МОМЕНТ: CMU выпускает первую базовую большую модель временных рядов с открытым исходным кодом
Анализ временных рядов — важная область, охватывающая широкий спектр приложений: от прогнозирования погоды до обнаружения нерегулярного сердцебиения с помощью электрокардиограммы и выявления аномального развертывания программного обеспечения.
Однако,Моделирование таких задач обычно требует большого опыта в предметной области, времени и проектирования для конкретных задач. Для решения этих задач,MOMENT Исследователи собрали большую и разнообразную коллекцию общедоступных временных рядов, называемых стеками временных рядов. Pile) и систематически решать проблемы, уникальные для временных рядов.,чтобы разблокировать массивные мульти-данные наборы предварительной подготовки.
MOMENT — это первая крупномасштабная серия предварительно обученных моделей временных рядов с открытым исходным кодом, выпущенная исследователями из Университета Карнеги-Меллона (CMU) в США. Эту серию моделей (1) можно использовать в качестве основных строительных блоков для различных задач анализа временных рядов (таких как прогнозирование, классификация, обнаружение и вменение аномалий и т. д. (2) по принципу «подключи и работай», то есть нет (); или только небольшое количество) конкретных выборок задач (например, прогнозирование с нулевым шагом, классификация с небольшим количеством шагов и т. д.) (3) Может быть настроен с использованием данных распределения и конкретных задач для повышения производительности.

Название статьи:MOMENT: A Family of Open Time-series Foundation Models
Бумажный адрес:https://arxiv.org/abs/2402.03885
Исходный код бумаги:https://anonymous.4open.science/r/BETT-773F/README.md
модельный подход
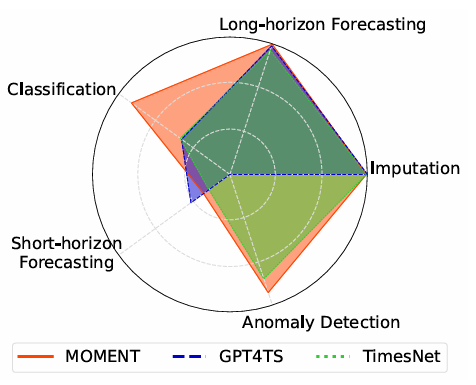
Рис. 1. Сравнение производительности MOMENT при выполнении нескольких задач анализа временных рядов
Исследователи сначала собрали большое количество общедоступных данных временных рядов и интегрировали их в «кучу временных рядов» (Time-series Pile), а затем использовали эти данные для предварительного обучения модели Transformer для задачи прогнозирования замаскированных временных рядов.
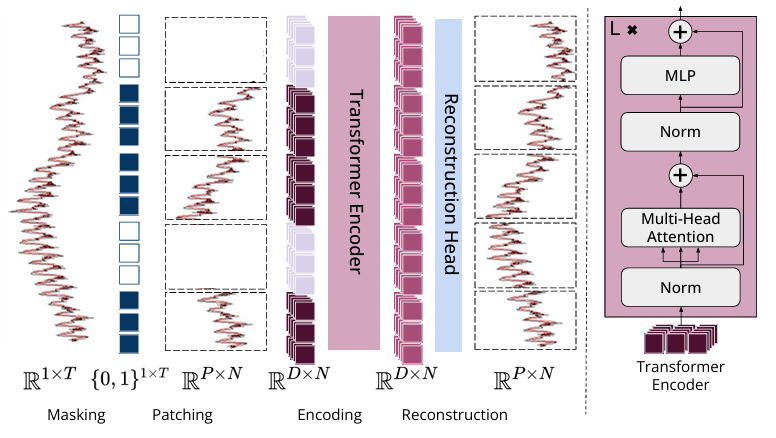
Рис. 2. Обзор модели момента
Временной ряд разбивается на непересекающиеся подпоследовательности фиксированной длины, называемые патчами, и каждый патч отображается во встраивание D-мерного сегмента. Во время предварительного обучения патчи маскируются равномерно и случайным образом путем замены внедрений патчей специальными внедрениями масок [MASK]. Цель предварительного обучения — изучить встраивания патчей, которые могут реконструировать входные временные ряды с помощью облегченной головки реконструкции.
Таким образом, MOMENT внимательно следит за конструкцией преобразователя, и исследователи могут использовать его для расширения эффективных реализаций (например, контрольных точек градиента, обучения смешанной точности).
Разделение временного ряда на сегменты может квадратично уменьшить объем памяти MOMENT и вычислительную сложность, а также линейно увеличить длину входного временного ряда, который он может получить. Исследователи обрабатывают многомерные временные ряды, управляя каждым каналом независимо по размеру партии.
Кроме того, мы используем облегченную прогностическую головку вместо декодера того же размера, что и кодировщик, чтобы обеспечить ориентацию на ограниченное количество обучаемых параметров для конкретной задачи, сохраняя при этом большинство параметров и высокоуровневые функции кодера без изменений. внести необходимые архитектурные изменения.
Экспериментальный эффект
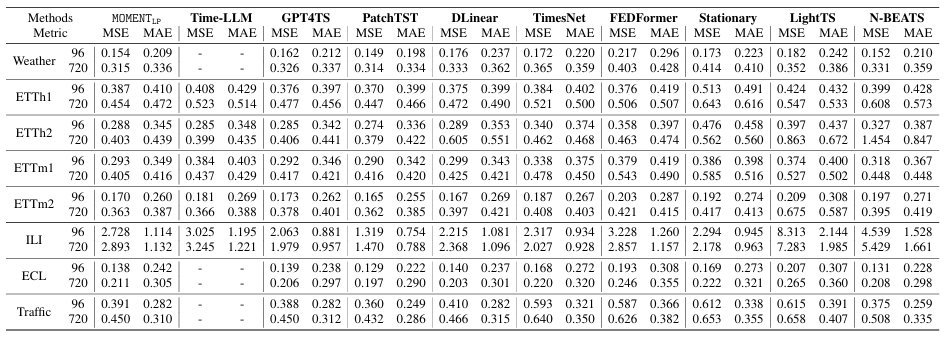
Что касается набора данных, исследователи использовали тот же набор данных, что и TimesNet, для прогнозирования и интерполяции. Однако для задач классификации и обнаружения аномалий исследователи выбрали для экспериментов более крупный и систематический подмножество набора данных в архиве классификации UCR и архиве аномалий UCR.
В частности, исследователи провели эксперименты по классификации на всех 91 наборах данных временных рядов, причем каждый временной ряд имел длину не более 512 временных шагов. Для обнаружения аномалий при выборе подмножества временных рядов приоритет отдавался охвату различных доменов и источников данных в архиве аномалий UCR.
Судя по результатам экспериментальных данных, представленным в статье, MOMENT может решать несколько задач моделирования временных рядов при ограниченных настройках наблюдения. В частности, следующие аспекты:
Долгосрочные прогнозы. Линейное зондирование MOMENT обеспечивает почти самую современную производительность на большинстве наборов данных и временных интервалов, уступая только PatchTST, который обычно достигает самого низкого MSE.
Краткосрочное прогнозирование с нулевой выборкой. Среди всех задач краткосрочное прогнозирование с нулевым шансом имеет наибольшие возможности для совершенствования. Статистические методы, такие как Theta и ETS, превосходят свои аналоги глубокого обучения. Однако в некоторых наборах данных MOMENT достигает более низкого значения sMAPE, чем ARIMA.

Классификация. Без какого -либо точного -для данных момент может изучать уникальные представления различных категорий данных и производительность SVM SVM, в котором он представляет собой лучше, чем все методы, кроме четырех методов для построения моделей классификации временных рядов, и эти Методы находятся в этих методах в этом методе.
Обнаружение аномалий. В 44 временных рядах в архиве обнаружения аномалий UCR MOMENT неизменно превосходит TimesNet и GPT4TS, а также две современные модели глубокого обучения, адаптированные для обнаружения аномалий, как в конфигурациях нулевого, так и линейного обнаружения.
Интерполяция. MOMENT с использованием линейного зондирования обеспечивает наименьшую ошибку реконструкции для всех наборов данных ETT. При настройке нулевой выборки MOMENT неизменно превосходит все методы статистической интерполяции, кроме линейной интерполяции.

Подвести итог
Исследователи выпустили первую серию базовых моделей временных рядов с открытым исходным кодом — MOMENT и систематически решили несколько проблем, связанных с временными рядами, которые мешали широкомасштабному исследованию крупномасштабного предварительного обучения с использованием нескольких наборов данных. Мы использовали стеки временных рядов и эти стратегии для предварительного обучения моделей преобразователей трех разных размеров.
В статье исследователи делают упор на крупномасштабную предварительную подготовку нескольких наборов данных по данным временных рядов, кодируют неявные характеристики временных рядов (такие как тенденции и частоты) и демонстрируют преимущества этого подхода.
В целом, превосходную производительность MOMENT, особенно в задачах обнаружения и классификации аномалий, когда наборы данных обычно небольшие, можно объяснить предварительным обучением. Кроме того, исследователи продемонстрировали, что меньшие статистические методы и более мелкие методы глубокого обучения могут достичь разумной производительности во многих задачах.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
