MediaCrawler извлекает облако слов из комментариев: пример Сяохуншу — область комментариев Май Линь
- Прежде чем начать статью, я хотел бы порекомендовать несколько хороших статей, написанных другими! Если вам интересно, вы также можете прочитать это!
- Рекомендуемая сегодня статья: Подготовка к работе: пользовательские аннотации для снижения чувствительности данных
- Ссылка на статью: https://cloud.tencent.com/developer/article/2464989
- В этом ресурсе Сяоюй подробно описывает, как использовать пользовательские аннотации Java для снижения чувствительности данных — технологии, которая имеет решающее значение для защиты конфиденциальности пользователей и безопасности корпоративных данных. Стиль написания статьи прост для понимания, ее содержание является глубоким и всеобъемлющим. Она не только предоставляет богатые теоретические знания, но, что более важно, содержит большое количество примеров кода. Эти примеры необходимы для понимания того, как это сделать. для обработки конфиденциальных данных (таких как номера телефонов, идентификационные номера и т. д.) десенсибилизация очень полезна.
MediaCrawler
Адрес проекта:
https://github.com/NanmiCoder/MediaCrawler- Можно реализовать рептилию Сяохуншу, рептилию Доуинь,быстрый работникрептилия,Bстоятьрептилия, Вейборептилия。
- В настоящее время он может захватывать видео, изображения, комментарии, лайки, репосты и другую информацию от Xiaohongshu, Douyin, Kuaishou, Bilibili и Weibo.
- Принцип: используйте драматург для построения моста, сохраняйте контекстную среду браузера после успешного входа в систему и получайте некоторые параметры шифрования, выполняя выражения JS. Используя этот метод, нет необходимости воспроизводить основной код JS шифрования, а также нет трудностей с обратным ходом. инженерное дело значительно сокращается.
- git скачать или скачать напрямую.
- Введите корневой каталог проекта
cd MediaCrawlerСоздайте виртуальную среду
python -m venv venv
# macos & linux Активировать виртуальную среду
source venv/bin/activate
# windows Активировать виртуальную среду
venv\Scripts\activate- Я открыл его через pycharm, и среда загрузки была автоматически установлена.
Установить зависимые библиотеки
pip install -r requirements.txt
Установить драйвер браузера драматурга
playwright install- Playwright был разработан Microsoft для автоматизации тестирования и Web Мультибраузерный, кроссплатформенный инструмент с открытым исходным кодом для сканирования.
Изменить конфигурацию
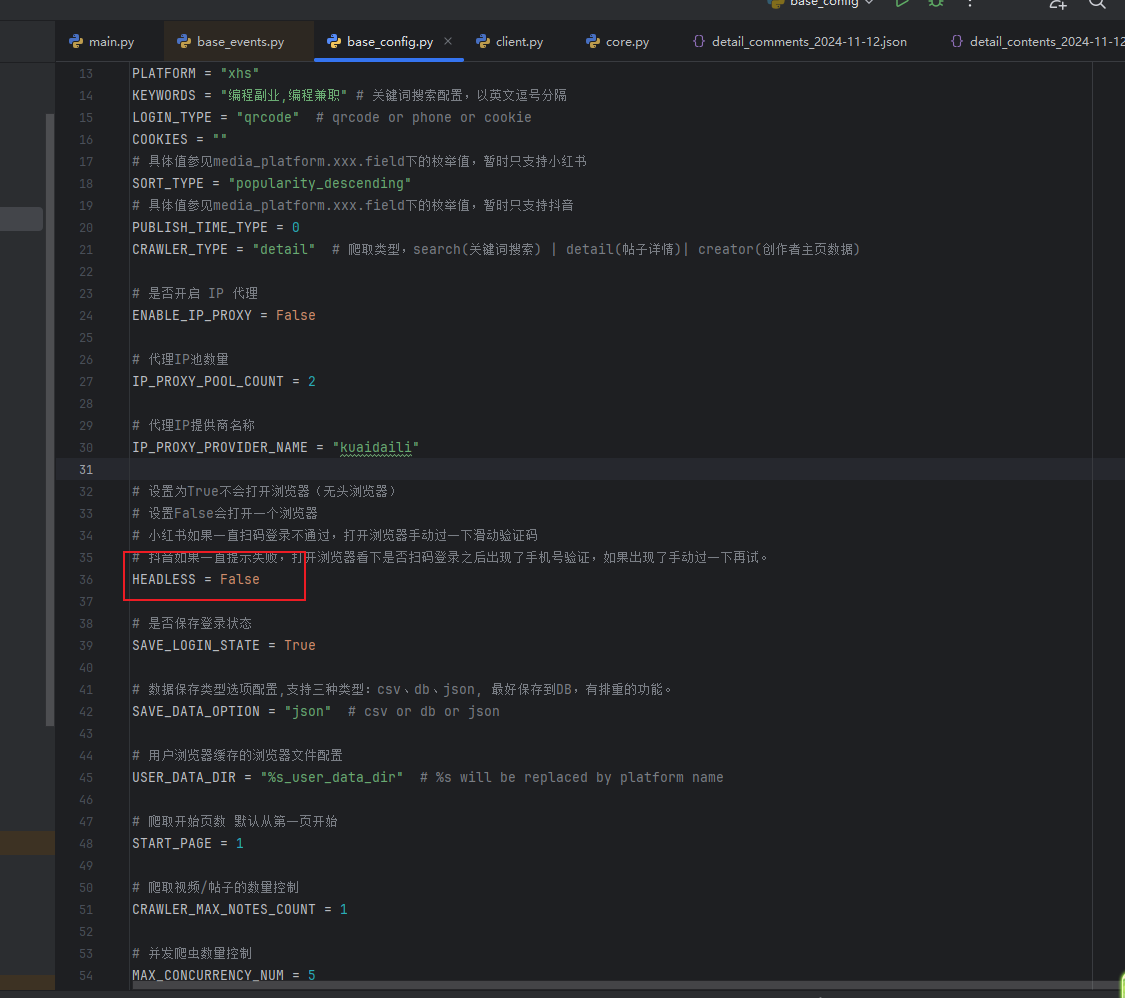
- Откройте браузер для сканирования кода.
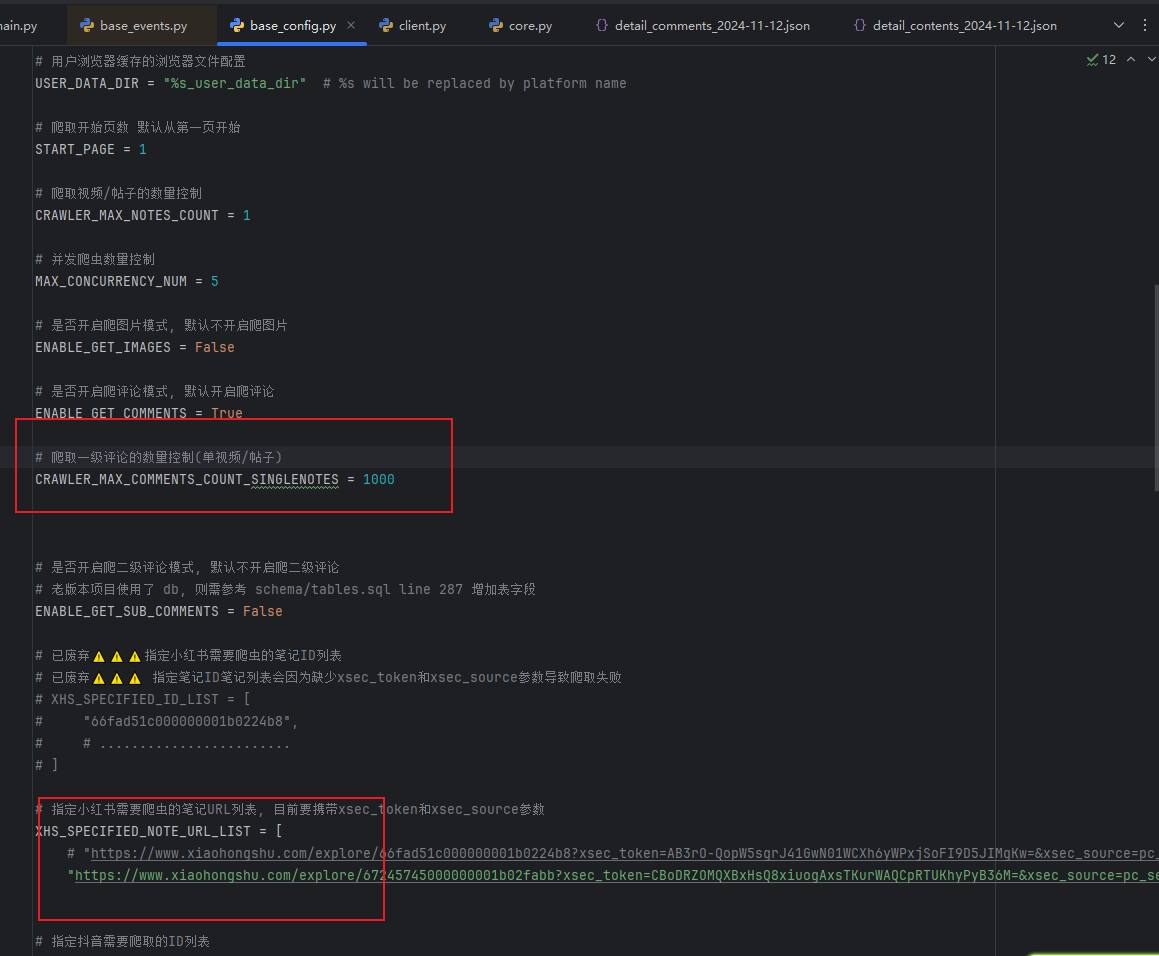
- Ограничьте сканирование до 1000 комментариев.
- Почтовый адрес Сяохуншу
Запустить сканер
- python main.py --platform xhs --lt qrcode --type detail
- Параметр --type Detail указывает на сканирование комментариев к указанному сообщению.
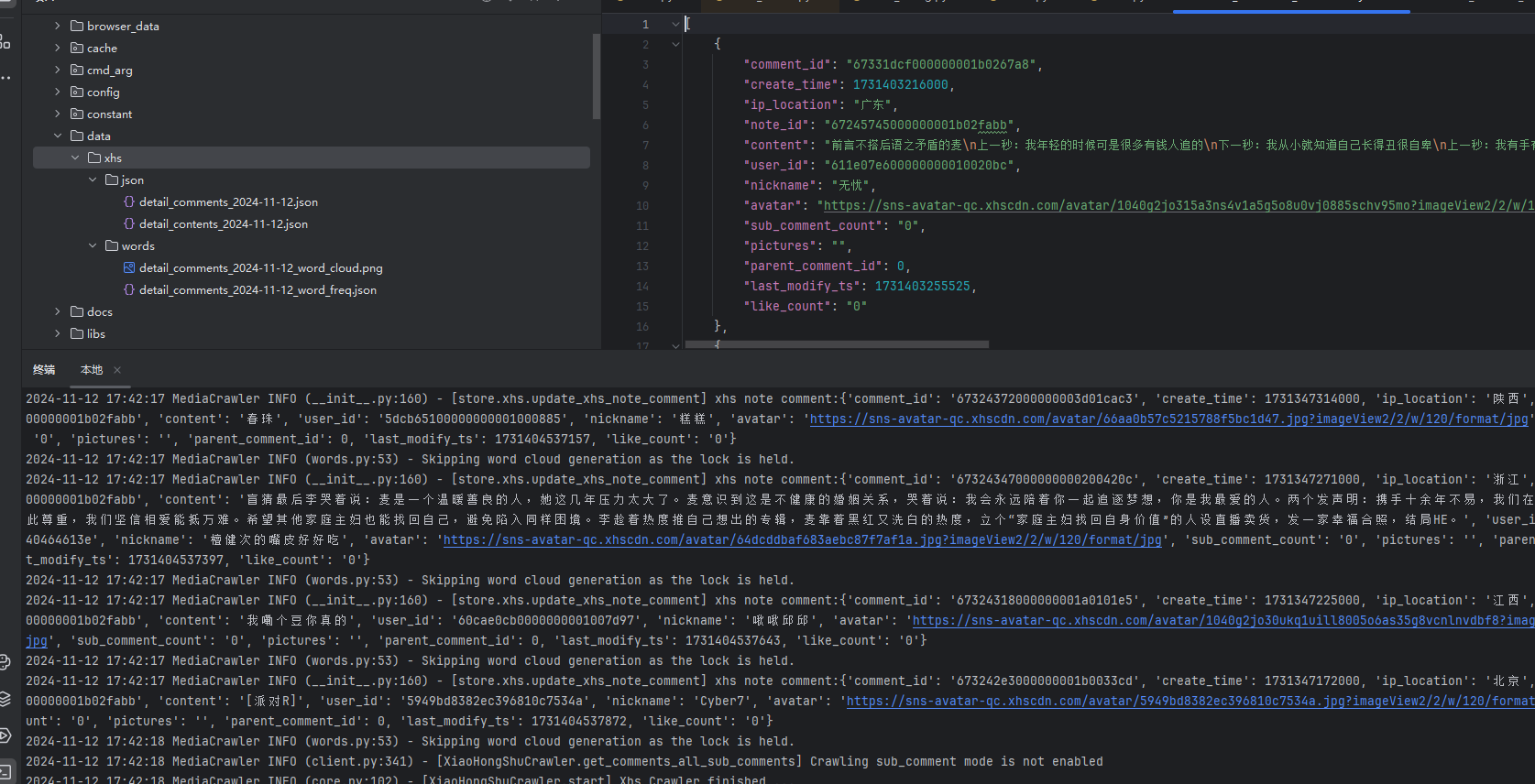
- Эффект от бега такой.
Обработка JSON
- Сам MediaCrawler поставляется с облаком слов, которое можно открыть после настройки.
- Здесь я решаю справиться с этим сам
- Мне не хотелось писать это самому, поэтому я попросил Tencent AI написать это:
Читать подробности comments 12 ноября 2024 г. значение содержимого каждого json в массиве списка в json используется в качестве данных облака слов.
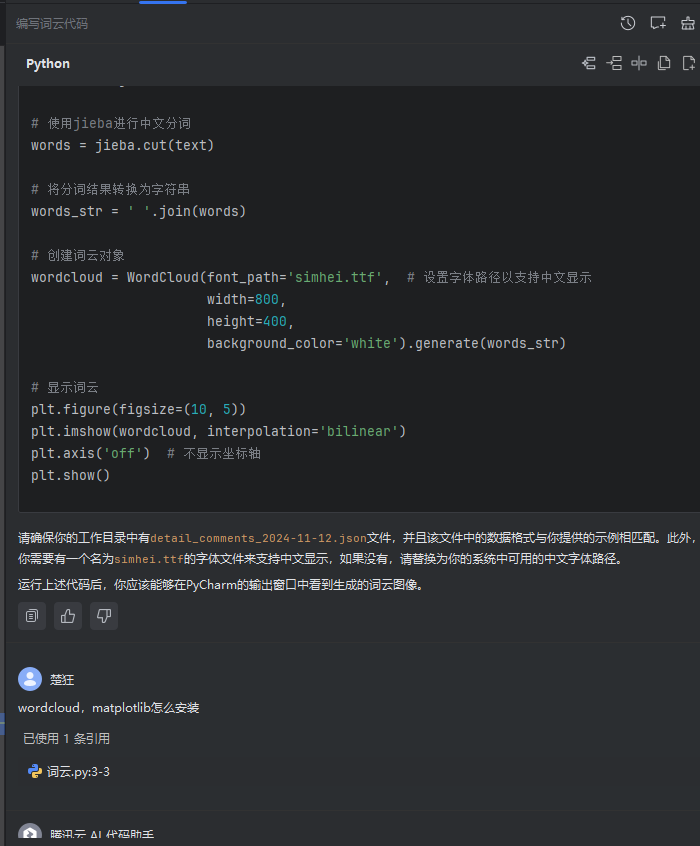
- Мы напрямую получаем код обработки облака слов.

- Запустив его, я обнаружил, что там есть самые нерелевантные слова типа «я» и «ты».
- Оптимизируйте, чтобы убрать падение.
import json
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# Чтение файла JSON
with open('detail_comments_2024-11-12.json', 'r', encoding='utf-8') as file:
data = json.load(file)
# Извлечь весь контент комментариев
comments = [item['content'] for item in data]
# Объединить все комментарии в одну строку
text = ' '.join(comments)
# Используйте jieba для сегментации китайских слов
words = jieba.cut(text)
# Определите конкретные слова, которые нужно удалить
stopwords = ['Я', 'ты', «Ле», «The», «Да», «Вверх», «Вниз», «Одна секунда». :','одна секунда',':']
# stopwords = []
# Отфильтровать определенные слова
filtered_words = [word for word in words if word not in stopwords]
# Преобразование отфильтрованных результатов сегментации слов в строки
words_str = ' '.join(filtered_words)
# Создайте объект облака слов
wordcloud = WordCloud(font_path='simhei.ttf', # Установите путь к шрифту для поддержки китайского дисплея.
width=1600,
height=800,
background_color='white').generate(words_str)
# Показать облако слов
plt.figure(figsize=(20, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off') # Не показывать оси
plt.show()- Регенерировать.

- Видно, что у Ли Синляна больше всего ключевых слов, а остальные — недавние горячие слова.
- В этой статье демонстрируется только демонстрация MediaCrawler и облака слов, а не конкретные события.
- ПРИМЕЧАНИЕ. При использовании этих данных,Всегда соблюдайте законы и правила,Уважайте конфиденциальность пользователей,и обеспечить законное и соответствующее требованиям использование данных. Неправильное манипулирование данными может нарушить закон,Нанести ущерб корпоративной репутации и доверию пользователей. Технология рептилий в этой статье предназначена только для учебных и исследовательских целей.,Его нельзя использовать для крупномасштабного парсинга других платформ или незаконной деятельности.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
