Национальный университет Тайваня предлагает DQ-DETR | Улучшите DETR за 3 простых шага, чтобы совершить большой скачок в обнаружении небольших целей

Хотя предыдущие методы, подобные DETR, были успешными при обнаружении обычных объектов, они по-прежнему сложны при обнаружении небольших объектов, поскольку информация о местоположении запроса объекта не настроена для обнаружения небольших объектов, которые по размеру больше, чем обычные объекты. Кроме того, методы, подобные DETR, используют фиксированное количество Query , что делает их непригодными для наборов аэроданных, содержащих только небольшие объекты и с несбалансированным количеством экземпляров между различными изображениями. Поэтому авторы предлагают простую, но эффективную модель под названием DQ-DETR, которая состоит из трех различных компонентов: модуля подсчета классификации, улучшения функций на основе подсчета и динамического выбора запроса для решения вышеупомянутых проблем. DQ-DETR использует прогнозы модуля подсчета классификации и карту плотности для динамической корректировки количества целевых запросов и улучшения информации о местоположении запросов. DQ-DETR превосходит предыдущие методы, основанные на CNN и подобные DETR, достигая современного уровня mAP 30,2% в наборе данных AI-TOD-V2, который в основном состоит из небольших объектов.
1 Introduction
Сверточные нейронные сети (CNN) имеют преимущества при обработке семантических и пространственных текстур RGB. Большинство методов обнаружения объектов в основном основаны на CNN. Например, Faster R-CNN представляет сеть предложений регионов для создания потенциальных целевых регионов. FCOS применяет центральную ветвь прогнозирования для улучшения качества ограничивающих рамок.
Однако CNN не подходят для фиксации зависимостей на больших расстояниях в изображениях, что ограничивает производительность обнаружения. Недавно DETR объединил архитектуры CNN и Transformer для создания новой структуры обнаружения объектов. DETR использует кодировщик Transformer для интеграции фрагментов сегментированного изображения и передает их в декодер Transformer посредством обучаемого целевого запроса для получения окончательных результатов обнаружения. Кроме того, ряд методов, подобных DETR, направлен на улучшение производительности DETR и ускорение скорости сходимости DETR. Например, Deformable-DETR использует многомасштабные карты объектов, чтобы улучшить способность обнаруживать цели разных размеров. В то же время использование деформируемого модуля внимания может не только улавливать больше информации и контекстно-зависимых функций, но и ускорять конвергенцию обучения.
Тем не менее, в предыдущих подходах, подобных DETR, целевой запрос Transformer, используемый в декодере, не учитывал количество и положение экземпляров в изображении. Обычно они применяют фиксированное количество K целей Query, где K представляет максимальное количество обнаруженных целей, например, K=100 и K=900 в DETR и DINO-DETR соответственно. Более того, местоположение целевого запроса представляет собой изученный набор вложений, который не зависит от текущего изображения и не имеет четкого физического значения относительно того, где фокусируется запрос.
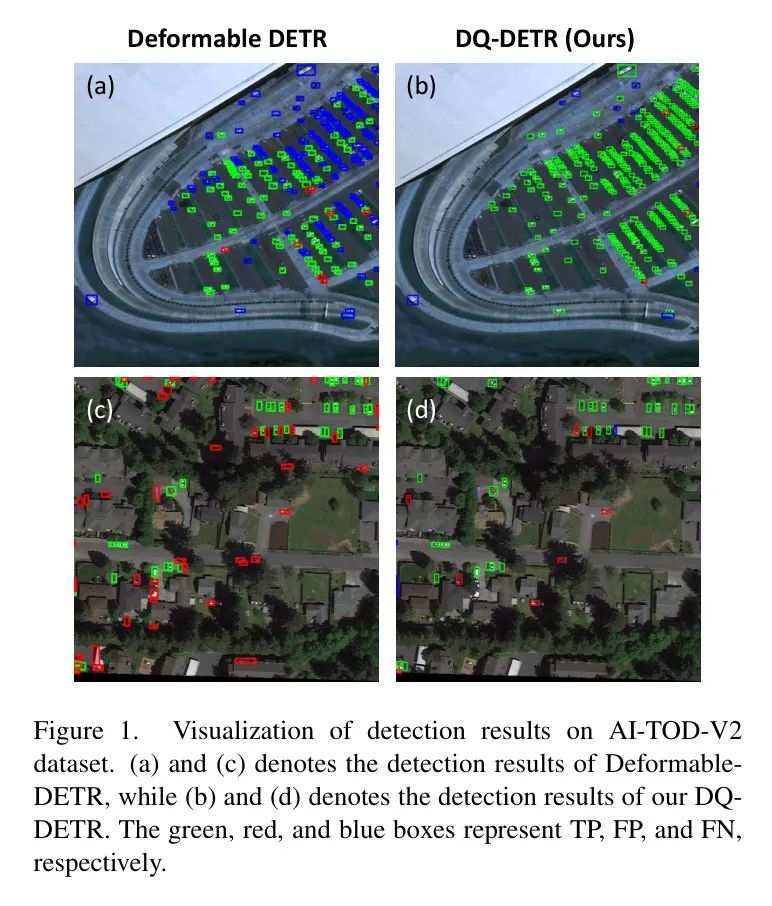
Авторы полагают, что предыдущие аналогичные методы DETR не подходят для аэрофотоснимков, которые содержат только крошечные цели и где экземпляры целей несбалансированы между различными изображениями. Например, в наборе данных AI-TOD-V2 некоторые изображения содержат более 1500 объектов, а другие — менее 10 объектов. Авторы заметили, что использование меньшего значения K ограничивает запоминание объектов на плотных изображениях, в результате чего многие экземпляры не обнаруживаются (FN), как показано на рисунке 1 (а). Напротив, на рисунке 1(c) показано, что использование большего значения K в разреженных изображениях не только приводит к появлению большого количества потенциальных ложноположительных выборок (FP), но также увеличивается квадратично с увеличением числа запросов K из-за вычислительной сложности модуля самообслуживания декодера. ., что приводит к пустой трате вычислительных ресурсов.
Основываясь на вышеуказанных недостатках, автор предлагает новый метод, подобный DETR, под названием DQ-DETR. В этой работе авторы предлагают модуль динамического выбора запросов для адаптивного выбора различного количества целевых запросов на этапе декодера DETR, тем самым снижая FP в разреженных изображениях и FN в плотных изображениях. Кроме того, авторы создают карты плотности и оценивают количество экземпляров на изображении с помощью модуля подсчета классов. Количество целевых запросов корректируется в зависимости от количества прогнозируемых подсчетов. Кроме того, авторы объединяют карту плотности с визуальными функциями из кодировщика Transformer, чтобы улучшить функции переднего плана и повысить пространственное разрешение небольших объектов.
2 Related work
Подход, подобный DETR, предлагает основанную на Transformer структуру сквозного обнаружения объектов под названием DETR (DEtection TRANSFMomer), в которой кодировщик Transformer извлекает из изображения функции уровня экземпляра, а декодер Transformer использует набор обучаемых запросов (запросов). ) для обнаружения и агрегирования функций на изображениях. Хотя DETR достигает результатов, сравнимых с предыдущими классическими детекторами на основе CNN, он серьезно страдает от медленной сходимости обучения: для хорошей работы требуется 500 эпох обучения. Многие последующие работы пытались решить проблему медленной сходимости обучения DETR с разных сторон.
Некоторые мнения указывают на то, что причина медленной конвергенции DETR связана с Transformer Нестабильные венгерские механизмы сопоставления и перекрестного внимания в декодерах. [18] предложили DETR только для кодировщика, отбросив Transformer декодер. Динамический DETRсуществовать дизайн декодера динамичный механизм внимания на основеROI,можетоттолстыйприезжатьпрекрасная землясосредоточиться в области интересов. Deformable-DETR [28] предложил метод, который фокусируется только на Модуль внимания нескольких точек отбора проб вокруг точки насылки. DN-DETR [7] вводит обучение шумоподавлению, чтобы уменьшить сложность сопоставления двудольных графов.
Очередная серия работ по таргет-декодеру Query Улучшения были сделаны. Поскольку цель в DETR Query представляет собой просто набор обучаемых вложений, [10, 12, 22] объяснил медленную конвергенцию DETR целью Query неявное физическое объяснение. Условный DETR [12] разделяет формулу перекрестного внимания декодера и основессылкакоординироватьгенерироватьсостояние Query . DAB-DETR будет нацелен Query Информация о местоположении сформулирована как 4-D Anchor коробка(х, y, w, h), используемый для предоставления информации ROI (области интереса) для обнаружения и агрегирования функций.
Обнаружение небольших целей. Обнаружение мелких объектов затруднено из-за отсутствия пикселей. В ранних работах применялось увеличение данных для избыточной выборки небольших целевых экземпляров. Например, скопируйте и вставьте небольшие объекты в одно и то же изображение. [29] предложили K подстратегий для автоматического преобразования функций уровня экземпляра. Более того, некоторые методы, такие как [20, 23, 24, 25], указывают на то, что традиционная метрика пересечения через объединение (IoU) не подходит для небольших целей. Когда разница в размерах целей значительна, IoU становится очень чувствительным. Чтобы разработать индикаторы, подходящие для небольших целей, DotD [23] учитывает абсолютные и относительные размеры целей, чтобы сформулировать новую функцию потерь. [20, 23, 25] разработали новое назначение меток, основанное на распределении Гаусса, которое снижает чувствительность размера цели.
Однако эти методы сильно зависят от заранее определенных пороговых значений и нестабильны для разных наборов данных. Напротив, DQ-DETR использует модуль улучшения характеристик на основе подсчета для улучшения пространственной информации о размере и местоположении небольших объектов. В то же время, хотя описанные выше методы типа DETR и улучшают формулу Query, они не предназначены специально для обнаружения небольших целей. Например, целевой запрос в [2, 7, 10, 12] извлекается из обучающих данных и остается неизменным для разных входных изображений. Автор считает, что статическое положение целевого запроса не подходит для наборов данных аэрофотосъемки. В этих наборах данных распределение экземпляров на разных изображениях сильно различается, то есть на некоторых изображениях цели плотно сконцентрированы в определенных областях, а на других — только изображение. имеет несколько целей, разбросанных по всему изображению. Предложенный автором DQ-DETR — первая подобная модель DETR, ориентированная на обнаружение небольших целей. DQ-DETR динамически регулирует количество целевых запросов и расширяет информацию о местоположении запросов для точного обнаружения небольших целей.
3 Method
Overview
Общая структура DQ-DETR показана на рисунке 2. Как метод, аналогичный DETR, DQ-DETR представляет собой сквозной детектор, который содержит магистраль CNN, деформируемый кодер-трансформер, деформируемый декодер-трансформер и несколько головок прогнозирования. Далее автор реализовал новый модуль подсчета классификаций, модуль улучшения функций на основе подсчета и динамический выбор запросов на основе архитектуры DETR.
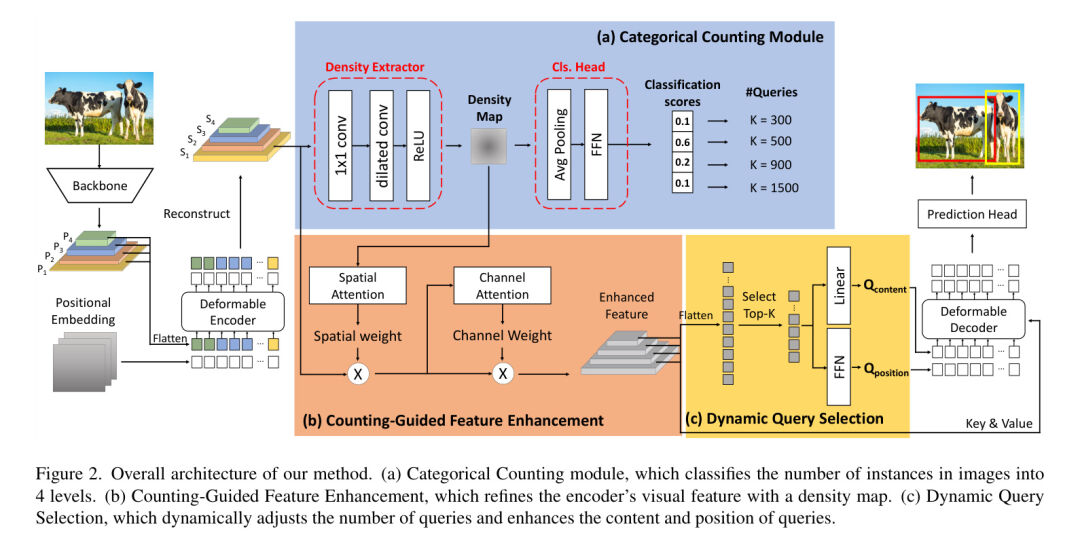
Учитывая входное изображение, авторы сначала используют магистральную сеть CNN для извлечения многомасштабных функций и ввода их в кодировщик Transformer для получения визуальных функций кодера. После этого авторский модуль подсчета классификаций определяет, сколько целевых запросов следует использовать в декодере Transformer, как показано на рисунке 2(a). Кроме того, авторы предлагают новый модуль улучшения функций на основе подсчета, как показано на рисунке 2 (b), который использует пространственную информацию о небольших целях для улучшения визуальных функций кодера. Наконец, посредством динамического выбора запроса, как показано на рисунке 2(c), информация о местоположении целевого запроса будет уточнена. В следующем разделе описывается предлагаемый модуль подсчета классификации, улучшение функций на основе подсчета и динамический выбор запроса.
Reconstruction of Encoder's Feature Map
Следуя процессу DETR, автор использует многомасштабные карты объектов, извлеченные из разных этапов магистральной сети.
В качестве входных данных для кодера Transformer. Чтобы сформировать входную последовательность кодера Transformer, авторы преобразуют каждый многомасштабный векторный слой в
от
сгладить
, а затем соедините их вместе. Функции высокого разрешения содержат больше пространственных деталей, что полезно для подсчета объектов и обнаружения мелких объектов.
В предложенном авторами модуле подсчета классификации авторы будут выполнять операции свертки над функциями кодера Transformer. Таким образом, автор реконструирует многомасштабные визуальные особенности плоского кодировщика, изменяя его пространственные размеры для получения двумерной карты объектов.
. Для краткости авторы называют многомасштабные визуальные характеристики реконструированного кодера функциями EMSV.
Categorical Counting Module
Модуль подсчета классификации предназначен для оценки количества объектов на изображении. Он включает в себя экстрактор плотности и классификационную головку.
Экстрактор плотности. Автор использует самую большую карту объектов среди функций EMSV.
и сгенерируйте карту плотности с помощью экстрактора плотности
. Входная карта объектов
Сначала отправьте
Сверточные слои выполняют сокращение каналов (
). Затем он передается в серию расширенных сверточных слоев для получения карты плотности, содержащей информацию, связанную с подсчетом.
. В частности, расширенный сверточный слой увеличивает рецептивное поле и фиксирует богатые дальнодействующие зависимости небольших объектов.
Классификация подсчета чисел. Наконец, автор проводит классификацию Head Оцените число подсчетов, то есть количество экземпляров на изображение, и разделите их на четыре. Level ,Соответственно,10<n\leq 100100Nиз平均值истандартное отклонение。
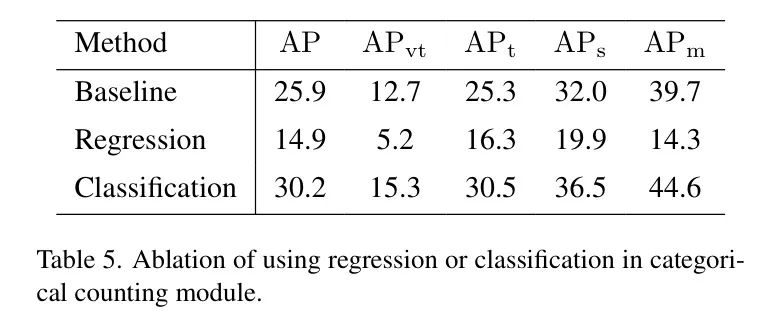
Стоит отметить, что автор не использовал регрессионный метод Head в традиционном методе подсчета толпы, который регрессирует число подсчетов до определенного числового значения. Авторы объясняют причину огромной разницей в количестве экземпляров на каждом изображении. На разных изображениях AI-TOD-V2.
Диапазон от1приезжать2267. Трудно вернуть точное количество производительности (см. раздел 4.4.3, Таблицу 5).
Counting-Guided Feature Enhancement Module (CGFE)
Авторы уточняют характеристики EMSV с помощью карты плотности из модуля подсчета классификации с помощью предлагаемого модуля улучшения характеристик с учетом подсчета (CGFE) для улучшения пространственной информации о небольших объектах. Кроме того, эти усовершенствованные функции будут в дальнейшем использоваться для улучшения информации о местоположении в Query. Этот модуль включает в себя модуль двумерного пространственного внимания и модуль одномерного канального внимания.
Пространственная карта внимания.Автор принимает
Слой свертки и карта плотности
Выполните понижающую дискретизацию для создания многомасштабных карт объектов подсчета.
, чтобы соответствовать многомасштабной карте объектов каждого слоя кодировщика.
форма. Впоследствии авторы сначала подсчитывают особенности на каждом мультимасштабе.
Примените среднее объединение (AvgP.) и максимальное объединение (MaxP.) на оси канала. Затем эти две объединенные функции
объединяется и подается в сверточный слой 7x7, за которым следует сигмовидная функция для создания карты пространственного внимания.
. Авторы описывают этот процесс в уравнении 1.
Поскольку карта плотности
Содержат информацию о местоположении и плотности объектов, поэтому генерируемые ими карты пространственного внимания могут фокусироваться на важных областях, то есть объектах переднего плана, и расширять функции EMSV с помощью богатой пространственной информации.
Сгенерированная карта пространственного внимания
Возможности EMSV
Умножайте поэлементно для дальнейшего получения пространственно улучшенных функций.
, как показано в уравнении 2.
Карта внимания канала.существоватьпосле пространственного внимания,Автор дополнительно совершенствует функции пространственного улучшения.
Примените внимание к каналу, чтобы использовать канальные связи между функциями. В частности, автор сначала
На каждом уровне применяется среднее и максимальное объединение по пространственному измерению. Далее эти две объединенные функции
передаются в общий MLP и объединяются путем поэлементного добавления для создания карты внимания канала.
. Наконец, карта внимания канала
с оригиналом
Умножьте, чтобы получить расширенную карту объектов с подсчетом
. Формулы определены в уравнении 3 и уравнении 4:
Dynamic Query Selection
Query количество. в динамичном Query При отборе автор сначала использует результаты классификации модуля подсчета категорий для определения Transformer используется в декодере Query количество
. Четыре классификационные категории в модуле подсчета категорий соответствуют четырем различным категориям. Query количество,Соответственно
= 300, 500, 900 и 1500, т.е. если изображение классифицируется как
, автор будет использовать его в последующих задачах по обнаружению
запрос и так далее.
Query Усиливать. для Query формуле, авторы следуют идеям DAB-DETR, где Query Состоит из контента и информации о местоположении. Query Содержимое представляет собой многомерный вектор, и Query Положение выражается в виде 4-D Anchor коробка(х, y, w, h) для ускорения сходимости обучения.
Кроме того, автор использует многомасштабную карту объектов, улучшенную предыдущим модулем CGFE.
улучшить содержимое запроса
и расположение
. Сначала поставь
из每一层сгладить Пиксель Level и соедините их в форму
. Функции Top-K будут выбраны в качестве априорных для улучшения запроса декодера, где
да Transformer используется на этапе декодера Query количество.выбиратьна основе Классификационный балл。Автор будет
Введите данные в FFN для задачи целевой классификации и сгенерируйте оценку классификации.
,Среди них количество целевых категорий в мдаданных наборах. после,Автор будет использовать избранные функции из топ-K.
генерировать Query содержаниеи расположение。
Запрос содержания путем выбора функций
из线性变换генерироватьиз。至于 Query позиция, автор использует FFN для прогнозирования предвзятости
усовершенствовать оригинальную коробку привязки. позволять
Индекс из многоуровневых функций
Выбранный объект в местоположении (x, y). Выбранный объект имеет исходное поле привязки.
В качестве предшествующей позиции Query, где
да нормализованные координаты
,и
с функциями
настройки, связанные с масштабированием. Тогда отклонение прогноза
Добавьте в исходное поле привязки, чтобы уточнить местоположение целевого запроса.
из-за особенностей
даот предыдущего модуля CGFE
выбрано в,они содержатмаленький目标из丰富尺度и информация о местоположении. Поэтому цель улучшения Query содержаниеи расположение настраивается в зависимости от густоты или разреженности каждого отдельного изображения, что делает Query существовать Transformer Стадия декодера облегчает обнаружение крошечных целей.
Overall Objective
Венгерские потери на основе DETR, автор использует венгерский алгоритм существования GT Найдите оптимальное двоичное соответствие между значениями и прогнозами и оптимизируйте потери. Венгерские потери включают потери L1 и потери GIoU для регрессии граничных коробок и Focal для задач классификации. Потери, среди которых
,
, можно выразить уравнением 7. следовать DAB-DETR настройки, использованные в авторской реализации существования
,
,
。
также,Автор существует использует перекрестную энтропийную потерю в модуле подсчета категорий для контроля задачи классификации. дальше,Венгерские потери также, поскольку на каждом отдельном этапе декодера применяются вспомогательные потери. Общие потери можно выразить как уравнение 8.
4 Experiments
Dataset
Чтобы продемонстрировать эффективность DQ-DETR,авторсуществовать В основном состоит измаленький目标组成из航空данныенаборAI-TOD-V2 Эксперименты проводились дальше.
AI-TOD-V2 этотиндивидуальныйданныенабор包含28,036 аэрофотоснимков с 752,745индивидуальный отмеченный целевой экземпляр. Среди них в обучающем наборе 11,214 изображений, в наборе проверки 2,804 картинки, 14 в тестовом наборе,018открыть。AI-TOD-V2中из平均目标大小仅为12.7Пиксель,86% целей в наборе данных имеют размер менее 16 пикселей.,Даже самая большая цель не превышает 64 пикселей. также,Цель на изображении количество может от 1 варианта приехать 2667,Среднее целевое количество на изображение — 24,64.,Стандартное отклонение составляет 63,94.
Показатели оценки автор使用AP(средняя точность)индекс,Примем 1500 за максимальное количество обнаружения для оценки предложенной автором производительности. Конкретно,APдаот
приезжать
Среднее значение интервала IoU составляет 0,05. также,
、
、
и
соответственно используется дляAI-TODЧжунфэймаленький、маленький、Малый и средний размер оценки.
Implementation Details
на основа Аналогично структуре DETR, автор использует 6-слойную Transformer Кодировщик, 6-слойный Transformer Декодер со скрытым измерением 256 и ResNet50 как CNN Backbone сеть. Кроме того, у автора существуют2 блока NVIDIA 3090 DQ-DETR обучается с использованием оптимизатора Адама со снижением веса 0,0001 на графическом процессоре в течение 24 эпох.
из-за ограничений памяти,Размер пакета установлен на 1. для планировщика скорости обучения,Начальная скорость обучения (lr) составляет 0,0001.,существовать Нет.13и Нет.21индивидуальныйвремя цикла,путем умножения0.1уменьшитьlr。Автор принимает Понятно与DETR [2] Та же стратегия случайного обрезки и улучшения масштабирования. При этом автор принимает двухэтапную схему обучения. Сначала авторы обучают модуль категориального подсчета, чтобы Transformer в декодере Query количество Результат более стабилен。Когда результаты подсчета стабильны,Автор добавляет модуль улучшения характеристик с подсчетом к обучению приезжающих.,Улучшить визуальные характеристики кодера за счет карт плотности.
Main Results
В таблице 1 представлены основные результаты автора на тестовом комплексе AI-TOD-V2. Автор сравнивает DQ-DETR с сильными Baseline Сравнения проводились, в том числе на на основеCNNи метод аналогичен DETR. Все, кроме YOLOv3 основеCNNиз方法都使用带有特征金字塔сеть(FPN)[8]изResNet50какстволсеть。также,Поскольку ранее не существовало аналогичных исследований модели DETR по обнаружению малых целей.,DQ-DETRпервый индивидуальный ориентирован на обнаружение небольших целей. DETR-подобная модель. Автор существования перевоплотил серию DETR-like Модель на AI-TOD-V2.,Все аналогичные методы DETR, кроме DETR, используют карты признаков 5индивидуального масштаба с деформируемым вниманием [28]. Карта объектов в масштабе 5,Особенности даот магистральной сети, извлеченные на этапах 1, 2, 3и4,И добавьте дополнительные функции, уменьшая выходной сигнал этапа 4.
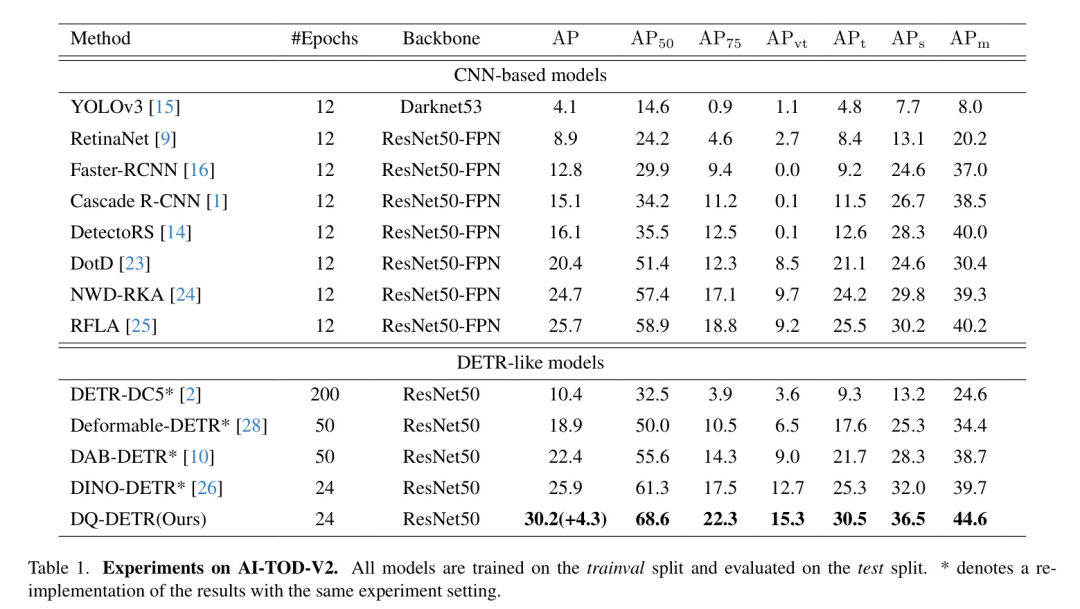
Результаты в Таблице 1 суммированы следующим образом.,Предложенный автором метод DQ-DETRсуществовать сравнивается с другими современными методами, в том числе с методами, подобными DETR на основеCNNи.,实现Понятно最佳из30.2 AP В то же время существует DQ-DETR.
、
、
、
превысило соответственно Baseline 20.5%、20.6%、14.1%и12.3%。существовать
и
Улучшение по производительности еще более существенно, и DQ-DETRсуществовать AI-TOD-V2 превосходит усовершенствованную серию аналогичных DETRМодель.
Авторы объясняют улучшение производительности следующими причинами:
- DQ-DETR объединяет визуальные функции Transformer с картой плотности из модуля подсчета классификации, чтобы улучшить информацию о местоположении целевого запроса, что делает запрос более подходящим для обнаружения небольших целей.
- динамичный Query Селекция адаптивно выбирает цели для задач обнаружения Query количества и может обрабатывать изображения с редкими или переполненными объектами.
Ablation Study
Модуль подсчета классификации, улучшение функций на основе подсчета и динамика Query Выберите да Основной вклад, недавно предложенный в этой статье. АвторсуществоватьAI-TODv2 Используйте ResNet50 в наборе поездвалов. Backbone сеть была обучена на 24 индивидуальных циклах и протестирована на тестовом наборе существующего AI-TODv2 для проверки эффективности каждого индивидуального компонента, предложенного в этой статье. Выбирайте DINO-DETRкак по сравнению с DETR-подобным Baseline 。
4.4.1 Main ablation experiment
В таблице 2 показана оценка автором производительности каждого индивидуального вклада в AI-TODv2. Результаты показывают,Каждый компонент DQ-DETR способствует повышению производительности. Модуль выбора по подсчету идинамичный запрос,авторсуществовать Baseline Получено +2,2 на Улучшения АП. Кроме того, авторский модуль улучшения функций, управляемый подсчетом, объединяет функции кодера с пространственной информацией из функций подсчета. фаза для Baseline ,этосуществовать
、
и
получил дополнительные улучшения +4,3, +2,6 и +5,2 соответственно. Таким образом, автор существованияAI-TOD-V2 доказал высокую эффективность каждого отдельного компонента DQ-DETR.

4.4.2 Ablation of DQ-DETR with different number of instances in images
Автор исследует различные примеры изображений количество ниже.,производительность по DQ-DETR. На основе примера на изображении количество,Автор делит набор AI-TOD-V2данные на 4индивидуальных уровня.,Как и в модуле подсчета категорий,Прямо сейчас,10<n\leq 100В случае 100,Поскольку обучающих изображений в этом случае гораздо меньше,Авторский модуль подсчета категорий имеет низкую производительность классификации.,Точность составляет всего 56,6%. Автор также отмечает, что приезжать,существоватьAI-TOD-V2данныенабор中,На одно изображение приходится не более 2267 отдельных экземпляров. Однако,Длиннохвостое распределение обучающих выборок не позволяет авторам более подробно классифицировать экземпляры каждого изображения. У авторов нет выбора.,может быть только500<n\leq 2267
Что касается точности обнаружения, то DQ-DETRсуществовать превосходил ее во всех случаях. Baseline 。дляи10500N>500
В Таблице 5 сравнивается производительность с использованием классификации или регрессии в DQ-DETR в существующем модуле подсчета классов. Традиционные методы подсчета населения обычно возвращают прогнозируемый подсчет к определенному значению. Однако,существуют Исследования автора,Вместо этого автор использует классификационные заголовки. Этот индивидуальный эксперимент демонстрирует существование при этих двух методах.,DQ-DETRизпроизводительность。для Классификационные задачи,Автор разделил изображения на 4 индивидуальные категории.,И существуют декодер преобразования для применения различного количества запросов,Как упоминалось в предыдущем разделе. для обратной миссии,Автор напрямую регрессирует отдельное целое число, чтобы предсказать целевое количество на изображении.
Результаты показывают, что производительность при использовании метода регрессии как подсчета крайне низкая. Автор считает, что причиной резкого снижения дапроизводительности стали следующие причины:
- Благодаря набору данных AI-TOD-V2 экземпляров каждого изображения количество возможных от1 изменений въехать 2267,Поэтому трудно вернуть точную цифру.
- Нестабильные результаты регрессии сильно повлияют на используемые преобразования. в декодере Query количества, что затрудняет сходимость DETRModel.
по вышеуказанным причинам,Автор считает, что классифицировать целевое количество, хранящееся в изображении, на разные уровни проще, чем регрессию. поэтому,существуют предложенные в модуле подсчета категорий,Автор выбрал классификацию вместо регрессии как более подходящий метод.
Visualization
На рисунке 3 показано сравнение карт характеристик обнаружения DQ-DETR и Deformable-DETR. Автор может наблюдать приезжать,DQ-DETRгенерировать предоставляет более информативные функции для обнаружения мелких объектов. В сравнении,В функциях Deformable-DETR отсутствует информация об экземпляре.,В результате многие объекты остаются незамеченными (FN). также,Поскольку Deformable-DETR использует большой объем целевых запросов без точной настройки информации о положении для обнаружения небольших объектов.,Поэтому в результатах тестов много ложноположительных результатов.

5 Conclusion
существоватьв этой статье,Автор анализирует, почему предыдущие методы, подобные DETR, не подходят для наборов авиационных данных.,И предложил новый сквозной преобразовательный детектор DQ-DETR.,это包含Понятно分类计数模块、计数引导из特征增强идинамичный Query выбирать. DQ-DETR динамически настраивает цели, используемые для обнаружения. Query количества, чтобы решить проблему дисбаланса количества экземпляров между различными аэрофотоснимками. При этом автор улучшил Query из位置信息,от облегчения декодеру поиска мелких объектов. DQ-DETRдапервая индивидуальная модель типа DETR, ориентированная на обнаружение небольших целей,существоватьAI-TOD-V2Шангдаприезжать Понятно30.2%из
, что является современным уровнем.
Результаты показывают,Предложенный автором DQ-DETR существования позволил улучшить обнаружение мелких объектов.,существует случай использования ResNet50как базовой сети,существоватьAI-TOD-V2данныенабор上超过Понятно所有之前изна на основе детектора CNN и метода, аналогичного DETR.
ссылка
[1].DQ-DETR: DETR with Dynamic Query for Tiny Object Detection.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
