Мощный инструмент для управления метаданными при управлении данными — вводное руководство Atlas (статья объемом 10 000 слов)
По мере продвижения цифровой трансформации,,данныеуправлениеиз Рабочих мест становится все большеиз Компания включила этот вопрос в повестку дня。делатьдляHadoopСамая строгая экологияиз Управление метаданнымииинструменты обнаружения,Атлас играет важную роль в своей середине. Но его официальная документация не очень богата.,Это тоже недостаточно подробно. Поэтому я составил этот документ, чтобы каждый мог научиться его использовать.
Авторские права на документ - публичный аккаунт большой поток данных все,Не используйте в коммерческих целях。По соответствующим техническим вопросам и установочным пакетам обращайтесь к автору.ДугуфэнПрисоединяйтесь к соответствующим группам технического обмена, чтобы обсудить и получить。
1. Управление данными и управление метаданными
фон
Зачем нам нужно управление данными? Существует много предприятий, много данных, и бизнес-данные постоянно повторяются. Наблюдается поток кадров, неполная документация и неясная логика. Данные сложно понять интуитивно и сложно их поддерживать в дальнейшем.
В исследованиях и разработках больших данных существует множество баз данных и таблиц для необработанных данных.
После агрегирования данных будет много таблиц измерений.
В последние годы объем данных бешено растет, что повлекло за собой ряд проблем. Что касается поддержки данных для команд искусственного интеллекта, наиболее частый вопрос, который мы слышим, — «им нужен правильный набор данных для анализа». Мы начали понимать, что, хотя мы создали масштабируемое хранилище данных, вычисления в реальном времени и другие возможности, наша команда по-прежнему тратила время на поиск подходящих наборов данных для анализа.
То естьда Нам не хватает праваданныересурсыизуправлять。фактически,Есть много компаний, которые предоставляют решения с открытым исходным кодом для решения вышеуказанных проблем.,этот То естьдаданные Обнаружитьи Управление метаданнымиинструмент。
Управление метаданными
Проще говоря, Управление метаданнымидадля Верноданныересурсы Входить ХОРОШОэффективныйизорганизовать。этоиспользовать Юаньданныеприйти на помощьуправлятьихизданные。этотакже может помочьданные Профессиональная коллекция、организовать、доступ и обогащение Юаньданные,Для поддержки управления данными.
Тридцать лет назад активом данных могла быть таблица в базе данных Oracle. Однако на современном предприятии мы имеем ошеломляющее количество различных типов информационных активов. Это могут быть таблицы в реляционной базе данных или хранилище NoSQL, потоковые данные в реальном времени, функции в системе искусственного интеллекта, метрики в платформе метрик, информационные панели в инструменте визуализации данных.
Современное Управление метаданными должно содержать все эти типы изданных активов и позволять работникам, работающим с данными, более эффективно использовать эти активы для выполнения своей работы.
Таким образом, Управление метаданными должно иметь следующие функции:
- Ищите и открывайте:данныеповерхность、Поле、Этикетка、использоватьинформация
- Контроль доступа:группа контроля доступа、пользователь、Стратегия
- Родословная данных:трубопроводосуществлять、Запрос
- Согласие:данныеконфиденциальность/Типы аннотаций соответствияиз Классификация
- Управление данными:данныеисточник Конфигурация、проглотить Конфигурация、бронировать Конфигурация、данные Прозрачный Стратегия
- Объяснимость и воспроизводимость ИИ:Определение функции、Определение модели、Выполнение тренировочного бега、постановка задачи
- Операции с данными:трубопроводосуществлять、Ручка изданных перегородок、данныестатистика
- Качество данных:данные Определение правила качества、Результаты выполнения правила、данныестатистика
Архитектура и решения с открытым исходным кодом
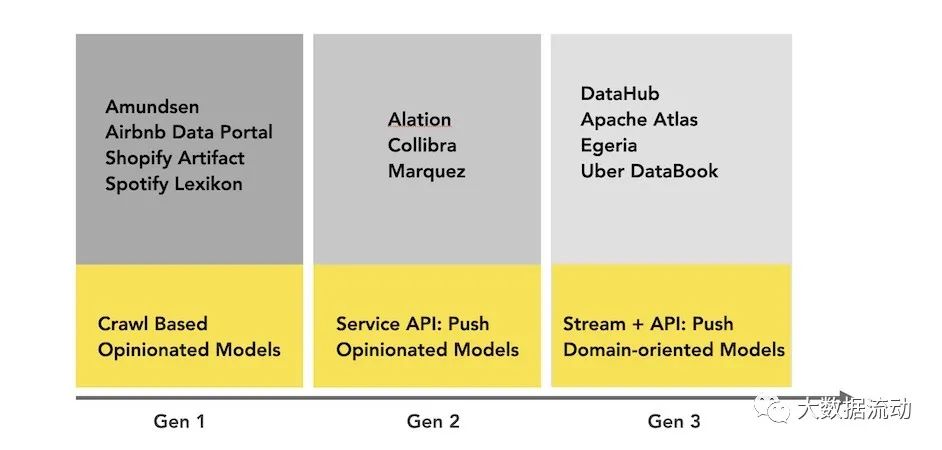
Ниже представлена реализация архитектуры управления метаданными. Различные архитектуры соответствуют различным реализациям с открытым исходным кодом.
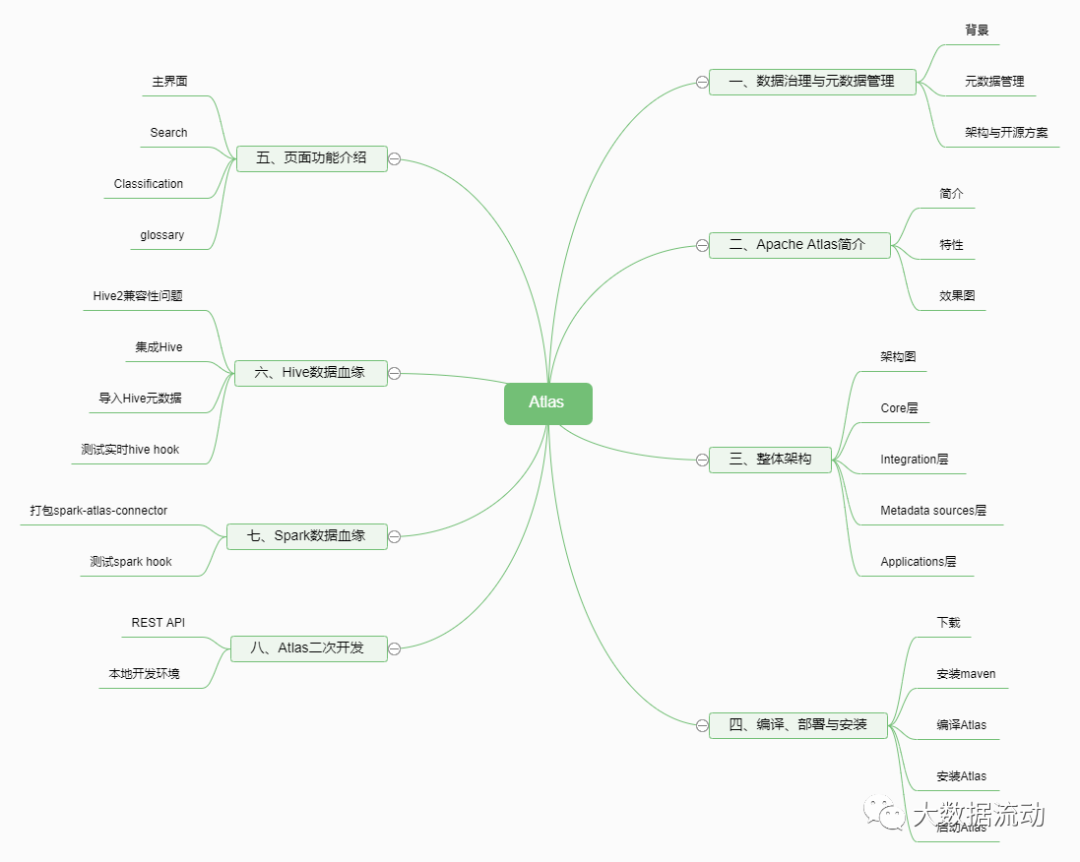
На следующей диаграмме изображена архитектура метаданных первого поколения. Обычно это классический монолитный интерфейс (вероятно, приложение Flask), подключенный к основному хранилищу для запросов (обычно MySQL/Postgres), поисковому индексу для обслуживания поисковых запросов (обычно Elasticsearch) и для этого поколения 1.5 этой архитектуры, возможно, один раз. был достигнут предел «рекурсивных запросов» реляционных баз данных, использовались индексы графов, которые обрабатывали запросы графов происхождения (обычно Neo4j).
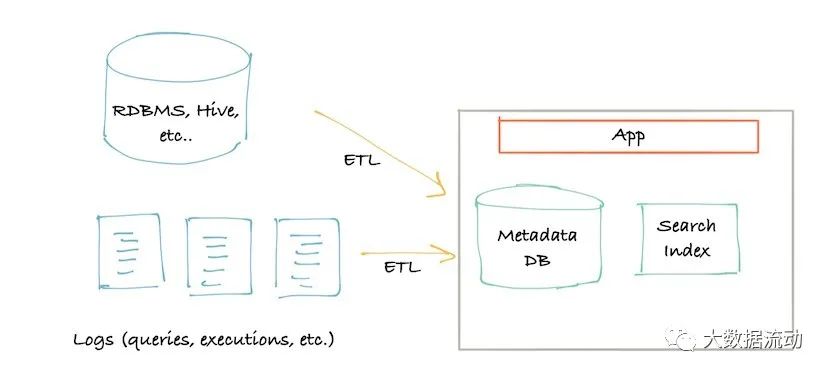
Вскоре появилась архитектура второго поколения. Монолитное приложение было разделено на службы, расположенные перед базой данных хранилища метаданных. Служба предоставляет API, который позволяет записывать метаданные в систему с использованием механизма push.
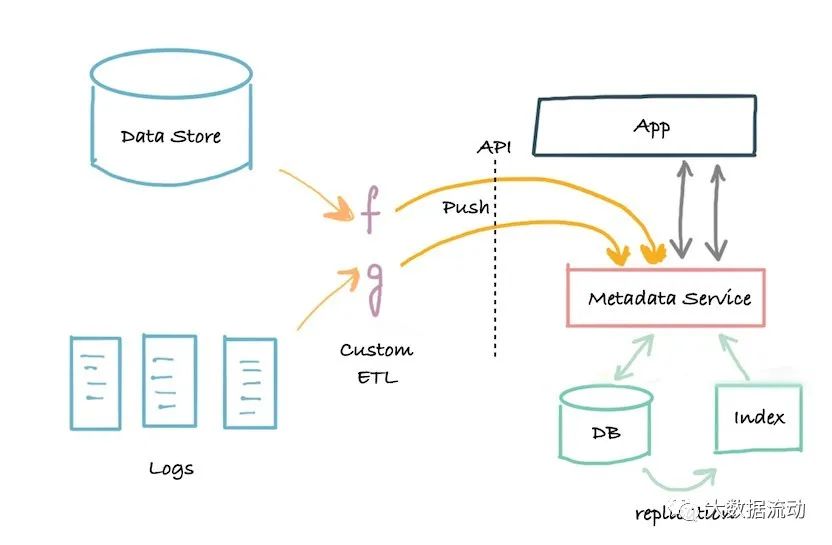
архитектура третьего поколениядаоснованный на событияхиз Управление метаданными Архитектура,Клиенты могутв соответствии сихизнужно быть другимиз Способи Юаньданныеданныевзаимодействие с библиотекой。
Поиск метаданных с малой задержкой, возможность выполнять полнотекстовый и ранжированный поиск по атрибутам метаданных, графические запросы по связям метаданных, а также возможности полного сканирования и анализа.
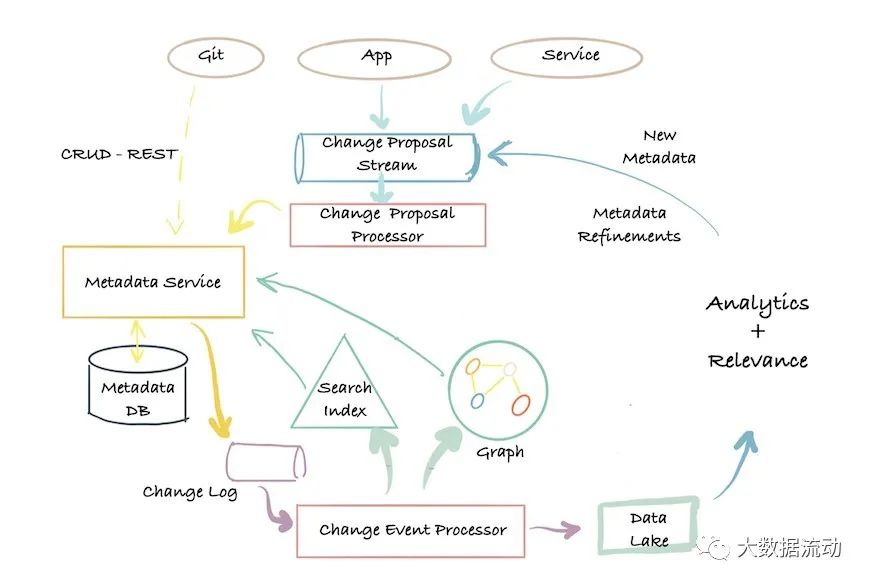
Apache Atlas использует эту архитектуру и тесно связан с экосистемой Hadoop.
Следующая диаграмма представляет собой простое визуальное представление современного ландшафта метаданных:
(Включая некоторые решения с закрытым исходным кодом)
В качестве основного направления исследования можно использовать и другие варианты, но они не являются предметом данной статьи.
2. Введение в Apache Atlas
Введение
Поскольку сегодня применение больших данных становится все более распространенным, управление данными всегда было огромной проблемой, с которой сталкивались предприятия.
Большинство компаний просто обрабатывают данные, но добиться их происхождения, классификации и т. д. Рынок также остро нуждается в технической системе, ориентированной на управление данными. В это время появился Atlas.
Адрес официального сайта Атласа: https://atlas.apache.org/
Atlas — это платформа управления данными и метаданными Hadoop.
Atlas — это набор расширяемых и расширяемых основных базовых служб управления, которые позволяют предприятиям эффективно и результативно соблюдать требования соответствия в Hadoop и обеспечивают интеграцию со всей экосистемой корпоративных данных.
Apache Атлас предоставляет организациям открытое из Управление метаданнымииуправление Функция,для создания своих информационных ресурсов из каталога,Классифицировать и управлять этими активами,И проданные учёные,Группы аналитиков и управления данными обеспечивают возможности совместной работы над этими активами данных.
Если вы хотите управлять этими данными, недостаточно использовать слова, документы и т. д. Вы должны использовать изображения. Атлас — это инструмент, который превращает метаданные в графики.
характеристика
- Atlas поддерживает различные типы элементов Hadoop и не Hadoop.
- Предоставляет богатый REST API для интеграции.
- верноданные Родословнаяиз Ретроспектива достигла Полеуровень,Аналогичной структуры, которая могла бы реализовать эту технологию, пока не существует.
- Также имеется хороший контроль над разрешениями.
Атлас включает в себя следующие компоненты:
- Использование данных элемента хранилища Hbase
- Использование Solr для реализации индексации
- Ingest/Export Собирайте и экспортируйте компоненты Type Тип системы система Graph Engineграфический движок Вместе они образуют основной механизм Atlas.
- Весь функционал доступен пользователям через API, а также может быть интегрирован через систему обмена сообщениями Kafka.
- Atlas поддерживает получение элементов из различных источников: Hive, Sqoop, Storm. . .
- Существует также отличная поддержка пользовательского интерфейса.
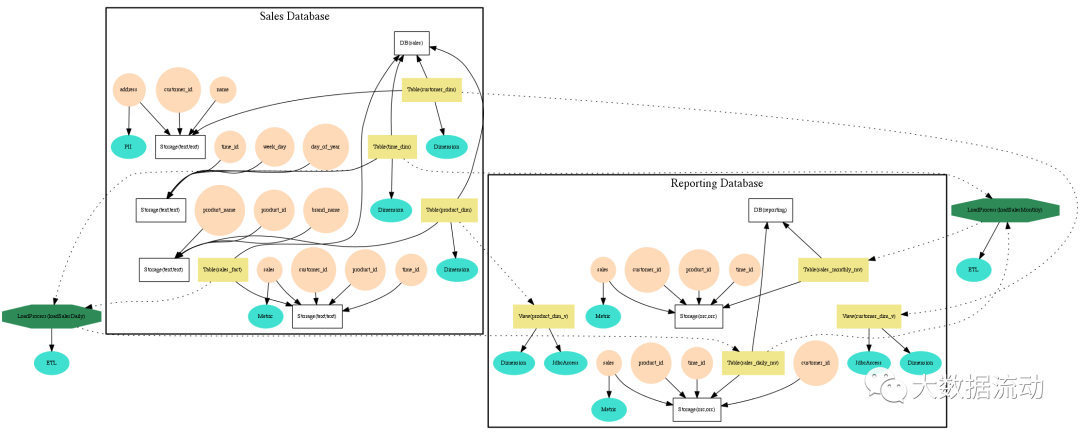
визуализации
3. Общая структура
Схема архитектуры
AtlasСхема архитектурыследующее:
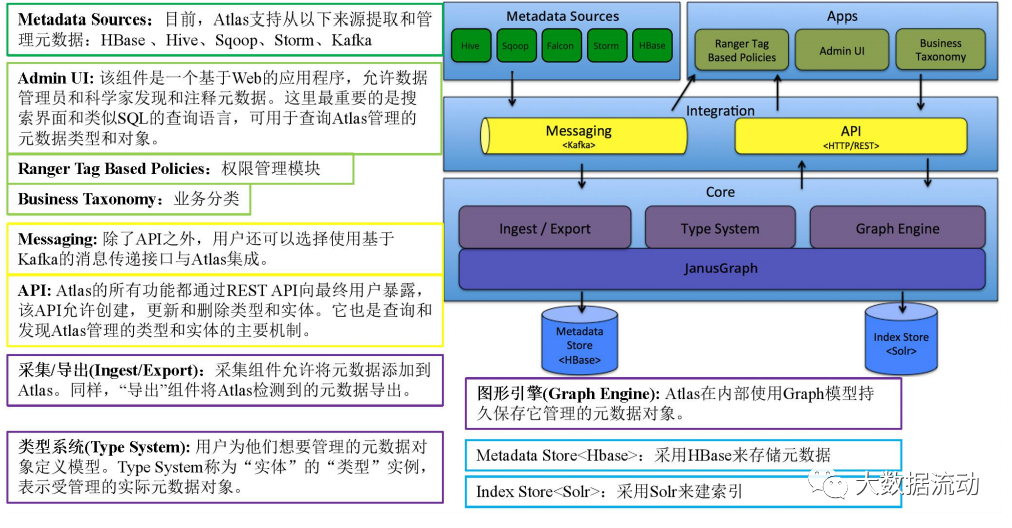
Основной слой
Ядро Atlas содержит следующие компоненты:
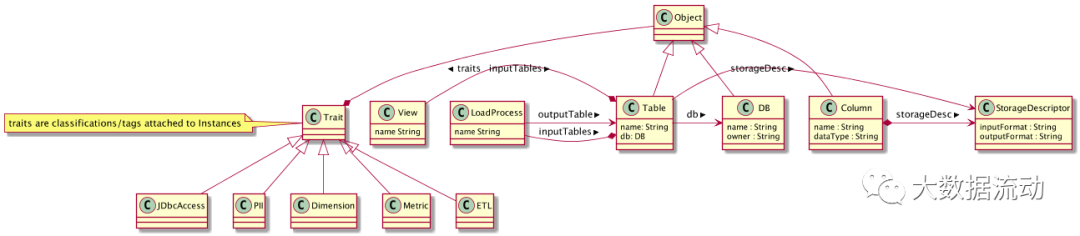
Типовая система: Atlas позволяет пользователям определять модели для объектов метаданных, которыми они хотят управлять. Модель состоит из определений, называемых «типами». Экземпляры «типов», называемые «сущностями», представляют собой фактические управляемые объекты метаданных. Тип Система — это компонент, который позволяет пользователям определять типы и сущности и управлять ими. Все объекты метаданных, управляемые Atlas по умолчанию (например, таблицы Hive), моделируются с использованием типов и представляются в виде сущностей. Чтобы хранить новые типы метаданных в Atlas, вам необходимо понять концепцию компонентов системы типов.
нуждаться Уведомлениеизключевой моментдаAtlasсередина Моделированиеизв целомхарактеристикапозволятьданныеуправлять员и集成商定义技术Юаньданныеи业务Юаньданные。также Можно Функция использования Atlasиз определяет богатую связь между двумя из.
графический движок: Atlas внутренне использует модель Graph для сохранения объектов метаданных, которыми он управляет. Этот подход обеспечивает большую гибкость для эффективного управления разнообразными связями между объектами метаданных. Компонент графического движка отвечает за преобразование между типами и сущностями системы типов Atlas, а также за базовую модель сохранения графики. Помимо управления графическими объектами, графический движок создает соответствующие индексы для объектов метаданных, чтобы их можно было эффективно искать. Atlas использует JanusGraph для хранения объектов метаданных.
Сбор/Экспорт:коллекциякомпонентыпозволять Воля Юаньданныедобавить вAtlas。такой же,“Экспорт”компоненты ВоляAtlasобнаружениз Юаньданные Изменить видимостьдлясобытие。потребитель Можно использовать Эти события изменения реагируют на изменения метаданных в реальном времени.
Уровень интеграции
В Atlas пользователи могут управлять метаданными следующими двумя способами:
API: Все функции Atlas реализуются через REST. Конечным пользователям доступен API, который позволяет создавать, обновлять и удалять типы и сущности. Это также основной механизм запроса и обнаружения типов и объектов, управляемых Atlas.
Messaging: В дополнение к API пользователи также могут выбрать интеграцию с Atlas с помощью интерфейса обмена сообщениями на основе Kafka. Это полезно для передачи объектов метаданных в Atlas и использования Atlas для обработки событий изменения метаданных, которые можно использовать для создания приложений. Интерфейс обмена сообщениями особенно полезен, если вы хотите использовать более слабую интеграцию с Atlas для достижения лучшей масштабируемости, надежности и т. д. Atlas использует Apache. Kafka действует как сервер уведомлений для связи между перехватчиками и последующими потребителями событий уведомлений метаданных. События записываются в разные темы Kafka с помощью хуков и Atlas.
Уровень источников метаданных
Atlas поддерживает интеграцию нескольких источников метаданных «из коробки». В будущем будут добавлены дополнительные интеграции. В настоящее время Atlas поддерживает извлечение метаданных и управление ими из следующих источников:
- HBase
- Hive
- Sqoop
- Storm
- Kafka
Интеграция означает две вещи: модель метаданных, определенная Atlas, используется для представления объектов этих компонентов. Atlas предоставляет компоненты для приема объектов метаданных из этих компонентов (либо в реальном времени, либо в некоторых случаях в пакетном режиме).
Уровень приложений
Метаданные, управляемые Atlas, используются различными приложениями для удовлетворения многих потребностей управления.
Atlas Admin UI: Этот компонент представляет собой веб-приложение, которое позволяет менеджерам данных и ученым обнаруживать и комментировать метаданные. Наиболее важным здесь является интерфейс поиска и язык запросов, подобный SQL, который можно использовать для запроса типов метаданных и объектов, управляемых Atlas. Админ Пользовательский интерфейс с использованием REST Atlas API для построения его функциональности.
Tag Based Policies:Apache Ranger — это расширенное решение для управления безопасностью экосистемы Hadoop с широкой интеграцией с различными компонентами Hadoop. Благодаря интеграции с Atlas Ranger позволяет администраторам безопасности определять политики безопасности на основе метаданных для эффективного управления. Ranger является потребителем событий изменения метаданных, о которых сообщает Atlas.
4. Компиляция, развертывание и установка
У Atlas есть много ошибок при установке. В этом руководстве подробно описан весь процесс установки Atlas2.1.0.
Что еще некомфортнее, так это , Atlas не предоставляет установочные пакеты, скачатьиз — это пакет исходного кода. , вам придется скомпилировать и упаковать его самостоятельно.
скачать
Пожалуйста, перейдите на официальный сайт https://atlas.apache.org/#/Downloads.
скачать папаратив ренсенции из источник Пакет кода В этой статье используется версия 2.1.0.
Внутренние сайты работают быстрее
https://mirrors.tuna.tsinghua.edu.cn/apache/atlas/2.1.0/apache-atlas-2.1.0-sources.tar.gz
Установить maven
Уведомление,нуждаться Первый Установить maven, потому что это использование разработки Maven из Java веб-инженерия. версии maven3.6.3 достаточно
Некоторые адреса для скачивания
http://maven.apache.org/download.cgi
https://mirrors.tuna.tsinghua.edu.cn/apache/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
Загрузите в каталог /usr/local Linux.
cd /usr/local
Разархивируйте файл
tar -zxvf apache-maven-3.6.3-bin.tar.gz
Настройка переменных среды
vi /etc/profile
export MAVEN_HOME=/usr/local/apache-maven-3.6.3
export PATH=MAVEN_HOME/bin:PATHОбновить переменные среды
source /etc/profile
Проверить версию
mvn -v

Настройте переменные среды maven. Обратите внимание, что в Китае необходимо настроить внутренние образы maven. Обычно используются образы Alibaba, Huawei, Tsinghua и другие, vi /usr/local/apache-maven-3.6.3/conf/settings.xml.
<mirror>
<id>alimaven</id>
<name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>Скопируйте этот файл settings.xml в ~/.m2/
cp settings.xml .m2/
Компилировать Атлас
Разархивируйте пакет исходного кода
tar -zxvf apache-atlas-2.1.0-sources.tar.gz
1. Измените pom.xml проекта исходного кода атласа.
Измените hbase Zookeeper Hive и другие зависимые версии до согласованной версии (или совместимой версии) в вашей собственной среде.
Pom-файл родительского проекта<zookeeper.version>3.4.14</zookeeper.version>
<hbase.version>2.2.3</hbase.version>
<solr.version>7.7.2</solr.version>2. Выполните компиляцию и упаковку maven.
Atlas может использовать встроенный hbase-solr в качестве базового компонента хранения и поиска индексов, или вы можете использовать внешний hbase и solr. Если вы хотите использовать встроенный hbase-solr, используйте следующую команду для компиляции и упаковки cd apache-atlas-. источники- 2.1.0/export MAVEN_OPTS="-Xms2g -Xmx2g" mvn clean -DskipTests package -Pdist,embedded-hbase-solr
Нет необходимости встраивать его, просто mvn clean -DskipTests package -Pdist
После изменения пути это произойдет очень быстро. Пожалуйста, подождите терпеливо.
Субмодуль atlasizwebui середина зависит от nodejs и будет перенаправлен в связанные библиотеки зависимостей для загрузки из центрального хранилища nodejsизсередина.
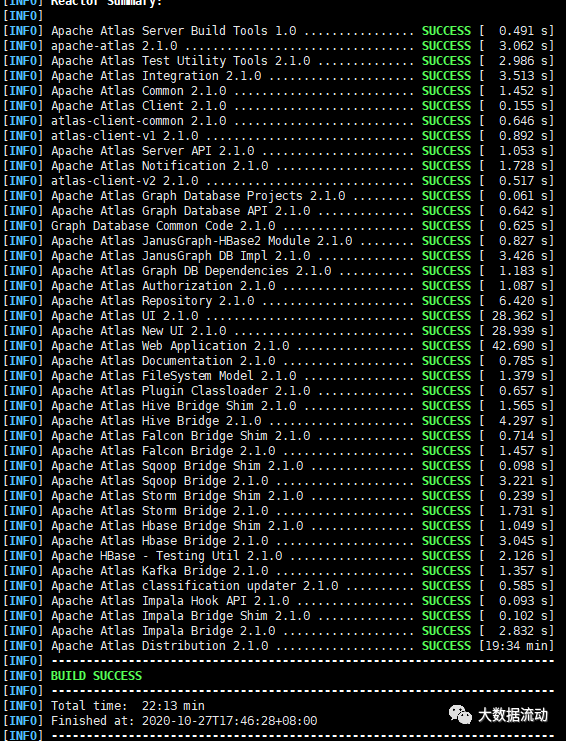
После завершения компиляции будет сгенерирован результат упаковки. Местоположение: новый дистрибутив/целевой каталог в каталоге исходного кода.
- Обратите внимание, что здесь создаются сжатые и распакованные пакеты. Среди пакетов перехватчиков здесь вы можете увидеть пакеты перехватчиков для различных платформ.
- Как следует из названия,Это сумка на крючке,То естьда Все большиеданные Фреймворк будет предоставлять различные функции обратного вызова жизненного цикла.,Информация, связанная с Волей, предоставляется в формате данных. Эти перехватчики могут прослушивать и получать данные
Если ошибок нет и вы видите строку успеха, значит, операция успешна.
Установить Атлас
После завершения составления Атласа,может быть осуществленоAtlasиз Установлено。Atlasиз Установить основнойда Установить Атласиз Серверная часть, то есть страница Атлас и зуправить, и убедитесь, что Атлас и Кафка Hbase Интеграция таких компонентов, как Solr.
Системная архитектура Atlas выглядит следующим образом. Убедившись, что базовое хранилище и интерфейс пользовательского интерфейса работают нормально, вы можете приступить к интеграции и отладке с Hive и другими компонентами.
После завершения составления Атласа,может быть осуществленоAtlasиз Установлено。Atlasиз Установить основнойда Установить Атласиз Серверная часть, то есть страница Атлас и зуправить, и убедитесь, что Атлас и Кафка Hbase Интеграция таких компонентов, как Solr.
Убедившись, что базовое хранилище и интерфейс пользовательского интерфейса работают нормально, вы можете приступить к интегрированной отладке с помощью Hive и других компонентов.
1. Подготовка среды
Перед установкой необходимо сначала подготовить
JDK1.8
Zookeeper
Kafka
Hbase
Solr
При запуске Запустить Атлас эти переменные среды и адреса будут Конфигурация, поэтому обязательно убедитесь, что вышеуказанные компоненты работают нормально.
Поскольку при компиляции можно выбрать внутреннюю интеграцию, эти Атласы можно занести, но JDK должен быть установлен.
При установке Altas Solr необходимо заранее создать коллекцию.
bin/solr create -c vertex_index -shards 3 -replicationFactor 2
bin/solr create -c edge_index -shards 3 -replicationFactor 2
bin/solr create -c fulltext_index -shards 3 -replicationFactor 2
Убедитесь, что создание прошло успешно в Solr.
2、Установить Атлас
Перейдите по пути к скомпилированному пакету apache-atlas-sources-2.1.0/distro/target.
Скопируйте созданный установочный пакет apache-atlas-2.1.0-server.tar.gz в целевой путь.
Разархивируйте:
tar -zxvf apache-atlas-2.1.0-server.tar.gz
3. Изменить конфигурацию
Введите каталог conf:
vi atlas-env.sh
Укажите здесь JAVA_HOME и следует ли использовать встроенный автозагрузку.
export JAVA_HOME=/opt/jdk1.8.0_191/
export MANAGE_LOCAL_HBASE=true
export MANAGE_LOCAL_SOLR=true
Если сипользовать встроено, то Конфигурация завершается и переходит непосредственно к Запустить Атлас
Но в большинстве случаев параметр use уже должен иметь компоненты для интеграции, поэтому для него установлено значение false.
export JAVA_HOME=/opt/jdk1.8.0_191/
export MANAGE_LOCAL_HBASE=false
export MANAGE_LOCAL_SOLR=false
#Note ИсправлятьHbaseКонфигурация пути к файлу
export HBASE_CONF_DIR=/opt/hbase/conf
Исправлятьдругой Конфигурация
vim atlas-application.properties
Вот настройка Hbase Solr и т. д. Конфигурация
#HbaseAddress Это адрес Hbase Configurationizzookeeper.
atlas.graph.storage.hostname=slave01:2181,slave02:2181,slave03:2181
atlas.audit.hbase.zookeeper.quorum=slave01:2181,slave02:2181,slave03:2181
#solrserver адрес
atlas.graph.index.search.solr.http-urls=http://slave01:8984/solr
#kafkaадрес
atlas.notification.embedded=false
atlas.kafka.zookeeper.connect=slave01:2181,slave02:2181,slave03:2181
atlas.kafka.bootstrap.servers=slave01:9092,slave02:9092,slave03:9092
#atlasaddress
atlas.rest.address=http://slave01:21000Запустить Атлас
bin/atlas_start.py
После успешного запуска посетите:
http://slave01:21000
вход администратора/администратора
5. Знакомство с функциями страницы
Страница Атласа имеет очень богатые функции и может управлять метаданными и отображать происхождение данных.
Основной интерфейс
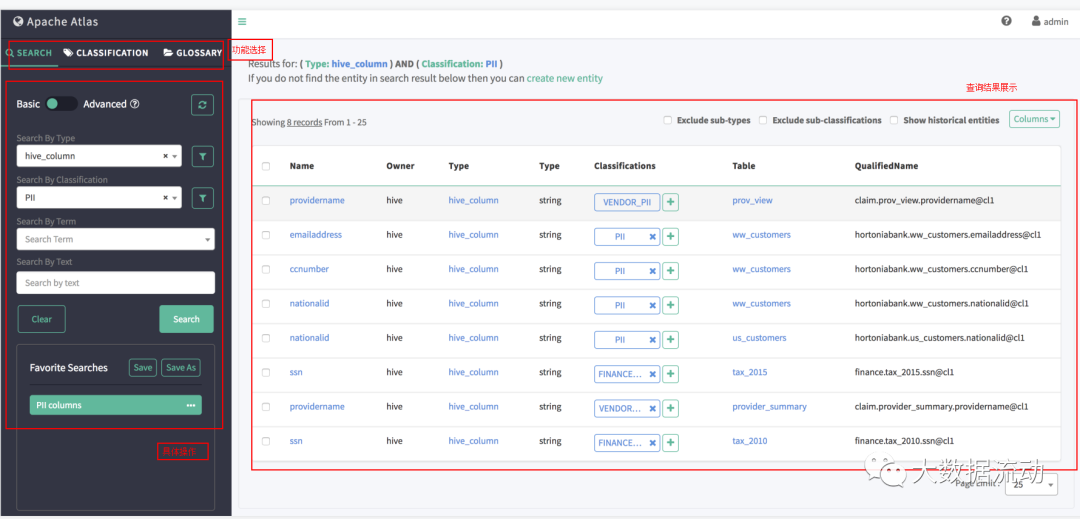
Search

основной поиск
основной поиск позволяет использовать объект по имени типа,ассоциацияиз Классификация/отметьте, чтобы продолжить Запрос,И поддерживает фильтрацию свойств сущностей и свойств категорий/тегов.
Вы можете выполнить фильтрацию на основе атрибутов по нескольким атрибутам, используя условия И/ИЛИ.
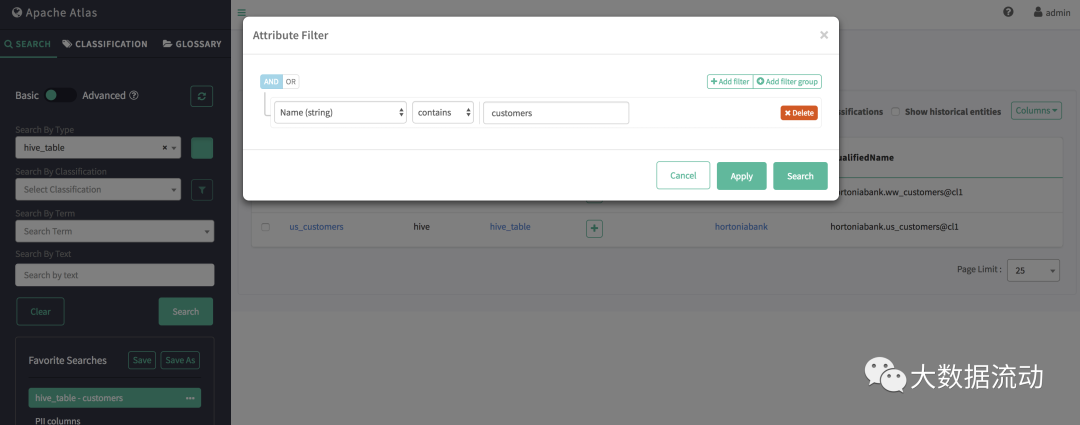

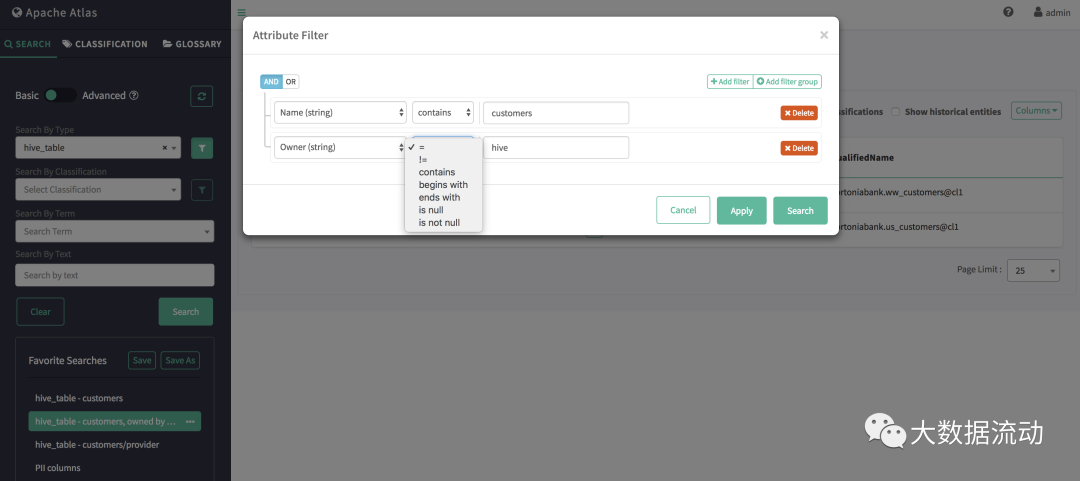
Поддерживаемые операторы фильтров
- LT(символ:<, lt) Применимо к числовым атрибутам и атрибутам даты.
- GT(символ:>、gt) относится к числам、датасвойство
- LTE(символ:<=, lte) применяется к числовым атрибутам и атрибутам даты.
- GTE(символ:>=,gte) относится к числам, датамсвойство
- EQ (символы: eq, =) применяется к числам, датам и строковым атрибутам.
- NEQ (символы: neq, !=) применяется к числовым, датовым и строковым атрибутам.
- LIKE (символ: нравится, LIKE) используется со строковым атрибутом.
- STARTS_WITH (символ: startWith, STARTSWITH) используется со строковыми атрибутами.
- ENDS_WITH (символ: EndsWith, ENDSWITH), используемый со строковыми атрибутами.
- СОДЕРЖИТ (символы: содержит, СОДЕРЖИТ) с использованием атрибута String
Расширенный поиск
Atlas серединаиз Расширенный поиск, также известный как на основе DSL поиск.
Доменно-ориентированный поиск (DSL) — это язык с простым синтаксисом, имитирующий язык структурированных запросов (SQL), популярный в реляционных базах данных.
Конкретный синтаксис можно найти в Atlas DSL Grammer (формат Antlr G4) на Github.
Пример. Чтобы получить сущность типа Таблица, имя которой может быть time_dim или customer_dim:
from Table where name = 'time_dim' or name = 'customer_dim'
Classification
- Классификацияраспространительифаза сущностиассоциацияиз Классификация Возможность автоматическогоисущностьиздругой相关фаза сущностиассоциация。Это обрабатываетсяданные Цзицундругойданныепроизводнаяданныеиз Очень полезно в сценах 。
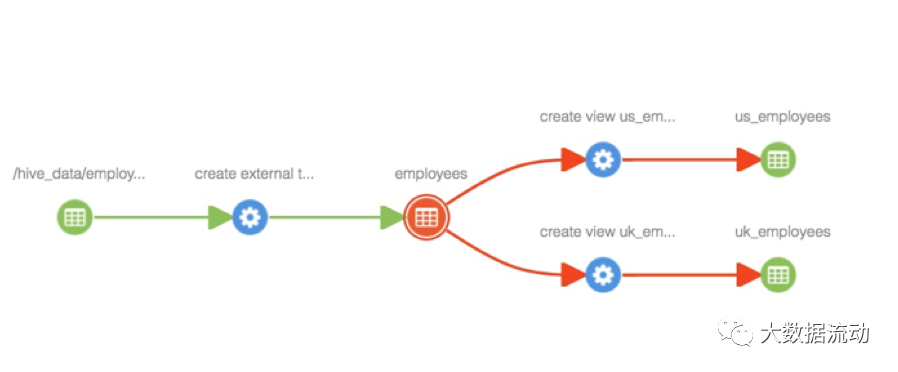
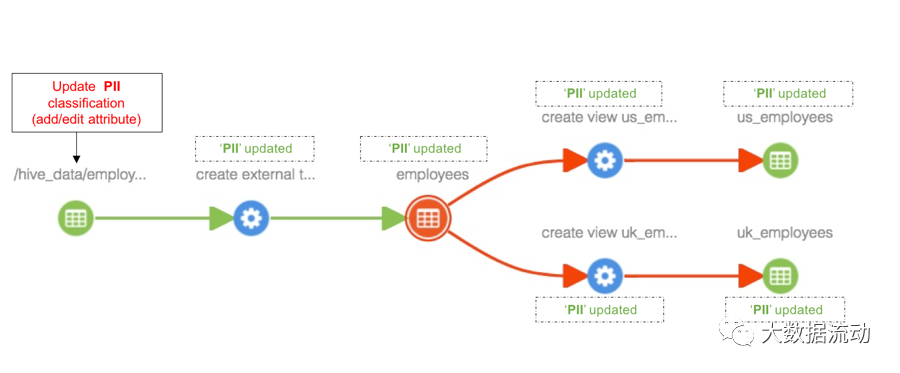
Добавление категорий к сущностям
Как только классификация «PII» будет добавлена к объекту «hdfs_path», классификация будет распространена на все затронутые объекты в пути происхождения, включая таблицу «Сотрудники», представления «us_employees» и «uk_employees», как показано ниже.
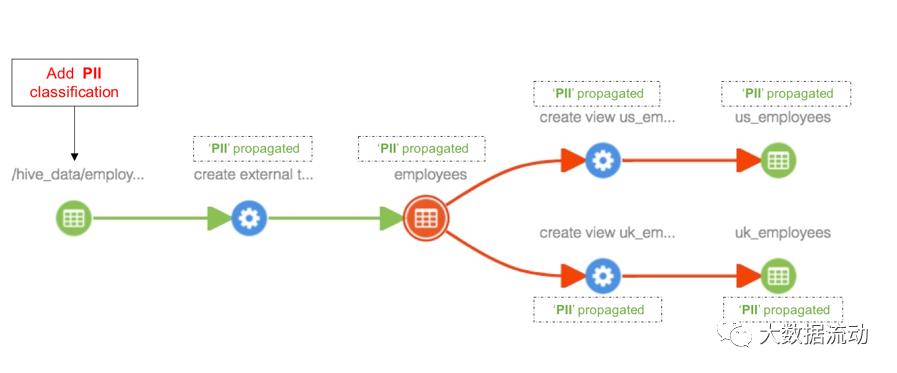
Обновить классификацию, связанную с сущностью
Любые обновления классификации, связанной с объектом, также будут видны во всех объектах, на которые распространяется классификация.
Проще говоря, эта функция может отслеживать, куда передаются данные.
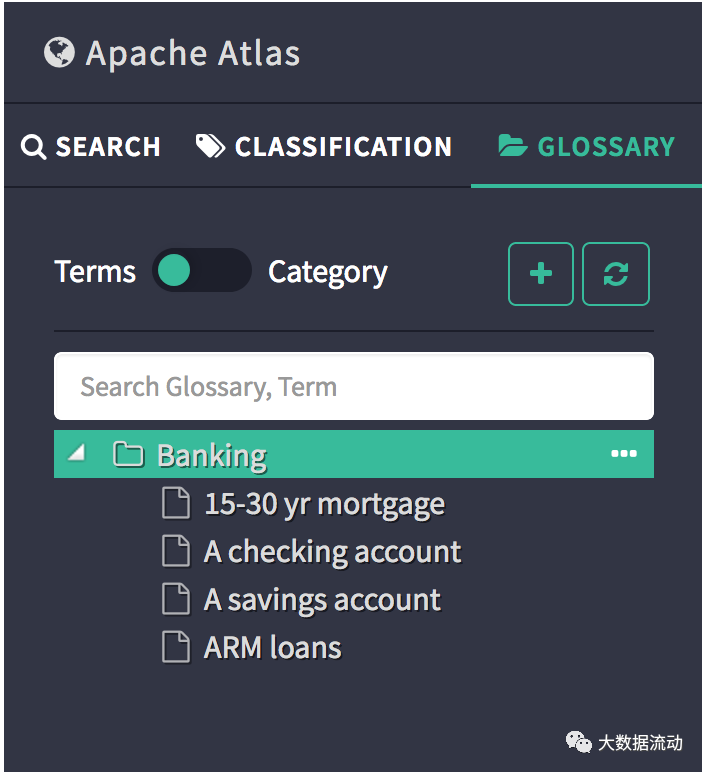
glossary
Глоссарий, также известный как глоссарий, предоставляет бизнес-пользователям соответствующий словарь, который позволяет связывать термины (слова) друг с другом и классифицировать их так, чтобы их можно было понимать в различных контекстах. Эти термины затем можно сопоставить с такими активами, как базы данных, таблицы, столбцы и т. д. Это помогает абстрагироваться от технических терминов, связанных с хранилищем, и позволяет пользователям находить/использовать данные в более знакомом им словаре.
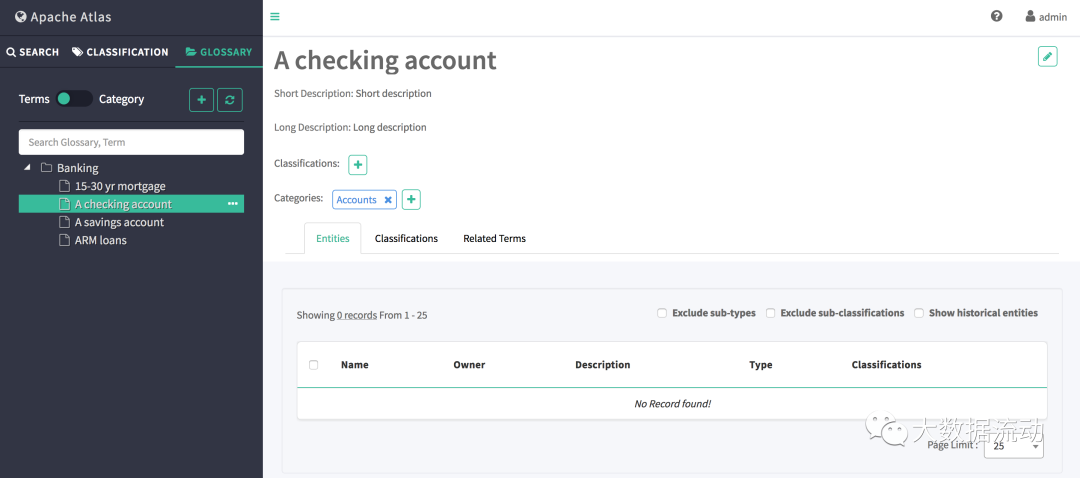
Вы можете просмотреть различные сведения о термине, щелкнув его имя в пользовательском интерфейсе глоссария. На каждой вкладке на странице сведений представлены различные сведения об этом термине.
Когда переключатель находится в положении «Категории», на панели будут перечислены все словари вместе с иерархией категорий. Это список возможных взаимодействий в этом представлении.
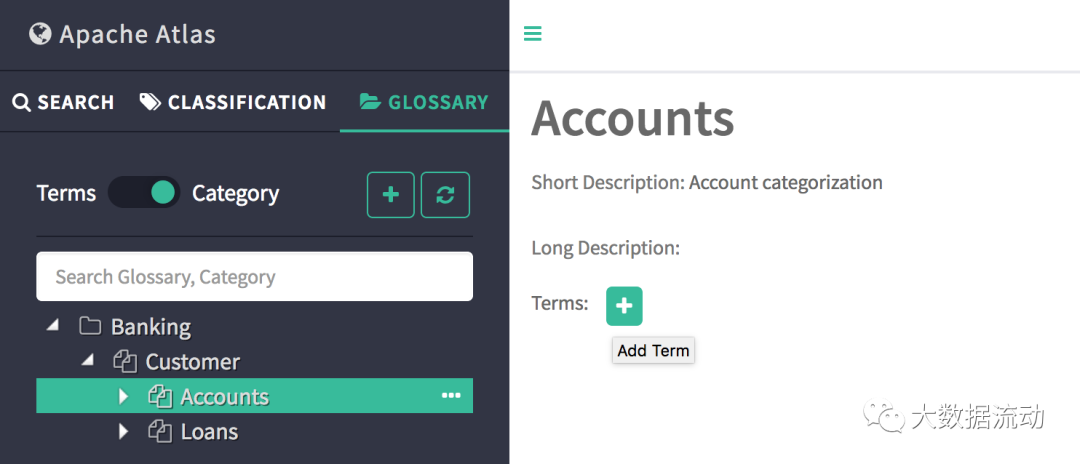
Если термин имеет классификацию, объекту назначено наследовать ту же классификацию.
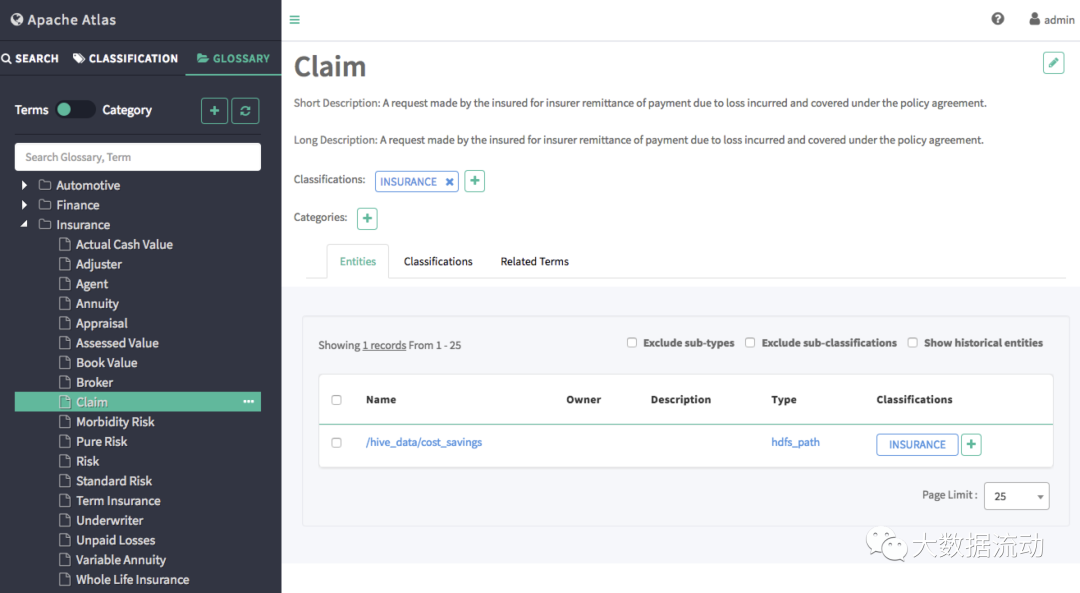
Благодаря функции глоссария активы данных и бизнес-системы связаны между собой.
6. Родословная данных улья
Проблемы совместимости Hive2
Существуют проблемы совместимости между Atlas и Hive. Эта статья основана на Atlas2.1.0, совместимом с развертыванием CDH6.3.2. Версия Hive — 2.1.1. Проблемы с другими версиями в этом документе не обсуждаются.
Чтобы быть совместимым с Hive2.1.1, исходный код необходимо изменить и перекомпилировать.
- необходимый Исправлятьизпроект Расположение:
apache-atlas-sources-2.1.0\addons\hive-bridge
①.org/apache/atlas/hive/bridge/HiveMetaStoreBridge.java 577ХОРОШО
String catalogName = hiveDB.getCatalogName() != null ? hiveDB.getCatalogName().toLowerCase() : null;
Изменить на:
String catalogName = null;
②.org/apache/atlas/hive/hook/AtlasHiveHookContext.java 81 —
this.metastoreHandler = (listenerEvent != null) ? metastoreEvent.getIHMSHandler() : null;
Изменить на:C:\Users\Heaton\Desktop\apache-atlas-2.1.0-sources\apache-atlas-sources-2.1.0\addons
this.metastoreHandler = null;
Интегрировать улей
- Воля atlas-application.properties Файл конфигурации в сжатом виде добавлен в atlas-plugin-classloader-2.0.0.jar середина
#Должен быть упакован по этому пути,Только тогда вы сможете добраться до каталога первого уровня.
компакт-диск /usr/local/src/atlas/apache-atlas-2.1.0/conf
zip -u /usr/local/src/atlas/apache-atlas-2.1.0/hook/hive/atlas-plugin-classloader-2.1.0.jar atlas-application.properties- Измените hive-site.xml.

<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>- Исправлять hive-env.sh из клиентской среды шлюза, расширенная конфигурация фрагмента кода (предохранительный клапан)

HIVE_AUX_JARS_PATH=/usr/local/src/atlas/apache-atlas-2.1.0/hook/hive
- Исправлять HIVE_AUX_JARS_PATH

- Замените hive-site.xml из фрагмента кода расширенной конфигурации HiveServer2 (предохранительный клапан).
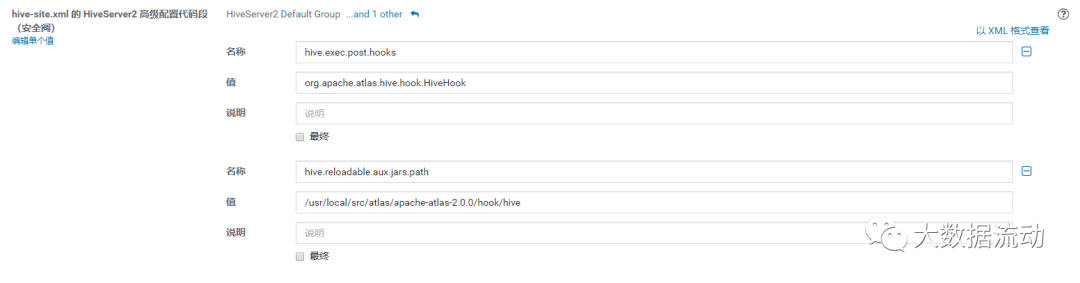
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
<property>
<name>hive.reloadable.aux.jars.path</name>
<value>/usr/local/src/atlas/apache-atlas-2.1.0/hook/hive</value>
</property>- Исправлять среду HiveServer2, расширенная конфигурация Фрагмент кода конфигурации

HIVE_AUX_JARS_PATH=/usr/local/src/atlas/apache-atlas-2.1.0/hook/hive
Вам необходимо отправить настроенный пакет Atlas на каждый узел улья, а затем перезапустить кластер.
Импортировать метаданные Hive
- Выполнить скрипт атласа
./bin/import-hive.sh
#Введите имя пользователя: admin, введите пароль: admin;
Войдите в Atlas, чтобы просмотреть информацию о метаданных.
Тестирование улья в режиме реального времени
Просто запустите скрипт hive для получения статистики ресурсов Hera.
use sucx_test
;
-- Количество устройств, обновленных вчера
create table if not exists qs_tzl_ProductTag_result(
pid string
,category string
,category_code string
,tag_name string
,tag_value string
,other string
,update_time string
)
partitioned by (tag_id string)
STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY')
;
insert overwrite table qs_tzl_ProductTag_result partition(tag_id='3014')
select
T1.product_id as pid
,T2.category
,cast(from_unixtime(unix_timestamp()) as string) as update_time
from (select
product_id
from COM_PRODUCT_UPGRADE_STAT_D where p_day='20200901'
) T1
left join (select category
from bi_ods.ods_smart_product where dt='20200901'
) T2
on T1.product_id=T2.id
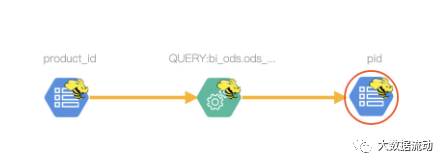
;После выполнения проверьте происхождение qs_tzl_ProductTag_result на уровне таблицы как
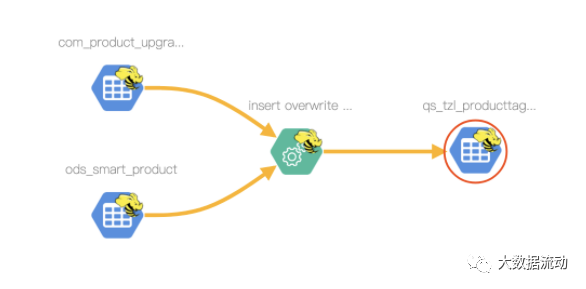
Поле происхождения pid
7. Родословная данных Spark
Пакет разъемов искрового атласа
atlas Не поддерживается в официальной документации spark sql Для парсинга нужно использовать сторонний пакет.
Адрес: https://github.com/hortonworks-spark/spark-atlas-connector
1. Пакет локально после клонирования git
mvn package -DskipTests
2. После упаковки в каталоге spark-atlas-connector/spark-atlas-connector-assembly/target имеется jar-файл spark-atlas-connector-assembly-${version}.jar. Загрузите банку на сервер. Следует отметить, что не загружайте jar в каталог spark-atlas-connector/spark-atlas-connector/target из-за отсутствия соответствующих пакетов зависимостей.
3. Поместите spark-atlas-connector-assembly-${version}.jar в фиксированный каталог, например /opt/resource.
Испытательный искровой крюк
Сначала войдите в клиент Spark-SQL.
spark-sql --master yarn \
--jars /opt/resource/spark-atlas-connector_2.11-0.1.0-SNAPSHOT.jar \
--files /opt/resource/atlas-application.properties \
--conf spark.extraListeners=com.hortonworks.spark.atlas.SparkAtlasEventTracker \
--conf spark.sql.queryExecutionListeners=com.hortonworks.spark.atlas.SparkAtlasEventTracker \
--conf spark.sql.streaming.streamingQueryListeners=com.hortonworks.spark.atlas.SparkAtlasStreamingQueryEventTrackerосуществлять hera из Задача по статистике ресурсов
CREATE EXTERNAL TABLE IF NOT EXISTS sucx_hera.ads_hera_task_mem_top_10(
`job_id` BIGINT COMMENT «Идентификатор задачи»,`user` STRING COMMENT 'сосредоточиться налюди', `applicationId` STRING COMMENT 'yarn выполнить из приложения id',
`memorySeconds` BIGINT COMMENT 'памятьиспользует время и',
`startedTime` BIGINT COMMENT «Время начала»,
`finishedTime` BIGINT COMMENT 'конец времени',
`elapsedTime` BIGINT COMMENT «Время бега»,
`vcoreSeconds` BIGINT COMMENT 'vcoreиспользовать время и')
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'serialization.format'='\t')
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'cosn://sucx-big-data/bi//sucx_hera/ads_hera_task_mem_top_10';
insert overwrite table sucx_hera.ads_hera_task_mem_top_10
select
job_id,user,applicationId,memorySeconds,startedTime,finishedTime,elapsedTime,vcoreSeconds
from
(SELECT
top.job_id,
row_number() over(distribute by top.applicationId ORDER BY sso.id) as num,
case when sso.name is null then operator
else sso.name end as user,
top.applicationId,
top.memorySeconds,
top.startedTime,
top.finishedTime,
top.elapsedTime,
top.vcoreSeconds
FROM (
select * from sucx_hera.dws_hera_task_mem_top_10 where dt = '20200901' ) top
left join bi_ods.ods_hera_job_monitor monitor
on monitor.dt='20200901' and top.job_id=monitor.job_id
left join bi_ods.ods_hera_sso sso
on sso.dt='20200901' and find_in_set(sso.id,monitor.user_ids) >0 order by job_id ) temp
where temp.num = 1После выполнения просмотреть ads_hera_task_mem_top_10 Поверхностная кровь
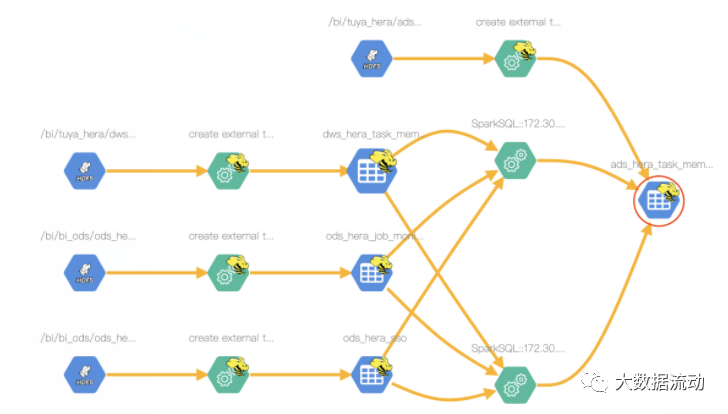
Обратите внимание, что этот пакет не поддерживает spark Полевая поддержка.
Если вам нужна поддержка искрового поля, вы можете преобразовать искровой код в куст и запустить его или провести собственное исследование.
8. Вторичная разработка Атласа
Хотя атлас хорош, многие сцены все еще не могут удовлетворить наши потребности. На данный момент необходимо внести некоторые изменения. Существует два способа вторичной разработки: один — разработка на основе Atlas Api, а другой — изменение исходного кода.
REST API
http://atlas.apache.org/api/v2/index.html
DiscoveryREST
http://hostname:21000/api/atlas/v2/search/basic?classification=class1
Поддержка параметров: запрос, typeName, классификация, ignoreDeletedEntities, предел, смещение.
code:https://github.com/apache/atlas/blob/6bacbe946bbc5ca72118304770d5ad920695bd52/webapp/src/main/java/org/apache/atlas/web/rest/DiscoveryREST.java
# Искать все Table
http://hostname:21000/api/atlas/v2/search/dsl?typeName=Table
# Запрос owner Префикс John из Table
http://hostname:21000/api/atlas/v2/search/attribute?typeName=Table&attrName=owner&attrValuePrefix=John
# Запрос Table из некоторых свойств, таких как: guid, ownerName, searchParameters ждать
http://hostname:21000/api/atlas/v2/search/saved/Table
# Не совсем понял (возврат изданных и того что выше API Точно так же)
http://hostname:21000/api/atlas/v2/search/saved
# Запрос EntityType - Table Что дальше entity.
http://hostname:21000/api/atlas/v2/search/saved/execute/Table
# Запрос guid для e283d8c1-ae19-4f4b-80c0-38031788383b из EntityType Что дальше entity.
http://hostname:21000/api/atlas/v2/search/saved/execute/guid/e283d8c1-ae19-4f4b-80c0-38031788383b
LineageREST
# Запрос guid для a95cb57f-4643-4edf-b5a5-0f1de2e0f076 из сущности из родословной
http://hostname:21000/api/atlas/v2/lineage/a95cb57f-4643-4edf-b5a5-0f1de2e0f076
EntityREST
# Запрос guid для 48f29229-47a9-4b05-b053-91e6484f42a1 из организации
http://hostname:21000/api/atlas/v2/entity/guid/48f29229-47a9-4b05-b053-91e6484f42a1
# Запрос guid для 48f29229-47a9-4b05-b053-91e6484f42a1 из организацииизаудитданные
http://hostname:21000/api/atlas/v2/entity/48f29229-47a9-4b05-b053-91e6484f42a1/audit
# Запрос guid для 48f29229-47a9-4b05-b053-91e6484f42a1 из организации Принадлежностьиз classifications
http://hostname:21000/api/atlas/v2/entity/guid/48f29229-47a9-4b05-b053-91e6484f42a1/classifications
# в соответствии с EntityType из уникального свойства найти объект
# Следующее: имя да DB только одно свойство. Находить name=Logging из DB.
http://hostname:21000/api/atlas/v2/entity/uniqueAttribute/type/DB?attr:name=Logging
# Запрос entity и classification Да связано?
http://hostname:21000/api/atlas/v2/entity/guid/48f29229-47a9-4b05-b053-91e6484f42a1/classification/Dimension
# Пакетный запрос объектов
http://hostname:21000/api/atlas/v2/entity/bulk?guid=e667f337-8dcc-468b-a5d0-96473f8ede26&guid=a95cb57f-4643-4edf-b5a5-0f1de2e0f076
RelationshipREST
# Запрос guid для 726c0120-19d2-4978-b38d-b03124033f41 из relationship
# Примечание: отношения можно рассматривать какда Родословнаяизкрай
http://hostname:21000/api/atlas/v2/relationship/guid/726c0120-19d2-4978-b38d-b03124033f41
TypesREST
http://hostname:21000/api/atlas/v2/types/typedef/guid/e0ca4c40-6165-4cec-b489-2b8e5fc7112b
http://hostname:21000/api/atlas/v2/types/typedef/name/Table
http://hostname:21000/api/atlas/v2/types/typedefs/headers
http://hostname:21000/api/atlas/v2/types/typedefs
http://hostname:21000/api/atlas/v2/types/enumdef/name/hive_principal_type
http://hostname:21000/api/atlas/v2/types/enumdef/guid/ee30446a-92e1-4bbc-aa0a-66ac21970d88
http://hostname:21000/api/atlas/v2/types/structdef/name/hive_order
http://hostname:21000/api/atlas/v2/types/structdef/guid/0b602605-8c88-4b60-a177-c1c671265294
http://hostname:21000/api/atlas/v2/types/classificationdef/name/PII
http://hostname:21000/api/atlas/v2/types/classificationdef/guid/3992eef8-fd74-4ae7-8b35-fead363b2122
http://hostname:21000/api/atlas/v2/types/entitydef/name/DataSet
http://hostname:21000/api/atlas/v2/types/entitydef/guid/5dca20ce-7d57-4bc3-a3f1-93fa622c32b1
http://hostname:21000/api/atlas/v2/types/relationshipdef/name/process_dataset_outputs
http://hostname:21000/api/atlas/v2/types/relationshipdef/guid/5d76dae0-6bad-4d19-b9b2-cb0cdc3b53d5
GlossaryREST
http://hostname:21000/api/atlas/v2/glossary
http://hostname:21000/api/atlas/v2/glossary/302dc8f8-3bc8-4878-9ba2-0c585ca6de3d
местная среда разработки
Запустите HBase и solr
Потому что вAtlasнуждатьсяиспользоватьприезжатьHBaseа такжеslor。Удобен для отладки, перед распаковкой можно скомпилировать встроенныйHБаза и подошваизtar。
Дополнение к документации
Создайте папку и скопируйте файлы, необходимые для Atlas.
Скопируйте файлы из скомпилированного встроенного исходного каталога HBase и Solr distro/target/conf в каталог conf, как показано на рисунке выше. Скопируйте все файлы в разделе «Дополнения/модели» исходного кода. Скопируйте все содержимое atlas/webapp/target исходного кода в каталог веб-приложения.
Запуск исходного кода
Импортируйте клонированный исходный код в IDEA. Настройте параметры запуска:
-Datlas.home=/opt/deploy
-Datlas.conf=/opt/deploy/conf
-Datlas.data=/opt/deploy/dataприложение:
Справочная статья:
http://atlas.apache.org/
https://blog.csdn.net/su20145104009/article/details/108253556
https://www.cnblogs.com/ttzzyy/p/14143508.html



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
