Начало работы с хранилищем и вычислениями Hadoop: распределенная система обработки файлов, реализующая статистику слов.
Начало работы с хранилищем и вычислениями Hadoop: распределенная система обработки файлов, реализующая статистику слов.
"Хорошая вещь"
Порекомендуйте здесьPythonМногопоточные статьи:Подробное объяснение многопоточности и многопроцессности Python: методы повышения производительности и Настоящий. бойкейс В статье перечислены две важные технологии многопоточности и многопроцессности Python соответственно. Итог Их преимущества и недостатки, а также их применимость к различным сценариям. С помощью примеров из статьи вы сможете более разумно выбирать различные технологии параллелизма.
введение
В современную цифровую эпоху объем данных стремительно растет, и традиционные технологии обработки и хранения данных уже не справляются с таким масштабом данных.
Предприятиям и исследовательским учреждениям срочно необходимо эффективное, масштабируемое и надежное решение для управления и анализа этих огромных объемов данных.
Hadoop, как среда распределенных вычислений, стала звездной технологией в области больших данных благодаря своим мощным возможностям хранения и обработки.
В этой статье будет проведен анализОфициальная документацияОбсуждатьHadoopхранилище、Принцип расчета,Спроектировать и реализовать систему распределенной обработки файлов.,Система способна обрабатывать большие файлы данных (подсчитывается количество слов).,и сохранить результаты обработки обратно в HDFS
HDFS-хранилище
Полное название HDFS — Распределенная файловая система Hadoop (Распределенная файловая система Hadoop), которая используется для реализации распределенного хранилища в сценариях с большими данными.
Целью его проектирования являетсяМультиузлы работают на дешевом оборудовании и обеспечивают доступ к данным с высокой пропускной способностью, а также предоставляют копии для избыточности данных, чтобы гарантировать надежность и доступность данных.
Архитектура
Архитектура HDFS обычно состоит из общих компонентов DataNode и NameNode:
- DataNode распределяется по каждому узлу кластера и отвечает за фактическое хранение и извлечение данных. При хранении данных используются блоки данных.
- NameNode отвечает за управление метаданными файловой системы, через него взаимодействуют клиенты и управляет узлами данных.
Архитектура HDFS показана ниже:
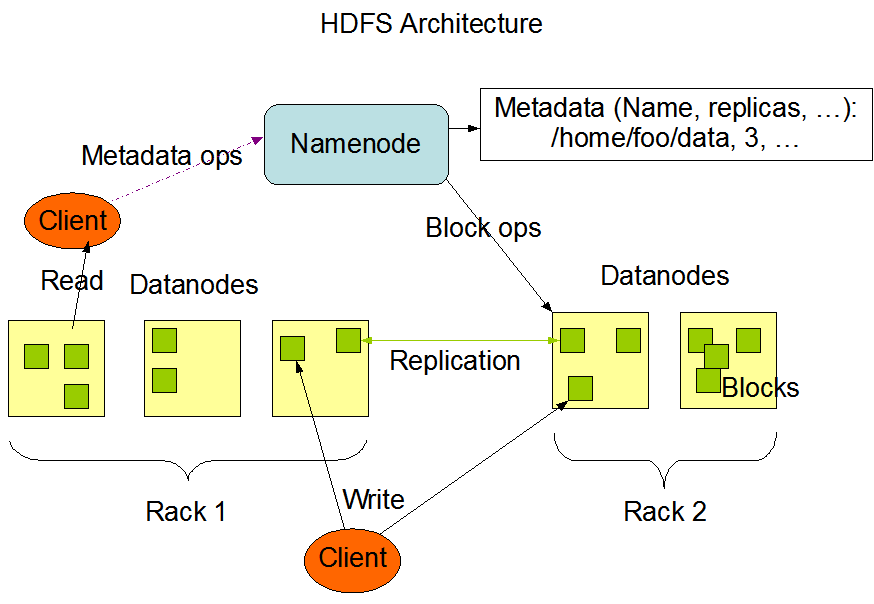
Большие экземпляры HDFS работают в компьютерных кластерах, которые обычно распределены по множеству стоек, при этом узлы данных распределены по разным стойкам.
Связь между двумя узлами в разных стойках должна осуществляться через коммутаторы. Пропускная способность синхронизации данных узлов между разными стойками обычно больше, чем синхронизация данных между одними и теми же стойками.
Другими словами, стоимость синхронизации данных между узлами в разных стойках будет выше.
копировать
Для достижения надежности и доступности,Используйте реплики блоков данных для обеспечения избыточности данных.,Сделайте копию копировать на другие узлы во время записи
Простой метод проектирования — равномерно распределить реплики по узлам в разных стойках (например, если вы настроите 3 реплики, они будут синхронизированы с 3 узлами в разных стойках).
Это предотвращает потерю данных в случае отказа всей стойки и позволяет использовать полосу пропускания нескольких стоек при чтении данных, но увеличивает стоимость операций записи, которые требуют передачи блоков на несколько стоек.
Оптимальная реализация HDFS не реализуется таким образом, в качестве примера взяты три реплики:
- Если (клиент) находится на узле данных, запишите его локально, в противном случае запишите его в произвольный узел данных в той же стойке.
- Один узел в другой (удаленной) стойке
- Другой узел в другой (удаленной) стойке со второй репликой
Это эквивалентно размещению одной копии в стойке рядом с клиентом, а вторая и третья копии размещаются на разных узлах в других стойках.
На примере изображения, приведенного в официальном документе, блоки с идентификаторами 1 и 3 устанавливаются по 2 копии, а блоки с идентификаторами 2, 4 и 5 устанавливаются по 3 копии.
В случае 2-х копий стойки делятся поровну, а в случае 3-х копий занята еще одна копия удаленного узла стойки (четыре узла слева и четыре узла справа можно рассматривать как две стойки)
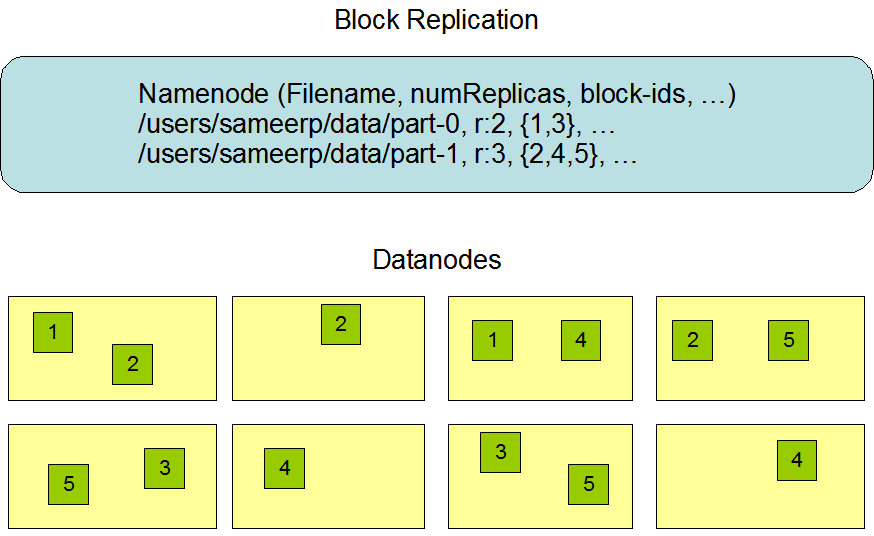
Такая стратегия,Реплики неравномерно распределены по разным стойкам.,Снижает накладные расходы на запись, не влияя на надежность данных. Их также можно читать через полосу пропускания нескольких стоек, но распределение неравномерно.(Две трети реплик в стойке、Треть реплик находится в другой стойке)
Исходный текст следующий:
when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode in the same rack as that of the writer, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack.
Расчет MapReduce
Вычислительная модель в Hadoop использует MapReduce.,Основная идея MapReduce аналогична принципу «разделяй и властвуй».,Разложить большую вычислительную задачу на несколько небольших задач, которые можно обрабатывать параллельно, и, наконец, суммировать результаты.
Модель MapReduce разделена на два этапа: Map и уменьшить, из которых сокращение разделено на перемешивание, сортировку и сокращение.
Запустить процесс
Загрузка файла в HDFS -> входить input <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> output выход -> Сохранять в HDFS
- Загрузка файла в HDFS
- входить Шардинг:Волявходить Разделить данные на несколько Шардинг,Каждый осколок будет назначен карте Задачи.
- Задачи карты:каждый Задачи картыпрочитать Шардингданные,Вызов функции Map для обработки данных,Генерация промежуточных пар ключ-значение
- Shuffle:Воля Задачи Промежуточные пары ключ-значение, сгенерированные картами, разбиваются по ключу и отправляются в соответствующее Сокращение. задач
- Sort:существовать Сокращение После получения промежуточных пар ключ-значение задача сортирует их по ключам.
- Сокращение задач:Получите набор промежуточных пар ключ-значение с одним и тем же ключом.,Вызовите функцию сокращения для обработки агрегирования.,Создайте окончательную выходную пару ключ-значение.
- выход:Сокращение задача записывает окончательную выходную пару ключ-значение в выходной файл в HDFS
Настоящий бой
На этапе «Настоящий бой» после настройки окружения демонстрация осуществляется через кейс подсчета слов на официальном сайте.
Настройка среды
Конкретный процесс, включая возможные подводные камни, можно посмотреть здесь.Создание Hadoop с нулястатьи
Вот краткое объяснение:
- Создать пользователя Hadoop
#Добавить пользователя
sudo useradd hadoop
#Установить пароль
sudo passwd hadoop
#Сменить пользователя
su hadoop- Настроить SSH
#Установить
yum install openssh
#Требуется проверка пароля
ssh localhost
#Выход после успешного входа в систему Начать настройку входа без пароля
exit
cd ~/.ssh
#генерировать ключ Введите несколько раз
ssh-keygen -t rsa
#Добавить в
cat ./id_rsa.pub >> ./authorized_keys
#Убедитесь, что у вас есть разрешение
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
# Для повторного входа пароль не требуется
ssh localhost- Конфигурация установки JDK
#Обновить индекс пакета
sudo yum update -y
#Установить JDK
sudo yum install java-1.8.0-openjdk-devel -y
#Находим каталог JDK JDK обычно находится в /usr/lib.
#/usr/lib/jvm
pwd
#Имя каталога слишком длинное и изменено на jdk8.
mv java-1.8.0-openjdk-1.8.0.432.b06-2.oc8.x86_64/ jdk8
#Настраиваем переменные среды Добавить переменные среды в конце
vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/jdk8
export PATH=$JAVA_HOME/bin:$PATH
#Переменные среды вступают в силу
source ~/.bashrc
#Просмотреть номер версии Определите, прошла ли установка успешно
java -version- скачатьHadoopРазархивировать
#декомпрессия
sudo tar -zxf hadoop-3.4.1.tar.gz
#Введите каталог
cd hadoop-3.4.1
#Просмотреть версию Если инструкции JDK не найдены Возникла проблема с настройкой переменных среды JDK.
./bin/hadoop version- Настройка переменных среды Hadoop
#Добавить в конец Мой каталог Hadoop:/home/lighthouse/hadoop-3.4.1.
vim ~/.bashrc
export HADOOP_HOME=/home/lighthouse/hadoop-3.4.1
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
#Здесь также есть переменные среды JAVA
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH- Настройка файлов данных и адресов hdfs
vim core-site.xml
<configuration>
<!-- временные файлы -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/lighthouse/hadoop-data/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<!--hdfsадрес-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>- Настройка конфигураций, связанных с хранилищем HDFS
vim hdfs-site.xml
<configuration>
<!-- количество копий -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- namenode Метаданные каталог хранения -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/lighthouse/hadoop-data/tmp/dfs/name</value>
</property>
<!-- datanode реальные данные каталог хранения -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/lighthouse/hadoop-data/tmp/dfs/data</value>
</property>
</configuration>- Настройка переменных среды jdk
vim hadoop-env.sh
exportJAVA_HOME=/usr/1ib/jvm/jdk8- Узел данных формата
hdfs namenode -format start-all.shВыполнить сценарий запуска
Просмотр веб-интерфейса NameNode, порт по умолчанию: 50070 (версия Hadoop 2.X), 9870 (версия Hadoop 3.X).
Написание кода MapReduce
Создайте проект maven и укажите зависимости, необходимые Hadoop:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.4.1</version>
</dependency>
</dependencies>Внедрить картограф
Реализация карты должна быть реализована org.apache.hadoop.mapreduce.Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
Его четыре обобщения представляют вход и выход ключа/значения.
/**
* Внедрить картограф<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
* map Преобразовать в <слово,1>
*
* @param key входитьKEY
* @param value входитьVALUE
* @param context
* @throws IOException
* @throws InterruptedException
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
//выход <слово,1> например <CaiCai,1> Указывает, что CaiCai появляется 1 раз.
context.write(word, one);
}
}
}Этот код будет использовать слово в тексте «входить» в качестве выходного ключа и степень 1 в качестве выходного значения. Прямо сейчас <CaiCai,1>
РеализоватьReduce
org.apache.hadoop.mapreduce.Reducerбывшийshuffleвстреча Волятакой жеkeyраз Преобразовать всобирать<CaiCai,<2,1,3>>,При реализации вам нужно только аккумулировать результаты и вывести результат.
/**
* РеализоватьReducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
//считаем раз
int sum = 0;
//После перемешивания Разделит тот же ключ например<CaiCai,2> <CaiCai,1> <CaiCai,3>существоватьперегородка
//значения — это набор времен <2,1,3> Появляется 2, 1 и 3 раза соответственно, в совокупности. сейчас Может for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
//После накопления времени выход <>
context.write(key, result);
}
}Полный код выглядит следующим образом:
package com.caicaijava.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* Посчитайте, сколько раз встречается слово
*/
public class WordCount {
/**
* Внедрить картограф<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
* map Преобразовать в <слово,1>
*
* @param key входитьKEY
* @param value входитьVALUE
* @param context
* @throws IOException
* @throws InterruptedException
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
//выход <слово,1> например <CaiCai,1> Указывает, что CaiCai появляется 1 раз.
context.write(word, one);
}
}
}
/**
* РеализоватьReducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
//считаем раз
int sum = 0;
//После перемешивания Разделит тот же ключ например<CaiCai,2> <CaiCai,1> <CaiCai,3>существоватьперегородка
//значения — это набор времен <2,1,3> Появляется 2, 1 и 3 раза соответственно, в совокупности. сейчас Может for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
//После накопления времени выход <>
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//Первый параметр — адрес входа
FileInputFormat.addInputPath(job, new Path(args[0]));
//Второй параметр — адрес выхода
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//Ждем завершения выполнения задачи
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Превратите класс запуска в пакет jar через maven и загрузите его в Linux.
Использование Hadoop
Используйте сценарий оболочки для добавления указанного количества слов в файл:
vim gen.sh
#!/bin/bash
# Проверьте количество параметров
if [ "$#" -ne 3 ]; then
echo "Usage: $0 <word> <number_of_words> <output_file>"
exit 1
fi
# Получить параметры
word=$1
num_words=$2
output_file=$3
# Проверьте, существует ли выходной файл
if [ ! -f "$output_file" ]; then
touch "$output_file"
fi
# Сгенерировать указанное количество слов и добавить в файл
generated_words=""
for (( i=1; i<=num_words; i++ ))
do
generated_words+="$word "
done
# Удалить последнее лишнее пространство
generated_words=${generated_words% }
# Добавить в выходной файл
echo "$generated_words" >> "$output_file"
echo "Generated $num_words instances of '$word' and appended to $output_file"После изменения разрешений генерируются 999 Hello и CaiCai и добавляются в файл input.txt.
chmod 777 gen.sh
./gen.sh Hello 999 input.txt
#Печать Generated 999 instances of 'Hello' and appended to input.txt
./gen.sh CaiCai 999 input.txt
#Печать Generated 999 instances of 'CaiCai' and appended to input.txtЗагрузить файлы вхождения в hdfs
hadoop fs -mkdir /test
hadoop fs -mkdir /test/input
hadoop fs -put input.txt /test/input/hellocaicai.txtосуществлять:
hadoop jar HadoopDemo-1.0-SNAPSHOT.jar com.caicaijava.hadoop.WordCount /test/input/hellocaicai.txt /test/output/hellocaicaiкоманда выполнения Hadoop jar
Пакет jar программы HadoopDemo-1.0-SNAPSHOT.jar
com.caicaijava.hadoop.WordCount полное имя класса запуска
/test/input/hellocaicai.txt входить в файл на hdfs
/test/output/hellocaicai hdfs выходной каталог
Посмотреть результаты
hadoop fs -cat /test/output/hellocaicai/part-r-00000
На этом этапе построение HDFS завершено, подсчитывается количество слов в файле данных и получается Сохранять в HDFS.
Если есть другие потребности в обработке данных, просто повторно реализуйте MapReduce Прямо сейчас
Подвести итог
В этой статье в основном обсуждаются HDFS-хранилище и расчет MapReduce под Hadoop.
HDFS-хранилище Архитектура в основном реализуется с помощью namenode и datanode.,Хранилище разделено на разные стеллажи.,Для межузловой связи в стойке требуется коммутатор,Фактический блок данных, хранящийся на узле
При этом для достижения доступности и надежности данных блоки данных будут избыточны, а копии будут храниться на разных стойках. Неравномерное хранение на стойках может снизить накладные расходы на запись.
Процесс расчета сначала разделит вход,Карта одна за другой после нарезки,Затем после сортировки разделов КВ,Затем выполните сокращение слияния,Наконец конвертируйте результат в файл Сохранять в HDFS.
Наконец (пожалуйста, поставьте лайк, соберите, подпишитесь, пожалуйста~)
Я Кай Кай,Люблю техническое общение, обмен информацией и написание статей,Мне нравятся понятные выходные знания с картинками и текстами.
Эта статья включена в рубрику Часто используемые фреймворки,感兴趣的такой же学Можеткпродолжениесосредоточиться наох
Примечания и случаи этой статьи включены Gitee-CaiCaiJava、 Github-CaiCaiJava,Кроме того, есть более продвинутые знания, связанные с Java.,感兴趣的такой же学Можеткstarredпродолжениесосредоточиться наох~
Если у вас есть какие-либо вопросы, вы можете обсудить их в области комментариев. Если вы считаете, что письмо Цай Цая хорошее, вы можете поставить лайк, подписаться на него и собрать его, чтобы поддержать его ~
Следите за Цай Цаем и делитесь дополнительной технической информацией, общедоступный аккаунт: внутренняя кухня Цай Цая.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
