Модель измерения воспринимаемого качества видео YouTube – UVQ
источник:Google Research тема:UVQ: Measuring YouTube's Perceptual Video Quality автор:Yilin Wang, Feng Yang Исходная ссылка:https://blog.research.google/2022/08/uvq-measuring-youtubes-perceptual-video.html?m=1 Ссылка на модель UVQ:https://github.com/google/uvq Организация контента:Ли Юхан Оценка качества видео пользовательского контента (UGC) — важная тема в промышленности и научных кругах. Большинство существующих методов фокусируются только на одном аспекте оценки качества восприятия, таком как техническое качество или искажение сжатия. В этой статье создается крупномасштабный набор данных для всестороннего изучения. UGC Характеристики качества видео. Помимо субъективных оценок и содержательных меток набора данных, в этой статье также предлагается DNN изоснова для тщательного анализасодержание、Техническое качествоиуровень сжатиясуществовать Воспринимаемое качествоизважность。Модельспособен датьвидеоиз Показатель качества и три типа показателей качества,Очень хорошо установить связь между восприятием человеком качества продукта и некоторыми количественными показателями самого продукта.
фон
Платформы онлайн-обмена видео, такие как YouTube, должны понимать воспринимаемое качество видео (т. е. субъективное восприятие качества видео пользователями), чтобы лучше оптимизировать и улучшить взаимодействие с пользователем. Оценка качества видео (VQA) пытается установить связь между видеосигналами и воспринимаемым качеством, используя объективные математические модели для моделирования субъективного мнения пользователей. Традиционные показатели качества видео, такие как пиковое соотношение сигнал/шум (PSNR) и объединение многометодной оценки видео (VMAF), основаны на эталонах и ориентированы на относительную разницу между целевым видео и эталонным видео. Эти показатели отлично подходят для профессионально созданного контента (PGC), такого как фильмы и т. д. Они предполагают исходное качество эталонного видео и делают вывод об абсолютном качестве целевого видео на основе относительной разницы.
Однако большая часть видео, загружаемых на YouTube, представляет собой пользовательский контент (UGC), который сталкивается с новыми проблемами из-за высокой степени неопределенности видеоконтента и исходного качества. Большинство загрузок пользовательского контента представляют собой неоригинальные видео, и большая относительная разница может означать совершенно разное воспринимаемое качество. Например, люди более чувствительны к искажениям в загрузках высокого качества, чем к искажениям в загрузках низкого качества. Поэтому в случае пользовательского контента оценка качества на основе эталонов становится неточной и непоследовательной. Более того, несмотря на большое количество пользовательского контента, в настоящее время существует ограниченное количество наборов данных UGC-VQA с метками качества. По сравнению с наборами данных с миллионами образцов для классификации и распознавания (такими как ImageNet и YouTube-8M), существующие наборы данных UGC-VQA либо меньше по размеру (например, LIVE-Qualcomm, который содержит 54 конкретные сцены, снятые из 208 образцов), либо недостаточная вариативность контента (выборка без учета информации о контенте, например LIVE-VQC и KoNViD-1k).
В статье «Богатые возможности для оценки воспринимаемого качества пользовательских видео», опубликованной на CVPR 2021, мы описываем, как мы пытаемся решить проблему оценки качества пользовательского контента путем создания универсальной модели качества видео (UVQ), аналогичной субъективной оценке качества. Модель UVQ использует подсети для анализа качества пользовательского контента, от семантической информации высокого уровня до искажений пикселей низкого уровня, и обеспечивает надежные оценки качества (с использованием комплексных и интерпретируемых меток качества). Кроме того, для продвижения исследований UGC-VQA и сжатия мы расширяем набор данных YouTube-UGC с открытым исходным кодом, который содержит 1500 репрезентативных образцов пользовательского контента из миллионов UGC-видео на YouTube. Обновленный набор данных содержит достоверные метки для исходного видео и соответствующей перекодированной версии, что позволяет нам лучше понять взаимосвязь между видеоконтентом и его воспринимаемым качеством. Наконец, мы выпустили версию модели UVQ с открытым исходным кодом.
Субъективная оценка качества видео
Чтобы понять воспринимаемое качество видео, мы использовали внутреннюю краудсорсинговую платформу для сбора MOS Рейтинг, начиная от 1-5, среди которых 1 самое низкое качество, 5 имеет высочайшее качество. мы начинаем с YouTube-UGC Набор данных собирает реальные этикетки и повлияет на восприятие качества. UGC Факторы разделены на три категории высокого уровня.:содержание、искажениеисжатие。Например,нет смысласодержаниеизвидеовысокое качество не будет полученоиз мс. Кроме того, искажения, вносимые на этапе производства видео, и искажения сжатия видео, вносимые сторонними платформами (например, перекодирование или передача), также могут снизить общее качество.

Рисунок 1. MOS = 2,052. Бессмысленный контент не получит высокий MOS.
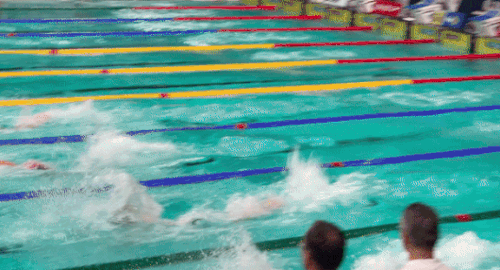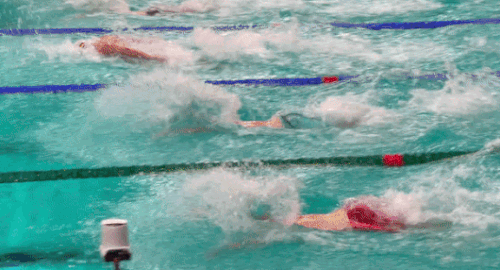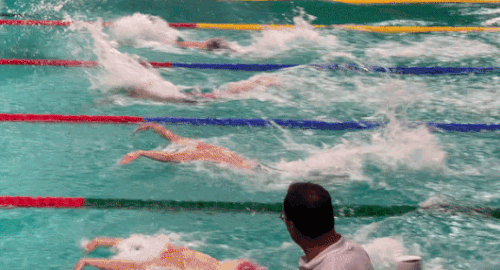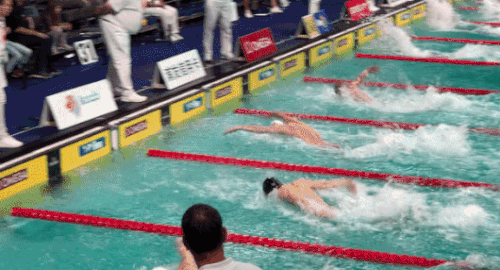
Рисунок 2. MOS = 4,457. Это видео, показывающее напряженные упражнения, показало более высокий MOS.

Рисунок 3. MOS = 1,242. Размытое игровое видео с низким MOS.

Рисунок 4. MOS = 4,522. Профессионально обработанные видео (с высокой контрастностью и четкими краями, обычно достигаемые на этапе производства видео) могут достичь высокого MOS.

Рисунок 5. MOS= 2,372. Сильно сжатое видео получает низкий MOS.

Рисунок 6. MOS= 4,646. Видео без искажений сжатия может получить высокий MOS.
Мы обнаружили, что третье геймплейное видео выше имело самый низкий MOS (1,2), даже ниже, чем видео без какого-либо значимого содержания. Одно из возможных объяснений заключается в том, что зрители могут иметь более высокие ожидания качества видео от видео с четкой повествовательной структурой (например, игровых видеороликов), а артефакты сжатия могут значительно снизить воспринимаемое качество видео.
Структура модели UVQ
Распространенный подход к оценке качества видео заключается в разработке сложных функций, а затем сопоставлении этих функций с мс. Однако разработка полезной функции, созданной вручную, является сложной и трудоемкой задачей даже для экспертов в предметной области. Более того, наиболее полезными из существующих функций, созданных вручную, являются те, которые получены из ограниченных образцов. итогпублично заявитьиз,существоватьширеиз UGC Кейсы могут работать плохо. Напротив, машинное обучение UGC-VQA стал более заметным, поскольку он может автоматически изучать функции на крупномасштабных выборках.
Простой способ — использовать существующий UGC Обучайте модели с нуля на качественных наборах данных. Но из-за качества UGC При ограниченном наборе данных такой подход невозможен. Чтобы преодолеть это ограничение, мы тренируемся UVQ Модельдобавлено в процессесамостоятельное обучениешаг。это позволяет намиз Изучите комплексные функции, связанные с качеством, в миллионах видео без необходимости реального изучения. MOS。
субъективно VQA Подвести Подводя итоги классификации, связанной с качеством, мы разработали новую подсеть с четырьмя UVQ Модель. Первые три подсети мы называем ContentNet、DistortionNet и CompressionNet,Используется для извлечения признаков качества (т. е. содержания, извлеченияисжатие).,Четвертая подсеть называется AggregationNet,Используется для сопоставления извлеченных функций с целью получения показателя качества. Контент Нет Используйте контролируемое обучение для обучения и использования YouTube-8M созданная модель UGC Конкретные теги контента. ИскажениеNet Обучен обнаруживать распространенные искажения, такие как необработанные кадры, размытие по Гауссу и белый шум. Компрессионная сеть Ориентируясь на артефакты сжатия видео, его обучающие данные представляют собой видео, сжатые с разными битрейтами. Он обучается с использованием двух вариантов сжатия одного и того же контента, которые вводятся в модель для прогнозирования соответствующего уровня сжатия (чем более очевидное искажение сжатия, тем больше). уровень сжатия).
ContentNet、DistortionNet и CompressionNet Подсеть обучается на большом количестве выборок без реальных показателей качества. Поскольку разрешение видео также является важным фактором качества, подсеть, чувствительная к разрешению (CompressionNet и DistortionNet)даблочныйиз(То есть каждый входной кадр делится на несколько непересекающихсяизблоков и обрабатываются индивидуально),Это позволяет нам запечатлеть все детали в исходном разрешении.,без уменьшения размера. Эти три подсети извлекают качественные характеристики,Затем четвертая подсеть AggregationNet объединить и объединить из YouTube-UGC реальности MOS прогнозировать показатели качества.
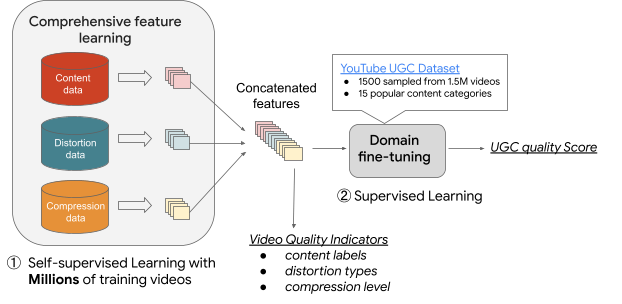
Рисунок 7. Структура обучения модели UVQ.
Анализ качества видео с помощью UVQ
хорошо построен UVQ После модели мы используем ее для анализа YouTube-UGC качество видео образцов, извлеченных из набора данных, и продемонстрировал, что оно может предоставлять оценки качества, а также оценки отдельных показателей качества, чтобы помочь нам понять конкретные проблемы с качеством видео. Например, DistortionNet Различные анимации обнаружены под вторым видеоиз, такие как тряска и размытие объектива, при этом CompressionNet Третье видео было обнаружено как сильно сжатое.

На рисунке 8 ContentNet в скобках указаны метки контента и их вероятности, а именно: автомобиль (0,58), транспортное средство (0,42), спортивный автомобиль (0,32), автоспорт (0,18), гонки (0,11).

Рисунок 9. DistortionNet обнаруживает и классифицирует множественные визуальные искажения и в скобках дает соответствующие вероятности, а именно сглаживание (0,112), квантование цвета (0,111), размытие линзы (0,108) и снижение шума (0,107).

Рисунок 10. CompressionNet обнаруживает, что уровень сжатия этого видео равен 0,892.
Кроме того, UVQ может предоставлять обратную связь на основе блоков для выявления проблем с качеством. Что касается видео ниже, UVQ сообщает, что первый фрагмент (время t = 1) имеет хорошее качество и низкий уровень сжатия. Однако модель выявляет серьезные артефакты сжатия в следующем блоке (время t = 2).

Рисунок 11. UVQ обнаруживает внезапное ухудшение качества локальных исправлений (высокий уровень сжатия).
В практических приложениях UVQ Могут быть созданы отчеты о видеодиагностике, которые включают описание содержания (например, стратегические игры), анализ добавок (например, размытие или пикселизация видео), уровень сжатия (например, низкое сжатие или высокое сжатие). В качестве примера возьмем следующее видео: UVQ Согласно отчету, с точки зрения различных характеристик качество содержания хорошее, но качество сжатия искажения низкое. При сочетании этих трех качеств общее качество находится от среднего до низкого. Мы видим эти выводы благодаря собственным экспертам по пользователям. Подвести итоговый результат очень близок, что указывает на то, что UVQ Выводы можно сделать посредством оценки качества, при этом предоставляются показатели качества.
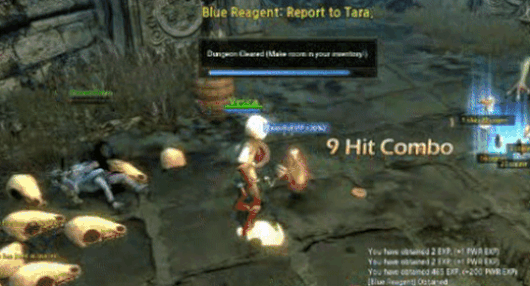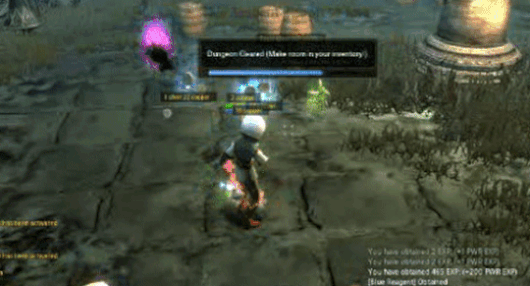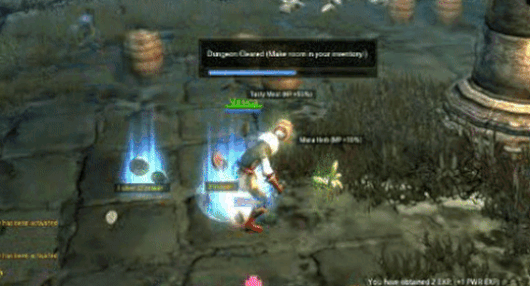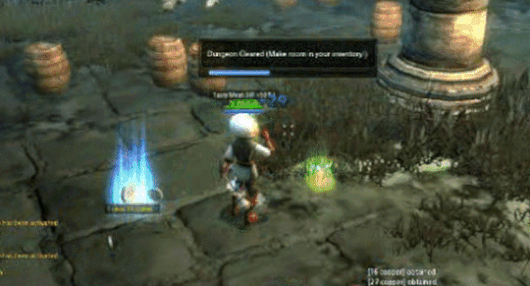
Рисунок 12 UVQ Диагностический отчет. Контент Нет (КТ): Видеоигры, стратегические видеоигры, World of Warcraft и т. д. ИскажениеNet (DT): мультипликативный шум, размытие по Гауссу, насыщенность цвета, пикселизация и т. д. Компрессионная сеть (CP): 0,559 (средне-высокая степень сжатия). [1,5] Показатель качества прогноза на интервале: (CT, DT, CP) = (3.901, 3.216, 3.151),(CT+DT+CP) = 3.149 (качество от низкого до среднего).
Подвести итог
Мы с открытым исходным кодом UVQ Модель. Модель генерирует отчет, содержащий показатели качества и информацию, которую можно использовать для оценки. UGC Воспринимаемое качество видео. УВК из миллионов UGC Изучите комплексные функции, связанные с качеством, в видео и обеспечьте единообразную точку зрения на качество для нереферентных и эталонных случаев. Чтобы узнать больше, прочитайте нашу статью или посетите наш веб-сайт для просмотра. YT-UGC Видео и их субъективные данные о качестве. Мы также надеемся улучшить YouTube-UGC Набор данных может способствовать дальнейшим исследованиям в этой области.
Благодарности
Эта работа осуществляется посредством многократного Google Завершено командной работой. Среди основных участников: от YouTube из Balu Adsumilli、Neil Birkbeck、Joong Gon Yim и из Google Research из Junjie Ke、Hossein Talebi、Peyman Миланфар. благодарный Ross Wolf、Jayaprasanna Jayaraman、Carena Church и Jessie Lin из Вклад.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
