Начните работу с сканером Python за 5 минут: начните с нуля и легко овладейте навыками
Многие слышали о краулерах, и я не исключение. Я видел код сканера, написанный другими. Хотя я не изучал его глубоко, я считаю, что он очень мощный. Поэтому сегодня я решил начать с нуля и потратить всего 5 минут на изучение технологии сканирования начального уровня. В будущем я смогу просматривать весь интересующий контент веб-сайта всего одним щелчком мыши. рекламировать? Его не существует, потому что я его не вижу. Сканер получит только ту информацию, которая меня интересует, а ненужный контент для меня — это просто набор кода. Нас не волнует интерфейс веб-сайта. После сканирования данных мы сосредоточимся только на основном контенте.
В этом процессе на самом деле не так уж много сложного технического содержания. На самом деле это терпеливая и кропотливая работа. Именно поэтому так много людей предпочитают заниматься подработкой гусеничными работами, ведь хотя это и занимает много времени, технические требования не очень высоки. Научившись сегодня, вы не будете думать, что ползать так сложно, как я. Возможно, в будущем вам придется подумать о том, как сохранить сеанс или обойти проверку, поскольку чем сложнее сканировать веб-сайт, это означает, что другая сторона не хочет, чтобы его сканировали. На самом деле, эта часть является самой сложной. Если у нас будет возможность, мы сможем подробно обсудить ее в будущих исследованиях.
Сегодня мы на примере выбора рецептов решаем жизненную проблему «что есть», с которой мы сталкиваемся во время еды.
Краулерный анализ
Принцип работы сканера аналогичен моделированию работы пользователя при просмотре сайта: сначала заходите на официальный сайт, проверяете, есть ли ссылки, по которым нужно перейти, и если есть, продолжаете кликать для просмотра. Когда вы найдете нужное изображение или текст, вы можете скачать или скопировать его. Базовая архитектура этого сканера показана на рисунке. Надеюсь, это описание поможет вам лучше ее понять.
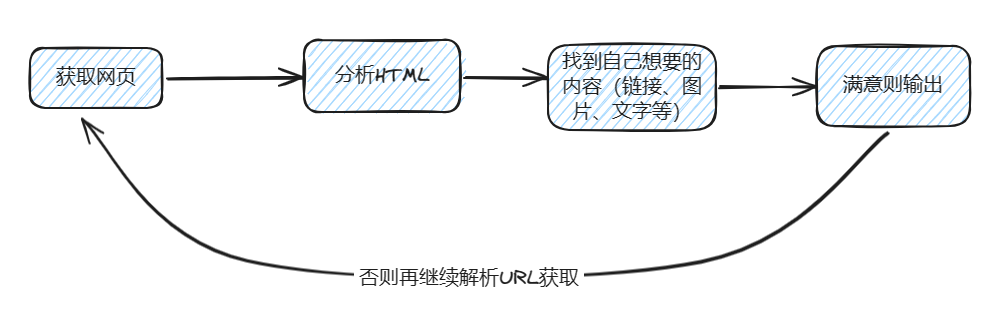
Сканировать HTML-страницу веб-страницы
При выполнении работы сканера мы обычно начинаем с первого шага — отправки HTTP-запроса для получения возвращаемых данных. В своей работе мы обычно запрашиваем ссылку для получения информации в формате JSON для бизнес-обработки. Однако сканеры работают немного по-другому, поскольку сначала нам нужно получить веб-контент, поэтому на этом этапе обычно возвращается HTML-страница. В Python существует множество библиотек запросов на выбор. Я привожу пример только для справки, но вы можете выбрать другие сторонние библиотеки в соответствии с реальными потребностями, если они могут выполнить задачу.
Прежде чем приступить к работе сканера, сначала необходимо установить необходимые зависимости сторонней библиотеки. Эта часть очень проста, просто установите соответствующие библиотеки по мере необходимости, сложных шагов не так уж и много.
Давайте пропустим ерунду и перейдем сразу к следующему примеру кода:
from urllib.request import urlopen,Request
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
req = Request("https://www.meishij.net/?from=space_block",headers=headers)
# Сделайте запрос и получите html
# Полученное содержимое HTML представляет собой байты и преобразуется в строку.
html = urlopen(req)
html_text = bytes.decode(html.read())
print(html_text)Обычно мы можем получить полное содержимое этой веб-страницы с рецептами, как и исходный код веб-страницы, когда нажимаем F12 в браузере.
элемент синтаксического анализа
Самый глупый способ — использовать синтаксический анализ строк, но поскольку в Python есть множество сторонних библиотек, которые могут решить эту проблему, мы можем использовать BeautifulSoup для анализа HTML. Мы не будем вводить другие методы анализа один за другим. Мы можем просто искать все, что нам нужно. Нет необходимости запоминать вещи, которые нам не нужно часто использовать.
Популярные рецепты
Давайте разберем и проанализируем рецепты в популярных запросах.
from urllib.request import urlopen,Request
from bs4 import BeautifulSoup as bf
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
req = Request("https://www.meishij.net/?from=space_block",headers=headers)
# Сделайте запрос и получите html
# Полученное содержимое HTML представляет собой байты и преобразуется в строку.
html = urlopen(req)
html_text = bytes.decode(html.read())
# print(html_text)
# Разбор HTML с помощью BeautifulSoup
obj = bf(html_text,'html.parser')
# print(html_text)
# Используйте функцию find_all, чтобы получить информацию обо всех изображениях.
index_hotlist = obj.find_all('a',class_='sancan_item')
# Распечатать информацию для каждого изображения отдельно
for ul in index_hotlist:
for li in ul.find_all('strong',class_='title'):
print(li.get_text())Основные шаги заключаются в том, чтобы сначала распечатать HTML-страницу, полученную на предыдущем шаге, затем путем визуального наблюдения определить, под каким элементом находится требуемый контент, а затем использовать BeautifulSoup для поиска элемента и извлечения необходимой информации. В моем случае я извлекал текстовое содержимое, поэтому все элементы списка li были успешно извлечены.
Случайный рис
В жизни на самом деле приготовление пищи — дело несложное. Трудность заключается в выборе того, что съесть. Таким образом, мы можем проанализировать и сохранить все рецепты в списке и позволить программе выбирать рецепты случайным образом. Это облегчает решение дилеммы о том, что есть при каждом приеме пищи.
При выборе блюда наугад можно использовать следующий пример кода:
from urllib.request import urlopen,Request
from bs4 import BeautifulSoup as bf
for i in range(3):
url = f"https://www.meishij.net/chufang/diy/jiangchangcaipu/?&page={i}"
html = urlopen(url)
# Полученное содержимое HTML представляет собой байты и преобразуется в строку.
html_text = bytes.decode(html.read())
# print(html_text)
obj = bf(html_text,'html.parser')
index_hotlist = obj.find_all('img')
for p in index_hotlist:
if p.get('alt'):
print(p.get('alt'))Здесь мы нашли новый адрес ссылки на этом веб-сайте. Я получил данные первых трех страниц и случайно выбрал их. Вы можете получить их все.
Учебник по рецептам
Фактически предыдущий шаг пройден, и теперь нам осталось только оформить заказ на вынос. Существует широкий выбор блюд на вынос, но они не подходят для такого семейного отца, как я, поэтому мне приходится готовить еду самостоятельно. Именно в этот момент учебные пособия становятся особенно важными.
Давайте продолжим более глубокий анализ содержания урока:
from urllib.request import urlopen,Request
import urllib,string
from bs4 import BeautifulSoup as bf
url = f"https://so.meishij.net/index.php?q=Тушеные свиные ребрышки"
url = urllib.parse.quote(url, safe=string.printable)
html = urlopen(url)
# Полученное содержимое HTML представляет собой байты и преобразуется в строку.
html_text = bytes.decode(html.read())
obj = bf(html_text,'html.parser')
index_hotlist = obj.find_all('a',class_='img')
# Распечатать информацию для каждого изображения отдельно
url = index_hotlist[0].get('href')
html = urlopen(url)
html_text = bytes.decode(html.read())
obj = bf(html_text,'html.parser')
index_hotlist = obj.find_all('div',class_='step_content')
for div in index_hotlist:
for p in div.find_all('p'):
print(p.get_text())Собери это
Упомянутый выше метод удовлетворил наши потребности, но многократное выполнение каждого шага вручную не является эффективным способом. Поэтому я инкапсулировал эти шаги в простое приложение. Это приложение использует консоль в качестве пользовательского интерфейса и не требует каких-либо сторонних библиотек. Давайте посмотрим на это приложение:
import subprocess
import sys
subprocess.check_call([sys.executable, "-m", "pip", "install", "readchar"])
subprocess.check_call([sys.executable, "-m", "pip", "install", "colorama"])
subprocess.check_call([sys.executable, "-m", "pip", "install", "termcolor"])
# Импортируйте функцию urlopen из библиотеки urllib.
from urllib.request import urlopen,Request
import urllib,string
# Импорт Красивый Суп
from bs4 import BeautifulSoup as bf
from random import choice,sample
from colorama import init
from os import system
from termcolor import colored
from readchar import readkey
FGS = ['green', 'yellow', 'blue', 'cyan', 'magenta', 'red']
print(colored('Ищем рецепты....',choice(FGS)))
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
req = Request("https://www.meishij.net/?from=space_block",headers=headers)
# Сделайте запрос и получите html
# Полученное содержимое HTML представляет собой байты и преобразуется в строку.
html = urlopen(req)
html_text = bytes.decode(html.read())
hot_list = []
all_food = []
food_page = 3
# '\n'.join(pos(y, OFFSET[1]) + ' '.join(color(i) for i in l)
def draw_menu(menu_list):
clear()
for idx,i in enumerate(menu_list):
print(colored(f'{idx}:{i}',choice(FGS)))
print(colored('8:выбрано случайно',choice(FGS)))
def draw_word(word_list):
clear()
for i in word_list:
print(colored(i,choice(FGS)))
def clear():
system("clear")
def hot_list_func() :
global html_text
# Разбор HTML с помощью BeautifulSoup
obj = bf(html_text,'html.parser')
# print(html_text)
# Используйте функцию find_all, чтобы получить информацию обо всех изображениях.
index_hotlist = obj.find_all('a',class_='sancan_item')
# Распечатать информацию для каждого изображения отдельно
for ul in index_hotlist:
for li in ul.find_all('strong',class_='title'):
hot_list.append(li.get_text())
# print(li.get_text())
def search_food_detail(food) :
print('Ищем подробные руководства, подождите около 30 секунд!')
url = f"https://so.meishij.net/index.php?q={food}"
# print(url)
url = urllib.parse.quote(url, safe=string.printable)
html = urlopen(url)
# Полученное содержимое HTML представляет собой байты и преобразуется в строку.
html_text = bytes.decode(html.read())
obj = bf(html_text,'html.parser')
index_hotlist = obj.find_all('a',class_='img')
# Распечатать информацию для каждого изображения отдельно
url = index_hotlist[0].get('href')
# print(url)
html = urlopen(url)
html_text = bytes.decode(html.read())
# print(html_text)
obj = bf(html_text,'html.parser')
random_color = choice(FGS)
print(colored(f"{food}Как это сделать: ",random_color))
index_hotlist = obj.find_all('div',class_='step_content')
# print(index_hotlist)
random_color = choice(FGS)
for div in index_hotlist:
for p in div.find_all('p'):
print(colored(p.get_text(),random_color))
def get_random_food():
global food_page
if not all_food :
for i in range(food_page):
url = f"https://www.meishij.net/chufang/diy/jiangchangcaipu/?&page={i}"
html = urlopen(url)
# Полученное содержимое HTML представляет собой байты и преобразуется в строку.
html_text = bytes.decode(html.read())
# print(html_text)
obj = bf(html_text,'html.parser')
index_hotlist = obj.find_all('img')
for p in index_hotlist:
if p.get('alt'):
all_food.append(p.get('alt'))
my_food = choice(all_food)
print(colored(f' случайно выбрано, ем сегодня: {my_food}',choice(FGS)))
return my_food
init() ## Вывод цветного текста из командной строки
hot_list_func()
print(colored('Поиск завершен!',choice(FGS)))
my_array = list(range(0, 9))
my_key = ['q','c','d','m']
my_key.extend(my_array)
print(colored('m: представляет сегодняшний рецепт',choice(FGS)))
print(colored('c: означает очистку консоли',choice(FGS)))
print(colored('d: означает Учебник по рецептам',choice(FGS)))
print(colored('q:Выход из рецепта',choice(FGS)))
print(colored('0~8: Выберите блюдо в рецепте',choice(FGS)))
while True:
while True:
move = readkey()
if move in my_key or (move.isdigit() and int(move) <= len(random_food)):
break
if move == 'q': ## Клавиатура «Q» — выход.
break
if move == 'c': ## Клавиатура «C» очищает консоль
clear()
if move == 'm':
random_food = sample(hot_list,8)
draw_menu(random_food)
if move.isdigit() and int(move) <= len(random_food):
if int(move) == 8:
my_food = get_random_food()
else:
my_food = random_food[int(move)]
print(my_food)
if move == 'd' and my_food : ## Клавиатура «D» предназначена для просмотра обучающих программ.
search_food_detail(my_food)
my_food = ''Создание простого небольшого сканера на самом деле несложно. Если не учитывать дополнительные этапы упаковки, это займет всего 5 минут. Это достаточно быстро, чтобы начать работу с технологией сканера. Начало сканирования данных веб-сайта на самом деле является кропотливой работой. Просто поищите соответствующую техническую информацию в Интернете и найдите подходящий метод. Если он работает, продолжайте использовать его, если нет, попробуйте другие методы.
Подвести итог
Цель этой статьи — помочь читателям о том, как на начальном этапе освоить гусеничную технологию. На начальном этапе освоить технологию сканирования несложно, но вы можете столкнуться с некоторыми трудностями в реальной работе. Например, некоторые веб-сайты не обеспечивают прямой доступ и требуют входа в систему или различных человеко-машинных проверок. Поэтому лучше всего начать с сканирования некоторых новостных и информационных веб-сайтов, поскольку это относительно легко. Веб-сайты, содержащие конфиденциальную информацию, такую как платежи пользователей, получить не так-то просто. Поэтому на начальном этапе рекомендуется не зацикливаться на выборе сложного сайта, а просто попробовать начать. Как только вы поймете основные принципы, вы сможете рассмотреть возможность добавления компонентов или использования сторонних библиотек для решения проблем, когда вы с ними сталкиваетесь.
В конечном итоге, я искренне надеюсь, что эта статья была вам полезна. Если вы находите контент интересным или полезным, пожалуйста, подпишитесь на него и поддержите, хе-хе.
[Tencent Cloud] Lighthouse помогает трансграничному бизнесу электронной коммерции выйти за границу
https://cloud.tencent.com/act/cps/redirect?
Преимущества продукта: Во-первых, он очень удобен для использования новичками, поскольку имеет удобный интерфейс, во-вторых, имеет встроенную панель-пагоду, что очень упрощает установку программного обеспечения; три основных поставщика облачных услуг, его цена самая конкурентоспособная, по крайней мере, когда я сравнивал цены, плюс это один из лучших вариантов для обучения использованию; Кроме того, он также поддерживает самостоятельное создание зеркальных снимков, что является преимуществом, которое нельзя игнорировать.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
