Методы обработки данных – 7 операций уменьшения размерности данных! !
Уменьшение размерности данных
Уменьшение размерности Данные — это метод, который преобразует данные высокой размерности в данные низкой размерности, пытаясь сохранить при этом важную информацию исходных данных. Это полезно для обработки крупномасштабных наборов данных, поскольку помогает снизить потребность в вычислительных ресурсах и повышает эффективность алгоритма. Вот некоторые часто используемые Уменьшение размерности методы данных, а также их принцип и применение.
1. Анализ главных компонент (PCA)
принцип:PCAПреобразование оригиналаданные Преобразование в набор линейно некоррелированных компонентов,Часто называемые главными компонентами. Он распознает закономерности в данных,чтобы узнатьданныеизМаксимальная дисперсиянаправление,И проецируйте данные в эти направления.
приложение:PCAОбычно используется для уменьшенияданные集из维度,При этом вариативность данных максимально сохраняется. Он также широко используется при предварительном просмотре многомерных данных.
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# Загрузка выпусков данных
data = load_iris()
X = data.data
# Применить PCA
pca = PCA(n_components=2) # до 2 измерений
X_pca = pca.fit_transform(X)
# Визуализациярезультат
plt.scatter(X_pca[:, 0], X_pca[:, 1])
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Iris Dataset')
plt.show()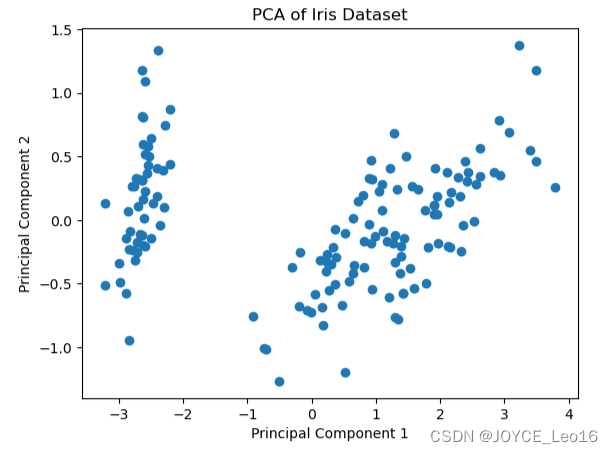
2. Линейный дискриминантный анализ (ЛДА).
принцип:LDAэто контролируемый алгоритм обучения,Его цель — найти подпространство признаков, которое максимизирует межклассовые различия и минимизирует внутриклассовые различия. Теги категорий для LDA, особое внимание уделяется наданным,После создания проекции данных,Похожие точки данных расположены максимально близко,точки данных разных категорий расположены как можно дальше друг от друга.
приложение:LDAОбычно используется для улучшения классификации Модельиз性能。Путем максимизации межклассовых различий и минимизации внутриклассовых различий,LDA может повысить точность алгоритмов классификации. Он также широко используется в задачах распознавания образов.,Например, распознавание лиц,LDA можно использовать для извлечения черт лица. (LDA используется для отображения распределения различных категорий данных после уменьшения размерности).
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
# LDA также является контролируемым алгоритмом обучения, требующим меток категорий.
y = data.target
# Применить LDA
lda = LDA(n_components=2) # до 2 измерений
X_lda = lda.fit_transform(X,y)
# Визуализациярезультат
plt.scatter(X_lda[:, 0], X_lda[:, 1], c=y)
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.title('LDA of Iris Dataset')
plt.show()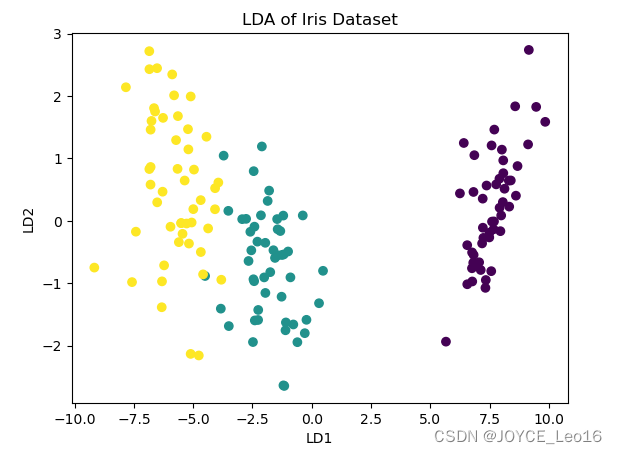
3. t-распределенное стохастическое встраивание соседей (t-SNE)
принцип:t-SNEЭто какое-то не-уменьшение линейной размерноститехнология,Особенно подходит для преобразованияданныевстроенный в двух- или трехмерное пространство Визуализация。оно проходитРаспределение вероятностей, преобразованное в сходствосохранить местную структуру,Сближайте похожие объекты в низкомерном пространстве.
приложение:t-SNEОбычно используется в больших размерах.данныеиз Визуализация。Поскольку он поддерживаетданные点间из局部关系,Поэтому он особенно подходит для исследовательского анализа данных.,Для выявления концентрированных шаблонов и групп многомерных данных. Это особенно распространено в биоинформатике и анализе социальных сетей.
from sklearn.manifold import TSNE
# Применить t-SNE
tsne = TSNE(n_components=2,random_state=0)
X_tsne = tsne.fit_transform(X)
# Визуализациярезультат
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y)
plt.xlabel('t-SNE feature 1')
plt.ylabel('t-SNE feature 2')
plt.title('t-SNE of Iris Dataset')
plt.show()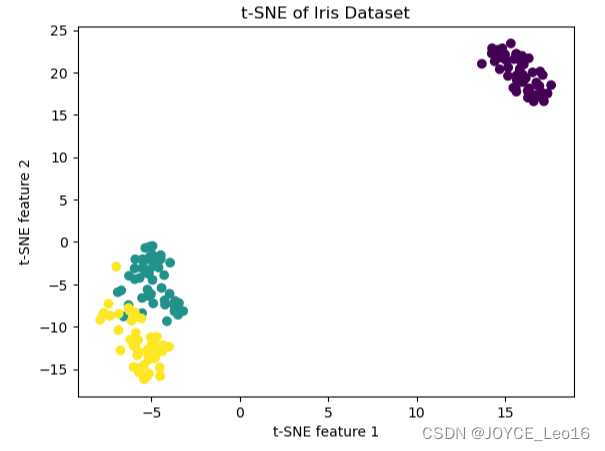
4. Локальное линейное вложение (ЛЛЭ).
принцип:LLEЭто какое-то не-уменьшение линейной Размерности Технология. Его основная идея заключается в сохранении локальных характеристик точек данных. LLE сначала находит лучшее линейное представление в окрестности каждой точки, а затем восстанавливает эти линейные отношения в низкоразмерном пространстве. Этот метод особенно подходит для тех территорий, где важна структура локальной территории.
приложение:LLEОбычно используется дляданные Визуализацияи исследоватьданныеанализировать,Особенно когда данные имеют нелинейную структуру. Он широко используется в обработке изображений, распознавании речи и биоинформатике.,За обнаружение внутренних структур и закономерностей в данных.
from sklearn.manifold import LocallyLinearEmbedding
# Примените уменьшение размерности LLE
lle = LocallyLinearEmbedding(n_components=2)
X_lle = lle.fit_transform(X)
# Визуализациярезультат
plt.scatter(X_lle[:, 0], X_lle[:, 1], c=digits.target, cmap='Spectral', alpha=0.5)
plt.colorbar()
plt.title("LLE on the Digits Dataset")
plt.show()
5. Многомерное масштабирование (MDS)
принцип:MDS是一种用于降维изтехнология,Предполагается, что относительные положения точек данных в низкомерном пространстве максимально отражают их расстояние в исходном многомерном пространстве. MDS ищет низкоразмерное представление посредством процесса оптимизации.,Сделайте расстояния между точками в этом представлении как можно ближе к расстояниям в исходных данных.
приложение:MDSОбычно используетсяданные Визуализация,Особенно, когда нас волнует расстояние или сходство между точками данных. Это особенно полезно в психологии, исследованиях рынка и социологии.,Используется для анализа и предварительного просмотра данных о расстоянии или сходстве.,Например, в семантическом анализе или исследовании предпочтений пользователей.
from sklearn.manifold import MDS
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
# Загрузка выпусков данных
digits = load_digits()
X = digits.data
# Применить уменьшение размерности MDS
mds = MDS(n_components=2)
X_mds = mds.fit_transform(X)
# Визуализациярезультат
plt.scatter(X_mds[:, 0], X_mds[:, 1], c=digits.target, cmap='Spectral', alpha=0.5)
plt.colorbar()
plt.title("MDS on the Digits Dataset")
plt.show()
6. Разложение по сингулярным значениям (SVD).
принцип:SVD是一种将矩阵分解为三个矩阵из乘积изметод。это будет оригинальноданные Разложение матрицы на собственные значения и собственные векторы,Способен раскрыть основную структуру данных.
приложение:SVDОчень полезно в рекомендательных системах.,Особенно при работе с большими разреженными матрицами. Извлекая наиболее важные функции из матрицы,SVD помогает прогнозировать рейтинги пользователей или предпочтения товаров. также,Он также используется в области цифровой обработки сигналов и сжатия изображений.
import numpy as np
from scipy.linalg import svd
import matplotlib.pyplot as plt
# гипотеза A это матрица
U, s, VT = svd(A)
# Выберите первые k сингулярных значений для аппроксимации исходной матрицы
k = 2
A_approx = np.dot(U[:, :k], np.dot(np.diag(s[:k]), VT[:k, :]))
# может быть A_approx Предварительный просмотр или для дальнейшего анализа7. Автоэнкодеры
принцип:Autoencoders是一种基于神经网络из非уменьшение линейной размерноститехнология。оно проходит训练网络学习一个低维表示(кодирование),Затем восстановите вывод,как можно ближе к вводу данных.
приложение:Autoencoders广泛应用于无监督学习из特征提取иданныесжатие。В области глубокого обучения,Они используются для изучения эффективных представлений данных.,Помогает улучшить задачи реконструкции изображения и шумоподавления. Также возможно генерировать новые экземпляры данных.,Например, его применение в генеративно-состязательных сетях (GAN).
from keras.layers import Input, Dense
from keras.models import Model
# Установить входные размеры
input_dim = 784 # Например, для 28x28 изображение, которое будет 784
encoding_dim = 32 # Размеры пространства кодирования
# Определите слой кодировщика
input_layer = Input(shape=(input_dim,))
encoded = Dense(encoding_dim, activation='relu')(input_layer)
# Определить уровень декодера
decoded = Dense(input_dim, activation='sigmoid')(encoded)
# Построение модели автоэнкодера
autoencoder = Model(input_layer, decoded)
# Создайте модель кодировщика
encoder = Model(input_layer, encoded)
# Построение модели декодера
encoded_input = Input(shape=(encoding_dim,))
decoder_layer = autoencoder.layers[-1] # Последний слой действует как декодер
decoder = Model(encoded_input, decoder_layer(encoded_input))
# Скомпилируйте автоэнкодер
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# Обучение автоэнкодера
# гипотеза x_train Да, введите данные
# autoencoder.fit(x_train, x_train, epochs=50, batch_size=256, shuffle=True)
# Используйте кодер и декодер для генерации закодированных и декодированных данных.
# encoded_imgs = encoder.predict(x_test)
# decoded_imgs = decoder.predict(encoded_imgs)Подвести итог
Уменьшение размерности данныхтехнология广泛被划分为两类:уменьшение линейной размерностиметод与非уменьшение линейной размерностиметод。线性метод,Например Анализ главных компонентов (PCA)и Линейный дискриминантный анализ (LDA), обычно подходит для сценариев, в которых данные имеют линейное распределение. Напротив, нелинейные методы, такие как t-распределенное стохастическое встраивание соседей (t-SNE), многомерное масштабирование (MDS) и локальное линейное внедрение (LLE) больше подходят для обработки наборов данных со сложными характеристиками распределения.
Выбор подходящего метода уменьшения размерности зависит от свойств данных и конкретных потребностей целей анализа. Применение соответствующих стратегий уменьшения размерности в соответствующих ситуациях может значительно повысить эффективность процесса обработки данных и общую производительность алгоритма.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
