Модель скрытой диффузии, управляемая движением, для реального временного сверхвысокого разрешения видео
источник:arxiv автор:Xi Yang ждать Название диссертации:Motion-Guided Latent Diffusion for Temporally Consistent Real-world Video Super-resolution Бумажная ссылка:https://arxiv.org/pdf/2312.00853.pdf Организация контента:Ван Ивэнь Недавно диффузионные модели продемонстрировали убедительную эффективность в создании реалистичных деталей для задач улучшения изображений. Однако из-за стохастического характера процесса диффузии сложно контролировать содержимое восстановленного изображения. Примените модель диффузии к VSR(Video Super-resolutionn) Эта индивидуальная проблема становится более серьезной, когда постоянство время имеет решающее значение для воспринимаемого качества видео. Этот метод использует предварительно обученные SD(Stable Diffusion) Преимущество модели в том, что она представляет собой эффективную реальную модель. VSR алгоритм.
введение
Видео супер разрешение (VSR) Стремится начать с заданного низкого разрешения (LR) Реконструкция видеоряда высокого разрешения (HR) видео. Благодаря быстрому развитию технологий глубокого обучения, VSR За последнее десятилетие был достигнут значительный прогресс благодаря появлению новых технологий, в том числе EDVR метод ожидания, BasicVSR на основе скользящего окна ожидание основано на рекурсивном методе, а последний основан на Transformer метод. Однако большинство из вышесказанного предполагают, что в LR и HR Простая деградация между видео. Следовательно, это VSR Модель сложно обобщить на реальный мир. LR видео, потому что реальная деградация гораздо сложнее.
В последнее время реальный мир VSR внимание исследователей на его огромную потенциальную ценность для улучшения камер мобильных телефонов и онлайн-трансляции. на. реальный мир VSR Предназначен для улучшения видео со сложной и неизвестной деградацией. Основная проблема заключается в том, как эффективно воспроизводить детали, подавляя при этом визуальные артефакты, вызванные неизвестным ухудшением качества. существующий реальный мир VSR алгоритм в основном пытается использовать генеративно-состязательные потери、Введите предварительную очисткуивнимание скрытого слояждать Технология кроется в деталяхикомпромиссы между артефактами。Несмотря на эти усилияипрогресс,Но из-за недостаточности данных обучения и ограниченных возможностей модели.,Их производительность на реальных тестовых наборах по-прежнему ограничена.
Вероятностная модель диффузии с самошумом (DDPM) Со времени новаторской работы генеративные модели, основанные на диффузии, добились больших успехов в создании изображений. В частности, модели скрытой диффузии (LDM) добился впечатляющих результатов не только в создании изображений для преобразования текста в изображения, но и в редактировании изображений, рисовании и раскрашивании последующих задач. Недавно исследователи также попытались LDM Мощные генеративные априоры используются в реальных задачах восстановления изображений и дают обнадеживающие результаты. Таким образом, исследование того, можно ли использовать априоры скрытой диффузии для улучшения реальных условий VSR Результаты значительны. Однако из-за присущей процессу диффузии стохастичности возникает временная несогласованность между видеокадрами в скрытом пространстве. Это несоответствие будет LDM Декодер дополнительно усиливает. Используйте непосредственно на основе LDM алгоритм сверхвысокого разрешения изображения VSR может вызвать несоответствие деталей между последовательными кадрами, ухудшив качество визуального восприятия реконструированного видео.

Рисунок 1
Для решения вышеперечисленных задач,В этой статье предлагается реальный VSR для MGLD., созданный для создания хорошего постоянства Высококачественные HD-видео последовательности времени. Этот метод войдет LR Динамика движения видео включена SR Процесс формирования вывода. Этого можно достичь посредством процесса направленной диффузии, согласно модели score function Сгенерируйте условные образцы. В частности, мы сначала вычисляем соседние LR оптический поток между кадрами и использовать рассчитанный оптический поток для анализа скрытых особенностей каждого кадра. деформация, которая выравнивает особенности соседних кадров. деформировать ошибка L1 norm используется как потеря, управляемая движением, и ее градиент добавляется в процесс выборки для обновления скрытых функций.
чтобы преодолеть LDM Поскольку исходный декодер создает противоречивые детали, этот метод вставляет в декодер модуль синхронизации и использует реальные данные. HR видеопоследовательность для ее точной настройки. В этой статье также представлена инновационная потеря, ориентированная на последовательность, которая помогает декодеру улучшить непрерывность деталей. предложенный MGLD Метод может устранить разрывы в генерируемых деталях, сохраняя при этом естественность и качество визуального восприятия восстановления текстур.
Основные положения этой статьи заключаются в следующем:
- предложил метод, основанный на Диффузионном отбор проб, управляемый Процедура движения может использовать временную динамику входного кадра при генерации согласованных во времени скрытых признаков.
- Предлагается декодер последовательности с учетом времени.,и две последовательные потери,Для дальнейшего повышения непрерывности создаваемого видео.
- предложенный MGLD Модель достигла чрезвычайно конкурентоспособных результатов в реальном мире. VSR результат,По сравнению с существующей технологией,Он показывает более реалистичные детали и меньше мерцающих артефактов.
метод
Учитывая содержащий
LR видеопоследовательность кадров
, наша цель — генерировать HR-видеоряды
,для улучшения визуального качества,При этом сохраняется единообразие содержимого соседней рамки. Вдохновлен недавно разработанным методом сверхразрешения, основанным на диффузии.,книгаметод Воспользуйтесь предварительной тренировкой SD Создание априорных моделей для улучшения реальных условий VSR производительность.
Прежде всего, этот метод представлен Диффузионным. отбор проб, управляемый Процесс движения, который вводится в процессе диффузионного отбора проб. LR Временная динамика последовательности,Чтобы улучшить согласованность потенциальной функции каждой рамки. Во-вторых,Этот метод разработал индивидуальный декодер последовательности с учетом времени.,и отрегулировать его с помощью видеоориентированных потерь,от, что еще больше повышает качество генерируемых деталей.
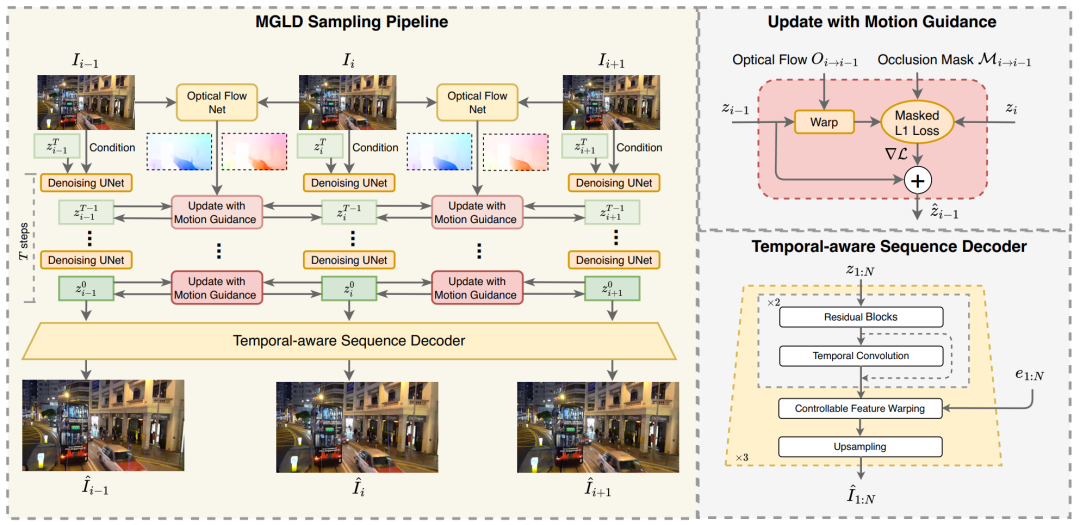
Рисунок 2
Модель скрытой диффузии (LDM)
модель скрытой диффузии (LDM) Это оказало значительное влияние на область создания изображений. В этих моделях используются вариационные автоэнкодеры. (VAE) Сопоставляет изображения со скрытым пространством, позволяя тренироваться на крупномасштабных наборах данных текстовых изображений. Это LDM Он предоставляет обширные предварительные знания о естественных изображениях изображений, а последующие задачи (такие как реконструкция изображений изображений и сверхвысокое разрешение) могут использовать эти знания для создания изображений изображений с четкими деталями и высококачественным контентом. Однако в Видео супер В разрешении (VSR) случайность процесса диффузии часто приводит к временным несоответствиям в восстановленной видеопоследовательности. Для решения этой отдельной проблемы этот метод предлагает модель диффузии, управляемой движением. (MGLD), который обеспечивает высокое качество за счет использования управления движением во время процесса выборки и добавления учета времени в декодере. VSR。
Диффузионный отбор проб, управляемый движением
С точки зрения оценки, процесс выборки диффузионной модели включает в себя градиент распределения данных.
игид Модель
Примените динамику Ланжевена:
Этот метод использует временную динамику входного видео с низким разрешением для создания поддерживаемого постоянства. потенциальные характеристики времени, от и улучшенные VSR результат. В частности, в процесс выборки добавляется инновационный модуль управления движением для расчета потенциальных характеристик каждого кадра. warp ошибка. данный LR После кадра сначала используйте
Рассчитайте их оптический поток и уменьшите дискретизацию карты оптического потока до размеров скрытых функций. Для прямого оптического потока
èОбратный оптический поток
,книгаметодпотенциальные возможности warp к соседним кадрам и вычислить накопление в обоих направлениях warp ошибка:
По опыту установлено, что наличие окклюзии будет иметь негативное влияние на оценку оптического потока, тем самым нарушая процесс отбора проб, и в конечном итоге VSR В результатах появляются артефакты. Чтобы решить эту проблему, в данной статье дополнительно оценивается окклюзия в каждой индивидуальной рамке. mask
и игнорирует вклад перекрытых областей. Учитывая планировщик шума на шаге
дисперсия
, этапы отбора проб
Процесс выборки, управляемой движением, можно записать как
пройти
После итераций окончательная скрытая последовательность без шума
отправлено VAE декодер для получения окончательного видеопоследовательности. ### Точная настройка декодера с учетом времени На основе предложенной диффузионной выборки, управляемой движением, VSR Модели могут лучше использовать временную динамику для создания более согласованных во времени HR видео. Однако поскольку наведение осуществляется в скрытом пространстве низкого разрешения, имеющем меньшие размеры, чем пространство выходного изображения 8 раз, поэтому прохождение VAE Реконструкция видео декодером все равно может привести к VSR Детали, сгенерированные на выходе, временно некогерентны. Поэтому в этой статье представлен декодер последовательностей с учетом времени и его точная настройка с использованием достоверных последовательностей для улучшения плавности и точности вывода. в предварительно обученном VAE На основе декодера в этой статье строится декодер временных рядов посредством одномерной свертки по измерению времени. Такая конструкция облегчает взаимодействие пространства и времени, позволяя Модели восстанавливать детали с высокой степенью непрерывности, минимизируя при этом вычислительные затраты. Этот метод использует контролируемые функции warping (CFW) модуль, который дополнительно интегрирует VAE Информация о кодере
, чтобы получить лучшие эффекты восстановления и генерации. Чтобы в полной мере воспользоваться преимуществами предварительной подготовки VAE Возможность ремонта, этот метод заморожен VAE Исходный пространственный блок, обновляется только временная свертка и CFW Параметры в модуле. Этот метод сначала рассчитывает для каждого кадра L1 Потеря и потеря восприятия и потеря реконструкции
, а затем вычислить видеопоследовательность GAN Потеря ирамка между потерями. потеря между рамкой
Вычислить последовательные предсказанные кадры
с рамами GT
Разница между ними определяется следующим образом:
Стоит отметить, что,Модель диффузии обычно создает прочные структуры. Чтобы сверхразрешение выглядело более естественно,Нам нужны ограничения согласованности приложений в этих структурных регионах. поэтому,Этот метод также вносит структурно взвешенную потерю согласованности:
в,
Выразите основу GT Форвард èОбратный расчет последовательности оптический поток。Потеря структурно-взвешенной согласованности помогает сети генерировать согласованные детали.,метод передается в GT Вес рассчитан на раму map
для расчета потерь, где
является весовым коэффициентом,
представляет собой структурный (реберный) граф, использующий оператор Собеля. Общие потери, используемые для точной настройки декодера, определяются как:
в,
Исходя из опыта, установлено 0.5、0.5 и 0.025。
эксперимент
экспериментнастраивать
эксперимент Детали реализации
Обучение предложенному методу Motion Guided Laten Diffusion (MGLD) состоит из двух индивидуальных этапов.
На первом этапе происходит шумоподавление для скрытой пространственной диффузии. U-Net Сделайте точную настройку. шумоподавление U-Net Вес SD V2.1 инициализация. Метод Бена находится в U-Net Одномерная временная свертка вставлена, чтобы помочь в моделировании временной динамики. Затем исправьте SD Шумоподавление модели U-Net вес, и обучить условную ветвь и модуль синхронизации. Что касается условных ветвей, для этого используется небольшой кодер с поддержкой времени. LR Условия кодируются и удаляются шум путем внедрения операций преобразования пространственных объектов. U-Net середина.
На втором этапе предлагаемый процесс диффузионной выборки, управляемой движением, сначала используется для генерации чистой последовательности неявного представления, а затем LR Последовательность, генерируемая неявная последовательность поверхностей HR Точная настройка последовательности декодера последовательности с учетом времени. зафиксированный VAE декодер и вставка временного слоя è CFW модуль для обучения.
Предложенная модель была обучена на 4 графических процессорах A100 с использованием фреймворка PyTorch, а в качестве оптимизатора был выбран Адам. Во время вывода видео LR разбивается на несколько последовательностей и запускается с 50 шагами выборки для каждой последовательности.
обучающий и тестовый набор
Этот метод слился с обучением REDS обучающий набор и набор проверки и оставьте 4 последовательности для тестирования (REDS4). в соответствии с RealBasicVSR В процессе деградации синтезируются пары обучающих последовательностей, которые включают в себя размытие, шум, понижающую дискретизацию и сжатие. Для реального мира данных,использовать VideoLQ Проведите тест, содержащий 50 Реальная последовательность действий со сложной деградацией.
экспериментрезультат
Количественные результаты
В данной статье предложенныйметод во всех синтетических тестах Набор Перцептивные показатели были получены на данных LPIPS и DISTS Для достижения наилучших результатов эта поверхность показывает, что предложенный метод способен реконструировать сложные деградированные последовательности с деталями высокого качества. Хотя похоже DBVSR Метод находится в PSNR или SSIM имеют более высокую производительность, но имеют тенденцию давать неоднозначные результаты, как показано на рис. LPIPS и DISTS Это подтверждается показателями.
для реального мира VSR Набор данных VideoLQ,Предлагаемый метод этой статьи показал второй лучший результат для NIQE, а BRISQUE улучшил лучшие показатели по MUSIQ.,Это отражает его мощную способность улучшать реальный мир и создавать реалистичные детали и текстуры.
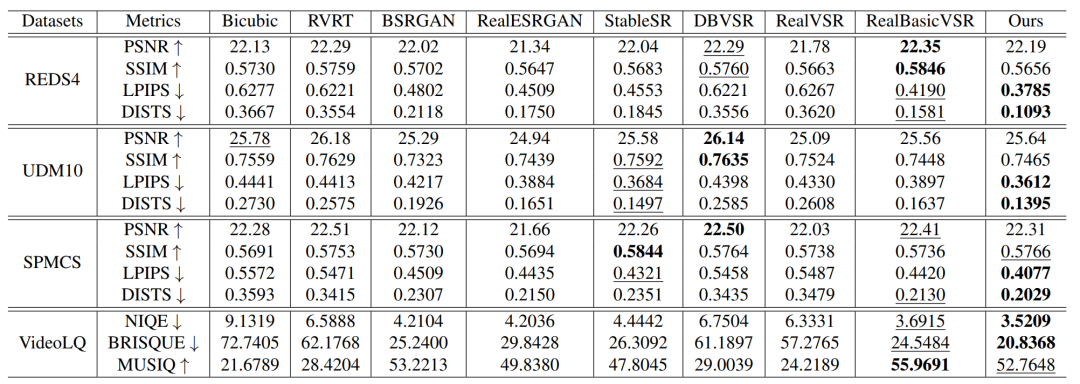
Таблица 1
Качественные результаты
MGLD Способен устранять сложные пространственные изменения и создавать реалистичные детали, которые превосходят другие современные модели реального мира. VSR алгоритм.В синтезе Набор По данным, предложенный в статье метод может хорошо реконструировать структуру, генерируя при этом достоверные детали в случае сложной деградации. В реальном мире видео, MGLD Может реконструировать символы икартина более четко, чем другие случаи метода.

Рисунок 3

Рисунок 4
постоянство времени
По сравнению со сверхразрешением одного изображения, VSR Еще одним важным аспектом индивидуальности является создание видеопостоянства. время. Как и в большинстве предыдущих исследований, в этой статье используется средняя ошибка деформации последовательности. (WE) количественно измерить пространственно-временную согласованность. хотя WE широкоприложение Впостоянство оценки времени, но она может не совсем точно отражать истинное человеческое восприятие видео. Например, нечеткая последовательность WE Оценки, как правило, выше, но качество видео ниже.
Предлагаемый статьей основан на распространенном предшествующем методе. MGLD Поверхность не очень хорошо работает по этому показателю, поскольку имеет тенденцию генерировать больше деталей и текстур, что не очень хорошо для WE Фракция. в соответствии с VSR Временной профиль результатов показан в MGLD. Более точные детали создаются при сохранении хорошей пространственно-временной согласованности.

Таблица 2

Рисунок 5
абляционныйэксперимент
Различные модули MGLD
и baseline Для сравнения, введение - это диффузия. отбор проб, управляемый движением (MDS) Улучшены все показатели, показывающие MDS Это не только помогает уменьшить временные ошибки, но и помогает улучшить качество восприятия реконструированной видеопоследовательности. МДС Добавление помогает поддерживать непрерывность восприятия, гарантируя плавный переход отремонтированного кадра от одного кадра к другому.
и baseline По сравнению с декодером последовательности с учетом времени (TSD) Добавление также дало лучшие результаты по всем показателям. Это потому, что TSD Возможность извлекать более подробную контекстную информацию из соседних кадров.

Таблица 3
Влияние сетей оптического потока
Сеть оценки оптического потока при выборке по движению не оказывает большого влияния на результаты, вероятно, потому, что выборка по движению применяется в пространстве с низким разрешением.

Таблица 4
Конструкция декодера VAE
Внедрение модуля адаптивного моделирования синхронизации улучшает согласованность синхронизации и качество восприятия, а добавление функций кодера-декодера во время точной настройки декодера еще больше улучшает результаты.
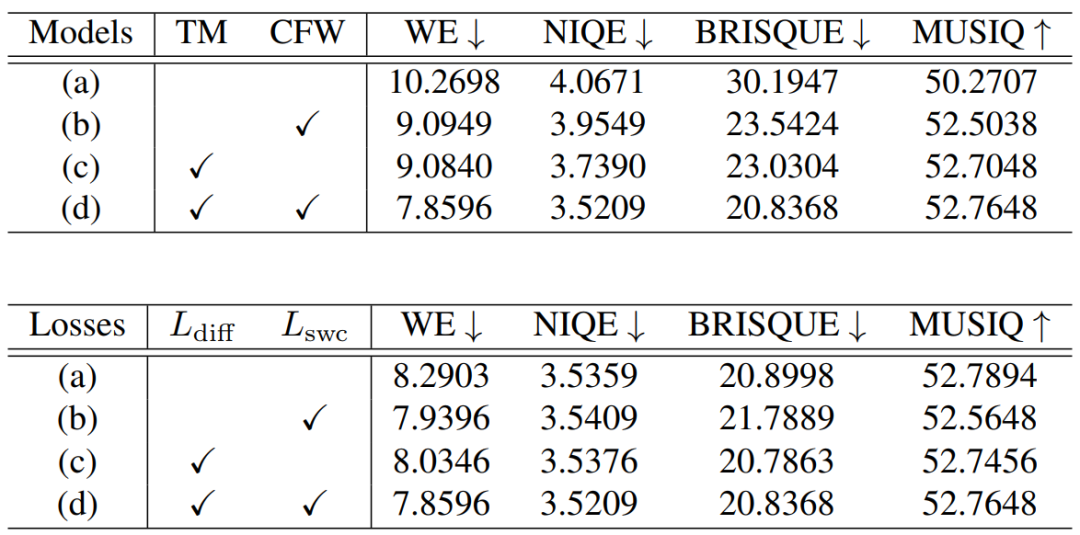
Таблица 5



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
