NL2SQL Advanced Series (5): бумажная интерпретация ведущих отраслевых решений (DIN-SQL, C3-SQL, DAIL-SQL), интерпретация набора данных нового поколения BIRD-SQL.
NL2SQL Advanced Series (5): бумажная интерпретация ведущих отраслевых решений (DIN-SQL, C3-SQL, DAIL-SQL), интерпретация набора данных нового поколения BIRD-SQL.
Серия практик NL2SQL (1): Углубленный анализ навыков применения проекта Prompt в text2sql.
Цель задачи NL2SQL — преобразовать вопросы пользователей о базе данных на естественном языке в соответствующие запросы SQL. С развитием LLM использование LLM для NL2SQL стало новой парадигмой. В этом процессе особенно важно то, как использовать быстрые проекты для изучения возможностей LLM NL2SQL.
1.DIN-SQL-V3 2023.11.02
- v1 Fri, 21 Apr 2023 15:02:18 UTC (8,895 KB)
- v2 Thu, 27 Apr 2023 17:49:23 UTC (8,895 KB)
- v3 Thu, 2 Nov 2023 20:30:12 UTC (2,202 KB)
Бумажная ссылка:DIN-SQL: Decomposed In-Context Learning of Text-to-SQL withSelf-Correction
Аннотация: Мы изучаем проблему разложения сложных задач преобразования текста в SQL на более мелкие подзадачи и то, как это разложение может значительно улучшить производительность больших языковых моделей (LLM) во время вывода. В настоящее время существует значительный разрыв между производительностью точно настроенных моделей и методов подсказки, использующих LLM для сложных наборов данных преобразования текста в SQL, таких как Spider. Мы демонстрируем, что генерацию SQL-запросов можно разложить на подзадачи, а решения этих подзадач можно передать в LLM, чтобы значительно повысить его производительность. Наши эксперименты с тремя LLM показывают, что этот подход последовательно улучшает их производительность при простой небольшой выборке примерно на 10%, повышая точность LLM до SOTA или выше. На тестовом наборе Spider’s Holdout SOTA по точности выполнения составляет 79,9, а новый SOTA по нашему методу — 85,3. Наш подход контекстного обучения превосходит многие хорошо настроенные модели как минимум на 5%.
В этой статье мы предлагаем новый подход, основанный на подсказках из нескольких шагов, для разложения задачи преобразования текста в SQL на естественном языке (так называемого преобразования текста в SQL) на несколько шагов. Предыдущая работа с использованием LLM для запроса текста в SQL оценивалась только при нулевой настройке. Однако сигналы с нулевой выборкой обеспечивают лишь нижнюю границу потенциальных возможностей LLM для большинства задач. В этой работе мы сначала оцениваем производительность LLM в условиях нескольких кадров, а затем предлагаем наш метод декомпозиции, который значительно превосходит метод хинтинга с несколькими кадрами. Чтобы сравнить наш метод с предыдущими методами, мы используем два официальных показателя оценки: точность выполнения и точность сопоставления. Мы используем два варианта семейства CodeX, а именно Davinci и Cushman, а также модель GPT-4 для подсказок. На тестовом наборе Spider наш метод достигает точности выполнения 85,3% и 78,2% при использовании моделей GPT-4 и CodeX Davinci соответственно, а точность сопоставления 60% и 57% при использовании той же модели соответственно.
1.1 Few-shot Error Analysis
Чтобы лучше понять, где LLM дает сбой при настройке нескольких попыток, мы случайным образом выбрали 500 запросов из разных баз данных в обучающем наборе набора данных Spider, исключив все базы данных, используемые в подсказках. Запрос, который мы искали, дал результаты, которые отличались от стандартных результатов, выдаваемых Spider, поэтому точность выполнения была некачественной. Мы вручную проверили эти неисправности и классифицировали их по шести категориям, как показано на рисунке 1 и обсуждается далее.
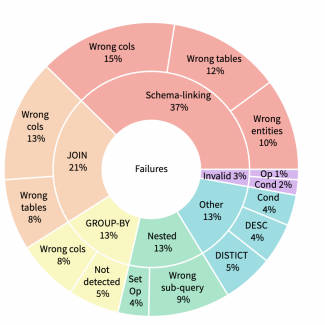
- Schema Linking
Эта категория содержит наибольшее количество неудачных запросов и случаи, когда модель не распознает имя столбца, имя таблицы или сущность, упомянутую в вопросе. В некоторых случаях запрос требует агрегатной функции, но выбирает соответствующие имена столбцов. Например, схема базы данных для вопроса «Какова средняя и максимальная вместимость всех стадионов?» включает столбец «среднее», который выбирается моделью вместо среднего значения столбцов вместимости.
- JOIN
Это вторая по величине категория, в которую входят запросы, требующие JOIN, но модель не распознает все необходимые таблицы или правильные внешние ключи для объединения таблиц.
- GROUP BY
В эту категорию входят ситуации, когда оператор SQL требует предложения GROUP BY, но модель не распознает необходимость группировки или для группировки результатов используется неправильный столбец.
- Queries with Nesting and Set Operations
Для этой категории стандартный запрос, заданный Spider, использует вложенные операции или операции над множествами, но модель не распознает вложенную структуру или не может обнаружить правильные вложенные операции или операции над множествами.
- Invalid SQL
Небольшая часть сгенерированных операторов SQL содержит синтаксические ошибки и не может быть выполнена.
- Miscellaneous
В эту категорию входят дела, не подпадающие ни под одну из вышеперечисленных категорий. Примеры включают запросы SQL, которые содержат дополнительные предикаты, отсутствующие предикаты или отсутствующие или избыточные ключевые слова DISTINCT или DESC. В эту категорию также входят ситуации, когда предложение WHERE отсутствует или запрос имеет избыточные агрегатные функции.
1.2 Methodology
Хотя модели с несколькими выстрелами обеспечивают улучшения по сравнению с моделями с нулевым выстрелом, модели с несколькими выстрелами испытывают трудности с обработкой более сложных запросов, в том числе с менее простыми связями схем и запросами, которые используют множественные соединения или имеют вложенные структуры, как описано в разделе 3. .
Мы подходим к этим задачам, разбивая проблему на более мелкие подзадачи, решая каждую подзадачу и используя эти решения для построения решения исходной проблемы.
Подобные методы (например, подсказки в виде цепочки мыслей (Wei et al, 2022b) и от минимального к большинству подсказок (Zhou et al, 2022)) использовались для повышения эффективности LLM при выполнении задач, которые можно разбить на несколько этапов, таких как математическое слово. проблемы и композиционное обобщение (Cobbe et al., 2021; Lake and Baroni, 2018). В отличие от доменов, где эти задачи имеют процедурную структуру (где один шаг непосредственно ведет к следующему), SQL-запросы в большинстве случаев являются декларативными, а возможные шаги и их границы менее ясны. Однако мыслительный процесс написания SQL-запроса можно разбить на (1) обнаружение таблиц и столбцов базы данных, соответствующих запросу, (2) определение общих структур запроса для более сложных запросов (таких как группировка, вложение, множественные соединения, операции над множествами и т. д.) (3) сформулируйте любые идентифицируемые подкомпоненты процесса и (4) напишите окончательный запрос на основе решения подзадачи.
Основываясь на этом мыслительном процессе, предлагаемый нами метод разложения текста на задачи SQL состоит из четырех модулей (как показано на рисунке 2): (1) связывание схем, (2) классификация и декомпозиция запросов, (3) генерация SQL, (4) ) самокоррекция, подробно описанная в следующих подразделах. Хотя эти модули могут быть реализованы с использованием методов из литературы, мы реализуем их все с помощью методов подсказки, чтобы показать, что LLM способен решить все эти проблемы, если проблемы просто разложены до правильного уровня детализации.
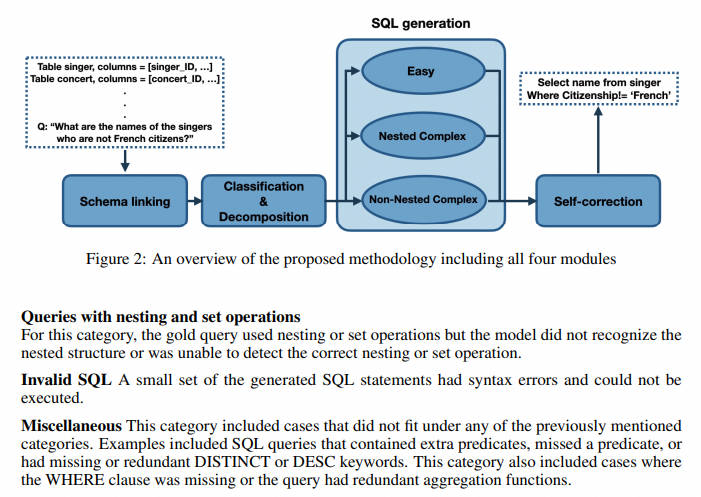
Модуль связывания схем
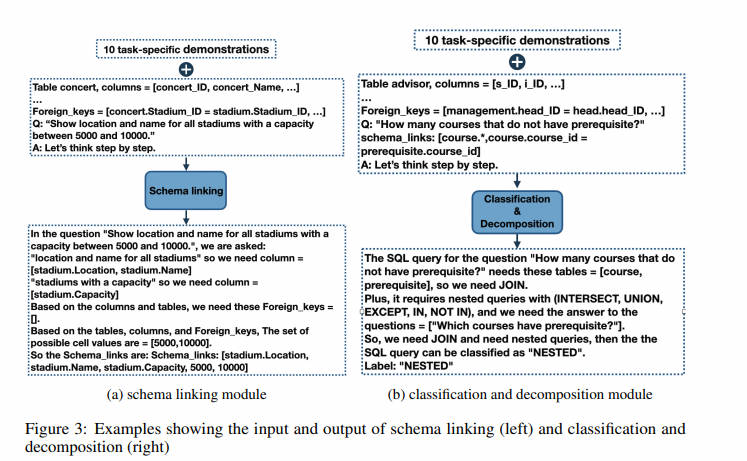
Связывание схем отвечает за идентификацию ссылок на схемы базы данных и условные значения в запросах на естественном языке. Доказано, что он облегчает междоменную общность и синтез сложных запросов (Lei и др., 2020), что позволяет практически всем существующим текстам SQL Важные предварительные шаги в методе. В нашем случае это тоже LLM Категория с наибольшим количеством неудач (рис. 2). Мы разработали модуль связывания шаблонов на основе подсказок. Советы включают от Spider Случайно выбрано из обучающего набора набора данных. 10 Образцы соответствуют шаблону цепочки идей (Wei и др., 2022б), что побудило «Давайте думать шаг за шагом» В начале, как Kojima (2022 г.), как было предложено.
дляпод вопросомКаждый раз, когда упоминается имя столбца, соответствующий столбец и его таблица выбираются из заданной схемы базы данных. Также извлеките возможные из сущностей и значений ячеек из вопроса。картина 3 Приведен пример, полные советы можно найти в приложении A.3 нашел в.
Classification & Decomposition Модуль (модуль классификации и декомпозиции запросов)
для каждого соединения,Возможно, не определены правильные условия подключения. По мере увеличения количества вступлений в Запрос,Также существует повышенная вероятность того, что хотя бы одно соединение будет работать неправильно. Один из способов облегчить эту проблему — ввести модуль для обнаружения соединяемых таблиц. также,Некоторые Запросы имеют технологические компоненты,Например, неактуально изребенок Запрос,Они могут стоять отдельно и сливаться с основным. решить Эти вопросы,Мы представили Запрос Классификацияи Разложить модули。Этот модуль преобразует каждый Запросточкадля Одна из трех категорий:Простой, невложенный комплекс и вложенный комплекс。
- Легкий класс включает в себя возможность отвечать на вопросы из отдельных таблиц без объединения или вложения.
- К невложенным классам относятся Запросиз Запрос, которые необходимо соединить, но не имеют дочерних элементов,
- Вложенные классы могут требовать операций соединения и подмножества.
Метки классов важны для нашего модуля генерации запросов, который использует разные подсказки для каждого класса запроса. Помимо меток классов, классификация и декомпозиция запросов также определяет набор таблиц, которые необходимо объединить для невложенных и вложенных запросов, а также любые подзапросы, которые могут быть обнаружены для вложенных запросов. На рисунке 4 показан пример входных данных, предоставленных модели, и выходных данных, сгенерированных моделью.
Модуль генерации SQL
Поскольку запросы становятся более сложными, необходимо включать дополнительные промежуточные шаги, чтобы преодолеть разрыв между вопросами на естественном языке и операторами SQL. Этот пробел, известный в литературе как проблема несоответствия (Guo et al, 2019), представляет собой серьезную проблему для генерации SQL, поскольку SQL в первую очередь предназначен для запросов к реляционным базам данных, а не для представления значения на естественном языке.
Хотя более сложные запросы могут выиграть от перечисления промежуточных шагов в подсказках цепочки мыслей, такие списки могут снизить производительность при выполнении более простых задач (Wei et al., 2022b). По той же причине наша генерация запросов состоит из трех модулей, каждый из которых ориентирован на свою категорию.
- для Мы делим проблемы на простые категории, без промежуточных шагов, достаточно небольшого количества намеков. Примеры этого Ej Презентация соответствует формату <Qj, Sj, Aj>,в Qj и Aj дано отдельно на английском языке и SQL из Запрос текста, Sj Представляет ссылку на схему.
- Наши из невложенных сложных классов включают в себя необходимость подключения из Запроса. Наш анализ ошибок (стр. 3 Раздел) показывает, что, хотя существование просто несколько раз намекать, поиск правильного столбца и внешнего ключа для объединения двух таблиц для LL.M может быть сложной задачей, особенно когда Запросу необходимо объединить несколько таблиц. для решения этих вопросов мы используем промежуточное представительство для связи Запросов SQL пробелы между высказываниями. В литературе были введены различные промежуточные представления. В частности, SemQL (Guo et al, 2019) Удалено существование из оператора, не имеющего четкого аналога в естественном языке. JOIN ON、FROM и GROUP BY и объединены HAVING и WHERE пункт. NatSQL(Gan и др., 2021) на основе SemQL Операторы множества созданы и удалены. Чтобы выразить для нас посередине, мы используем NatSQL, который демонстрирует высочайшую производительность в сочетании с другими моделями. (Li et al, 2023а). Пример невложенных сложных классов Ej Презентация соответствует формату <Qj, Sj, Ij, Aj>,в Sj и Ij Соответственно представляют j Примеры из Pattern Links и Среднее представительство.
- Вложенные сложные классы. Самый сложный изтип, существованиегенерация требует нескольких промежуточных шагов перед окончательным ответом. Этот класс может содержать вложенные операции над множествами, которые не требуют использования (например, EXCEPT、UNION и INTERSECT) изребенок Запрос, но также требует объединения нескольких таблиц из Запрос, как и предыдущий класс. Для того, чтобы дополнительно разложить проблему на несколько шагов, мы разработали такой подход. LLM Следует сначала решить подзапрос, затем исполь зовать им окончательный ответ. Этот тип намекать соответствует формату <Qj, Sj , <Qj1, Aj1, ..., Qjk, Ajk> , Ij, Aj>,в k представляет количество подзадач, Qji и Aji Соответственно представляют i вопросы - Первая подзадача и №. i Сын Запрос. То же, что и раньше, Qj и Aj Соответственно означает английский и SQL из Запрос,Sj Учитывая ссылку на шаблон, Ij да NatSQL Среднее представительство.
Полные подсказки для всех трех категорий запросов представлены в Приложении A.4, и все примеры для этих трех категорий были получены из одной и той же базы данных, выбранной для подсказок классификации.
Модуль самокоррекции
Сгенерированные SQL-запросы иногда могут содержать отсутствующие или избыточные ключевые слова, такие как DESC, DISTINCT и агрегатные функции. Наш опыт работы с несколькими LLM показывает, что эти проблемы менее распространены в более крупных LLM (например, запросы, созданные GPT-4, содержат меньше ошибок, чем запросы, созданные CodeX), но все же существуют. Чтобы решить эту проблему, мы предлагаем модуль самокоррекции, который инструктирует модель исправлять эти небольшие ошибки.
Это достигается при нулевой настройке, когда модели передается только код с ошибками и предлагается их исправить. Мы предлагаем две разные подсказки для модуля самокоррекции: общую и умеренную. С помощью общей подсказки мы просим модель определить и исправить “BUGGY SQL” ошибка в. С другой стороны, нежные подсказки не предполагают SQL В запросе есть ошибки, и вместо этого модель просит проверить наличие потенциальных проблем и предоставить некоторые подсказки относительно предложений, которые необходимо проверить. Наша оценка показывает, что общие сигналы могут CodeX дает лучшие результаты в модели, а мягкие подсказки полезны для GPT-4 Модель более эффективна. Если прямо не указано иное, иное DINSQL Запрос на самокоррекцию по умолчанию в GPT-4 Установите значение «Мягкое» для CodeX Установите значение «Универсальный». Примеры общих и щадящих подсказок для самокоррекции можно найти в приложении. A.6 нашел в.
Были объяснены основные методы. Более подробную информацию и результаты оценки можно найти в оригинальной статье.
1.3 Случай
- Zero-shot prompting
Подсказки, используемые для сценария нулевого выстрела, вдохновлены работой Лю и др. (2023a), предложенной для ChatGPT. На рисунке 6 мы демонстрируем пример сигналов нулевого выстрела, используемых в нашей работе.

- Few-shot prompting



2.C3: Zero-shot Text-to-SQL-2023.07.14
Бумажная ссылка:https://arxiv.org/pdf/2307.07306.pdf
код https://github.com/bigbigwatermalon/C3SQL
Основываясь на решении с несколькими шагами, предложенном DIN-SQL, C3 использовала chatgpt в качестве базовой модели и исследовала решение с нулевым шагом, которое может еще больше снизить стоимость вывода. А эффект генерации сравним с DIN-SQL. Структура метода C3 показана на рисунке 1. C3 состоит из трех ключевых компонентов: четкие подсказки (CP, Clear Prompting), подсказка о калибровке (CH) и выходные данные согласованности (CO), которые соответствуют входным данным модели, отклонению модели и выходным данным модели соответственно. Подробная информация о каждом компоненте представлена ниже.
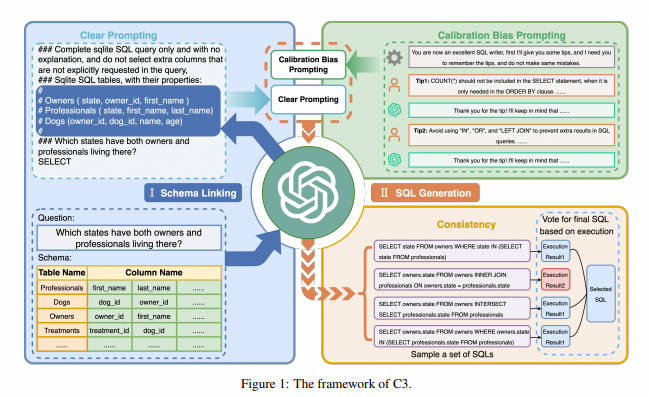
C3 также использует связывание схем, чтобы сначала найти таблицы данных и поля запроса, связанные с проблемой. Однако с точки зрения построения инструкций в статье считается, что при написании инструкций краткий текстовый формат (понятное расположение) и отсутствие введения ненужных табличных структур (четкий контекст) уменьшит сложность понимания модели и значительно улучшит эффект модели. Давайте рассмотрим эти две части по отдельности.
2.1 Clear Prompting
Цель компонента Clear Prompting (CP) — предоставить эффективные подсказки для анализа текста в SQL. Он состоит из двух частей: четкого макета и четкого контекста.
- Тип 1: Сложный макет: этот макет намекать напрямую связывает описание, вопрос и контекст (схему базы данных).,Кажется хаотичным.
- тип 2: Четкий макет: в этом макете используются четкие символы для разделения описания, контекста (схемы базы данных) и вопросов, что выглядит ясным и ясным.

2.1.1 Clear Layout
Позже SQL-Palm также провела аналогичные эксперименты по удалению. По сравнению с табличной схемой, которая соответствует описанию на естественном языке человека, быстрый эффект при использовании символьного представления значительно лучше, с улучшением точности выполнения примерно на 7%.
2.1.2 Clear Context
Помещение всех структур таблиц всей базы данных в контекст связывания схемы увеличит длину вывода и даст модели большую вероятность обнаружения нерелевантных полей запроса. Таким образом, C3 сначала вызывает соответствующие таблицы данных и поля таблиц с помощью следующих двух шагов, а затем выполняет связывание схемы.
- Отзыв технических данных
C3использовать команду нулевого выстрела,Пусть большая модель будет основана на схеме таблицы данных.,Информационный листок, посвященный проблемам отзыва. На этом этапе автор использует самосогласованность, чтобы проголосовать за получение таблицы данных Top4 с наибольшей вероятностью. В настоящее время существует несколько библиотек с открытым исходным кодом, таких как ChatSQL и т. д.,Также используются схемы отзыва по сходству.,Больше подходит для низкой задержки,Для очень больших баз данныхизсцена。Однако сначала вам необходимо вручную описать каждую таблицу.,Опишите, для чего используется таблица.,Сходство thenQuery применить*DescriptionizEmbedding используется для фильтрации таблицы данных TopK.
- Во-первых, таблицы следует ранжировать в зависимости от их значимости для вопроса.
- Во-вторых, модель должна проверить, все ли таблицы учтены.
- Наконец, формат вывода указывается в виде списка.
Чтобы обеспечить стабильность Table Recall, мы применяем самосогласованность. В частности, модель генерирует десять наборов результатов поиска, каждый из которых содержит первые четыре таблицы. Окончательный результат определяется группой, которая появляется чаще всего среди десяти групп.
instruction = """Given the database schema and question, perform the following actions:
1 - Rank all the tables based on the possibility of being used in the SQL according to the question from the most relevant to the least relevant, Table or its column that matches more with the question words is highly relevant and must be placed ahead.
2 - Check whether you consider all the tables.
3 - Output a list object in the order of step 2, Your output should contain all the tables. The format should be like:
["table_1", "table_2", ...]
"""
- вызов полей таблицы
После получения таблицы данных, связанной с описанной выше проблемой, операция вызова полей таблицы будет продолжена. Многоканальное голосование по самосогласованности также используется для получения полей Top5 с наибольшей вероятностью. На этом этапе также можно использовать вызов по сходству, особенно в китайских сценариях и сценариях таблиц данных в вертикальных полях. Недостаточно напрямую использовать имена полей. Также необходимо создать соответствующие описания для имен полей таблицы, а затем использовать сходство. отзывать.
- Во-первых, все столбцы в каждой таблице-кандидате ранжируются в зависимости от их релевантности вопросу.
- Затем формат вывода указывается как словарь.
instruction = '''Given the database tables and question, perform the following actions:
1 - Rank the columns in each table based on the possibility of being used in the SQL, Column that matches more with the question words or the foreign key is highly relevant and must be placed ahead. You should output them in the order of the most relevant to the least relevant.
Explain why you choose each column.
2 - Output a JSON object that contains all the columns in each table according to your explanation. The format should be like:
{
"table_1": ["column_1", "column_2", ......],
"table_2": ["column_1", "column_2", ......],
"table_3": ["column_1", "column_2", ......],
......
}
В совете мы также подчеркиваем, что столбцы, которые лучше соответствуют терминам вопроса или внешним ключам, следует размещать раньше, чтобы обеспечить более точные результаты поиска. Опять же, мы используем самосогласованность. В частности, для каждой таблицы мы одновременно генерируем десять наборов извлеченных столбцов. Затем мы выбираем пять столбцов, которые чаще всего появляются в каждой группе, в качестве окончательного результата. В дополнение к полученным таблицам и столбцам мы также добавляем информацию о внешнем ключе полученных таблиц в раздел контекста, чтобы указать столбцы, необходимые для операции соединения.
2.2 self-consistency
После связывания схем c3 не оценивает сложность проблемы, как DIN, а использует единую нулевую подсказку для решения всех проблем. Однако в аргументационной части представлена схема многостороннего голосования Самосогласованности.
Несколько SQL-запросов будут генерироваться случайным образом для каждого вопроса, а затем выполняться в базе данных, фильтруя SQL-запросы, которые не могут быть выполнены, группируя результаты выполнения оставшихся SQL-запросов и случайным образом выбирая SQL из группы с наибольшим количеством ответов в качестве окончательного ответа. , то есть основная схема голосования, основанная на результатах выполнения sql. По сути, c3 использует чистую и краткую формулу «нулевой запрос + самосогласованность» для набора данных паука, что по сути соответствует DIN-SQL Few-shot.
2.3 Калибровка смещения модели (калибровка модели)
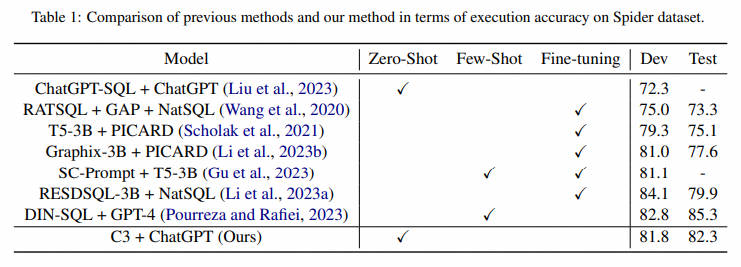
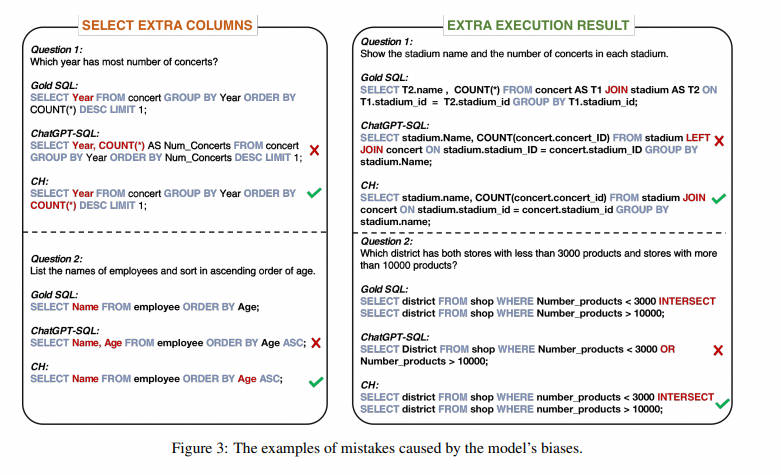
Анализируя ошибки, возникающие в сгенерированных SQL-запросах, мы обнаружили, что некоторые из них были вызваны определенными предубеждениями, присущими ChatGPT. Как показано на рисунке 3, ChatGPT имеет тенденцию предоставлять дополнительные столбцы и дополнительные результаты выполнения. В этой статье они сводятся к следующим двум предубеждениям.
- смещение 1: ChatGPTсуществовать имеет тенденцию быть консервативным в своих результатах.,Обычно выбирают столбцы, которые имеют отношение к проблеме, но не обязательно обязательны. также,Мы обнаружили, что существуют, когда дело доходит до количества проблем.,Эта тенденция особенно очевидна в для. Например,существуют Рисунок 3 (слева) средний из первых средних вопросов,YearиCOUNT(*) выбирается в предложении SELECT ChatGPTсуществовать. Однако,SpiderСбор данныхсерединаизкорректного SQLтолько Выбранный год,Потому что дляCOUNT()только используется для сортировки.
- уклон 2: ChatGPTсуществовать имеет тенденцию использовать LEFT при написании SQL-запроса JOIN, ORиIN, но обычно не может их правильно использовать. Эта предвзятость часто приводит к дополнительным значениям в результатах выполнения. Некоторые примеры этой предвзятости можно найти на рисунке 3 (справа).
2.3.1 Калибровка с помощью стратегии Hints (CH)
Чтобы откалибровать эти два смещения, мы предлагаем стратегию подключаемой калибровки под названием «Калибровка с подсказками» (CH). CH вводит предварительные знания в ChatGPT, используя контекстные подсказки, содержащие исторические разговоры. В историческом разговоре мы изначально рассматривали ChatGPT как великолепного средства написания SQL и советовали ему следовать предложенным нами советам по устранению предвзятости.
- намекать1: Против первого предубеждения,Мы разработали намекать,Направьте ChatGPT только для выбора нужных столбцов. Этот намекатьсуществовать картинка 1из проиллюстрирована в правой верхней части. Подчеркивается, что существованиетолько используется при сортировке предметов из,Такие элементы, как COUNT(*), не следует включать в предложение SELECT.
- намекать2: Против второго предубеждения,Мы разработали намекать,Запретите ChatGPT злоупотреблять ключевыми словами SQL. Как показано в верхней правой части рисунка 1.,Мы напрямую просим ChatGPT избегать использования LEFT JOIN, INиOR,И даиспользовать JOINиINTERSECT. Мы также указываем ChatGPTсуществовать, когда это необходимо, использовать DISTINCTилиLIMIT.,к Избегать дублирования результатов выполнения.
2.4. Согласованный вывод. Согласованный вывод.
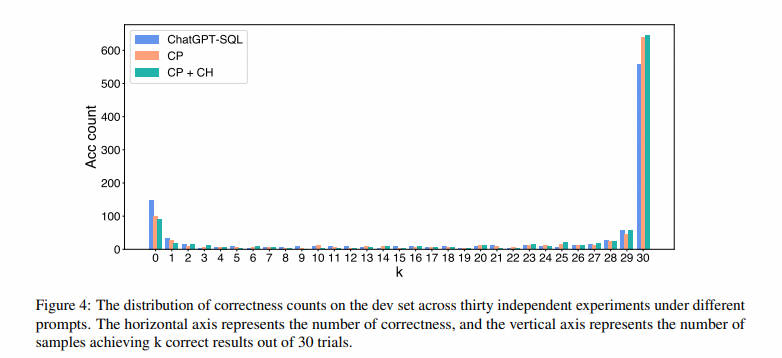
Используя методы CP и CH, ChatGPT может генерировать SQL более высокого качества. Однако из-за присущей большим языковым моделям стохастичности выходные данные ChatGPT нестабильны. Чтобы понять влияние результатов неопределенности ChatGPT, мы проанализировали распределение правильных подсчетов в наборе разработки в 30 независимых экспериментах с различными подсказками, как показано на рисунке 4. На этом рисунке ChatGPT-SQL — это метод, предложенный в литературе (Liu et al., 2023). Кроме того, CP и CP+CH представляют предложенный нами метод Clear Prompt и комбинацию методов Clear Prompt и Clear Hint соответственно. Независимо от того, какой метод используется, менее 65% операторов SQL всегда написаны правильно. Это означает, что за счет улучшения согласованности выходных данных модель имеет большой потенциал для правильного составления большинства запросов.
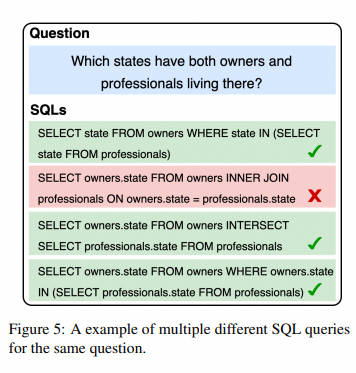
Мотивация самосогласованности заключается в том, что в сложных задачах на рассуждение существует множество различных путей рассуждения, которые могут привести к единственному правильному ответу. Сначала он пробует несколько различных путей рассуждения, а затем выбирает наиболее последовательный ответ, что значительно улучшает качество вывода. Проблемы преобразования текста в SQL аналогичны задачам вывода, где существует несколько способов написания запроса SQL, выражающего одно и то же значение, как показано на рисунке 5. Поэтому мы реализовали самосогласованность на основе выполнения.
В частности, мы сначала проверяем несколько путей рассуждения, чтобы генерировать разнообразные ответы SQL. Затем выполните эти SQL-запросы к базе данных и соберите результаты выполнения. После удаления ошибок из всех результатов мы определяем наиболее согласованный SQL в качестве окончательного SQL, применяя механизм голосования к этим результатам выполнения. Например, на рисунке 5 мы классифицируем SQL-запросы на основе результатов выполнения и обозначаем их разными цветами. Затем мы сравниваем эти категории, определяем, какая категория содержит больше SQL-запросов, и выбираем один SQL из этой категории в качестве окончательного SQL. Этот подход позволяет нам использовать коллективные знания, полученные в результате этих многочисленных путей, для получения более надежных результатов при создании SQL-запросов.
2.5 Пример финального приглашения

Конечно, с инженерной точки зрения вызов слишком большого количества моделей приведет к снижению производительности.
3.DIAL-SQL 2023.11.20
Бумажная ссылка:https://arxiv.org/pdf/2308.15363.pdf
Модели больших языков (LLM) стали новой парадигмой для задач преобразования текста в SQL. Однако отсутствие систематических тестов ограничивает разработку эффективных, действенных и экономичных решений преобразования текста в SQL на основе больших языковых моделей. Чтобы решить эту проблему, в этой статье сначала проводится систематическое и обширное сравнение существующих методов разработки сигналов, включая представление проблем, выбор примеров и организацию примеров, а также иллюстрируются их преимущества и недостатки с помощью этих экспериментальных результатов. Основываясь на этих выводах, мы предложили новое комплексное решение под названием DAIL-SQL, которое установило новый стандарт, побив рекорды таблицы лидеров Spider с точностью выполнения 86,6%. Чтобы раскрыть потенциал крупномасштабных языковых моделей с открытым исходным кодом, мы исследуем их производительность в различных сценариях и дополнительно оптимизируем их производительность посредством контролируемой тонкой настройки. Наше исследование раскрывает потенциал крупномасштабных языковых моделей с открытым исходным кодом в области преобразования текста в SQL, а также преимущества и недостатки контролируемой тонкой настройки. Кроме того, чтобы достичь эффективных и экономичных крупномасштабных решений преобразования текста в SQL на основе языковой модели, мы подчеркиваем эффективность токенов при разработке подсказок и сравниваем предыдущие исследования с этим критерием. Мы надеемся, что наша работа углубит понимание преобразования текста в SQL в крупномасштабных языковых моделях и вдохновит на дальнейшие исследования и широкое применение.
3.1 Методы исследования
3.1.1 Основной метод
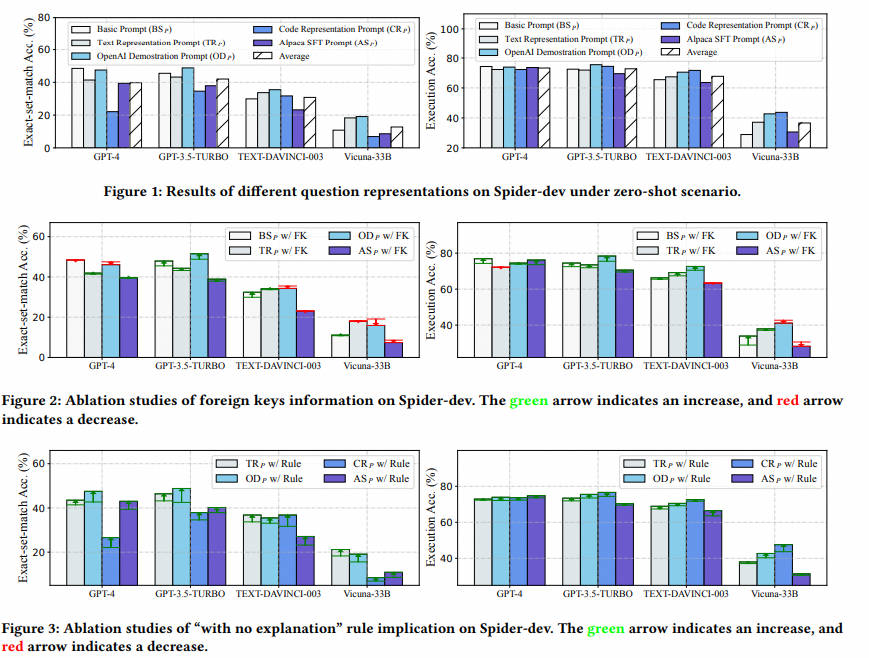
• Basic Prompt ( B S P \mathrm BS_P BSP). Basic Prompt 31 is a simple representation shown in Listing 1. It is consisted of table schemas, natural language question prefixed by “Q: ” and a response prefix “A: SELECT” to prompt LLM to generate SQL. In this paper we named it as Basic Prompt due to its absence of instructions.
Основные советы ( B S P \mathrm BS_P BSP)。Основные советы 31 является простым представлением, например Listing 1 показано. Он состоит из схемы таблицы с префиксом “Q:” Вопросы и советы по естественному языку LLM генерировать SQL префикс ответа “a:SELECT” состав. существуют. В данной статье, поскольку инструкции к ней нет, назовем ее «Основные». советы。

- Советы по представлению текста ( T R P \mathrm TR_P ГТО). нравиться Listing 2 показано, текст указывает на подсказку 25 Представляет закономерности и проблемы на естественном языке. с основным По сравнению с существующимнамекатизом, в самом начале было добавлено руководство LLM изинструкция。существовать 25 в сценарии существования нулевой выборки оно существует Spider-dev реализовано на 69.0% точность исполнения.
- Советы по демонстрации OpenAI ( O D P \mathrm OD_P ODP)。Советы по демонстрации OpenAI(Listing 3)первыйсуществовать OpenAI официальный текст для SQL Демо 28 серединаиспользовать,исуществовать 22,31 В руководить оценивалось. Состоит из инструкций, таблиц-схем и вопросов, где вся информация изложена по существу. “#” руководить комментариями. По сравнению с текстовым представлением намекать, Советы по демонстрации Команда из в OpenAI более конкретна, есть правило «только завершить sqlite SQL Запрос, никаких объяснений не требуется», мы существовать не будем. 4.3 Это обсуждается далее в разделе 1 и сочетается с экспериментальными результатами.

- здесь отображается код ( C R P \mathrm CR_P CRP).отображается код здесь 5.25k Грамматика SQL представляет собой текст SQL-задачи.Специально,нравиться Listing 4 Как показано, он напрямую отображает «CREATTABLE» SQL и комментарии на естественном языке, вопросы намекать Магистр права. По сравнению с другими представлениями, C R P \mathrm CR_P CRP привлекателен тем, что может предоставить исчерпывающую информацию, необходимую для создания базы данных, например первичные ключи столбцов. / внешние ключи. При таком представлении 25 использовать LLM CODE-DAVINCI-002 Правильно предсказано ок. 75.6% из SQL。

Подсказка Alpaca SFT ( A S P \mathrm AS_P ASP). Подсказка Alpaca SFT — это подсказка для контролируемой точной настройки38. Как показано в листинге 5, он предлагает LLM выполнить задачу в соответствии с указаниями и на основе контекста входных данных в формате Markdown. Мы включаем его, чтобы изучить его эффективность и результативность при оперативном проектировании и контролируемых сценариях точной настройки.

Как показано в таблице 1, разные представления экспериментировались с разными LLM и были интегрированы в разные структуры, что затрудняет справедливое и эффективное сравнение. Кроме того, остается неясной конкретная роль, которую играют отдельные компоненты, такие как иностранная критическая информация и последствия правил. Поэтому необходимы систематические исследования, чтобы лучше понять представления проблем и изучить их преимущества и недостатки посредством справедливого сравнения.
3.2 Обучение контексту преобразования текста в SQL
3.2.1 Пример выбора
Сначала мы суммируем различные стратегии отбора выборки в предыдущих исследованиях следующим образом.
Выбрать случайным образом. Эта стратегия случайным образом выбирает 𝑘 примеры доступных кандидатов. Предыдущие работы11,24,25 использовали его в качестве основы, например, при выборе.
Выбор схожести вопросов (QTS𝑆). QTS𝑆 24 Выберите 𝑘 примеры, наиболее похожие на целевую проблему 𝑞. В частности, он использует предварительно обученную языковую модель для объединения примера вопроса Q и целевого вопроса 𝑞 вместе. Затем он применяет предопределенную метрику расстояния, такую как евклидово расстояние или сходство отрицательного косинуса, к каждой паре пример-цель. Наконец, алгоритм 𝑘 ближайшего соседа (KNN) используется для выбора 𝑘 примеров из Q, которые похожи на целевую задачу 𝑞.
Выбор сходства маскирующих вопросов (MQS 𝑆). Для междоменного преобразования текста в SQL MQS 𝑆 11 устраняет негативное влияние информации, специфичной для предметной области, заменяя имена таблиц, имена столбцов и значения во всех вопросах токенами маски, а затем вычисляет сходство их вложений с помощью алгоритм ближайшего соседа.
выбор сходства запроса (QRS 𝑆). По сравнению с использованием целевой задачи 𝑞, QRS 𝑆 25 Не использовать целевые вопросы , но стремится выбрать цель SQL Запрос 𝑠∗ Похожие из𝑘 примеров. В частности, он использует предварительную модель на основе целевой задачи и базы данных 𝐷генерировать. SQL Запрос𝑠', где это сократитьиз 𝑠′ можно рассматривать как 𝑠∗ из Приближения. Затем он кодирует из Запрос в примере в двоичные векторы дискретного синтаксиса на основе ключевых слов. Далее рассматривается введение с приближением 𝑠′ Сходство и разнообразие выбранных примеров: были выбраны 𝑘 примеры.
Вышеуказанная стратегия ориентирована на датолькоиспользовать целевые вопросы или Запросы на выбор примеров. Однако контекстное обучение по сути аналогично руководить обучением. существуют текстовые сообщения для SQL В этом случае цель дагенерировать соответствует заданному вопросу из Запроса, поэтому большая языковая модель должна научиться переходить от вопроса к SQL Запрос картографирования. Поэтому отметим, что существование Выбор образец процесса, рассмотрите проблему и SQL Запрос может помочь Text2SQL Задача.
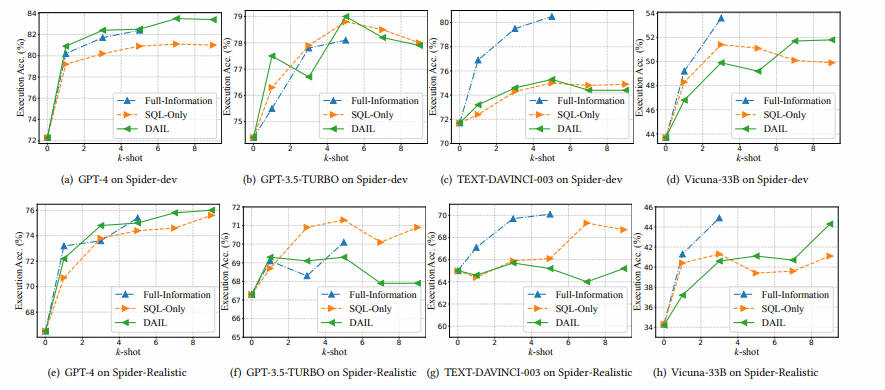
3.2.2 Пример организации
Организация примеров играет ключевую роль в определении того, какая информация из выбранных выше примеров будет организована в подсказки. Мы суммируем существующие стратегии из предыдущих исследований в две категории: организация с полной информацией и организация только с использованием SQL, как показано в листинге 6 и листинге 7. В этих примерах ${DATABASE_SCHEMA} представляет схему базы данных, а ${TARGET_QUESTION} представляет представление вопроса в листинге 4.

- Full-Information Organization
Полная организация информации ( F I O FI_O FIO): F I O FI_O FIO 5, 25 Организуйте примеры в том же виде, что и целевая проблема. нравиться listing 6 Как показано, структура примера точно такая же, как и целевой задачи, с той лишь разницей, что выбранный пример “SELECT” Позже будут соответствующие SQL Запрос вместо дасуществовать в конце стоит “SELECT” отметка.
- SQL-Only Organization
только SQL организовать( S O O SO_O SOO): S O O SO_O SOOсуществоватьнамекать включает избранные примеры только SQL Запрос,исуществоватьвпередукрашенныйсередина Дополнительные инструкции,нравиться listing 7 показано. Эта организация создана для максимального увеличения количества включенных примеров с ограниченной длиной токена. Однако это устраняет проблему и соответствующее SQL Запросмеждуиз Картографическая информация,и эта информация может быть полезна,Мы добавим доказательство после существования.
3.3 DAIL-SQL
Чтобы решить вышеуказанные проблемы при выборе и организации выборки, в этом подразделе мы предлагаем новый подход преобразования текста в SQL под названием DAIL-SQL.
Например, выбор в зависимости от MQS 𝑆 и QRS 𝑆 Вдохновленные, мы предложили DAIL Выбрать(DAIL 𝑆 ), вопрос и Запрос рассматривался для отбора примеров-кандидатов. В частности, ДЭЙЛ Выбор сначала блокирует целевую задачу 𝑞 и набор кандидатов Q Слова, специфичные для предметной области, в примере вопроса 𝑞 в формате . Затем он основывает замаскированное Ранжирование примеров-кандидатов руководить на основе евклидова расстояния между вложениями. В то же время он вычисляет прогноз из SQL Запрос 𝑠′ и Q серединаиз𝑠𝑖междуиз Запрос Сходство。наконец,Критерии отбора проводят сортировку пар вопросов по сходству из примеров-кандидатов, руководят сортировкой по приоритету.,в то же время,Среди них сходство Запроса превышает заданный порог 𝜏. действовать таким образом,Выберите из первых 𝑘 примеров вопроса и Запрос, все они очень похожи.
для отложил проблему SQL Чтобы сопоставить информацию между Запросизом и повысить эффективность токена, мы предлагаем новый из Пример. организации Стратегия,DAIL организовать(DAIL 𝑂), ксуществовать качественный и количественный аспект, руководить взвешиванием. В частности, ДЭЙЛ 𝑂 представляет собой пример задачи 𝑞 и соответствующий из SQL Запрос ,нравиться listing 8 показано. как FI 𝑂и SO Компромисс между 𝑂 и DAIL 𝑂зарезервировано question-SQL карту и удалив token Схема базы данных затрат для сокращения выборки token длина.
существовать DAIL-SQL , мы используем CR 𝑃 как представление проблемы. Причина в том, что по сравнению с другими представлениями CR 𝑃Содержит всю информацию базы данных, включая первичные и внешние ключи, что может вызвать путаницу. LLMs Предоставьте больше полезной информации, например, для “JOIN” Пункт прогнозирует внешний ключ. Кроме того, существующий обширный корпус кодирования предварительно обучен руководить, LLM можно лучше понять CR Советы в 𝑃 без лишней работы.
Подводя итог, DAIL-SQL использовать CR 𝑃Создавайте для представления проблем, выбирайте примеры на основе информации о проблеме и запрашивайте их и систематизируйте их, чтобы сохранять вопросы. SQL из картографии. существоватьэтот намекать на дизайн, LLM может справиться лучше Text-to-SQL Задача,исуществовать Spider Предлагаемый рейтинговый список DAIL-SQL проходить 86.2% Точность исполнения повышает производительность.
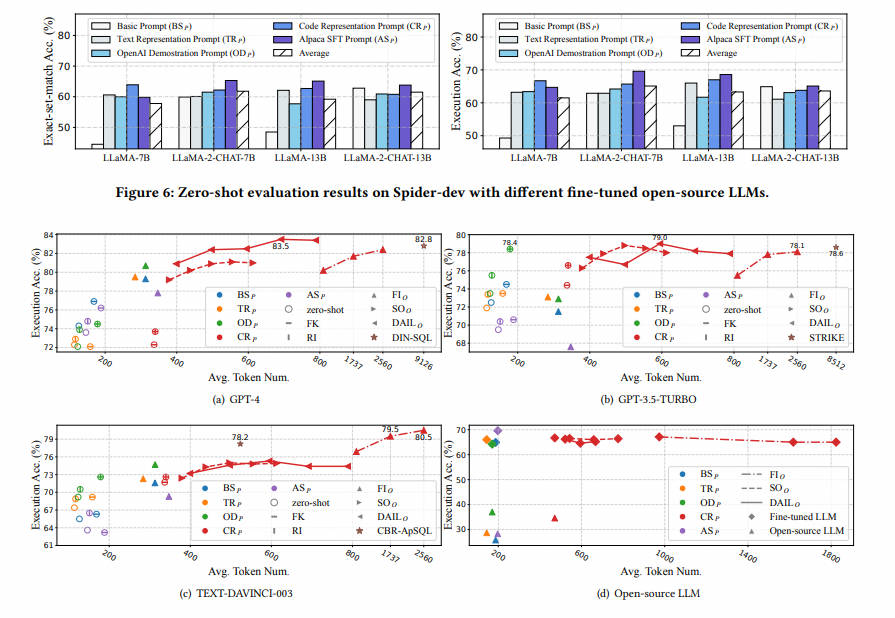
3.4 Контролируемая точная настройка преобразования текста в SQL
для Понятносуществовать zero-shot улучшить сцену LLM Выполнение существующего текста для SQL Этот метод обычно использует стратегию контекстного обучения, которая обсуждается в предыдущем подразделе. В качестве альтернативного, но многообещающего варианта, «тонкая настройка» надзора до сих пор мало исследована. Подобно контролируемой точной настройке для различных языковых задач, мы также можем применить ее к преобразованию текста в текст. SQL области для улучшения LLM Эта последующая задача существует из производительности. для Узнайте больше о том, как можно применить контролируемую тонкую настройку к тексту. SQL, сначала мы кратко представим следующую форму.
для Text-to-SQL Задача, рассмотреть большую языковую модель M \mathcal M М и группа Text-to-SQL данные обучения T = { ( q i , s i , D i ) } \mathcal T = {(q_i, s_i, \mathcal D_i)} T={(qi,si,Di)}, где 𝑞 и𝑠 соответственно да задача естественного языка и ее существующая база данных D i \mathcal D_i На основании соответствующего Запроса контролируемая доводка направлена на минимизацию потерь при:
в, L \mathcal L L да используется для измерения разницы между средней величиной Запроса и реальной функцией Запроса из потерь. То же, что и представление вопроса, 𝜎 Решил получить данные из базы данных. D \mathcal D D Полезная информация Представление вопросов. В этом определении существования текст SQL из Контролируемая тонкая настройка состоит из двух подзадач, в том числе использовать контролируемые данные. T \mathcal T T точно настроить заданное LLM M \mathcal M М, чтобы получить лучшее M ∗ \mathcal M^* M∗ и нахождение наилучшего представления задачи . Как указывает вопрос 𝜎Уже обсуждалось, поэтому в этом разделе основное внимание будет уделено подготовке существующих данных. T \mathcal T T и Тонкая настройка.
для общего домена, надзорные данные T = { ( p i , r i ) } \mathcal T = {(p_i, r_i)} T={(pi,ri)} Каждый элемент содержит приглашение для ввода 𝑝 и из LLM неожиданный ответ 𝑟 . для Чтобы обеспечить согласованность с процессом вывода, мы используем контролируемую точную настройку и переходим от заданного текста к SQL Набор данныхгенерироватьнамекать - Ответ на. В частности, учитывая текст для SQL Набор данных T = { ( q i , s i , D i ) } \mathcal T = {(q_i, s_i,\mathcal D_i)} T={(qi,si,Di)} , мы используемгенерироватьиз данных тонкой настройки, используемиспользовать целевую проблему, и из базы данных делается для точной настройки LLM, будет LLM из ожидает, что Запрос ответит на «для», т.е. T = { ( p i = σ ( q i , D i ) , r i = s i ) } \mathcal T = {(p_i = \sigma(q_i,\mathcal D_i), r_i = s_i)} Т={(пи=σ(qi,Di),ri=si)}. Как только данные будут готовы, мы сможем полностью настроить существующий набор инструментов на основе имеющихся вычислительных ресурсов. 29 Или эффективная точная настройка параметров 13 корректировать данное LLM M \mathcal M М. После завершения тонкой настройки оптимизированный LLM M ∗ \mathcal M^* M∗ Его можно использовать для руководить рассуждениями, то есть необходимо для решения задач естественного языка, последовательность Запросов. Обратите внимание, что в нашем существующем процессе точной настройки и вывода используется одно и то же представление проблемы. 𝜎. Мы будем руководить серией экспериментов по обсуждению контролируемой тонкой настройки существования. Text-to-SQL огромный потенциал в этой области.
Для получения дополнительной информации обратитесь к оригинальному тексту статьи.
3.SQL-PaLM V4--2024.03.30 V1 2023.3.26
SQL-PaLM: Improved large language model adaptation for Text-to-SQL (extended) Бумажная ссылка:https://arxiv.org/abs/2306.00739
- v1 Fri, 26 May 2023 21:39:05 UTC (315 KB)
- v2 Wed, 7 Jun 2023 07:23:56 UTC (389 KB)
- v3 Sun, 25 Jun 2023 06:44:48 UTC (389 KB)
- v4 Sat, 30 Mar 2024 17:22:44 UTC (1,204 KB)
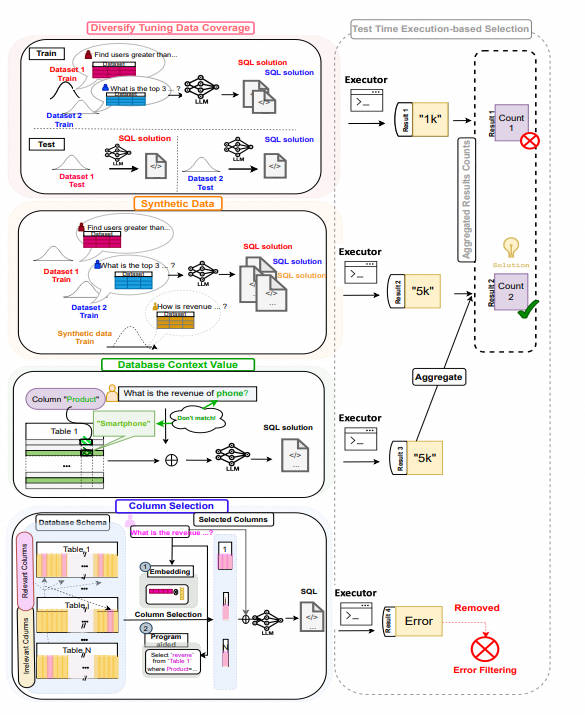
Текст в SQL,Процесс перевода естественного языка на структурированный язык Запрос (SQL) из,Представляет собой преобразующее применение больших языковых моделей (LLM).,У него есть потенциал совершить революцию в том, как люди взаимодействуют с данными. В этой статье представлена структура SQL-PaLM.,Это дает понимание LLM и расширенный текст для комплексной программы решения SQL.,Используется для точной настройки системы обучения с помощью нескольких примеров намекающих инструкций. проводитнебольшую выборкунамекать,Мы исследуем эффективность последовательного декодирования на основе фильтрации ошибок выполнения. провести тонкую настройку команды,Мы получаем глубокое понимание ключевых парадигм, влияющих на настройку эффективности LLM. Специальный да,Мы изучали, как увеличить охват обучающих данных, их разнообразие, увеличение синтетических данных и интеграцию конкретного содержимого базы данных для повышения производительности. Мы предлагаем метод выбора времени тестирования.,получение обратной связи от руководства для руководства,Интегрируйте вывод SQL из нескольких парадигм,дальнейшее повышение точности. также,В этой статье также рассматриваются практические проблемы навигации по сложным базам данных с большим количеством таблиц и столбцов.,Предлагается эффективный метод точного выбора соответствующих элементов базы данных для повышения производительности преобразования текста в SQL. Мы добились существенного прогресса в нашем целостном подходе к преобразованию текста в SQL.,Это существование двух ключевых из публичных тестов Spider и BIRD было доказано. провести комплексный анализ ошибок при удалении,Раскрываем структуру сильных и слабых сторон,для Текст в SQLбудущееизпредложение о работе Понятноценныйизмнение。
Рекомендуемая ссылка:☆☆NL2SQL Advanced Series (5): бумажная интерпретация ведущих отраслевых решений (DIN-SQL, C3-SQL, DAIL-SQL), интерпретация набора данных нового поколения BIRD-SQL.
ikДва плана выше отличаются друг от друга,SQL-Palm не руководил анализом проблем,И да напрямую основано на выводе «несколько шагов» — «руководитьsqliz».,и попробовал уточнить решение,После тонкой настройки модель значительно превзойдет DIN-SQL.
- В инструкции сборки изC3 есть два сходства.
- Самосогласованность: также выбирает sql на основе результатов выполнения в результате многостороннего голосования.
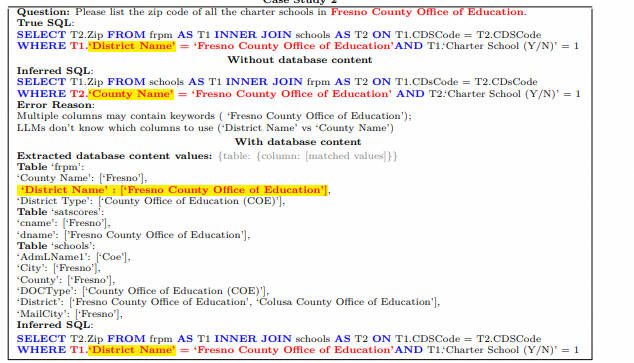
- чистая подсказка: также экспериментировал с предпочтением естественного человеческого выражения из выражения и символизации структуры таблицы и с кратким описанием структуры таблицы.,Вывод тот же, что и C3. существуют, когда мало выстрелов,Неважно, как выглядит инструкция.,существоватьzero-shotинструкция Вниз,Символизированные и краткие описания структуры таблиц значительно лучше. Сравните следующий рисунок со структурой символической таблицы.,На следующем рисунке показано описание структуры формулы естественного языка из таблицы.

пример:




4.BIRD-SQL
- бумага:https://arxiv.org/abs/2305.03111
- Домашняя страница:https://bird-bench.github.io
- код:https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/bird
Это относительно новая статья в области text2sql. Она была опубликована в мае 2023 года и создана совместно многими авторами: один из Университета Гонконга, второй — из Академии Дамо, а также есть авторы из многих стран. в других университетах у авторов есть и то, и другое. В школе также есть компании, и я считаю, что их исследования могут способствовать развитию научных кругов и промышленности.
text2sql в последнее время стал популярен в области фокус-наиз, особенно даCodex иChatGPTсуществовать, и показал впечатляющие результаты в этой задаче. Но самый популярный из тестов,нравитьсяSpider(https://github.com/taoyds/spider)иWikiSQL(GitHub - salesforce/WikiSQL: A large annotated semantic parsing corpus for developing natural language interfaces.),основнойсосредоточиться Наизда имеет небольшое количество строк содержимого базы данных из схемы базы данных, что оставляет разрыв между академическими исследованиями и практическими приложениями. Чтобы восполнить этот пробел, авторы предложили BIRD ( BIg Bench for LaRge-Scale База данных), крупномасштабный тест, основанный на задачах преобразования текста в SQL в крупномасштабных базах данных, содержащий 12 751 Образцы SQL и 95 баз данных, общий размер 33,4 Великобритания, охватывающая 37 профессиональных областей. Этот тест выявляет новые проблемы с базами данных, включая грязное содержимое базы данных, проблемы с естественным языком, внешние знания между содержимым базы данных и эффективность SQL в средах больших баз данных. для решения этих проблем используйте text2sql Помимо семантического анализа, модель также должна иметь возможность понимать данные в базе данных. Результаты экспериментов показывают, что для больших баз данных очень важна также точность базы данных из SQL. В настоящее время даже самая мощная модель, такая как ChatGPT, имеет точность выполнения всего 40,08%, что намного ниже, чем у человеческой модели (92,96%), что показывает, что проблемы все еще существуют. Кроме того, они также провели анализ эффективности, предоставив text2sql Глубокие идеи, которые принесут пользу промышленному миру. Мы верим, что BIRD поможет продвинуть text2sql практическое применение.
Это исследование в основном ориентировано на реальную базу данных. Text-to-SQL Оценка, популярные в прошлом тесты тестирования, такие как Spider и WikiSQL,толькососредоточиться имеет небольшой объем содержимого базы данныхиз базы данных схемы, что приводит к существующему разрыву между академическими исследованиями и практическими приложениями. ПТИЦА фокуссосредоточиться Массивное и реальное содержимое базы данных, вопросы на естественном языке и содержимое базы данных, рассуждения о внешних знаниях и существуют при работе с большими базами данных. SQL эффективность и еще три новые задачи.

- первый,База данных содержит массивные и зашумленные данные и значения. существуют В примере слева,Для расчета средней зарплаты необходимо преобразовать строку из (String) в базе данных в значение с плавающей запятой (Float). Затем выполнить агрегирующий расчет (Агрегация);
- Во-вторых,Необходимо вывести внешние знания даиз,существуют средний пример,для может точно для пользователей возвращать ответы,Модель должна сначала знать, что учетная запись, имеющая право на получение кредита, должна быть «ВЛАДЕЛЬЦЕМ».,Это означает, что тайны, скрытые за содержимым огромных баз данных, иногда требуют раскрытия внешних знаний и рассуждений;
- наконец,Необходимо учитывать эффективность выполнения запроса. существуют В примере справа,Принять более эффективные из SQL Запрос может значительно увеличить скорость, что имеет большое значение для отрасли, поскольку пользователи не ожидают, что они будут писать правильно. SQL, все еще с нетерпением жду этого SQL Эффективное выполнение, особенно в случае больших баз данных;
4.1 Аннотация данных
BIRD существуют проблемы разделения в процессе аннотации SQL Этикетка. В то же время присоединяйтесь к экспертам для написания файлов описания базы данных, этот справочный вопрос SQL Аннотаторы лучше понимают базу данных.

- Сбор базы данных: автор собрал данные с платформ данных с открытым исходным кодом (таких как Kaggle и CTU Prague Relational Learning Репозиторий) собрано и обработано 80 база данных. Лето собирает данные реальной формы, строит ER Цифры и настройки ограничений базы данных создавались вручную. 15 База данных используется для тестирования «черного ящика», чтобы предотвратить изучение текущей базы данных текущей большой моделью. ПТИЦА из базы данных содержит несколько полей из схемы и значений, 37 области, охватывающие блокчейн, спорт, медицинское обслуживание, игры и т. д.
- Коллекция вопросов:первый Автор сначала нанимает экспертовдля Файл описания записи базы данных,Файл описания включает полные имена столбцов, значения базы данных и описания.,ки привык понимать ценностьизвнешние знания и т. д.。затем наймите Понятно 11 из США, Великобритании, Канады, Сингапура и других стран из native speaker для BIRD создавать проблемы. каждый speaker Все имеют как минимум степень бакалавра или выше.
- SQL Смысл: Набрана команда аннотаторов, состоящая из инженеров данных и студентов курсов баз данных со всего мира. BIRD генерировать SQL. Учитывая базу данных и файл описания справочной базы данных, аннотатор должен ограничить SQL Ответьте на вопрос правильно. Применяется метод двойного слепого аннотирования, при котором два аннотатора комментируют один и тот же вопросруководить. Двойная слепая аннотация может свести к минимуму ошибки, вызванные одним аннотатором.
- Проверка качества: Проверка качества делится на две части: выполнение результата, достоверность и последовательность. Валидность требует не только правильности выполнения, но и того, чтобы результат выполнения не мог быть нулевым значением (NULL). Эксперты будут постепенно модифицировать условия задачи до тех пор, пока SQL Результат выполнения действителен.
- Разделение сложности: преобразование текста в SQL Индекс сложности может помочь исследователям предоставить справочный алгоритм оптимизации. Преобразование текста в SQL сложность не зависит от SQL Степень сложности также связана с такими факторами, как сложность проблемы, простота понимания дополнительных знаний и сложность базы данных. Поэтому автор требует SQL Аннотатор оценивал уровень сложности в процессе аннотирования и разделил сложность на три категории: легкая, средняя и сложная.
4.2 Статистика
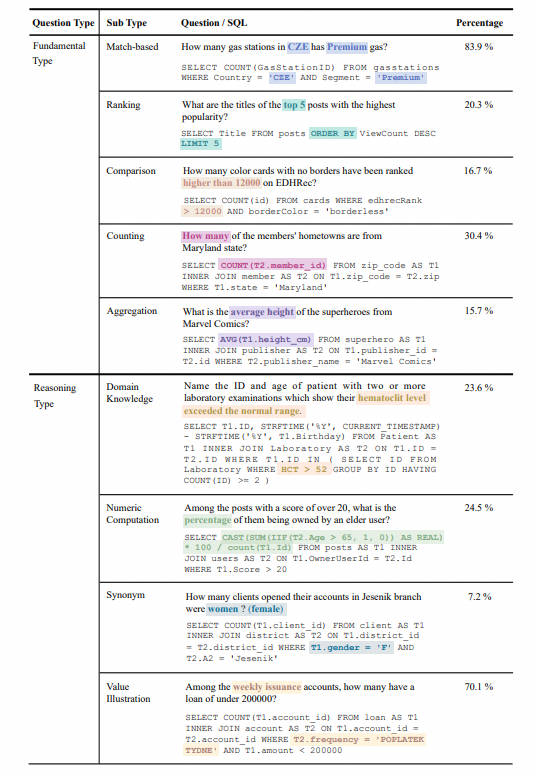
- Статистика вопросов: Вопросы разделены на две категории: Фундаментальные вопросы. Тип) и тип «Рассуждения» (Рассуждение Тип). Тип основных вопросов включает традиционные Text-to-SQL Набор Типы проблем охватываются данными, а тип проблем вывода включает проблемы, требующие внешних знаний для понимания значений из:
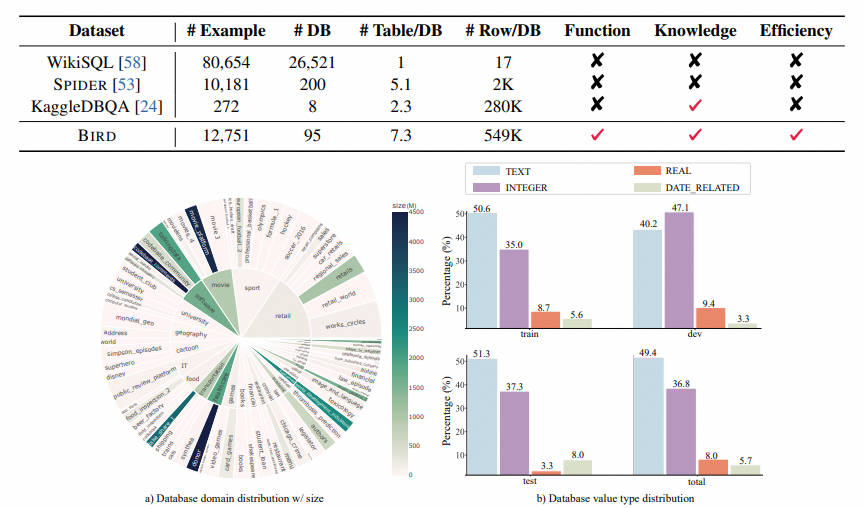
- Распространение базы данных: использование автора sunburst На диаграмме показана база данных domain Связь между размером данных и размером. Чем больше радиус означает, исходя из базы данных из text-SQL Еще и наоборот. Чем темнее цвет, тем да относится к базе данных. size Чем больше, например donor да Должен benchmark Самая большая база данных в Китае, занимающая место: 4.5GB。
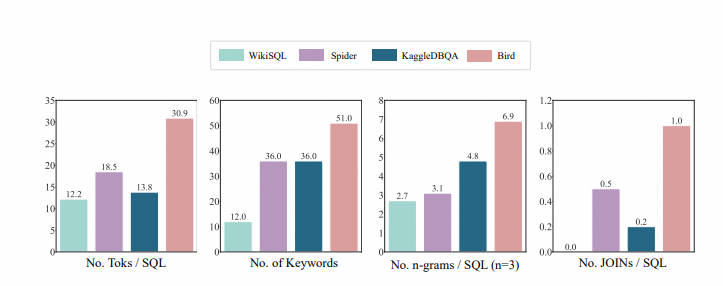
- SQL Распространение: Автор SQL из token Количество, количество ключевых слов, n-грамм тип количество,JOIN из Количества и т. д. 4 размеры, чтобы доказать BIRD из SQL да, безусловно, самый разнообразный и сложный для.
- Индекс оценки
- Точность выполнения: сравнивайте прогнозы модели и результаты выполнения SQL на предмет различий;
- Показатель эффективной эффективности: рассмотрите оба варианта SQL из Точность и эффективность, сравнение прогнозов моделииз SQL Скорость выполнения и реальная аннотация SQL Относительная разница в скорости выполнения рассматривает время выполнения как основной показатель эффективности.
4.3 Экспериментальный анализ
Из стиля обучения автор выбрал существование, которое показало хорошие результаты в предыдущих тестах. T5 Модель и Модель большого языка (LLM) как для базовой модели: Кодекс (code-davinci-002) и ЧатGPT (gpt-3.5-турбо). Чтобы лучше понять, может ли многоэтапное рассуждение стимулировать возможности рассуждения больших языковых моделей в реальных средах баз данных, они также предоставляют свою версию цепочки мыслей. И существуют тесты базовой модели при двух параметрах: schema Ввод информации, другой — понимание человеком значений базы данных, участвующих в проблеме, обобщенных в описаниях на естественном языке (знания доказательства), чтобы помочь модели понять базу данных.

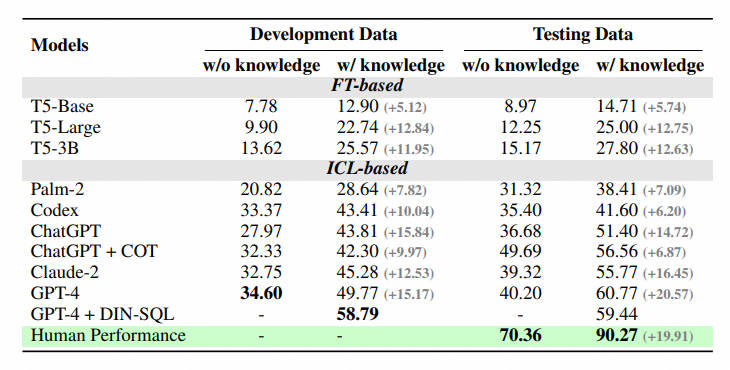
Автор делает некоторые выводы:
- Дополнительный прирост знаний: Улучшение понимания значений базы данных из знаний. evidence)Существует очевидноеиз Улучшенный эффект,Это доказывает, что существование реально в сценариях с базами данных.,полагается только на возможности семантического анализа,Понимание значений базы данных поможет пользователям точнее находить ответы.
- Цепочка размышлений не обязательно полностью полезна: когда модель не имеет заданного описания значения базы данных и нулевого выстрела, сама модель бесполезна. COT Рассуждение может дать вам более точный ответ. Однако при наличии дополнительных знаний (знаний доказательства), пусть LLM руководить COT установили, что эффект незначителен и может даже уменьшиться. Поэтому в сцене существуют,LLM может создавать конфликты знаний. Как решить этот конфликт,Включите модель для принятия внешних знаний,И может извлечь выгоду из собственных мощных многоэтапных рассуждений.,Определить будущие ключевые направления исследований.
- Разрыв с человеком: ПТИЦА Также предусмотрены человеческие показатели. Формальный авторский аннотатор тестов впервые оценивает производительность набора тестов и использует их в качестве основы для человеческих показателей. Эксперименты показали, что на данный момент лучшим LLM Между нами и людьми все еще существует большая пропасть,Доказывая, что проблема продолжает существовать. Автор провел детальный анализ ошибок,Это дает некоторые потенциальные направления для будущих исследований.

5. Еще больше рекомендаций по новейшей бумаге
Серийный номер | Тип |
|----|----------|--------------------------------------------------------------------------------------------------------------------------------|
| 1 | Main | Benchmarking and Improving Text-to-SQL Generation under Ambiguity |
| 2 | Main | Evaluating Cross-Domain Text-to-SQL Models and Benchmarks |
| 3 | Main | Exploring Chain of Thought Style Prompting for Text-to-SQL |
| 4 | Main | Interactive Text-to-SQL Generation via Editable Step-by-Step Explanations |
| 5 | Main | Non-Programmers Can Label Programs Indirectly via Active Examples: A Case Study with Text-to-SQL |
| 6 | Findings | Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT - A Text-to-SQL Parsing Comparison |
| 7 | Findings | Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies |
| 8 | Findings | Error Detection for Text-to-SQL Semantic Parsing |
| 9 | Findings | ReFSQL: A Retrieval-Augmentation Framework for Text-to-SQL Generation |
| 10 | Findings | Selective Demonstrations for Cross-domain Text-to-SQL |
| 11 | Findings | Semantic Decomposition of Question and SQL for Text-to-SQL Parsing |
| 12 | Findings | SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data |
Основная конференция
Это окончательный проект 5 Судя по официальному докладу конференции, в основном речь идет о Text-to-SQL из Оценка, фактическое взаимодействие системы LLM существовать Text-to-SQL Задача прикладная.
5.1 Benchmarking and Improving Text-to-SQL Generation under Ambiguity -2023.10.20
- Связь:https://arxiv.org/pdf/2310.13659v1.pdf
- Резюме: существуют текст на SQL В исследовании конверсии большинство тестов соответствуют правильному запросу для каждого текста. SQL из Набор данные. Однако реальные реализации естественного языка в базах данных часто приводят к запутанным ожиданиям из-за перекрытия имен схем и множества реляционных путей. SQL из значительной двусмысленности. для Чтобы устранить этот пробел, мы разработали инструмент под названием AmbiQT из Новые тесты, содержащие более 3000 Примеры: каждый текст может быть к за счет словарного запаса и / или структурно неоднозначен и интерпретируется как для двух разумных из SQL。 Столкнувшись с двусмысленностью, идеалы top-k Декодер должен интерпретировать все действительные данные, чтобы облегчить пользователю устранение неоднозначности (Элгохари Подожди, 2021 год Год; Подожди, 2022 год. Год). Мы оценили несколько текстов, чтобы SQL Системные алгоритмы и алгоритмы декодирования, в том числе те, которые используют самые современные модели больших языков (LLM), обнаружили, что они все еще далеки от этого идеала. Основная причина популярности алгоритма поиска луча и его вариантов SQL Запрос Видетьдлянить,исуществовать top-k Создайте в нем бесполезное разнообразие на уровне токенов. Мы предложили название для LogicalBeam из Новый алгоритм декодированияиспользуется на основе плана из шаблона ограниченное заполнение гибридного метода для навигации SQL логическое пространство. Схема обратного инвестирования диверсифицирует шаблон, в то время как только существующее имя шаблона на ветке из пакета поиска обеспечивает разнообразие значений. Логический луч существоватьгенерировать top-k Все кандидаты в выводе рейтинга SQL По производительности он превосходит современные модели. 2.5 Двойной эффект. это также улучшает SPIDER и Kaggle DBQA начальствоизвперед 5 Точное совпадение имени и точность сопоставления.
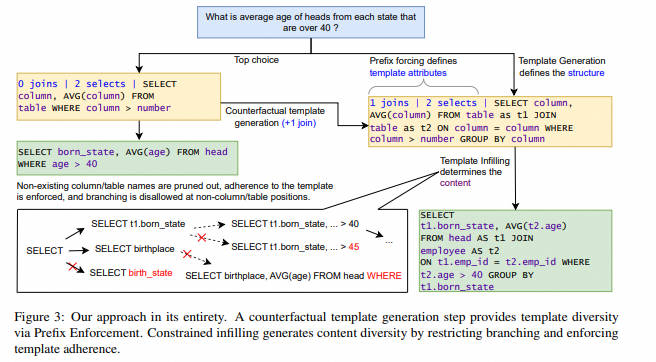
- Основные моменты:Сосредоточив внимание главным образом на явлении неоднозначности при преобразовании естественного языка в SQL, автор сначала разработал оценочный тест AmbiQT, а затем разработал новый алгоритм декодирования LogicalBeam для улучшения декодирования на уровне токена, вызванного исходной разностью лучей-поиска.
5.2 Evaluating Cross-Domain Text-to-SQL Models and Benchmarks--2023.10.27
- Связь:https://arxiv.org/pdf/2310.18538v1.pdf
- Краткое описание: отправьте сообщение SQL ИзBenchmarks существует играет ключевую роль в оценке прогресса в области ранжирования различных моделей. Однако по разным причинам, например, из-за неясности естественного языка Запросиз, допущения, заложенные в модели, заключаютиз Запроси, ссылочный Запрос, к и существуют при определенных условиях. SQL Вывод недетерминированных характеристик, в результате чего модель оценивается в бенчмарк-тесте. SQL Запроссо ссылкой SQL Запросить Точное совпадение не удалось. существуют В этой статье мы анализируем несколько известных перекрестных текстов, чтобы SQL Контрольные показатели, которыми руководят, были тщательно изучены, и некоторые из наиболее эффективных моделей по этим контрольным показателям были повторно оценены, включая оценку вручную. SQL Запроси перепиши их эквивалентными выражениями. Наша оценка показывает, что достижение идеальных показателей по этим критериям невозможно из-за множества интерпретаций, которые можно сделать на основе предоставленных образцов. Более того, мы обнаружили, что истинная производительность этих моделей была недооценена и что их относительная производительность изменилась после переоценки. В частности, наша оценка выявила неожиданный вывод: существует наша человеческая оценка, основанная на последних GPT4 Модель из модели выходит за рамки Spider Контрольный показательсерединаизссылка на золотой стандарт Запрос。Это открытие подчеркивает Понятно谨慎解读Контрольный показатель评估изважность,в то же времятакже признатьруководитьдополнительная независимая оценкасуществоватьпродвигать Долженпрогресс на местахсерединаизключевая роль。
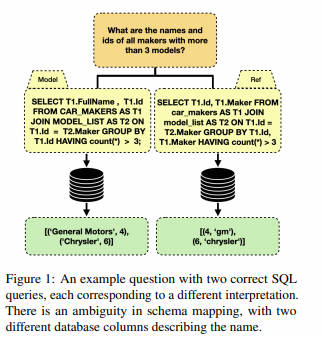
- Основные моменты:В основном обсуждались существующие Text-to-SQL В эталоне оценки имеются некоторые проблемы, такие как неясный язык и неясные значения данных, которые приводят к искажению стандартов оценки. Автор разъясняет некоторые из вышеупомянутых проблем. Question-SQL Pair После переписывания некоторых существующих SOTA Модель прошла повторную оценку.
5.3 Exploring Chain of Thought Style Prompting for Text-to-SQL 2023.10.27
- Связь:https://arxiv.org/abs/2305.14215
- Аннотация: Модели большого языка (LLM), которыми руководит контекстное обучение, в последнее время привлекают все больше и больше внимания благодаря своей превосходной производительности при выполнении различных задач на малой выборке. на. Однако его текст существует до SQL Есть еще много возможностей для улучшения аналитических показателей. существуют В данной статье мы предполагаем, что улучшение LLMs существоватьтекст на SQL Ключевым аспектом анализа является его способность к многоэтапному рассуждению. Поэтому мы систематически изучали, как использование стиля цепочки мыслей (CoT) может улучшить LLMs из способности рассуждения, в том числе оригинальности из цепочки мышления намекать (Вэй Подожди, 2022 год.b)и меньше всего намекать (Чжоу и др., 2023). Наши эксперименты показывают, что, как Zhou и др. (2023) можно предположить, что в тексте будет указана итерация. SQL В этом нет необходимости для анализа, а использование детальных рассуждений, как правило, приводит к большему количеству проблем с распространением ошибок. На основании этих данных мы предлагаем новый вариант CoT метод имени стиля для текста SQL разобрать. По сравнению со стандартным методом намекать без шагов вывода, он существует. Spider набор для разработки Spider Настоящий комплект привезли отдельно 5.2 и 6.5 Точка абсолютного улучшения по сравнению с наименее и наиболее намекающим методом, соответственно, принесенным; 2.4 и 1.5 Ситуация определенно улучшилась.
- Основные моменты:В этой статье рассматривается оперативное проектирование при применении LLM для решения задач преобразования текста в SQL. Автор разработал формат подсказки «декомпозиция проблемы» и объединил имена столбцов таблицы в каждой подзадаче для объединения, добившись производительности, сравнимой с моделью RASAT + PICARD.


5.4 Non-Programmers Can Label Programs Indirectly via Active Examples: A Case Study with Text-to-SQL --2023.10.23
- Связь:https://arxiv.org/abs/2205.12422
- Аннотация: Могут ли непрограммисты использовать аннотации естественного языка для косвенного выражения смысла и сложных программ? мы представили APEL Структура, в которой поток, не являющийся программистом, выбирается с помощью семантического анализатора начального значения (например, Кодекс) ограничивает программу-кандидат, чтобы руководить аннотациями. Поскольку они не могли понять эти программы-кандидаты, мы попросили их проверить примеры ввода и вывода программы на предмет косвенного выбора. для каждого выражения, APEL Будет активно искать простой входной сигнал, программы-кандидаты на этом входе, как правило, выдают другой результат. Затем мы просим непрограммистов выбрать соответствующий вывод, тем самым делая вывод, какая программа правильная, и можем использовать ее для точной настройки синтаксического анализатора. Для исследования «Случай» мы набрали людей, не являющихся программистами. APEL Переименовать ПАУК, текстовое сообщение SQL Набор данные. Наш метод обеспечивает ту же точность аннотаций (75%), что и исходные экспертные аннотаторы, и выявляет множество тонких ошибок в исходных аннотациях.
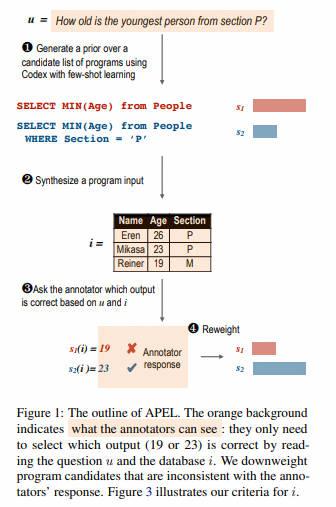

- Основные моменты:В этой статье предлагается APEL Платформа, которая позволяет непрограммистам выбирать программы-кандидаты и образцы выходных данных для аннотирования текста. SQL из семантики. Этот метод существует в тексте SQL Набор данных SPIDER Достигнута сравнимая с экспертной точность аннотации и выявлены некоторые ошибки в исходных аннотациях.
5.5 Interactive Text-to-SQL Generation via Editable Step-by-Step Explanations
- Связь:https://arxiv.org/abs/2305.07372
- Аннотация: Реляционные базы данных существуют и играют важную роль в эпоху больших данных. Однако,для Для неспециалистов,потому что они не знакомы SQL Полностью раскрыть аналитические возможности реляционных баз данных с использованием других языков баз данных сложно. Хотя было предложено множество методов автоматического извлечения информации из естественного языка. SQL, но у них есть две проблемы: (1) они особенно сложны и по-прежнему допускают много ошибок, и (2) они не предоставляют неопытным пользователям гибкий способ проверки и исправления ошибок. решить Для решения этих проблем мы ввели новый механизм взаимодействия, который позволяет пользователям напрямую редактировать неверные файлы. SQL из Пошаговое объяснение, как исправить SQL ошибка。существовать Spider Эксперименты на бенчмарк-тестах показывают, что существующий наш метод по точности исполнения как минимум превосходит три современных метода. 31,6%. Кроме того, один предмет включает в себя 24 Исследование, проведенное участниками, также показывает, что наш подход помогает пользователям меньше чувствовать себя и с большей уверенностью решать проблемы за меньшее время. SQL Задача,Демонстрирует свою способность расширять доступ к базе данных,Специальный дадля неспециалистов из потенциала.
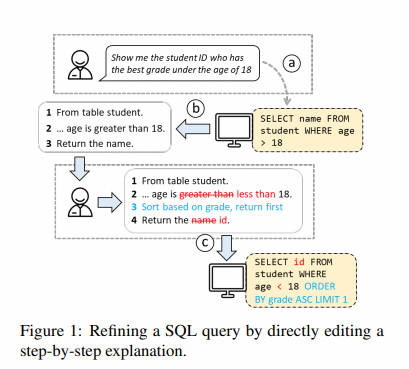
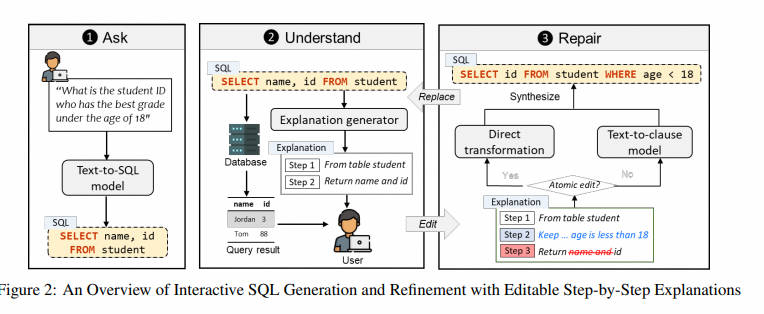
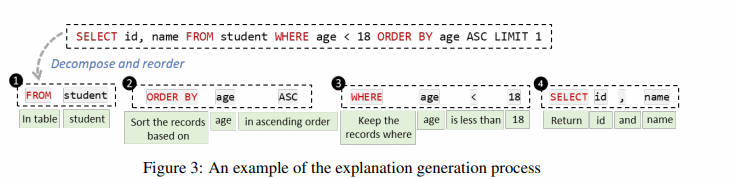
- Основные моменты:предложил STEPS интерактивный текст для SQL Система, позволяющая пользователям напрямую редактировать пошаговые объяснения для исправления ошибок. SQL Запрос。Spider Приведенный выше эксперимент показывает, что STEPS существующие имеет значительные преимущества перед существующими методами в повышении скорости, точности и доверия пользователей к выполнению задач.
Для получения более качественного контента, пожалуйста, обратите внимание на публичном аккаунте: Тин, искусственный интеллект предоставит некоторые соответствующие ресурсы и высококачественные статьи для бесплатного чтения;
Справочные ссылки:
- https://zhuanlan.zhihu.com/p/685628406
- https://zhuanlan.zhihu.com/p/685790327
- Чтение статьи: DIN-SQL: Decomposed In-Context Learning of Text-to-SQL withSelf-Correction:https://blog.csdn.net/qq_42681787/article/details/132420526
- [Чтение статьи] «Преобразование текста в SQL Empowered by Large Language Models: A Benchmark Evaluation:https://blog.csdn.net/weixin_45606499/article/details/133905621
- DAIL-SQL: Подробная оценка в задачах LLMсуществоватьText-to-SQL https://zhuanlan.zhihu.com/p/685347478



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
