[Машинное обучение] Whisper: практика больших моделей преобразования речи в текст с открытым исходным кодом
1. Введение
Предыдущая статья праваМодель преобразования текста в речь ChatTTSОбъясняются принципы и практика,В шестой раз занял первое место в горячем списке🏆. сегодня,Поделитесь своей функцией симметрии (голос к тексту) Модель: Whisper. Whisper разработан OpenAI и опубликован Открытым исходным кодом.,Минимальный размер параметра — 39 МБ.,Максимум 1550М,Поддерживает несколько языков, включая китайский. Благодаря низкой стоимости ресурсов и высококачественному эффекту выживания.,Он широко используется в различных сценариях преобразования текста в текст, таких как распознавание музыки, чат личных сообщений, синхронный перевод и взаимодействие человека с компьютером.,И это будет дорого после коммерциализации. Поделитесь им со всеми бесплатно сегодня,Больше не тратьте деньги на услуги идентификации по голосу!
2. Принцип модели Whisper
2.1 Архитектура модели
Whisper — это типичная структура преобразователя кодировщика-декодера, которая выполняет многозадачную (многозадачную) обработку речи и текста соответственно.
2.2 Обработка голоса
Обработка голоса шепотом:на основе680000часы аудиоданных для обучения,Включая английский, другие языки, конвертированные в английский, неанглийские и другие языки. Преобразование аудиоданных в мел-спектрограмму,После прохождения двух сверточных слоев он отправляется в модель трансформатора.
2.3 Обработка текста
Обработка текста шепотом:текстtokenВключать3добрый:special токены (токены отметок), текст токены (текстовые токены), метка времени токены (временные метки), основанные на метках, управляют началом и концом текста на основе временной метки Токены выравнивают время речи с текстом.
Просто опишите принципы Whisper простым языком.,Если вы хотите узнать глубже,Пожалуйста, обратитесь кОфициальный документ OpenAI Whisper。
3. Практика модели шепота
3.1 Установка среды
Эта статья основана на библиотеке трансформеров HuggingFace.,Используйте конвейерный метод для чрезвычайно простой практической реализации Модели.,специфическийpipelineи другиеtransformersМодель Как его использовать, можно посмотреть в моем предыдущемстатья。
Итак, вам нужно только установить библиотеку трансформеров.
pip install transformersВ настоящее время голос часто ассоциируется с другими медиа, такими как видео, поэтому я рекомендую вам, кстати, установить инструмент обработки мультимедиа ffmpeg. Библиотеки pip не предусмотрено, поэтому для ее установки можно полагаться только на apt-get.
sudo apt-get update && apt-get install ffmpeg3.2 Загрузка модели
Модель будет загружена автоматически в зависимости от конвейера. Конечно, если скорость вашей сети недостаточна, замените HF_ENDPOINT внутренним изображением.
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
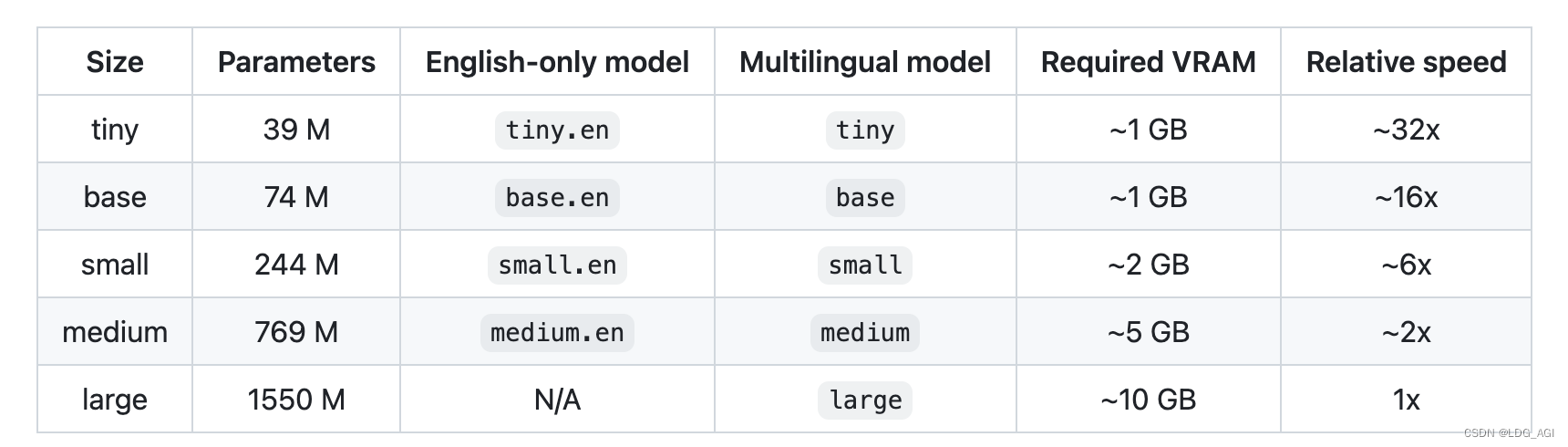
transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")Количество параметров модели, многоязычная поддержка, требуемый существующий размер и скорость вывода разных размеров следующие:
3.3 Модельное обоснование
Для функции вывода требуется всего две строки, что очень просто. Создайте экземпляр объекта модели на основе конвейера и передайте аудиофайл для преобразования в объект модели:
def speech2text(speech_file):
transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")
text_dict = transcriber(speech_file)
return text_dict3.4 Полный код
Запустите полный код:
python run_whisper.py -a output_video_enhanced.mp3 Полный код выглядит следующим образом:
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
os.environ["TF_ENABLE_ONEDNN_OPTS"] = "0"
from transformers import pipeline
import subprocess
def speech2text(speech_file):
transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")
text_dict = transcriber(speech_file)
return text_dict
import argparse
import json
def main():
parser = argparse.ArgumentParser(description="голос к тексту")
parser.add_argument("--audio","-a", type=str, help="Путь к выходному аудиофайлу")
args = parser.parse_args()
print(args)
text_dict = speech2text(args.audio)
#print("Текст в видео:\n" + text_dict["text"])
print("Текст в видео:\n"+ json.dumps(text_dict,indent=4))
if __name__=="__main__":
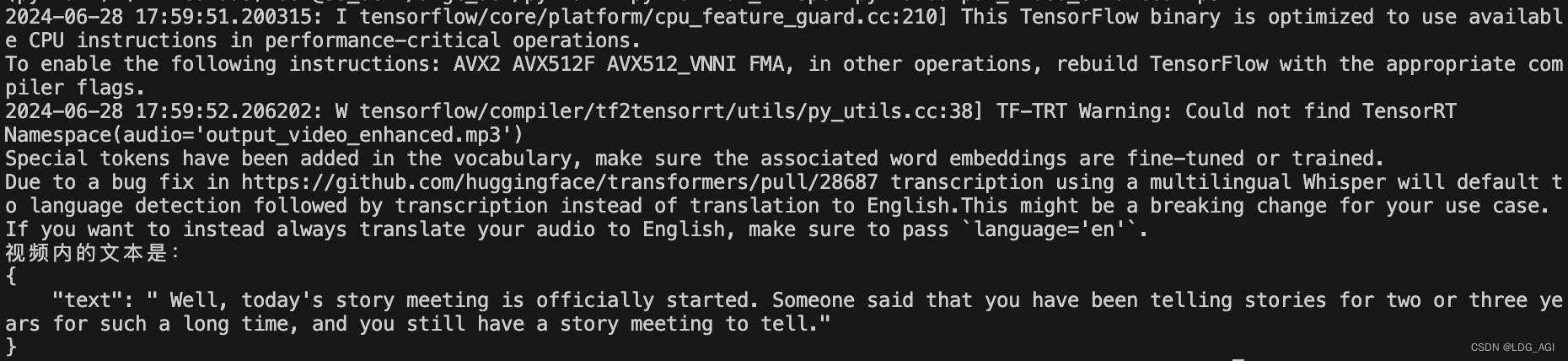
main()Здесь argparse используется для обработки параметров командной строки. После ввода аудиофайла в формате mp3 он обрабатывается функцией преобразования речи в текст voice2text и возвращается соответствующий текст:
3.5 Развертывание модели
Если вы хотите развернуть эту службу как службу API распознавания голоса,Вы можете обратиться к предыдущемуСтатья, связанная с FastAPI。
4. Резюме
Эта статья является продолжением предыдущей статьи о чате. Поскольку я научил вас преобразовывать текст в речь, я должен научить вас преобразовывать речь в текст, чтобы техническая система была завершена. Сначала я кратко опишу принцип модели Whisper, а затем реализую вывод модели Whisper на основе двух строк кода в библиотеке конвейеров преобразователей. Надеюсь, это поможет всем. Кодирование непростое. Если вам понравилось, жду вашего внимания + 3 голоса подряд.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
