Мировая премьера отечественной модели «генерации текстового видео» с открытым исходным кодом! Бесплатный онлайн-опыт, бесплатное создание видео одним щелчком мыши

Новый отчет мудрости
Редактор: ЛРС
【Шин Джиген Введение】AIGCмаршировать ввидеогенерировать!
В апреле прошлого года OpenAI выпустила DALL-E 2, который охватил всю область AIGC благодаря более высокому разрешению, более реалистичному созданию изображений и более точному пониманию естественных описаний.
Однако для реальной демократизации генерации изображений требуется открытый исходный код Stable Diffusion, который можно запускать только на графических процессорах потребительского уровня. Пользователи могут точно настраивать свои собственные наборы данных и не должны терпеть «безопасность», установленную крупными компаниями. Веб-сайты рисования. Различные списки слов с фильтрацией действительно реализуют «свободу рисования».
В области создания видео крупные производители пока осмеливаются использовать только демо-версии для демонстрации, а обычные пользователи пока не могут их использовать.
Недавно Академия Alibaba DAMO впервые открыла параметры модели «генерации текстового видео» на ModelScope, и вместе мы сможем достичь «свободы видео»!

Ссылка на модель: https://modelscope.cn/models/damo/text-to-video-synthesis/files.
Ссылка на опыт: https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis
Необходимо вводить только текст, и могут быть возвращены видео, соответствующие текстовому описанию. Эту модель можно применять к созданию видео в «открытых полях» и делать выводы на основе текстовых описаний. Однако в настоящее время она поддерживает только ввод на английском языке.
Например, введите классическую фразу «космонавт верхом на лошади», чтобы заставить космонавта двигаться!
Или введите «панда ест бамбук на камне», чтобы просмотреть видео ниже.
Вы также можете ввести подсказку самостоятельно в соответствии с интерфейсом, представленным на HuggingFace. Например, если вы введете «собака, едящая торт», вы можете получить 2-секундное видео, однако из-за недостаточности вычислительных ресурсов вам может потребоваться это сделать. постойте в очереди какое-то время.
Отечественный первый релиз «Text-Video Generation»
Модель диффузии генерации текста в видео состоит из трех подсетей: «извлечение текстовых признаков», «модель диффузии текстовых признаков в скрытое пространство видео» и «скрытое видеопространство в видеовизуальное пространство». 1,7 миллиарда.
Модель диффузии многоэтапной генерации текста в видео использует структуру Unet3D и реализует функцию генерации видео посредством процесса итеративного шумоподавления из видео с чистым гауссовским шумом.
В основном имеются два связанных документа для справки по реализации.
Синтез изображений высокого разрешения и модель скрытой диффузии
Разлагая процесс формирования изображения на последовательное применение шумоподавления автокодировщика, модель диффузии достигает самых современных результатов синтеза данных изображения и других данных, а формулировка модели диффузии может принять механизм управления для управления процесс генерации изображения без необходимости повторного обучения.

Однако, поскольку эти модели часто работают непосредственно в пиксельном пространстве, оптимизация мощных диффузионных моделей часто занимает сотни дней использования графического процессора и делает вывод дорогим из-за последовательной оценки.

Ссылка на документ: https://arxiv.org/pdf/2112.10752.pdf.
Чтобы обеспечить обучение диффузионной модели на ограниченных вычислительных ресурсах, сохраняя при этом ее качество и гибкость, исследователи применили ее к скрытому пространству мощного предварительно обученного автокодировщика.
По сравнению с предыдущей работой, обучение диффузионных моделей на этом представлении может достичь почти оптимальной точки между снижением сложности и сохранением деталей, что значительно улучшает визуальную точность.
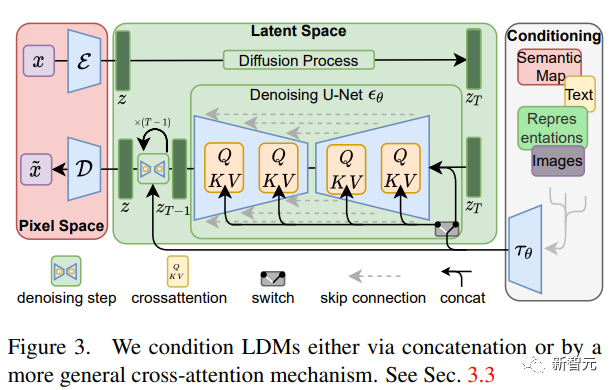
Путем введения слоев перекрестного внимания в структуру модели диффузионные модели можно превратить в мощные и гибкие генераторы для общих условных входных данных (таких как текст или ограничивающие рамки) и обеспечить сверточный синтез с высоким разрешением.

Предлагаемая модель скрытой диффузии (LDM) обеспечивает новый прогресс в рисовании изображений и высокую конкурентоспособность в различных задачах, включая безусловную генерацию изображений, семантический синтез сцен и суперразрешение, конкурируя при этом с моделями скрытой диффузии на основе пикселей. Значительно снижены вычислительные требования по сравнению с моделями скрытой диффузии.
VideoFusion: декомпозированная диффузионная модель для создания высококачественного видео.
Доказано, что диффузионная вероятностная модель (DPM), которая строит процесс прямой диффузии путем постепенного добавления шума к точкам данных и изучает процесс обратного шумоподавления для создания новых выборок, способна обрабатывать сложные распределения данных.
Несмотря на недавние успехи в синтезе изображений, применение DPM для создания видео остается сложной задачей из-за более высокой размерности пространства данных видео.

Предыдущие методы обычно использовали стандартный процесс диффузии, который искажает кадры в одном и том же видеоклипе независимым шумом, игнорируя избыточность контента и временную корреляцию.

Ссылка на документ: https://arxiv.org/pdf/2303.08320v2.pdf.
В этой статье предлагается процесс диффузии разложения путем разложения шума каждого кадра на базовый шум, общий для всех кадров, и остаточный шум, который изменяется по оси времени. Конвейер шумоподавления использует две совместно обученные сети для соответствующего согласования разложения шума.
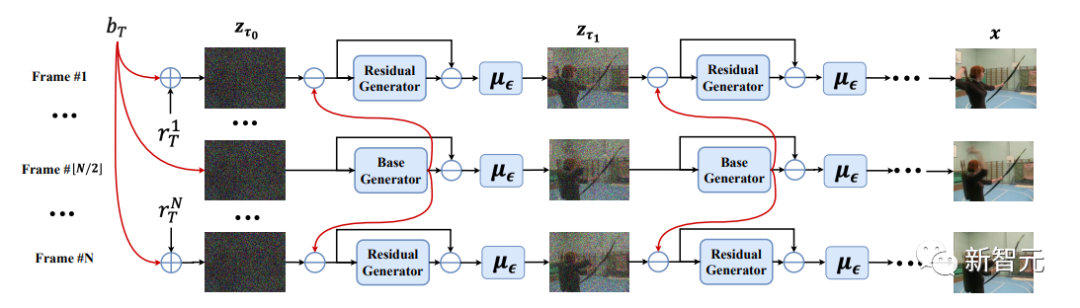
Эксперименты на различных наборах данных подтверждают, что наш метод VideoFusion превосходит альтернативы на основе GAN и диффузии в создании высококачественных видео.
Эксперименты также показывают, что формула разложения может выиграть от предварительно обученных моделей распространения изображений и хорошей поддержки генерации видео с текстом.
Как использовать
В рамках ModelScope текущую модель можно использовать путем вызова простого конвейера, где входные данные должны быть в словарном формате, допустимое значение ключа — «текст», а содержимое — небольшой фрагмент текста.
Эта модель в настоящее время поддерживает вывод только на графическом процессоре, и для нее требуется аппаратная конфигурация примерно из 16 ГБ памяти и 16 ГБ памяти графического процессора.
Введите конкретные примеры кода следующим образом.
Среда выполнения (пакет Python)
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/modelscope && cd modelscope && pip install -e .
pip install open_clip_torchДемо-код
from modelscope.pipelines import pipeline
from modelscope.outputs import OutputKeys
p = pipeline('text-to-video-synthesis', 'damo/text-to-video-synthesis')
test_text = {
'text': 'A panda eating bamboo on a rock.',
}
output_video_path = p(test_text,)[OutputKeys.OUTPUT_VIDEO]
print('output_video_path:', output_video_path)Посмотреть результаты
Приведенный выше код отобразит путь сохранения выходного видео. Текущий формат кодирования можно нормально воспроизводить с помощью проигрывателя VLC.
Ограничения и предвзятости модели
- Модель обучается на основе общедоступных наборов данных, таких как Webvid, и сгенерированные результаты могут отличаться от данных. предвзятость, связанная с распределением обучения.
- Модель не может достичь идеального уровня кино и телевидения.
- Модель не может создать разборчивый текст.
- Модель в основном обучается на корпусе английского языка и не поддерживает другие языки.
- Необходимо улучшить производительность Модели при решении сложных задач комбинаторной генерации.
данные обучения
данные обучениявключать LAION5B、 ImageNet、 Webvid и другие общедоступные наборы данных. Фильтрация изображений и видео выполняется после предварительного обучения, такого как эстетическая оценка, оценка водяных знаков и дедупликация.
Ссылки:
https://modelscope.cn/models/damo/text-to-video-synthesis/summary



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
