MiniMax, одна из пяти лучших отечественных моделей, использует первую в стране архитектуру MOE.
Выяснилось, что Alibaba сделала вторую крупную инвестицию в AIGC в 2024 году, добавив к большой модели трека «единорог» Minimax.,Возглавьте инвестиции как минимум600 миллионов долларов。
Об этом сообщает Bloomberg News.,Новый раунд финансирования может позволитьMiniMax оценивается более чем в 2,5 миллиарда долларов США.В настоящее время АлииSequoia взяла на себя обязательство принять участие в этом раунде финансирования.,С остальными инвесторами пока ведутся переговоры.,Соответствующие условия могут быть скорректированы. Кроме Али,Тенсент, ми Хо Йо、ИДГ Капитал、Hillhouse вложил в них все средства. Текущая оценка составляет 2,5 миллиарда долларов США.
Кто такой Минимакс?
MiniMax Основан в 2021 Год 12 В марте ее основал Ян Цзюньцзе, бывший вице-президент SenseTime Technology. Компания стремится развивать передовые технологии искусственного интеллекта, особенно в области больших языковых моделей (LLM). Его техническое ядро разработано ABAB большая модель, основанная на MoE(Mixture of Experts)Архитектураиз Модель,цельсуществовать通过集成多个专家网络来提高Модельиз Масштабируемостьиэффективность。MoE Архитектура позволяет модели иметь большее количество параметров при решении сложных задач, сохраняя при этом высокую вычислительную эффективность. Мини Макс из ABAB6 Эта модель является первой в Китае, которая приняла MoE Архитектураиз大语言Модель,Он может обучать больше данных в единицу времени,Значительно улучшены производительность и эффективность модели.MiniMax Предоставляет разнообразные продукты и услуги на основе своей большой модели, включая, помимо прочего, MiniMax API открытая платформа, раковина AI Хосино и др. Эти продукты служат различным сценариям, таким как диалог в чате, генерация контента, синтез речи и анализ настроений, отвечая потребностям различных отраслей и приложений. Мини Макс Постоянно способствовать развитию своей крупной модельной технологии, например, ее ABAB6 Существующая модель была значительно улучшена при решении сложных задач, обеспечивая лучшее мультимодальное понимание и многоязычную поддержку.
Minimax использует большую языковую модель Архитектура, которая является первой МО, выпущенной в Китае. Конструкция, полное название «Смесь экспертов», представляет собой ансамблевый метод, в котором вся проблема делится на несколько подзадач, и для каждой подзадачи обучается группа экспертов. МО Модель будет охватывать разных учащихся (экспертов) и разные входные данные. 2024 год Год 4 луна 17 день、Мини Макс Официально запущен абаб 6.5 Серийные модели. Абаб 6.5 В серию входят две модели: abab 6.5 и abab 6.5s。abab 6.5 Содержит триллионы параметров и поддерживает 200k tokens длина контекста abab; 6.5s и abab 6.5 Использует те же технологии обучения и данные, но более эффективен и поддерживает 200k tokens из-за длины контекста, может 1 Обрабатывается в течение нескольких секунд 3 万字изтекст。существовать Все видытест на базовую компетентностьсередина,abab 6,5 начинает приближаться GPT-4、 Claude-3、 Gemini-1.5 Ожидание самой совершенной в мире модели большого языка.
тест на базовую компетентность
Для тестирования двух моделей мы используем отраслевой стандарт из набора тестов с открытым исходным кодом.,существовать Знание、рассуждение、математика、программирование、Ведущие в отрасли языковые модели сравнивались с точки зрения соответствия инструкциям и других параметров.
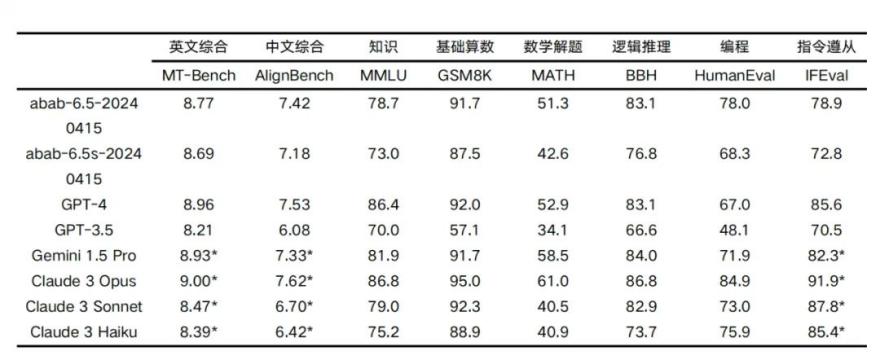
abab 6.5 ответил правильно в 891 тесте.
МО архитектуры Из-за огромных накладных расходов, вызванных обучением и развертыванием больших моделей, исследователи решили изучить возможность использования смешанных экспертов (MoE) для повышения эффективности больших моделей. Особенно это заметно на крупных моделях, где МО оптимизирует вычислительные ресурсы и повышает производительность за счет выборочной активации различных сетевых компонентов. Новаторскую работу в этой области можно увидеть в модели GShard [42], которая ввела использование MoE для крупномасштабных многоязычных языковых моделей и продемонстрировала значительные улучшения в задачах перевода. Выключатель Трансформаторы [22] еще больше усовершенствовали эту концепцию. Расширив метод MoE, существующие достигли беспрецедентного размера модели и эффективности обучения с точки зрения визуального понимания. Кроме того, БАЗА Слои [43] исследовали интеграцию MoE в представления двунаправленных кодеров от преобразователей, еще раз подчеркнув потенциал MoE для улучшения задач понимания языка. Также изучалось применение MoE в модели генерации, среди которых GLaM [44] является важным примером, демонстрирующим способность MoE решать разнообразные и сложные задачи генерации. существуют В этой статье мы в основном изучаем использование МО. Стройте унифицированные конструкции из крупномасштабных мультимодальных моделей. Размер и производительность модели можно увеличить без увеличения вычислительных требований.
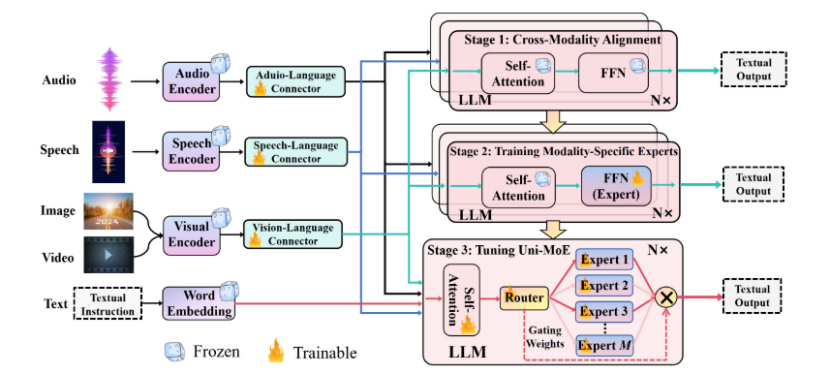
картина 2 Показывает дизайн из Uni-MoE Демонстрируя свой комплексный дизайн, компания продемонстрировала свой комплексный дизайн, включая кодеры для звука, речи и изображения, а также соответствующие им модальные разъемы. Функция этих соединителей — преобразовать различные модальные входные данные в единое языковое пространство. Тогда мы существуем ядро LLM встроен в блок MoE Архитектура, которая имеет решающее значение для повышения эффективности процесса обучения и вывода, поскольку активируется только часть параметров. Это достигается за счет реализации механизма разреженной маршрутизации, такого как картина 2 Показано внизу. Университет-МО Весь процесс обучения разделен на три различных этапа: кросс-модальное согласование, обучение специалистов по конкретным методам, использование разнообразных мультимодальных инструкций, корректировка набора данных. Университет МО. существуют В следующем разделе мы подробно обсудим Uni-MoE из Комплексной Архитектуры прогрессивный метод обучения.
Чтобы в полной мере раскрыть уникальные способности разных экспертов,Повысьте эффективность сотрудничества нескольких экспертов,И повысить способность обобщения всей структуры,Мы внедрили прогрессивную стратегию обучения для постепенного развития Uni-MoEiz. Алгоритм 1 определяет цель достижения интегрированного трехэтапного протокола обучения на основе MoEизMLLMАрхитектураиз. существуют, за которым следует заявление,Мы подробно объясним конкретное содержание каждого этапа обучения и цели.
Процесс обучения Uni-MoE
Этап 1: Кросс-модальное согласование. существуютначальный этап,Наша цель — установить связи между различными модальностями и языками. Мы достигаем этого, создавая соединители,Эти соединители преобразуют различные модальные данные в программную разметку в языковом пространстве. Основная цель здесь — минимизировать потери энтропии генерации. Как показано в верхней части картины2из.,LLM оптимизирован для создания кросс-модальных входных данных из описаний.,Обучение проходят только коннекторы. Этот подход обеспечивает плавную интеграцию всех модальностей, существующих в единой языковой структуре.,Содействие взаимопониманию в рамках LLM.
Второй этап: подготовка специалистов по конкретным направлениям. На этом этапе основное внимание уделяется подготовке экспертов по одному виду транспорта посредством специализированного обучения по конкретным кросс-модальным данным. Цель – повысить уровень квалификации каждого специалиста в своей области.,Тем самым улучшая общую производительность системы МО по разнообразным мультимодальным данным. сохраняя при этом потерю генеративной энтропии в качестве основной метрики обучения,Мы адаптируем FFN для более точного соответствия целевым модальным характеристикам.
Этап 3: Корректировка Uni-MoE. Заключительный этап включает в себя интеграцию экспертных весов, скорректированных на втором этапе, в уровень MoE. Затем,Мы продолжаем совместно дорабатывать MLLM, используя смешанные мультимодальные данные инструкций. Ход обучения и прогресс,Как показано на кривой потерь,Отражено в существованиикартина3. Сравнение конфигураций МЧС по результатам анализа показывает,существуют Второй этап усовершенствованные эксперты достигают более быстрой конвергенции,И существование демонстрирует более высокую стабильность на смешанно-модальных наборах данных. также,существуют, включающие сложные смешанные модальные данные из сцен,Включая видео, аудио, изображения и текст,Использование модели с четырьмя экспертами показало меньшую вариативность потерь и более стабильные результаты обучения, чем модель с двумя экспертами. По сравнению с использованием вспомогательных балансировочных потерь,Uni-MoE демонстрирует лучшую конвергенцию,Последнее приводит к колебаниям общих потерь при обучении.,Он не демонстрирует очевидной конвергенции.
Этот тренинг расширяет возможности крупных мультимодальных моделей за счет интеграции гибридных экспертов [MoE] Архитектура,Благодаря новому трехэтапному методу обучения,Специально используется для повышения стабильности и обобщения результатов мультимодального обучения.,Лучше, чем традиционная конструкция МО той же конфигурации.
Вычисления в памяти:
Модель MoE является одной из передовых областей исследований в области глубокого обучения и искусственного интеллекта.,Помимо разработки мультимодальных больших моделей, модель постоянно оптимизируется для улучшения возможностей и эффективности обработки модели.,Оптимизация вычислительной мощности имеет решающее значение для развития глубокого обучения и искусственного интеллекта.,Вычисления в памяти Архитектура действительно обеспечивает интеграцию хранения и вычислений.,По сравнению с традиционной архитектурой фон Неймана, расчет режима осуществляется внутри блока хранения.,Уменьшение передачи данных туда и обратно,Вычислительная мощность увеличена в 20 раз,Особенно подходит для крупномасштабных параллельных вычислений, таких как глубокое обучение.
Zhicun Technology опирается на свою передовую техническую мощь, чтобы занять лидирующие позиции в массовом производстве коммерческой продукции.,Станьте мировым лидером в области вычислений в памяти. Zhicun Technology основана в 2017 году. разработал первую в мире многослойную нейронную систему сеть In-memory вычислительный чип доктора Го Синьцзе является главным научным сотрудником. 2022Год,Чип Zhicun Technology WTM2101 официально выпущен на рынок,Предоставьте миллионам терминалов возможности для улучшения возможностей искусственного интеллекта и продвижения приложений.,Становится первым в мире крупномасштабным коммерческим чипом для вычислений в памяти, выпускаемым серийно.
эпоха искусственного интеллекта,Вычисления в памяти превосходят Мура,Это станет новым типом вычислительной мощности в эпоху искусственного интеллекта.
Подведите итог:
Отечественные крупные модели идут рука об руку и сейчас,существованиеединица времени,Улучшение возможностей и эффективности обработки моделей,Одновременно сократить затраты на вычислительную мощность,Это может стать ядром крупномасштабного конкурса моделей.,Поэтому более высокие требования выдвигаются к оптимизации модели Архитектуры и обновлению вычислительных мощностей Архитектуры.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
