Мои уникальные технические идеи: векторная база данных
введение
За последний год или около того GPT произвела сенсацию во всем мире благодаря своей высокой производительности и стала широко наблюдаемой технологией. Концепция GPT не только завоевала рынок, но и считалась очередной определяющей тенденцией. С притоком капитала приложения ИИ быстро развиваются, способствуя процветанию всей цепочки индустрии приложений ИИ. В этом быстро развивающемся контексте векторные базы данных стали одним из наиболее востребованных приложений.

память ИИ
Некоторые люди говорят, что у ИИ есть память
память Функция ИИ не является встроенной функцией модели GPT. Фактически, модели серии GPT, такие как GPT-3.5/4иgpt-3.5-turbo, имеют ограничения контекста ввода (токена), особенно модель gpt-3.5-turbo, которая ограничена разрешением 4K. токены (около 3000 слов). Это ограничение означает, что пользователи могут использовать не более 3000 слов контента для понимания и вывода при взаимодействии с моделью.
поэтому,Сам ChatGPT не имеет функции памяти разговоров.Память разговоров реализуется путем хранения записей разговоров во внешней памяти или базе данных.,а не функция памяти внутри модели. Когда пользователь отправляет сообщение модели,Программа автоматически выберет самые последние разговоры из сохраненных записей разговоров (по номеру 4096). в пределах токенов) и объединены в финальный вопрос через подсказку, а затем отправлены в ChatGPT. Итак, если память разговоров превышает 4096 токенов, модель забудет предыдущие разговоры.
Разные версии модели имеют разные лимиты токенов. Например, лимит gpt-4 составляет 32 000 токенов, а модель Claude достигает 100 000 токенов. Хотя это предоставляет больше места для контекстного ввода, это также поднимает новые вопросы. Когда модель Клода обрабатывает контекст 72 тысяч токенов, скорость ответа достигла около 20 секунд. Это означает, что, хотя у нас больше пространства для ввода контекста, на практике эффективность обработки крупномасштабных документов по-прежнему сталкивается с проблемами.
Кроме того, учитывая, что выставление счетов GPT API основано на токенах, ввод большего количества контекста приведет к более высоким затратам. Поэтому найти баланс между стоимостью, производительностью и требованиями миссии становится сложной задачей.
Рост векторных баз данных
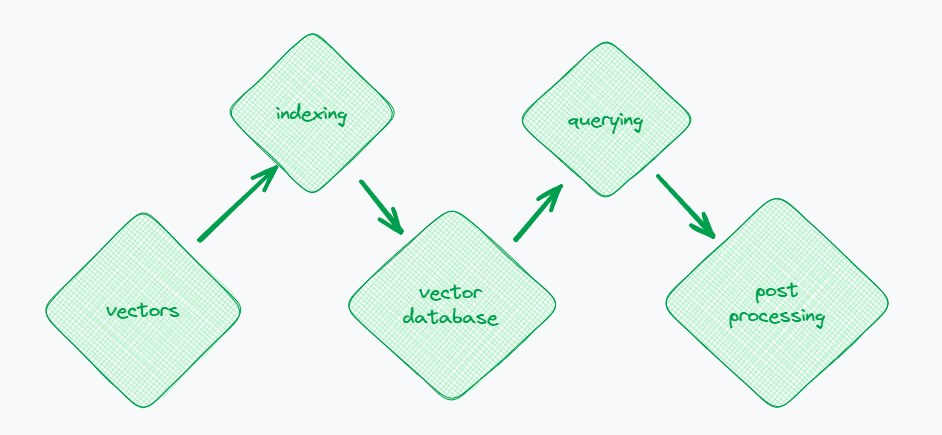
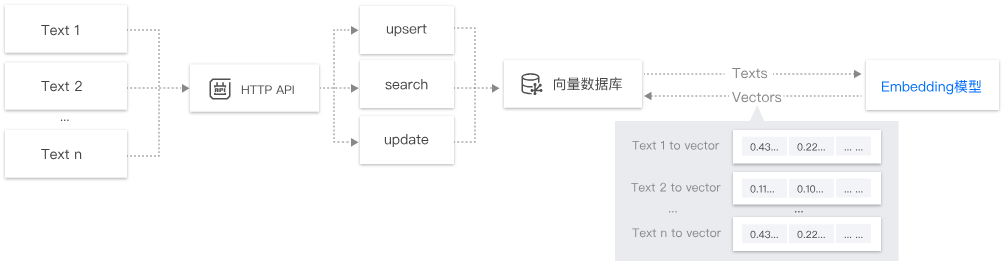
В рамках ограничений модели GPT,Разработчики активно ищут инновационные решения,ввектор Базы данных становятся привлекательным вариантом。Основная идея концепции — преобразовать текст в векторы и затем эффективно сохранить эти векторы в базе данных.когда пользователь задает вопрос,Система преобразует вопрос в вектор.,Затем найдите в базе данных наиболее похожие векторные изображения, связанные с контекстом.,Наконец, соответствующий текст возвращается пользователю. Этот метод компенсирует ограничение длины контекста модели GPT и в то же время,Он также может более эффективно обрабатывать и извлекать крупномасштабные текстовые данные.,Предоставляйте пользователям более точную и персонализированную информацию. Это инновационное приложение демонстрирует потенциал векторных баз данных для решения современных задач обработки текста.,И это предоставляет многообещающий метод для решения сложных запросов и крупномасштабной обработки текста.
Предположения:
У нас есть обширная база данных медицинских записей в медицинской сфере, которая содержит большой объем информации, такой как записи пациентов, медицинская литература и т. д. Мы надеемся предоставить врачам и исследователям более интеллектуальную и персонализированную медицинскую информацию с помощью модели GPT.
Сценарии применения:
Во-первых, мы используем технологию Vector Embedding для преобразования всех медицинских документов, медицинских записей и т. д. в векторные представления. Таким образом, каждый документ может быть представлен многомерным вектором, фиксирующим семантическую информацию документа.
Когда у врачей или исследователей возникают конкретные медицинские вопросы или им необходимо получить соответствующую информацию, они могут задать вопросы системе. Система преобразует содержание вопроса пользователя в векторы посредством векторного внедрения.
Затем через базу данных векторов система быстро ищет и находит наиболее похожие векторы и связанную с ними контекстную информацию среди хранящихся векторов медицинских документов. Это позволяет системе разумно сопоставлять медицинские вопросы со знаниями в базе данных для предоставления целевой медицинской информации.
Преимущество этого сценария применения заключается в том, что с помощью базы данных векторов система может быстро и точно получать соответствующую информацию из огромной медицинской базы данных, предоставляя врачам более быстрые и более персонализированные рекомендации по диагностике и лечению. В то же время это также эффективно обходит GPT. Ограничение токенов снижает чрезмерную зависимость от модели GPT и повышает производительность и эффективность всей системы. с другой стороны,когда мы сChatGPTКогда много разговоров,Все разговоры можно сохранить в виде вектора. Каждый разговор преобразуется в векторное представление.,и хранится в базе данных векторов. Когда мы спросили ChatGPT,Система также преобразует вопрос в векторный формат.,и выполнять семантический поиск,Найдите «воспоминание», наиболее соответствующее текущей проблеме.,Затем отправьте эти связанные разговоры вместе в ChatGPT. Этот подход эффективно сочетает в себе семантическое представление истории разговоров и возможности генерации языка GPT.,Может значительно улучшить качество вывода GPT.,Сделайте его более точным, чтобы понять контекст и намерения пользователя.
Это приложение не ограничивается семантическим поиском текста, но также может быть расширено для распознавания лиц, поиска изображений, распознавания речи и других функций в традиционных приложениях искусственного интеллекта и сценариях машинного обучения. Преобразуя данные из разных модальностей в векторы и сохраняя их в базе данных, система может обеспечить более комплексный кросс-модальный поиск и обработку информации. Это решение обеспечивает мощную поддержку ИИ для понимания и поддержания долговременной памяти и выполнения сложных задач, что еще больше расширяет потенциал применения векторных баз данных в различных областях.
Векторное встраивание

Векторное встраиваниеэто способ отображения данных на высоком уровнеразмерный векторные космические технологии, обычно генерируемые моделями глубокого обучения. Это сопоставление направлено на сбор различных характеристик и семантической информации данных, что делает В векторном пространстве различные аспекты и взаимосвязи данных представлены положением и направлением вектора.
Благодаря векторному встраиванию,Сложная структура и корреляция необработанных данных могут быть закодированы в значимые низкоуровневые размерные файлы. вектор。этотдля Обработка естественного языка、изображение、Мультимодальные данные, такие как аудио, очень полезны.,Потому что это позволяет модели лучше понимать и представлять внутренние связи данных.
модель глубокого обучения,Такие как Слово Вложения (вложения слов) или изображения Встраивания (встраивания изображений) используют большие объемы данных и сложные структуры нейронных сетей при изучении этих векторных вложений для захвата высокоуровневых функций и семантической информации данных. Этот метод стал ключевым компонентом во многих приложениях искусственного интеллекта, обеспечивая более эффективное представление и лучшую производительность модели.
Для текстовых данныхVector Embedding Сопоставьте каждое слово, фразу или весь документ в многомерный вектор, который содержит информацию о синтаксисе, семантике, тональности и т. д. текста. Это встроенное представление помогает модели лучше понять смысл и контекст текста.
Аналогично, для различных типов данных, таких как изображения и аудио, Vector Embedding также может фиксировать их характеристики. При обработке изображений векторы встраивания изображений, полученные с помощью таких моделей, как сверточные нейронные сети (CNN), могут отражать визуальные особенности изображения. При обработке звука векторы внедрения звука, полученные с помощью таких моделей, как рекуррентная нейронная сеть (RNN) или преобразователь, могут представлять временную информацию звука.
Одной из основных целей использования векторного внедрения является преобразование неструктурированных или полуструктурированных данных в форму, понятную алгоритмам машинного обучения. Это представление сохраняет ключевую информацию о данных, позволяя модели более эффективно обрабатывать и изучать характеристики данных. В результате Vector Embedding обеспечивает прочную основу для решения множества задач, включая поиск по сходству, классификацию текста, системы рекомендаций и т. д. Широкое применение этой технологии внедрения способствовало развитию искусственного интеллекта во многих областях.
традиционная база данных Функция поиска в основном основана на различных методах индексации (таких как B-дерево, инвертированный индекс и т. д.) и алгоритмах точного сопоставления и сортировки (таких как BM25, TF-IDF и т. д.). Эти методы хорошо работают при поиске по ключевым словам и идеально подходят для точного соответствия текста. Однако эти традиционные алгоритмы индексирования и поиска относительно слабы для возможностей семантического поиска.
При поиске по ключевым словамэтот Эти алгоритмы могут эффективно обрабатывать явные ключевые слова, вводимые пользователями.,Например, выполните поиск названий продуктов в базе данных продуктов. Но когда дело доходит до более сложных семантических поисков,Пользователи могут использовать описательные слова, синонимы или выражать одну и ту же концепцию по-разному.,Традиционные методы поиска могут неправильно понять или уловить намерения пользователя.
Семантический поиск делает упор на понимание смысла пользовательских запросов, а традиционная база Алгоритмы поиска данных часто не могут точно собрать и обработать семантическую информацию запроса. Поэтому для более сложных задач поиска, особенно там, где задействовано понимание естественного языка и сложный контекст, традиционная база Функция семантического поиска данных оказывается относительно слабой. Это именно то, что используют некоторые сценарии приложений, используя новые технологии, такие как векторное внедрение (Vector Встраивание) или методы на основе глубокого обучения для улучшения качества семантического поиска.
разработка функций:
Когда пользователь ищет «кошка», традиционная база данные могут возвращать только результаты, содержащие ключевое слово «кошка», и не могут понимать семантические расширения слова «кошка», такие как «рэгдолл», «британская короткошерстная кошка» и т. д. Это потому, что традиционная база данные часто не могут распознать семантические отношения между словами.
Чтобы восполнить этот недостаток,Традиционные приложения могут потребовать ручной маркировки каждого слова.метка функции,Выполнить ассоциацию вручную。этотпроцесс называетсяОсобенности проектирования,Он предполагает преобразование необработанных данных в функции, которые лучше выражают суть проблемы. В этом примере,Для реализации семантического поиска,Может потребоваться маркировка кошек разных пород вручную.,Чтобы база данных могла понять связь между ними.
Однако разработка функций имеет определенные ограничения. Маркировка и управление большим количеством объектов вручную может оказаться сложной задачей и отнять много времени. Кроме того, ручное проектирование функций может оказаться недостаточно гибким и осуществляться в режиме реального времени, когда речь идет о крупномасштабных и быстро меняющихся данных.
Знакомство с векторным встраиванием (Vector Embedding)метод может автоматически изучать семантическую информацию путем,Избегаются ручные аннотации и утомительное проектирование функций. Сопоставляя слова, фразы или документы в векторном пространстве большого размера.,Модель может автоматически фиксировать семантические отношения.,Делает поиск более интеллектуальным и гибким. Этот подход обеспечивает более современное и эффективное решение для обработки семантического поиска.
Особенности и векторы
Особенности и выражения часто называют «использованием» в областях машинного обучения и науки о данных, где они играют ключевую роль в описании и представлении данных.
Особенность:
- определение: Характеристики относятся к атрибутам или свойствам, извлеченным из данных, которые имеют значение для проблемы. В машинном обучении функции — это атрибуты, используемые для описания данных, которые могут быть числовыми, категориальными или другими типами данных.
- пример: В задаче прогнозирования цен на жилье характеристики могут включать площадь комнаты, количество спален, количество ванных комнат и т. д. Каждая функция описывает аспект проблемы.
- эффект: Функции предоставляют информацию, необходимую модели машинного обучения для обучения и составления прогнозов. Хорошие функции могут лучше фиксировать закономерности и взаимосвязи в данных.
Вектор:
- определение: Вектор — это упорядоченный набор значений, представляющий точку в пространстве. В машинном обучении векторы часто используются для представления коллекций данных, где каждый элемент соответствует функции данных.
- пример: Если существует вектор, содержащий функции прогнозирования цены на жилье, это может быть площадь, количество спален, количество ванных комнат, площадь, количество спален, количество ванных комнат, где каждый элемент соответствует определенному признаку.
- эффект: Вектор — это эффективный способ представления данных в моделях машинного обучения. Организовав функции в вектор, модель может легче обрабатывать данные и учиться на их основе.
Вектор характеристики:
- определение: Собственный вектор — это вектор, содержащий несколько собственных значений. В машинном обучении данные обычно представляются в виде векторов признаков, где каждый элемент соответствует признаку.
- пример: Если бы существовал вектор признаков, содержащий функции прогнозирования цен на жилье, это могло бы быть 2000 квадратных футов, 3 спальни, 2 ванные комнаты и 2000 квадратных футов, 3 спальни, 2 ванные комнаты.
- эффект: Вектор признаков — это обычное представление данных в машинном обучении, которое представляет каждый образец в наборе данных как положение точки в пространстве признаков.
Связь между признаками и векторами заключается в том, что признаки могут быть организованы в векторы, а вектор, образованный всеми значениями признаков выборки, отражает положение выборки в пространстве признаков. Эта связь имеет решающее значение в машинном обучении и науке о данных, поскольку позволяет обрабатывать данные алгоритмами машинного обучения в форме векторов.
Организовав признаки каждого образца в вектор, мы можем представить весь набор данных в виде матрицы, где каждая строка соответствует вектору признаков образца. Таким образом, модели машинного обучения могут учиться и делать выводы в этом многомерном пространстве признаков.
В задачах машинного обученияиспользоватьвектор Идея представления данных очень распространена.。Каждое измерение соответствует функции,Весь вектор формирует исчерпывающее описание выборки данных. Такое представление не только облегчает обработку алгоритмов,Это также облегчает понимание данных и математическое манипулирование ими.
Такие технологии, как векторное встраивание, еще больше расширяют возможности представления векторов. Он может отображать объекты в многомерное векторное пространство, чтобы лучше фиксировать семантическую информацию данных. Благодаря такому сопоставлению взаимосвязи и шаблоны данных могут быть закодированы более сложным образом, тем самым повышая производительность моделей машинного обучения.
Понятие векторного пространства играет важную роль в таких задачах, как поиск по сходству и кластеризация. В векторном пространстве схожие точки данных находятся ближе друг к другу, что обеспечивает мощный инструмент для поиска похожих выборок, выполнения кластерного анализа и т. д. Гибкость и универсальность моделей векторного пространства делают их основной концепцией во многих задачах машинного обучения и обработки данных.
Приведите пример
Сначала мы начинаем с повседневных наблюдений и думаем, почему мы можем различать разные вещи. Это связано с тем, что мы идентифицируем их категории, определяя их различные характеристики.
Рассмотрим ситуацию классификации растений, в которой мы хотим различать растения, наблюдая за их характеристиками. Во-первых, мы выбираем некоторые важные функции:
- Форма листа: У некоторых растений листья овальные, у некоторых сердцевидные, у некоторых удлиненные.
- Цвет Цветка: Цветки растения могут быть красными, синими, желтыми и т. д.
- Высота роста (Высота): Разные растения могут значительно различаться по высоте: одни карликовые, другие высокие.
- Среда роста (Environment): Некоторые растения адаптированы к влажной среде, а другие лучше подходят к более сухому климату.
Представьте каждое растение как вектор признаков, например:
- Растение А (роза): сердцевидное, красное, средней высоты, приспособленное к влажной среде. Сердцевидное, красное, средней высоты, приспособленное к влажной среде.
- Растение Б (подсолнечник): Длинные полоски, желтые, высокие, приспособлены к сухой среде. Длинные полоски, желтые, высокие, приспособлены к сухой среде.
- Растение C (кактус): Круглое, зеленое, короткое, адаптируемое к сухой среде. Круглое, зеленое, короткое, адаптируемое к сухой среде.
На начальном этапе, абстрагируя эти характеристики в числовые значения по осям, мы можем построить двумерную систему координат, в которой одна ось представляет форму листа, а другая ось представляет цвет цветка. В этом пространстве признаков мы можем получить положение каждого растения в пространстве признаков. Размещение разных растений отражает их различия в форме листьев и окраске цветков.
Впоследствии мы можем ввести дополнительные функции, такие как учет высоты роста и среды роста, чтобы построить более сложную многомерную систему координат. В этом многомерном пространстве признаков каждое растение можно более подробно описать по различным характеристикам, что делает похожие растения ближе в пространстве.
Этот процесс демонстрирует, как путем наблюдения и выбора нескольких характеристик растения можно построить многомерное пространство признаков, чтобы более полно представить различия и сходства растений.
фактически,Пока функции достаточно богаты,Мы можем однозначно представить что угодно в многомерной системе координат. Такое представление делает возможным поиск сходства. В двумерной системе координат,Если две точки координат расположены близко друг к другу,Это показывает, что их характеристики также схожи. Представьте эти функции в виде вектора.,Мы можем определить сходство между векторами, рассчитав расстояние между ними, что составляет основной принцип поиска сходства.
Сопоставляя объекты в многомерном пространстве признаков, мы можем использовать векторные представления и вычислять сходства для достижения эффективного поиска сходства. Эта концепция закладывает основу для алгоритма поиска по сходству в векторных базах данных, делая реальностью быстрый поиск похожих векторов в многомерном пространстве.
Важность этой идеи заключается в том, что даже в многомерных пространствах мы все еще можем эффективно сравнивать и искать похожие вещи. Это предоставляет мощный инструмент для приложений, которые обрабатывают крупномасштабные данные и ищут похожие изображения, текст или другие сложные структуры. Алгоритм поиска по сходству базы данных векторов может использовать это представление для быстрого поиска векторов, похожих на вектор запроса, тем самым обеспечивая эффективные функции поиска и рекомендации в практических приложениях.
Поиск сходства
Поиск сходства — это метод поиска объектов, похожих на заданный объект запроса, в многомерном пространстве. Основная идея этого метода поиска — представлять объекты как большие по размеру. вектор,Затем вычислите сходство между этими векторами, чтобы определить их расстояние в пространстве признаков. Поиск по сходству широко используется в различных областях.,В том числе обработка текста, распознавание изображений, Рекомендательные системы и т.д.
Евклидово расстояние Евклидово расстояние
Евклидово расстояние оценивает сходство двух векторов путем измерения расстояния по прямой между их точками. Абсолютное расстояние между более похожими векторами короче, а абсолютное расстояние между более несходными векторами больше.
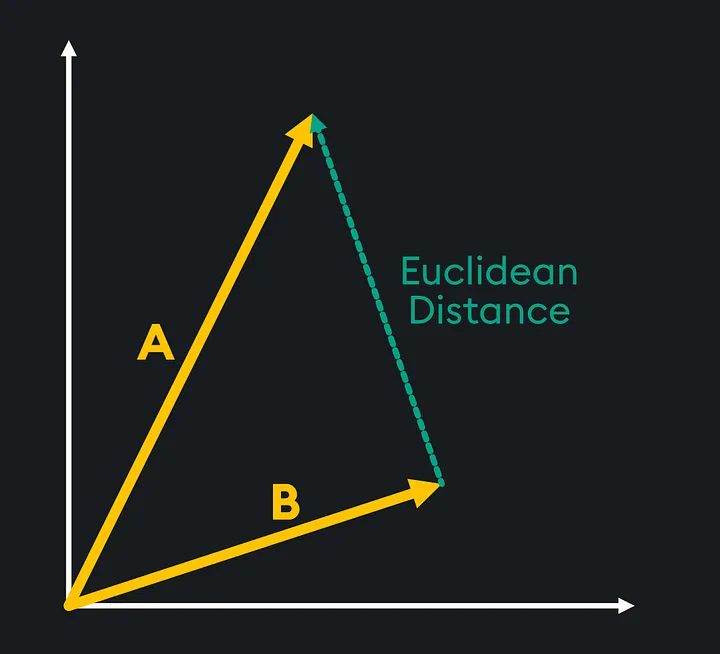
Математическая формула для расчета евклидова расстояния между векторами a и b с размерностями «n» выглядит следующим образом:

Давайте рассмотрим пример, где мы определим два трехмерных вектора A = (4, 5, 6) и B = (1, 2, 3) и выполним шаги расчета.
Step 1: Найдите разницу между соответствующими элементами в двух векторах
координата x: 4–1 = 3 координата y: 5–2 = 3 координата z: 6–3 = 3
Step 2: Возведите полученную разницу в квадрат
координата х: 32 = 9 координата y: 32 = 9 координата z: 32 = 9
Step 3: Добавьте эти квадраты разностей
9 + 9 + 9 = 27
Step 4: Найдите квадратный корень из суммы
√27 ≈ 5.196
Скалярное произведение
Скалярное произведение — это простая мера того, насколько выровнены два вектора друг с другом. Он говорит нам, направлены ли векторы в одном направлении, в противоположных направлениях или перпендикулярны друг другу. Он рассчитывается путем умножения соответствующих элементов вектора и сложения результатов для получения одного скаляра.
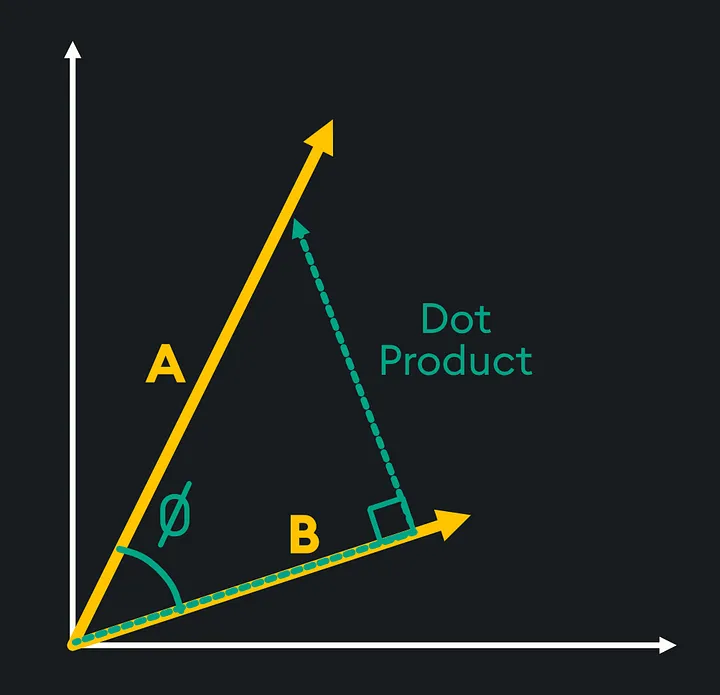
Для n-мерных векторов a и b скалярное произведение математически определяется как:
Это простое уравнение умножает соответствующие элементы вектора и Добавить. эти результаты。Приведите пример, если у нас есть два вектора: A = (1, 2, 3) и B = (4, 5, 6), скалярное произведение будет рассчитываться следующим образом:
Step 1: Умножьте соответствующие элементы в двух векторах
координата х: 1 * 4 = 4 координата y: 2 * 5 = 10 координата z: 3 * 6 = 18
Step 2: Добавить эти результаты
4 + 10 + 18 = 32
Если результат большой и положительный, это означает, что векторы имеют одинаковые направления; если результат большой и отрицательный, это означает, что векторы имеют противоположные направления; Когда скалярное произведение равно нулю, это означает, что векторы вертикальны и образуют угол 90 градусов.
Косинусное сходство Косинусное сходство
Косинусное сходство измеряет сходство двух векторов, используя угол между ними. Размер самих векторов не имеет значения, при расчете учитываются только углы, поэтому если один вектор содержит меньшие значения, а другой — большие значения, это не повлияет на полученное значение подобия.
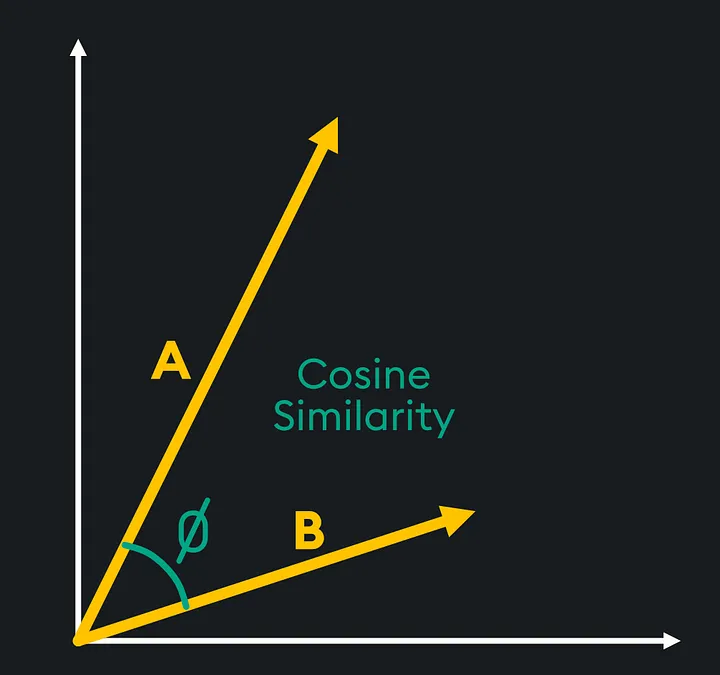
Подумайте об этом так: евклидово расстояние — это мера между двумя точками, а косинусное сходство означает, что подобные векторы, скорее всего, будут указывать в одном направлении, поэтому угол между ними уменьшится. Для вектора с размерностью «n» a и б. Косинусное подобие математически определяется как:
Формула для меры сходства «скалярного произведения» является верхней частью этого уравнения. Это связано с тем, что скалярное произведение измеряет выравнивание направлений векторов, а затем нижняя часть уравнения нормализует это значение, принимая во внимание разницу в размерах векторов. Это дает нам –1 и 1 значение сходства между ними. Мы можем использовать одни и те же два трехмерных вектора A = (1, 2, 3) и B = (4, 5, 6) Точно поймите ситуацию.
Верхняя часть уравнения: Step 1: Умножьте соответствующие элементы в двух векторах
координата х: 4 * 1 = 4 координата y: 5 * 2 = 10 координата z: 6 * 3 = 18
Step 2: Добавить эти результаты
4 + 10 + 18 = 32
Нижняя часть уравнения: Step 3: Возведите в квадрат каждый элемент в каждом векторе
Вектор 1: (1², 2², 3²) = (1, 4, 9) Вектор 2: (4², 5², 6²) = (16, 25, 36)
Step 4: Сложите полученные квадраты значений
Вектор 1: 1 + 4 + 9 = 14 Вектор 2: 16 + 25 + 36 = 77
Step 5: Умножьте эти результаты
sqrt(14 * 77) = sqrt(1,078) = 32.83
Полное уравнение: Step 6: Разделите верхнее значение на нижнее значение
32/32.83 = 0.9747
напиши в конце
База данных векторов — это технология обработки крупномасштабных многомерных данных. Ее основная идея — преобразовать данные в векторное представление и сохранить их в базе данных. База данных такого типа имеет широкий спектр применений, включая поиск по сходству, обработку текста, поиск изображений и другие области.
В этой статье в основном представлены принцип и реализация базы данных векторов.,Включая основные понятия базы данных векторов, поиска сходства, измерения сходства и т. д. Эти методы могут повысить эффективность при обработке крупномасштабных данных.,Уменьшите вычислительную сложность,И играет ключевую роль в задачах машинного и глубокого обучения.
VectorDatabase — новое поле,В настоящее время стоимость большинства компаний, работающих с базами данных векторов, быстро растет благодаря развитию искусственного интеллекта и GPT. Однако,В реальных бизнес-сценариях,В настоящее время существует относительно немного сценариев применения базы данных Vector. Отложи в сторону порывистую шерсть,Вектор Сценарии применения базы данных требуют от разработчиков и бизнес-экспертов более глубокого изучения.
будущее,Мы можем рассчитывать на развитие базы данных векторов в других областях.,Особенно в условиях мультимодальных данных, крупномасштабных изображений, обработки текста и речи и т. д. также,Оптимизируйте алгоритм поиска и улучшите качество и эффективность векторного представления.,А возможность интеграции информации из нескольких источников станет важным направлением развития векторной базы данных. Благодаря постоянному развитию технологий и расширению сценариев применения,,Ожидается, что база данных векторов станет одним из важных инструментов для обработки сложных данных.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
