Недостатки «больших моделей» и сильные стороны «графов знаний»
01. Сравнение большой языковой модели и графа знаний
Для начала давайте сравним преимущества и недостатки больших языковых моделей и графов знаний.
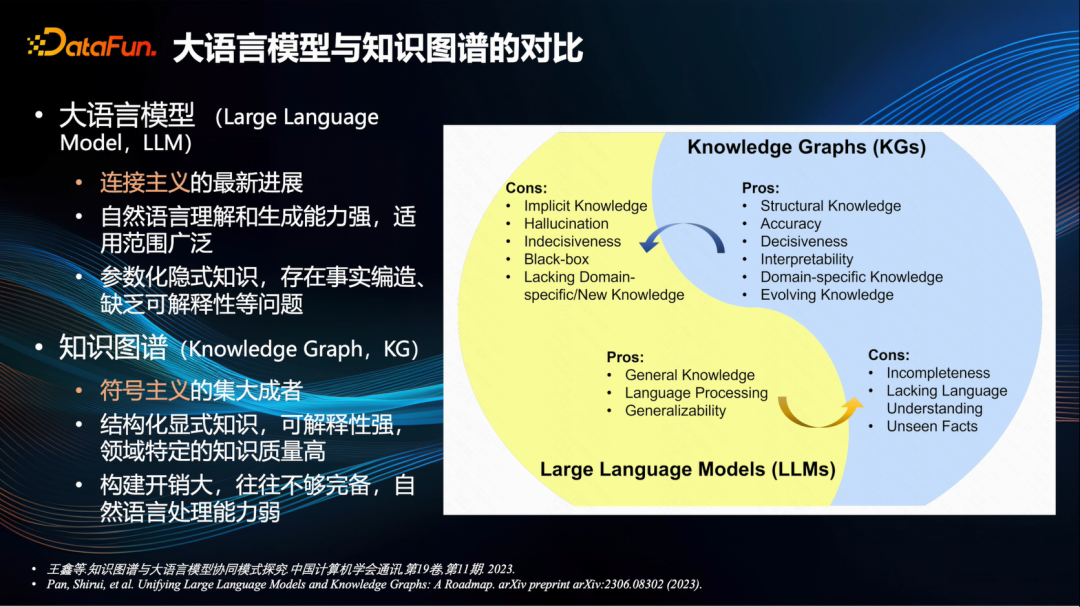
Когда в прошлом году вышел ChatGPT, раздавались голоса, утверждавшие, что графы знаний устарели и будут заменены большими моделями. Однако, благодаря углубленным дискуссиям и исследованиям, проведенным за последний год, в настоящее время в отрасли в целом полагают, что большие языковые модели и графы знаний имеют свои сильные стороны и могут дополнять друг друга [1,2].
В частности, модель большого языка, основанная на технологии глубоких нейронных сетей, является последней вехой коннекционизма. Ее преимущество заключается в ее сильной способности понимать и генерировать естественный язык, а также в широком спектре приложений. Недостаток заключается в том, что знание представляет собой параметризованное неявное знание, и существуют такие проблемы, как фабрикация фактов и отсутствие интерпретируемости. Это то, что мы часто называем феноменом галлюцинаций в контенте, генерируемом большими моделями.
Граф знаний является мастером символизма и широко изучается и применяется за последние десять лет. Его преимущество состоит в том, что знания структурированы, явны и легко интерпретируются. Качество знаний, особенно в некоторых конкретных областях, чрезвычайно велико. Конечно, недостатки также очевидны: стоимость конструкции слишком высока, она часто не совсем корректна и относительно плохо обрабатывает естественный язык.
Так как же их объединить, чтобы дополнить преимущества друг друга? Далее взаимодействие между ними будет проанализировано с разных точек зрения.
02. Большие языковые модели помогают извлекать знания
Во-первых, мощные возможности понимания языка больших моделей могут помочь в задачах извлечения знаний.
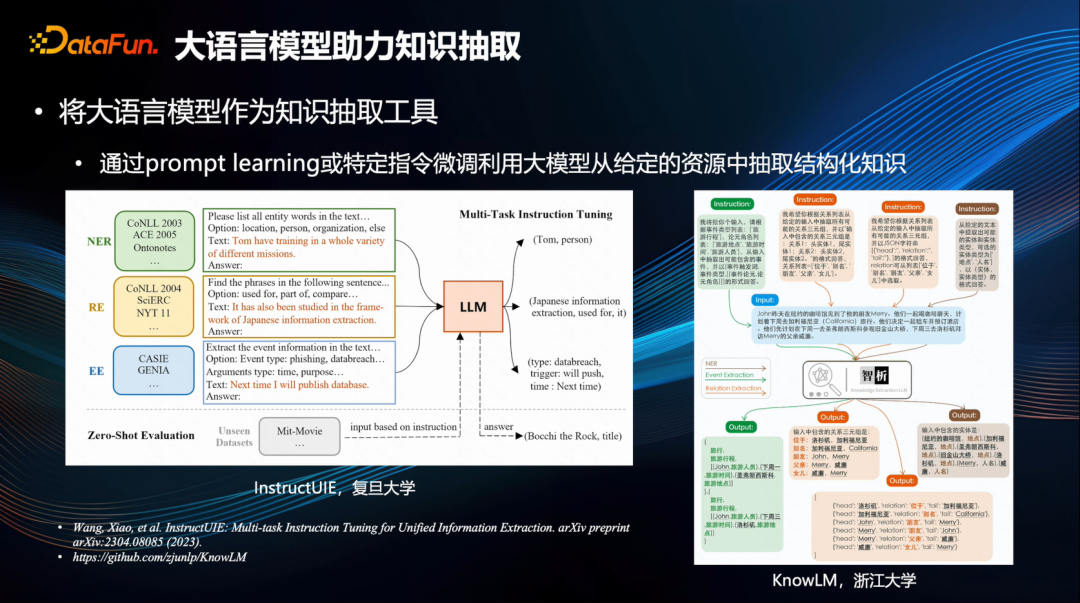
Типичными примерами являются InstructUIE[3] Университета Фудань и KnowLM[4] Университета Чжэцзян. Используйте специальные инструкции для мобилизации больших моделей для извлечения полезных знаний из заданных ресурсов и выполнения различных задач, таких как извлечение сущностей, извлечение отношений, извлечение событий и т. д. Конечно, для этих инструкций также можно выполнить специальную тонкую настройку SFT (глубокое извлечение признаков), что может усилить эффект оптимизации. Другими словами, используя эти инструкции, вы можете легко выполнять различные задачи по извлечению объектов и отношений в данном контенте.
03. Большие языковые модели помогают дополнить знания
Есть также некоторые работы, в которых параметризованные знания извлекаются из крупномасштабных моделей с помощью конкретных инструкций по построению структурированных знаний для облегчения заполнения графа знаний [5].
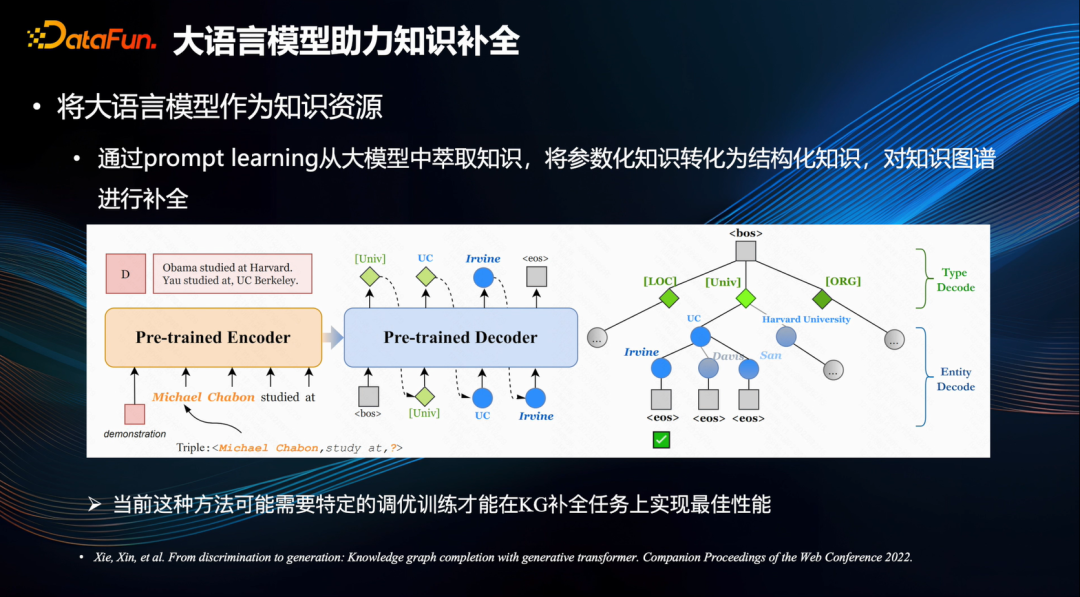
Поскольку в процессе обучения крупномасштабные модели подвергаются воздействию большого количества текстовых данных, которые содержат богатые объективные знания, если их можно точно извлечь, это значительно улучшит полноту графа знаний. Однако, учитывая, что контент, генерируемый современными крупномасштабными моделями, может страдать от проблем с галлюцинациями, современные методы требуют определенных ограничений по настройке и обучению, и в этой области все еще существует значительное пространство для исследований.
04. График знаний помогает оценить возможности большой языковой модели.
В свою очередь, графы знаний также могут помочь в больших моделях.
1. Оценочный набор

Графы знаний оказывают существенную помощь при оценке больших моделей. Они всесторонне оценивают возможности больших моделей с точки зрения освоения и использования мировых знаний. Типичным представителем является оценочный набор KoLA, предложенный Университетом Цинхуа [6], который предназначен для. Четыре уровня познания знаний, а именно память знаний, понимание знаний, применение знаний и инновации знаний, всесторонне проверяют большую модель.
2. Заключение оценки
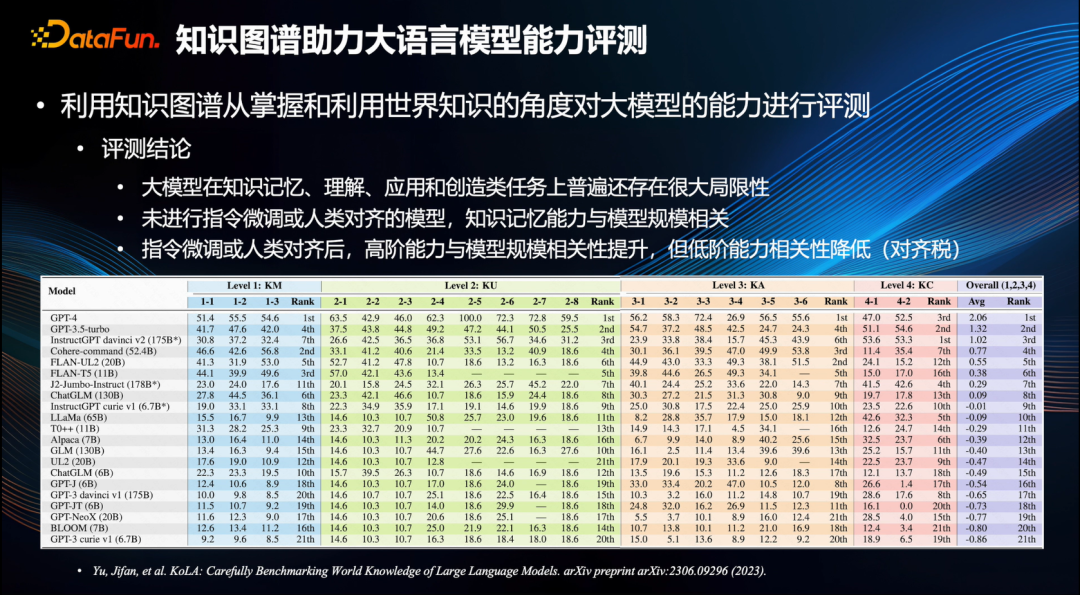
Судя по текущим результатам испытаний, можно сделать несколько интересных выводов, заслуживающих внимания. Прежде всего, большие модели обычно имеют большие ограничения в таких задачах, как запоминание знаний, понимание, применение и инновации. Во-вторых, для модели, которая не была точно настроена и не имеет ничего общего с людьми, ее способность памяти знаний положительно коррелирует с размером модели. То есть, чем больше параметров имеет модель, тем сильнее ее способность памяти знаний. . Однако после точной настройки инструкций и согласования их с людьми его способности высокого уровня, такие как применение знаний и инноваций, положительно коррелируют с моделью, а способности низкого уровня, такие как память и понимание, отрицательно коррелируют с моделью. С ним коррелирует так называемый «налог на выравнивание», этот вывод чрезвычайно важен [6].
05. График знаний помогает реализовать большие языковые модели
1. График знаний используется в качестве внешнего инструмента или плагина для повышения точности знаний и интерпретируемости контента, создаваемого большими моделями.
Другой аспект графа знаний, помогающий большим языковым моделям, заключается в том, что он может помочь в реализации больших моделей. Иллюзия больших моделей является одним из важных факторов, затрудняющих практическое применение. Все рассматривают возможность использования расширенного режима [7] для управления и ограничения контента, создаваемого большими моделями. Это означает включение некоторого контента, связанного с проблемами пользователей, в качестве входных данных в справочную информацию большой модели, чтобы смягчить явление серьезной бессмыслицы и тем самым повысить точность и интерпретируемость знаний.
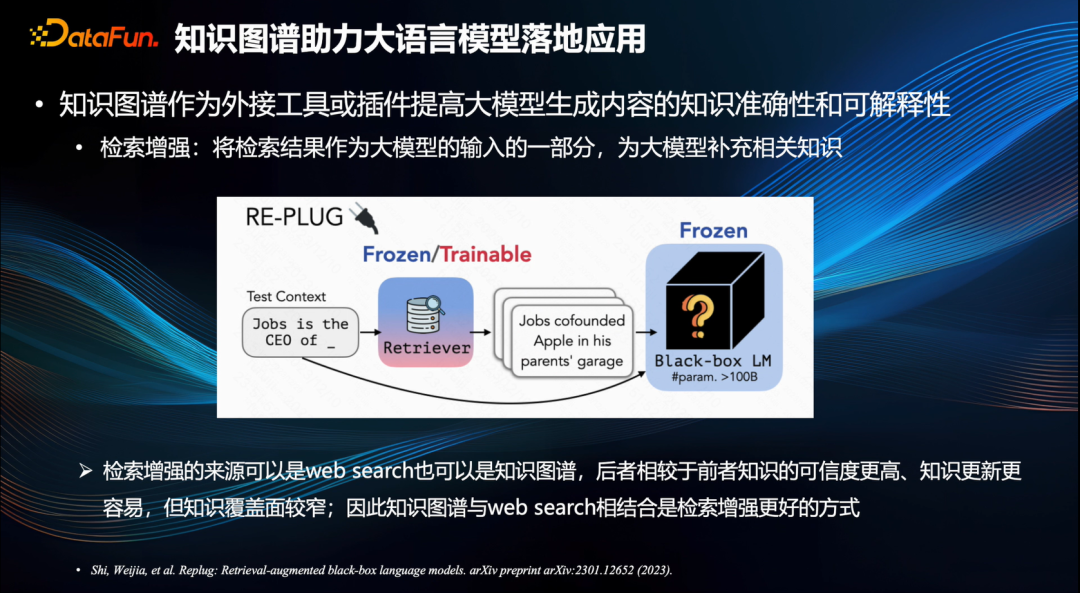
Будучи высококачественным источником знаний, граф знаний закладывает основу для открытия режима улучшения. По сравнению с веб-поиском информация, содержащаяся в графах знаний, более достоверна, а ошибки легче найти в процессе обновления знаний и их можно точно исправить. Однако графы знаний также имеют определенные ограничения. Например, их охват относительно узок, и, особенно, с большей вероятностью будут опущены знания с длинным хвостом и сложные знания. Таким образом, сочетание графа знаний и веб-поиска является хорошим способом улучшить поиск знаний.
Фактически, первоначальное намерение Google предложить граф знаний состояло в том, чтобы улучшить производительность своей поисковой системы.
2. Граф знаний может повысить безопасность и согласованность контента, создаваемого большими моделями.
Графы знаний также помогают повысить безопасность и согласованность контента, создаваемого большими моделями.
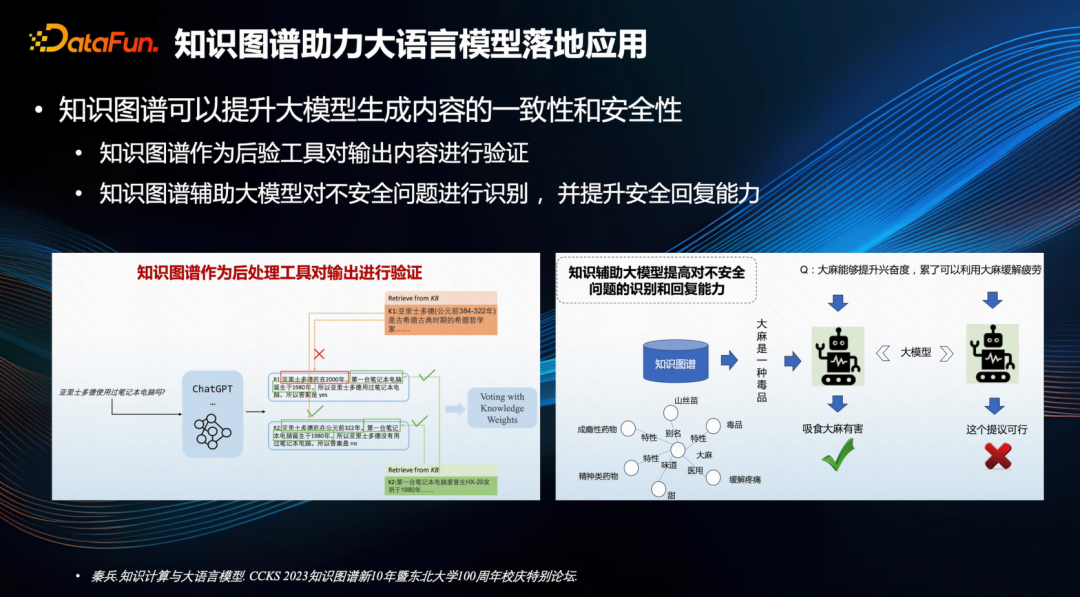
Например, Харбинский технологический институт предложил два решения. Первое — использовать граф знаний в качестве апостериорного инструмента для проверки выходного содержания, тем самым повышая его согласованность. Например, в примере слева «Использовал ли Аристотель ноутбук?» ChatGPT может генерировать связанный с этим контент, например, первая часть контента — «Аристотель умер в 2000 году». Однако эти сведения не согласуются с даты рождения и смерти Аристотеля на карте знаний, поэтому возникает конфликт. Благодаря такой проверке могут быть обнаружены некоторые ошибочные знания, а ответы, более соответствующие объективным фактам, могут быть отсеяны для вывода.
Во-вторых, граф знаний может помочь крупным моделям выявить небезопасные проблемы и повысить способность справляться с небезопасными сценариями. В примере справа пользователи могут задавать вопросы, касающиеся незаконной деятельности. Большие модели могут использовать графы знаний для идентификации конфиденциальных знаний и связанного с ними контента, тем самым генерируя более надежные ответы.
3. Графы знаний могут улучшить сложные логические способности больших моделей.
Графы знаний также могут улучшить возможности комплексного рассуждения крупномасштабных моделей.

Столкнувшись со сложными проблемами, большие модели не могут напрямую получить ответы от улучшений поиска. Вместо этого им необходимо находить ответы на вопросы посредством сравнения атрибутов операций набора отношений с несколькими переходами и других ссылок. В этом случае требуются точные рассуждения.
Университет Цинхуа разработал язык программирования, специально предназначенный для рассуждений и ответов на вопросы — KoPL [8]. Этот язык может преобразовать естественный язык в комбинацию основных функций для рассуждения и ответа на сложные вопросы. Например, посмотрите на пример справа и спросите: кто выше, Леброн Джеймс или его отец? Эта задача будет разложена на несколько основных функций, таких как определение роста Леброна Джеймса, запрос информации о его отце, затем определение роста его отца и, наконец, сравнение роста для получения ответа. Этот процесс отражает точное и строгое рассуждение. Стоит отметить, что язык программирования Университета Цинхуа имеет очевидные, прозрачные и модульные характеристики, что способствует отображению и пониманию процесса рассуждения. Это очень полезно для взаимодействия человека с компьютером и помогает улучшить интерпретируемость больших объемов информации. масштабные модели для ответов на вопросы. Кроме того, это программное обеспечение также может обрабатывать различные форматы текстов разных баз знаний и обладает хорошей масштабируемостью.
06. Интерактивное объединение графа знаний
Наконец, г-н Ван Синь из Тяньцзиньского университета поделился своим взглядом на интерактивную интеграцию графов знаний и крупномасштабных моделей в будущем на основе текущих результатов исследований [1].
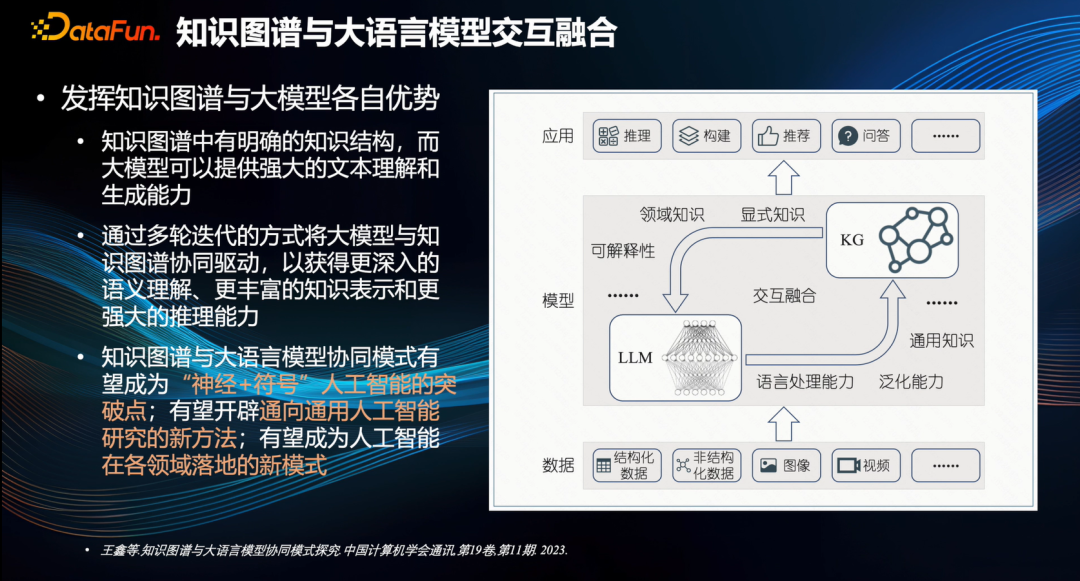
В графе знаний существует четкая структура знаний, а большие модели могут обеспечить мощные возможности понимания и создания текста. Благодаря множеству итераций большая модель и граф знаний могут управляться совместно для получения более глубокого семантического понимания, более богатого представления знаний и более мощного. способности рассуждения.
07. Заключение
Ожидается, что модель взаимодействия между графами знаний и большими моделями станет важным прорывом в поддержке нейронного и символического искусственного интеллекта, откроет новый путь к общему искусственному интеллекту, а также станет новой моделью применения искусственного интеллекта в различные поля.
В этих областях еще предстоит проделать большую работу. Специалисты в области графов знаний должны активно воспринимать и приветствовать изменения, вызванные технологией больших моделей. С одной стороны, мы должны в полной мере использовать потенциал крупномасштабных моделей для повышения эффективности и результативности инженерии знаний, с другой стороны, мы должны также использовать графы знаний для повышения точности, безопасности и интерпретируемости генерируемого контента; с помощью крупномасштабных моделей, чтобы провести исследование глубже. Эта способность глубоко интегрировать эти два направления выведет эту область на более высокий путь развития, который открывает множество интересных возможностей для научных исследований.
Выше представлен контент, которым поделились на этот раз, всем спасибо.
08. Ссылки
[1] Ван Синь, Чэнь Зируй, Ван Хаофэн. Исследование совместной модели графа знаний и модели большого языка [J/OL]. Коммуникации Китайской компьютерной федерации, 2023, 11(01): 2377. DOI:10.3778/. j.issn.1673-9418.2308070 .
[2] ПАНЬ С, ЛУО Л, ВАН И, ждать. Объединение больших языковых моделей и графов знаний: дорожная карта [J/OL]. Транзакции IEEE по знаниям и инженерии данных, 2024: 1-20. DOI:10.1109/TKDE.2024.3352100.
[3] ВАН X, ЧЖОУ W, ZU C, ждать. InstructUIE: настройка многозадачных инструкций для унифицированного извлечения информации[M/OL]. arXiv, 2023[2024-03-08]. http://arxiv.org/abs/2304.08085. DOI: 10.48550/arXiv.2304.08085.
[4] zjunlp/KnowLM[CP/OL]. ZJUNLP, 2024[2024-03-08]. https://github.com/zjunlp/KnowLM.
[5] СЕ X, ЧЖАН Н, ЛИ Z, ждать. От дискриминации к генерации: пополнение графа знаний с помощью генеративного преобразователя [C/OL] // Сопутствующие материалы веб-конференции 2022. 2022: 162-165 [2024-03-08]. http://arxiv.org/abs/2202.02113. DOI: 10.1145/3487553.3524238.
[6] Ю Ч, ВАН Х, ТУ С, ждать. KoLA: Тщательный анализ мировых знаний о больших языковых моделях [M/OL]. arXiv, 2023[2024-03-08]. http://arxiv.org/abs/2306.09296. DOI: 10.48550/arXiv.2306.09296.
[7] ШИ В, МИН С, ЯСУНАГА М, КИ. REPLUG: языковые модели черного ящика с расширенным поиском [M/OL]. arXiv, 2023[2024-03-08]. http://www.archiv.org/abs/2301.12652. DOI: 10.48550/arXiv.2301.12652.
[8] ЦАО С, ШИ Дж, ПАН Л, ждать. KQA Pro: набор данных с явными композиционными программами для ответов на сложные вопросы в базе знаний [M/OL]. arXiv, 2022[2024-03-08]. http://arxiv.org/abs/2007.03875. DOI: 10.48550/arXiv.2007.03875.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
