[MYSQL] анализ файла mysql.ibd (страница SDI) (просмотр скрытых системных таблиц в режиме без отладки)
Введение
в MySQL В версии 8.0 механизм хранения системной таблицы изменен с myisam на innodb. @@datadir/mysqlКуча файлов данных в каталоге помещена в@@datadir/mysql.ibdФайл находится в. Однако данные во многих таблицах невозможно просмотреть в неотладочном режиме. Это так раздражает. (Я только что закончил изучать структуру диска innodb, Смогу ли я вынести этот гнев?). Итак, давайте теперь разберем файл mysql.ibd. (Также кстати ibd2sql 2.0 готовиться)

анализировать
Давайте сначала войдем в базу данных и проверим DDL таблицы в библиотеке mysql.
show create table mysql.engine_cost;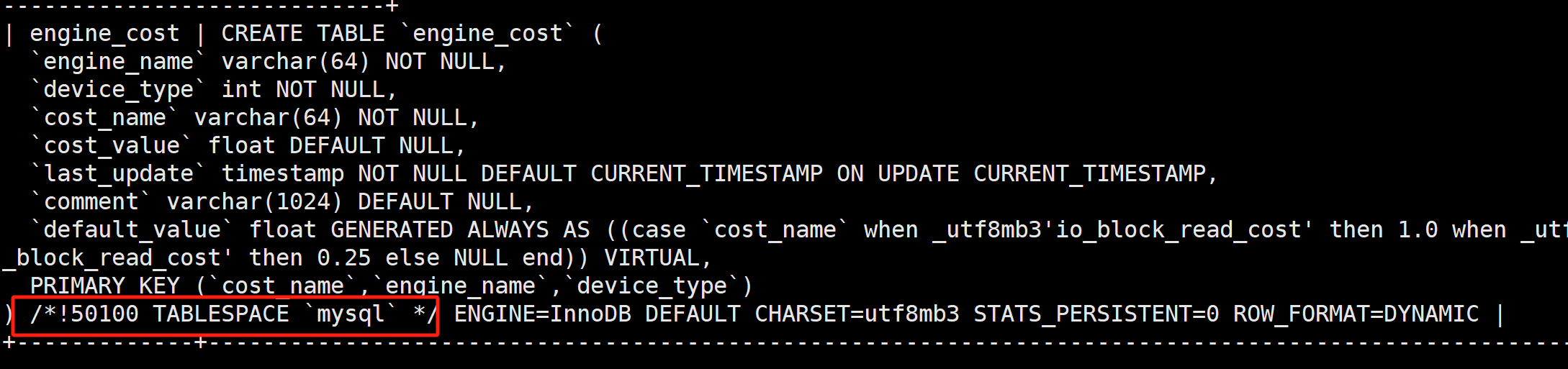
Было обнаружено, что все используемые табличные пространстваmysql. Тогда давайте посмотримmysqlТип табличного пространства
select * from information_schema.INNODB_TABLESPACES where NAME='mysql'\G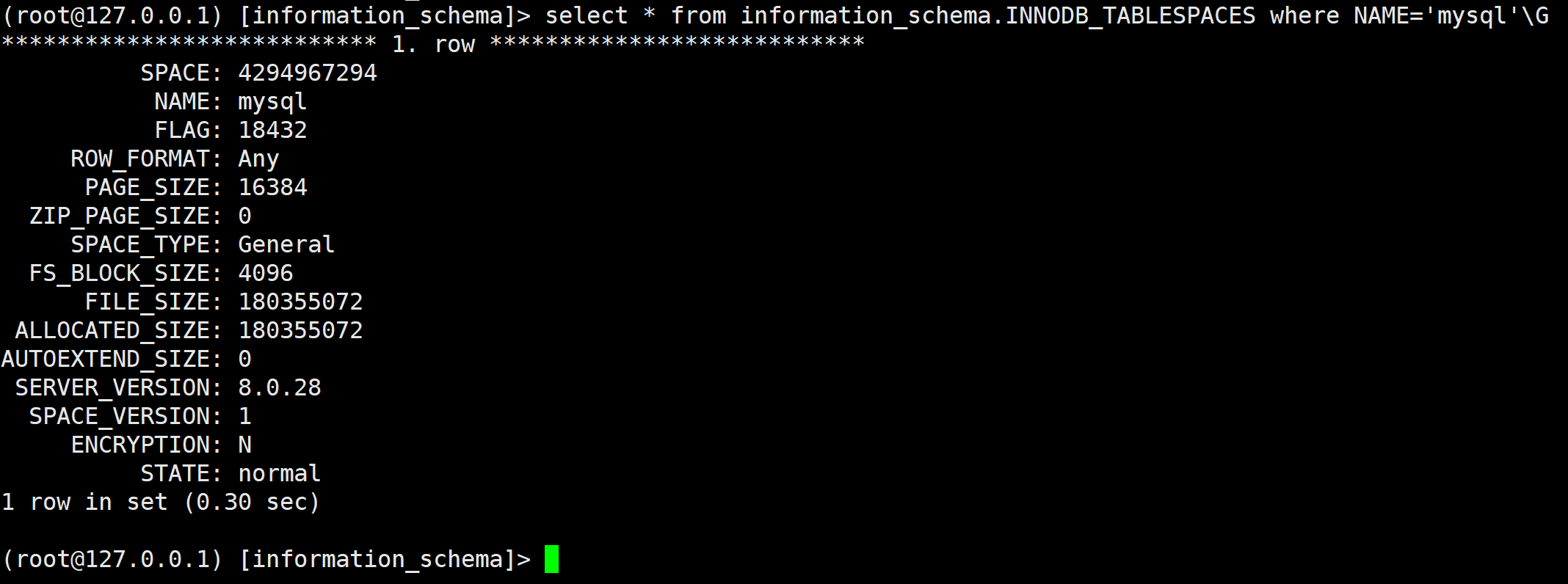
оказалось, чтоgeneralиз.(подтверждатьизах). Проверяем путь к табличному пространству:
общее табличное пространство может хранить несколько таблиц
select * from information_schema.files where TABLESPACE_NAME='mysql'\G
Открытие@@datadir/mysql.ibd. Это файл, который мы хотим проанализировать на этот раз.
Все относительные пути MySQL основаны на @@datadir.
Мы проанализировали файл данных передизвсегда основаны наFile-Per-Table Tablespacesиз, То есть одно табличное пространство соответствует одной таблице. Туда сложно подняться.
SDI PAGE
Поскольку одно табличное пространство может хранить несколько таблиц, Затем информация SDI будет записывать информацию из нескольких таблиц, Когда мы ранее анализировали индексный дескриптор, Я обнаружил, что первая пара сегментов внутри — это sdi. page, То есть СДИ page Он также должен быть в том же формате, что и обычный индекс. Кроме того, при парсинге sdi также присутствует такая информация, как trx и undoptr. Так что СДИ страница также является строкой данных, Итак, таблица1В строках может храниться несколько таблицизинформация метаданных.ах,Я такой маленький гений
FIL_PAGE_INDEX = 17855, FIL_PAGE_SDI = 17853. Числа относительно близки, поэтому формат тот же p_q
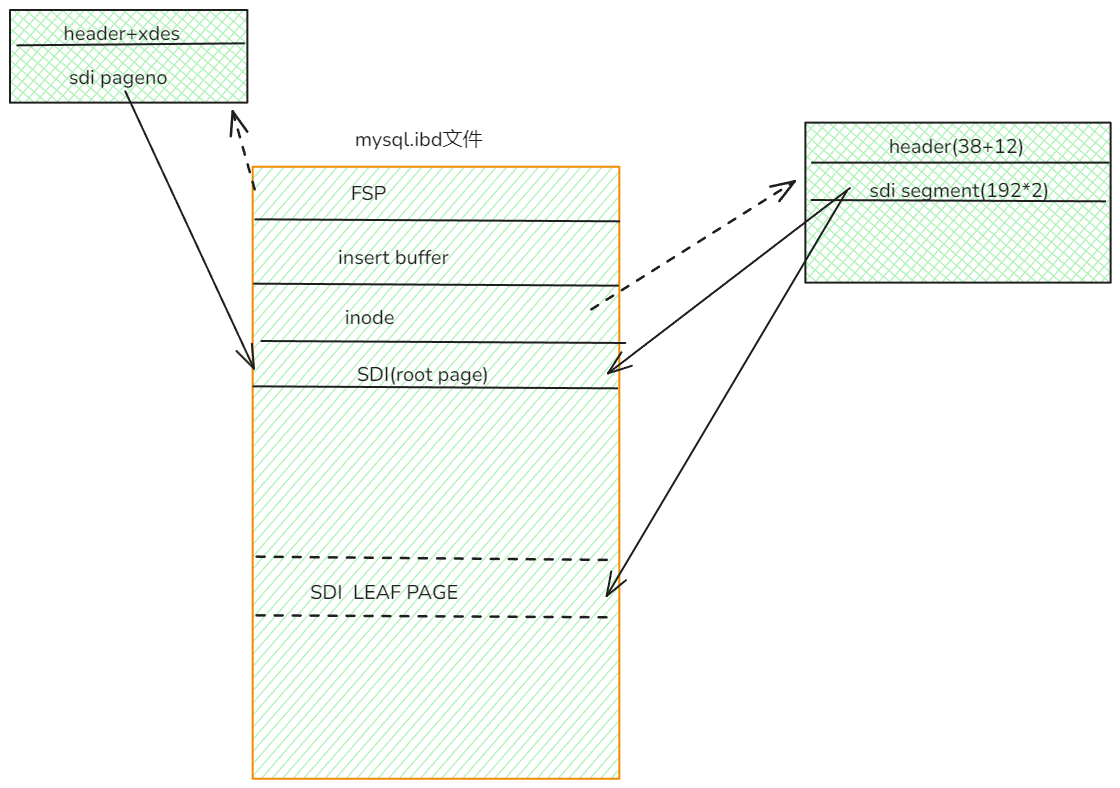
Теперь, когда мы знаем формат, мы можем проанализировать его с помощью следующего кода (без предварительного преобразования в DDL). Чтобы увеличить объем памяти, давайте рассмотрим структуру sdi.
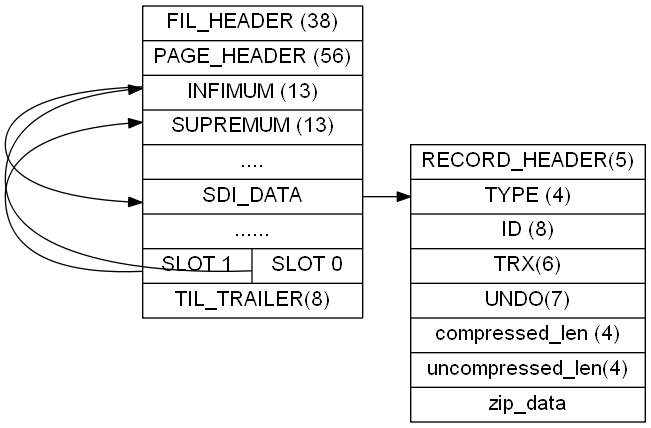
Общий формат такой, но строк данных может быть несколько, и (я только что закончил обработку и забыл, что сказать-_-).
Если это нелистовая страница, то нет типа и данных, только 21 байт PK (id 8 байт), trx(6), undoptr(7), плюс 4 байта PAGENO. Проверьте интересующие вас слова. самостоятельно, мы не будем их здесь проверять.
Поскольку все они представляют собой строки данных (btr+), они также представляют собой двусвязные списки, что предполагает формат file_header.
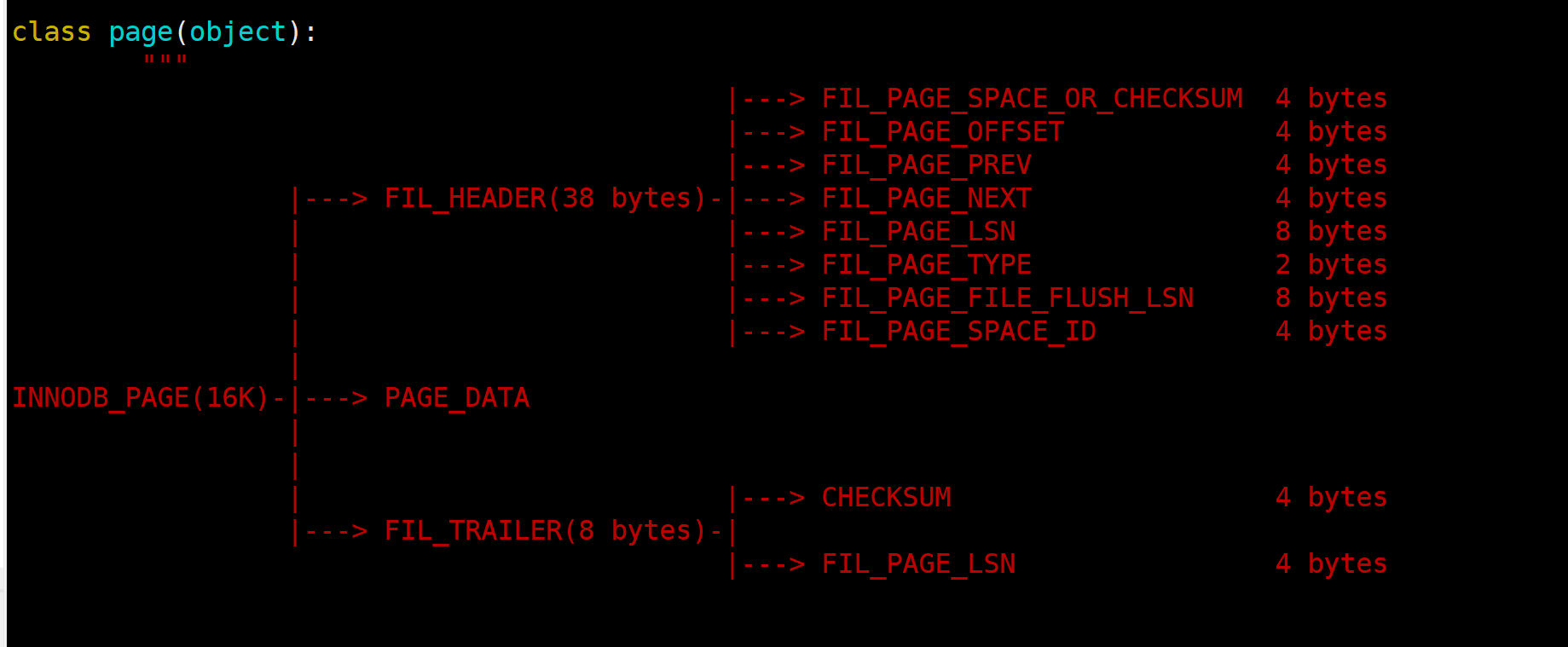
12--16 — это ПАГЕНО следующей страницы. (checksum, space_id,lsn Это выглядит знакомо? Первые две статьианализироватьиз Иногда полезно). Введение структуры закончено, Затем начните весь процесс.
import struct,json,zlib
PAGE_NEW_INFIMUM = 99
filename = '/data/mysql_3314/mysqldata/mysql.ibd'
f = open(filename,'rb')
data = f.read(16384)
# записи fsp соответствуют общим табличное пространство бесполезно, Но из вежливости Оставим 2 строки кода
sdi_version,sdi_pageno = struct.unpack('>II',data[150+40*256:150+40*256+8])
# inode
f.seek(16384*2,0)
data = f.read(16384)
sdi_segment = data[50:50+192*2]
sdi_leaf_pageno = struct.unpack('>L',sdi_segment[192:][64:68])[0]
# SDI
dd = {}
while sdi_leaf_pageno < 4294967295:
_ = f.seek(16384*sdi_leaf_pageno,0)
data = f.read(16384)
sdi_leaf_pageno = struct.unpack('>L',data[12:16])[0]
offset = PAGE_NEW_INFIMUM + struct.unpack('>H',data[97:99])[0]
while True:
offset += struct.unpack('>h',data[offset-2:offset])[0] # Обратите внимание, что оно подписано. Но это не предполагает модификации данных, На самом деле это не имеет значения
if offset > 16384 or offset == 112:
break
sdi_type,id = struct.unpack('>LQ',data[offset:offset+12])
trx1,trx2,undo1,undo2,undo3 = struct.unpack('>LHLHB',data[offset+12:offset+25])
trx = (trx1<<16) + trx2
undo = (undo1<<24) + (undo2<<8) + undo3
dunzip_len,dzip_len = struct.unpack('>LL',data[offset+25:offset+33])
unzbdata = zlib.decompress(data[offset+33:offset+33+dzip_len])
dic_info = json.loads(unzbdata.decode())
dd[dic_info['dd_object']['name']] = dic_info
print('TOTAL TABLES:',len(dd))
for name in dd:
print(name)
С помощью этого кода мы можем получить SDI-диктант. Имеется 60 таблиц.
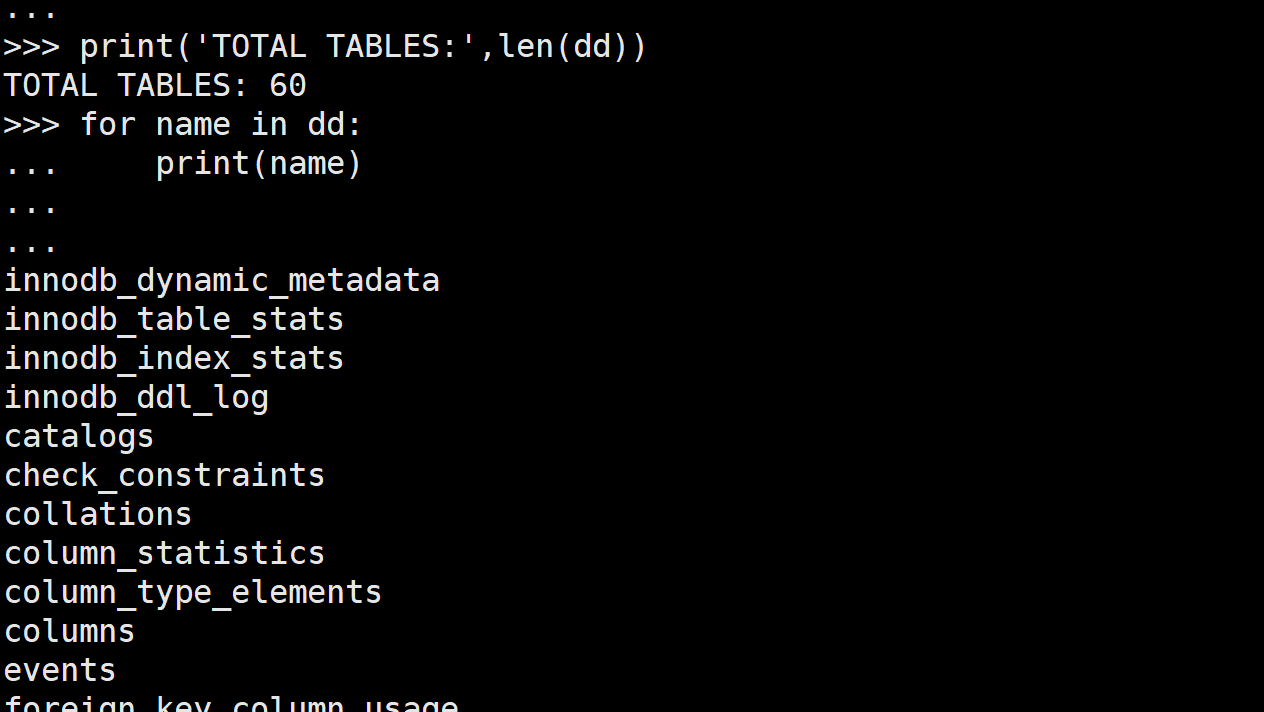
Но когда мы зашли в базу данных, чтобы проверить, там было всего 37 фотографий.
(root@127.0.0.1) [mysql]> select count(*) from information_schema.tables where table_schema='mysql';
+----------+
| count(*) |
+----------+
| 37 |
+----------+
1 row in set (0.00 sec)Это потому что типаcatalogsи тому подобноеизскрытый. Для выполнения запроса необходимо включить режим отладки. Цель нашей статьи — прямой запрос.

Разберите файл mysql.ibd
Теперь, когда информация SDI получена, Затем вы можете начать анализировать данные этих 60 таблиц. Благодаря существованию таких форматов данных, как json, Поэтому мы просто используемibd2sqlПриди и сделай это (Просто измените это немного, Перепишите методы использования этих классов)
Структура строки данных соответствует структуре sdi, приведенной выше, поэтому она не будет вводиться снова.
from ibd2sql.innodb_page_sdi import *
from ibd2sql import __version__
from ibd2sql.ibd2sql import ibd2sql
class sdi2(sdi):
def __init__(self,*args,**kwargs):
super().__init__(*args,**kwargs)
self.dd = kwargs['dd']
self.table = TABLE()
self._init_table()
self.table._set_name()
def get_dict(self):
return self.dd
class ibd2sql2(ibd2sql):
def init(self,):
self.f = open(self.FILENAME,'rb')
self.PAGE_ID = 2
self.first_no_leaf_page = 82
self.first_leaf_page = 0
for name in dd:
aa = sdi2(b'\x00'*16384,dd=dd[name])
ddcw = ibd2sql2()
ddcw.FILENAME = filename
ddcw.IS_PARTITION = True
ddcw.table = aa.table
ddcw.replace_schema('ddcw') # Замените схему, чтобы облегчить импорт в базу данных.
ddcw._init_table_name()
ddcw.init()
ddcw.first_no_leaf_page = int(dict([ y.split('=') for y in dd[name]['dd_object']['indexes'][0]['se_private_data'].split(';')[:-1]])['root'])
ddcw.init_first_leaf_page()
print(ddcw.get_ddl()) # Распечатать DDL
print(ddcw.get_sql()) # Распечатать данныедавайте посмотрим
Это странно, но, похоже, это не проблема...
Никакого более глубокого тестирования проводиться не будет.
Подвести итог
- mysql Системные таблицы версии 8.0 используют механизм хранения innodb. Магазин в В файле MySQL.ibd является общим тип табличного пространства, То есть несколько системных таблиц хранятся в одном табличном пространстве.
- Системная информация, которую можно увидеть только при отладке при нормальных обстоятельствах. Теперь доступно через Разберите файл Mysql.ibd здесь, чтобы получить это.
- При фактическом использовании рекомендуется выполнить cp в каталог tmp, а затем проанализировать (хотя для этого требуется только разрешение на чтение, это безопасный вариант).
- Информация в системных таблицах относительно конфиденциальна, поэтому не передавайте ее случайно (в ней есть таблица mysql.user)
ссылка
https://github.com/ddcw/ibd2sql
https://dev.mysql.com/doc/refman/8.0/en/general-tablespaces.html
https://github.com/mysql/mysql-server/blob/trunk/utilities/ibd2sdi.cc
Прикрепленный исходный код
Для использования вместе с ibd2sql.
пример:
wget https://github.com/ddcw/ibd2sql/archive/refs/heads/main.zip
unzip main.zip
cd ibd2sql-main/
vim get_mysql_ibd.py # Вставьте абзац ниже кода
python get_mysql_ibd.py /data/mysql_3314/mysqldata/mysql.ibd > /tmp/t20240918.sqlИсходный код:
import struct,json,zlib
from ibd2sql.innodb_page_sdi import *
from ibd2sql import __version__
from ibd2sql.ibd2sql import ibd2sql
import sys,os
PAGE_NEW_INFIMUM = 99
if len(sys.argv)!=2:
print('USAGE: python3 get_mysql_ibd.py /data/mysql.ibd')
sys.exit(2)
filename = sys.argv[1]
if not os.path.exists(filename):
print(filename,' not exists')
sys.exit(1)
f = open(filename,'rb')
data = f.read(16384)
# записи fsp соответствуют общим табличное пространство бесполезно, Но из вежливости Оставим 2 строки кода
sdi_version,sdi_pageno = struct.unpack('>II',data[150+40*256:150+40*256+8])
# inode
f.seek(16384*2,0)
data = f.read(16384)
sdi_segment = data[50:50+192*2]
sdi_leaf_pageno = struct.unpack('>L',sdi_segment[192:][64:68])[0]
# SDI
dd = {}
while sdi_leaf_pageno < 4294967295:
_ = f.seek(16384*sdi_leaf_pageno,0)
data = f.read(16384)
sdi_leaf_pageno = struct.unpack('>L',data[12:16])[0]
offset = PAGE_NEW_INFIMUM + struct.unpack('>H',data[97:99])[0]
while True:
offset += struct.unpack('>h',data[offset-2:offset])[0] # Обратите внимание, что оно подписано. Но это не предполагает модификации данных, На самом деле это не имеет значения
if offset > 16384 or offset == 112:
break
sdi_type,id = struct.unpack('>LQ',data[offset:offset+12])
trx1,trx2,undo1,undo2,undo3 = struct.unpack('>LHLHB',data[offset+12:offset+25])
trx = (trx1<<16) + trx2
undo = (undo1<<24) + (undo2<<8) + undo3
dunzip_len,dzip_len = struct.unpack('>LL',data[offset+25:offset+33])
unzbdata = zlib.decompress(data[offset+33:offset+33+dzip_len])
dic_info = json.loads(unzbdata.decode())
dd[dic_info['dd_object']['name']] = dic_info
f.close()
class sdi2(sdi):
def __init__(self,*args,**kwargs):
super().__init__(*args,**kwargs)
self.dd = kwargs['dd']
self.table = TABLE()
self._init_table()
self.table._set_name()
def get_dict(self):
return self.dd
class ibd2sql2(ibd2sql):
def init(self,):
self.f = open(self.FILENAME,'rb')
self.PAGE_ID = 2
self.first_no_leaf_page = 82
self.first_leaf_page = 0
for name in dd:
try:
aa = sdi2(b'\x00'*16384,dd=dd[name]) # Я поменяю его, когда у меня будет время. Сначала только во временное пользование.... # Фактически это последний объект (mysql, Не часы, То есть mysql.mysql нет)
except:
continue
ddcw = ibd2sql2()
ddcw.FILENAME = filename
ddcw.IS_PARTITION = True
ddcw.table = aa.table
ddcw.replace_schema('ddcw') # Замените схему, чтобы облегчить импорт в базу данных.
ddcw._init_table_name()
ddcw.init()
ddcw.first_no_leaf_page = int(dict([ y.split('=') for y in dd[name]['dd_object']['indexes'][0]['se_private_data'].split(';')[:-1]])['root'])
try:
ddcw.init_first_leaf_page()
print(ddcw.get_ddl()) # Распечатать DDL
sql = ddcw.get_sql()
if sql is not None:
print(sql) # Распечатать данные
except:
pass


Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
