MMA-UNet | Мультимодальная асимметричная сеть слияния, которая повышает производительность слияния инфракрасных и видимых изображений!

Мультимодальное объединение изображений (MMIF) отображает полезную информацию из разных модальностей в одно и то же пространство представления, в результате чего создаются насыщенные информацией объединенные изображения. Однако существующие алгоритмы объединения имеют тенденцию симметрично объединять мультимодальные изображения, что приводит к тому, что результаты объединения теряют неглубокую информацию в некоторых областях или отдают предпочтение одной модальности. в этой статье,Автор анализирует пространственное распределение информации в разных модальностях.,И доказано, что кодирование признаков в одной сети не способствует одновременному выравниванию глубоких признаковых пространств мультимодальных изображений. Чтобы преодолеть эту проблему,Автор предлагаетМультимодальная асимметричная сеть UNet(MMA-UNet)。 Авторы отдельно обучили специальные кодировщики функций для разных модальностей и реализовали стратегию межмасштабного слияния, чтобы сохранять функции разных модальностей в одном пространстве представления, обеспечивая сбалансированный процесс объединения информации. Кроме того, авторы также провели большое количество экспериментов по слиянию и последующим задачам, чтобы продемонстрировать эффективность MMA-UNet в объединении информации инфракрасного и видимого изображения, создавая визуально естественные и семантически богатые результаты слияния. Его производительность превосходит существующие методы сравнительного синтеза.
1. Introduction
Технология объединения инфракрасных и видимых изображений (IVIF) объединяет полезную информацию, полученную различными модальными датчиками, для обеспечения комплексной интерпретации целевой сцены (Sang et al., 2014; Wang et al., 2015; Wang et al., 2016 год; Wang и др., 2017; Ван и др., 2018; Видимые изображения (VI) эффективно улавливают глобальные детали и информацию о цвете целевой сцены, а инфракрасные изображения (IR) превосходно выделяют информацию о температуре. Эффективно объединяя информацию, полученную из этих двух модальностей, можно достичь комплексного восприятия различных условий освещения и сложных сред. Кроме того, IVIF может эффективно помогать в последующих задачах, таких как обнаружение объектов, семантическая сегментация и оценка глубины.
В последние годы IVIF разделили на две основные категории: традиционные методы обработки изображений для извлечения признаков из мультимодальных изображений и архитектуры нейронных сетей для обучения высокопроизводительных моделей слияния изображений.
В поисках более сильных возможностей обобщения и точности слияния недавние усилия были в основном сосредоточены на архитектуре нейронных сетей. IVIF представляет собой нетипичную обратную задачу в области обработки изображений и не ориентируется на реальные ситуации. Поэтому в IVIF сложно внедрить эффективную парадигму обучения с учителем и глубоким обучением. Однако существующие неконтролируемые методы IVIF могут обеспечить привлекательные результаты слияния. Однако слияние, когда пространственное распределение информации среди мультимодальных изображений противоречиво, остается нерешенной проблемой.
Из-за потенциальных проблем объединение изображений из разных модальностей в одной структуре может привести к потере исходной информации об изображении или смещению в сторону особенностей одной модальности. Например, Чжао и др. (2019) предложили двухветвевую декомпозицию признаков IVIF, используя Трансформатор и сверточные слои для извлечения глобальных и локальных признаков изображения соответственно. Однако режим разложения признаков позволяет сети изучать только важные детали или энергию из мультимодальных изображений без учета взаимодействия признаков между ними, что приводит к неравномерному распределению мультимодальной информации в результатах слияния. Ли и др. (2020) представили модуль взаимодействия с графами для содействия интерактивному обучению кросс-модальным функциям. Перед взаимодействием функций необходимо извлечь мелкие функции различных модальных изображений.
Однако, поскольку несогласованность пространственного распределения информации между мультимодальными изображениями игнорируется, нельзя гарантировать, что мультимодальные признаки, вводимые в модуль взаимодействия графов во время интерактивного обучения, будут расположены в одном и том же пространстве представления. Это приводит к ухудшению эффективности стратегии интерактивного обучения. Кроме того, некоторые исследователи (Wang et al., 2019) ввели механизм внимания в процесс извлечения признаков для достижения кросс-модального восприятия. Этот подход предполагает создание карт внимания для особенностей каждой модальности отдельно, а затем перекрестное управление реконструкцией мультимодальных функций.
Однако интерактивное руководство не обязательно может способствовать эффективному извлечению признаков. Когда информационное содержание модального изображения невелико, созданная карта внимания может ввести сеть в заблуждение при определении полезных функций. Луо и др. (2019) предложили метод слияния, основанный на обучении раздельному представлению, для достижения распутанного представления изображений и различения общих и частных функций в мультимодальных изображениях.
Они следуют принципу, согласно которому мультимодальные изображения имеют только одни и те же общие функции, и используют формулу «частные функции + общие функции = исходное изображение» для ограничения сети. Однако из-за внутренних различий в разных модальностях съемки одной и той же сцены общие характеристики изображений могут не быть полностью одинаковыми. Они представляют собой схожие аспекты одного и того же объекта, например, детали в VI и слабую текстуру в IR. Короче говоря, вышеупомянутые методы, будь то с точки зрения глобального-локального, кросс-модального взаимодействия функций, управления перекрестным вниманием или общих-частных функций, не учитывают разницу в пространственном распределении информации между мультимодальными функциями. Следовательно, для того, чтобы рассуждать о повышении производительности термоядерного синтеза, необходимы сложные или фиксированные парадигмы.
В этом исследовании авторы пересмотрели метод выделения мультимодальных признаков для IVIF и разработали простую и эффективную асимметричную структуру слияния для преодоления проблемы непоследовательного пространственного распределения информации в мультимодальных изображениях.
Автор анализирует пространственное распределение мультимодальных признаков.,и заметил то же самоесеть Скорость достижения глубокого смыслового пространства в разных модальных образах существует.разница。Основные вклады резюмируются следующим образом.:
- Для IVIF автор предложил Мультимодальную асимметричная сеть UNet(MMA-UNet)Архитектура,По сравнению с существующими сложными парадигмами,Этот метод проще и эффективнее при объединении мультимодальных функций.
- Автор обнаружил пространственное распределение информации между инфракрасным (ИК) и видимым светом (ВИ).,И получил асимметричную сеть. Предложенный метод эффективно сохраняет особенности разных модальностей в одном и том же пространстве представления.,Для ФОМС предлагается новая парадигма интеграции.
- Автор проверил эффективность и превосходство MMA-UNet на существующем общедоступном наборе данных.,Он превосходит существующие современные алгоритмы для решения последующих задач.
Motivation
Существующие алгоритмы IVIF в основном ориентированы —Эффективно изучить мультимодальное взаимодействие функций,Однако несогласованность распределения пространственной информации в мультимодальных изображениях игнорируется. поэтому,Авторы переосмысливают парадигму мультимодального слияния. первый,Две уникальные UNet были обучены на наборе IRи ВИданные соответственно.,Представлены соответственно как IR-UNet и VI-UNet. Затем,Авторы рассчитали выравнивание по центру ядра (CKA) признаков, извлеченных двумя кодировщиками UNets (Zhou et al.,2017) сходство. Как показано на рисунке 1(а)и(б),пожалуйста, обрати внимание,Общее количество слоев намного превышает заявленную UNet глубину. Последний учитывает только сверточные слои в сети.,Но автор включает все промежуточные представления. Конкретно,Для платформы UNet,Первый сверточный блок содержит 7 слоев промежуточных представлений объектов.,Блоки свертки со второго по пятый содержат 11 слоев промежуточных представлений объектов. Нейронная сеть имеет тенденцию изначально изучать мелкие функции,По мере увеличения глубины сети,Они постепенно углубляются в более глубокие семантические пространства для изучения функций. Мелкие черты в основном схожи. Однако,По мере увеличения глубины сети,Разница между глубокими и мелкими особенностями увеличивается. ИК захватывает мелкие детали в первых 22 слоях.,потому что они имеют большее сходство с окружающими объектами,Как показано на рисунке 1(а). Когда глубина превышает 22 слоя,Извлеченные объекты значительно отличаются от окружающих объектов.,На рисунке 1 он имеет более темный цвет. Напротив,Сеть извлечения признаков VI демонстрирует свою уникальность, начиная с уровня 12.,И между последующими функциямиразница Продолжать увеличивать。Таким образом, автор отмечает, что при той же архитектуре VI достигает глубокого семантического пространства быстрее, чем IR, а в сети автора VI может извлекать неглубокую информацию на 10 слоев быстрее, чем IR.
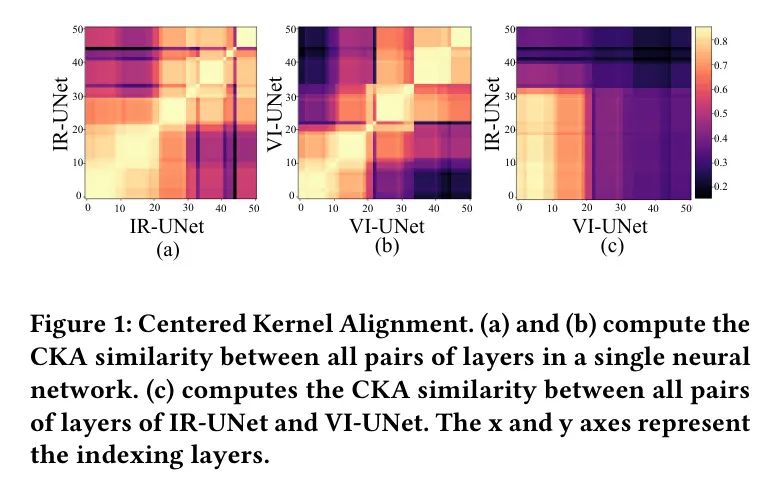
В некоторых исследованиях (Zhou et al., 2017; Liu et al., 2019) сообщается, что мультимодальные изображения можно использовать для различения общедоступных и частных функций в MMIF. Публичные объекты имеют высокое сходство, а частные — нет. Как показано на рисунке 1(c), автор рассчитал сходство CKA между особенностями каждого слоя VI и IR. Первые 30 слоев функций IR очень похожи на первые 20 слоев функций VI, что указывает на то, что скорость извлечения частных функций IR медленнее, чем у VI. Более того, это еще раз подтверждает сделанный выше вывод о том, что VI быстрее достигает глубокого семантического пространства, чем IR.
2. Related Work
Сначала мы рассматриваем соответствующие работы в двух основных областях: во-первых, мы обсуждаем последние достижения в области классификации изображений на основе глубокого обучения; во-вторых, мы освещаем исследования в области малократного обучения и его применения для обнаружения объектов.
Infrared and Visible Image Fusion Methods
Существующие алгоритмы IVIF, основанные на глубоком обучении, в основном делятся на две категории: генеративные модели и модели кодирования. Генеративные модели в основном основаны на генеративно-состязательных сетях (GAN) и диффузии. Они стремятся изучить распределение данных из скрытого пространства и смоделировать распределение целевых данных путем генерации данных. Например, Лю и др. (2019) предложили целенаправленную стратегию двойного состязательного обучения для получения результатов объединения, полезных для последующих задач. Они разработали дискриминаторы объектов и деталей для изучения характеристик объектов из IR и VI соответственно.
Чтобы решить проблемы слабой стабильности обучения и отсутствия интерпретируемости в моделях на основе GAN, Чжао и др. (2019) представили модель диффузии шумоподавления для IVIF, определяя задачу объединения как безусловно сгенерированную подзадачу и максимальное правдоподобие. подзадача. Напротив, модели кодирования не генерируют новые выборки данных, а извлекают ключевые характеристики из исходных входных данных, отображая исходные данные в более компактное пространство представления. Например, Ма и др. [22] внедрили Swin Transformer в объединение изображений и включили междоменный модуль, управляемый вниманием. Этот дизайн эффективно объединяет мультимодальную дополнительную информацию и глобальную интерактивную информацию.
Чтобы улучшить интерпретируемость извлечения признаков, Ли и др. [10] предложили структуру объединения изображений, основанную на обучении представлению, устанавливающую связь между математическими формулами и сетевой архитектурой для повышения интерпретируемости извлечения признаков. Они использовали теорию обучения представлений низкого ранга для построения модели декомпозиции изображения, эффективно избегая трудоемкого проектирования сети. Поскольку структура слияния изображений продолжает совершенствоваться, некоторые исследователи начали анализировать эффективность моделей слияния при выполнении последующих задач. Появилось множество методов многозадачного совместного обучения [15, 34]. Например, объединение с обнаружением объектов [15], объединение с семантической сегментацией [17, 34], объединение с обнаружением заметных объектов [40] и объединение с усилением при слабом освещении [33]. Они обычно направляют обучение объединенной сети посредством обратной связи по результатам объединения последующих задач. Кроме того, из-за пространственной деформации и смещения мультимодальных датчиков в процессе визуализации в некоторых исследованиях была предложена модель «регистрации и слияния» (Shi et al., 2017; Wang et al., 2018; Wang et al. , 2019), чтобы эффективно избежать чрезмерной зависимости алгоритма от пар регистрационных данных.
3. Method and Analysis
В этом разделе авторы впервые предоставляют подробную информацию обо всех компонентах и функциях потерь MMA-UNet. Затем дополнительно анализируются принципы и осуществимость проектирования асимметричной архитектуры и механизма наведения.
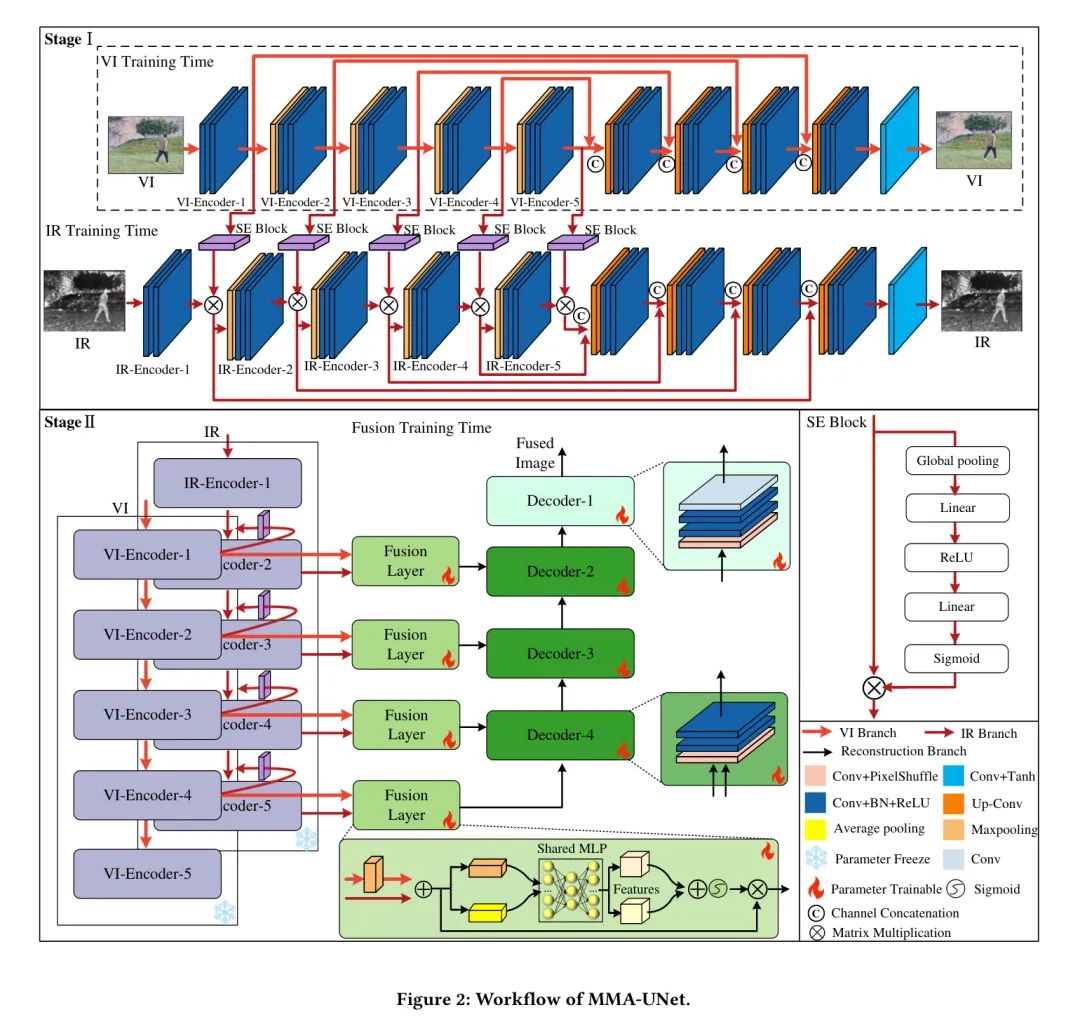
IR-UNet and VI-UNet
На первом этапе две разные модели UNet были независимо обучены с использованием инфракрасного (ИК) и видимого света (VI) соответственно. Обратите внимание, что сначала обучается IR-UNet, а затем VI-UNet. Как показано на рисунке 2, для обучения VI-UNet авторы представили исходную архитектуру UNet (Wang et al., 2018) и доработали ее, преобразовав ввод и вывод в три канала. Для обучения IR-UNet автор использует информацию из VI, чтобы помочь IR-UNet изучить функции IR, тем самым ускоряя процесс извлечения функций сети. В частности, часть автоэнкодера совместима с VI-UNet. Единственное отличие заключается в этапе извлечения признаков кодера, где авторы используют сжатие и возбуждение (блок SE) (He et al., 2016) для получения карт внимания информации VI, а затем сравнивают их поэлементно с IR. карты признаков. Этот процесс может внедрить важную информацию, полученную VI, в функции IR, чтобы помочь сети IR-UNet в извлечении функций. Стоит отметить, что в процессе обучения IR-UNet параметры VI-UNet замораживаются. Чтобы обучить эти две модели UNet отдельно, среднеквадратическая ошибка (MSE) вводится как функция потерь для достижения разложения и реконструкции изображения, используя следующую формулу:
в
и
Представляет высоту и ширину изображения соответственно.
представляет входное изображение,
Представляет выходное изображение.
Asymmetric UNet
Нет.дваэтапы включают слияниеиреконструкция。обычными методами термоядерного синтеза(Wangи др.,2019) наоборот,Автор использует асимметричную архитектуру. Поскольку изображения разных модальностей имеют уникальное пространственное распределение информации,Поэтому в той же Архитектуре,Количество сверточных слоев для извлечения глубоких семантических особенностей также должно варьироваться в зависимости от разных модальностей. поэтому,Автор спроектировал асимметричную Архитектуру UNet.,Объединив результаты сходства CKA,Это позволяет объединять различные модальные характеристики с одинаковым пространственным распределением информации.
Конкретно,Как показано на рисунке 2,Автор использует кодировщик IR-UNetиVI-UNet для извлечения низкоуровневых и глубоких семантических особенностей IRиVI. впоследствии,Автор объединяет первые четыре уровня функций VI-UNet с последними четырьмя уровнями функций IR-UNet. Например,Автор объединяет первые четыре уровня функций VI-UNet с последними четырьмя уровнями функций IR-UNet.,Создаются четыре набора объединенных карт объектов. Для стратегии интеграции,Автор сначала снижает дискретизацию карты объектов VI, чтобы она соответствовала размеру карты функций IR. Затем над добавленными функциями выполняются операции добавления функций и внимания канала (Васвани и др.,2017),Это усиливает важные функции и подавляет ненужные функции. наконец,Авторы реконструируют слитые элементы для получения слитого изображения.
Для первых трех слоев декодера авторы используют операции свертки и перемешивания пикселей для повышения дискретизации. Последний уровень декодера добавляет
Ядро свертки。在Нет.дваэтап,Автор вводит MSE, показатель индекса структурного сходства (SSIM) и норму L1 для расчета соответствующей функции потерь. SSIM рассчитывается следующим образом:
в
и
представляет собой два разных изображения.
репрезентативное изображение
среднее значение
репрезентативное изображение
Стандартное отклонение
репрезентативное изображение
и
ковариация.
и
— константа, используемая для предотвращения приближения знаменателя формулы к 0. Таким образом, структурные потери,
Формула расчета следующая:
потеря детализации,
, выраженный следующим образом:
в
Это оператор Собеля.
функция полных потерь,
, можно выразить как:
вF означает слитое изображение.
Analysis for Multi-modal Feature Extraction
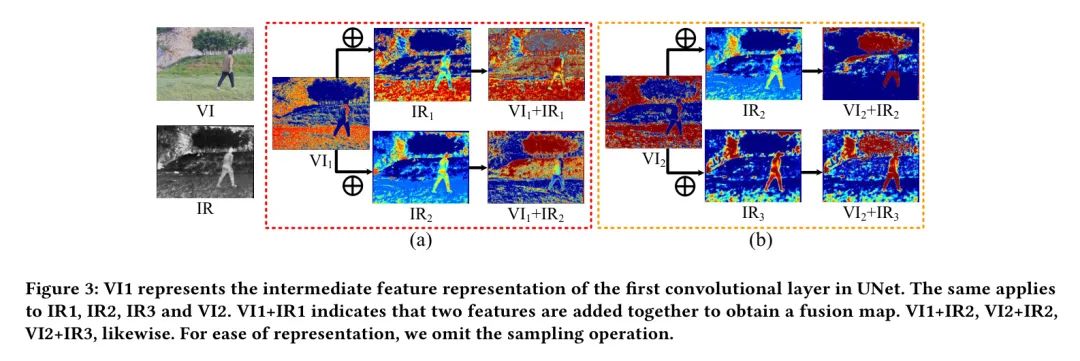
Предыдущие исследования (Wang et al.,2018 г.;,2019 г.;,2019) не обсуждали степень извлечения признаков различными способами в рамках одной и той же структуры. с этой целью,Авторы провели визуальный анализ карт характеристик VI-UNet и IR-UNet. На рисунке 3(а) показаны результаты сложения карт признаков на разных уровнях. в мелком слое,Кодер извлекает функции на уровне пикселей.,Например, текстура листьев и травы, а также детали пешеходов. в то же время,Эту поверхностную информацию можно идентифицировать на изображениях различной модальности. Когда один и тот же уровень двух модальностей выполняет операцию сложения,Результат становится лишним. Для задач MMIF,Сосредоточьтесь на Дополнительная информация, полученная с помощью различных методов, имеет решающее значение. для публичных функций,Сначала следует извлечь пиксели, захваченные датчиком VI.,Потому что они ближе к зрительной системе человека (ЗСЧ). также,Обработка большого количества похожих функций из разных модальностей ослабляет репрезентативную способность Модели.,Тем самым влияя на его производительность и способность к обобщению. Напротив,Асимметричное слияние соответствует концепции MMIF.,Он объединяет полезную информацию из разных модальных изображений и устраняет избыточную информацию. Он включает в себя информацию об ИК-излучении, сохраняя при этом детали VI. По мере увеличения количества слоев,Функции, извлекаемые кодировщиком, становятся более абстрактными. Существует дисбаланс в глубине извлечения признаков.,в Функции, извлекаемые с помощью модальности, более абстрактны.,Другая модальность имеет относительно поверхностные характеристики. поэтому,Прямое слияние может привести к чрезмерной зависимости модели от абстрактных функций.,приводит к информационному дисбалансу. Информация об объектах из ИК теряется в результате слияния одного и того же слоя.,А из результатов, полученных с помощью стратегии асимметричного слияния,Дополняющие друг друга особенности нескольких модальностей хорошо сохранились.,Как показано на рисунке 3(b).
Analysis for Guidance Mechanism
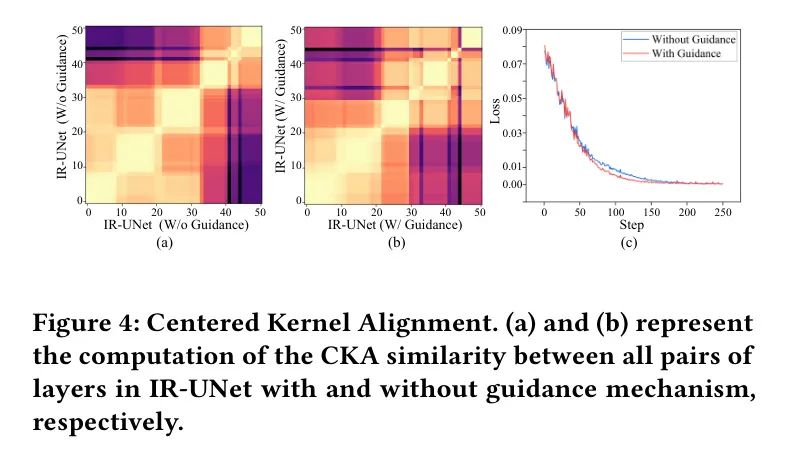
Из-за непоследовательного распределения пространственной информации в разных модальностях существуют различия в скорости извлечения глубоких смысловых особенностей в рамках одной и той же структуры. Чтобы ускорить извлечение глубокой семантической информации из инфракрасных изображений (ИК), авторы используют функции визуального изображения (VI) для управления реконструкцией ИК-функций на каждом уровне. Авторы сравнили сходство двух наборов CKA, полученных с помощью двух разных методов обучения. Как показано на рисунке 4, в IR-UNet без механизма наведения существенное расхождение семантической информации появляется только после 30 слоев. Однако после введения механизма наведения IR-UNet начинает проявлять глубокие семантические особенности после 22-го уровня. Это экспериментальное явление показывает, что механизм управления способствует кросс-модальной передаче знаний, позволяет IR-UNet быстрее изучать семантические функции, связанные с задачей, и ускоряет скорость переобучения модели.
4. Experiment
- Начало экспериментального раздела.
Experimental Setting
На двух блоках NVIDIA GeForce RTX 3090 Графический процессор и 64-ядерный процессор Intel Xeon Platinum 8350C Эксперименты проводились на процессоре. Экспериментальные настройки VI-UNet и IR-UNet одинаковы. Для настройки параметров обучения автор выбрал оптимизатор AdamW. Базовая скорость обучения изначально установлена на
, затухание веса установлено на
. Стратегия косинусного отжига используется для адаптивной регулировки скорости обучения. Что касается увеличения данных, авторы использовали обрезку случайного размера. Кроме того, экспериментальные настройки фреймворка Fusion немного отличаются от IR-UNet. Базовая скорость обучения изменена на
. В функции потерь
и
соответственно установлен на
и
。
Dataset and Evaluation Metrics
Авторы выбрали M3FD (Liu et al.,2017) и MSRS (Лю и др.,2017) Данные установлены в качестве эксперимента. Конкретно,В качестве обучающего набора автор выбрал 4200 и 1083 пары изображений из M3FD и MSRS соответственно. Что касается тестового набора,Имеется 300 пар изображений M3FD и 361 пара изображений MSRS.
Чтобы проверить превосходство MMA-UNet в производительности сварки, авторы выбрали семь современных методов сравнения (SoTA). Эти методы сравнения охватывают все популярные структуры мультимодального слияния (MMF), включая модель алгоритмического развертывания (LRRNet) (Liu et al., 2017), гибридную модель (CDDFuse) (Wang et al., 2017), модель на основе CNN ( МФЭИФ) (Лю и др., 2017), на основе Tr модель анформера (TGFuse) (Wang et al., 2017), модель на основе GNN (IGNet) (Wang et al., 2017), модель на основе GAN (TarDAL) (Liu et al., 2017) и модель на основе диффузии модель (DDFM) (Ванг и др., 2017).
Авторы выбрали пять популярных показателей объективной оценки для качественной оценки различных методов слияния, включая метрику Чена-Блюма (
), мера сходства на основе ребер (
),Верность визуальной информации (VIF),Индекс структурного подобия (SSIM) и пиковое отношение сигнал/шум (PSNR) (Wang et al.,2017 г.;,2017). По этим показателям,Чем выше оценка, тем лучше качество объединенного изображения.
В задаче обнаружения,Автор использовал размеченные пары изображений, предоставленные M3FD.,И разделите их на обучающий набор, проверочный набор и тестовый набор в соотношении 6:3:1. Автор использует основную сеть обнаружения.,YOLOv7 (Редмон и др.,2016),проверить результаты слияния. в разделении задач,Автор использовал обучающий и тестовый набор, предоставленный MSRS, для проведения обучающего и тестового эксперимента по сегментации сети (Wang et al.,2017). Для обеспечения строгости эксперимента,Экспериментальная постановка всех последующих задач Модель строго соответствовала условиям, изложенным в исходном тексте.
Qualitative Analysis
Анализ слияния. Как показано на картинке5показано,С точки зрения деталей и структурной информации,MMA-UNet превосходит сравниваемые методы. Например,Области, отмеченные кружками в первом наборе объединенных изображений,когда скрыт густым дымом,MMA-UNet способен хорошо сохранять контуры гор и подробную информацию о текстурах, полученную с помощью ИК-излучения. также,Во втором наборе результатов слияния,Когда VI переэкспонирован,MMA-UNet хорошо справляется с сохранением структуры дома в ИК и устранением пересветов. Это все из-за асимметричного слияния в одном и том же пространстве признаков.,Достигается информационный баланс разных модальностей. наконец,И IGNet, и MFEIF, и DDFM потеряли подробную информацию и в разной степени снизили контраст в двух наборах результатов слияния.

Обнаружение и анализ. На рисунке 6 показано сравнение MMA-UNet и метода сравнения в эксперименте по обнаружению. В этой ситуации дым в VI блокирует информацию о пешеходах внутри. Следовательно, метод слияния должен идентифицировать пиксели, которые извлекают интерференционные характеристики и собирают наиболее ценную информацию о тепловой энергии из ИК-излучения. Как показано на рисунке 6, детектор достигает наибольшей точности при использовании MMA-UNet, что демонстрирует положительное влияние предложенного алгоритма на последующие задачи.

Сегментационный анализ. На рисунке 7 показаны результаты семантической сегментации слитых изображений, созданных разными методами. Как показали две серии экспериментов, только MMA-UNet всегда предоставляет наиболее точную информацию о цели и демонстрирует высокую способность улавливать информацию о пешеходах, скрытую в далекой темноте. Это показывает, что предложенная асимметричная структура эффективно сохраняет дополнительную информацию из разных модальных изображений. В других алгоритмах сбой сегментации происходит из-за избыточной информации, например, из-за захвата более подробной, но более слабой и более зашумленной информации о пикселях из VI.

Quantitative Analysis
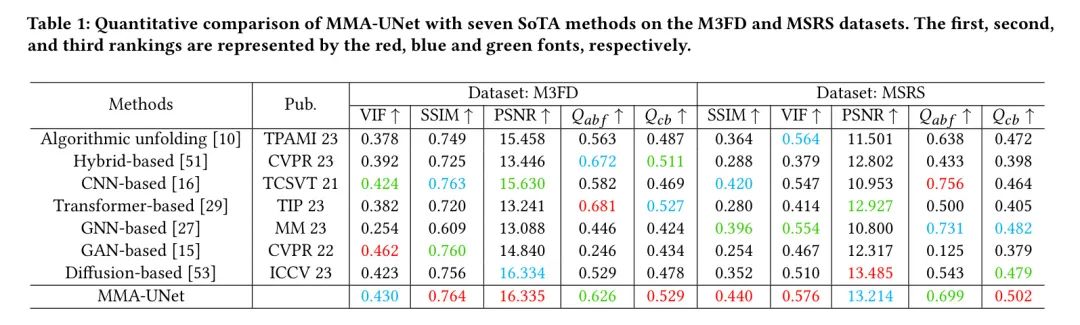
Анализ слияния. В таблице 1 приведены средние значения пяти объективных показателей в двух общедоступных наборах тестов. общий,Используете ли MSRS или M3FD,Оба MMA-UNet достигли наилучшей производительности. Конкретно,Две метрики SSIMи
Всегда показывайте лучшее соотношение цены и качества,Показывает, что MMA-UNet способен сохранять структуру и контрастность исходного изображения.,и генерирует результаты слияния, которые наиболее соответствуют HVS. Рейтинг ВИФи ПСНР незначительно колеблется,Но всегда показывал высокую производительность. Отличные значения PSNR и VIF доказывают, что результаты слияния автора обладают высокой надежностью и высокой достоверностью информации. Для двух наборов данных,
Занимая третье место, MMA-UNet демонстрирует стабильные возможности сохранения периферийной информации.
Обнаружение и анализ. В таблице 2 показана точность обнаружения каждой категории в M3FD для всех методов, включая исходные изображения. MMA-UNet показывает лучшую точность обнаружения, чем другие методы по показателю AP@0,5иAP@[0,5:0,95]. Поскольку различные сложные условия часто влияют на обнаружение одной модальности, производительность,MMIF может повысить надежность обнаружения,Поэтому объединенные изображения обычно приводят к повышению точности обнаружения. также,MMA-UNet демонстрирует превосходную точность обнаружения в различных категориях.,особенно для людей,Это показывает, что у людей сохраняется отличная детализация и структурная информация.
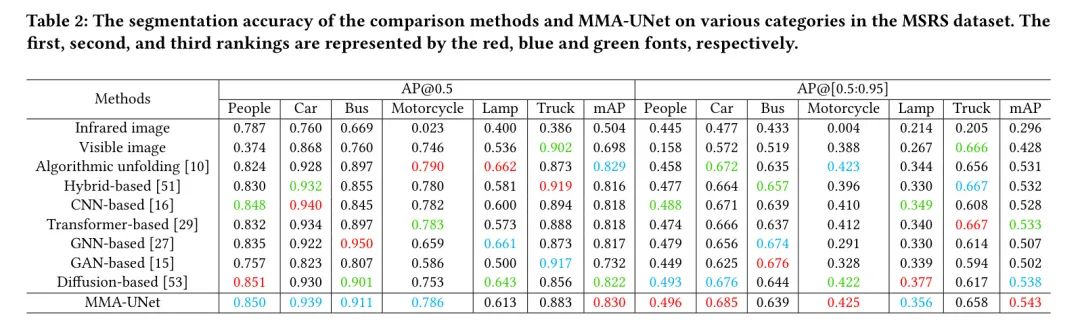
Таблица 1: На наборе M3FDиMSRSданные,MMA-UNetс семью видамиSoTAКоличественное сравнение методов。排名Нет.一、два、Трое в красном、Обозначается синим и зеленым шрифтом.
Таблица 2. Набор данных MSRS,метод сравненияиMMA-UNetТочность сегментации по каждой категории。排名Нет.一、два、Трое в красном、Обозначается синим и зеленым шрифтом.
Рисунок 3: V11 представляет собой промежуточное представление функций первого сверточного уровня UNet. То же самое относится и к IR1.、IR2、ИР3и В2. V1+IR1 означает добавление двух функций для получения объединенной карты. То же самое касается В1+ИР2, V12+IR2 и V12+IR3. Чтобы упростить представление,Авторы опустили операцию выборки.
Сегментационный анализ. В таблице 3 показаны показатели сегментации каждой категории в наборе данных MSRS для всех методов, включая исходные изображения. MMA-UNet достиг наилучшей точности сегментации. первый,Благодаря преимуществам MMIF,Методы слияния обычно обеспечивают более высокую точность сегментации, чем одномодальные изображения. также,MMA-UNet занимает более высокое место по точности сегментации в каждой категории.,Демонстрирует стабильное сочетание производительности и генерации богатой семантической информации в различных сценариях.
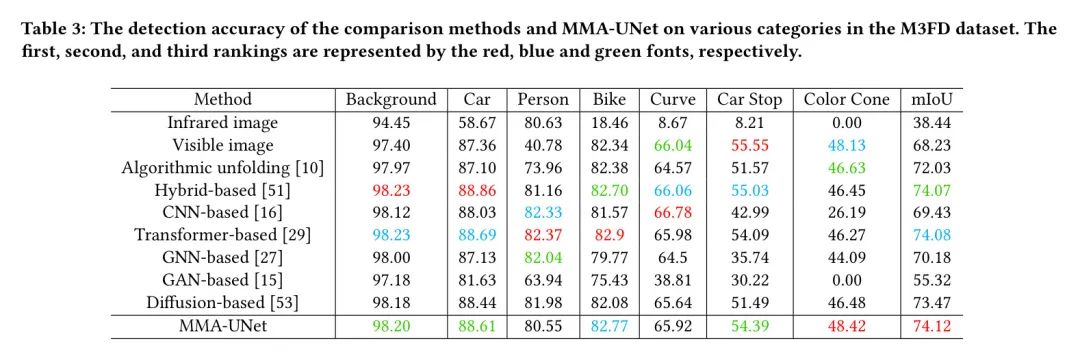
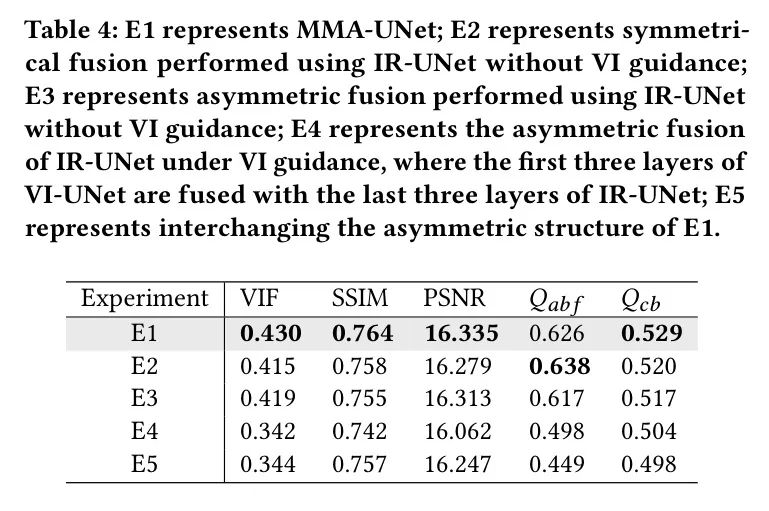
Таблица 4: На наборе M3FDданные,Предлагаемый метод и средние объективные показатели, полученные для различных стратегий абляции. общий,MMA-UNet обеспечивает оптимальную производительность сварки. Конкретно,После потери руководства VI по извлечению функций IR-UNet,Как симметричные, так и асимметричные методы слияния хуже, чем MMA-UNet, сохраняют структурную информацию и точность исходного изображения. В основном это связано с руководством VI, которое помогает выровнять пространственное распределение информации между двумя модальностями.,Это полезно для последующего слияния и реконструкции совмещенного изображения. также,Хотя E4 использует IR-UNet под управлением VI,Но его чрезмерно асимметричный подход отбрасывает слишком много поверхностной ИК-информации.,Это приводит к значительному снижению точности изображения, структурного сходства и сохранения информации о краях. наконец,Это видно с Е5.,Замена асимметричных структур приводит к снижению производительности модели fusion. Это можно объяснить наличием значительных различий в пространстве представления слияния признаков.,В результате детали и смысловая информация теряются в процессе слияния.
Вышеупомянутые эксперименты подтверждают эффективность предложенной асимметричной структуры и вывод о том, что извлечение признаков VI достигает более глубокого семантического пространства быстрее, чем IR.
Таблица 4. E1 представляет собой MMA-UNet; E2 представляет собой симметричное слияние с использованием IR-UNet без управления VI; E4 представляет собой асимметричное слияние IR-UNet под контролем VI, а первые три уровня VI-UNet соответствуют последним трем слоям. слиты E5 представляет собой асимметричную структуру обмена E1;
Рисунок 4. Центральное выравнивание ядра. (a) и (b) соответственно выражены в IR-UNet,С механизмом наведения или без него,Расчет сходства CKA между всеми парами слоев.
Рисунок 5. Сравнение субъективных результатов слияния, полученных методами сравнения MMA-UNet и SoTA на M3FDиMSRS.
Таблица 3. О наборе M3FDданные,метод сравненияиMMA-UNetТочность обнаружения по категориям。排名Нет.一、два、Трое в красном、Обозначается синим и зеленым шрифтом.
5. Discussion
Раздел 5 — начало раздела обсуждения.
Conclusion
В этом исследовании,Авторы предлагают асимметричную архитектуру UNet для IVIF.,Предоставляет простой и эффективный метод объединения функций мультимодального изображения. Автор анализирует распределение пространственной информации между модальностями IRиVI, разница.,И рассудил, что в скорости извлечения глубоких смысловых особенностей из разных модальностей в рамках одной и той же структуры существует разница. Чтобы решить эту проблему,Автор разработал правило межмасштабного слияния, основанное на разном количестве слоев. впоследствии,Автор разработал механизм руководства для обучения IR-UNet.,Замечено, что простое руководство с использованием функций VI повышает эффективность глубокого извлечения семантических функций в IR. Результаты экспериментов показывают,MMA-UNet превосходит существующую основную архитектуру,Достигнута хорошая производительность в MMIF и последующих задачах.
Limitations and Future Work
В этом исследовании,Автор раскрывает пространственное распределение информации между инфракрасным (ИК) и видимым светом (ВИ).,И предложил особую, асимметричную, межмасштабную фьюжн-сеть Архитектура. Однако,Предлагаемая асимметричная сеть UNet требует ручного анализа пространственного распределения информации между изображениями разных модальностей.,И в соответствии с этой разницей в конструкции предусмотрены сросшиеся слои. поэтому,в будущей работе,С целью распространения предлагаемого метода на более широкий круг зрительных задач,Автор стремится разработать адаптивный механизм.,Выборочная корректировка разницы слоев при слиянии различных модальных объектов.
ссылка
[1].MMA-UNet: A Multi-Modal Asymmetric UNet Architecture for Infrared and Visible Image Fusion.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
