MFDS-DETR с открытым исходным кодом | HS-FPN многоуровневое объединение функций + деформируемое самообслуживание, продолжение легенды DETR

При стандартном больничном анализе крови традиционный процесс требует, чтобы врачи вручную отделяли лейкоциты от микроскопического изображения крови пациента с помощью микроскопа, а затем сортировали изолированные лейкоциты с помощью автоматического сортировщика лейкоцитов, чтобы определить количество и количество лейкоцитов. различные типы лейкоцитов в образце крови, что помогает в диагностике заболевания. Этот подход не только требует много времени и усилий, но также может привести к ошибкам из-за таких факторов, как качество изображения и условия окружающей среды, что потенциально может привести к последующей классификации и неправильному диагнозу. Современные методы обнаружения лейкоцитов имеют ограничения в обработке изображений с меньшим количеством особенностей лейкоцитов и различиями в масштабах между разными лейкоцитами, что в большинстве случаев приводит к неудовлетворительным результатам. Для решения этих проблем в данной статье предлагается инновационный метод обнаружения лейкоцитов: многоуровневое слияние признаков и деформируемый DETR самовнимания (MFDS-DETR). Чтобы решить проблему разницы в шкале лейкоцитов, автор разработал пирамиду слияния функций скрининга высокого уровня (HS-FPN) для достижения многоуровневого слияния. Эта модель использует функции высокого уровня в качестве весов для фильтрации информации о функциях низкого уровня через модуль внимания канала, а затем объединяет отфильтрованную информацию с функциями высокого уровня, тем самым улучшая способность модели выражать функции. Кроме того, авторы решают проблему нехватки характеристик лейкоцитов, интегрируя многомасштабный деформируемый модуль самообслуживания в кодировщик и используя механизмы само-внимания и перекрестно-деформируемого внимания в декодере, что помогает извлечь глобальные характеристики Карта характеристик лейкоцитов. Эффективность, превосходство и универсальность предлагаемого метода MFDS-DETR демонстрируются в сравнении с другими современными моделями обнаружения лейкоцитов с использованием частных наборов данных WBCDD, общедоступных L1SC и BCCD. Исходный код и набор данных WBCDD: https://github.com/JustIC03/MFDS-DETR
1 Introduction
В последние годы глобальная заболеваемость такими серьезными заболеваниями, как острый лейкоз, значительно возросла. Основным инструментом диагностики этих заболеваний является рутинный анализ крови, при котором врач изучает микроскопическое изображение мазка крови пациента с помощью микроскопа. Диагноз основывается на различных типах и соотношениях лейкоцитов. Автоматизированная классификация лейкоцитов обычно используется в качестве метода гематологического анализа для классификации лейкоцитов на изображениях крови. Этот метод обычно точно определяет различные типы лейкоцитов путем изучения таких атрибутов, как морфология, размер, пигмент и ядрышковые характеристики. Однако применение моделей классификации лейкоцитов часто требует от опытных врачей ручного отделения лейкоцитов от микроскопических изображений крови пациентов, что является трудоемким и длительным процессом, подверженным ошибкам.
Кроме того, на процесс могут влиять такие факторы, как качество изображения и условия окружающей среды, что приводит к потенциальным ошибкам в последующей классификации. Эти ошибки могут ввести врачей в заблуждение и привести к проблемам с безопасностью пациентов. Чтобы решить эти проблемы, исследователи изучают обнаружение мишеней лейкоцитов. Целью данного исследования было автоматическое и точное определение местоположения лейкоцитов на микроскопических изображениях крови и подсчет различных типов лейкоцитов. Этот метод может ускорить процесс диагностики и принятия врачами решений о лечении, тем самым улучшая уход за пациентами, и имеет очень важное исследовательское значение.
Традиционное обнаружение мишени лейкоцитов часто сталкивается со следующими проблемами на микроскопических изображениях крови:
- В разных больницах используется разное оборудование для получения изображений крови, создавая изображения с разными цветовыми конфигурациями. Это изменение может привести к менее эффективному обнаружению лейкоцитов.
- Ограниченное количество идентифицируемых особенностей на изображениях лейкоцитов также представляет собой препятствие для эффективного обнаружения.
- На изображениях крови, полученных с помощью разного больничного оборудования и при разных уровнях увеличения, наблюдаются несоответствия в размерах лейкоцитов. Кроме того, присущие различия в размерах разных типов лейкоцитов могут усугублять эти различия в размерах, отрицательно влияя на эффективность обнаружения лейкоцитов.
- По сравнению с другими естественными изображениями,Изображения лейкоцитов, полученные при медицинской микроскопии, часто имеют низкое разрешение и различные режимы визуализации. Большие различия в геометрическом внешнем виде между объектами на этих изображениях и объектами на естественных изображениях создают серьезные проблемы для традиционных алгоритмов обнаружения объектов.
Для решения проблем обнаружения лейкоцитов-мишеней, связанных с визуализацией микроскопии крови, в этой статье предлагается метод, основанный на многоуровневом слиянии признаков и деформируемом самовнимании DETR (MFDS-DETR). Пирамида слияния функций скрининга высокого уровня (HS-FPN) была разработана для облегчения многоуровневого слияния и учета уникальных свойств лейкоцитов и различий в размерах между различными лейкоцитами. В HS-FPN функции высокого уровня используются в качестве весов для фильтрации информации о функциях низкого уровня через модуль внимания канала. Отфильтрованная информация объединяется с расширенными функциями для расширения возможностей выражения функций модели.
Кроме того, чтобы решить проблему нехватки признаков в лейкоцитах, в кодировщике введен многомасштабный деформируемый механизм самообслуживания. Это помогает извлечь глобальные особенности карты признаков лейкоцитов. Затем, используя механизмы само-внимания и перекрестно-деформируемого внимания, декодер изучает объекты, которые необходимо обнаружить, исходя из глобальных функций кодера. Затем выходные данные декодера сопоставляются со значением GT в двудольном графе, чтобы получить местоположение и категорию объекта. Этот процесс позволяет автоматически обнаруживать лейкоциты.
По сравнению с существующими методами обнаружения лейкоцитов, MFDS-DETR эффективно решает проблему ограниченных характеристик лейкоцитов на микроскопических изображениях крови. Кроме того, это снижает влияние различий в размерах разных лейкоцитов на изображении на эффективность процесса моделирования. Результаты данного исследования можно резюмировать следующим образом:
В области мелкозернистого обнаружения лейкоцитов авторы предложили новый метод под названием MFDS-DETR. Этот метод, основанный на многомасштабном слиянии и деформируемом самовнимании, состоит из четырех ключевых компонентов: магистральной сети, пирамиды с расширенными функциями фильтрации, кодера и декодера.
Под руководством нашей команды медицинских специалистов мы нацелились на существующий общедоступный набор данных по классификации лейкоцитов LISC. Автор также работал с больницей-партнером автора над разработкой собственного набора данных для обнаружения лейкоцитов WBCCD, который будет доступен другим исследователям через ссылку для скачивания в репозитории автора на GitHub.
Разработки в области тестирования лейкоцитов во многом зависят от текущего состояния наборов данных. Существующие общедоступные наборы данных по лейкоцитам LISC и BCCD собирались в течение длительного времени, но они малы и имеют низкое качество. Поэтому автор решил поделиться своим набором данных WBCCD с другими исследователями и внести важный вклад в развитие этой области.
Авторы предложили инновационный HS-FPN. В отличие от традиционных методов объединения признаков, основанных на естественных изображениях, этот модуль разработан с учетом присущих лейкоцитам различий в размерах. Это существенное изменение значительно расширяет возможности модели по выражению признаков в наборе данных обнаружения лейкоцитов.
Предложенная авторами модель MFDS-DETR превосходит другие продвинутые и базовые модели в обнаружении лейкоцитов. Это подтверждается превосходными результатами обнаружения, полученными в двух общедоступных наборах данных, LISC и BCCD, а также в частном наборе мелкозернистых данных обнаружения лейкоцитов WBCCD, хранящемся у авторов. Эти результаты подчеркивают обоснованность и широкую применимость модели авторов.
2 Related Work
Модель серии сверточных нейронных сетей (CNN) представляет собой эффективный и точный одноэтапный механизм обнаружения целей и широко используется в области обнаружения целей. Поэтому он стал неотъемлемой частью многих исследований, посвященных обнаружению мишеней лейкоцитов [31]. [1] использовали модели SSD и YOLOv3 для автоматического обнаружения лейкоцитов, добившись обнаружения 11 типов периферических лейкоцитов. Стоит отметить, что изображение лейкоцитов — это лишь малая часть изображения крови.
Чтобы решить проблему относительно низкой производительности современных методов обнаружения при работе с более мелкими целями, [2] предложили SO-YOLO, который сначала использует CNN для извлечения особенностей изображения, а затем использует YOLO для обнаружения целей лейкоцитов. Чтобы еще больше улучшить производительность модели, [3] предложили MID-YOLO, одноэтапный детектор CNN для изображений лейкоцитов. Эта модель использует механизм внимания и демонстрирует превосходную эффективность обнаружения в общедоступном наборе данных Raabin-WBC. [4] использовали EfficientNet в качестве магистральной сети для повышения эффективности и гибкости модели и предложили детектор TE-YOLOF. [32] применили эту проблему к диагностике острого лимфобластного лейкоза с помощью алгоритма обнаружения мишеней YOLOv4, который в настоящее время используется в качестве важного вспомогательного инструмента для предварительного скрининга. [5] предложили YOLOv5-CHE, модель обнаружения лейкоцитов, основанную на улучшенном YOLOv5. Эта модель решает проблему нехватки выборок и различий в категориях, а также расширяет возможности модели по извлечению признаков за счет интеграции механизма координатного внимания в сверточный слой.
Учитывая, что использование одной модели может привести к систематической ошибке, [6] разработали интегрированную модель на основе YOLOv3, YOLOv3-SPP и YOLOv3-tiny. Когда IoU равен 0,5, средняя точность (AP) достигает 88,6%. [7] предложили метод обнаружения лейкоцитов, основанный на Twin-Fusion-Feature CenterNet (TFF-CenterNet), для облегчения проблем, вызванных изменениями уровней окрашивания лейкоцитов. Этот метод решает проблему различий в степени окрашивания за счет оптимизации пирамиды слияния признаков.
Хотя скорость одноэтапной модели обнаружения объектов может быть ниже, точность обнаружения по-прежнему отстает от двухэтапной модели обнаружения объектов. [8] использовали Faster R-CNN для обнаружения объектов и экспериментально продемонстрировали, что использование ResNet-50 в качестве магистральной сети позволяет добиться более высокой точности распознавания. [9] улучшили возможности многомасштабного объединения признаков модели Mask R-CNN, добавив механизм внимания к модулю пирамиды объединения признаков, тем самым повысив точность обнаружения. [33] объединили YOLOv5 с моделью RetinaNet для точного количественного определения лимфоцитов по пространственному расположению и фенотипическим характеристикам, а также проверили производительность сети, например, применяя такие модификации изображения, как размытие, резкость, яркость и контрастность. [34] использовали YOLOv8 с DETR для обнаружения тысяч лейкоцитов и использовали DETR для обработки нескольких объектов на одном изображении для повышения точности обнаружения.
Однако в этих исследованиях по обнаружению мишеней лейкоцитов используются сверточные нейронные сети (CNN) для извлечения признаков, а затем выполнения целевой локализации и классификации. Этот метод страдает от оператора свертки и не способен изучить глобальные особенности изображений лейкоцитов, что затрудняет точную локализацию и классификацию лейкоцитов периферической крови. Кроме того, эффективность обнаружения лейкоцитов ограничена следующими двумя проблемами:
В отличие от методов визуализации естественных изображений, изображения лейкоцитов, полученные при медицинской микроскопии, имеют низкое разрешение. В сочетании с присущими лейкоцитам свойствами это приводит к обычному ухудшению изображения лейкоцитов.
Микроскопические инструменты в разных больницах имеют разное увеличение, а размер лейкоцитов также неравномерен, что приводит к разрыву в размерах между лейкоцитами.
Для решения вышеуказанных проблем часто применяется многомасштабное объединение функций. Этот процесс включает в себя объединение глубоких функций с поверхностными, чтобы мелкие функции имели надежную семантическую информацию. Существует два многомасштабных метода объединения функций: параллельная многоветвевая сеть и структура последовательного пропуска. Параллельные сети с несколькими ветвями обычно используют разные свертки для извлечения объектов одной и той же карты объектов, а затем используют конкатенацию для объединения извлеченных объектов. Эта идея воплощена в модуле Inception от GoogLeNet, который использует различные свертки для извлечения функций одной и той же карты объектов, а затем объединяет их по размерам канала.
Аналогичным образом, SSPNet объединяет одну и ту же карту объектов тремя разными способами, а затем объединяет их вместе, чтобы получить многомасштабную объединенную карту объектов. DeepLabv3+ использует структуру ASSP для объединения функций, получает функции в разных масштабах посредством пустой свертки и выполняет операции унификации масштабов посредством повышения дискретизации. TridentNet и Big-Little Net применяют схожие стратегии, причем последняя использует модули BL для более гибкой обработки информации различного масштаба. В отличие от методов параллельного соединения, структуры последовательного пропуска обычно выполняют многомасштабное объединение выходов разных уровней в магистральной сети.
Feature Pyramid Network (FPN) обеспечивает многомасштабное объединение функций путем повышения выборки функций высокого уровня в едином масштабе, а затем добавления их к функциям низкого уровня. Однако, поскольку FPN имеет неоднозначность в отношении целевой информации высокого уровня, PANet добавляет модуль двунаправленного объединения функций поверх FPN для улучшения информации о локальном позиционировании. На основе этих методов BiFPN предлагает более краткое двунаправленное объединение функций. Сбалансированное FPN добавляет функции всех масштабов к исходным функциям масштаба перед их интеграцией и оптимизацией. CE-FPN улучшает процесс интеграции и оптимизации за счет использования семантических функций высокого уровня и механизмов внимания для выборочного объединения функций. FaPN также разработала модули выбора и выравнивания функций, чтобы повысить точность объединения функций в FPN и решить потенциальные проблемы несовпадения функций FPN.
Хотя эти многомасштабные методы объединения признаков имеют важное значение,Но по сути они созданы на основе естественных изображений. Хотя некоторые методы эффективны при обнаружении лейкоцитов,Но они не учитывают реальные свойства микроскопических изображений лейкоцитов.,Это ограничивает эффект обнаружения Модели. Предложенная автором сетевая модель MFDS-DETR эффективно решает эти ограничения. Модель прошла первой Backbone Сеть получает многомасштабные карты признаков из микроскопических изображений лейкоцитов, а затем использует разработанный HS-FPN для объединения признаков. Он интегрирует многомасштабный деформируемый механизм самообслуживания в работу кодера для получения глобальных характеристик микроскопических изображений лейкоцитов и, наконец, использует декодер для получения местоположения и категории лейкоцитов. Инновационная модель автора использует функции высокого уровня в качестве весов для фильтрации функций низкого уровня и объединяет отфильтрованные функции с функциями высокого уровня, тем самым значительно улучшая эффект обнаружения модели.
Кроме того, за счет применения многомасштабного деформируемого механизма самообслуживания для извлечения особенностей изображения авторская модель значительно снижает сложность и улучшает результаты обнаружения.
3 Method
Overall Architecture
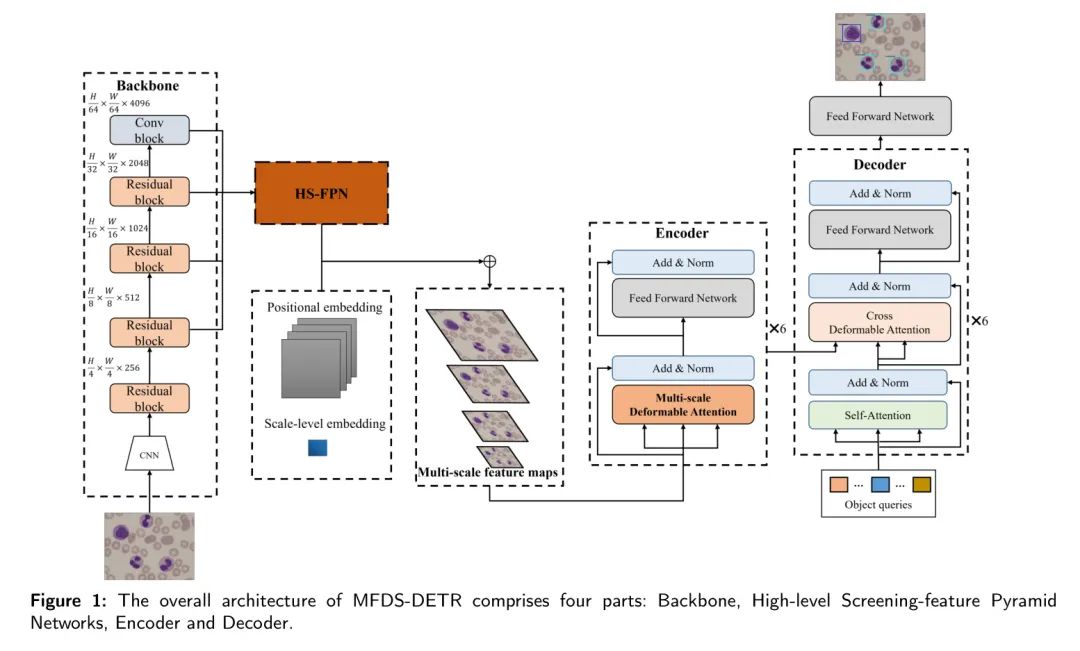
Общая структура модели MFDS-DETR показана на рисунке 1 и включает в себя четыре ключевых компонента: магистральная сеть, HS-FPN, кодер и декодер. Основная функция сети Backbone — извлечение многомасштабных признаков изображения лейкоцитов, тем самым способствуя расширенному слиянию признаков в последующем процессе. HS-FPN — это разработанная и улучшенная пирамида функций, учитывающая особенности изображений лейкоцитов и решающая проблемы ограниченных функций и различий в диаметрах лейкоцитов на изображениях лейкоцитов. HS-FPN выполняет фильтрацию признаков низкого уровня, используя модуль внимания канала (CA) в HS-FPN для использования семантических признаков высокого уровня в качестве весов. Эти отфильтрованные признаки добавляются по пунктам с семантическими признаками высокого уровня для достижения многомасштабного объединения признаков, тем самым в конечном итоге улучшая возможности выражения признаков модели. Основная функция модуля кодера — изучение глобальных особенностей изображений лейкоцитов.
Благодаря интеграции многомасштабного деформируемого модуля самообслуживания модель может изучать глобальные особенности изображений лейкоцитов в разных масштабах. Вместо этого декодер выполняет сопоставление двудольного графа между выходными значениями и значениями GT, чтобы определить местоположение и категорию объекта. Это достигается за счет использования механизмов самообслуживания и перекрестной деформации для изучения объектов, которые необходимо распознать, на основе глобальных функций кодера.
Backbone Network
В процессе извлечения функций MFDS-DETR в качестве магистральной сети используется расширенная версия ResNet-50. ResNet-50 использует остаточные соединения для решения проблемы исчезновения градиента, тем самым способствуя конвергенции и решая проблемы деградации, которые часто сопровождают глубокие нейронные сети.
Из-за отсутствия функций в изображениях лейкоцитов авторы усовершенствовали исходную модель ResNet-50, добавив в магистральную сеть модуль свертки. Этот модуль предназначен для извлечения более глубокой семантической информации для улучшения эффекта обнаружения модели. Подобно ResNet-50, этот модуль свертки сначала проходит
Использование свертки
Блок свертки уменьшает количество каналов и затем передает
Свертка уменьшает размер карты объектов и, наконец, передает другой
Свертка увеличивает количество каналов.
High-level Screening-feature Pyramid Networks
В наборе данных лейкоцитов задача идентификации лейкоцитов сталкивается с многомасштабными проблемами, что затрудняет точную идентификацию лейкоцитов с помощью модели. Эта сложность связана с тем, что разные типы лейкоцитов часто имеют разный диаметр, и даже под одним и тем же микроскопом один и тот же тип лейкоцитов может оказаться разного размера при изображении под разными микроскопами.
Чтобы решить присущие многомасштабные проблемы в наборах данных по лейкоцитам, авторы разработали иерархическую масштабную пирамидную сеть признаков (HS-FPN) для достижения многомасштабного объединения признаков. Это позволяет модели собирать более полную информацию о характеристиках лейкоцитов.
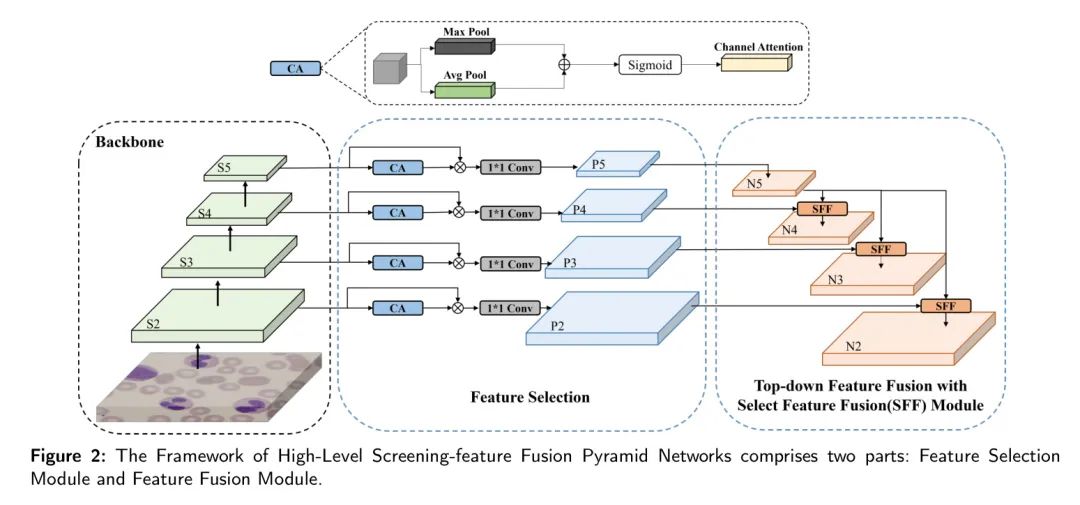
Структура HS-FPN показана на рисунке 2 и включает два основных компонента:
- Модуль выбора функций;
- Особенность модуля Fusion.
Сначала карты признаков разного масштаба проходят процесс проверки в модуле выбора признаков. Затем информация высокого и низкого уровня в этих картах функций совместно интегрируется с помощью механизма выборочного объединения функций (SFF). Такое слияние создает признаки с богатым семантическим содержанием, которые полезны для обнаружения тонких особенностей на микроскопических изображениях лейкоцитов, тем самым расширяя возможности обнаружения модели. Подробное описание механизма SFF и его влияния на производительность модели будет представлено в следующем разделе исследований абляции.
Модуль выбора функций: В этом процессе ключевую роль играют модуль CA и модуль сопоставления размеров (DM). Модуль CA сначала обрабатывает входную карту объектов.
,в
Указывает количество каналов,
Представляет высоту карты объектов,
Представляет ширину карты объектов. После того, как эта карта объектов обрабатывается двумя слоями объединения — глобальным средним объединением и глобальным максимальным объединением, полученные объекты объединяются вместе. Затем используйте функцию активации Sigmoid, чтобы определить значение веса каждого канала, тем самым получив вес каждого канала,
。
Пулирование имеет множество основных применений:Это уменьшает размерность карт объектов и уменьшает размерность карт объектов.;Устранение избыточностиданные,Сжимайте объекты и уменьшайте количество параметров, а также добивайтесь неизменности перемещения, вращения и масштаба. В модуле СА,Объединение глобальных средних и глобальных максимальных значений используется для расчета среднего и максимального значения каждого канала. Основная цель максимального пула — извлечь наиболее важные данные из каждого канала.,А среднее пулирование предназначено для равномерного получения всех данных из карты объектов.,минимизировать чрезмерные потери.
Таким образом, в модуле CA объединение этих двух методов объединения позволяет легко извлечь наиболее репрезентативную информацию из каждого канала, минимизируя при этом потери информации. Отфильтрованная карта объектов затем генерируется путем умножения информации о весе для выполнения сопоставления размеров с картой объектов соответствующего масштаба. Перед объединением функций решающее значение имеет сопоставление размеров карт объектов в различных масштабах, поскольку они имеют разные номера каналов. Для этого модуль DM применяет
Свертка уменьшает количество каналов каждой карты признаков масштаба до 256.
Особенность модуля Fusion: Backbone Многомасштабная карта объектов, созданная сетью, содержит богатую семантическую информацию, но целевая локализация является относительно грубой. Напротив, низкомасштабные объекты обеспечивают точные целевые местоположения, но содержат ограниченную семантическую информацию. Распространенный способ решить эту дилемму — напрямую суммировать высокоуровневые функции с повышенной дискретизацией и значения пикселей низкомасштабных функций для добавления семантической информации к каждому слою. Однако этот метод не выполняет выбор объектов, а просто добавляет значения пикселей нескольких векторных слоев. Чтобы устранить это ограничение, в данном исследовании авторы разработали модуль SFF. Этот модуль фильтрует необходимую семантическую информацию, содержащуюся в низкомасштабных объектах, используя высокоуровневые функции в качестве весов.
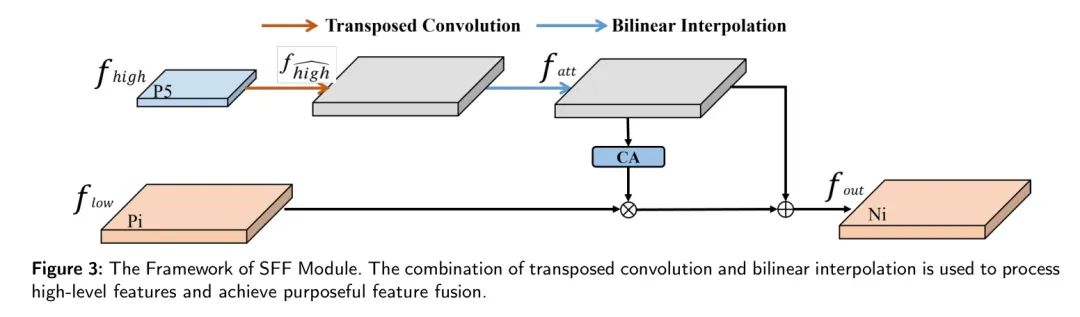
Как показано на рисунке 3, учитывая входную функцию высокого уровня
и входной низкомасштабный объект
, высокоуровневые функции сначала расширяются с использованием транспонированной свертки (T-Conv) размера 2 и размера ядра 3x3 для получения размера функции
。
Затем, чтобы унифицировать размеры объектов высокого уровня и объектов низкого масштаба, авторы используют билинейную интерполяцию для повышения или понижения дискретизации объектов высокого уровня для получения объекта.
. Затем модуль CA используется для преобразования функций высокого уровня в соответствующие веса внимания для фильтрации низкомасштабных функций после получения функций с теми же размерами.
Наконец, отфильтрованные низкомасштабные функции объединяются с высокоуровневыми функциями, чтобы улучшить представление функций модели и получить
. Уравнения (1) и (2) иллюстрируют процесс объединения выбора признаков:
В процессе выборки изображений авторы используют комбинацию транспонированной свертки и билинейной интерполяции для восстановления масштаба карт объектов высокого уровня. Билинейная интерполяция проста и быстра и может напрямую управлять пикселями изображения для его масштабирования.
К преимуществам транспонированной свертки относятся:
- Адаптация через изучаемые параметры,Чтобы выходные данные не только увеличивали карту объектов.,И восстановите входные данные в виде свертки,Это достигается за счет реализации операции свертки путем заполнения нулями после расширения карты объектов;
- Он может решать проблемы неравномерной выборки, осуществляя выборку различных областей входного изображения в разных местах выходного изображения.
Эксперименты авторов по абляции также подтвердили, что комбинация транспонированной свертки и билинейной интерполяции превосходит использование только билинейной интерполяции.
Deformable Self-attention Module
Деформированный модуль самовнимания в основном состоит из двух компонентов: модуля смещения и модуля внимания. Далее полностью описаны их соответствующие реализации.
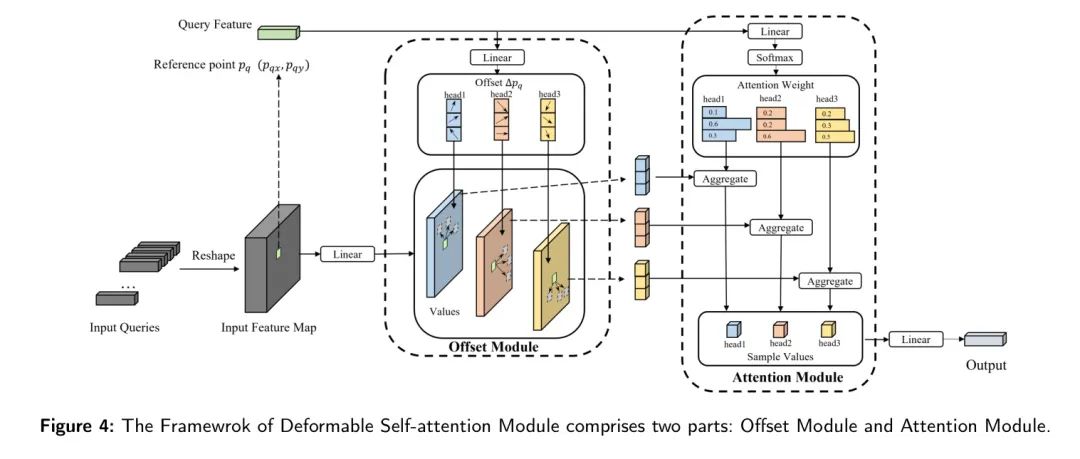
Офсетный модуль:Как показано на картинке4показано,Перед интеграцией векторов в модуль смещения,Его необходимо преобразовать в карту объектов.,Затем сгенерируйте ввод Query вектор с учетом координат точки связи. верно Query Примените линейное преобразование к вектору, чтобы получить смещение.
, применив аналогичный метод к входной карте объектов, чтобы получить карту объектов контента.
Затем,Определите точку интереса (точку выборки) каждой точки ссылки на основе смещения точки ссылки.,И используйте билинейную интерполяцию для достижения результата каждой точки.
. Как показано на рисунке 4, каждый вектор запроса имеет
головы внимания, каждая голова внимания связана с
связанные точки смещения. В экспериментах, проведенных в рамках данного исследования,
и
Значения 8и4 соответственно.
Внимание модуль:Как показано на картинке4показано,Процесс внимания модуля начинается с ввода Query Линейное преобразование векторов. Затем используйте функцию Softmax, чтобы сгенерировать весовой вектор для каждого смещения. Выходные данные каждого смещения, определенного в модуле Offset, умножаются на соответствующий весовой вектор. Затем суммируйте результаты, чтобы получить
。
Следующий,Подключите головки внимания, соответствующие каждой точке связи.,получить окончательный вектор,называется
. наконец,Линейно преобразуйте выбранный выходной вектор,Получите окончательное выходное значение. Уравнения этого процесса приведены в (3), (4), (5) и (6).
Поскольку MFDS-DETR использует модуль HS-FPN для облегчения многомасштабного объединения входных функций магистральной сети, входные данные кодера содержат многомасштабные карты объектов.
Чтобы извлечь информацию о характеристиках лейкоцитов в разных масштабах,Используется многоуровневый деформируемый модуль внимания. Этот модуль позволяет не только узнать смещение шкалы входной точки связи.,Это также позволяет проводить обучение смещению на основе относительных положений между нормализованными точками связи в этих шкалах. Модуль вычисляет выходной вектор смещения в каждом масштабе. Затем,Векторы результатов в разных масштабах взвешиваются и интегрируются.,Получите окончательный выходной вектор. Уравнение для расчета многомасштабного деформируемого внимания показано в (7).
в
Представляет количество голов внимания,
представляет многомасштабное число,
Указывает количество точек отбора проб. Нет.
внимание голова
Точка отбора проб слоя
Вес точки ссылки
Выражено как
。
Соответствует преобразованной карте признаков входного вектора.
ссылкаточка
В первом
внимание голова
Точка отбора проб слоя
Абсолютные координаты Выражено как
。ссылкаточка
В первом
внимание голова
Точка отбора проб слоя
компенсация в
выражать. Значение выборки, соответствующее текущей точке выборки на карте объектов контента.
Зависит от
данный.
Encoder and Decoder
кодер Играет ключевую роль в извлечении глобальных характеристик из изображений лейкоцитов.。кодер Входные данные представляют собой многоуровневую карту объектов.,Интегрированное кодирование пространственного положения и кодирование масштаба,Как показано на картинке1показано。кодер Каждый этаж внутри Зависит от Состоит из деформируемого модуля самообслуживания и сети прямой связи (FFN). Зависит от Вссылкаточка Положение оказывает существенное влияние на деформируемое внимание к себе.,Поэтому он инициализируется путем определения координат центра каждого пикселя шкалы и их нормализации. После определения положения точки связи,Многоуровневый деформируемый модуль самообслуживания генерирует выходные векторы.
В этом исследовании,Деформируемое самообслуживание в виде восьми головок внимания.,каждая головасосредоточиться на Смещение в разные стороны. Чтобы снизить риск исчезновения градиентов и ускорить сходимость модели, используйте добавку и нормализацию (Добавить and Norm) для генерации нормализованного выходного вектора.
Затем,Эти выходные векторы обрабатываются структурой сети FFN.,Это многослойный перцептрон,Отвечает за расширение и уменьшение размеров.,Позволяет модели изучить больше нелинейных корреляций между функциями. Эксперименты по абляции в этом исследовании показали,В MFDS-DETRМодель,Шестой этажкодер Лучшее выступление。
Декодер играет ключевую роль в установлении связи между различными обнаруженными представлениями объектов и определении точного местоположения и категории объекта. Как показано на рисунке 1,Каждый уровень декодера состоит из двух компонентов: модуля извлечения признаков самообслуживания и модуля извлечения признаков перекрестного внимания. Модуль извлечения функции самообслуживания включает в себя модуль самообслуживания и сеть прямой связи (FFN).,Конструктивно похож на Вкодеркомпоненты в。
Однако,В отличие от кодера,Ключ к модулю извлечения признаков перекрестного вниманияи Query из кодировки позиции (Объект Queries), значения которых поступают из глобальных функций, извлеченных из последнего слоя кодировщика.
Joint Loss Function
Комбинированная функция потерь представлена формулой (8).
Сложная функция потерь Зависит от Состоит из трех основных компонентов:Классификацияпотеря、регрессионная потеряивспомогательная потеря。Классификацияирегрессионная потеряиспользовать Воптимизация Модельи определить наилучшее значение соответствия。Напротив,Вспомогательные потери используются для ускорения сходимости Модели. первый,Вспомогательные потери рассчитывают потери классификации и потери регрессии для каждого выходного слоя декодера.
3.6.1 Classified Losses
Зависит от Декодер содержит 100 мишеней Query в то время как реальная цель изображения лейкоцитов обычно содержит только 2 или 3 лейкоцита, поэтому может возникнуть дисбаланс между положительными и отрицательными образцами. Поэтому автор вводит функцию фокусных потерь для решения этой проблемы дисбаланса. Расчет функции фокусных потерь приведен в формуле (9).
Функция фокусных потерь включает в себя два гиперпараметра:
и
. здесь,
представляет долю каждой категории в наборе данных, и
присвоено значение 2. В этой обстановке
Используется в функции «Фокальные потери» для балансировки неравномерных пропорций в наборе данных. в то же время,
Представляет взвешенный вклад сложных выборок и простых выборок в функцию общих потерь.
3.6.2 Regression Loss
На функцию потери L1 влияет размер входного изображения лейкоцитов.,Автор объединяет функцию потери L1 с функцией потери GIoU.,Для решения этой проблемы создана новая функция потерь регрессии. Это можно выразить формулой (10):
и
Представьте соответственно блок предсказания и целевой блок, спаренные с использованием венгерского алгоритма.
и
это два гиперпараметра,Представляет вес потерь GIoU и L1 соответственно.,
представляет собой функцию потерь GIoU, а функция потерь L1 представляет собой разницу абсолютных значений между целевым и прогнозируемым положениями блоков.
3.6.3 Ancillary Losses
В сравнении,Вспомогательные потери в основном используются для ускорения обучения Модели. В то время как исходная Модель использует только выходные данные последнего слоя кодировщика для прогнозирования цели,Но вспомогательные потери используют выходные данные каждого уровня кодера для прогнозирования. также,Функция потерь классификации рассчитывается для каждого уровня кодера, чтобы упростить обучение Модели. поэтому,окончательная потеряфункция Например, формула(8)показано,в Каждый уровень декодера прогнозируется как терминальный уровень Модели здесь.,«N» представляет количество слоев декодера.
4 Experiment
Dataset
Для проверки модели автор использовал три набора данных: набор данных обнаружения лейкоцитов (WBCDD), L1SCиBCCD. Публичный набор данных L1SC и BCCD используется для оценки способности модели к обобщению.

Напротив, набор данных WBCDD был специально создан для этого исследования.

На рисунке 5 показаны изображения лейкоцитов из каждого набора данных, а в таблицах 1 и 2 указано количество различных типов клеток в каждом наборе данных.
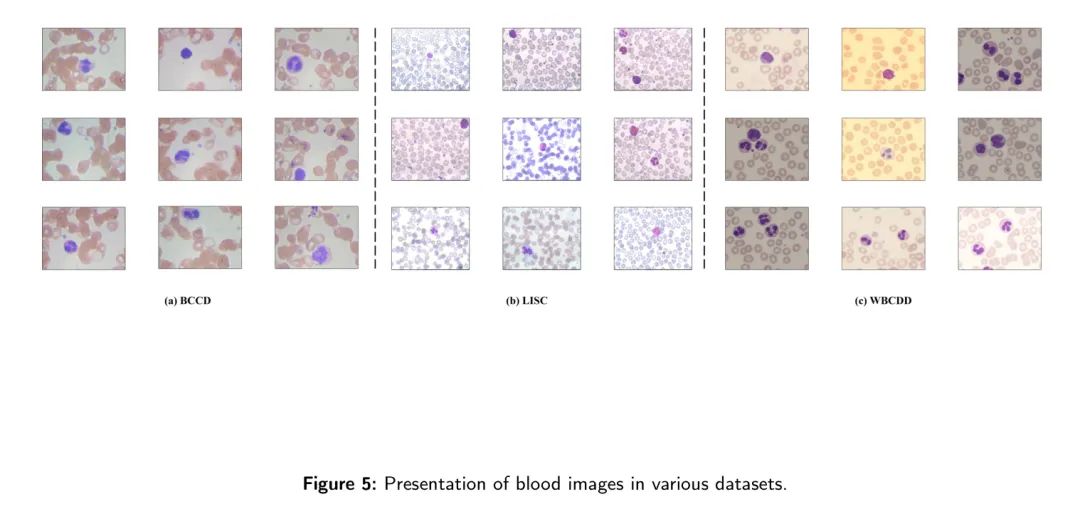
Авторы получили набор данных WBCDD из нескольких местных больниц. В лабораторных условиях врачи просматривают изображения клеток крови пациентов под микроскопом и используют программное обеспечение LabelMe для аннотирования ограничивающих лейкоцитов рамок для построения набора данных.
Набор данных включает 684 образца.,Охватывает пять различных типов лейкоцитов: нейтрофилы (NEU), эозинофилы (EOS), моноциты (MON), базофилы (BAS) и лимфоциты (LYM). перед экспериментом,Автор делит набор данных на обучающий набор и тестовый набор. Обучающий набор содержит 540 образцов изображений.,Тестовый набор содержит 144 образца.
Набор данных L1SC — это ранний набор данных по лейкоцитам, Зависит. от Получено из образцов периферической крови здоровых людей. Слайды были окрашены гизмографическим методом, а затем отображены на камере Sony модели SSCD50AP и Axioskope. Наблюдайте под 40-градусным микроскопом при 100-кратном увеличении. Профессиональный гематолог классифицировал 250 изображений клеток крови на пять более мелких категорий.
Однако,Зависит от Эта коллекция данных засекречена.,Автор использует инструмент LabelMe для маркировки под руководством врача.,Делаем его подходящим для авторской модели обнаружения целей. перед экспериментом,Автор делит этот набор данных на обучающий набор.,Включает 200 изображений.,Тестовый набор,Включает 50 изображений.
Набор данных BCCD представляет собой общедоступный набор данных аннотаций изображений лейкоцитов. Для подготовки этого набора данных использовался метод окрашивания Gismo-right.,Затем Оснащен100увеличиватьCCDЦветная камера для визуализации под стандартным световым микроскопом.。Эксперты по крови предоставили аннотации к этому сборнику.。Это содержит364Коллекция изображений разделена на три категории.:лейкоцит(WBCs)、Красные кровяные тельца (эритроциты) и тромбоциты.
Отличие от двух предыдущих эпизодов данных,BCCDданный набор включает аннотацию клеток крови и тромбоцитов. поэтому,В этих данных концентрированные клетки крови демонстрируют плотное распределение, в этом случае наблюдаются случаи целевой адгезии и окклюзии между различными клетками крови. до начала эксперимента,Набор данных разделен на обучающий набор из 292 изображений и тестовый набор из 72 изображений.
Развитие выявления лейкоцитов неотделимо от размера и качества коллекции. Зависит от В现有的公开可использовать的L1SCданные Набор собирался очень давно.,И существует проблема недостаточного размера набора данных.,Поэтому Модель не может хорошо обучаться на этом наборе данных. также,Существующий общедоступный набор аннотаций данных BCCD включает в себя не только клетки крови.,Также включает тромбоциты,В результате концентрированное распределение клеток крови становится очень плотным. Существует также целевая адгезия и окклюзия между различными клетками крови.,Серьезно влияет на реальную эффективность Модели.
поэтому,Автор собрал данные из местных больниц.,И сотрудничать с профессиональными врачами-лаборантами,Наблюдайте за изображениями крови пациента через микроскоп. Авторы также использовали инструмент LabelMe для маркировки целевых блоков лейкоцитов.,И в конечном итоге была создана коллекция данных WBCCD. в то же время,Автор решил сделать эту коллекцию данных доступной для других исследователей в этой области.,Способствовать дальнейшему развитию в области обнаружения лейкоцитов.
Experimental setup
Автор использовал язык Python и реализовал MFDS-DETRМодель в среде глубокого обучения PyTorch. Зависит от Из-за медленной скорости сходимости MFDS-DETRМодель на небольших наборах данных автор сначала опубликовал MS Он обучается на наборе данных COCO, а затем настраивается на наборе данных обнаружения целей лейкоцитов с использованием концепций трансферного обучения. Экспериментальная установка включает NVIDIA с памятью 24 ГБ. GeForce RTX 3090иUbuntu Операционная система 20.04 в качестве аппаратной конфигурации.
Модель обучается с размером пакета 100. Скорость обучения магистральной сети установлена на 0,00002.,Скорость обучения кодера и декодера составляет 0,0002 соответственно.,Скорость обучения HS-FPN установлена на 0,0003. Принять стратегию снижения скорости обучения StepLR,Уменьшайте скорость обучения до 0,1x от исходного значения каждые 40 пакетов. Настройка модели с использованием оптимизатора AdamW,параметр
,
, снижение веса установлено на 0,0001.
Comparison of other methods
Эффективность и способность к обобщению MFDS-DETR оценивали путем проведения сравнительных экспериментов на нескольких различных наборах для обнаружения лейкоцитов. В этом сравнительном эксперименте проводятся отдельные эксперименты над тремя наборами данных: WBCDD, L1SCиBCCD. Автор сравнивает Модель MFDS-DETR с традиционными Моделью в области обнаружения лейкоцитарных мишеней, такими как Faster R-CNN, SSD, RetinaNet, DETR, Deformable DETR, TE-YOLOFиYOLOv5-ALT.
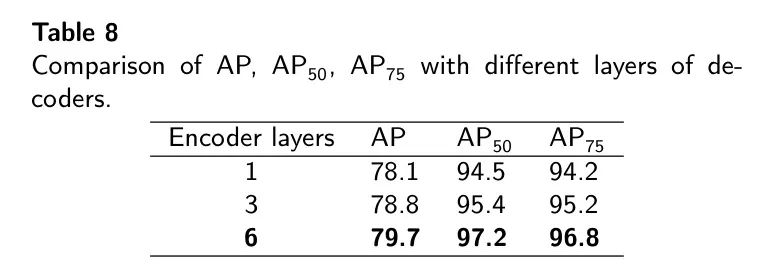
Результаты MFDS-DETRМодель на наборе для обнаружения лейкоцитов представлены в Таблице 3. Предлагаемая модель MFDS-DETR достигает AP 79,7% и 97,2% и в наборе данных WBCDD.
,соответственно. Эти результаты показывают,Используя многомасштабное и глобальное извлечение признаков.,Авторская Модель позволяет эффективно повысить точность обнаружения лейкоцитов.
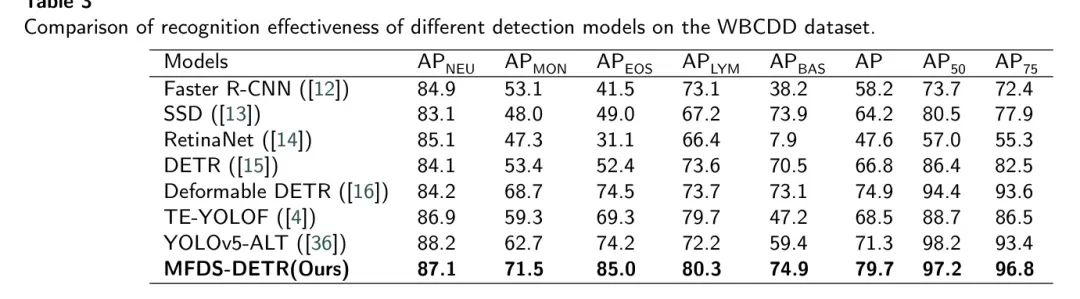
По сравнению с традиционной двухступенчатой моделью обнаружения целей (Faster R-CNN) по сравнению с,MFDS-DETRМодель в APи
Они увеличились на 21,5% и 23,5% соответственно. По сравнению с традиционной моделью одноэтапного обнаружения объектов (например, SSD) с использованием многоуровневого извлечения признаков, модель MFDS-DETR имеет лучшую производительность в APi.
Они увеличились на 15,5% и 16,7% соответственно. также,По сравнению с обнаружением объектов с использованием глобального извлечения признаков (например, DETR),MFDS-DETRМодель в APи
Они увеличились на 12,9% и 10,8% соответственно.
также,Значения AP для каждой категории лейкоцитов в Таблице 3 способствуют более глубокому анализу улучшений Модели. В эпизоде данных WBCDD,Стоит отметить, что,Значение AP эозинофилов и лимфоцитов значительно улучшилось по сравнению с базовой моделью (Деформируемая DETR),Увеличились на 10,5% и 6,6% соответственно. также,Среди современных современных методов определения лейкоцитов (TE-YOLOF и YOLOv5-ALT) выделяется авторский МФДС-ДЕТР.
Для дальнейшей оценки способности обобщения Модели,Автор провел тот же эксперимент на модели с набором данных LISCи BCCD. Как показано в Таблице 4 и Таблице 5.,МодельсуществоватьLISCданныенабор
и
Выдающаяся производительность.
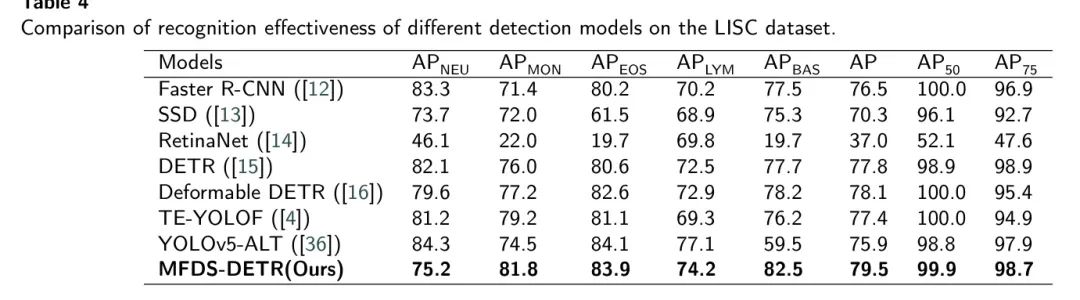
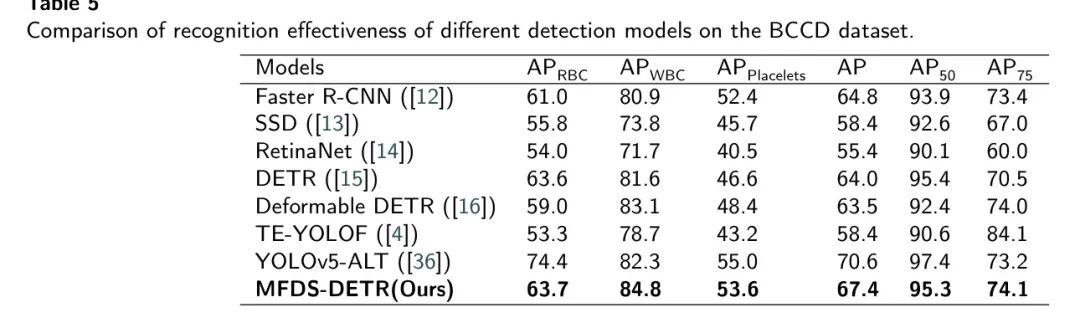
Несмотря на
Только быстрее, чем быстрее R-CNNи Baseline Модель (Деформируемая DETR) был на 0,1% ниже, но модель достигла оптимальных результатов при обнаружении всех типов клеток, кроме нейтрофилов. Это можно объяснить тем фактом, что нейтрофилы в наборе данных LISC сегментированы на ядросодержащие клетки с уникальными ядрами, в отличие от других типов лейкоцитов.
также,В эпизоде с данными BCCD,Авторская Модель превосходит другие Модели по всем показателям.,Это еще раз подтверждает, что предложенный автором метод обнаружения лейкоцитов MFDS-DETR позволяет более точно классифицировать и локализовать лейкоциты.
Ablation study
Эффективность тестирования лейкоцитов существенно зависит от размера и качества используемого набора. Сбор данных LISC, Зависит от было собрано ранее,Он ограничен по размеру и плохого качества. В сравнении,В аннотацию набора BCCDданные входят не только лейкоциты.,Также включает тромбоциты,Вызывает плотное распределение концентрированных клеток крови. Это приводит к частой адгезии и окклюзии мишеней между различными типами клеток крови в данной концентрации.
Ввиду этих особенностей,Авторы использовали эти два общедоступных набора данных только для оценки способности Модели к обобщению в различных условиях.,и решил не использовать их для экспериментов по абляции。Автор использует толькоWBCDDданные Коллекция для изучения различных компонентовиидентификацияпараметрпара конфигурацииMFDS-DETRМодель Влияние на производительность。
4.4.1 Comparison of different multi-level feature fusion strategies
Зависит от разницы в размерах лейкоцитов,Автор разработал модуль HS-FPN для выборочного объединения семантической информации высокого уровня с функциями низкого уровня.,Для достижения более точного местоположения и классификации лейкоцитов.
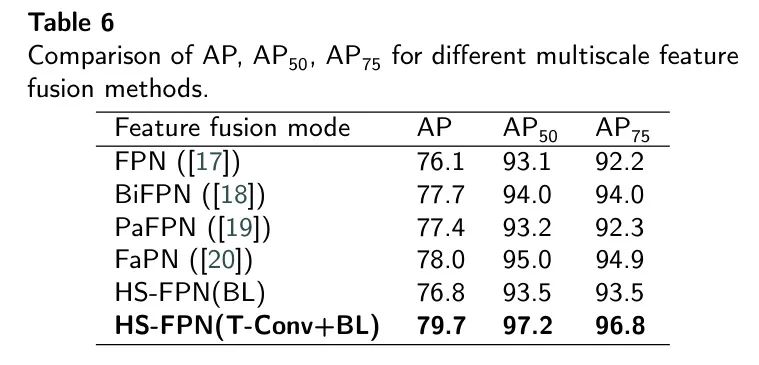
Чтобы продемонстрировать эффективность модуля HS-FPN при объединении многомасштабных функций, его сравнивают с другими методами многомасштабного объединения функций, такими как FPN, BiFPN, PaFPN, и Фа ПН. Как показано в таблице 6, HS-FPN превосходит FPN, улучшая производительность точки доступа еще на 3,6%.
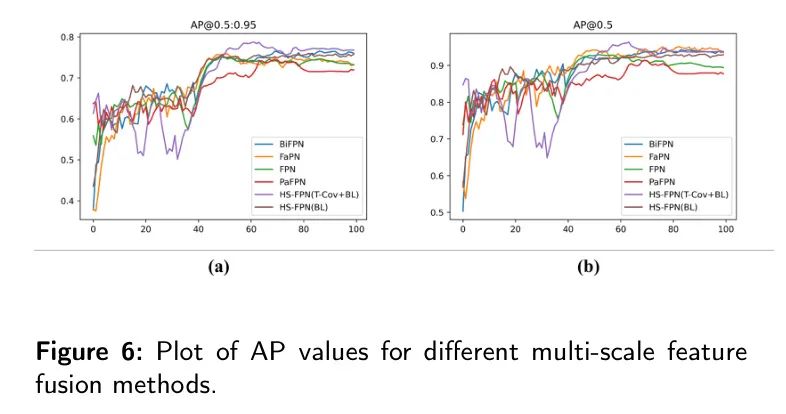
Кроме того, это также улучшает
и
4,1% и 4,6% соответственно. По сравнению с другой современной моделью FPN,HS-FPN показал превосходные результаты при обнаружении лейкоцитов. Эти результаты подтверждают, что HS-FPN эффективно отбирает семантическую информацию высокого уровня.,Используйте его как вес для фильтрации функций низкого уровня.,Это способствует более эффективному слиянию семантической информации высокого уровня и атрибутов низкого уровня в изображениях лейкоцитов. Кривые AP различных вариантов FPN показаны на рисунке 6. На рисунке 6(а) показана кривая AP.,На рисунке 6(b) конкретно показана кривая AP, когда порог IoU равен 0,5.
Таблица 6 поясняет,В модуле HS-FPN,Используя методы повышения дискретизации, такие как транспонированная свертка и билинейная интерполяция.,По сравнению с повышающей дискретизацией с использованием только билинейной интерполяции,Авторам удалось более эффективно расширить возможности обнаружения Модели.
4.4.2 The comparison between the number of encoder layers and decoder layers
В модели MFDS-DETR роль кодировщика имеет решающее значение для того, чтобы модель могла изучать глобальные функции. Чтобы подчеркнуть важность глобального обучения функциям, авторы изучили влияние изменения количества слоев кодера.
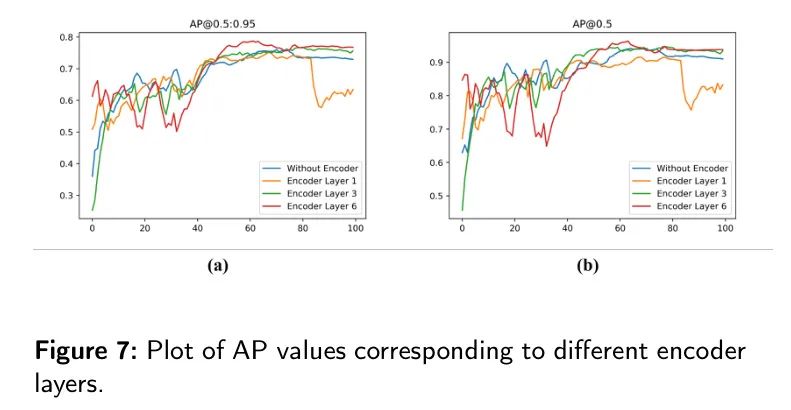
Как показано в Таблице 7, удаление энкодера приведет к уменьшению AP на 2,8% соответственно.
и
упал соответственно3.2%и3.0%。Используйте одинкодерслой не улучшает производительность,Вместо этого это привело к небольшому ухудшению производительности.。Это указывает на единственнуюкодерслоев недостаточно для точного извлечения глобальных функций из изображений。
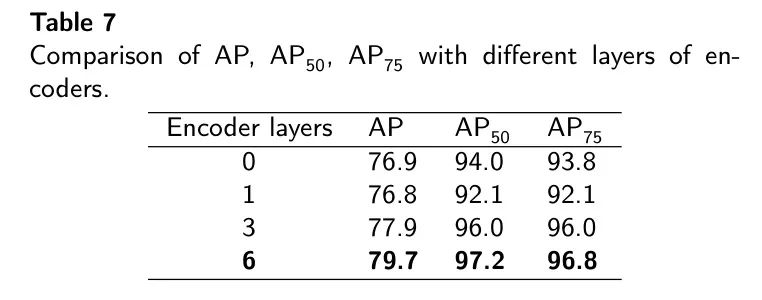
Количество слоев кодера пропорционально AP, что подчеркивает фундаментальную роль кодеров в обработке лейкоцитов и их пространственной конфигурации. Этот эксперимент убедительно подчеркивает важность изучения глобальных особенностей. На рисунке 7(a) показана кривая AP для разных номеров уровней кодера, а на рисунке 7(b) показана кривая AP, когда порог IoU равен 0,5.
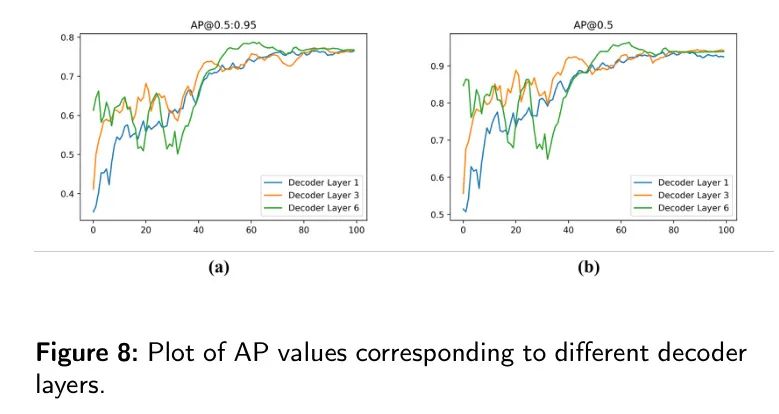
В декодере MFDS-DETR,Моделирование взаимодействия между различными представлениями функций обнаружения играет ключевую роль. В этом исследовании,Авторы скорректировали количество слоев декодера, чтобы подтвердить важность декодера. Как показано в таблице 8 и на рисунке 8.,Уменьшение количества слоев декодера приводит к последовательному снижению производительности обнаружения. Конкретно,Когда автор использует один слой кодера в качестве прогнозируемого результата Модели,AP,
и
Они упали на 1,6%, 2,7% и 2,6% соответственно.
4.4.3 Comparison of different position coding methods
В моделях MFDS-DETR авторы столкнулись с различными позиционными кодировками: выходное кодирование (целевое запрос), кодирование масштаба и кодирование пространственного положения. Чтобы улучшить глобальное изучение функций изображений,Изображения должны быть сериализованы. Затем,Кодирование пространственного положения добавляется к каждому блоку последовательности.,для представления положения сериализованного изображения в исходном изображении.
Отличается от DETRМодель,Кодирование пространственного положения в MFDS-DETR добавлено только в кодер.,Из-за использования деформируемого внимания,И точка ссылки Зависит от вывода в декодере в порядке,Поэтому нет необходимости добавлять ключевые значения в кодировку пространственного местоположения. Однако,Для многомасштабных карт объектов,Кодирование пространственного местоположения одинаково в разных масштабах.,Невозможно определить местоположение. поэтому,Чтобы различать входы разных масштабов,MFDS-DETR представляет кодирование положения шкалы. Выходное кодирование является необходимым кодированием положения для вывода предсказанного положения кадра.
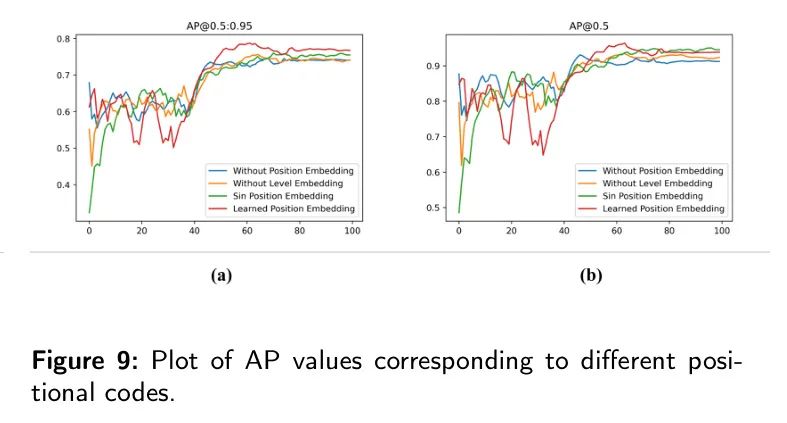
Кодирование пространственного положения в основном использует два метода: кодирование изученного положения (кодирование изученного положения). PE) и фиксированная кодировка (Sin ПЭ). Результаты экспериментов подтверждают необходимость масштабного кодирования и кодирования пространственного положения.

Как показано в Таблице 9,Отсутствие кодирования пространственного положения и масштабного кодирования привело к снижению AP на 3,1% и 3,4% соответственно. также,кодирование фиксированной позициисуществоватькодерболее эффективно, чем изучение позиционного кодирования。картина9Показывает различные позиционные кодировкиAPизгиб。
4.4.4 Comparison of joint loss functions
Подчеркнуть важность отдельных компонентов Модели в функции совместных потерь.,Авторы провели эксперименты по абляции с различными комбинациями перестановок потерь. При совместной потере функции MFDS-DETR,Используются три типа потерь: потери классификации, потери регрессии и вспомогательные потери. Потери регрессии включают в себя функцию потери ограничивающего прямоугольника L1 и функцию потери GIOU. Функция потери классификации имеет решающее значение для обучения модели.,Нельзя опустить.
поэтому,В этом исследовании,Автор обучил Модель без потери расстояния в ограничивающей рамке и Модель без потери GIoU. также,Определить значимость вспомогательных потерь.,Авторы обучили Модель, которая не учитывала эту потерю.
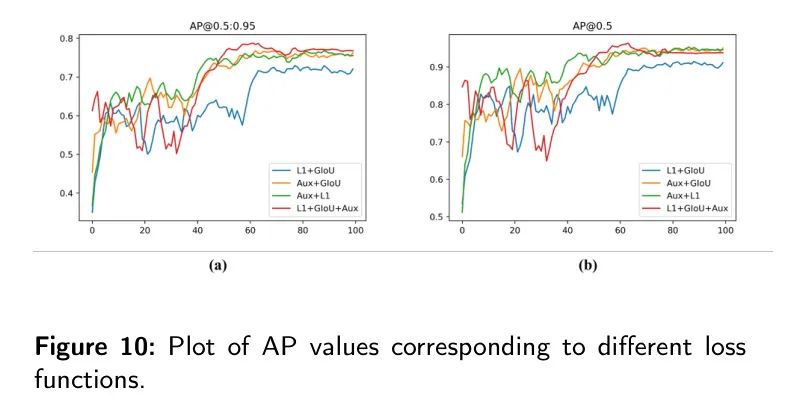
Как показано на рисунке 10 и в таблице 10.,Потеря GIoU более важна, чем потеря L1. Отсутствие потери L1 привело к снижению AP на 1,4%.,Отсутствие потерь GIoU привело к снижению AP на 1,9%. также,Эксперименты показывают,По сравнению с моделью, которая не включает вспомогательные потери,АП упал на 4,5%,Важность этой функции потерь при обучении модели дополнительно подтверждается.

Model visualization analysis
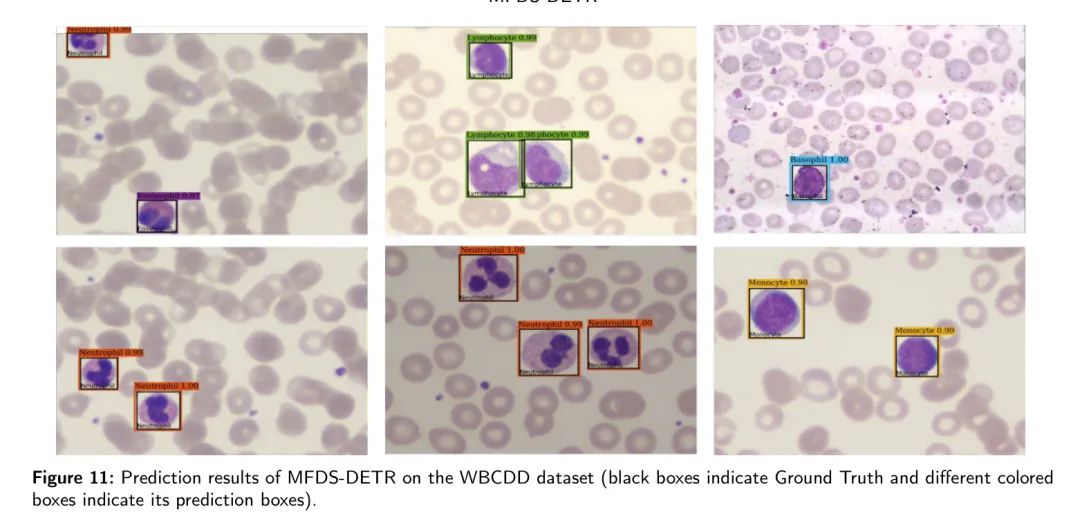
Чтобы более наглядно проиллюстрировать прогнозирующий эффект Модели,На рисунке 11 показаны прогнозируемые категория и положение Модели.,И исходная категория изображения и целевой блок из набора данных WBCDD. Настоящий черный ящик,Остальные поля представляют результаты и уровни достоверности, предсказанные автором MFDS-DETRModel. Зеленые, оранжевые, фиолетовые, синие и желтые прямоугольники представляют лимфоциты, нейтрофилы, гранулоциты, эозинофилы и моноциты соответственно. Это видно из рисунка,Прогнозы модели автора получили высокую достоверность и точное предсказание местоположения для всех пяти изображений лейкоцитов.,Это доказывает его замечательную эффективность и важную прикладную ценность.
5 Conclusion
в этой статье,Автор предложил MFDS-DETRМодель,подробно представил своюсетьструктураисовместная потеряфункция。сетьструктура包括 Backbone Сеть, иерархическая масштабная пирамидальная сеть (HS-FPN), кодер и декодер. Backbone сеть Основная функция отлейкоциткартина Извлечение многомасштабных объектов из изображений,Это обеспечивает последующее многомасштабное объединение функций. HS-FPN настроен с учетом уникальных характеристик лейкоцитов.,Использование модуля внимания канала,Карты объектов высокого уровня используются в качестве весов для фильтрации объектов низкого уровня. Эти отфильтрованные функции объединены с расширенными функциями.,тем самым обогащая низкоуровневые функции,и вводит важную семантическую информацию. Кодер использует деформируемое самовнимание для извлечения глобальных особенностей изображения.,Декодер использует само-внимание и перекрестно-деформируемое внимание, чтобы узнать локализацию цели.
также,Совместные потери, разработанные для этой Модели, включают потери классификации, потери регрессии и вспомогательные потери. Модель Оптимизация посредством классификации и потери регрессии,Основная цель – определить наиболее подходящее значение соответствия. Вспомогательные потери помогают ускорить сходимость Модели.,Путем вычисления потерь классификации и регрессии выходного сигнала декодера на каждом уровне.
В последующем сравнительном экспериментальном разделе,Авторы сравнили специально разработанную авторскую модель MFDS-DETR с другой усовершенствованной моделью обнаружения лейкоцитов.,Используются три набора данных.,Это WBCDD, LISCиALL-IDB.,Доказать эффективность и обобщающую способность автора Модель. также,Автор провел эксперименты по абляции на наборе данных WBCDD.,Определить важность ключевых компонентов в модели.,Такие как позиционное кодирование, кодер, декодер и функция совместной потери. наконец,Автор использует визуальный анализ эффекта и Модель для дальнейшего подтверждения эффективности авторской Модели.
Достижения в области обнаружения лейкоцитов были ограничены размером и качеством доступных коллекций. Коллекция данных LISC является давним общедоступным ресурсом.,Но его масштаб меньше. также,BCCDданный набор не только маркирует различные клетки крови,Также включает тромбоциты,в результате получился плотный и сложный набор данных,Он характеризуется адгезией цели, окклюзией и плохим качеством изображения. признать эти ограничения,Автор решил предоставить коллекцию данных WBCCD исследователям в этой области.,Ожидайте, что этот высококачественный сбор данных будет способствовать развитию области тестирования лейкоцитов.
Исследования автора внесли важный вклад в область обнаружения лейкоцитов.,Но автор должен признать свои ограничения. Чтобы повысить надежность и способность к обобщению MFDS-DETRМодель.,Будущие исследования должны быть направлены на сбор более крупных и разнообразных наборов данных для дальнейшей проверки. также,Учитывая быстрое развитие технологий медицинской визуализации и методов глубокого обучения,,Автору необходимо постоянно совершенствоваться и адаптироваться к Авторской Модели.,сохранить свою актуальность и практичность в практическом применении.
ссылка
[1].Accurate Leukocyte Detection Based on Deformable-DETR and Multi-Level Feature Fusion for Aiding Diagnosis of Blood Diseases.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
