превосходя исходные версии LoRA и LLaMA-, которые имеют большее количество обучаемых параметров. Адаптер, который достаточно близок к результату полной доводки.
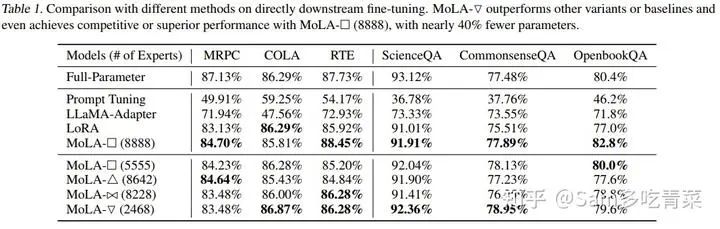
Экспериментальные результаты при настройке 1
При настройке 2,Это также оптимальный метод распределения чисел эксперта перевернутых треугольников MoLA-▽.,Проверено "Нужно больше экспертов наверху”из猜想。

Комментарий автора: С интуитивной точки зрения высокоуровневые слои модели кодируют больше высокоуровневой информации и ближе к обучающему сигналу целевой задачи. По сравнению с низкоуровневыми параметрами, кодирующими базовые атрибуты языка, они требуют. больше корректировок, что согласуется с выводами этой статьи, а также совпадает с общим методом послойной настройки скорости обучения в трансферном обучении (установка более высокой скорости обучения на верхнем уровне и установка более низкой скорости обучения на нижнем уровне). ). В будущем мы сможем выяснить, может ли их сочетание привести к дальнейшему улучшению.
Ссылки
[1] Zadouri, Ted, et al. "Pushing mixture of experts to the limit: Extremely parameter efficient moe for instruction tuning."arXiv preprint arXiv:2309.05444(2023).
[2] Dou, Shihan, et al. "Loramoe: Revolutionizing mixture of experts for maintaining world knowledge in language model alignment."arXiv preprint arXiv:2312.09979(2023).
[3] Gao, Chongyang, et al. "Higher Layers Need More LoRA Experts."arXiv preprint arXiv:2402.08562(2024).
[4] Shazeer, Noam, et al. "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer."International Conference on Learning Representations. 2016.
[5] Chen, Tianlong, et al. "Sparse MoE as the New Dropout: Scaling Dense and Self-Slimmable Transformers."The Eleventh International Conference on Learning Representations. 2022.


Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
