Механизм внимания «подключи и работай» | Внимание ResNet50+DSA все еще может испытывать трудности! ! !

Сверточные нейронные сети (CNN) превосходно справляются с распознаванием локальных пространственных образов. Для многих задач машинного зрения, таких как распознавание и сегментация объектов, важная информация также существует за пределами ядра CNN. Однако из-за ограниченного рецептивного поля CNN они чувствуют себя неспособными уловить эту важную информацию. Механизм самообслуживания может улучшить способность модели получать глобальную информацию, но он также увеличивает вычислительные затраты. Авторы предлагают быстрый и простой полностью сверточный метод DAS, который помогает сосредоточить внимание на важной информации. В этом методе используются деформируемые свертки для представления местоположения соответствующих областей изображения и отделимые свертки для достижения эффективности. DAS можно подключить к существующим CNN и использовать механизмы внимания каналов для распространения соответствующей информации. По сравнению с вычислительной сложностью O(n^2), необходимой для внимания в стиле Transformer, вычислительная сложность DAS составляет O(n). Авторы утверждают, что способность DAS концентрировать внимание на соответствующих функциях может привести к повышению производительности при добавлении к популярным CNN (сверточным нейронным сетям) для классификации изображений и обнаружения объектов. Например, DAS хорошо работает на Stanford Dogs (улучшение на 4,47%), ImageNet (улучшение на 1,91%) и COCO AP (улучшение на 3,3%) по сравнению с исходной моделью, основанной на магистральной сети ResNet50. Этот подход превосходит другие механизмы внимания CNN при использовании аналогичных или меньшего количества FLOP. Авторский код будет опубликован публично.
1 Introduction
Сверточные нейронные сети (CNN) структурно разработаны для использования локальных пространственных иерархий путем применения сверточных фильтров, реализованных сверточными ядрами. Хотя это делает их одновременно эффективными и действенными при решении задач, связанных с локальными пространственными структурами, их присущая конструкция ограничивает их восприимчивое поле, потенциально препятствуя полной интеграции соответствующей информации, которая находится за пределами границ ядра.
Visual Transformer (ViT) позволяет фиксировать глобальные зависимости и контекстное понимание изображений и демонстрирует повышенную производительность во многих задачах компьютерного зрения. ViT разлагает изображение на серию сплющенных фрагментов и впоследствии отображает их в последовательность векторов внедрения кодера Transformer.
Этот подход, основанный на исправлениях, принят из-за присущего ему механизма внимания.
Сложность вычислений связана с количеством входных векторов. ViTs эффективно уменьшает количество входных фрагментов за счет преобразования изображений в более толстые фрагменты, т.е.
. Однако при концентрации внимания на уровне пикселей все еще существуют вычислительные проблемы. Более того, ViT обычно требуют больших размеров моделей, более высоких требований к памяти и обширного предварительного обучения по сравнению с CNN, а их вычислительные требования ограничивают их полезность во встроенных приложениях реального времени.
Хотя продолжаются попытки контролировать квадратичную сложность Трансформера для обеспечения плотного внимания к длинным последовательностям с использованием сверток, было проведено множество исследований, напрямую интегрирующих механизмы самообслуживания в CNN для достижения плотного внимания к важным функциям. Основной мотивацией данной работы является последнее.
Механизм внимания в CNN можно в общих чертах разделить на канальное внимание, пространственное внимание и внимание смешанной области. Эти методы предлагают стратегии, включающие внимание, специфичное для вычислений, например, использование таких методов, как агрегирование, подвыборка, объединение и т. Д., Что, в свою очередь, затрудняет обеспечение плотного внимания.
Например, в большинстве статей, посвященных работе составных модулей внимания, перед расчетом весов внимания используются операции объединения средних значений на картах функций, учитывающих внимание. Популярной стратегией является вычисление веса для каждого канала [15, 33]. Это может привести к тому, что важная информация о пространственном контексте будет упущена из виду.
Были предложены некоторые методы, расширяющие вышеуказанные методы путем смешивания канального и пространственного внимания для получения более надежных модулей внимания. Другой метод расширения использует глобальное объединение двух вращений входных данных и исходного тензора в сочетании с глобальным объединением для объединения трехмерной информации из объектов.
Однако они по-прежнему сталкиваются с проблемой эффективного привлечения внимания к важным особенностям. Они рассматривают канал и пространственное внимание как независимые процессы, поэтому не учитывают всесторонне информацию в функциях, что может привести к потенциальной потере информации.
Многообещающий подход к усилению внимания к соответствующим областям изображения — использование деформированной сетки вместо обычной сетки, используемой в стандартных сверточных фильтрах. DCN v2 продемонстрировала улучшенные возможности фокусировки на соответствующих областях изображения.
Эти методы [35, 39] использовались для обеспечения искаженного внимания для задач мелкозернистой семантической сегментации и классификации изображений в ViT путем поиска лучших ключей и запросов в ViT. Однако основной интерес авторов заключается в обеспечении механизма внимания непосредственно в CNN, минимизируя при этом изменения в исходной сети или ее обучении. Поэтому в оставшейся части статьи основное внимание будет уделено методам сверточного внимания.
Подход авторов частично вдохновлен успехом DCN, а частично — доминированием архитектуры Raft в различных задачах машинного зрения, таких как оптический поток и стереозрение, например, распространение изображений/карт объектов с использованием рекурсивных блоков GRU (GRU Perform). .
Основной вклад автора — эффективный механизм контролируемого внимания DAS, который может фокусировать и усиливать внимание к важным областям изображения. Его можно очень легко интегрировать в любую существующую CNN для повышения производительности CNN с минимальными дополнительными FLOP и, самое главное, без изменения структуры Backbone.
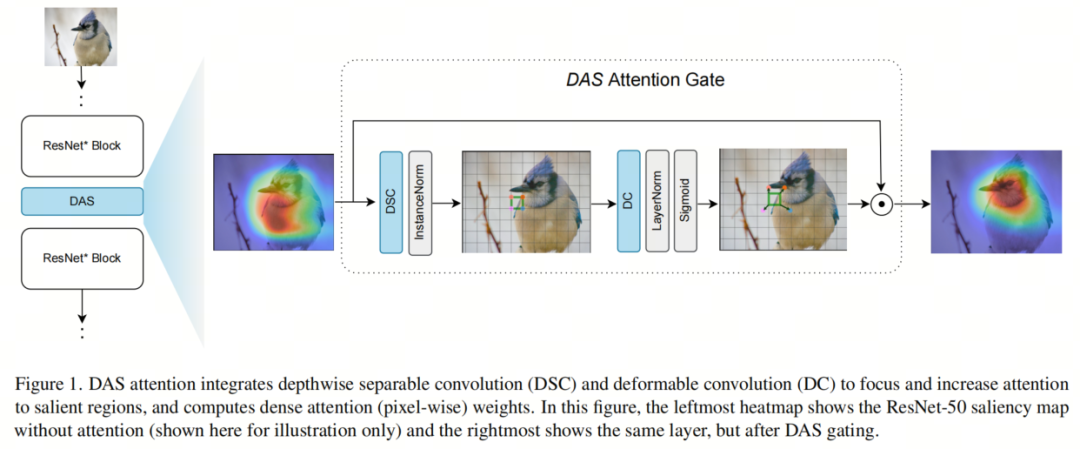
Ворота внимания авторов сочетают в себе контекст, обеспечиваемый функциями слоя, с силой деформированных извилин, позволяющих элегантно повысить внимание к важным функциям (см. Рисунок 1). DAS добавляет только один гиперпараметр и его легко настроить.
Авторы демонстрируют методы добавления авторского стробирования к стандартным CNN, таким как ResNet и MobileNetV2, и посредством обширных экспериментальных результатов демонстрируют повышение производительности в различных задачах. Чтобы поддержать утверждение авторов о том, что CNN с контролем внимания автора действительно фокусируют и увеличивают внимание к функциям, связанным с задачей, мы представляем тепловые карты градиентной свертки, которые выделяют важные пиксели. Авторы также определяют и рассчитывают простую метрику под названием «оценка обнаружения существенных признаков» (sfd_), которая используется для количественного сравнения эффективности нашего контроля внимания.
2 Related Work
Механизм внимания CNN был разработан для устранения избыточной информации, проходящей через нейронную сеть, при решении проблемы вычислительной нагрузки. Цель состоит в том, чтобы сосредоточить внимание на существенных функциях и уменьшить/отключить внимание на ненужных функциях.
Направьте внимание. Сеть сжатия и возбуждения (SENet) представляет эффективный механизм внимания к каналам с использованием глобального пула и полностью связанных уровней. SENet вычисляет вес внимания для каждого канала, что приводит к значительному повышению производительности по сравнению с базовыми архитектурами. Между тем, метод глобальной сети пулов второго порядка (GSoP-Net) использует пул второго порядка для расчета вектора веса внимания. Efficient Channel Attention (ECA-Net) [33] вычисляет веса внимания для каждого канала посредством глобального среднего пула и одномерной свертки. Вышеупомянутые методы внимания к каналу игнорируют большой объем информации о пространственном контексте.
Пространственное внимание. GE-Net пространственно кодирует информацию посредством глубокой свертки, а затем интегрирует входную и закодированную информацию в последующие уровни.
Сеть двойного внимания. Метод сети двойного внимания (A2-Nets) вводит новую функцию связи для нелокальных (NL) блоков, последовательно используя два последовательных блока внимания. Метод глобальной контекстной сети (GC-Net) объединяет NL-блоки и SE-блоки, используя сложные операции на основе перестановок для фиксации долгосрочных зависимостей.
Перекрестные пути включают контекстную информацию. CC-Net включает контекстную информацию о пикселях на траекториях пересечения. Обрабатывайте подфункции параллельно. SA-Net использует разделение каналов для параллельной обработки дополнительных функций.
Среди всех упомянутых выше методов пространственного внимания, хотя цель состоит в том, чтобы уловить долгосрочные зависимости, вычислительные затраты могут быть выше, как увидели авторы по результатам экспериментов.
Канально-пространственное внимание. Модуль сверточного блока внимания (CBAM) и модуль внимания узким местам (BAM) разделяют канальное и пространственное внимание и объединяют их на последнем этапе для достижения более высокой производительности, чем SENet. Модуль внимания CBAM включает в себя многоуровневый персептрон (MLP) и сверточные слои, используя объединение глобального среднего и максимального пула. В SPNet [13] был представлен метод группирования, называемый групповым пулом, в котором используется длинное и узкое ядро для эффективного сбора обширных контекстных деталей для задач, связанных с прогнозированием на уровне пикселей.
GALA также находит локальную и глобальную информацию отдельно, используя два 2D-тензора и интегрируя их для привлечения внимания к пространству каналов. Тройное внимание [26] повышает производительность за счет замены входных тензоров и объединения в пул для учета межпространственных взаимодействий.
DRA-Net также использует два независимых уровня FC для сбора данных о каналах и пространственных отношениях. OFDet использует все три типа внимания (канальное, пространственное и канально-пространственное внимание) одновременно.
Во всех вышеперечисленных подходах эти отдельно обрабатываемые проблемы необходимо тщательно объединить, чтобы обеспечить более полное представление зависимостей функций. Обеспечение концентрации внимания также затруднено из-за использования усреднения и/или объединения. Кроме того, вычислительные затраты высоки.
Что касается механизма внимания в CNN, опрос разделил его на 6 категорий:
- канал внимания
- пространственное внимание
- время внимание
- разветвленное внимание
- канал спространственное внимание
- пространство ивремя внимание
Предложенный авторами модуль внимания не разделяет внимание, как описанные выше методы, а рассматривает всю функцию одновременно и очень простым способом возвращает веса внимания на уровне пикселей. Таким образом, существующие методы еще не полностью охватывают комплексный сбор канальной, пространственной и корреляционной информации, что имеет решающее значение для понимания контекстной информации. В большинстве случаев проблемой также может быть повышенное внимание и/или вычислительные затраты.
Напротив, шлюзование внимания, предложенное авторами, сочетает в себе преимущества отделимой по глубине свертки и деформированной свертки, чтобы комплексно обеспечить внимание на уровне пикселей. Это позволяет модели авторов эффективно фокусировать внимание на соответствующей информации, сохраняя при этом архитектурную простоту CNN.
3 Methodology
В этом разделе автор предлагает механизм внимания под названием DAS, позволяющий повысить эффективность вычислений CNN и обеспечить сосредоточенное внимание на соответствующей информации. Авторы иллюстрируют их использование, используя авторский шлюз внимания DAS после пропуска соединения для каждого основного блока моделей ResNet и MobileNetV2. Ключевые шаги и компоненты подхода авторов описаны ниже.
Bottleneck Layer
Авторы используют операцию свертки с разделением по глубине в качестве узкого слоя. Эта операция уменьшает количество каналов в карте объектов, преобразуя их из
канал уменьшен до
канал, где
. Этот параметр уменьшения размера
выбран для обеспечения баланса между эффективностью и точностью вычислений.
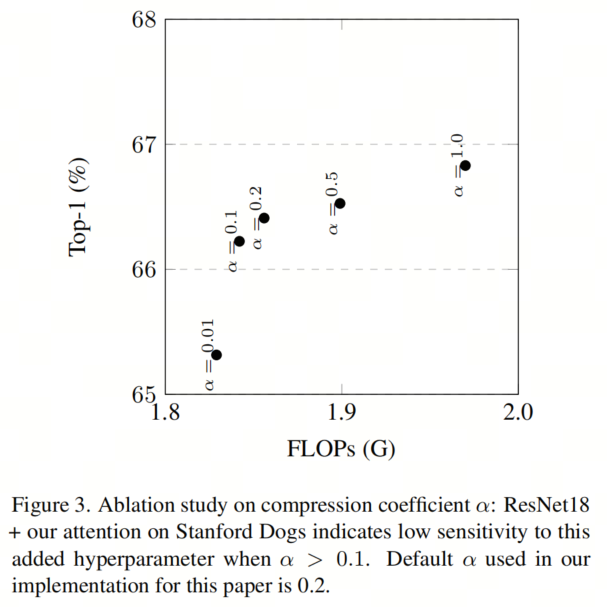
Путем экспериментов по исследованию абляции, представленных автором, автор определил
Оптимальное значение (см. рисунок 3). Это также показывает, что единственный гиперпараметр, добавленный в модель авторов, — это
для
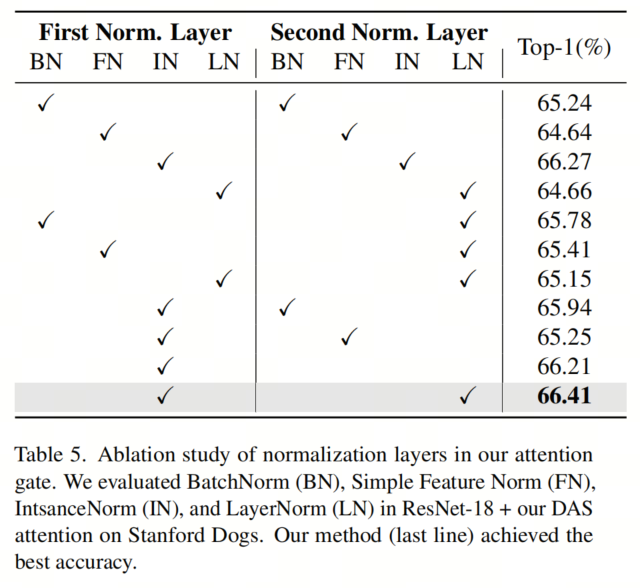
Это не чувствительно. После слоя узкого места авторы применяют слой нормализации, в частности, нормализацию экземпляра, за которой следует нелинейная активация GELU. Эти операции усиливают выразительную силу черт и способствуют эффективности механизма внимания.
Выбор нормализации экземпляра и слоя подтверждается экспериментальными результатами в таблице 5. Уравнение 1 показывает процесс сжатия, где X представляет входной объект,
Представляет отделимую по глубине свертку.
В Таблице 5 авторы демонстрируют важность использования InstanceNorm в качестве метода нормализации перед деформируемыми операциями свертки. Интуитивно понятно, что процесс нормализации экземпляра позволяет удалять из изображений специфичную для экземпляра информацию о контрасте, тем самым повышая надежность деформированной модели сверточного внимания во время обучения.
Deformable Attention Gate
Сжатые данные объекта, полученные на предыдущем шаге (уравнение 1), представляют контекст объекта и затем передаются через динамическую сетку, представленную в [5, 38] (через смещение
) обрабатывается деформированной сверткой. Авторы знают, что эта сетка помогает сосредоточиться на соответствующих областях изображения.
и
Значение зависит от того, к каким функциям применяется функция ядра.
После DCN автор применяет нормализацию слоев, а затем функцию активации сигмоида.
(Уравнение 3). Эта операция свертки изменяет номер канала карты объектов с
Перейти к исходному вводу
。
Выходные данные уравнения 3 представляют собой ворота внимания. Эти ворота контролируют поток информации из карты объектов.,Значение элемента из в каждом гейт-тензоре находится в диапазоне от 0 до 1. Эти значения определяют, какие части карты объектов выделяются или отфильтровываются. наконец,Для интеграции механизма внимания DAS в CNNМодель,Автор выполняет точечное умножение между исходным входным тензором и тензором внимания, полученным на предыдущем шаге.
Результат умножения уравнения 4 является входными данными для следующего уровня модели CNN, плавно интегрируя механизм внимания в модель без изменения структуры Backbone. По сравнению с предыдущим механизмом внимания к деформации, механизм внимания DAS в основном используется в CNN. Он использует ядро 3x3, которое больше подходит для CNN.
В то время как [39] применяет внимание к деформации конкретно к функциям запроса, механизм внимания DAS рассматривает функции изображения целостно. Авторский механизм внимания работает как автономный модуль и не требует серьезных архитектурных изменений, тем самым улучшая подключаемость по сравнению с методом внимания на основе Трансформера.
4 Experiments
4.1 Настройки обучения
для классификации изображений,Автор использовал CIFAR100,Stanford Собаки, набор иImageNet1кданные, для обнаружения объектов автор использовал MS Набор данных COCO. Автор принимает В [26] упоминается, что непротиворечивая архитектура изResNetиMobileNetV2.
дляImageNetэксперимент,Автор принимает Соответствующие настройки, как указано в [26]: обучение ResNet с размером пакета 256, начальная скорость обучения 0,1, снижение веса 1e-4, всего 100 эпох. Скорость обучения 30.
,60
и90
эпохи, скорректированные с коэффициентом 0,1.
MobileNetV2: размер пакета — 96, начальная скорость обучения — 0,045, снижение веса — 4e-5, скорость обучения корректируется в 0,98 раза в каждую эпоху.
дляCIFAR100иStanford Сбор данных о собаках, автор с вниманием Triplet [26] и Vanilla ResNet сравнивали. Автор выполнил поиск гиперпараметров в ResNet-18 и установил одинаковые настройки для всех базовых показателей: 300 эпох, размер пакета 128, начальная скорость обучения 0,1, снижение веса 5e-4 и скорость обучения 70.
,130
,200
,260
При , оно ослабляется кратно 0,2.
дляStanford Dogsданныенабор,Автор использовал следующие настройки: размер пакета — 32.,Скорость обучения 0,1.,Снижение веса составляет 1e-4.,Планировщик скорости обучения CosineAnnealing,Для предварительной обработки изображения используются случайное переворачивание и обрезка.
для обнаружения целей,Для проведения автор использует Faster R-CNN в MS COCO.,Использование набора инструментов MMdetection,Размер партии – 16.,Начальная скорость обучения составляет 0,02.,Снижение веса составляет 0,0001.,И используйте ImageNet-1k, предварительно обученный из Backbone. Автор уменьшает шум, предварительно обучая Backbone,Затем тренируйте остальную часть модели Backbone в течение нескольких раундов. Веса, полученные в результате этого начального обучения, используются в качестве точек инициализации для последующего процесса обучения автора. Автор использовал оптимизатор SGD.
Image Classification
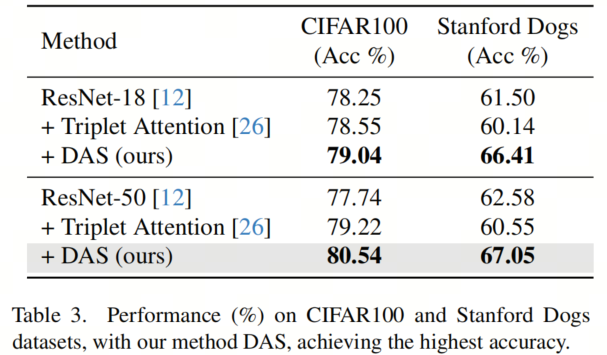
Таблица 3 показывает, что добавление тройного внимания немного повышает точность ResNet-18 по CIFAR100 (0,3%), но по Стэнфордскому Данные эпизода у собак снизились на 1,36%. Тем не менее, DAS находится в CIFAR100 и Стэнфорде. Точность ResNet-18 на собаках увеличилась на 0,79% и 4,91% соответственно.
Подобно ResNet-18, добавление тройного внимания к ResNet-50 по сравнению со Стэнфордом. Собаки и з Backbone Мо дель оказали негативное влияние и DAS в CIFAR100 и Stanford. Модель магистрали на 2,8% и 4,47% были улучшены на собаках соответственно, что свидетельствует о стабильности DAS на маленькой и большой модели и производительности. Интересно то, что автор есть в CIFAR100 и Stanford. В наборе данных Dogs видно, что предложенный автором метод DAS-18 не только превосходит базовую модель ResNet-18, но также превосходит более глубокие архитектуры, включая ResNet-50, при этом используя на 2,26 ГБ меньше FLOP. Это делает DAS-18 отличным выбором для мобильных приложений.
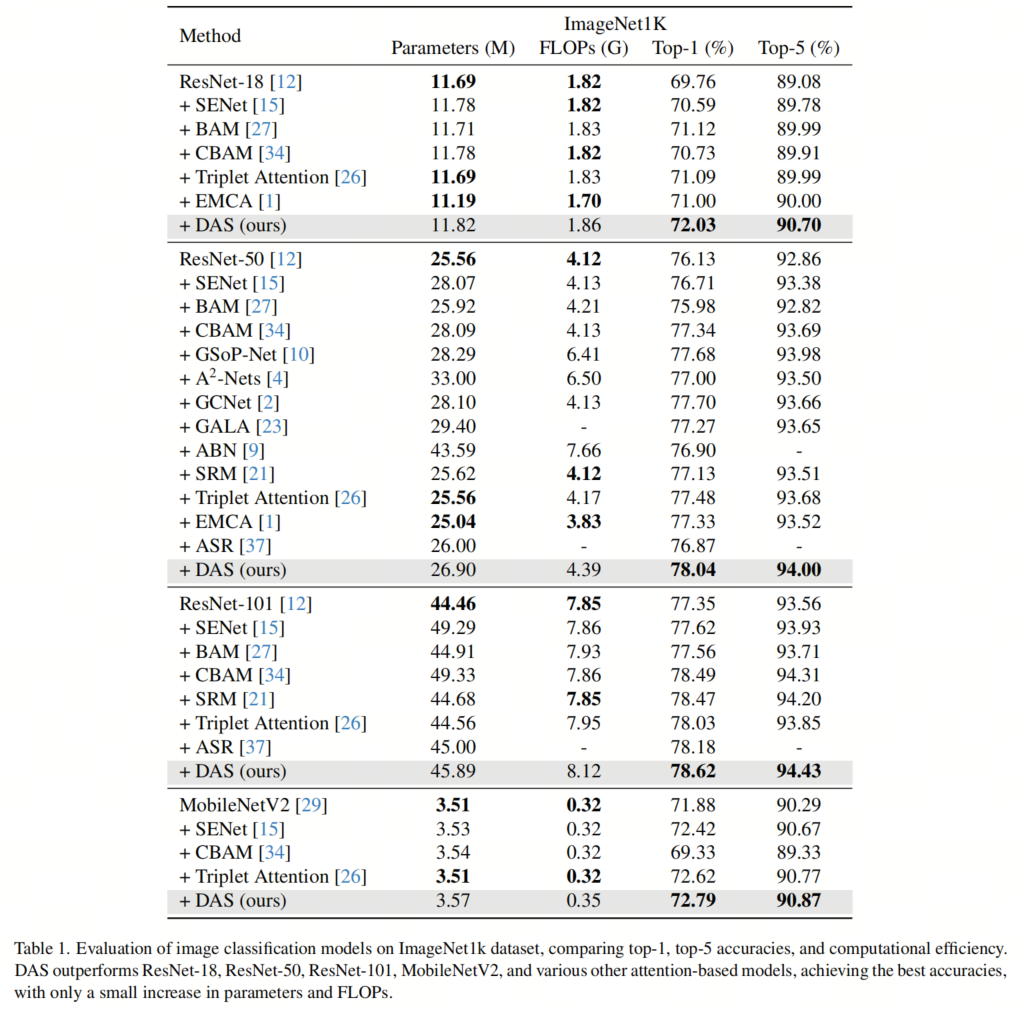
Результаты классификации ImageNet приведены в таблице 1. Когда к ResNet-18 применяется ограничение внимания DAS, точность классификации значительно повышается. DAS достигает 72,03% в точности Top-1 и 90,70% в Top-5. Это превосходит другие существующие методы, такие как SENet. ,BAM,CBAM,Triplet Attention,иEMCA,показалDASулучшение Модельпроизводительностьаспектизэффективность。
Когда глубина DAS равна 50,Достижение 78,04% в Топ-1 точности,Точность Топ-5 достигает 94,00%. Он достиг наилучшей производительности, используя на 32% меньше FLOPS и на 1,39 млн меньше параметров.,превосходитьGSoP-NetЖду второго местаизпроизводительность。ResNet-50 + Внимание DAS превзошло ResNet-101 по точности Top-1 и улучшило точность на 0,69% примерно по 60% числа параметров FLOP. Рес Нет-101 + Внимание DAS достигает лучшей точности Top-1 (78,62%) среди других модулей внимания с меньшим количеством параметров (по сравнению с SENet и CBAM).
На облегченном из MobileNetV2,DAS все еще действителен. Он достиг 72,79% в Топ-1 точности.,Достигнута точность 90,87% в Топ-5.,Превышает SENet,CBAM,иTriplet Внимание, несмотря на свою вычислительную эффективность, количество FLOP составляет всего 0,35G.
Object Detection
В таблице 2 показаны экспериментальные результаты автора по обнаружению объектов с использованием модели Faster R-CNN на сложном наборе данных MS COCO. Метрики, используемые для оценки, включают среднюю точность (AP), AP при различных пороговых значениях IoU (AP
,AP
), и для малых (AP
), средний (AP
) и Большой (AP
) конкретная точка доступа объекта.
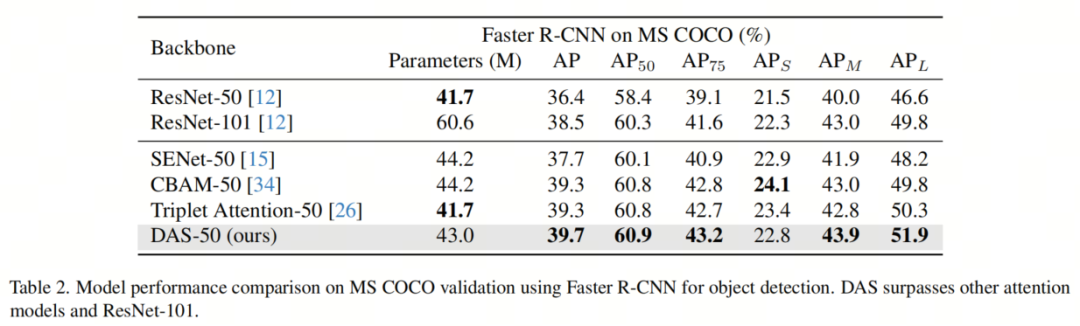
BackboneАрхитектураиз Выберите обнаружение целипроизводительностьиметь значительное влияние。у автораиз На стадии оценки,ResNet-50,ResNet-101,SENet-50,CBAM-50иTriplet Внимание-50 используется в качестве мощного базового уровня. Авторская модель DAS-50 есть в АП, АП
,AP
,AP
иAP
Превзошла все Backbone Архитектура,Количество параметров одновременно больше, чем у ResNet-101.,SENet-50 и CBAM-50 меньше.
Design Evolution and Ablation Studies
Прежде чем завершить проект DAS,Авторы исследуют две концепции внимания на уровне пикселей. Эти концепции продемонстрированы на рис. 2(а)и(б).,и в Стэнфорде Соответствующие результаты приведены в Таблице 4 для набора данных о собаках.
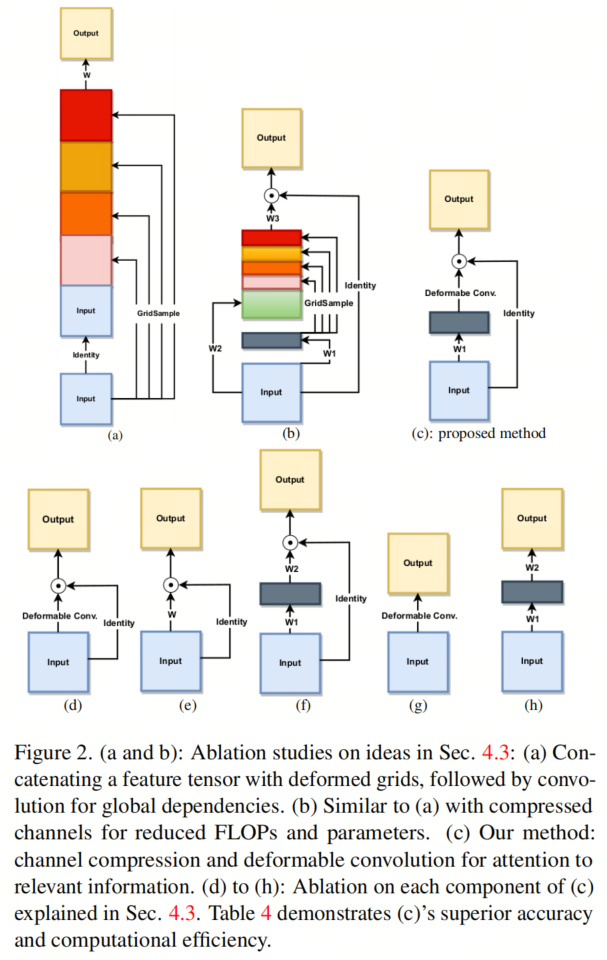
**(a)**: автор объединяет входные данные со своим собственным GridSample.,Затем используется сверточный слой для объединения входных данных и информации из удаленных пикселей. Хотя этот подход демонстрирует потенциал,Но в Стэнфорде Точность набора данных о собаках составляет всего 65,00%. GridSample — это дифференцируемая функция PyTorch, которая пространственно интерполирует соседние пиксели на основе заданного тензора сетки.
**(b)**: автор рассчитывает вес избыточной информации в объектах, используя сжатые входные данные и выходные данные GridSample.,Первоначальная концепция была расширена. Это улучшение увеличило точность с 65,00% до 65,21%.,В то же время сокращаются вычислительные затраты. Для оценки авторских конструктивных решений **(в)**, автор различных методов абляции исследует.
**(d)**: Удаление начальной части и использование только деформированных сверток приводит к снижению точности (65,338%), что подчеркивает важность первого сверточного слоя.
**(e)**: Удаление деформированной свертки, но сохранение начальной части увеличивает вычислительные затраты и снижает точность (65,291%), что указывает на то, что для точного моделирования внимания необходимо несколько слоев.
**(f)**: Замена деформированной свертки на свертку с разделением по глубине повышает точность (66,107%), но все же превосходит авторский метод, что подчеркивает преимущество деформированной свертки в плане внимания к соответствующей информации.
**(g)**: Удаление модуля внимания и использование только деформированных извилин существенно снижает точность, что подчеркивает важность внимания.
**(h)**: Аналогично, удаление модуля внимания и использование дополнительных слоев также показало низкую точность, что подчеркивает предпочтение использования этих слоев в качестве модулей внимания.
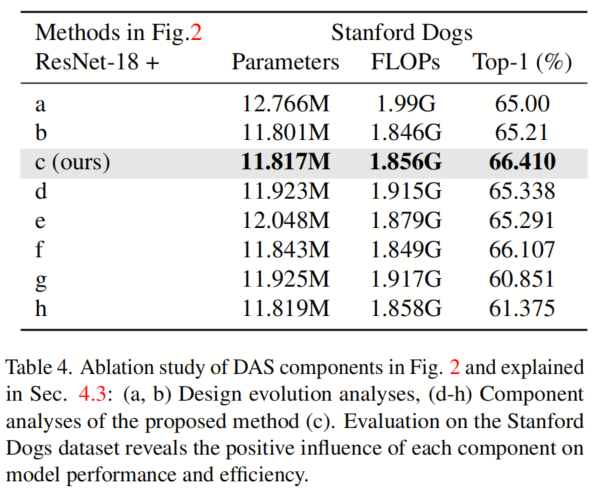
Предложенный авторами метод внимания (в) превосходит другие методы на всех конфигурациях, достигая наилучшей точности (66,410%). Это подчеркивает эффективность контекстно-зависимого механизма внимания авторов, позволяющего сосредоточиться на соответствующей информации даже за пределами ядра, и повышает производительность модели.
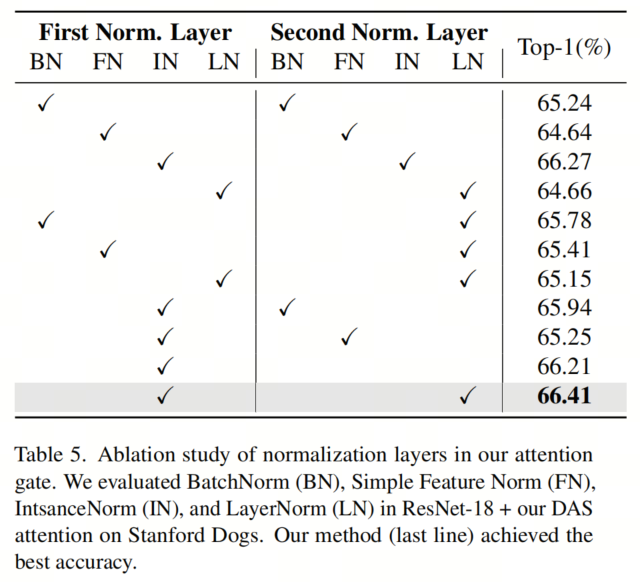
В таблице 5 показано влияние различных уровней нормализации на модуль внимания. Суммируя,Результаты экспериментов автора показывают, что,По сравнению с другими идеями и конфигурациями,Авторский метод имеет преимущества по точности и вычислительной эффективности.,Ценное дополнение к вниманию на уровне пикселей.
Авторы изучили параметры
Влияние изменения от 0,01 до 1 на объем вычислений. Увеличивать
Это увеличит объем вычислений и количество параметров. Автор обнаружил, что, как показано на рисунке 3, оно больше 0,1 из
значение, чтобы получить лучшие результаты. в целом,Существует компромисс между провалами и точностью. поэтому,В большинстве исследований,Автор выбрал
。
Автор исследовал влияние слоев внимания. Добавление уровня внимания после всех пропусков соединений может немного улучшить производительность.,Но это существенно увеличит объем расчета и параметры.,Особенно в больших из Модель. Опыт,Авторы заметили, что четыре слоя ворот внимания обеспечивают хороший баланс между вычислительными затратами и точностью. Автор также изучил расположение ворот внимания.,Окончательный выбор малых и больших наборов данных прост, эффективен и точен. Модель внимания.
Salient Feature Detection Effectiveness
Цель применения механизмов внимания к любой задаче — повысить внимание к значимым функциям, одновременно уменьшая или избегая внимания к нерелевантным функциям. Авторы полагают, что основная причина раннего частичного улучшения производительности заключается в том, что наше стробирование выделяется на изображении и увеличивает внимание к важным функциям. В этом разделе мы визуализируем, в какой степени наш механизм внимания достигает вышеуказанных целей.
с этой целью,Автор использует gradCAM,Это функция,Можно создать тепловую карту, показывающую, какие части входного изображения важны для принятия решений о классификации после обучения. Использование цветовой схемы в тепловой карте — от красного к синему.,Синий означает меньшую важность.

картина4Показано с использованиемResNet-50и Ворота внимания до и после,для нескольких образцовизblock 3иblock 4 Тепловая карта. Эти случаи ясно показывают, что внимание авторов лучше фокусируется на соответствующих особенностях изображений. Автор применяет шлюз авторского внимания в конце каждого блока ResNet, чтобы сеть могла начать обращать внимание на соответствующие особенности изображения на ранней стадии. Обратите внимание на блок на рисунке 4. 3, чтобы заблокировать 4 Изменения тепловой карты: автор видит, что при использовании DAS внимание действительно переключается на соответствующие функции.
Наконец, авторы определяют простую метрику для измерения эффективности обученной сети при сосредоточении внимания на соответствующих функциях. Авторы основывали результаты весов, полученные с помощью gradCAM. Поскольку мы наблюдаем, что веса gradCAM сжимаются в диапазоне от 0 до 1, в дальнейшем мы используем обратное логарифмическое масштабирование весов gradCAM. Оценка обнаружения существенных особенностей такова.
Обеспечивает измерение интенсивности внимания, получаемого соответствующими элементами изображения. Чем выше его значение, тем выше внимание уделяется соответствующим функциям. с другой стороны,
Более высокое значение означает, что внимание к несущественным функциям также увеличивается.
из значений варьируются от 0 до 1. Оценка, близкая к 1 из, означает сосредоточенность внимания на соответствующем признаке, а оценка, близкая к 0 и з, означает полную концентрацию внимания. Промежуточное значение указывает на то, что внимание распределяется между релевантными и нерелевантными функциями. Авторы использовали следующую процедуру для обнаружения RиB.
Автор впервые использует Grounding-DINO+SAM для идентификации объектов, которые необходимо классифицировать на изображениях. Чтобы избежать ручной проверки,Автор признает, что в этой операции могут быть ошибки,Это дает авторам релевантную особенность региона R. за пределами R,Авторы решили включить области со значимыми пикселями на основе gradCAM. Это вместе с R дает B. В последней строке рисунка 4из показан ResNet-50иDASиз.
ценить. Авторы также рассчитали
ценить. ResNetиDASиз
Значения составляют 0,59 и 0,72 соответственно, что соответственно иллюстрирует силу авторского метода в достижении целевого внимания к функциям.
5 Conclusion, Limitations and Extensions
В этой статье автор предлагает ворота внимания DAS, новый механизм самообслуживания, подходящий для CNN. DAS не использует Transformer. По сравнению с более ранними методами CNN, DAS уделяет пристальное внимание и всесторонне рассматривает контекст объекта.
ДАС – это очень просто - Он сочетает в себе отделимые по глубине свертки (для эффективного представления глобального контекста) и деформированные свертки (для повышения точности соответствующих областей изображения). настепень)。Результаты внедрения действительно показывают,Хотя DAS прост,Но с его помощью можно добиться сосредоточения внимания на важных для задачи особенностях изображений.
Одним из ограничений является то, что вычислительные затраты могут значительно увеличиться, если сеть имеет большие глубокие функции. поэтому,
Значение следует выбирать тщательно. если
Если значение слишком мало, это приведет к потере контекстной информации;
Если значение слишком велико, объем вычислений увеличится.
Хотя автор продемонстрировал DAS в классификации изображений и обнаружении объектов,но в будущем,Авторы надеются применить его для решения более интенсивных визуальных задач.,Например, семантическая сегментация и стереосопоставление.,среди этих задач,Способность DAS интенсивно концентрироваться может дать значительные преимущества.
ссылка
[1]. DAS: A Deformable Attention to Capture Salient Information in CNNs.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
