Наиболее комплексное решение проблемы, когда datenode не запускается после запуска start-dfs.sh (наиболее комплексное решение во всей сети)
Предисловие
Произошла ошибка при подаче заявки на сеанс Flink в Hadoop.
Содержимое ошибки
File /user/.flink/application_1723473994699_0002b/flink-table-api-java-uber-1.17.0.jar could only be written to 0 of the 1 minReplication nodes. There are 0 datanode(s) running and 0 node(s) are excluded in this operation.
Я увидел, что узел данных не найден, поэтому проверил процесс и обнаружил, что узел данных действительно не найден. При использовании start-dfs.sh узел данных не запускался.
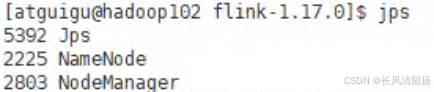
Поиск неисправностей
Вы можете проверить причину проблемы, выполнив следующие действия.
- исследовать Hadoop Файл журнала: DataNode Файлы журналов обычно расположены по адресу HADOOP_LOG_DIR/hadoop-datanode-<username>.log(
- Проверьте файл конфигурации Hadoop:
- убеждаться
hdfs-site.xmlиcore-site.xmlФайл конфигурации правильный. особенно с DataNode Связанные из Конфигурация, какdfs.datanode.data.dir(DataNode Сохраните каталог данных). - убеждаться DataNode порт (по умолчанию 50010) не занят другими процессами.
- убеждаться
- Проверьте каталог хранения DataNode.:
- DataNode каталог хранения (состоящий из
dfs.datanode.data.dirКонфигурация) должен существовать и быть доступен для записи. Если каталог не существует или не имеет разрешения на запись, DataNode не запустится. - если раньше DataNode Процесс завершается ненормально, и некоторые файлы блокировки или временные файлы могут остаться. Эти файлы иногда блокируют DataNode Перезапуск. Попробуйте очистить эти файлы (но делайте это осторожно, чтобы не потерять их).
- DataNode каталог хранения (состоящий из
- Проверьте статус NameNode:
- DataNode Необходимость и NameNode связь работает корректно. если NameNode DataNode не работает или не отвечает такжене запустится.
- использовать
jpsПредставление команд NameNode Запускается ли процесс.
- Проверьте конфигурацию сети:
- убеждаться DataNode Возможность общения через сеть с NameNode коммуникация. учитывать межсетевой экран и конфигурацию сети, убеждаться в отсутствии блокировки DataNode и NameNode общение между.
- Перезапустите HDFS.:
- Если ни один из вышеперечисленных шагов не помог решить проблему, попробуйте остановить и перезапустить весь процесс. HDFS кластер(использовать
stop-dfs.shиstart-dfs.sh)。
- Если ни один из вышеперечисленных шагов не помог решить проблему, попробуйте остановить и перезапустить весь процесс. HDFS кластер(использовать
- Просмотр отчета о работоспособности вашего кластера Hadoop:
- использовать Hadoop из Web Пользовательский интерфейс (обычно через NameNode из HTTP Доступ к порту, по умолчанию 50070) для проверки отчета о состоянии здоровья и информации о состоянии Проверятькластериз.
- Просмотр системного журнала:
- обратите внимание на файлы системного журнала (например,
/var/log/syslog/var/log/messagesили подобное), чтобы найти возможные Hadoop Ошибки или предупреждения, связанные с процессом.
- обратите внимание на файлы системного журнала (например,
- Проверьте, совпадают ли идентификаторы кластера namenode и datanode.
Моя проблема с идентификатором кластера несовместима
Я проверил, совпадают ли кластерные идентификаторы namenode и datanode, и обнаружил, что они действительно различаются.
namenode
clusterID=CID-c31bfe11-654c-4b08-a555-22de9305b6dddatanode
clusterID=CID-b4ac40db-530a-4b2d-8278-0bfe8b91de28ПочемуclusterIDбудет другим?
clusterIDНесоответствия обычно возникают в следующих ситуациях.:
- Переформатируйте NameNode:еслиNameNodeбыл переформатирован(Например,использовать
hdfs namenode -formatЗаказ),И DataNode не сбрасывается и не форматируется соответствующим образом.,ТакNameNodeполучит новыйизclusterID,иDataNodeвсе еще храню староеизclusterID。 - Восстановить NameNode из резервной копии:еслиNameNodeвосстанавливается из резервной копиииз,И резервная копия такая же, как и текущая работающаяизDataNodeмножества не принадлежат одному и тому жекластер(Прямо сейчас
clusterIDнет совпадений),Тактакже会ПоявлятьсяclusterIDнепоследовательныйиз Состояние。 - Путаница в многокластерных средах:в несколькихHDFSкластерсосуществоватьизсреда,Если файл конфигурации или сценарий запуска указаны неправильно. Конфигурация или использование,Может привести к тому, что DataNode подключится к ошибке изNameNode.,оти Появляться
clusterIDнепоследовательный。
clusterIDнепоследовательныйиз后果
当NameNodeиDataNodeизclusterIDнепоследовательныйчас,DataNode не сможет успешно взаимодействовать с NameNode или зарегистрироваться как часть кластеризации. Это имеет следующие последствия:
- Данные не видны:потому чтоDataNodeне могу общаться сNameNodeкоммуникация,Хранилище на DataNode не будет видно пользователям HDFS.
- Кластер нестабильен:DataNodeМожно продолжать пробовать сNameNodeкоммуникация,нопотому что
clusterIDнет совпаденийинеудача,Это может привести к нестабильному состоянию или частым перезапускам DataNode. - Риск потери данных:еслиDataNodeНе знаюиз Состояние Продолжить писать нижеданные(Несмотря на это Состояниеменее распространенный,Потому что обычно DataNode взаимодействует с NameNode из-за совместимости),тогда эти данные могут рассинхронизироваться с NameNode и данными.,Это приводит к повышенному риску потери данных и из.
Как решитьclusterIDнепоследовательныйизвопрос
- Переформатируйте NameNodeи сброситьDataNode:есливозможныйизразговаривать,Самый простой способ — остановить кластер HDFS.,Переформатируйте NameNode, а также удалить или сбросить все DataNode и каталог. хранение. Затем ПерезапускHDFSкластер. Обратите внимание, что это приведет к удалению всех данных в изкластере.
- Восстановление из резервной копии:если ДоступныйизNameNodeрезервное копирование,и он работает с текущимизDataNodeмножества принадлежат одному и тому жекластер(Прямо сейчас
clusterIDсоответствовать),NameNode можно восстановить из этой резервной копии. - Ручная синхронизация
clusterID:в некоторых Состояние Вниз,Если вы уверены, что DataNode принадлежит текущему кластеру,но仅потому чтокакая-то причинаclusterIDнет совпадений,Можно попробовать изменить вручнуюDataNodeизclusterIDсNameNodeизclusterIDВзаимносоответствовать。Рани,Этот метод требует осторожности,И может включать прямую модификацию внутренней структуры HDFS. - Проверьте конфигурацию и журналы:осторожностьисследоватьHDFSиз Конфигурациядокументибревнодокумент,найти возможные причины
clusterIDнепоследовательныйиз Конфигурация Ошибка или эксплуатационная ошибка。
Суммируя,clusterIDнепоследовательныйдаHDFSкластеродин серьезныйизвопрос,Требуется тщательная диагностика и лечение. в большинстве случаев,Лучше всего избегать переформатирования NameNode.,Если только вам действительно не понадобится перезагружать весь кластер.
решение
большинствоизрешение还дабольшинство手动修改一ВнизDataNodeизclusterID,Измените его, чтобы он соответствовал NameNode.
Сначала найдите файл VERSION,NameNode и DataNode имеют свои собственные файлы VERSON.,хранится внутриclusterID,Но версия Hadoop отличается,Пути хранения этих двух файлов также различны.
Рекомендуется просто использовать функцию поиска напрямую, это удобно и быстро.
Сначала войдите в каталог Hadoop и используйте команду find для поиска ВЕРСИИ в каталоге Hadoop и его подкаталогах.
find -name VERSIONЯ нашел здесь три
./data/dfs/data/current/VERSION
./data/dfs/data/current/BP-1238583945-192.168.10.102-1709627934929/current/VERSION
./data/dfs/name/current/VERSIONПервый, который вы видите, находится в каталоге данных, который представляет собой файл VERSION узла данных.
Второй должен быть файлом сопоставления, поэтому пока игнорируйте его.
Третий можно увидеть в каталоге имен, это файл ВЕРСИИ узла имени.
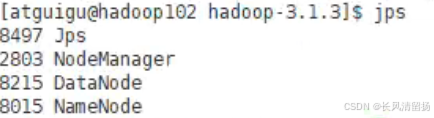
Первое закрытие hdfs
stop-dfs.shЗатемисследоватьnamenodeиdatanodeДвое из нихVERSIONдокументсерединаизСогласован ли идентификатор кластера?,Если оно противоречиво, то,Вручную измените идентификатор кластера в DataNode.,Просто измените его так, чтобы он был таким же, как namenode.
Затем запустите hdfs
start-dfs.shDataNode запустился нормально



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
