На каком уровне вы находитесь в создании модульных тестов на основе LLM?
На каком уровне вы находитесь в создании модульных тестов на основе LLM?
Л1 Просто для развлечения
Выберите тестируемый метод (фокальный метод), передайте исходный код тела метода в большую модель и попросите сгенерировать сценарии модульного тестирования. Это множество так называемых решений, которые могут расширить возможности разработки больших моделей для единичного тестирования. В демо-версиях некоторых производителей все еще можно создать вариант использования уровня Hello. После переключения на реальный проект вы можете только ха-ха.

L2 Разовая сделка
Если вы хотите быть более серьезным и написать несколько отдельных тестовых случаев, вы будете знать, что тестируемый метод будет зависеть от методов внешних классов/сторонних пакетов, а не только от JDK/сторонних пакетов. Следовательно, при использовании LLM для создания отдельных тестов, помимо предоставления кода фокусного метода, вам также необходимо предоставить дополнительную ключевую информацию, такую как сигнатура, переменные и зависимости фокусного класса, чтобы LLM мог лучше понимать код и создавать тестовые примеры. Но даже в этом случае уровень успеха Pass@1 в настоящее время все еще средний. Обычно уровень успеха, упомянутый в статье, составляет около 40-50% и основан на проектах с открытым исходным кодом. Реальные проекты компании более сложны (или, по мнению некоторых экспертов, качество кода может быть хуже), что приводит к худшему эффекту генерации LLM.
Многораундовый диалог L3 на основе модели генерации-проверки-восстановления GVR
Таким образом, направлением исследований является повышение скорости прохождения сценариев использования, созданных LLM.
Создавайте, проверяйте, исправляйте и улучшайте показатели успешности генерации посредством нескольких раундов диалога. (Документы Чжэцзянского университета и Фуданьского университета)
Ниже приводится обзор плана, приведенного в статье Чжэцзянского университета [1].
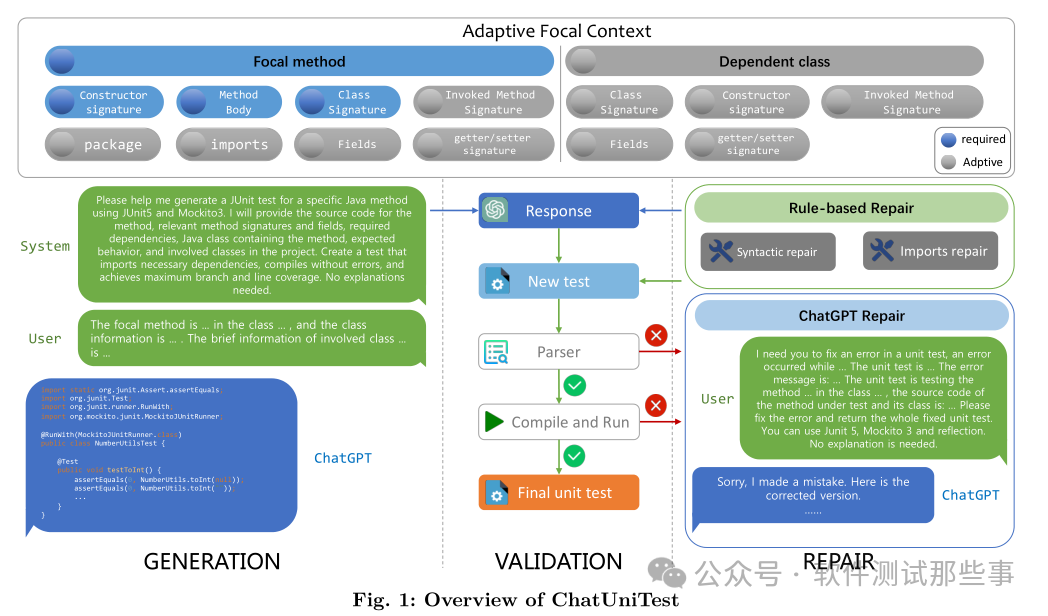
Каковы преимущества этого плана перед предыдущей одноразовой сделкой? Давайте посмотрим на пример эффекта, приведенный в статье Чжэцзянского университета.
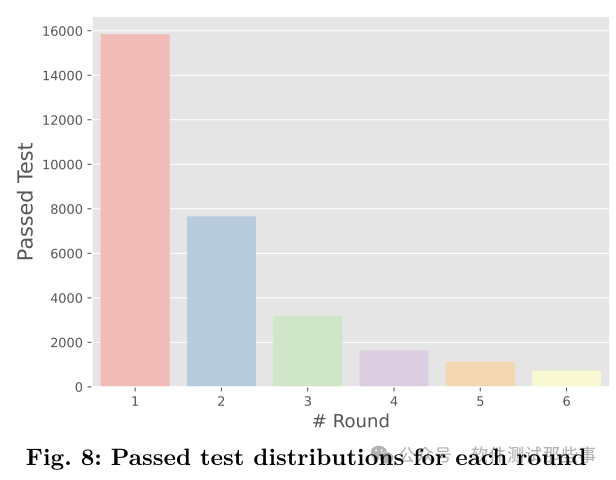
Как видно из приведенного выше рисунка, примерно на основе базы открытого исходного кода решение диссертационной группы сгенерировало около 16 000 «пройденных» тестовых случаев, а после раунда исправлений было пройдено около 8 000 тестовых случаев. количество сценариев использования, пройденных после 3-6 раундов ремонта, составляет около 7000. Другими словами, благодаря такой универсальной услуге, как GVR, появляется примерно в два раза больше новых вариантов использования, чем при простой «разовой сделке».
Конечно, из практики автора решающее значение имеет способность генерации большой модели, то есть качество вариантов использования, сгенерированных на первом этапе генерации. Это также легко понять. Если вы родились с дефицитом, вы не сможете восполнить его послезавтра.
L4 G-V-R-S модель экрана генерации-проверки-восстановления
На основе модели GVR тестовые примеры выбираются с помощью индикаторов покрытия (Meta, документ NTU).
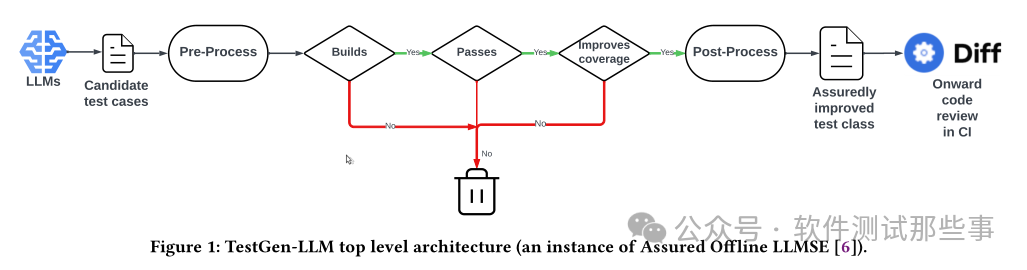
В статье, опубликованной Meta [2], на основе исходной выборки отдельных тестовых примеров, прошедших компиляцию и выполнение, была наложена ссылка «Улучшает покрытие». Для тестируемого фокального метода (фокального метода) была добавлена ссылка. были наложены. Варианты использования, созданные моделью, будут сохранены только в том случае, если они увеличивают охват (строки кода, ветки и т. д.).
В статье приведена следующая диаграмма Сэнки:
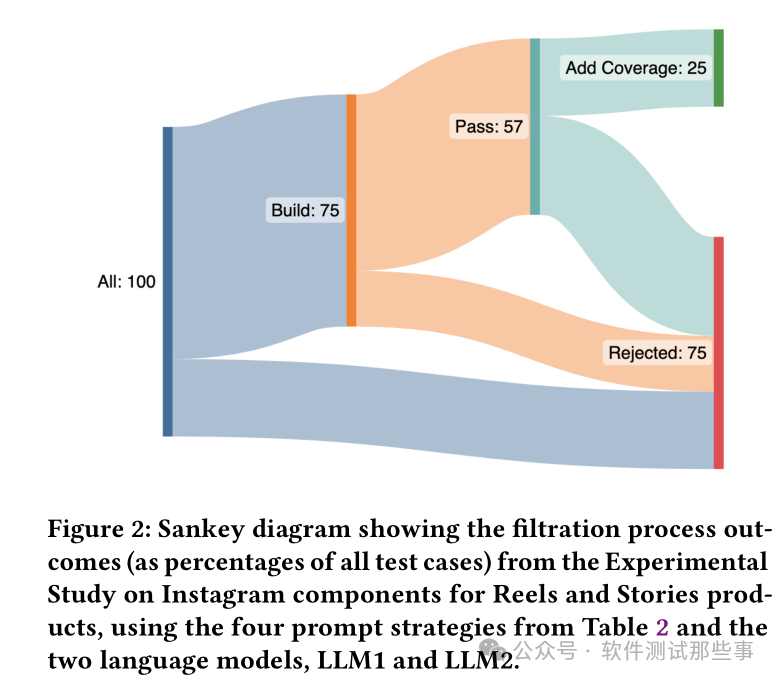
Учитывая, что 57% тестовых сценариев могут быть выполнены и пройдены, только около половины вариантов использования, то есть 25% от общего числа, могут увеличить охват тестированием и, следовательно, могут быть сохранены как новые варианты использования как действительные. варианты использования.
Аналогично, команда NTU также опубликовала статью [3] и предложила аналогичную процедуру под названием «Обратная связь по тестированию», которая также использует данные о покрытии, чтобы определить, можно ли сохранить вновь созданные варианты использования.
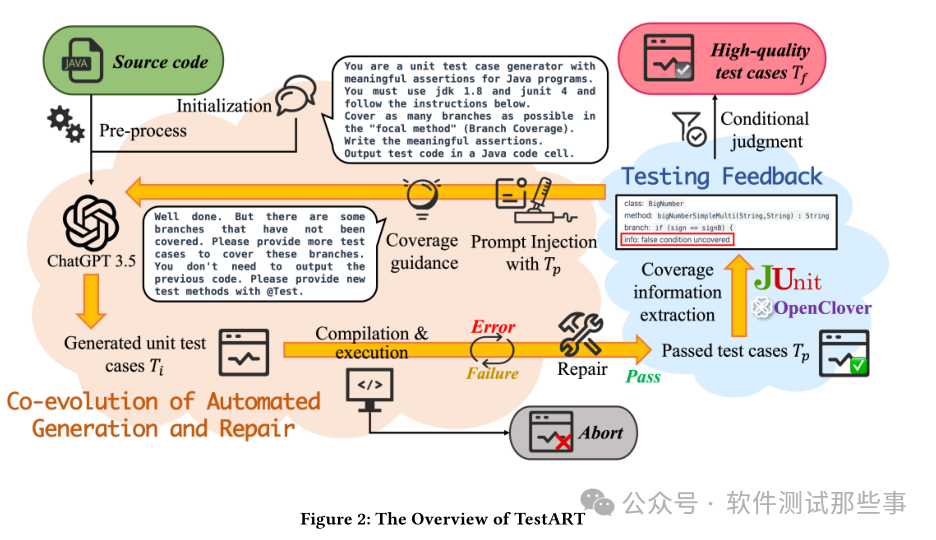
Конечно, главное нововведение этой статьи заключается в процессе исправления тестовых сценариев, и в ней предлагается несколько очень интересных способов исправления неудачных сценариев использования. Заинтересованные читатели могут прокрутить статью до конца, чтобы просмотреть ее.
L5 В мире боевых искусств непобедима только скорость
В приведенных выше статьях для взаимодействия с LLM обычно используются несколько раундов диалога. В настоящее время, поскольку размер модели становится все больше и больше, размер диалогового окна становится все больше и больше, тем больше контента возвращается LLM и тем дольше занимает весь процесс диалога. Компиляция тест-кейсов, выполнение, анализ покрытия и т. д. в решении также требуют времени. Даже если одна ссылка занимает среднее количество времени, общая сумма впечатляет.
В процессе продвижения автор обнаружил, что на самом деле в сценарии IDE «LLM генерирует один тестовый пример» на самом деле является задачей, зависящей от времени. После того, как разработчик нажимает «Создать вариант использования», если нет ответа в десятках. секунд или более минуты. Создаются варианты использования, и разработчики начинают беспокоиться. А если это также отнимает ресурсы IDE и вызывает задержки, разработчики будут жаловаться на это.
Таким образом, как решить трудоемкую проблему, становится проблемой, которую необходимо решить позже.
На данный момент идеального решения не существует. Основное внимание по-прежнему уделяется улучшению первого звена, то есть при первой генерации одного тестового примера, можно ли предоставить LLM различные процедуры (см. план Чжэцзянского университета [1] выше), чтобы понять тестируемый код и генерировать тестовые примеры всех видов необходимой информации и данных. Путем однократной генерации скорости прохождения последующие раунды сокращаются, чтобы сократить общие затраты времени. Другая идея состоит в том, чтобы больше не ждать, пока разработчик нажмет «Создать вариант использования» в IDE, чтобы запустить этот процесс, а использовать предварительную генерацию и другие процедуры для устранения самой проблемы, поскольку она не может решить проблему.
Если у вас есть хорошие идеи или планы, пожалуйста, оставьте сообщение.
Ссылки:
【1】Automated Unit Test Improvement using Large Language Models
【2】Automated Unit Test Improvement using Large Language Models at Meta
【3】Improving LLM-based Unit test generation via Template-based Repair



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
