Модель большого языка. Принцип и реализация тензорного параллелизма.
Базовые знания
NCCL
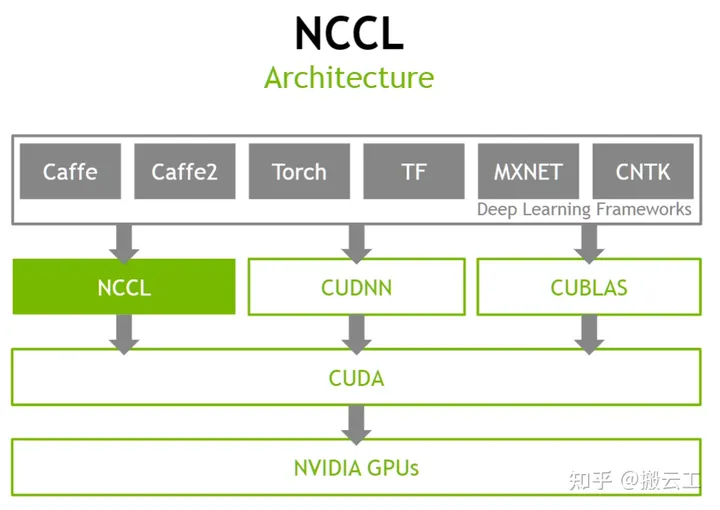
NCCL — это коммуникационная библиотека, разработанная Nvidia для обеспечения связи между несколькими графическими процессорами или платформа для связи между несколькими графическими процессорами. Она предоставляет API-интерфейсы коллективной связи, включая AllReduce, Broadcast, уменьшает, AllGather, уменьшаетScatter и т. д. NCCL скрывает базовые сложные детали, предоставляет восходящие API для вызовов платформы обучения и нисходящие соединения графических процессоров между машинами для обеспечения эффективной передачи параметров модели.
Megatron-LM
NVIDIA Megatron-LM — это среда распределенного обучения на основе PyTorch, используемая для обучения больших языковых моделей на основе Transformer. Мегатрон-ЛМ комплексно применяет параллелизм данных (Data Parallelism), тензорный параллелизм (Tensor Parallelism) и конвейерный параллелизм (Pipeline Parallelism). Он используется в процессе обучения многих крупных моделей, таких как Bloom, opt, Zhiyuan и др.
torch.distributed(dist)
между несколькими вычислительными узлами, работающими на одной или нескольких машинахPyTorch предоставляет примитивы для поддержки параллельного взаимодействия нескольких процессов.。Он может легко распараллеливать вычисления между процессами и машинными кластерами.。
Группа — это часть всех наших процессов.
Библиотека взаимодействия с внутренними процессами. PyTorch поддерживает NCCL, GLOO и MPI.
world_size Количество процессов в группе процессов.
Ранг Уникальный идентификатор, присвоенный каждому процессу в распределенной группе процессов. Это всегда последовательные целые числа от 0 до world_size.
Введение в оператор torch.distributed
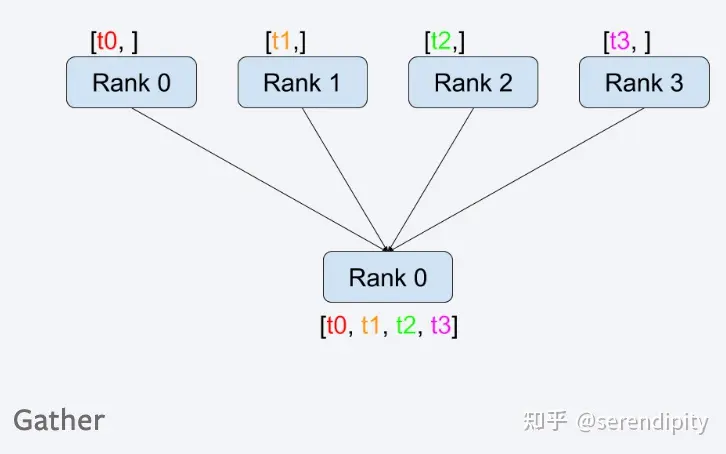
gather
Собирать данные из других процессов в целевой процесс и возвращать список.
all_gather
Он собирает данные всех процессов и затем распределяет их между ними.

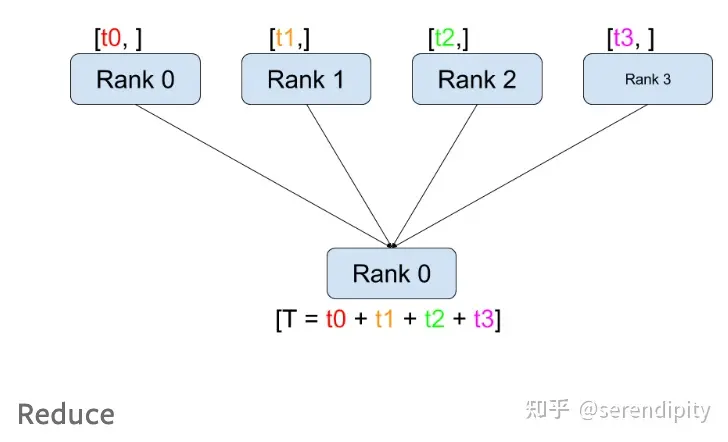
reduce
Сложите данные всех процессов и отправьте их целевому процессу.
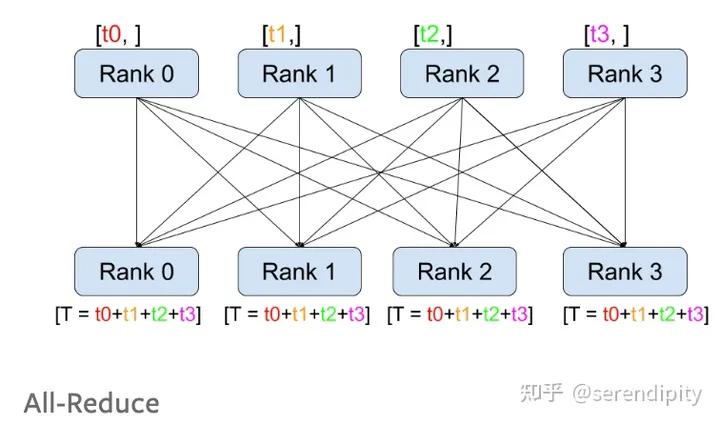
all_reduce
Сложите значения всех узлов и распределите их по всем узлам.
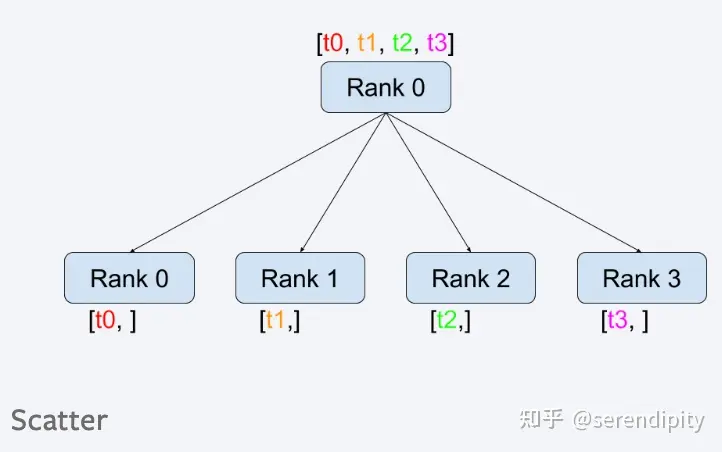
broadcast
Распределить данные определенного узла на все узлы.
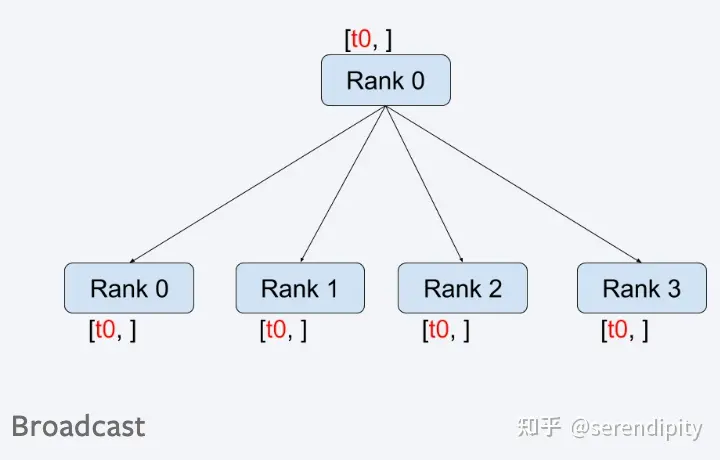
scatter
Распределить данные списка по процессу всем остальным процессам один за другим.
Введение в операторы, поддерживающие параллелизм в LLM
Слой внедрения
Слой Оно содержит два входа, один из которых — слово embedding(v, h) хранит векторы всех слов, а v представляет размер словаря. Списки словаря часто бывают очень большими, и параллелизм в основном рассматривается для слов. Разделение вложения.
Другой вариант — встраивание позиции, которое в основном используется для индексации соответствующего встраивания из встраивания слов. Например, входные данные — это [0, 212, 7, 9]. Каждый элемент в данных представляет собой порядковый номер слова. нужно сделать, чтобы строки 0, 212, 7 и 9 в встраивании слов использовались для поиска соответствующих векторов слов. Обычно он не слишком велик, поэтому нет необходимости рассматривать параллелизм.
Метод сегментации встраивания слов:
Разделить по столбцу
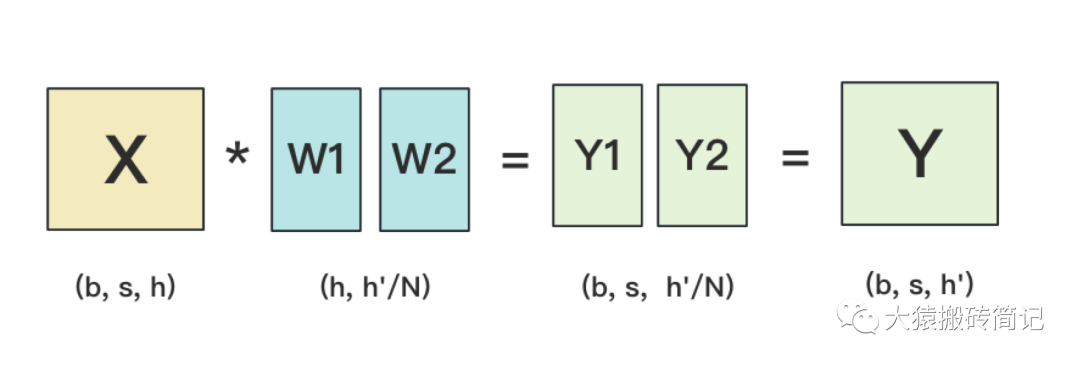
Разделите встраивание слова по столбцам. Каждая карточка имеет полное встраивание позиции. Индексируйте встраивание слова в соответствующую позицию в соответствии со значением встраивания позиции, чтобы получить Y1 и Y2, чтобы получить полный Y.
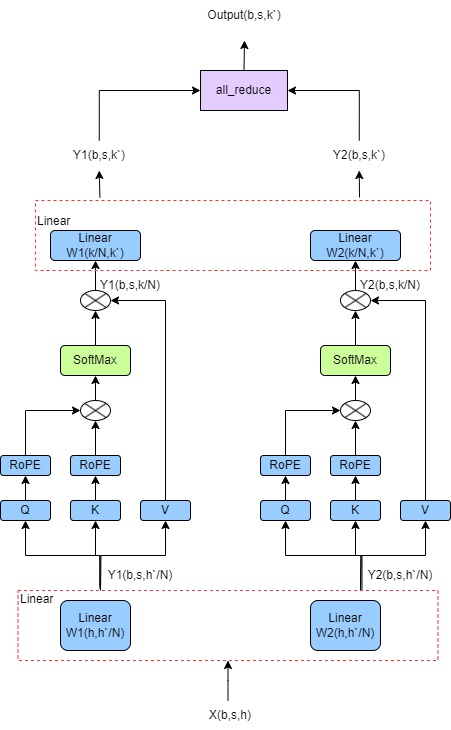
Уровень внимания Llama2
Основная формула внимания:

Как видно на рисунке ниже, слой внимания в модели llama2 добавляет линейный слой до и после основной формулы.
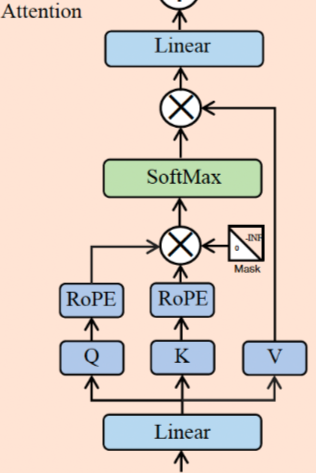
Параллельная стратегия для вышеуказанного уровня внимания:
1. Первое линейное выражение разбивается на столбцы, а вход X рассчитывается с помощью W1 и W2 соответственно для получения двух выходных данных.
2. Каждый из двух выходов первого шага подвергается процессу расчета формулы ядра внимания. После расчета будет два выхода.
3. Второй линейный график разбивается по строкам, и два выходных сигнала второго шага вычисляются с помощью W1 и W2 для получения двух выходных данных.
4. Добавьте all_reduce к двум выходным данным, чтобы получить окончательный результат. Параллельный конец слоя внимания
Процесс выглядит следующим образом:
Слой прямой связи Llama2
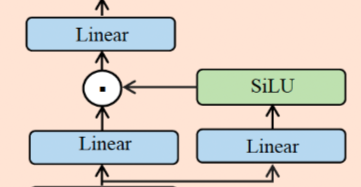
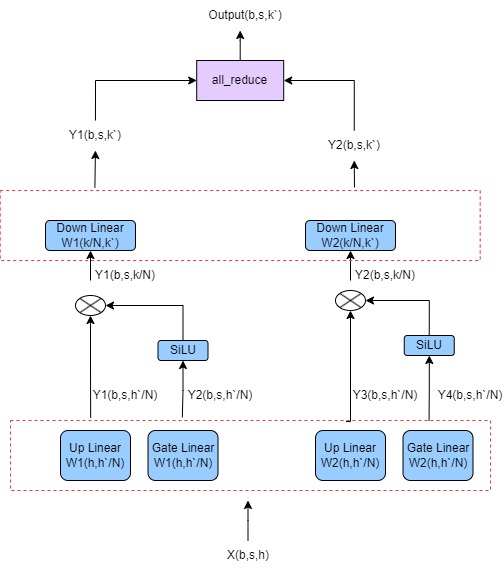
Процесс расчета FeedForward в Llama2 выглядит следующим образом:
down(up(X)*SiLU(gate(X)))
вверх, вниз и ворота — это линейные слои с одинаковыми тремя измерениями. Процесс расчета показан на рисунке:
Параллельная стратегия заключается в следующем:
1. Линейный верхний слой разделен по столбцам. После расчета входного значения X на каждой карте будет получен выходной сигнал.
2. Слой ворот «Линейный» разделяется по столбцам. После расчета входного значения X каждая карта имеет выходной.
3. Выход каждой карты рассчитывается отдельно с помощью SiLU и умножения матрицы.
4. Нижний слой Linear разбивается на строки и рассчитывается отдельно с выходными данными каждой карты для получения двух выходных данных.
5. Добавьте два выхода с помощью all_reduce, чтобы получить окончательный результат.
Процесс выглядит следующим образом:
Отдельный линейный слой
Линейный в основном выполняет матричное умножение,Выполните матричное умножение ввода s*h и веса h*h`,придетсяприезжатьодинs*h`Выход。Процесс выглядит следующим образом:
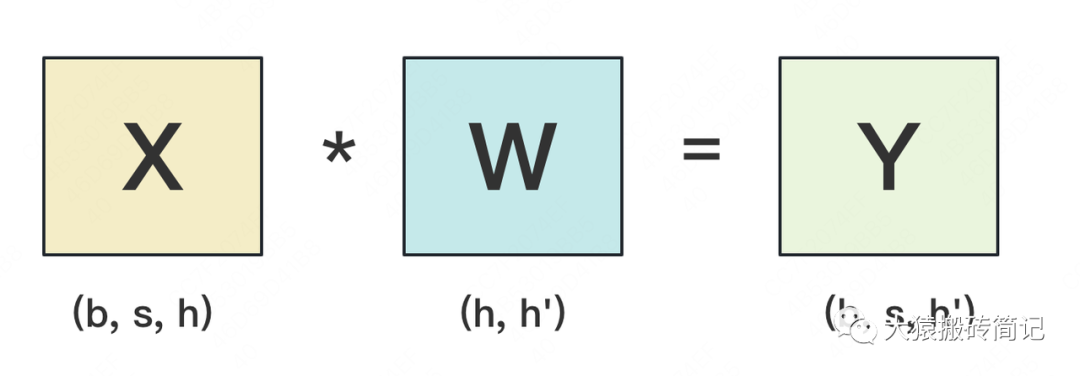
Разделить по столбцу
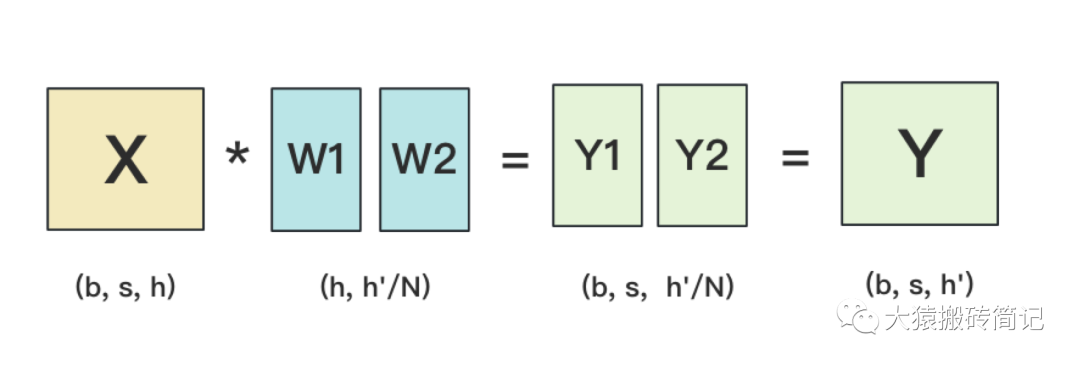
Y1 и Y2 используют оператор all_gather для суммирования результатов и получения окончательного Y.
Реализация кода
Загрузка модели
Каждое вычислительное устройство загружает часть веса соответственно. Функция load_state_dict модели должна загрузить соответствующий вес для каждого устройства в соответствии с количеством устройств. Кроме того, определение слоев и операторов также должно основываться на количестве устройств, позволяя рассчитывать только соответствующие части.
Линейные сводные результаты
Как упоминалось выше, последний Linear уровня внимания и последний Linear уровня MLP должны суммировать результаты, и необходимо использовать оператор all_reduce.
ppl.pmx/torch_function/RowParallelLinear.py at master · openppl-public/ppl.pmx (github.com)
Отдельный Linear должен использовать all_gather для суммирования результатов.
ppl.pmx/torch_function/ColumnParallelLinear.py at master · openppl-public/ppl.pmx (github.com)
Ссылки:



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
