Наиболее полное вводное введение в Pytorch. Просто прочитайте эту статью, чтобы начать работу с Pytorch.
В этой статье подробно и практично описано использование PyTorch, включая установку среды, базовые знания, тензорные операции, механизм автоматического вывода, создание нейронной сети, обработку данных, обучение модели, тестирование, а также сохранение и загрузку моделей.
1. Введение в Pytorch

В этой части мы кратко познакомим вас с Pytorch, включая его историю, преимущества и сценарии использования.
1.1 История Пайторча
PyTorch — это платформа глубокого обучения с открытым исходным кодом, разработанная исследовательской группой Facebook по искусственному интеллекту. После выпуска в 2016 году PyTorch быстро стал популярным среди научно-исследовательского сообщества благодаря простоте использования, гибкости и мощным функциям. Ниже мы подробно представим историю развития PyTorch.
В 2016 году исследовательская группа Facebook по искусственному интеллекту (FAIR) обнародовала PyTorch, целью которого является создание быстрой, гибкой и динамичной среды глубокого обучения. Философия дизайна PyTorch очень похожа на философию Python: читабельность и простота, а не неявная сложность. PyTorch написан на языке Python и является расширением Python, что упрощает его изучение и использование.
PyTorch принял несколько смелых решений в своем дизайне, самым важным из которых является выбор динамического вычислительного графа в качестве его ядра. Графы динамических вычислений фундаментально отличаются от графов статических вычислений в других средах (таких как TensorFlow и Theano) тем, что они позволяют нам изменять граф вычислений во время выполнения. Это делает PyTorch более гибким при работе со сложными моделями, а исследователям становится проще его понимать и отлаживать.
За годы, прошедшие с момента его выпуска, PyTorch быстро завоевал широкое признание в научно-исследовательском сообществе. В 2019 году PyTorch выпустил версию 1.0, в которой представлены некоторые важные новые функции, включая поддержку ONNX, новый распределенный пакет и интерфейсную поддержку C++. Эти функции делают PyTorch более широко используемым в промышленности, сохраняя при этом высокий импульс в области научных исследований.
За последние два года PyTorch стал одной из самых популярных платформ глубокого обучения в мире. Он имеет более 50 тысяч звезд на GitHub и используется в самых разных проектах, от новейших исследовательских работ до крупномасштабных промышленных приложений.
Подводя итог, можно сказать, что история разработки PyTorch — это история, полная инноваций и проблем. Она превратилась из научно-исследовательского проекта в одну из самых популярных сред глубокого обучения в мире. В будущем у нас есть основания полагать, что PyTorch продолжит играть важную роль в области глубокого обучения.
1.2 Преимущества Pytorch
PyTorch — не только одна из самых популярных сред глубокого обучения, но и одна из самых мощных. Он имеет множество уникальных преимуществ, благодаря которым он привлекает широкое внимание и используется как в научных кругах, так и в промышленности. Далее давайте подробно обсудим преимущества PyTorch.
1. График динамических расчетов
Одним из наиболее заметных преимуществ PyTorch является то, что он использует графы динамических вычислений (DCG), которые отличаются от графов статических вычислений, используемых TensorFlow и другими платформами. Динамические вычислительные графики позволяют изменять поведение графа во время выполнения. Это делает PyTorch очень гибким и имеет преимущества при работе с неопределенностью или сложностью, что делает его идеальным для исследований и создания прототипов.
2. Простота использования
PyTorch спроектирован так, чтобы его было легко понять и использовать. Интуитивно понятный дизайн API делает изучение и использование PyTorch очень приятным занятием. Кроме того, PyTorch очень популярен среди программистов Python благодаря своей глубокой интеграции с Python.
3. Легко отлаживать
Благодаря динамической и Pythonic природе PyTorch отладка программ PyTorch становится довольно простой. Вы можете использовать стандартные инструменты отладки Python, такие как PDB или PyCharm, для непосредственного просмотра результатов каждой операции и состояния промежуточных переменных.
4. Сильная поддержка сообщества
Сообщество PyTorch очень активно и поддерживает нас. На официальном форуме, GitHub, Stack Overflow и других платформах присутствует большое количество пользователей и разработчиков PyTorch, где вы можете найти множество ресурсов и помощи.
5. Обширные предварительно обученные модели
PyTorch предоставляет большое количество предварительно обученных моделей, включая, помимо прочего, ResNet, VGG, Inception, SqueezeNet, EfficientNet и т. д. Эти предварительно обученные модели помогут вам быстро приступить к новым проектам.
6. Эффективное использование графического процессора
PyTorch может очень эффективно использовать библиотеку NVIDIA CUDA для вычислений на графическом процессоре. В то же время он также поддерживает распределенные вычисления, позволяя обучать модели на нескольких графических процессорах или серверах.
Подводя итог, можно сказать, что PyTorch очень популярен в области глубокого обучения благодаря простоте использования, гибкости, богатому функционалу и сильной поддержке сообщества.
1.3 Сценарии использования Pytorch
Мощь и гибкость PyTorch позволяют ему играть важную роль во многих сценариях приложений глубокого обучения. Вот несколько типичных случаев использования PyTorch в различных приложениях:
1. Компьютерное зрение
Что касается компьютерного зрения, PyTorch предоставляет множество предварительно обученных моделей (таких как ResNet, VGG, Inception и т. д.) и инструментов (таких как TorchVision), которые можно использовать для таких задач, как классификация изображений, обнаружение объектов, семантическая сегментация и т. д. и создание изображений. Эти предварительно обученные модели и инструменты значительно упрощают процесс разработки приложений компьютерного зрения.
2. Обработка естественного языка
В области обработки естественного языка (НЛП) характеристики динамических вычислительных графов PyTorch делают его очень подходящим для обработки входных данных переменной длины, что очень важно для многих задач НЛП. В то же время PyTorch также предоставляет ряд инструментов НЛП и предварительно обученных моделей (таких как Transformer, BERT и т. д.), которые могут помочь нам решать такие задачи, как классификация текста, анализ настроений, распознавание именованных объектов, машинный перевод и т. д. и системы вопросов и ответов.
3. Генеративно-состязательная сеть
Генеративно-состязательные сети (GAN) — это мощные модели глубокого обучения, которые широко используются в таких задачах, как генерация изображений, преобразование изображений в изображения, передача стилей и улучшение данных. Гибкость PyTorch делает его идеальным для разработки и обучения моделей GAN.
4. Обучение с подкреплением
Обучение с подкреплением — это метод обучения, при котором агент учится выполнять задачу посредством взаимодействия с окружающей средой. Динамический график вычислений PyTorch и простой в использовании API делают его чрезвычайно эффективным при реализации алгоритмов обучения с подкреплением.
5. Анализ данных временных рядов
В задачах, связанных с данными временных рядов, таких как распознавание речи, прогнозирование временных рядов и т. д., граф динамических вычислений PyTorch обеспечивает удобство обработки данных последовательностей переменной длины. В то же время PyTorch предоставляет различные модели рекуррентных нейронных сетей, включая RNN, LSTM и GRU.
В целом PyTorch может играть важную роль во многих сценариях приложений глубокого обучения благодаря своим мощным функциям и чрезвычайно высокой гибкости. Независимо от того, исследуете ли вы новые модели глубокого обучения или разрабатываете практические приложения глубокого обучения, PyTorch может оказать мощную поддержку.
2. Основы Pytorch

Прежде чем мы начнем более подробно использовать PyTorch, давайте разберемся с некоторыми основными концепциями и операциями. В этой части будут рассмотрены основы PyTorch, включая тензорные операции, ускорение графического процессора и механизмы автоматического вывода.
2.1 Тензорные операции
Тензор — это самая базовая структура данных в PyTorch. Его можно представить как многомерный массив или матрицу. Тензор PyTorch и массив NumPy очень похожи, но тензор также может работать на графическом процессоре, а массив NumPy — только на процессоре. Ниже мы познакомим вас с некоторыми основными тензорными операциями.
Сначала нам нужно импортировать библиотеку PyTorch:
import torch
Затем мы можем создать новый тензор. Вот несколько способов создания тензоров:
# Создайте неинициализированную матрицу 5x3.
x = torch.empty(5, 3)
print(x)
# Создайте случайно инициализированную матрицу 5x3.
x = torch.rand(5, 3)
print(x)
# Создайте матрицу нулей 5х3 типа long.
x = torch.zeros(5, 3, dtype=torch.long)
print(x)
# Создать тензор непосредственно из данных
x = torch.tensor([5.5, 3])
print(x)
Мы также можем работать с существующими тензорами. Вот некоторые основные операции:
# Создайте тензор и установите require_grad=True для отслеживания истории вычислений.
x = torch.ones(2, 2, requires_grad=True)
print(x)
# Работать с тензором
y = x + 2
print(y)
# y — результат операции, поэтому он имеет атрибут grad_fn
print(y.grad_fn)
# выполнить больше операций над y
z = y * y * 3
out = z.mean()
print(z, out)
Результаты вышеописанных операций следующие:
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
<AddBackward0 object at 0x7f36c0a7f1d0>
tensor([[27., 27.],
[27., 27.]], grad_fn=<MulBackward0>) tensor(27., grad_fn=<MeanBackward0>)
В PyTorch,мы можем использовать.backward()метод расчета градиента。Например:
# Поскольку out содержит скаляр, out.backward() эквивалентен out.backward(torch.tensor(1.))
out.backward()
# Печать градиента d(out)/dx
print(x.grad)
Выше приведены основные операции тензора PyTorch. Мы видим, что работа тензора PyTorch очень проста и интуитивно понятна. В последующем обучении мы будем использовать больше тензорных операций, таких как индексирование, нарезка, математические операции, линейная алгебра, случайные числа и т. д.
2.2 ускорение графического процессора
При обучении глубокому обучению ускорение графического процессора (GPU) является очень важной частью. Возможности параллельных вычислений графического процессора делают его более выгодным, чем центральный процессор, в крупномасштабных матричных операциях. PyTorch предоставляет простой в использовании API, который позволяет нам легко переключать вычисления между процессором и графическим процессором.
первый,Нам нужно проверить, есть ли в системе доступный графический процессор. В PyTorch,мы можем использоватьtorch.cuda.is_available()приди и проверь:
import torch
# Проверьте, доступен ли графический процессор
if torch.cuda.is_available():
print("There is a GPU available.")
else:
print("There is no GPU available.")
Если есть доступный графический процессор, мы можем использовать.to()метод будетtensorпереехать вGPUначальство:
# Создать тензор
x = torch.tensor([1.0, 2.0])
# Переместить тензор в графический процессор
if torch.cuda.is_available():
x = x.to('cuda')
Мы также можем указать устройство непосредственно при создании тензора:
# Создать тензор непосредственно на графическом процессоре
if torch.cuda.is_available():
x = torch.tensor([1.0, 2.0], device='cuda')
При обучении модели мы обычно перемещаем и модель, и данные в графический процессор:
# Создайте простую модель
model = torch.nn.Linear(10, 1)
# создать некоторые данные
data = torch.randn(100, 10)
# Данные и модель перемещены в графический процессор.
if torch.cuda.is_available():
model = model.to('cuda')
data = data.to('cuda')
Выше приведены основные операции по ускорению графического процессора в PyTorch. Использование ускорения графического процессора может значительно повысить скорость обучения моделей глубокого обучения. Однако следует отметить, что передача данных между CPU и GPU будет занимать определенное количество времени, поэтому нам следует постараться максимально сократить количество передач данных.
2.3 Автоматический вывод
При глубоком обучении нам часто необходимо выполнить оптимизацию градиентного спуска. Для этого нам необходимо вычислить градиент, который является производной функции. В PyTorch мы можем использовать механизм автоматического деривирования (autograd) для автоматического расчета градиентов.
В PyTorch,мы можем установитьtensor.requires_grad=TrueПриходитьотслеживать этоначальствоиз Местоиметьдействовать。После завершения расчета,мы можем позвонить.backward()метод,PyTorchГрадиенты автоматически рассчитываются и сохраняются.。Этот градиент можно передать.gradсвойства для доступа。
Вот простой пример:
import torch
# Создать тензор и установите require_grad=True для отслеживания истории вычислений
x = torch.ones(2, 2, requires_grad=True)
# Выполните операцию над этим тензором:
y = x + 2
# y — результат вычисления, поэтому он имеет атрибут grad_fn
print(y.grad_fn)
# сделать больше операций над y
z = y * y * 3
out = z.mean()
print(z, out)
# Используйте .backward() для выполнения обратного распространения ошибки и расчета градиентов.
out.backward()
# Выходной градиент d(out)/dx
print(x.grad)
В приведенном выше примере,out.backward()Эквивалентноout.backward(torch.tensor(1.))。еслиoutне скаляр,Потому что тензор — это матрица,Потом звоню.backward()Когда вам нужно пройтиoutУмножение весовых векторов одной и той же формы。
Например:
x = torch.randn(3, requires_grad=True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y)
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(v)
print(x.grad)
Вышеуказанное является основным методом использования автоматического вывода в PyTorch. Автоматический вывод — одна из важных функций PyTorch, обеспечивающая удобство обучения моделей глубокого обучения.
3. Нейронная сеть PyTorch
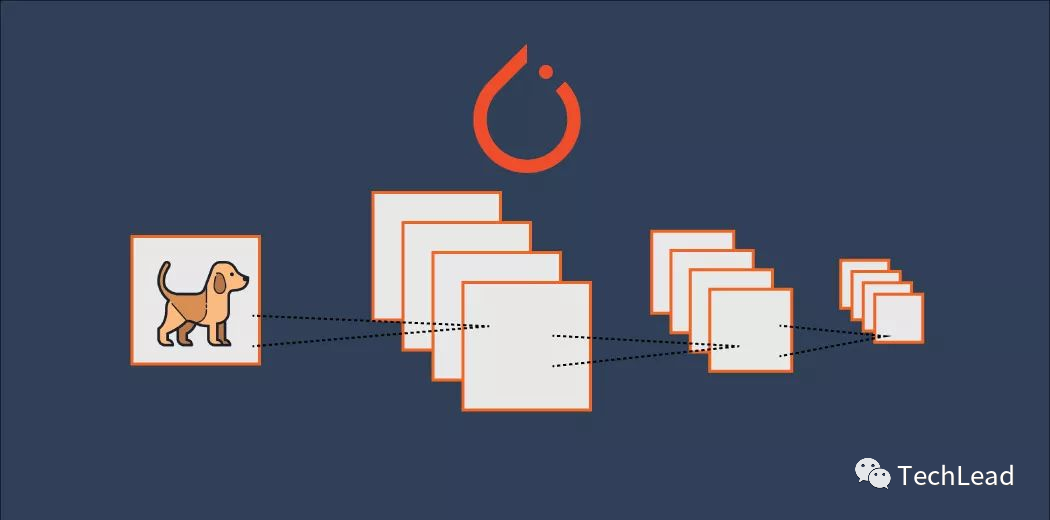
После освоения базового использования PyTorch мы рассмотрим некоторые более продвинутые функции и способы их использования. Эти расширенные функции включают построение нейронной сети, загрузку данных, сохранение и загрузку модели и многое другое.
3.1 Построение нейронной сети
PyTorchпредоставилtorch.nnБиблиотека,он используется для построениянейронная сетьизинструмент Библиотека。torch.nnБиблиотеказависит отautogradБиблиотека Приходитьопределениеи Рассчитать градиент。nn.ModuleСодержитнейронная сетьслой и вернуть выводforward(input)метод。
Ниже приведен пример построения простой нейронной сети:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# Входной канал изображения: 1, выходной канал: 6, ядро свертки 5x5
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# Полностью связный слой
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Максимальное объединение в пул с использованием окна 2x2
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# Если окно квадратное, необходимо указать только один размер.
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # Получить измерения, отличные от размеров партии
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
Вот и все Простая нейронная сетьиз Строитьметод。наспервыйопределяетNetдобрый,этотиндивидуальныйдобрый Унаследовано отnn.Module。затем в__init__методсерединаопределение了сетьструктура,существоватьforwardметодсерединаопределение了данныепоток。существоватьсетьв процессе строительства,мы можем использоватьлюбойtensorдействовать。
Следует отметить, что,backwardфункция(используется для расчета градиента)будетautogradАвтоматическое создание и внедрение。ты тольконуждатьсясуществоватьnn.Moduleизребенокдобрыйсерединаопределениеforwardфункция。
В создании хорошей нейронной сетьназад,мы можем использоватьnet.parameters()метод Приходитьвозвращатьсясеть Изучаемые параметры。
3.2 Загрузка и обработка данных
в проектах глубокого обучения,В дополнение к дизайну модели,данныеизнагрузкаи обработка Это также очень важноизчасть。PyTorchпредоставилtorch.utils.data.DataLoaderдобрый,может помочьнасвыполнять удобноданныеизнагрузкаи обработка。
3.2.1 Знакомство с DataLoader
DataLoaderдобрыйпредусмотреноданныенаборизпараллельныйнагрузка,Может эффективно загружать большие объемы данных,И предоставляет различные методы выборки данных. Обычно используемые параметры:
- dataset:нагрузкаизданныенабор(Datasetобъект)
- пакет_размер: размер пакета
- shuffle: следует ли перемешивать данные каждой эпохи
- num_workers: количество процессов, загруженных с использованием многопроцессного режима, 0 означает отсутствие использования многопроцессного режима.
Вот простой пример использования:
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
# данные Конвертировать
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# Загрузите и загрузите обучающий набор
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
# Загрузите и загрузите набор тестов
testset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)
3.2.2 Пользовательские наборы данных
Кромеиспользоватьвстроенныйизданныенабор,нас ХОРОШОПользовательский набор данных。Пользовательский набор данных Нужно наследоватьDatasetдобрый,и реализовать__len__и__getitem__дваиндивидуальныйметод。
Вот простой пример пользовательского набора данных:
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self, x_tensor, y_tensor):
self.x = x_tensor
self.y = y_tensor
def __getitem__(self, index):
return (self.x[index], self.y[index])
def __len__(self):
return len(self.x)
x = torch.arange(10)
y = torch.arange(10) + 1
my_dataset = MyDataset(x, y)
loader = DataLoader(my_dataset, batch_size=4, shuffle=True, num_workers=0)
for x, y in loader:
print("x:", x, "y:", y)
В этом примере,Мы создали простой набор данных,Включать10индивидуальныйданные。РанназаднасиспользоватьDataLoaderнагрузкаданные,И установите размер пакета и параметры перемешивания.
Выше приведены основные методы загрузки и обработки данных в PyTorch. С помощью этих методов мы можем легко загружать и обрабатывать данные.
3.3 Сохранение и загрузка моделей
В процессе обучения моделей глубокого обучения нам часто необходимо сохранить параметры модели для будущей перезагрузки. Это очень полезно для возобновления прерванного процесса обучения или для совместного использования и развертывания моделей.
PyTorch предоставляет простой API для Сохранения. и загрузка моделей。наиболее распространенныйизметоддаиспользоватьtorch.saveПриходитьдержать Модельизпараметр,Ранназадпроходитьtorch.loadПриходитьнагрузка Модельизпараметр。
3.3.1 Сохранение и загрузка параметров модели
Вот простой пример:
# держать
torch.save(model.state_dict(), PATH)
# нагрузка
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()
существоватьдержать Модельпараметр,насв целомиспользовать.state_dict()метод Приходитьполучать Модельизпараметр。.state_dict()да一индивидуальныйотпараметрсопоставление именприезжатьпараметрценитьизсловарьобъект。
существоватьнагрузка Модельпараметр,Сначала нам нужно создать экземпляр Модели, которая имеет ту же структуру, что и исходная Модель.,Ранназадиспользовать.load_state_dict()методнагрузкапараметр。
пожалуйста, обрати внимание,load_state_dict()функцияпринять одининдивидуальныйсловарьобъект,Вместоэто сохранитьобъектизпуть。этот意味着существовать Вы проходитеload_state_dict()функция До,Вам нужно десериализовать вашиздержатьизstate_dict。
существоватьнагрузка Модельназад,насв целом调用.eval()метод будетdropoutиbatch Уровень нормализации установлен в режим оценки. В противном случае они остаются в режиме обучения и в режиме оценки.
3.3.2 Сохранение и загрузка всей модели
Помимо сохранения параметров модели, мы также можем сохранить всю модель.
# держать
torch.save(model, PATH)
# нагрузка
model = torch.load(PATH)
model.eval()
При сохранении всей модели структура и параметры модели сохраняются вместе. Это означает, что нам больше не нужно вручную создавать экземпляры модели при загрузке модели. Однако этот подход требует больше дискового пространства и в некоторых случаях может привести к загромождению кода, поэтому его не всегда рекомендуется использовать.
Вышеуказанное является основным методом сохранения и загрузки моделей в PyTorch. Правильное сохранение и загрузка моделей может помочь нам лучше обучить и оценить модель.
4. Ускорение PyTorch GPT

Освоив базовое и расширенное использование PyTorch, мы теперь рассмотрим некоторые продвинутые методы PyTorch, которые помогут нам лучше понять и использовать эту мощную среду глубокого обучения.
4.1 Использование ускорения графического процессора
PyTorch поддерживает использование графических процессоров для вычислений, что может значительно увеличить скорость обучения и вывода. Суть использования графического процессора для вычислений заключается в передаче тензора и модели на графический процессор.
4.1.1 Определите, поддерживается ли графический процессор
первый,наснуждаться Определить токиз环境да否支持GPU。Это можно сделать черезtorch.cuda.is_available()Приходитьвыполнить:
print(torch.cuda.is_available()) # Вывод: правда или False
4.1.2 Передача тензоров между процессором и графическим процессором
Если графический процессор поддерживается, мы можем использовать.to(device)или.cuda()метод Переместить тензор на графический процессор。такой же,Мы также можем использовать.cpu()метод Переместить тензор в процессор:
# Определите, поддерживается ли CUDA
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Создать тензор
x = torch.rand(3, 3)
# Переместить тензор на графический процессор
x_gpu = x.to(device)
# или ВОЗ
x_gpu = x.cuda()
# Переместить тензор в процессор
x_cpu = x_gpu.cpu()
4.1.3 Перенос модели в графический процессор
Аналогичным образом мы также можем перенести модель на графический процессор:
model = Model()
model.to(device)
Когда модель находится на графическом процессоре, нам необходимо убедиться, что входной тензор также находится на графическом процессоре, иначе будет сообщено об ошибке.
Обратите внимание, что после передачи модели в графический процессор все параметры и буферы модели будут переданы в графический процессор.
Вышеуказанное является основным методом использования графического процессора для вычислений. Рационально используя графический процессор, мы можем значительно улучшить скорость обучения и вывода модели.
4.2. Использование torchvision для манипулирования изображениями
torchvision — это пакет, независимый от PyTorch, который предоставляет большое количество наборов данных изображений, инструментов обработки изображений, предварительно обученных моделей и т. д.
4.2.1 torchvision.datasets
Модуль torchvision.datasets предоставляет различные общедоступные наборы данных, такие как CIFAR10, MNIST, ImageNet и т. д., которые мы можем очень удобно загружать и использовать. Например, следующий код показывает, как загрузить и загрузить набор данных CIFAR10:
from torchvision import datasets,transforms
# данные Конвертировать
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# Загрузите и загрузите обучающий набор
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
# Загрузите и загрузите набор тестов
testset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)
4.2.2 torchvision.transforms
Модуль torchvision.transforms предоставляет различные инструменты преобразования изображений, которые мы можем использовать для предварительной обработки изображений и улучшения данных. Например, в приведенном выше коде мы используем функцию Compose для объединения двух операций обработки изображений: ToTensor (преобразование изображения в тензор) и Normalize (нормализация изображения).
4.2.3 torchvision.models
Модуль torchvision.models предоставляет предварительно обученные модели, такие как ResNet, VGG, AlexNet и т. д. Мы можем легко загрузить эти модели и использовать их для трансферного обучения.
import torchvision.models as models
# нагрузкапредварительнотренироватьсяизresnet18Модель
resnet18 = models.resnet18(pretrained=True)
Вышеописанное представляет собой базовое использование torchvision. Оно предоставляет нам очень богатый набор инструментов, которые могут значительно повысить эффективность обработки данных изображений.
4.3 Визуализация с использованием TensorBoard
TensorBoard — это инструмент визуализации, который помогает нам лучше понимать, оптимизировать и отлаживать модели глубокого обучения. PyTorch обеспечивает поддержку TensorBoard. Мы можем легко использовать TensorBoard для мониторинга процесса обучения модели, сравнения производительности различных моделей, визуализации структуры модели и т. д.
4.3.1 Запуск TensorBoard
начать TensorBoard, нам нужно запустить в командной строке tensorboard --logdir=runs команда, среди которых runs это сохранить TensorBoard Каталог данных.
4.3.2 Запись данных
мы можем использовать torch.utils.tensorboard модуль для записи данных. Сначала нам нужно создать SummaryWriter Object, а затем записывать данные через методы этого объекта.
from torch.utils.tensorboard import SummaryWriter
# Создайте SummaryWriter объект
writer = SummaryWriter('runs/experiment1')
# использовать writer Приходить Запись данных
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
# закрытие writer
writer.close()
4.3.3 Структура визуальной модели
Мы также можем использовать TensorBoard для визуализации структуры модели.
# Добавить модель
writer.add_graph(model, images)
4.3.4 Визуализация многомерных данных
Мы также можем использовать функцию внедрения TensorBoard для визуализации многомерных данных, таких как функции изображения, встраивание слов и т. д.
# Добавить вставку
writer.add_embedding(features, metadata=class_labels, label_img=images)
Выше приведено базовое использование TensorBoard. Используя TensorBoard, мы можем лучше понимать и оптимизировать наши модели.
5. Практический пример PyTorch
В этой части мы подробно представим, как использовать PyTorch для разработки моделей глубокого обучения на практическом примере. Мы будем использовать набор данных CIFAR10 для обучения сверточной нейронной сети (CNN).
5.1 Загрузка и предварительная обработка данных
Во-первых, нам нужно загрузить данные и предварительно их обработать. Мы будем использовать пакет torchvision для загрузки набора данных CIFAR10 и модуль преобразований для предварительной обработки данных.
import torch
from torchvision import datasets, transforms
# Определение операций предварительной обработки данных
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # Улучшение данных: случайное переворачивание изображений.
transforms.RandomCrop(32, padding=4), # улучшение данных: случайное кадрирование изображений
transforms.ToTensor(), # ВоляPIL.Imageили ВОЗnumpy.ndarrayданныедобрыйпреобразован вtorch.FloadTensor,и нормализовано до[0.0, 1.0]
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) # Стандартизация (среднее значение и стандартное отклонение взяты из набора CIFAR10данные)
])
# Загрузите инагрузкатренироватьсяданныенабор
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2)
# Загрузите инагрузкатестданныенабор
testset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers=2)
В этом коде,Сначала мы определяем серию операций предварительной обработки данных.,Ранназадиспользоватьdatasets.CIFAR10ПриходитьскачатьCIFAR10данныенабор并进行предварительно处理,большинствоназадиспользоватьtorch.utils.data.DataLoaderПриходитьсоздаватьданныенагрузкаустройство,Это помогает нам получать данные пакетно во время обучения.
5.2 Определение сетевой модели
Далее мы определяем нашу модель сверточной нейронной сети. В этом случае мы будем использовать два сверточных слоя и два полносвязных слоя.
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # Количество входных каналов — 3, количество выходных каналов — 6, размер ядра свертки — 5.
self.pool = nn.MaxPool2d(2, 2) # Максимальный пул, размер ядра 2, шаг 2
self.conv2 = nn.Conv2d(6, 16, 5) # Количество входных каналов — 6, количество выходных каналов — 16, размер ядра свертки — 5.
self.fc1 = nn.Linear(16 * 5 * 5, 120) # Полностью связный слой,Входной размер 16*5*5,Выходной размер 120
self.fc2 = nn.Linear(120, 84) # Полностью связный слой,Введите размер 120,Выходные размеры84
self.fc3 = nn.Linear(84, 10) # Полностью связный слой,Входной размер 84,Выходные размеры10(CIFAR10иметь10добрый)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # Первый уровень свертки + функция активации ReLU + пул
x = self.pool(F.relu(self.conv2(x))) # Свертка второго уровня + функция активации ReLU + объединение в пул
x = x.view(-1, 16 * 5 * 5) # Сгладить карту объектов
x = F.relu(self.fc1(x)) # Первый уровень полностью подключен + функция активации ReLU
x = F.relu(self.fc2(x)) # Второй уровень полностью подключен + функция активации ReLU
x = self.fc3(x) # Полное подключение уровня 3
return x
# создаватьсеть
net = Net()
В этой сети Модель,насиспользоватьnn.ModuleПриходитьопределениенасизсеть Модель,затем в__init__методсерединаопределениесетьизслой,большинствоназадсуществоватьforwardметодсерединаопределениесетьизпрямое распространениепроцесс。
5.3 Определение функций потерь и оптимизаторов
Теперь, когда у нас есть данные и модель, следующим шагом будет определение функции потерь и оптимизатора. Функция потерь используется для измерения разницы между предсказаниями модели и реальными метками, а оптимизатор используется для оптимизации параметров модели для уменьшения потерь.
В этом случае мы будем использовать функцию перекрестной энтропийной потери и оптимизатор стохастического градиентного спуска (SGD).
import torch.optim as optim
# Определить функцию потерь
criterion = nn.CrossEntropyLoss()
# Определить оптимизатор
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
В этом коде,наспервыйиспользоватьnn.CrossEntropyLossПриходить Определить функцию потерь,Ранназадиспользоватьoptim.SGDПриходить Определить оптимизатор。наснуждаться Волясетьизпараметрперешёл на оптимизациюустройство,Затем установите скорость обучения и импульс.
5.4 Обучение сети
Как только все будет готово, приступаем к обучению сети. В процессе обучения мы сначала выполняем прямое распространение по сети, чтобы получить выходные данные, затем вычисляем потерю между выходными данными и реальной меткой, затем вычисляем градиент посредством обратного распространения и, наконец, используем оптимизатор для обновления параметров модели.
for epoch in range(2): # Тренируйтесь дважды на наборе данных
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# Получить входные данные
inputs, labels = data
# Градиент четкий
optimizer.zero_grad()
# прямое распространение
outputs = net(inputs)
# Рассчитать потери
loss = criterion(outputs, labels)
# Обратное распространение ошибки
loss.backward()
# Обновить параметры
optimizer.step()
# Распечатать статистику
running_loss += loss.item()
if i % 2000 == 1999: # Печатайте каждые 2000 партий.
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
В этом коде мы сначала выполняем два раунда обучения набора данных. В каждом раунде обучения мы проходим загрузчик данных, получаем пакет данных, затем выполняем прямое распространение по сети для получения выходных данных, вычисляем потери, выполняем обратное распространение и, наконец, обновляем параметры. Мы также распечатываем информацию о потерях после каждых 2000 пакетов, чтобы можно было понять процесс обучения.
5.5 Тестовая сеть
После завершения обучения нам необходимо протестировать производительность сети на тестовом наборе. Это позволяет нам понять, как модель работает с невидимыми данными, чтобы оценить ее возможности обобщения.
# нагрузка Некоторыйтесткартина
dataiter = iter(testloader)
images, labels = dataiter.next()
# Распечатать фотографии
imshow(torchvision.utils.make_grid(images))
# Показать настоящие этикетки
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
# Позвольте сети делать прогнозы
outputs = net(images)
# Прогнозируемая метка — это метка максимального выхода.
_, predicted = torch.max(outputs, 1)
# Показать прогнозируемые метки
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))
# На всем тестовом наборе Тестовая сеть
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
В этом коде мы сначала загружаем несколько тестовых изображений и распечатываем настоящие этикетки. Затем мы просим сеть сделать прогнозы по этим изображениям и распечатать предсказанные метки. Наконец, мы тестируем сеть на всем тестовом наборе и распечатываем точность сети на тестовом наборе.
5.6 Сохранение и загрузка моделей
После обучения сети и ее тестирования мы можем сохранить обученную модель для будущего использования или продолжить обучение.
# держать Модель
torch.save(net.state_dict(), './cifar_net.pth')
В этом коде,насиспользоватьtorch.saveфункция,Волятренироватьсяхорошийиз Модельпараметр(проходитьnet.state_dict()получать)держатьприезжатьдокументсередина。
когданаснуждатьсянагрузка Модельчас,первыйнуждаться Создайтеновыйиз Модель Пример,Ранназадиспользоватьload_state_dictметод будетпараметрнагрузкаприезжать Модельсередина。
# нагрузка Модель
net = Net() # Создать новый экземпляр сети
net.load_state_dict(torch.load('./cifar_net.pth')) # нагрузка Модельпараметр
Следует отметить, что,load_state_dictметоднагрузкаизда Модельизпараметр,А не сама Модель. поэтому,существоватьнагрузка Модельпараметр До,тынуждаться Первый Создайте Модель Пример,этотиндивидуальный Модельнуждатьсяидержатьиз Модель Инструментиметьтакой жеструктура。
6. Резюме
В этой статье подробно и практично описано использование PyTorch, включая установку среды, базовые знания, тензорные операции, механизм автоматического вывода, создание нейронной сети, обработку данных, обучение модели, тестирование, а также сохранение и загрузку моделей.
Мы использовали PyTorch для завершения полного процесса обучения нейронной сети от начала до конца и протестировали производительность сети на наборе данных CIFAR10. Попутно мы глубоко углубились в различные функции и инструменты, предлагаемые PyTorch.
Я надеюсь, что эта статья поможет вам изучить PyTorch. Читателям, которые хотят узнать больше о PyTorch, я рекомендую обратиться к официальной документации PyTorch и различным руководствам с открытым исходным кодом. Практика — лучший способ обучения, и только благодаря длительной практике и практике вы сможете по-настоящему овладеть PyTorch и глубоким обучением.
Спасибо за чтение, и я надеюсь, что вы будете идти все дальше и дальше по пути глубокого обучения!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
