Nomic Embed: модель встраивания SOTA с открытым исходным кодом, которую можно воспроизвести.
Nomic-embed-text был выпущен только в феврале и представляет собой модель встраивания английского текста с полностью открытым исходным кодом и длиной контекста 8192. Он превосходит существующие модели, такие как Ada-002 от OpenAI и text-embedding-3-small, при обработке как коротких, так и длинных текстовых задач. Эта модель имеет 137M параметров, что сейчас можно считать очень маленькой моделью.
Были выпущены модель, обучающий код и большой набор данных из 235 миллионов текстовых пар, что позволяет нам воспроизводить, проверять и перестраивать эту современную модель внедрения.

Модельная архитектура
Ниже приведены архитектурные изменения и оптимизации этой модели, примененные к базе BERT:
- Используйте ротационное позиционное внедрение вместо абсолютного позиционного кодирования.
- Используйте активацию SwiGLU вместо GeLU.
- Используйте мгновенное внимание.
- Удалить отсев.
- Размер словаря кратен 64.
В результате получается nomic-bert-2048, модель с максимальной длиной последовательности 2048 на всех этапах. Используйте динамическую интерполяцию NTK во время вывода, чтобы расширить модель до длины последовательности 8192.
Дампы BooksCorpus и Википедии 2023 года используются в качестве корпусов предварительного обучения. Каждый документ сегментируется с помощью токенизатора без регистра bert-base и упаковывается в фрагменты с тегами 2048. Используйте коэффициент маски 30% вместо BERT 15%. Предварительное обучение не учитывает задачу прогнозирования следующего предложения и выполняет только заполнение маски.
Предварительное обучение для сравнения без присмотра
Он учит Модель отличать наиболее похожие документы от других нерелевантных документов.
Набор данных статьи использует большой объем общедоступных данных для формирования текстовых пар. Эти наборы данных охватывают различные цели и области, от поиска в Интернете до научных статей, при этом в общей сложности выбрано 470 миллионов текстовых пар из 29 наборов данных.
Чтобы удалить зашумленные сэмплы, была выполнена фильтрация согласованности с использованием модели gte-base.
Для 1 миллиона подвыборок набора данных каждая пара внедряется как запрос и документ. Если документ не находится в топе k (в данном случае 2), используя косинусное сходство, то пример будет отброшен. После фильтрации получается примерно 235 миллионов текстовых пар.
Кроме того, были использованы полные статьи Википедии с их названиями, а также рефераты и полнотекстовые тексты отдельных статей из S2ORC, в результате чего был получен длинный контекстный набор данных.
Во время обучения одна пара отбирается из одного источника данных за раз, и весь пакет заполняется выборками из одного источника данных. Это предотвращает изучение модели проблем, связанных с источником (не позволяя модели использовать ярлыки и уменьшая переобучение). .)
Используйте InfoNCE для сравнения потерь. Для данной партии B = (q0, d0), (q1, d1), …, (qn, dn) минимизация выглядит следующим образом:

Среди них s(q, d) — это косинус-подобие (q, d).
Чтобы нарушить симметрию двух кодировщиков, используются следующие префиксы для конкретных задач:
- Поисковый запрос (обычно используется для вопросов)
- Поиск документов (обычно используется в ответе)
- Классификация (для задач, связанных с STS, таких как переписывание)
- Кластеризация (для задачи группировки семантически схожих текстов)
Надзор против тонкой настройки
Этот этап обучения направлен на повышение производительности за счет использования наборов данных, размеченных человеком.
Контролируемая точная настройка выполняется на основе некоторых данных из MSMarco, NQ, NLI, HotpotQA, FEVER, MEDI, WikiAnswers и Reddit.
Парная потеря контраста корректируется таким образом, чтобы в каждой партии были включены неразличимые отрицательные образцы. Авторы обнаружили, что увеличение количества отрицательных образцов выше 7 существенно не улучшило производительность. Кроме того, многократные тренировки также могут привести к ухудшению производительности.
Оценивать

Небольшая выборка BEIR была проведена на сайте Оценивать.,Было получено влияние обучения на конкретном наборе данных на общий балл MTEB. Тренировки на наборах существованияFEVER, HotpotQA и MEDIданные улучшили общий балл MTEB.,Это показывает, что выбор существующих наборов данных при обучении имеет решающее значение для повышения производительности.
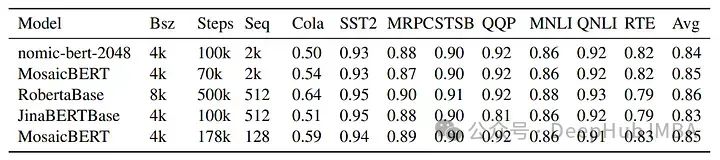
nomic-bert-2048существовать Тест производительности GLUE проводился на Оценивать. для некоторых задач,Он инициализируется с контрольной точки MNLI. nomic-bert-2048существовать Эталонный тест GLUE Сравнительно конкурентоспособен с моделью аналогичного размера и подготовки,Оценки по каждому заданию также очень похожи на MosaicBERT и JinaBERTсуществовать.,За исключением Cola (в этой задаче из-за более длинной последовательности Модели), поскольку существующие видят больше токенов во время предварительного обучения.,Так что производительность другая.

Тест МТЕБ
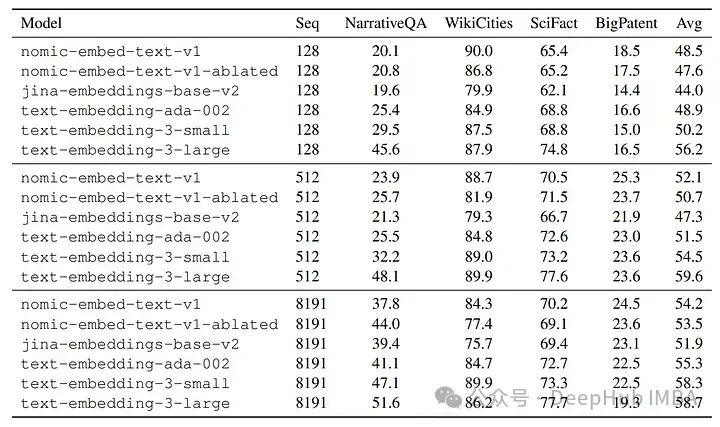
Джина длинный контекстный тест
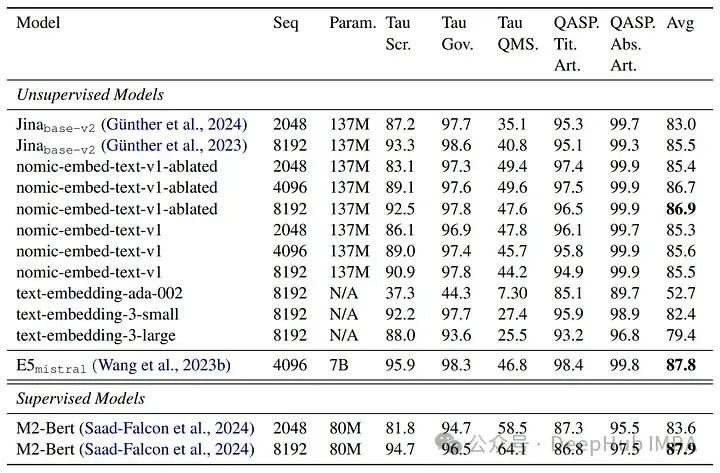
Ло Ко Бенчмарк
Сравнение nomic-embed-text-v1 с другими моделями, такими как text-embedding-ada-002 и jina-embeddings-v2-base-en. nomic-embed-text-v1 превосходит text-embedding-ada-002 и jina-embeddings-v2-base-en на MTEB. Он неизменно превосходит jina-embeddings-v2-base-en в тестах с длинным контекстом (тесты с длинным контекстом LoCo и Jina), демонстрируя превосходную производительность на длинных последовательностях.
Nomic Embed 1.5
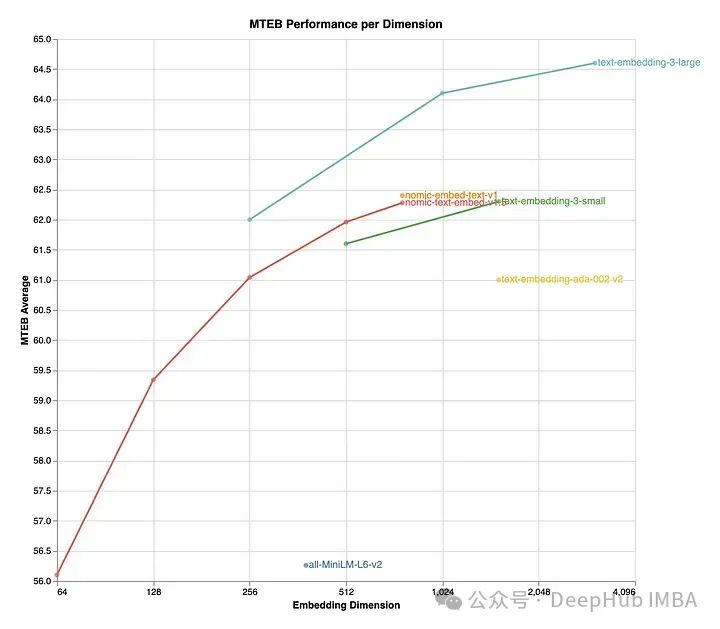
Nomic Embed v1.5 — это расширенная версия модели Nomic Embed, которая включает в себя обучение представлению Matryoshka, позволяя настраивать размеры внедрения в рамках одной модели. Процесс обучения начинается с неконтролируемого сравнительного обучения на слабо связанных текстовых парах и постепенно переходит к точной настройке на наборах размеченных данных более высокого качества.
nomic-embed-text-unsupervised осуществляет тонкую настройку с использованием MRL в наборе данных точной настройки nomic-embed-text.
Nomic Embed v1.5 поддерживает размеры встраивания от 64 до 768 и превосходит другие модели в размерах 512 и 768. Он обеспечивает значительное сокращение памяти по сравнению с предыдущими версиями, сохраняя при этом уровень производительности, сравнимый с другими продвинутыми моделями, такими как MiniLM-L6-v2.
Вот краткое введение в обучение представлениям матрешки:
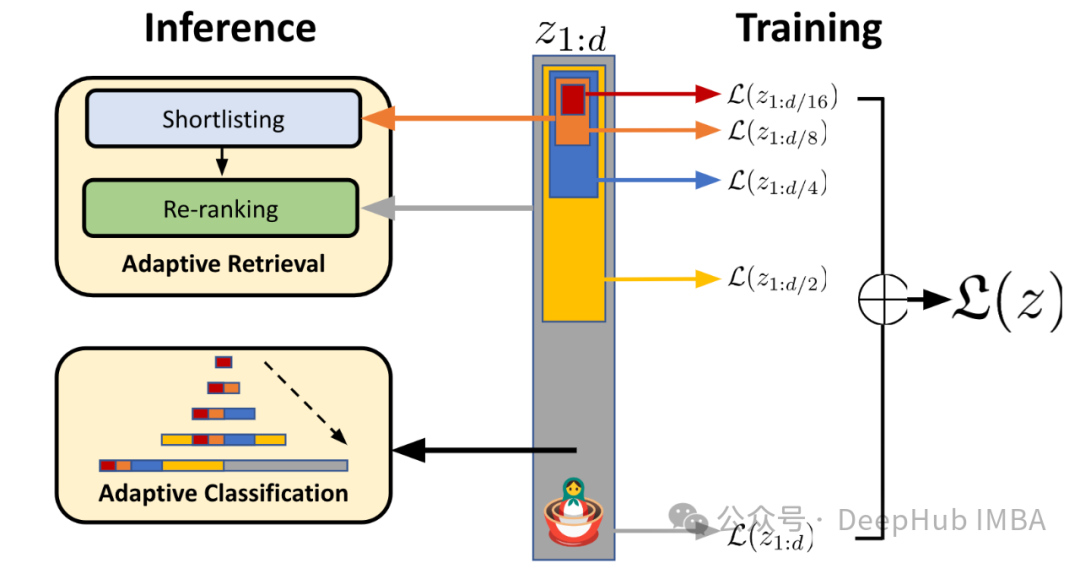
Обучение матрешковому представлению — это метод, который позволяет нашим моделям иметь переменные размеры внедрения. Подобно русским матрешкам, мы явно обучаем модель изучению вложенных представлений в различных измерениях встраивания. Это позволяет нам усекать встраивания от их полного размера, чтобы уменьшить объем памяти, сохраняя при этом производительность.
Подвести итог
Я очень рад видеть последнюю статью по внедрению текста. Эта статья также показывает, что лучшие результаты тестирования могут быть получены, когда модель очень мала. Это очень важно для нашего приложения. Это стало динамичным пространственным представлением, но лично я считаю, что в этой области можно добиться большего развития.
бумага:
https://arxiv.org/abs/2402.01613
Код обучения:
https://github.com/nomicai/contrastors
Matryoshka Representation Learning
https://arxiv.org/abs/2205.13147
Автор: Ритвик Растоги



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
