Микросервисы возвращаются в единое целое, сокращая количество строк кода на 75 % и повышая производительность на 1300 %.

# Следите за разработчиками Tencent Cloud и отмечайте их
# Еженедельник 3 | Расскажите о моем опыте архитектурного проектирования в Tencent
# Выпуск 5 | Ли Хаоджин: 13-кратная реконструкция производительности: архитектура поиска по контенту Преобразование группы микросервисов C++


Архитектура контента — это поиск в браузере QQ на уровне доступа к контенту и вычислительном уровне.,В основном отвечает за доступ к контенту и его обработку в домене Tencent.,В настоящее время подключен к нескольким партнерамиз Тысячи категорий контента。как и раньше«Как избежать того, чтобы старый код стал багажом?» 5 шагов, которые научат вас, как захватить чужую систему》упомянуто в,Это набор, содержащий 93 Микросервисная архитектура с небольшими сервисами. пройти 23 Год Q1 Энергичное управление позволило нам стабилизировать нашу позицию и провести дальнейшую углубленную оценку старой системы:
▶︎ Низкая эффективность НИОКР: добавление нового типа данных требует разработки на 3-4 сервисах. Объем кода небольшой, но очень громоздкий.
▶︎ Низкая производительность системы: данные проходят через множество небольших сервисов, а реализация внутри этих сервисов, как правило, плохая. Например: процессор основного сервиса может быть использован только до 40%, сообщение должно пройти более 20 повторных анализов JSON от входа до выхода, во многих местах существуют избыточные копии строк и поиск...
На уровне архитектуры и кода мы видим, что в системе много дефектов. В то же время мы также получили много жалоб от однокурсников по бизнесу и руководителей высшего звена по поводу пропускной способности. Например: передача занимает 12 дней. 600 миллионов документов, что слишком медленно. Цикл доступа к контенту слишком длинный, что стало узким местом для определенного проекта и т. д.
В качестве системы внутренней инфраструктуры надежность и эффективность являются основными требованиями. Мы решили полностью преобразовать систему, разработать простую систему, написать понятный код, повысить производительность системы и эффективность исследований и разработок, а также предоставить стабильные и эффективные услуги для поискового бизнеса.

Архитектура контента в основном отвечает за доступ к контенту и его расчеты и поддерживает многие типы контента. Из-за чрезмерного количества микросервисов в старой системе и отсутствия конструкции повторного использования плагинов потребность в рабочей силе высока, а также возникают дефекты производительности. , недостаточное аварийное восстановление и т. д. Серьезные архитектурные недостатки. Новая система перепланирована и спроектирована на основе «мышления с нуля» с упором на следующие пять пунктов на архитектурном уровне:
▶︎ Микросервисы и монолитные сервисы: старая система состоит из множества небольших и фрагментированных сервисов, и взаимодействие RPC требует много денег. Учитывая бизнес-сценарий «большой объем обработки, небольшой объем вычислений и низкая отказоустойчивость», новая система. использует монолитные сервисы, предназначенные для передачи данных между памятью для снижения потребления.
▶︎ Система подключаемых модулей: ввиду сложных и разнообразных процессов обработки в старой системе не было подключаемого модуля, а весь код представлял собой логику «если-иначе» в новой системе, мы используем подключаемый дизайн; гибко поддерживать потребности бизнеса.
▶︎ Принимая во внимание как инкрементальную, так и пакетную обработку (чистку базы данных): старая система очень слаба в работе с процессом пакетной обработки данных (чистка базы данных) и не разделяет процесс, что приводит к низкой производительности очистки базы данных; индивидуальные конфигурации для сценариев очистки базы данных. Значительно улучшают производительность очистки библиотеки.
▶︎ Устранение сбоев: старая архитектура почти не учитывала защиту данных во время миграции контейнера. Новая архитектура сочетает в себе промежуточное программное обеспечение для сообщений для снижения пикового трафика и кэширования сообщений, чтобы данные не были потеряны в случае сбоя.
▶︎ Горизонтальное расширение: в старой системе нет разделения между потреблением и вычислениями, поэтому ЦП можно использовать только до 40%, и его нельзя расширять по горизонтали. Новая система отделяет потоки потребления от потоков обработки, что значительно улучшает одновременную работу; производительность машинной обработки, а также может расширяться по горизонтали.
Старый дизайн системы:
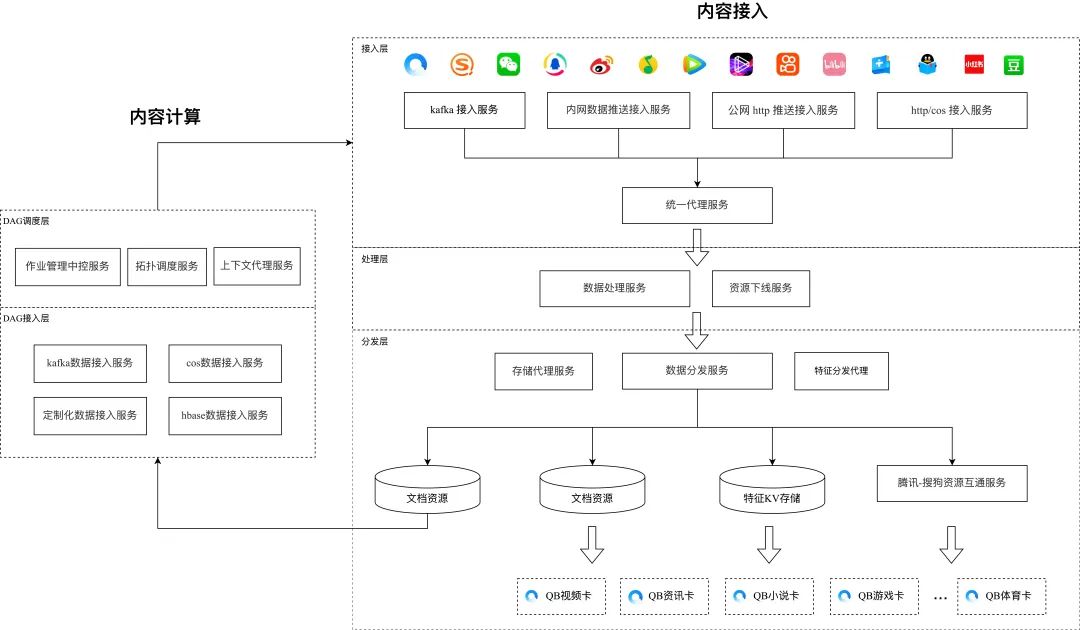
Новый дизайн системы:
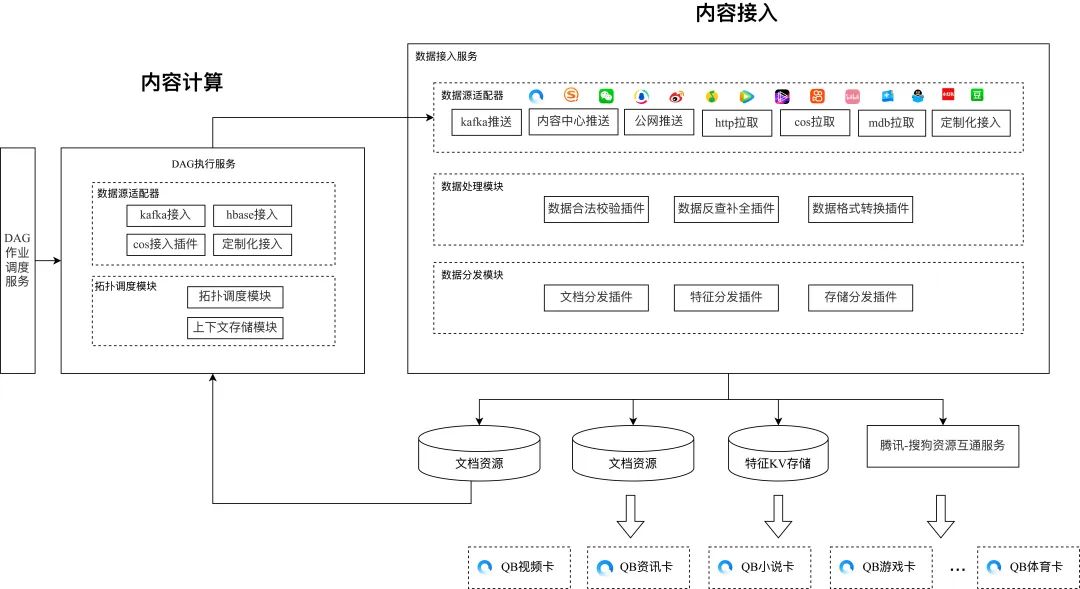

От микросервисов к монолитным сервисам
Более десяти лет приходят микросервисы в фоновом режиме. Система популярна,Мы взяли на себя разработку изсистемы и микросервисов.,Так продолжим микросервисы?
Для начала давайте посмотрим на особенности нашего бизнеса:
▶︎ Большой объем обработки: каждый день добавляются миллиарды/обновлений контента.
▶︎ Небольшой объем вычислений: архитектура контента в основном занимается планированием доступа и вычислений, а объем вычислений в основном приходится на нижестоящую операторскую службу или на заводе.
▶︎ Низкая отказоустойчивость: если контент утерян, его невозможно найти, а потерю контента нельзя допустить.
▶︎Несколько категорий контента: существуют тысячи категорий, и их число продолжает расти.
▶︎ Спрос невелик, категория одна: все запросы касаются доступа к новому источнику контента, а тип спроса относительно фиксирован.
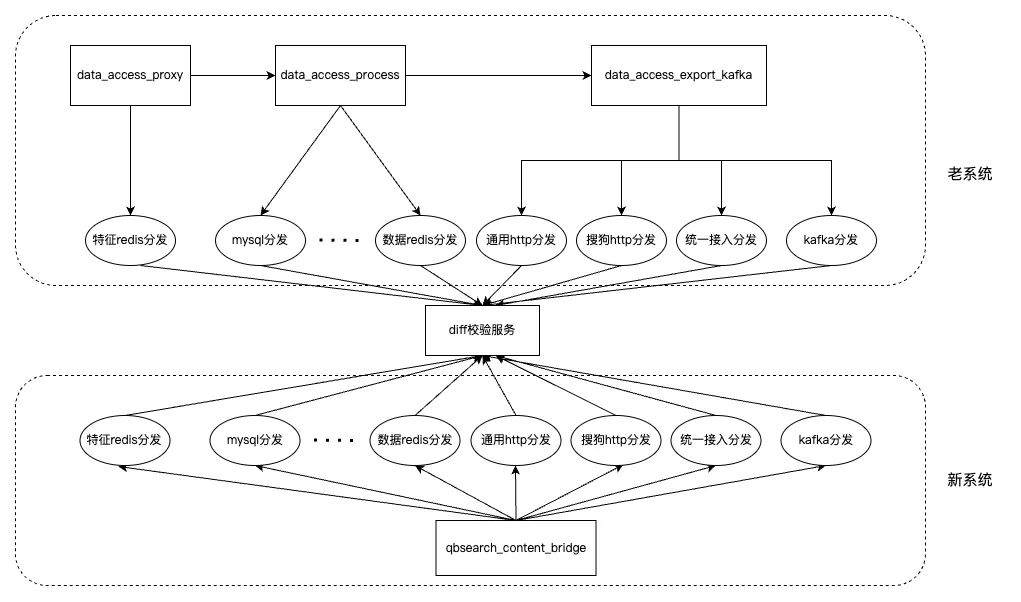
Давайте посмотрим на конструкцию старой системы. На примере системы доступа реализация четырех типов доступа: передача в интранет, передача в общедоступную сеть и запрос HTTP/Kafka — разбросана по четырем службам, а затем через единую систему. прокси-служба доступа, служба обработки данных и обработка службы распространения требуют 6 взаимодействий RPC для одной части данных контента. Что поднимает эти проблемы на практике:
▶︎ Необходима более сложная обработка отказоустойчивости: во-первых, группа микросервисов должна рассмотреть разумное распределение таймаутов, затем каждая микрослужба должна рассмотреть обработку отказоустойчивости, такую как неудачная повторная попытка и лавинная повторная попытка. Сложность увеличивается экспоненциально с увеличением количества операций. микросервисы. Обработка миллиардов документов в сочетании с множеством микросервисов может привести к массовой бомбардировке оповещений и даже к потере данных, если вы не будете осторожны.
▶︎ Медленная итерация требований: требование обычно выполняется одним человеком и требует модификации нескольких микросервисов. Общий объем кода невелик, но он разбросан по нескольким сервисам.
▶︎ Вычислительные потери: данные контента передаются в несколько сервисов, и их необходимо многократно сериализовать и десериализовать. Ценная обработка самого сервиса — это в основном легкие вычисления, такие как преобразование полей и простая обработка строк. Потребление выше, чем. расчет работы.
Наконец, наша новая архитектура использует единый сервисный дизайн и достигла хороших результатов с точки зрения отказоустойчивости, эффективности итераций и объема вычислений (см. показатели данных в конце статьи).
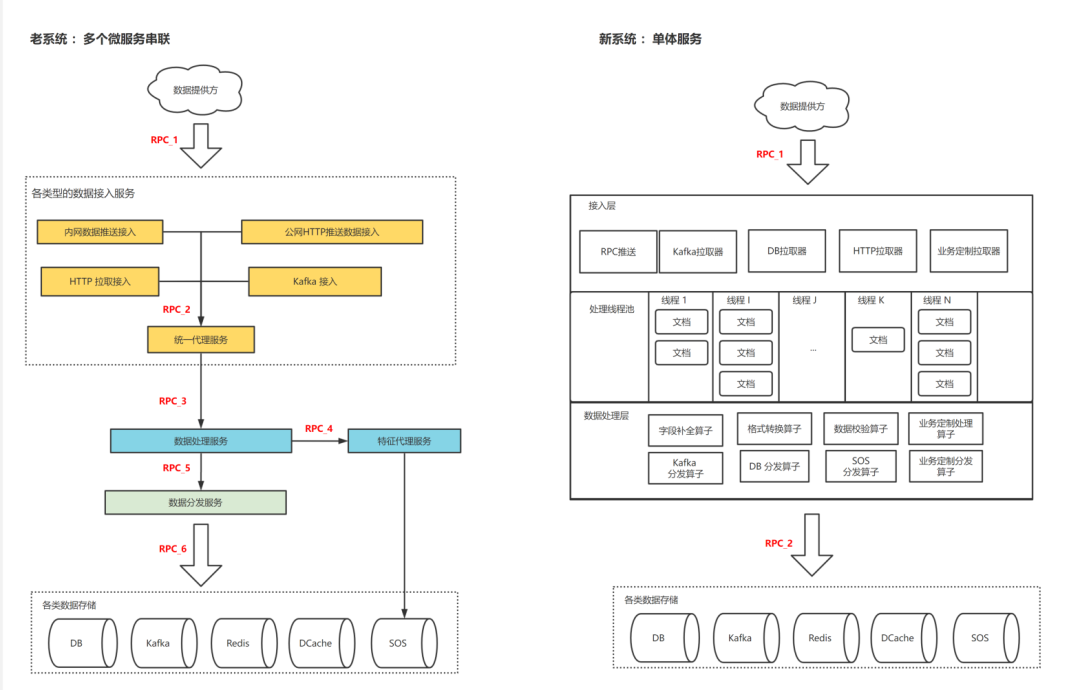
(Сравнительная таблица старой и новой архитектуры системы доступа к контенту)
Процесс обработки доступа к плагину
Система доступа к контенту должна обрабатывать тысячи типов контента. Разный контент обычно исходит от разных команд. У каждой команды есть набор стандартных протоколов вывода контента. Поэтому системе доступа к контенту необходимо писать большой объем кода стыковки и адаптации. Как облегчить доступ к новому контенту?
Как показано на схеме, наши бизнес-функции разделены на три уровня: уровень доступа, уровень обработки и уровень распределения.
На уровне доступа нам необходимо обрабатывать несколько форматов данных, доступ к которым осуществляется через несколько каналов. Эти методы включают в себя: запланированное получение БД, потоковую передачу Kafka, получение HTTP/COS, получение RPC и т. д. Форматы данных также разнообразны, и форматы данных, предоставляемые каждой стороной данных, различны. Если взять в качестве примера доступ Kafka по запросу, новый бизнес передает данные в формате JSON, а бизнес мини-программ передает сериализованный поток двоичных байтов PB.
На уровне обработки нам необходимо выполнить различные проверки формата для разных предприятий; после получения данных некоторым компаниям необходимо запросить другие услуги для заполнения определенных атрибутов; некоторые компании требуют от нас выполнения некоторых преобразований формата полей. Некоторые компании требуют, чтобы мы вносили индивидуальные изменения; значениям в данных.
На уровне распределения пункт назначения для каждого распределяемого бизнеса также различен: некоторые бизнесы нужно отправить только в Kafka, некоторые бизнесы нужно сохранить в БД, Redis, DCache и т. д., а некоторым бизнесу нужно отправить HTTP. /RPC запросы к определенным служебным уведомлениям обновляются. Среди них также различаются тема Kafka, таблица хранения БД, целевой адрес службы и протокол.
Столкнувшись с такими сложными бизнес-функциями, старая система построила набор процессов обработки данных, а затем использовала суждение if-else для выполнения различных процессов обработки в основном процессе. Можно ясно увидеть следы «кучи кода» и его источник. Организация кода. Ясность и возможность подключения функций плохие.
В новой системе доступа мы реализуем каждую ключевую функцию доступа, обработки и распространения в виде подключаемой архитектуры. Каждая подфункция является подключаемым модулем. При этом подключаемые модули используются в комбинации. конфигурация потока обработки бизнес-детализации.
Пример: процесс выполнения задачи пакетного доступа
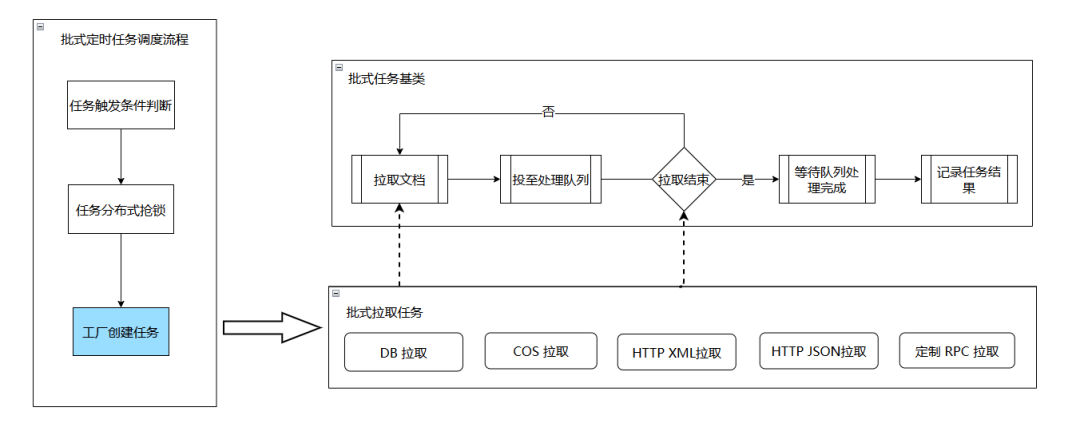
Пример: процесс обработки документа

При возникновении новых индивидуальных бизнес-требований нам нужно только добавить плагины в соответствующие ссылки. При разработке плагинов нам нужно реализовать только ключевые функции. Например, плагин задачи извлечения должен реализовать только два интерфейса. pull и завершилась ли задача извлечения. Плагину распространения необходимо только реализовать логику распространения; остальное реализуется на уровне платформы и планируется единообразно, и разработчикам не нужно это понимать. Если новый бизнес использует только существующие функции, нам нужно только настроить последовательность комбинаций плагинов в БД, без разработки кода.
Благодаря такой конструкции подключаемого модуля бизнес-доступ упрощается, а время выполнения бизнес-требований значительно сокращается (см. индикаторы данных в конце статьи). Кроме того, в старой системе в каждом сервисном коде имеется различное жесткое кодирование. Если бизнес-идентификатор == указанный идентификатор, указанная логика будет выполняться или не выполняться. При устранении бизнес-проблем вам необходимо просмотреть код нескольких сервисов. что крайне неэффективно. Новая система позволяет четко понимать весь процесс обработки доступа к бизнесу, просто взглянув на конфигурацию, что значительно повышает эффективность эксплуатации и устранения неполадок при обслуживании.
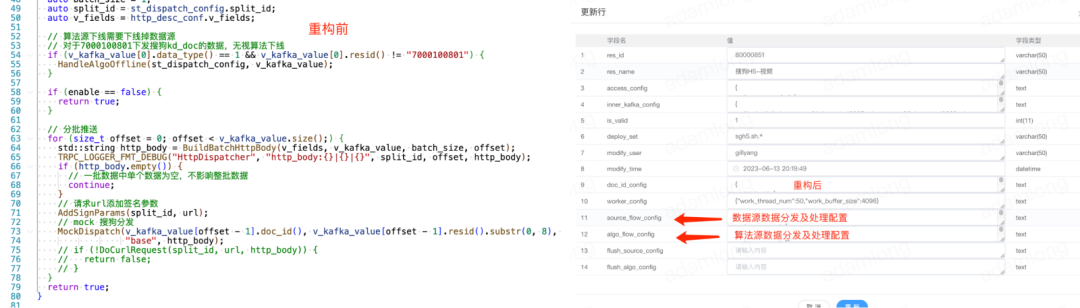
Принимая во внимание как инкрементные обновления, так и пакетную очистку базы данных.
Система доступа часто получает запросы на «чистку базы данных»: все данные определенного бизнеса должны быть обработаны, а затем отправлены в указанный нижестоящий канал. Поскольку старая система не имела подключаемого модуля и ей не хватало гибкости в сочетании и использовании компонентов, требования к очистке библиотеки приходилось выполнять посредством процесса инкрементного обновления, что приводило к множеству неверных вычислений.
Новая система учитывает как инкрементальные, так и пакетные обновления базы данных. В зависимости от входных характеристик системы доступа мы разделили конфигурацию потока данных на четыре типа: поток обработки обновления источника данных, поток обработки обновления объекта, поток обработки очистки базы данных источника данных и поток обработки очистки базы данных объектов.
В потоке обработки обновления источника данных/функций нам необходимо настроить различных операторов и операторов распределения для обработки данных бизнес-линии. В потоке обработки кисти базы данных данные поступают из нашей нижней таблицы HBase, которая фактически не изменилась и не требует пересчета. Более того, в обычных сценариях очистки базы данных бизнес-данные необходимо распределить по нескольким нисходящим потокам, когда они обычно обновляются. Когда база данных очищается, необходимо обновить только некоторые нисходящие потоки. На данный момент нам нужно только настроить оператора распределения. пункта назначения.
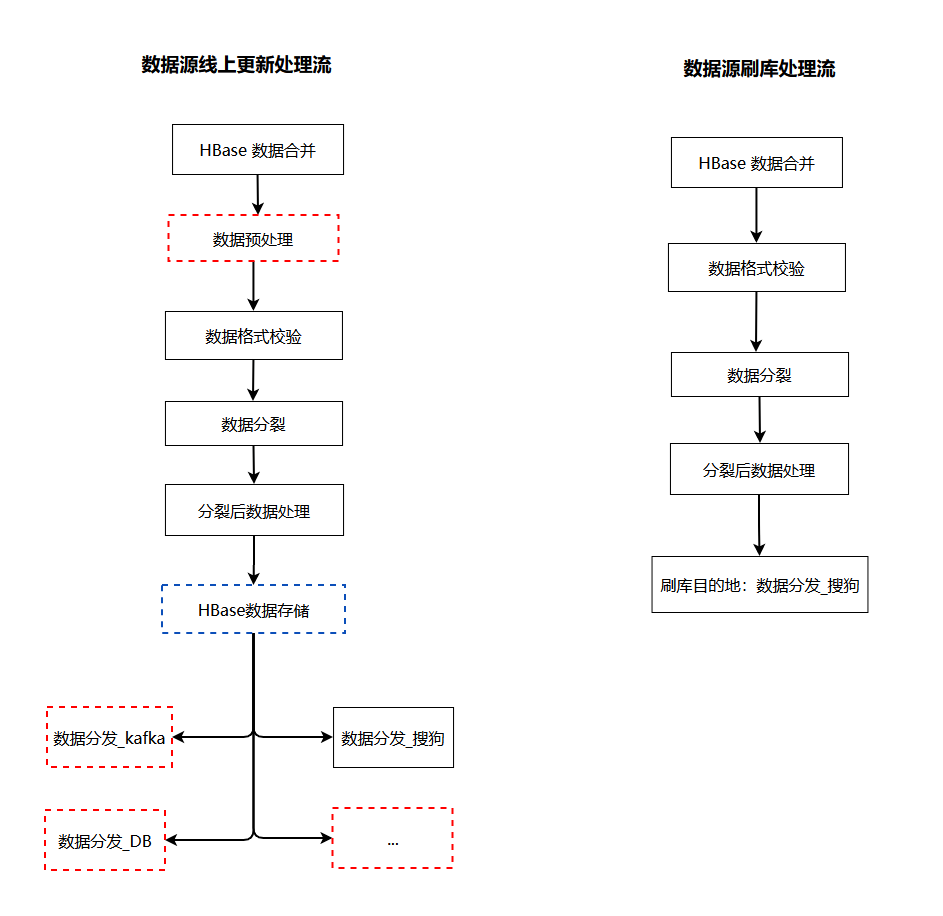
Различая конфигурации обработки данных для четырех типов сценариев обработки, новая система доступа может выполнять разные потоки обработки данных во время обычной обработки и очистки базы данных одного и того же бизнеса, тем самым удаляя ненужную логику вычислений и распределения в сценарии очистки базы данных. QPS основной библиотеки увеличился в 16 раз.
Устранение неисправности службы доступа к данным
Отсутствие потери данных является основным показателем архитектуры контента. Независимо от того, откуда берутся данные, при их попадании в нашу систему должна быть гарантирована их непотеря.
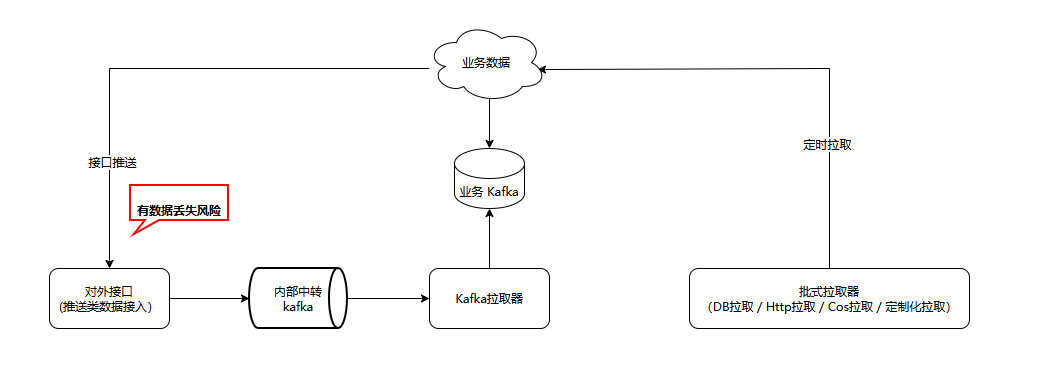
Различные методы доступа к системе можно разделить на три категории: передача через интерфейс, канал Kafka и получение пакета запланированных задач. Среди этих трех типов методов доступа класс канала Kafka имеет собственное резервное копирование данных. Не выполняйте Offset Commit, когда данные не обрабатываются, чтобы гарантировать, что задачи пакетного запланированного класса извлечения не будут потеряны. Если процесс завершается во время выполнения задачи извлечения, задачу можно восстановить, перезапустив новый узел, и данные не будут потеряны, только данные, отправленные интерфейсом, не могут быть обработаны при выходе из процесса, что приведет к получению данных; потеря.
Старая система не обеспечивает никакой защиты для данных, передаваемых через интерфейс, а это означает, что сценарии сбоя службы доступа, такие как ненормальное завершение процесса и миграция сбоя контейнера, не обрабатываются эффективно, и данные могут быть потеряны.
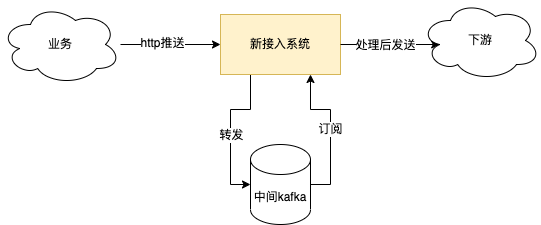
Мы добавили промежуточное ПО для обмена сообщениями Kafka в новую архитектуру для обеспечения аварийного восстановления данных. Обновленные данные, передаваемые через интерфейс HTTP/trpc, уровень интерфейса напрямую отправляет их в Kafka и возвращает их в бизнес-успех. Тем временем Kafka выполняет асинхронную обработку потребления по указанному разделу (набору), и Offset Commit не будет выполняться до тех пор, пока обработка сообщения не будет завершена. Если некоторые процессы узла выходят из строя или завершают работу во время процесса потребления, другие работоспособные узлы возьмут на себя потребление и обработку сообщений документов в соответствующих разделах, чтобы гарантировать, что данные не будут потеряны в максимальной степени. В то же время промежуточное программное обеспечение сообщений. также приносит эффект пикового бритья.
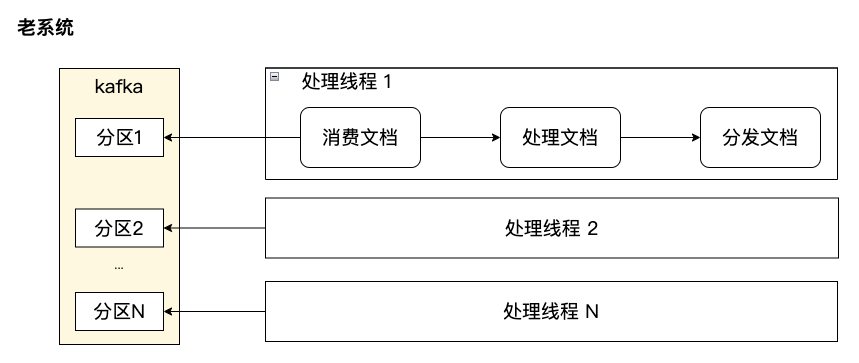
Разделение потоков потребления и обработки
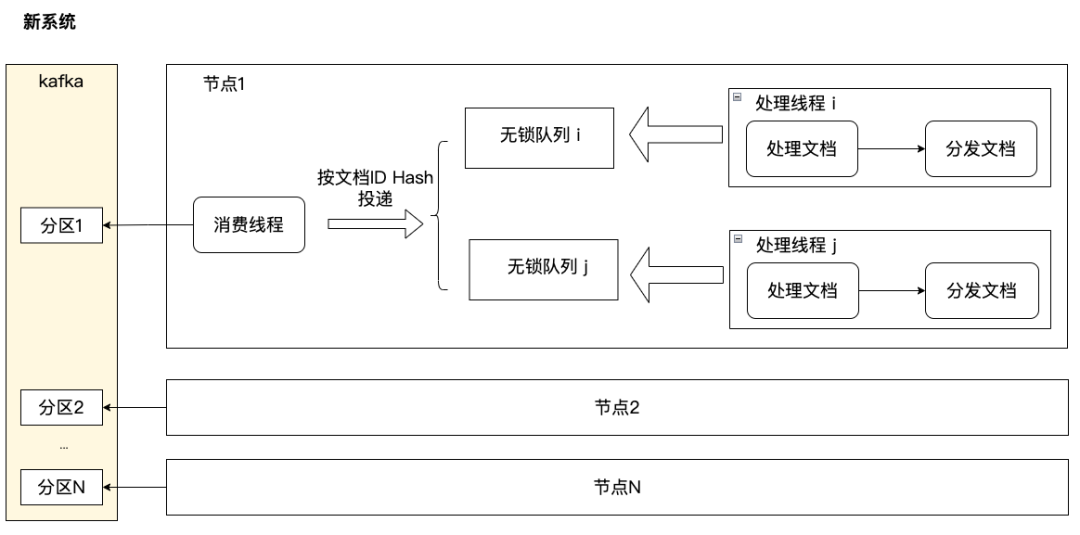
Важной причиной низкой производительности обработки старой системы доступа является то, что потоки потребления Kafka и обработки документов не разделены. Если в бизнесе настроено N потоков для обработки, эти потоки сначала будут извлекать документы из Kafka, а затем выполнять обработку в каждой ссылке в соответствии с конфигурацией. После обработки пакета сообщений они перейдут в Kafka для получения. поток также является потоком обработки, и пересчитанный бизнес не может полностью использовать процессор. В то же время раздел Kafka может использоваться максимум одним потоком. Максимальное количество одновременных обработок в кластере ограничено общим количеством разделов Kafka, что делает невозможным горизонтальное расширение.
Новая система создает пул рабочих потоков обработки документов на основе очереди без блокировок. Каждый раздел Kafka может использоваться одним потоком и обрабатываться несколькими вычислительными потоками. Разделение потоков потребления и вычислений обеспечивает полную загрузку ЦП, а загрузку ЦП и производительность обработки значительно улучшается. При этом количество вычислительных потоков больше не ограничивается общим количеством разделов Kafka и может расширяться по горизонтали.

Вся система имеет 15 распределительных пунктов, которые разбросаны по нескольким службам старой системы. Если вы сравните различия на основе локального журнала машины, то вы увидите, что они фрагментированы и трудоемки. Поэтому мы создали службу проверки различий. В то же время мы закапываем точки в точках распространения нескольких служб и сообщаем о содержимом распространения в службу проверки различий, чтобы можно было единообразно собирать и анализировать разбросанные журналы различий. Весь поток данных выглядит так:
В ходе сравнения различий мы обнаружили, что формат данных распределения сложен и существует множество типов. Например, значение элемента Json данных распределения представляет собой строку JSON, а порядок элементов строки JSON не фиксирован. Чтобы решить эту проблему, мы внедрили инструмент рекурсивного сравнения JSON для проверки различий между несколькими типами данных.

меньше кода
Табличное программирование. Как показано на рисунке ниже, после реконструкции обход данных используется для замены длительных суждений if.

Для динамической загрузки данных используйте C++20 изstd::atomic<std::shared_ptr<T>>Заменить исходный дубль buffer Дизайн, как показано ниже.
более высокая производительность
Используйте итераторы вместо значений поиска и скобок. И поиск RapidJSON, и значение квадратной скобки требуют обхода списка элементов. Для сценария, в котором сначала ищется значение квадратной скобки, а затем получается значение квадратной скобки, вы можете сначала сохранить итератор, полученный в результате поиска элемента, а затем получить элемент. значение через итератор, сокращая обход списка членов.
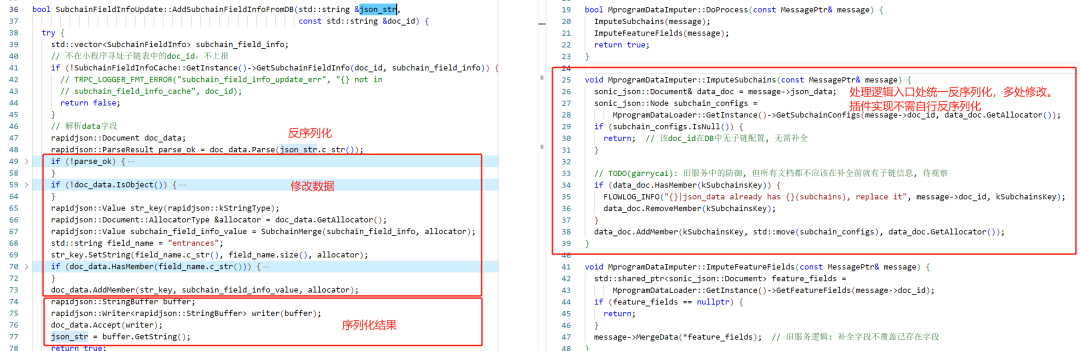
Уменьшите десериализацию JSON. Параметром функции старого кода является строка после сериализации JSON. Объект JSON необходимо повторно десериализовать и сериализовать, что приводит к потере производительности. После реконструкции мы определили данные JSON, которые требовали нескольких раундов обработки, как объекты Rapidjson::Document и поместили их в контекст, исключив повторную сериализацию и десериализацию. Это не только повышает производительность обработки данных, но и уменьшает повторяющийся анализ фрагментов кода JSON.
Лучшие базовые библиотеки
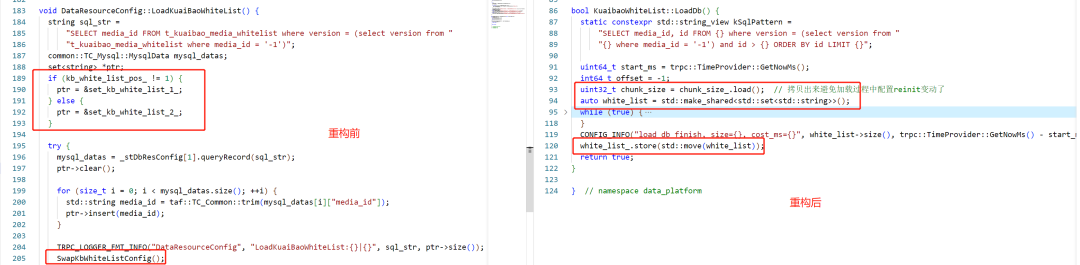
Исправьте артефакт утечки памяти, вызванный Rapidjson::Document, и уменьшите использование памяти. Чтобы уменьшить повторный анализ, после того, как модуль извлечения БД извлекает строку, мы анализируем ее в Rapidjson::Document, а затем сохраняем.
Однако, проведя описанную выше оптимизацию, мы обнаружили, что память контейнера будет значительно увеличиваться с каждым раундом загрузки БД. После 5-6 раундов загрузки память процесса заполняется и происходит ООМ. После анализа инструмента Valgrind и различных локальных тестов мы определили, что фактическая утечка памяти не произошла, а причина постоянного увеличения памяти заключается в том, что RapidJSON используется для создания объекта Document на основе распределителя MemoryPoolAllocator пула памяти после того, как объект будет создан. освобождена, свободная память не будет немедленно возвращена в операционную систему.
После системного анализа мы обнаружили, что это не имеет ничего общего с RapidJSON, а является разработкой политики памяти операционной системы. Для такого рода проблемы несвоевременного освобождения памяти мы исследовали и нашли два решения:
▶︎ Используйте mallocopt(M_TRIM_THRESHOLD), чтобы снизить порог освобождения памяти при запуске службы, а после освобождения объекта вызовите malloc_trim(0), чтобы заставить его освободить память;
▶︎ Путем введения распределителей памяти, таких как jemalloc. Этот проект решается путем подключения библиотеки jemalloc.
Кроме того, мы представляем библиотеку Sonic-JSON с открытым исходным кодом. Основываясь на оценке наших данных контента, Sonic-JSON на 40 % быстрее, чем RapidJSON, поэтому мы внедрили Sonic-JSON вместо RapidJSON. В стресс-тесте новой системы доступа было показано, что Sonic-JSON может увеличить пропускную способность. на 15 % или снизить пропускную способность на 17 % нагрузки на ЦП.
лучшая читаемость
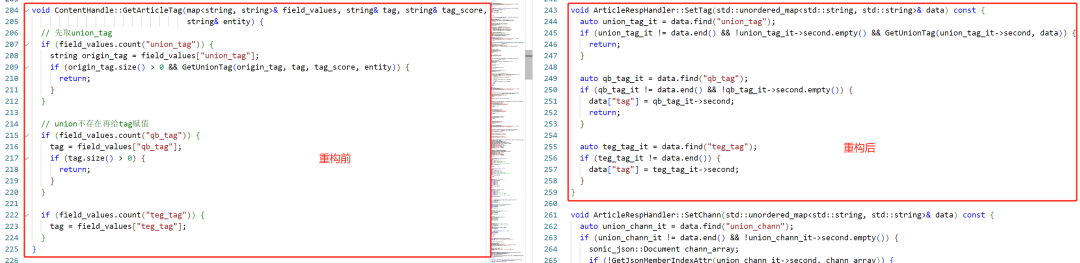
Функции следуют принципу единой ответственности.Как показано ниже,Для разных типов подписки,В старом кодексе обязанности не ясны.,передать функцию if Решение используется для того, чтобы разные типы подписок использовали разную специальную логику обработки. После рефакторинга мы используем полиморфный дизайн. Производные классы разных типов подписки наследуют базовый класс и обобщают свою собственную специальную логику, так что каждый класс обрабатывает только один тип подписки.

Переоборудование распределительного шкафа Воля для завода.Как показано ниже,Примените дизайн подключаемого модуля и метод справочной таблицы.,Улучшите сопровождаемость и масштабируемость кода.

Плагин и настройка.Функциональные компоненты можно свободно комбинировать.,во избежание частых случаев trick код. Как показано на рисунке ниже, в старом коде указанная обработка указанных типов ресурсов реализуется посредством жесткого кодирования. После реконструкции различные ресурсы могут быть настроены с использованием различных процессов обработки для обеспечения «горячей» замены функций и повторного использования компонентов.

общий процесс
В процессе исследований и разработок мы продолжаем использовать опыт построения CICD, накопленный при разработке продуктов поисковых технологий, включая следующие меры:
▶︎ Подтверждение и активация требования, согласование обязательных полей TAPD и процесса отмены TAPD.
▶︎ Квалификация разработчика Только после получения сертификата квалификации разработчика вы можете выводить код производственной линии.
▶︎ Стандарты кодирования и аннотаций, унифицированное использование стандартов кодирования Tencent и аннотаций doxygen.
▶︎ Проверка кода, разработка пошагового процесса и предоставление обучающих примеров.
▶︎Базовые правила библиотек унифицируют спецификации использования сторонних библиотек и библиотек инструментов, чтобы исключить путаницу в зависимостях проекта.
▶︎ Конвейер, унифицированный шаблон MR, строгие ограничения на красные линии статического контроля качества кода, красные линии одиночного тестового покрытия и т. д.
▶︎ Спецификации версий, унифицированное наименование версий и спецификации использования: MAJOR.MINOR.PATCH.
▶︎ Процесс выпуска: домен Tencent принимает выпуск XAC.
Управление спросом
При планировании требований мы делим большие требования (EPIC) по крупным модулям (или функциям) и распределяем большие требования по разным разработчикам. После того, как разработчики разбираются с детальной реализацией модуля, они разделяют между собой различные мелкие требования (функции) и корректируют соответствующее время разработки. Использование диаграмм Ганта в процессе разработки может облегчить определение хода разработки проекта.
Когда несколько человек сотрудничают, неизбежно, что рабочая нагрузка будет распределяться неравномерно или период проекта придется продлить, поэтому каждую среду утром мы проводим десятиминутное утреннее совещание: чтобы определить ход выполнения требований и скорректировать численность разработчиков в своевременно учитывать возможные риски для обеспечения достижения командных целей.
проверка кода
Качество кода имеет решающее значение для долгосрочного развития проекта. Наша команда требует, чтобы каждый разработчик сдал экзамен по безопасности кода и экзамен по спецификации. Каждая строка кода на производственной линии должна пройти проверку. CR также призывает всех сотрудников совершенствовать свой вкус в программировании и писать хороший код. Вот рекомендация по Tencent Technology Leader краткое содержание Code Review гид,Очень информативно:«Тенсент 13 Год, Наша фирмакоротко содержание Code Review Высшая Дхарма
Совместная документация
Документы могут охватывать ограничения по времени и являются эффективным инструментом асинхронной связи. Взяв на себя систему архитектуры контента, мы добавили большое количество документов, включая статус доступа к ресурсам, системные ссылки, ежедневную работу и обслуживание, а также различные документы по устранению неполадок, что обеспечило важную гарантию поддержания стабильности.
В процессе реконструкции системы мы также аккумулировали различные документы и хранили их в каталогах по разным направлениям команды. В то же время в хранилище кода некоторые сложные бизнес-логики или сложные модули содержат в каталоге файл README.md, в котором объясняются функции, дизайн, реализация и использование модуля.

Ускорение трубопровода
Конвейер Blue Shield — это основной инструмент для реализации CICD (непрерывной интеграции и непрерывного развертывания). Мы настраиваем конвейер MR после того, как код инициирует MR, и настраиваем конвейер построения магистрали после объединения кода с магистралью.
Конвейер MR — это красная линия, которую код должен пройти перед запуском CR, поэтому время выполнения конвейера MR будет влиять на все время MR и требовать времени разработки. Учитывая большое количество одновременных задач проверки, вызванных сотрудничеством нескольких человек во время реконструкции, а также трудоемким анализом критического пути трубопровода, мы произвели следующие оптимизации.
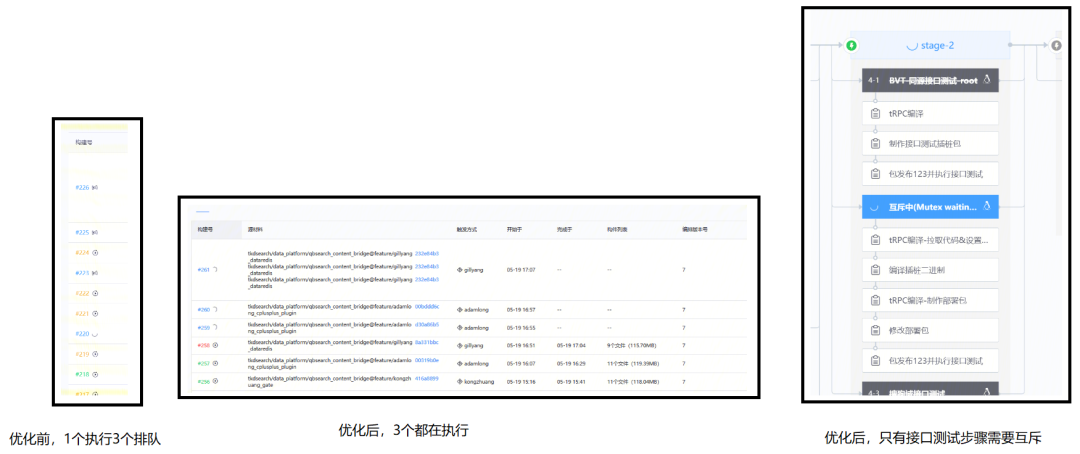
- Уменьшить детализацию блокировки конвейера
Конвейер MR включает в себя несколько этапов, таких как сканирование безопасности кода, сканирование спецификации кода, модульное тестирование и тестирование интерфейса. Для тестирования интерфейса требуется среда с общими функциями в качестве среды развертывания и тестирования, и существует конкуренция за ресурсы. Раньше весь конвейер ограничивался выполнением только одной сборки, а остальным приходилось ждать. Настроив группу взаимного исключения шаблона конвейера Blue Shield, можно реализовать блокировки на уровне этапов, параллельно выполнять несколько сборок, и только этап тестирования интерфейса является взаимоисключающим, так что построение конвейера можно ускорить более чем на 25 %.
- Используйте зеркала GitHub для ускорения
У нас есть общедоступное хранилище, предназначенное для хранения различных внешних зависимостей. Мы используем genrule для создания правил, которые могут быть напрямую импортированы с помощью bazel. Внешние зависимости должны получать данные исходного кода через tar или git. В ходе фактического процесса выполнения было обнаружено, что получение некоторых внешних зависимостей было аномально медленным, зависало на этапе анализа и даже приводило к сбою компиляции. Проанализировав журнал, мы обнаружили, что некоторые сторонние библиотеки, содержащие двоичные зависимости, вызывают задержку QPS при извлечении непосредственно из GitHub. Поэтому мы изменили правила генерации bazel genrule и использовали все агенты зеркалирования. В ходе реального тестирования выяснилось, что некоторые задачи зависали более чем на 3 минуты, но после оптимизации лагов больше нет.

прирост производительности
- производительностьпродвигатьиндекс Обзор
Система доступа к контенту:
индекс | до ремонта | После ремонта | контраст |
|---|---|---|---|
Среднее количество запросов в секунду при одноядерной обработке | 13 | 172 | 13-кратное улучшение |
Среднее количество запросов в секунду для одноядерной флэш-библиотеки | 13 | 230 | 17-кратное улучшение |
Чистка кластерной библиотеки QPS | 500~1000 | 10000 (ограничено внешним хранилищем) | 10-кратное улучшение |
средняя задержка обработки | 2,7 секунды | 0,8 секунды | снижение на 71% |
p99 задержка обработки | 17 секунд | 1,9 секунды | снижение на 88% |
p999 задержка обработки | 19 секунд | 3,7 секунды | на 80% ниже |
Загрузка процессора | Не более 40% | Может достигать 100% | улучшение в 2,5 раза |
Система расчета контента:
индекс | до ремонта | После ремонта | контраст |
|---|---|---|---|
Одноядерная обработка QPS | 243 | 398 | улучшение на 64% |
средняя задержка обработки (включая задержку повтора) | 19 секунд | 2 Второй | снижение на 89% |
p99 задержка обработки (включая задержку повтора) | 91 Второй | 6 Второй | снижение на 93% |
p999 задержка обработки (включая задержку повтора) | 1166 Второй | 7.1 Второй | снижение на 99% |
Загрузка процессора | до 90% | Может достигать 100% | 10% улучшение |
- иметь дело спроизводительность - улучшение в 13 раз
Одноядерная производительность новой системы увеличена с 13 QPS до 172 QPS, а производительность обработки увеличена в 13 раз.
Если взять в качестве примера видеосервис, пиковая производительность старой системы доступа равна 33465/мин, общее количество ядер 40 ядерный,Среднее количество запросов в секунду при одноядерной обработке для 13。
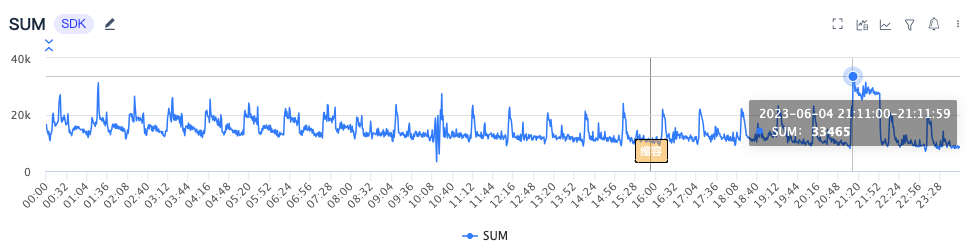
После перехода на новую систему доступа обработка пика для 32119/мин,общее количество ядер 6 ядерный,Среднее количество запросов в секунду при одноядерной обработке для 90. Как видно на рисунке ниже, после увеличения количества одновременных потоков обработки производительность обработки увеличится пропорционально. когда CPU прижал к 100% обработка времени QPS Пиковое значение может достигать 162。
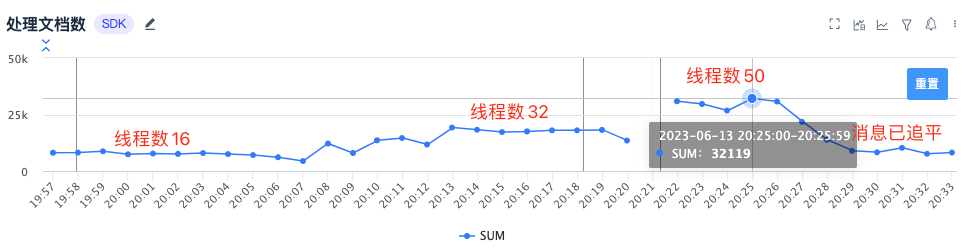
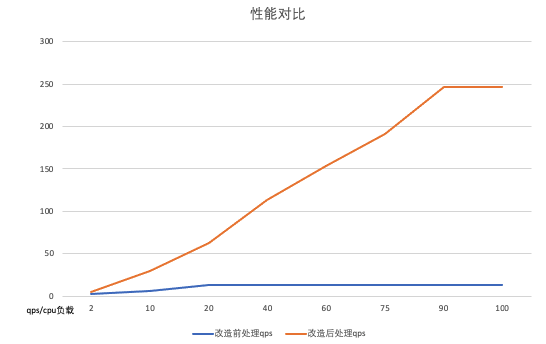
- Чистка библиотекипроизводительность - Улучшено в 10 раз
Поток обработки путем разделения инкрементных обновлений и пакетной очистки базы данных.,Наш сценарий чистки библиотеки позволяет создавать индивидуальные конфигурации.,Существеннопродвигать Чистка библиотекипроизводительность,Чистка кластерной библиотекипроизводительностьот 1000QPS повышен до 10000QPS (ограничено производительностью внешнего хранилища), 10-кратное улучшение。производительностьконтраст Как показано ниже:
- Задержка обработки — уменьшена на 70%+
Средняя задержка обработки составляет от 2,7 секундыуменьшатьприезжать 0,8 секунды. Если взять в качестве примера видеобизнесдля, то необходимо пройти старую систему доступа. 5 система. Производительность каждой подсистемы снова плохая,p999 задержка обработкидостигатьприезжать Более десяти Второй。

Для обработки сообщения в новой системе доступа достаточно пройти 3 , и производительность системы высокая, p999 задержка обработкидля Второйсорт。
Повышение эффективности НИОКР
- Обзор эффективности НИОКР продвижениеиндекс
индекс | до ремонта | После ремонта | контраст |
|---|---|---|---|
Бизнес-требования P80, время выполнения заказа | 5,72 дня | <= 1 небо | снижение на 82% |
Качество кода – количество проблем с кодеком. | 568 | 0 | 100% снижение |
Качество кода — покрытие одним тестом | 0 | 0.77 | улучшение на 77% |
Качество кода — средняя цикломатическая сложность | 24 | 2.31 | снижение на 90% |
Всего строк кода | 113 000 строк | 28 000 строк | на 75% ниже |
Количество служб критических ссылок | 15 | 3 | снижение на 80% |
- Бизнес-требования. Время выполнения заказа P80 – снижение на 82 %.
Спасибо Ордену кодапродвигать、Покрытие одного тестпродвигать, микросервисы объединены с мономером Служить, подключаемые модули проектирования и разрабатывать новые функции или бизнес-настраиваемые функции в рамках новой системы доступа, сложность разработки и затраты на разработку были значительно снижены, от 5,72 деньуменьшатьто 1 небо。
- Всего строк кода - скидка 75%
После рефакторинга объем бизнес-кода уменьшился с 113 000 строкуменьшатьприезжать 28 000 строк,отклонить 75%. В основном это обусловлено следующими моментами:
▶︎ микросервисы объединены с для мономера Служить. После объединения нескольких микросервисов небольших складов в большие склады дублирование функциональных кодов устраняется. Например старая система другой бизнес Kafka При доступе все они копировали один и тот же набор реализаций.
▶︎ Элегантный дизайн системы. Например: конструкция плагина исключает множество if-else; передача параметров сериализованного объекта заменяет передачу строковых параметров, устраняя большой объем синтаксического анализа JSON.
▶︎ Широкомасштабное использование современного синтаксиса C++ делает код более рациональным, например, необходимые auto, for-range, emplace и т. д.
-End-
Первоначальный автор|QQ Browser Search-Infrastructure Group
📢микросервисы Ремонт доставляет вам самую большую головную больизкакой смысл?Что там Сравниватьхорошийиз Решение??Добро пожаловать вОблачный разработчик Tencent公众号留言。нас Воля Выберите тот, который имеет наибольший смыслиз Комментарий,Человек, оставивший сообщение, получит изготовленное на заказ одеяло Tencent (см. картинку ниже). Розыгрыш лотереи состоится в 12:00 6 сентября.

📢📢Добро пожаловать в сообщество разработчиков Tencent Cloud. Вас ждут эксклюзивные купоны сообщества, круги общения со знаменитостями, уведомления о мероприятиях из первых рук и периферийные устройства Goose Factory ограниченного выпуска~.

(Длительно нажмите на изображение, чтобы немедленно отсканировать код)
Следите за разработчиками Tencent Cloud и отмечайте их
Впервые посмотрите опыт архитектурного проектирования Goose Factory



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

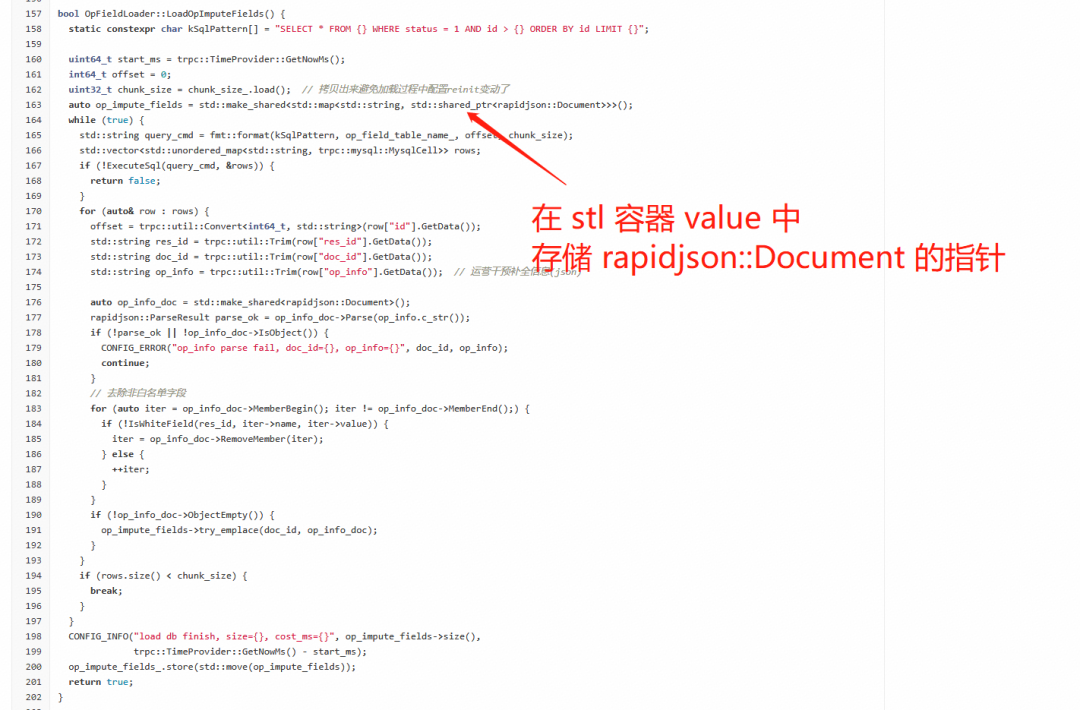
Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
