Несколько способов и анализ создания индекса elasticsearch
1. Создайте индекс, используя API создания индекса.
1. Укажите имя индекса для создания индекса.
PUT test_index
Когда elasticsearch возвращает true, это означает, что мы успешно создали индекс с именем test_index в elasticsearch, и при его создании для индекса не были указаны поля.
Затем мы просматриваем детали этого индекса:
GET test_index{
"test_index": {
"aliases": {},
"mappings": {
"dynamic_templates": [
{
"message_full": {
"match": "message_full",
"mapping": {
"fields": {
"keyword": {
"ignore_above": 2048,
"type": "keyword"
}
},
"type": "match_only_text"
}
}
},
{
"message": {
"match": "message",
"mapping": {
"type": "match_only_text"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
},
"settings": {
"index": {
"refresh_interval": "10s",
"indexing": {
"slowlog": {
"threshold": {
"index": {
"warn": "200ms",
"trace": "20ms",
"debug": "50ms",
"info": "100ms"
}
},
"source": "1000"
}
},
"translog": {
"sync_interval": "5s",
"durability": "async"
},
"provided_name": "test_index",
"max_result_window": "65536",
"creation_date": "1700017444301",
"unassigned": {
"node_left": {
"delayed_timeout": "5m"
}
},
"number_of_replicas": "1",
"uuid": "YAIUJ64oTYuQpEjMvQK_Rg",
"version": {
"created": "8080199"
},
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_hot,data_warm,data_cold"
}
}
},
"search": {
"slowlog": {
"threshold": {
"fetch": {
"warn": "200ms",
"trace": "50ms",
"debug": "80ms",
"info": "100ms"
},
"query": {
"warn": "500ms",
"trace": "50ms",
"debug": "100ms",
"info": "200ms"
}
}
}
},
"number_of_shards": "1"
}
}
}
}Мы видим, что в сопоставлениях индексов, за исключением конфигурации сопоставления, поставляемой с динамическим шаблоном, нет других сопоставлений индексов. В то же время параметры индекса шаблона default@template также адаптируются.
Теперь мы вручную вставляем в индекс фрагмент данных.
PUT /test_index/_doc/1?pretty
{
"name":"Чжан Сан",
"age":23,
"remark":"Люблю учиться, люблю читать, люблю жизнь"
}В это время elasticsearch возвращает следующую информацию, сообщающую нам, что часть данных с «_id», равным 1, была успешно создана в индексе test_index. «_version» данных также равна 1. Выполнение было успешным на 2 сегментах. и не удалось на 0 осколках.

Теперь мы повторно выполняемGET test_index,Мы обнаружили, что при отображении индекса,Есть дополнительный раздел свойств.,В свойствах уже есть «имя», «возраст», «от рекомендаций». три поля. В то же время elasticsearch автоматически сопоставляет типы полей с этими тремя полями.
{
"test_index": {
"aliases": {},
"mappings": {
"dynamic_templates": [
{
"message_full": {
"match": "message_full",
"mapping": {
"fields": {
"keyword": {
"ignore_above": 2048,
"type": "keyword"
}
},
"type": "match_only_text"
}
}
},
{
"message": {
"match": "message",
"mapping": {
"type": "match_only_text"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
],
"properties": {
"age": {
"type": "long"
},
"name": {
"type": "keyword"
},
"remark": {
"type": "keyword"
}
}
}
}На этом этапе мы можем получить данные, которые мы вставили с помощью запросов. Вы можете видеть, что elasticsearch вернул нам совпадающие данные.
GET test_index/_search
{
"query": {
"term": {
"age": {
"value": "23"
}
}
}
}
Когда мы использовали другой запрос, используя match для запроса текущих данных, мы обнаружили, что elasticsearch не возвращает нам данные.
GET test_index/_search
{
"query": {
"match": {
"remark": "читать"
}
}
}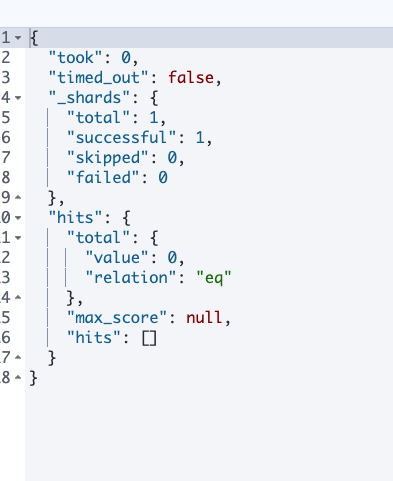
Проверив сопоставление индекса, мы обнаружили, что тип поля примечания, определяемый elasticsearch, — ключевое слово. Из предыдущей статьи мы знаем, что ключевое слово не может быть сегментировано. Поэтому мы не можем найти данные с помощью запроса на совпадение. Так как же нам действовать при создании индекса?
"properties": {
"age": {
"type": "long"
},
"name": {
"type": "keyword"
},
"remark": {
"type": "keyword"
}
}Когда мы создаем индекс, мы вручную ограничиваем типы полей индекса.
PUT /test_index_new
{
"mappings": {
"properties": {
"name": { "type": "text" },
"age": { "type": "integer" },
"remark": { "type": "text" }
}
}
}После PUT того же фрагмента данных мы выполнили запрос на совпадение по индексу test_index_new и обнаружили, что данные можно найти нормально.
GET test_index_new/_search
{
"query": {
"match": {
"remark": "читать"
}
}
}
Использование создания индекса вручную имеет следующие основные преимущества и недостатки.
преимущество:
- Гибкость: при создании индекса вручную мы можем самостоятельно устанавливать параметры и типы сопоставления индекса. Включая количество сегментов индекса, количество копий, типы полей, анализаторы, используемые для указанных полей, и другие конфигурации параметров. Он может лучше удовлетворить потребности конкретных бизнес-сценариев.
- Настраиваемость: при создании индекса можно выполнить соответствующую оптимизацию параметров на основе характеристик данных и требований запроса. Выбирайте подходящие типы полей, чтобы повысить производительность чтения и записи, а также релевантность сопоставления запросов.
- Управление версиями. Когда бизнесу необходимо сохранить несколько версий данных, мы можем вручную создать несколько индексов версий для управления данными. Это также облегчает последующие операции, такие как миграция или откат различных версий данных.
недостаток:
- Требуется ручное управление индексами: при создании индекса пользователи должны понимать значение и использование связанных с индексом конфигураций и использовать их с соответствующими инструментами. Могут потребоваться дополнительные работы.
- Склонен к ошибкам: создание индексов вручную может привести к человеческой ошибке. Если во время создания индекса возникают ошибки, это может повлиять на производительность индекса и работу системы.
- Требуется обслуживание. Индексы, созданные вручную, требуют обслуживания вручную. Если структура индекса или требования к полям изменяются, вам необходимо вручную настроить параметры индекса и сопоставление.
думать:
В конкретных бизнес-сценариях создание индексов вручную может лучше удовлетворить потребности нашего бизнеса. Когда бизнес растет, необходимо создавать все больше и больше индексов вручную. Есть ли более удобный способ создания индексов?
2. Используйте шаблоны индексов для автоматической адаптации индексов.
Мы можем заранее определить параметры индекса и сопоставление для различных бизнес-индексов, определив шаблоны индексов. Когда индекс будет создан, он будет адаптирован к соответствующему шаблону путем чтения «index_patterns» в шаблоне. Для удовлетворения различных потребностей в индексировании в разных бизнес-сценариях.
В следующем коде мы создаем шаблон с именем test_template. Приоритет шаблона равен 1, что в основном адаптируется к индексу, начинающемуся с «test». В настройках индекса мы устанавливаем количество первичных шардов индекса на 3 и количество реплик на 1. В сопоставлениях индексов мы ограничили типы трех полей: «имя», «возраст» и «примечание». Когда elasticsearch возвращает true, это означает, что создание шаблона завершено.
PUT _template/test_template
{
"order": 1,
"index_patterns": ["test*"],
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"name": { "type": "text" },
"age": { "type": "integer" },
"remark": { "type": "text" }
}
}
}
Теперь мы заново создаем индекс с именем test_template_index, ничего не указывая. Давайте посмотрим на отображение индекса.
PUT test_template_indexВ это время мы обнаружили при сопоставлении индекса, что этот индекс автоматически адаптировал параметры индекса, которые мы ранее указали в шаблоне для имени индекса, начинающегося с «теста», при сопоставлении. Это значительно облегчает создание индексов и управление ими.
{
"test_template_index": {
"aliases": {},
"mappings": {
"_source": {
"enabled": false
},
"dynamic_templates": [
{
"message_full": {
"match": "message_full",
"mapping": {
"fields": {
"keyword": {
"ignore_above": 2048,
"type": "keyword"
}
},
"type": "match_only_text"
}
}
},
{
"message": {
"match": "message",
"mapping": {
"type": "match_only_text"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
],
"properties": {
"age": {
"type": "integer"
},
"name": {
"type": "text"
},
"remark": {
"type": "text"
}
}
},
"settings": {
"index": {
"refresh_interval": "10s",
"indexing": {
"slowlog": {
"threshold": {
"index": {
"warn": "200ms",
"trace": "20ms",
"debug": "50ms",
"info": "100ms"
}
},
"source": "1000"
}
},
"translog": {
"sync_interval": "5s",
"durability": "async"
},
"provided_name": "test_template_index",
"max_result_window": "65536",
"creation_date": "1700030711762",
"unassigned": {
"node_left": {
"delayed_timeout": "5m"
}
},
"number_of_replicas": "1",
"uuid": "cTiJp67xThSwpavbV3Hlog",
"version": {
"created": "8080199"
},
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_hot,data_warm,data_cold"
}
}
},
"search": {
"slowlog": {
"threshold": {
"fetch": {
"warn": "200ms",
"trace": "50ms",
"debug": "80ms",
"info": "100ms"
},
"query": {
"warn": "500ms",
"trace": "50ms",
"debug": "100ms",
"info": "200ms"
}
}
}
},
"number_of_shards": "3"
}
}
}
}Использование создания индекса вручную имеет следующие основные преимущества и недостатки.:
преимущество:
- Автоматизация: параметры индекса и сопоставление полей можно заранее определить с помощью шаблонов, а объем ручных операций можно уменьшить за счет адаптации шаблона. Убедитесь, что индексы, созданные в одном и том же бизнес-сценарии, имеют согласованную структуру и конфигурацию параметров.
- Единообразие. Благодаря адаптации шаблона индекса вы можете гарантировать, что индексы, созданные конкретными бизнес-индексами, будут иметь одинаковые настройки и сопоставления. Он может эффективно обеспечить согласованность структуры данных. Особенно важно в кластерах эластичного поиска с большим количеством индексов.
- Упрощенное управление: адаптация шаблона индекса может значительно снизить нашу рабочую нагрузку по созданию и обслуживанию индексов. Нам нужно поддерживать лишь небольшое количество шаблонов индексов. Нет необходимости управлять настройкой каждого индекса индивидуально.
недостаток:
- Ограничения: Шаблон индекса имеет определенные ограничения по гибкости индекса, поскольку метод адаптации шаблона индекса используется для создания индексов с общими характеристиками. Предопределенные методы не могут удовлетворить потребности специальных индексов. Если встречаются специальные индексы, требуются дополнительные модификации.
FAQ
После создания шаблона индекса при создании индекса вы обнаружили, что параметры в шаблоне не адаптированы к созданному индексу?
Причины и идеи по устранению неполадок:
- Проверьте конфигурацию index_patterns в шаблоне и проверьте, правильно ли настроен подстановочный знак. Когда шаблон индекса адаптируется к индексу, он использует index_patterns, чтобы определить, управляется ли индекс текущим шаблоном.
- Отметьте «заказ» в шаблоне. «Заказ» представляет приоритет шаблона. Чем больше значение «заказ», тем выше приоритет шаблона. Когда шаблоны адаптируются к индексу, в первую очередь адаптируются шаблоны с высоким приоритетом.
- Проверьте, имеют ли другие шаблоны индексов, значение «index_patterns» которых настроено как «*», более высокий приоритет, чем шаблон индекса для конкретного бизнеса.
ЯсуществоватьучаствоватьНа третьем этапе специального тренировочного лагеря Tencent Technology Creation 2023 года будет проводиться конкурс сочинений. Сформируйте команду и примите участие, чтобы разделить приз!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
