Microsoft использует GPT-4V для декодирования видео, понимания фильмов и объяснения их незрячим людям. 1 час — не проблема.
Отчет о сердце машины
Монтажер: Панда, Чэнь Пин
В поле зрения выходят крупные модели, почти освоившие языковые возможности, но знаковые GPT-4V Есть еще много недостатков,Видеть《Пытался GPT-4V Позже Microsoft написала 166 Отчет об оценке страницы, инсайдеры отрасли: обязательно к прочтению опытным пользователям》。Недавно Microsoft Azure AI Воля GPT-4V Интегрирован с некоторыми специализированными инструментами для создания более мощного MM-Vid, который не только имеет другие LMM Он обладает базовой способностью анализировать часовые видеоролики и поясняющие видеоролики для слабовидящих.
Люди по всему миру каждый день создают большое количество видеороликов, включая живой пользовательский контент, короткие видеоролики, фильмы, спортивные игры, рекламу и многое другое.
Видео — это универсальный носитель, который может доставлять информацию и контент различными способами, включая текст, визуальные эффекты и аудио. Если мы сможем разработать методы, которые смогут учиться на мультимодальных данных, мы сможем помочь людям разработать мощные когнитивные машины, которые не ограничиваются искусственно скорректированными наборами данных, но могут анализировать исходное видео реального мира. Однако такое богатое представление мультимодальности создает множество проблем при изучении понимания видео, особенно когда видео длинные.
Понимание длинных видеороликов — сложная задача, требующая продвинутых методов, позволяющих анализировать последовательности изображений и аудио из нескольких сегментов. Мало того, еще одной большой проблемой является извлечение информации из разных источников, например, различение разных говорящих, идентификация персонажей и поддержание связности повествования. Кроме того, ответы на вопросы, основанные на доказательствах из видео, также требуют глубокого понимания содержания, контекста и субтитров видео. При анализе прямых трансляций или игровых видеороликов также возникает проблема обработки динамической среды в реальном времени, что требует семантического понимания и возможностей долгосрочного стратегического планирования.
В последнее время большие предварительно обученные видеомодели и модели видеоязыка добились огромного прогресса, и появилась их способность рассуждать на основе видеоконтента. Однако эти модели обычно обучаются с помощью коротких видеоклипов (например, 10-секундных видеороликов в Kinetics и VaTEX) или с помощью заранее определенных категорий действий (Something-Something v1 имеет 174 категории). В результате этим моделям может быть сложно детально понять сложные тонкости реального видео.
Чтобы модели могли более полно понимать видео, с которыми мы сталкиваемся в повседневной жизни, нам нужны методы, которые помогут решить эти сложные проблемы.
Недавно у Microsoft Azure AI появился собственный ответ на эти вопросы: MM-Vid. Команда утверждает, что эту технологию можно напрямую использовать для понимания реального мира. Проще говоря,Их метод заключается в том, чтобы разбить длинное волявидео на связное повествование.,Эти сгенерированные истории затем используются для анализа видео.

- Адрес статьи: https://arxiv.org/pdf/2310.19773.pdf.
- Адрес проекта: https://multimodal-vid.github.io/
MM-Vid недавно был в AI Новый участник Большой мультимодальной модели (LMM), ориентированной на сообщество; LMM самый представительный из GPT-4V Уже продемонстрированные прорывные возможности —— Он может одновременно обрабатывать входные изображения и текст, выполняя мультимодальное понимание. Чтобы добиться понимания видео, MM-Vid Воля GPT-4V В сочетании с некоторыми специализированными инструментами экспериментальные результаты также доказывают эффективность этого метода. картина 1 показал MM-Vid Могут быть достигнуты различные возможности.
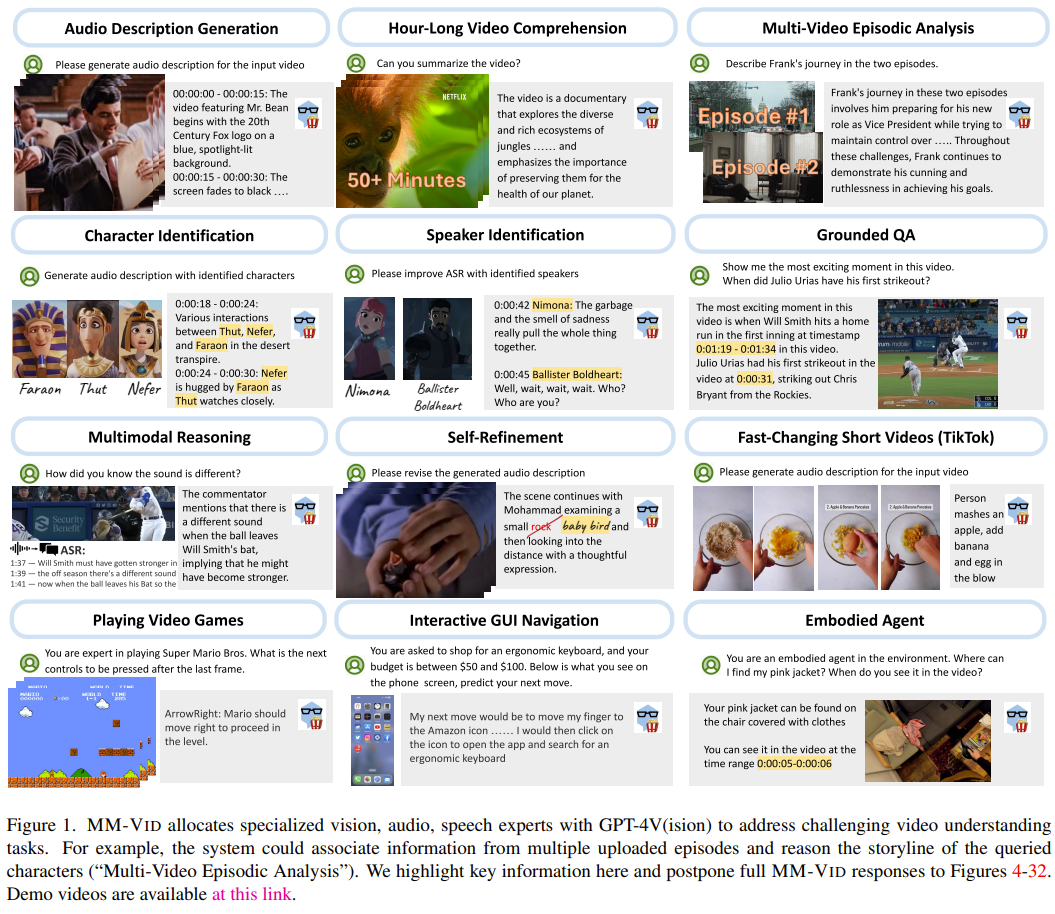
Введение в метод MM-Vid
картина 2 показал MM-Vid Системный рабочий процесс. ММ-Вид Принимает видеофайл в качестве входных данных и выводит сценарий, описывающий видеоконтент. Этот сгенерированный скрипт позволяет LLM Могут быть достигнуты различные возможности понимания видео.
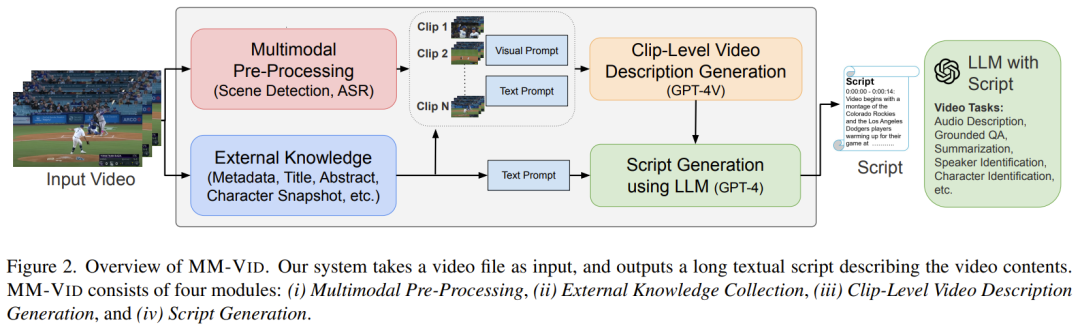
MM-Vid содержит четыре модуля: мультимодальная предварительная обработка, сбор внешних знаний, генерация описания видео на уровне видеоклипа и генерация сценария.
Мультимодальная предварительная обработка. Для входных видеофайлов модуль предварительной обработки сначала использует существующие ASR Инструмент извлекает транскрибированный текст из видео. После этого Волявидео разрезается на короткие видеофрагменты. Этот процесс требует равномерной выборки видеокадров, чтобы каждый сегмент состоял из 10 композиция кадра. Чтобы улучшить общее качество выборки, исследователи использовали PySceneDetect Подождите, пока появятся зрелые инструменты обнаружения сцен, которые помогут определить ключевые границы сцен.
Внешний сбор знаний. Во входной строке GPT-4V исследователи применили метод интеграции внешних знаний. Этот метод включает сбор доступной информации, такой как метаданные видео, заголовок, краткое описание и фотографии людей. В ходе эксперимента исследователи собрали метаданные, заголовки и резюме с YouTube.
Генерация описания видео на уровне сегмента. На этапе мультимодальной предварительной обработки входное видео делится на несколько видеосегментов. Каждый фрагмент обычно содержит 10 подход исследователей заключается в использовании GPT-4V генерировать описание для каждого фрагмента. Автор: Волявидео кадры с соответствующим текстом prompt Войдите вместе в GPT-4V Моделью вы получаете подробное описание, фиксирующее визуальные элементы, действия и события, изображенные в этих кадрах.
Кроме того, исследователи также исследовали дизайн визуальной подсказки, то есть на входе GPT-4V предоставляется не только имя человека, но и фотография лица человека. Результаты экспериментов показывают, что такой дизайн визуальных подсказок помогает улучшить качество описаний видео, особенно помогая более точно идентифицировать людей.
использовать LLM Создать Скрипт. После создания описания для каждого сегмента видео используйте GPT-4 Воля Эти описания на уровне фрагментов объединены в последовательный Скрипт. Скрипт представляет собой исчерпывающее описание всего видео и может быть GPT-4 Используется для решения различных задач по распознаванию видео.
MM-Vid для потокового ввода
картина 3 показалMM-Vid для потокового ввода。
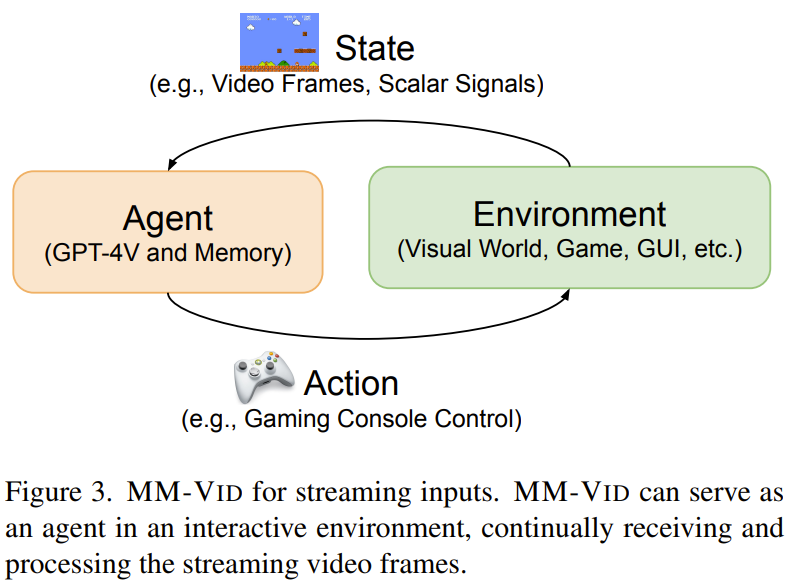
В данном случае ММ-Вид Режим работы — агент в динамической среде, а его основной входной сигнал — поток кадров. Агент рассматривает непрерывный поток входных кадров как состояние, которое представляет собой текущую визуальную информацию, постоянно отображающуюся в окружающей среде. а затем GPT-4V Обрабатывайте эти состояния, чтобы принимать обоснованные решения и генерировать ответы.
Постоянно анализируя потоковые видеокадры, MM-Vid Необработанные визуальные данные можно преобразовать в значимую информацию, которую затем можно использовать для игр, воплощенных агентов и т. д. GUI Такие приложения, как Bootstrap, оказывают ценную помощь.
эксперимент
экспериментнастраивать
Команда добилась MM-Vid на основе MM-React кодовая база. Их инструмент автоматического распознавания речи (ASR) Azure Cognitive Services API общедоступный инструмент use для обнаружения сцен isuse PySceneDetect。
Особенности ММ-Вид
исследователь в статьепоказал Несколько MM-Vid Пример полного потока выполнения.
Ниже приведен пример потока выполнения MM-Vid.

После этих процессов MM-Vid Сгенерированный сценарий суммирует понимание видеоконтента. тем самым позволяя последующим LLM Да основа Это решает конкретные задачи. Конкретные задачи, обсуждаемые исследователями, включают в себя: вопросы и ответы на основе наличия, мультимодальное рассуждение, понимание часовой речи, анализ ситуации с несколькими видео, распознавание людей, идентификация говорящего, генерация аудиоописания, самонастройка, быстро меняющееся короткое видео. Подробности см. в оригинальной статье, но в целом MM-Vid Все показали очень хорошие результаты.
Ниже приведен пример распознавания говорящего.
Используется в интерактивных средах
Исследователи также оценили MM-Vid применительно к потоковому вводу. MM-Vid действует как агент в интерактивной среде, постоянно получая потоковые видеокадры.
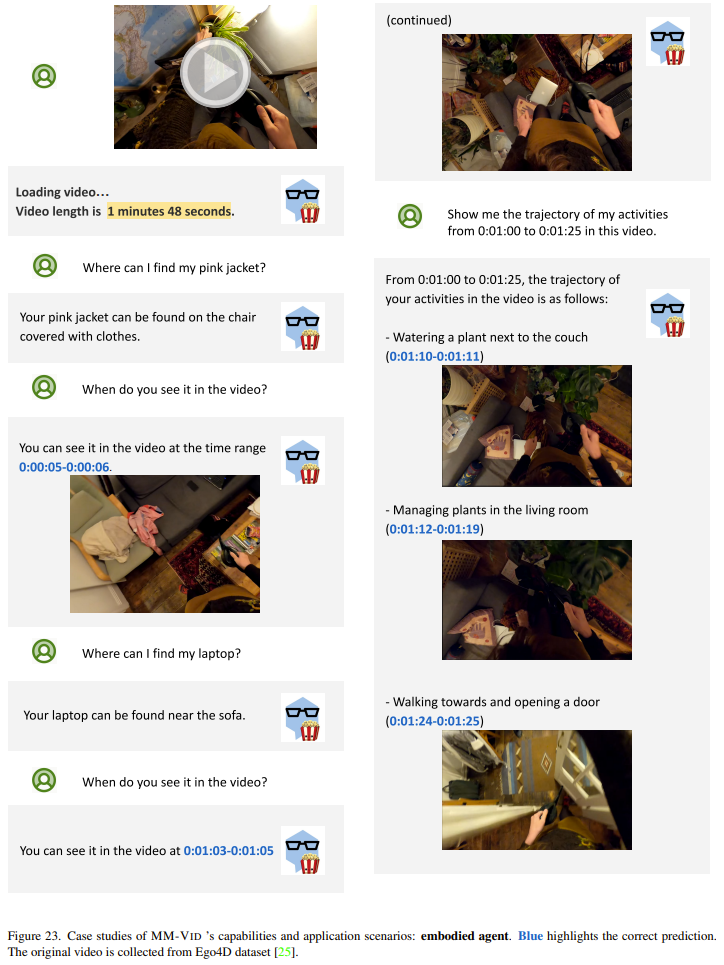
Воплощенный интеллект.Внизкартинапоказал Воля MM-Vid Применяется к случаю видео от первого лица, снятого наголовной камерой. Это видео взято из Ego4D Набор данных, простые фотографии, сделанные людьми в домашней обстановке и повседневной жизни. Стоит отметить, что ММ-Вид Демонстрируется способность понимать этот видеоконтент, а также это может помочь пользователям в выполнении некоторых практических задач.
Играйте в игру видео. Пример видео ниже: Воля MM-Vid используется длявидеоигра《супер Марио》。экспериментсередина,Агент продолжит принимать три кадра в качестве входных данных.,Затем рассчитывается следующее возможное управляющее воздействие. Результаты показывают,Этот агент способен понять динамику конкретной видеоигры.,И он может генерировать разумное управление движением, которое позволяет эффективно играть в игру.
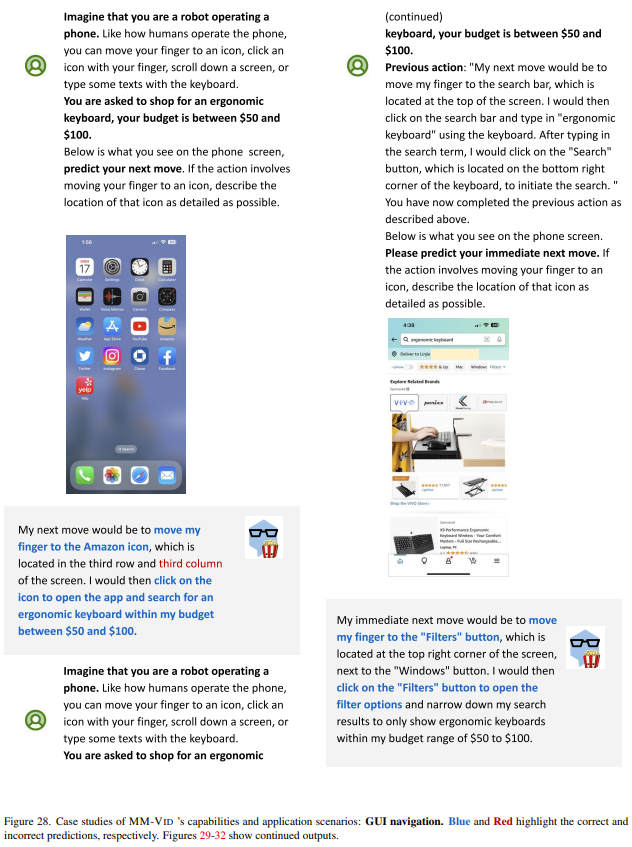
GUI гид. Пример изображения приведен ниже. Здесь непрерывный прием агентом входа равен iPhone Снимок экрана с изображением действий пользователя ранее. Было обнаружено, что агент может эффективно предсказывать следующее возможное действие пользователя при использовании мобильного телефона, например, нажатие на правильное приложение для покупок, затем поиск интересующих продуктов и, наконец, размещение заказа на покупку. Эти результаты показывают MM-Vid Он может эффективно взаимодействовать с пользовательским интерфейсом изображения и обеспечивать плавное и интеллектуальное управление пользователем через цифровые интерфейсы.
исследование пользователей
Исследователи изучают потенциал MM-Vid в помощи слепым или слабовидящим людям. Аудиоописание (AD) добавляет к звуковой дорожке видео звуковое повествование, которое может предоставить важные визуальные детали, отсутствующие в звуковой дорожке основного видео. Такие описания передают ключевой визуальный контент людям с нарушениями зрения.
чтобы оценить MM-Vid Об эффективности генерации аудиоописаний исследователи провели исследование пользователей. они пригласили 9 Участники приняли участие в оценке. в 4 Участники были слепы или имели слабое зрение, а остальные 5 Зрение нормальное. Все участники имели нормальный слух.
Видео ниже представляет собой пример приложения описания звука MM-Vid:
Результат следующий:картина 5 Как показано, общая удовлетворенность участников измеряется по шкале Лайкерта (0 = Не удовлетворен 10 = Очень доволен), ММ-Вид Созданные аудиоописания в среднем имеют более низкое качество, чем аудиоописания, созданные человеком. 2 точка.
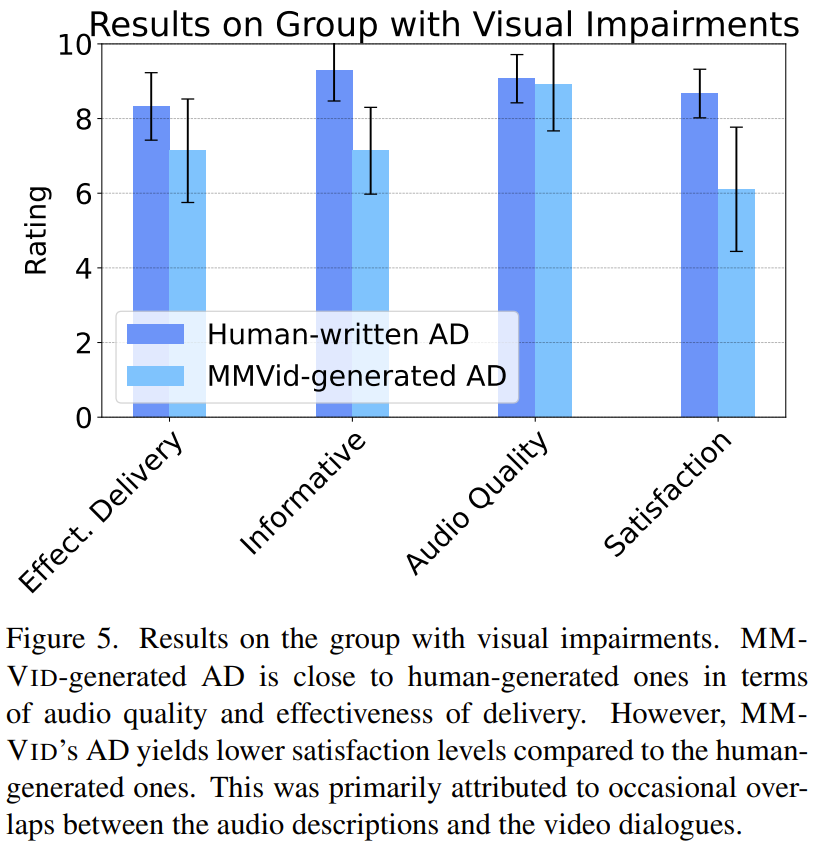
слушаю MM-Vid Трудности, отмеченные участниками при создании аудиоописаний, включали: 1) аудиоописания иногда перекрывались с диалогами в исходном видео, 2) из-за GPT-4V Неверное описание появляется из-за проблем с галлюцинациями. Несмотря на различия в общей удовлетворенности, все участники согласились: MM-Vid Сгенерированные аудиоописания — экономичное и масштабируемое решение. Поэтому для большого количества видео, которые профессионалы не могут назвать аудио, просто используйте MM-Vid Такие инструменты для их решения приносят пользу сообществу с нарушениями зрения.
© THE END
Пожалуйста, свяжитесь с этим общедоступным аккаунтом, чтобы получить разрешение на перепечатку.
Публикуйте статьи или ищите освещение: content@jiqizhixin.com



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
