MORA: LORA помогает диагностировать мультимодальные заболевания с отсутствующими модальными заболеваниями!

Мультимодальные предварительно обученные модели могут эффективно извлекать и объединять функции из разных модальностей, имеют низкие требования к памяти и легко настраиваются. Однако, несмотря на их высокую эффективность, применение этих моделей в диагностике заболеваний до конца не изучено. Важной проблемой является то, что часто появляются недостающие модальности, что ухудшает производительность. Кроме того, тонкая настройка всей предварительно обученной модели требует большого количества вычислительных ресурсов. Для решения этих проблем автор предлагает вычислительно эффективный метод, а именно низкоранговую адаптацию с учетом модальности (MoRA). MoRA сопоставляет каждый вход с низкими внутренними измерениями, но использует различные аппроекции с учетом модальности для адаптации к конкретной модальности при наличии отсутствующих модальностей. Фактически, первая часть MoRA, интегрированная в модель, может значительно улучшить производительность при отсутствии одного из методов. Для этого требуется менее 1,6% обучаемых параметров по сравнению с обучением всей модели. Результаты экспериментов показывают, что MoRA превосходит существующие технологии диагностики заболеваний, демонстрируя превосходную производительность, надежность и эффективность обучения. Ссылка на код: https://github.com/zhiyiscs/MoRA.
1 Introduction
Мультимодальные предварительно обученные модели достигли больших успехов в общих задачах компьютерного зрения, включая классификацию и регрессию [1, 2, 8]. Предварительное обучение на широком спектре разнообразных наборов данных позволяет мультимодальным предварительно обученным моделям понимать сложные закономерности и взаимосвязи между различными модальностями, такими как изображения, текст, аудио и видео. Более того, уже существующие знания уменьшают потребность в больших объемах конкретных данных при использовании этих моделей в качестве последующих задач.
В последние годы исследователи внедрили предварительно обученные модели в медицинскую область, обучая мультимодальные модели на больших наборах медицинских данных [3, 4, 13]. Однако существуют две основные проблемы при применении этих моделей для диагностики заболеваний в реальных клинических условиях. Прежде всего, при диагностике фактического заболевания довольно часто рентгеновское изображение пациента (например, рентгенограмма грудной клетки) является полным, но соответствующая аннотация отсутствует. Однако эксперименты доказали, что при отсутствии модальностей производительность мультимодальных предварительно обученных моделей резко падает [8]. Во-вторых, большинство предварительно обученных моделей основаны на крупномасштабных моделях Transformer, поэтому точная настройка всей предварительно обученной модели по-прежнему обходится очень дорого.
Большинство соответствующих новаторских исследований сосредоточено на улучшении структуры модели, но этот подход не может быть напрямую применен к точной настройке предварительно обученной модели. Многие исследования [10, 5] также используют интерполяцию, т. е. заполнение недостающих модальностей на основе других полных модальных входных данных. Однако когда количество мод относительно невелико (например, две или три), интерполяция оказывается очень неробастной и может привести к ухудшению результатов. Для точной настройки мультимодальных предварительно обученных моделей Ли и др. [6] впервые представили концепцию мультимодальных подсказок, которая использует MAP (т.е. подсказки, которые повышают производительность при использовании отсутствующих модальностей) для улучшения недостающих модальностей в обучении. и тестовые наборы времени. Однако MAP не обладают устойчивостью к различным отсутствующим параметрам модальности при обучении и тестировании. Помимо MAP, Цзян и др. [7] предложили подсказки, специфичные для модальности (MSP), которые более устойчивы к различным настройкам удаления по сравнению с MAP. Однако для достижения оптимальной производительности MSP по-прежнему необходимо подключать к нескольким уровням.
Вдохновленные низкоранговой адаптацией (LoRA) [9], авторы предлагают низкоранговую адаптацию с учетом модальности (MoRA) для повышения производительности и надежности перед лицом отсутствующих модальностей в обучающих и тестовых наборах данных. В частности, MoRA обеспечивает адаптацию с учетом модальности путем сопоставления каждого входного сигнала с низкой эндогенной размерностью при использовании различных верхних элементов с учетом модальности. Эти адаптации способны идентифицировать уникальные характеристики каждой модальности, тем самым повышая надежность и производительность модели в отсутствие определенных модальностей. Ключевым преимуществом MoRA по сравнению с существующими методами тонкой настройки является эффективность его реализации. Его необходимо только интегрировать в начальный модуль модели, и он может привести к значительным улучшениям при работе с отсутствующими модальностями. В процессе тонкой настройки все параметры, которые необходимо обучить, — это только MoRA и классификатор. Таким образом, метод авторов ограничивает параметры обучения до 1,6% от общих параметров модели, что позволяет модели достичь более высокой производительности при точной настройке небольших наборов данных (тысячи выборок). Экспериментальные результаты автора демонстрируют эффективность MoRA, которая не только обладает более высокой точностью и надежностью, чем существующие методы, но и повышает эффективность обучения.
Основной вклад автора:
- Автор вводит мультимодальную модель предварительного обучения в диагностику заболеваний.,А MoRA предлагается для повышения производительности и надежности в случае отсутствия данных по обучению и концентрации тестов.
- По сравнению с другими методами тонкой настройки с использованием недостающих модальностей, метод автора обеспечивает высочайшую производительность и надежность.
- Авторы провели комплексные эксперименты с использованием модальностей с разной частотой пропусков.,Чтобы доказать это с разными модальными недостающими пропорциями,Авторский метод обладает превосходной производительностью и надежностью.
2 Method
Problem Definition
Для простоты авторы объясняют свой подход, рассматривая диагностику заболеваний, представленную двумя модальностями, как ситуацию. Например, это может быть выражено как и (например, изображение и текст). Авторы представляют этот набор данных как . Здесь часть, которая представляет существование двух модальностей одновременно, называется модальным полным подмножеством. Напротив, и представляют собой подмножества с неполной модальностью, такие как пациенты, использующие только изображения или только текст, у которых одна модальность отсутствует. Как показано на рисунке 1, набор данных включает полных пациентов (обозначается ), пациентов только с текстом (обозначается ) и пациентов только с изображениями (обозначается ).
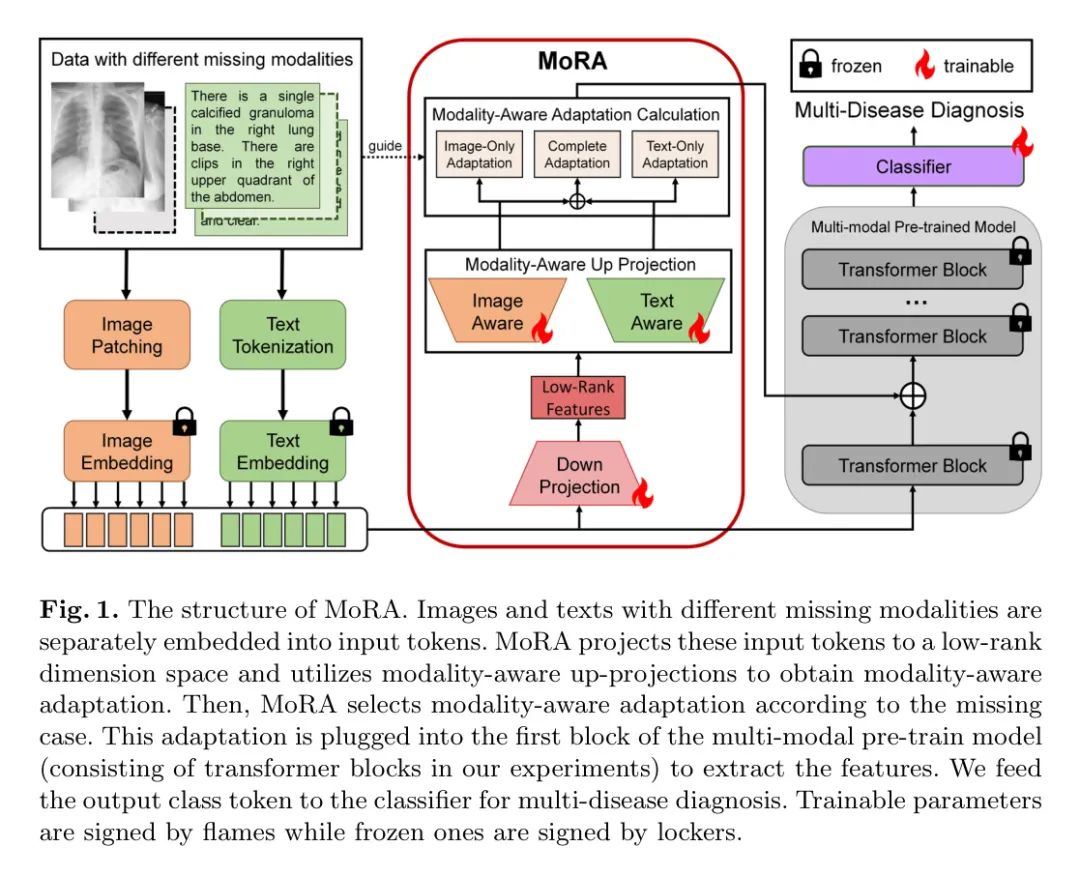
Чтобы сохранить формат мультимодальных входных данных для мультимодальности в мультимодальных предварительно обученных моделях, авторы просто назначают пустые строки или пиксели (например, для текста или изображений) пациентам с отсутствующими модальностями и генерируют , . Таким образом, весь набор данных о пациентах может быть реформирован.
Modality-Aware Low-Rank Adaptation
Адаптация низкого ранга широко использовалась при точной настройке больших языковых моделей. Его основной механизм — заморозить веса предварительно обученной модели и внедрить обучаемую матрицу рангового разложения в предварительно обученную модель. Теория LoRA утверждает, что при адаптации внутренний ранг обновлений веса снижается. Для предварительно обученной матрицы весов LoRA ограничивает ее обновления, используя разложение низкого ранга, где и ранг. Во время обучения зависает и не получает обновлений градиента, хотя и содержит обучаемые параметры. Обратите внимание, что и умножаются на одни и те же входные данные, а их выходные векторы суммируются отдельно с соответствующими координатами. Улучшенные результаты прямого распространения следующие:
где и представляют входные и выходные функции соответственно. Автор будет относиться к этому как к адаптации (называемой) к вводу. На практике ранг всегда устанавливается на небольшое число (например, 4), чтобы LoRA можно было обучать в рамках ограниченных вычислительных ресурсов.
В дополнение к LoRA автор предлагает LoRA, учитывающую модальную осведомленность. Отличием от LoRA является введение адаптации модальной осведомленности. Авторы используют единую нисходящую проекцию для проецирования всех входных данных в измерения низкого ранга для получения функций низкого ранга. Для каждой модальности авторы отдельно указывают конкретную восходящую проекцию с учетом модальности (обозначают и ). После выборки и суммирования MoRA вычисляет пригодность на основе пропущенных случаев. В частности, если у пациента есть данные определенной модальности, MoRA добавит соответствующую модальность к адаптации, и наоборот. Следовательно, для подмножества соответствующая адаптация с учетом модальности выглядит следующим образом:
в,,. Выбранные адаптации будут вставлены в первый блок мультимодальной предварительно обученной модели, чтобы повысить устойчивость к отсутствующим модальностям. На начальном этапе авторы используют случайную инициализацию по Гауссу и инициализируют сумму нулем, поэтому пригодность равна нулю в начале обучения.
Overall Framework
Следуя реализации в [8, 6, 7], авторы используют мультимодальный предварительно обученный Transformer ViLT [1] в качестве базовой модели, которая предназначена для обработки двух модальностей: изображений и текста. Структура авторского метода представлена на рисунке 1. Обучаемые параметры представлены пламенем, а фиксированные параметры представлены шкафами. У пациентов есть изображения и текст с различными недостающими модальностями. Для отсутствующих модальностей авторы используют ввод-заполнитель (для отсутствующего текста — пустая строка; для отсутствующих изображений — нулевая матрица). Это используется для поддержания общего количества входных токенов для предварительно обученной модели. Авторы используют фиксированный предварительно обученный процесс внедрения для преобразования данных во входные токены. Авторы фактически применили MoRA в предыдущем блоке предварительно обученной модели (блок Transformer в ViLT).
3 Experiments
Datasets
Набор данных рентгенограммы грудной клетки (CXR)[20] Открытый источник данных Университета Индианы. В этом наборе данных содержатся рентгенограммы грудной клетки 3794 пациентов, соответствующие аннотации и различные заболевания, диагностированные несколькими экспертами. Всего насчитывается 120 различных заболеваний, и в качестве диагностических целей авторы выбрали 20 наиболее часто встречающихся. Обратите внимание, что этот набор данных содержит две проекции рентгенограмм: фронтальную и боковую. В данной статье авторы уделяют особое внимание фронтальной проекции.
Набор данных интеллектуальной идентификации офтальмологических заболеваний (ODIR)[21] Получено на основе офтальмологической базы данных, предназначенной для отражения фактических коллекций пациентов, собранных в больницах. Он включает данные о 3500 пациентах, в частности создан для помощи в диагностике заболеваний глаз. Этот набор данных охватывает различные методы, включая демографическую информацию, клинические текстовые аннотации для обоих глаз и изображения глазного дна для каждого глаза.
Прогнозируемые подразделения заболеваний и типы набора данных автора показаны в таблице 1.
Implementation Details
Код автора в основном основан на PyTorch и использует PyTorch Lightning для обучения и тестирования инкапсуляции вывода. Все эксперименты проводятся на графическом процессоре NVIDIA RTX A4000. Учитывая, что наша модель прогнозирует несколько заболеваний одновременно, мы устанавливаем отдельную бинарную кросс-энтропийную потерю для каждого заболевания.
Для MoRA и всех базовых методов авторы применяют одинаковые настройки для сравнения эффективности. Авторы замораживают все параметры ViLT и используют тот же обучаемый классификатор (включая два линейных слоя). Автор использует оптимизатор AdamW для обучения с размером партии 4 и снижением веса 2e-2. Автор устанавливает максимальную скорость обучения 5e-3, причем скорость обучения прогревается на уровне 2% от общего числа шагов обучения, а затем линейно снижается до нуля. Авторы обучили каждую модель, используя одно и то же разделение обучения, проверки и тестирования, и провели 40 эпох для каждой модели. Если результаты не улучшатся в течение 5 циклов, тренировка будет прекращена досрочно. Авторы использовали шкалу F1-Macro для оценки эффективности прогнозирования множества заболеваний.
Comparisons with the previous method
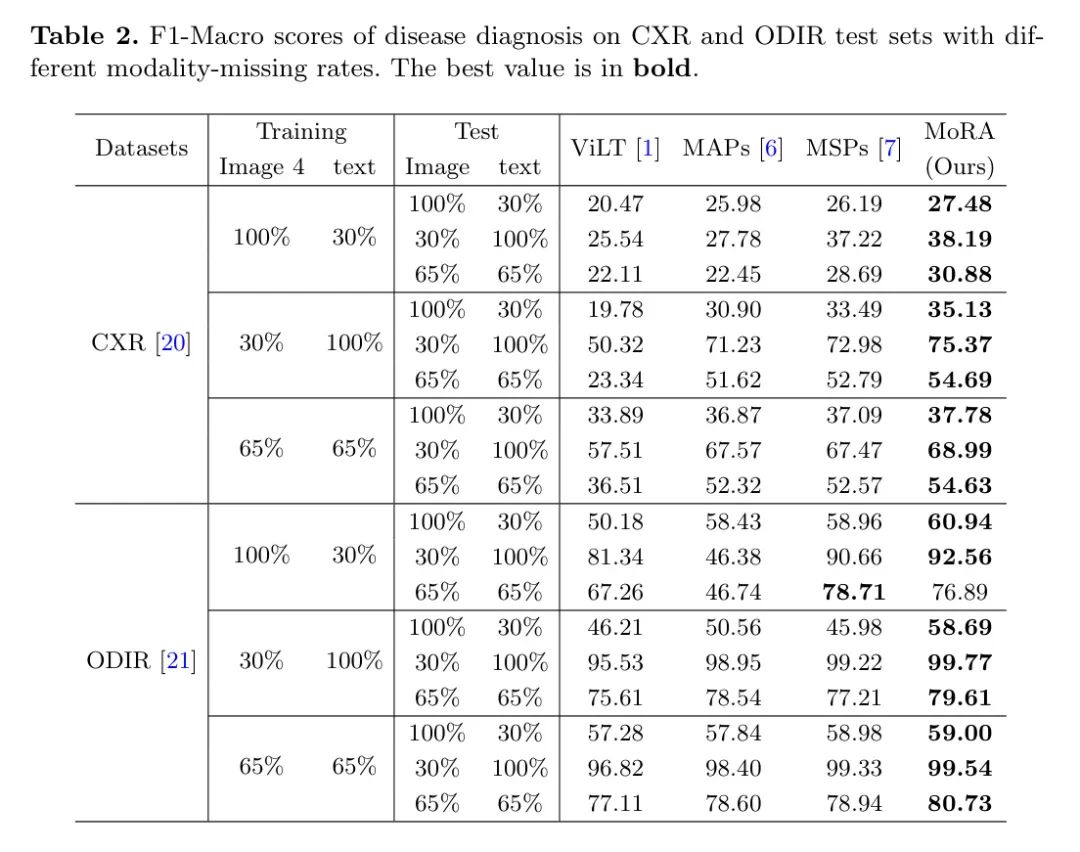
В этой части авторы проводят эксперименты с различными настройками по умолчанию в наборах обучающих и тестовых данных, чтобы сравнить MoRA с тремя предыдущими методами. Результаты эксперимента F1-Macro показаны в таблице 2. Можно заметить, что MoRA достигает наилучших результатов в большинстве сценариев отсутствия, даже если показатели пропуска в наборах данных для обучения и тестирования различаются. Стоит отметить, что согласно настройкам оригинальных статей MSP и MAP, авторы вставили их в блоки с 1-го по 6-й, тогда как MoRA авторы вставили только в 1-й блок. Результаты показывают, что MoRA может добиться большей производительности, вставив первый блок. Из таблицы также видно, что модель значительно менее устойчива к тексту, чем к изображениям. Это разумно в практическом мультимодальном обучении: одна модальность важнее других. Поэтому крайне важно повысить надежность этого важного метода. Как видно из таблицы, MoRA работает значительно лучше, когда текст сильно отсутствует.
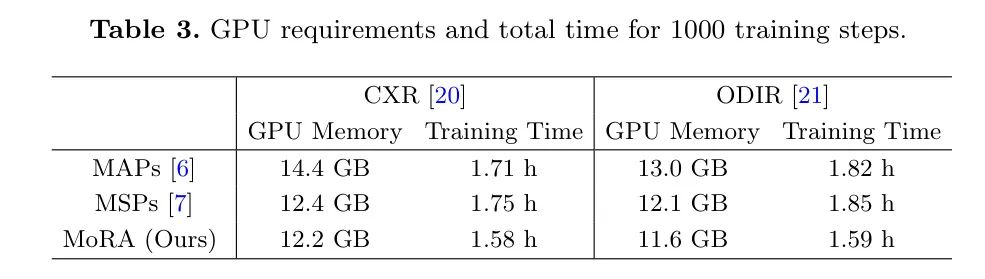
Авторы также сравнили требования к памяти графического процессора и время обучения различных методов в процессе обучения. Как показано в таблице 3, при 1000 шагах обучения MoRA требует относительно небольшой памяти графического процессора и короткого времени обучения. Это связано с тем, что MoRA нужно вставить только первый слой предварительно обученной модели, что приводит к меньшему количеству обучаемых параметров.
Ablation Study
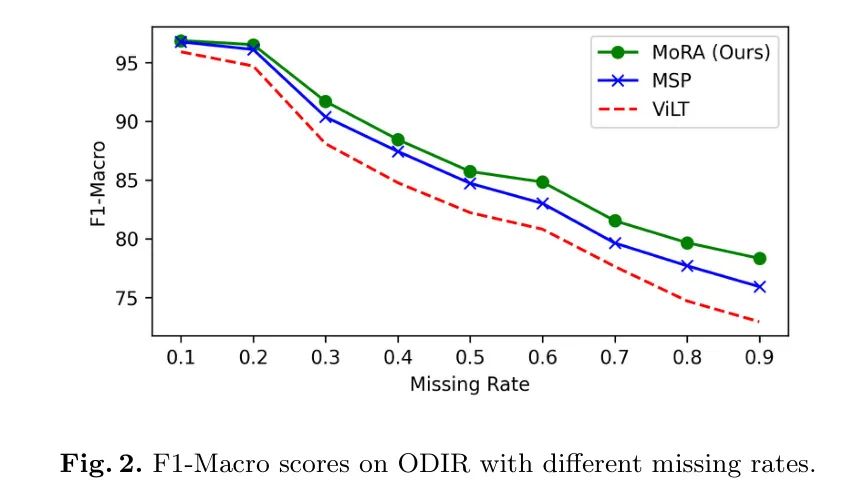
Устойчивость к различным отсутствующим шаблонам: Авторы провели дальнейшие эксперименты для анализа предложенного method Устойчивость при различных показателях отсутствия шаблонов. Чтобы внести ясность, авторы сохранили уровень пропусков одинаковым для каждой модальности и считали общий уровень пропусков равным . Автор находится в ODIR обучение МОРА, которое , что означает 65% модальность изображения и 65% Текстовый модальный образец. Автор находится в тесте при различных показателях пропусков, как показано на рисунке 2. Результаты показаны в . В случае, когда коэффициент пропуска невелик, применяют авторский метод и Baseline Результаты существенно не отличались. Поскольку уровень пропусков продолжает расти, модель авторов демонстрирует большую надежность. Это показывает, что модель авторов лучше справляется с экстремальными ситуациями модального отсутствия.
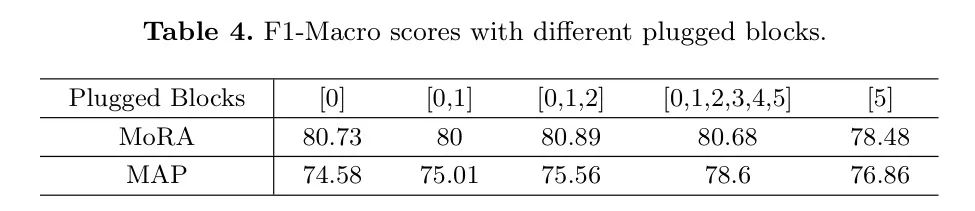
Эффекты вставленных блоков: в соответствии с [6]。MAPs Очень чувствителен к вставленным блокам. Авторы также провели эксперименты по анализу пар позиций вставки. MoRA влияние. Автор находится в ODIR обучение МОРА, которое 65% модальность изображения и 65% Текстовые модальные образцы, но с фиксированным рангом р. Автор пытается MoRA Вставляйте в разные блоки, чтобы проверить производительность. в соответствии Таблица 4 Результаты экспериментов показывают, что производительность вставки в несколько блоков близка к производительности вставки в первый блок. Видно, что с MAPs По сравнению с МОРА Не очень чувствителен к количеству вставленных блоков. Однако в ходе экспериментов авторы обнаружили, что вставка в первый блок MoRA эффективность имеет решающее значение. Вероятно, это связано с тем, что первый уровень может принимать входные данные напрямую. Token информация, эта пара MoRA Это очень полезно для подтверждения статуса отсутствующих модулей и облегчения последующей тонкой настройки. Таким образом, при фактическом использовании MoRA Лучше всего вставить в первый блок для тонкой настройки, которая позволит добиться хороших результатов, используя как можно меньше параметров обучения. Это также MoRA и MAPs преимущества.
классифицировать r Влияние на производительность: Проверка автораклассифицировать r вернопроизводительностьвлияние. Автор находится в ODIR обучение МОРА, которое 65% модальность изображения и 65% Текстовый модальный образец, но с различной классификацией р. Автор покажет в таблице 5 Покажите результаты в формате . Как видно из таблицы, производительность улучшается с увеличением классифицировать. Однако результаты показывают, что когда классифицировать установлено значение 4 Когда производительность достигает своего максимума. Автор упомянул и крайний случай, т.е. классифицировать r равно входному значению Token размеров. В этом случае результат очень плохой, даже хуже, чем ничего. MoRA Ситуация еще хуже. Это показывает MoRA Это работает только тогда, когда классификация очень мала, это и LoRA Вывод последовательный. В целом, МОРА верно r Выбор не очень чувствителен.

4 Conclusion
В этой статье авторы предлагают мультимодальную предварительно обученную модель для диагностики заболеваний.
Чтобы решить эти проблемы, авторы предлагают MoRA для тонкой настройки мультимодальных предварительно обученных моделей с отсутствующими модальностями.
MoRA отображает каждый входной сигнал в одно и то же низкое внутреннее измерение, но использует различные аппроекции с учетом модальности для получения адаптации с учетом модальности к конкретным ситуациям с дефицитом модальности.
Автор провел эксперименты над двумя задачами по диагностике заболеваний с разными показателями модальных пропусков, и результаты показали, что преимущества метода MoRA не только повышают надежность и производительность, но и позволяют экономить. вычислительные ресурсы.
В будущей работе авторы распространят свой метод на более крупные предварительно обученные модели и исследуют возможность внедрения крупномасштабных мультимодальных предварительно обученных моделей в диагностику заболеваний.
ссылка
[1].MoRA: LoRA Guided Multi-Modal Disease Diagnosis with Missing Modality.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
