Несколько распространенных способов чтения файлов конфигурации в Python
Введение
Когда мы разрабатываем среды автоматизированного тестирования, мы часто используем файлы конфигурации, и существует множество типов файлов конфигурации. Существует множество распространенных форматов файлов конфигурации: ini, yaml, xml, Properties, txt, py и т. д.
Конфигурационный файл ini
Хотя файл конфигурации размещает некоторый общедоступный контент, такой как среда, путь, параметры и т. д. Но вы также можете поместить тестовые данные, например некоторую информацию об интерфейсе, но это не рекомендуется.
Давайте посмотрим на пример Python, читающего файл конфигурации ini:
1. Создайте новый файл конфигурации ini, символ:; является комментарием.
;Тестовый файл конфигурации
[апи]
URL = "www."
метод = получить
заголовок =
данные =
resp_code = 200
resp_json = {}2. Создайте файл py, который читает ini, желательно в том же каталоге, что и файл конфигурации ini:
from configparser import ConfigParser
import os
class ReadConfigFile(object):
def read_config(self):
conn = ConfigParser()
file_path = os.path.join(os.path.abspath('.'),'config_test.ini')
if not os.path.exists(file_path):
raise FileNotFoundError("Файл не существует")
conn.read(file_path)
url = conn.get('api','url')
method = conn.get('api','method')
header = conn.get('api','header')
data = conn.get('api','data')
resp_code = conn.get('api','resp_code')
resp_json = conn.get('api','resp_code')
return [url,method,header,data,resp_code,resp_json]
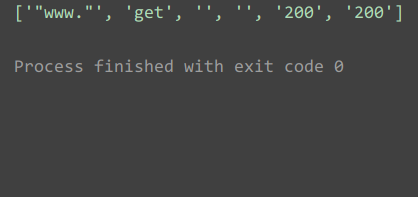
rc = ReadConfigFile()
print(rc.read_config())Результаты запуска:
Ямл-файл конфигурации
Метод чтения файла конфигурации ini был представлен выше. Теперь поговорим о чтении файла yaml.
yaml [ˈjæməl]: Еще один язык разметки: Еще один язык разметки. yaml — это язык, специально используемый для записи файлов конфигурации.
1. Правила файла Yaml
1. С учетом регистра;
2. Используйте отступы для обозначения иерархических связей;
3. Используйте пробел для отступов вместо клавиши Tab.
4. Количество пробелов для отступов не фиксировано, выравнивать по левому краю нужно только элементы одного уровня;
5. Строки в файле не обязательно заключать в кавычки, но если строка содержит специальные символы, их необходимо обозначить кавычками;
6. Комментарий отмечен #
2. Структура данных файла YAML.
1. Объект: коллекция пар ключ-значение (называемая «картой или словарем»). Пары ключ-значение представлены структурой двоеточия ":", и для разделения двоеточия и значения необходимо использовать пробелы.
2. Массив: набор значений, расположенных по порядку (называемый «последовательностью или списком»). Перед массивом стоит символ «-», а символ и значение должны быть разделены пробелами.
3. Скаляры: одно неделимое значение (например: строка, логическое значение, целое число, число с плавающей запятой, время, дата, ноль и т. д.). Ни одно значение не может быть представлено нулем или ~
Основные типы данных файлов yaml
# скалярная величина
s_val: name # Строка: {'s_val': 'name'}
spec_s_val: "name\n" # Специальная строка: {'spec_s_val': 'name\n'
num_val: 31.14 # Число: {'num_val': 31.14}
bol_val: true # Логическое значение: {'bol_val': True}
nul_val: null # нулевое значение: {'nul_val': None}
nul_val1: ~ # нулевое значение: {'nul_val1': None}
time_val: 2018-03-01t11:33:22.55-06:00 # Значение времени: {'time_val': datetime.datetime(2018, 3, 1, 17, 33, 22, 550000)}
date_val: 2019-01-10 # Значение даты: {'date_val': datetime.date(2019, 1, 10)}Простое чтение:
Предварительное условие: перед чтением файлов yaml в python вам необходимо установить pyyaml и импортировать модуль yaml.
import yaml
doc = """
---
"data":
"id":
-
123
---
"data":
"name":
-
"тест"
"age": 2
"""
doc2 = """
---
"data":
"id":
-
123
"""
# Способ 1
data = yaml.load(doc2,Loader=yaml.FullLoader)
print(type(data))
print(data)
get_dict = []
# Итератор
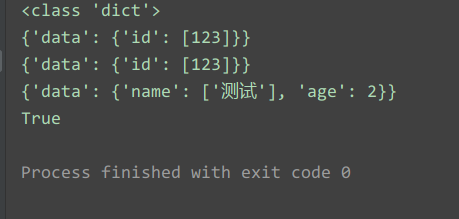
data2 = yaml.load_all(doc,Loader=yaml.FullLoader)
for i in data2:
print(i)
get_dict.append(i)
print(get_dict[1]['data']['age'] == 2)Результаты запуска:
Здесь есть проблема: Loader=yaml.FullLoader, объяснение такое:
"""
1.
yaml.load(f, Loader=yaml.FullLoader)
2.
yaml.warnings({'YAMLLoadWarning': False}) # Предупреждение о глобальных настройках, не рекомендуется
Несколько методов загрузки Loader
BaseLoader - -Загружайте только самый простой YAML.
SafeLoader - - Безопасно загружайте подмножества языка YAML. Рекомендуется для загрузки ненадежных входных данных.
FullLoader - - Загрузите полный язык YAML. Избегайте произвольного выполнения кода. Это текущий вызов загрузчика по умолчанию (PyYAML5.1).
yaml.load(input) (после предупреждения).
UnsafeLoader - - (также известный как обратная совместимость загрузчика) Исходный код загрузчика, который можно легко использовать с помощью ненадежного ввода данных.
"""Чтение одного документа yaml
Здесь метод open Python используется для открытия файла, а метод загрузки yaml может использоваться для преобразования данных в одном документе yaml в словарь или список.
Создайте новый файл конфигурации test_config02:
---
data:
id: 1
name: {
age: 2}
other:
-
height: 3Создайте новый файл конфигурации чтения py:
# единый документ
import yaml
import os
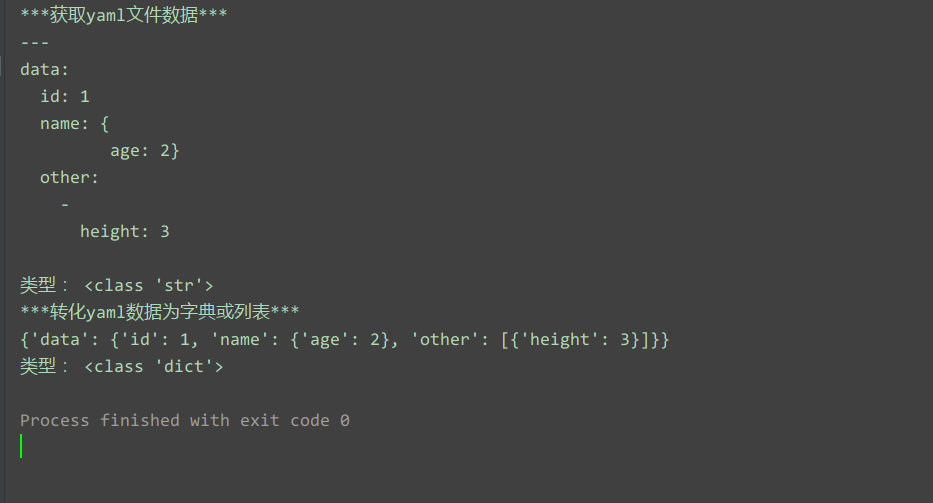
def get_yaml_data(yaml_file):
# Открыть файл YAML
print("***Получить данные файла yaml***")
file = open(yaml_file, 'r', encoding="utf-8")
file_data = file.read()
file.close()
print(file_data)
печать("Тип:", type(file_data))
# Преобразование строки в словарь или список
print("***Преобразовать данные yaml в словарь или список***")
data = yaml.load(file_data,Loader=yaml.FullLoader)
print(data)
печать("Тип:", type(data))
return data
current_path = os.path.abspath(".")
yaml_path = os.path.join(current_path, "test_config02")
get_yaml_data(yaml_path)Результаты запуска:
Чтение нескольких документов yaml
Несколько документов в одном файле yaml, для сегментации используйте метод разделения ---
Создайте новый файл конфигурации yaml test_config:
---
data:
id: 1
name: {
age: 2}
other:
-
height: 3
---
id: 2
name: «Тестовый пример 2»Напишите функции чтения и записи yaml:
import yaml
import os
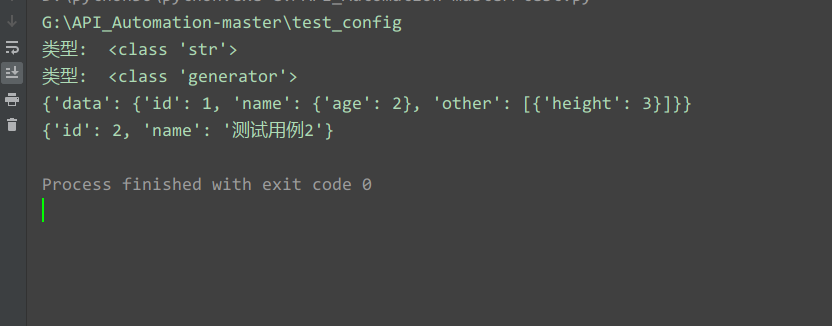
def get_yaml_load_all(filename):
with open(filename,'r') as fp:
file_data = fp.read()
fp.close()
print("Введите: ",type(file_data))
all_data = yaml.load_all(file_data,Loader=yaml.FullLoader)
print("Введите: ",type(all_data))
for data in all_data:
print(data)
current_path = os.path.abspath('.')
file_path = os.path.join(current_path,'test_config')
print(file_path)
get_yaml_load_all(file_path)Результаты запуска:
XML-файл конфигурации
XML-файлы чтения Python могут реже использоваться в автоматизированном тестировании. Вот введение:
Содержимое этого XML-файла следующее:
<collection shelf="New Arrivals">
<movie title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title="Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title="Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title="Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
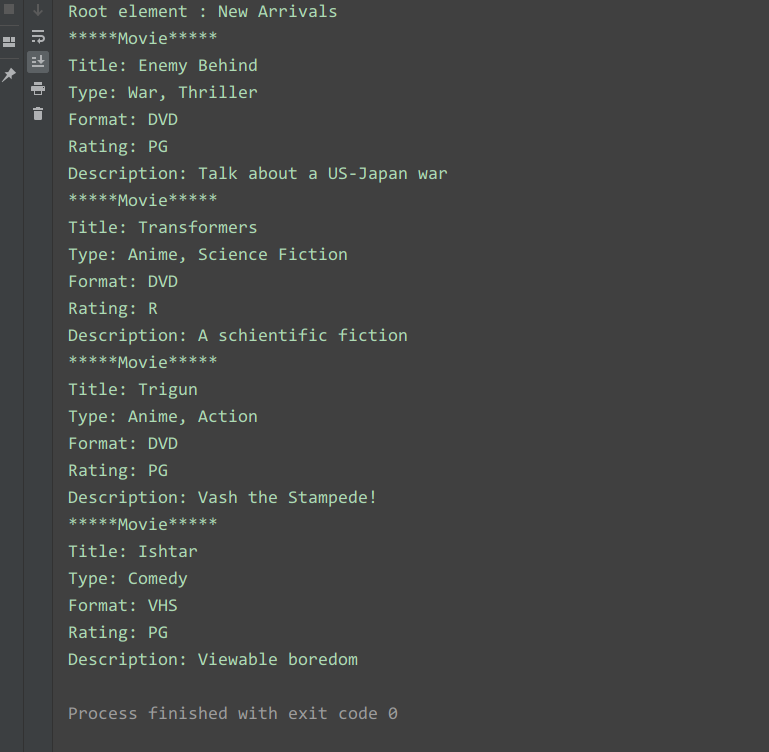
</collection>Чтение кода:
# coding=utf-8
import xml.dom.minidom
from xml.dom.minidom import parse
DOMTree = parse('config')
collection = DOMTree.documentElement
if collection.hasAttribute("shelf"):
print("Root element : %s" % collection.getAttribute("shelf"))
# Получить все фильмы в коллекции
movies = collection.getElementsByTagName("movie")
# Распечатать подробную информацию о каждом фильме
for movie in movies:
print("*****Movie*****")
if movie.hasAttribute("title"):
print("Title: %s" % movie.getAttribute("title"))
type = movie.getElementsByTagName('type')[0]
print("Type: %s" % type.childNodes[0].data)
format = movie.getElementsByTagName('format')[0]
print("Format: %s" % format.childNodes[0].data)
rating = movie.getElementsByTagName('rating')[0]
print("Rating: %s" % rating.childNodes[0].data)
description = movie.getElementsByTagName('description')[0]
print("Description: %s" % description.childNodes[0].data)Результаты запуска:



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
