[Машинное обучение] QLoRA: Количественная точная настройка большой модели Qwen2 на основе PEFT
я уже писал об этомQwen1.5、Qwen2.0、GLM-4Ожидание, когда отечественный открытый исходный код станет большим Модельпринцип、Статьи, связанные с обучением и выводами,Каждая статья занимает первое место в горячем списке,Но обучающая часть основана наРамка-лама-фабрика,верно Для инженеров,Больше всего мне нравится докапываться до сути,Структура обучения с использованием промежуточных слоев,«Безопасности» все равно меньше. Сегодня мы откладываем средние рамки,Идите глубоко на дно,Шаг за шагом мы поможем вам доработать большую Модель.
2. Количественная оценка и точная настройка — анализ принципов
2.1 Зачем нужна количественная точная настройка?
Количественная оценка Проблемы, которые необходимо решить путем тонкой настройки: полнопараметрическое высокобитное (32-битное или 16-битное) обучение точной настройке требует большого объема ресурсов памяти графического процессора.,Так прошлоУменьшите количество параметров(Quantization)а такжеУменьшите размер обучаемых параметров(LoRA)и другие стратегии по снижению затрат на обучение,Добейтесь того же эффекта тонкой настройкой всех параметров.
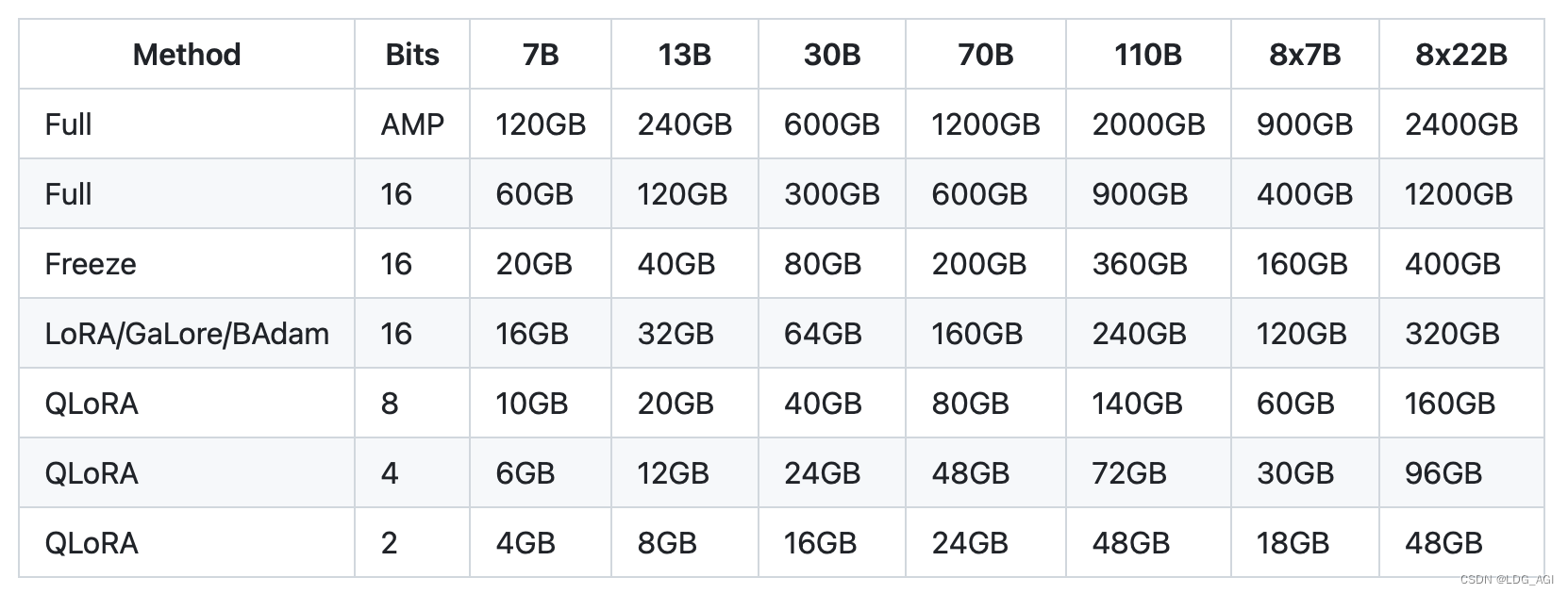
Как показано выше, для модели 7В 16-битная тонкая настройка всех параметров требует 60Гб видеопамяти, а 4-битная тонкая настройка QLoRA требует всего 6ГБ, что составляет всего 1/10. Перед лицом дорогих ресурсов графического процессора технология количественной точной настройки действительно является моделью «производительности, высвобождающей знания». Принципы квантования и точной настройки объясняются ниже.
2.2 Квантование
2.2.1 Принцип количественного определения
Векторное квантование:int8/int4
Популярный метод — преобразовать 16-битный тип с плавающей запятой в 8-битный целочисленный тип, который можно разделить на квантование «с нулевой точкой» и квантование «максимального абсолютного значения absmax». Следующий рисунок представляет собой пример «максимального абсолютного значения». абсмакс» квантование.
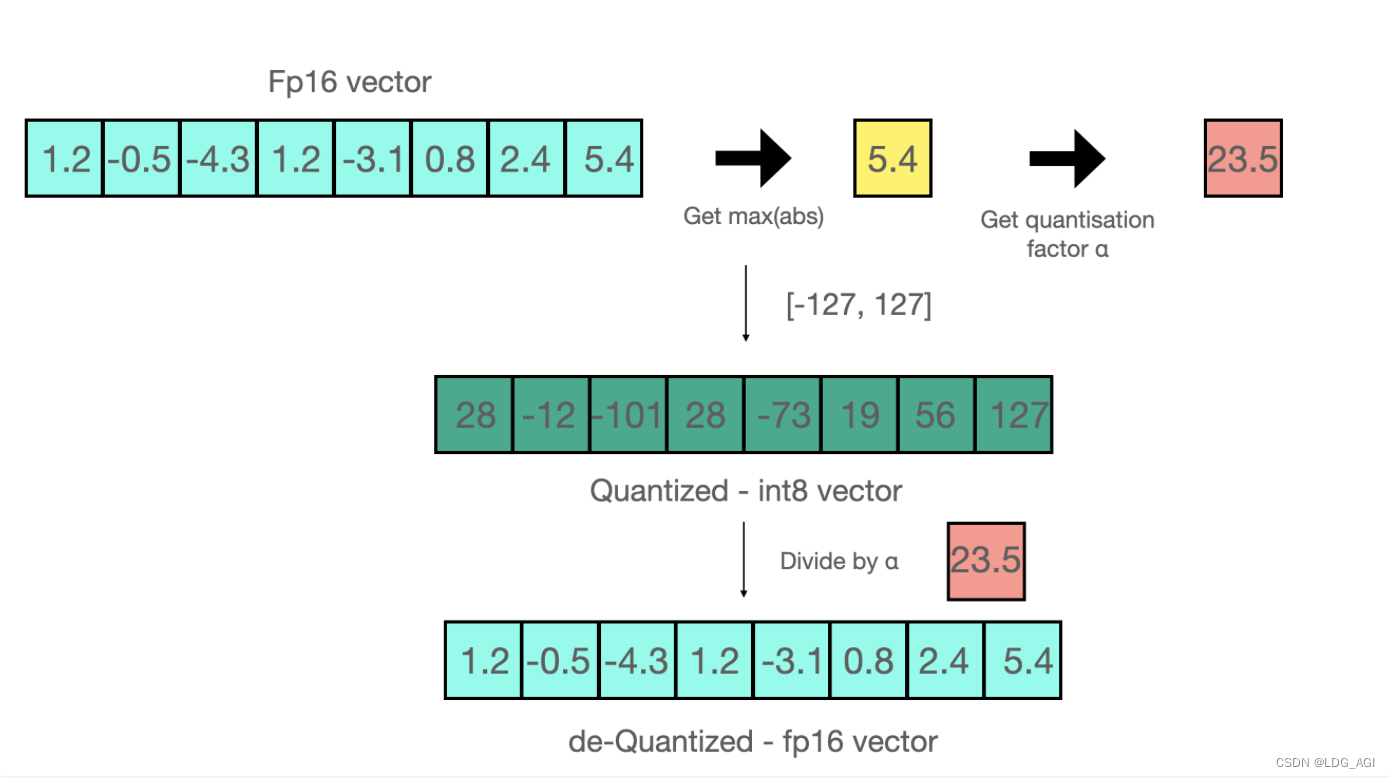
Диапазон, который мы планируем квантовать до int8, — [-127, 127]:
- Возьмите максимальное значение вектора fp16, 5,4, и разделите 127 на 5,4, чтобы получить 23,5 в качестве коэффициента масштабирования.
- Все числа в векторе fp16 умножаются на 23,5, чтобы получить вектор int8.
Обратное квантование к FP16:
- Разделите вектор int8 на масштабный коэффициент 23,5.
Квантование матрицы (0 вырождение)
Было доказано, что количественные потери вызваны характеристиками выбросов (точек, которые отклоняются от общего распределения), поэтому устанавливается аномальный порог, столбцы, превышающие порог, извлекаются для поддержания fp16, а матрица меньше, чем Аномальный порог рассчитывается количественно. Это может гарантировать, что точность не будет потеряна. Демонстрация анимации выглядит следующим образом:
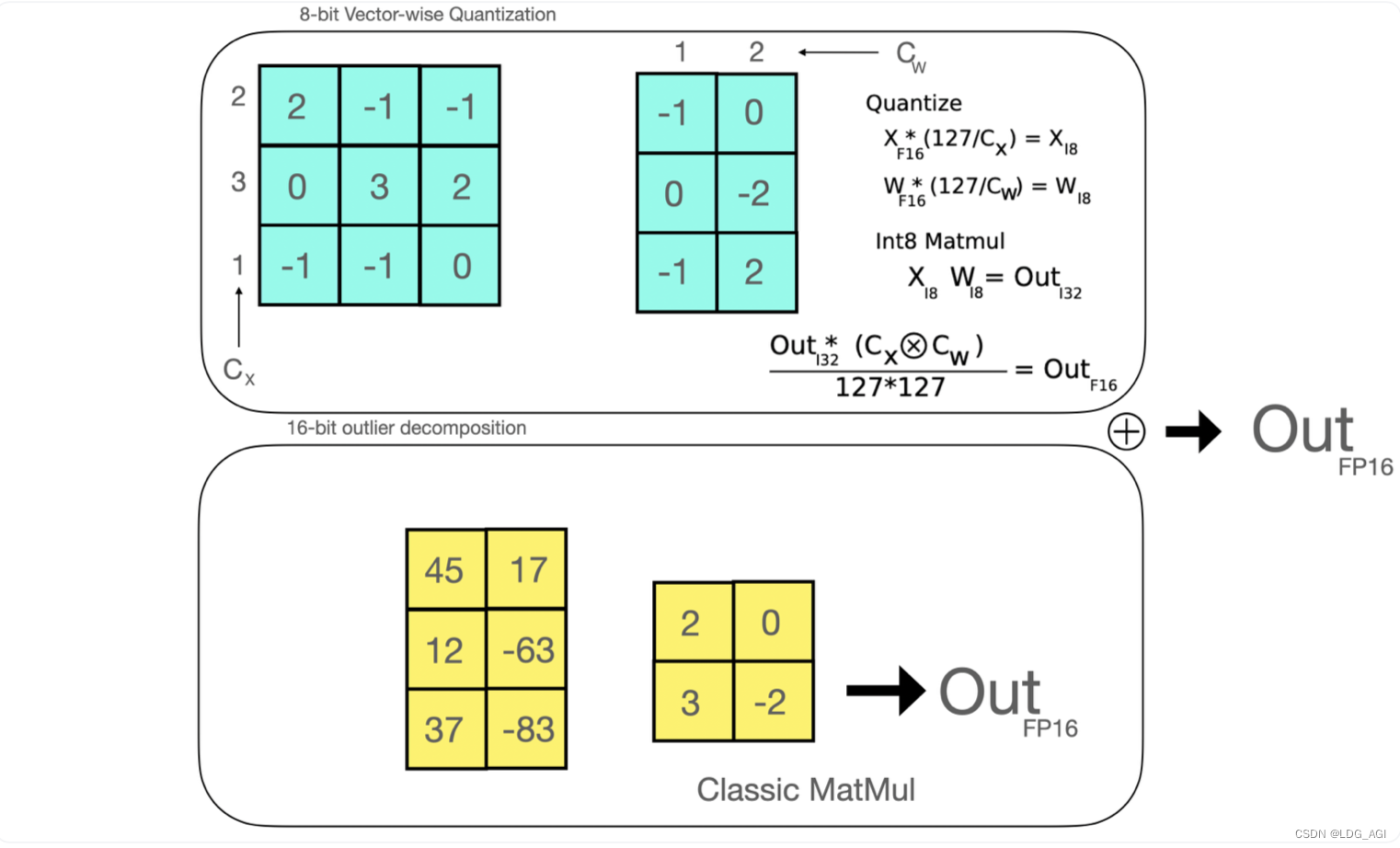
Извлеките невыпадающие значения линейных матриц W и X и квантовайте их как int8:
- Извлекайте выбросы (т. е. значения, превышающие некоторый порог) по столбцам из скрытого состояния ввода.
- Выполните матричные умножения отдельно для матрицы выбросов FP16 и матрицы без выбросов Int8.
Обратное квантование к FP16:
- противоположный Количественная Оценка. Результат матричного умножения значения, не являющегося выбросом, добавляется к результату матричного умножения значения выброса, чтобы получить окончательное значение. FP16 результат.
2.2.2 Код квантования
биты и байты:Количественная Оценка Один из самых простых методов для любой Модели, как с GGUF, так и с Количественной нулевой выборкой. оценка,ненужный Количественная рейтинг Данные калибровки и процесс калибровки (при AWQ и GPTQ и т. д. Количественная Оценка Все методы требуют небольшого количества образцов для калибровки) . Любая модель, содержащая torch.nn.Linear модуль, его можно квантовать прямо из коробки.
Код квантования nf4/fp4 очень прост и требует только использования конфигурации BitsAndBytesConfig.
from transformers import AutoTokenizer, AutoModelForCausalLM,BitsAndBytesConfig
###int4Количественная оценка Конфигурация
quantization_config = BitsAndBytesConfig(
load_in_4bit=True, # или load_in_8bit=True, установите по мере необходимости
#llm_int8_threshold=6.0,
#llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",#Добавить nf4Конфигурацию, удалить ее в fp4
bnb_4bit_use_double_quant=True,#Добавить nf4Конфигурацию, удалить ее в fp4
)
model = AutoModelForCausalLM.from_pretrained(model_dir,device_map=device,trust_remote_code=True,torch_dtype=torch.float16,quantization_config=quantization_config)
print(model)Выведя структуру модели, вы увидите, что все линейные линейные слои в слоях «Внимание» и «MLP» стали линейными4-битными:
Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(152064, 3584)
(layers): ModuleList(
(0-27): 28 x Qwen2DecoderLayer(
(self_attn): Qwen2SdpaAttention(
(q_proj): Linear4bit(in_features=3584, out_features=3584, bias=True)
(k_proj): Linear4bit(in_features=3584, out_features=512, bias=True)
(v_proj): Linear4bit(in_features=3584, out_features=512, bias=True)
(o_proj): Linear4bit(in_features=3584, out_features=3584, bias=False)
(rotary_emb): Qwen2RotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear4bit(in_features=3584, out_features=18944, bias=False)
(up_proj): Linear4bit(in_features=3584, out_features=18944, bias=False)
(down_proj): Linear4bit(in_features=18944, out_features=3584, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm()
(post_attention_layernorm): Qwen2RMSNorm()
)
)
(norm): Qwen2RMSNorm()
)
(lm_head): Linear(in_features=3584, out_features=152064, bias=False)
)2.3 Точная настройка
2.3.1 LoRA
Основная идея: моделировать изменения параметров посредством низкоранговой декомпозиции и достигать непрямого обучения больших моделей с чрезвычайно маленькими параметрами.
Как показано на рисунке ниже, модули, включающие умножение матриц, такие как линейные модули Q, K, V в трансформаторах, добавляют две малоразмерные маленькие матрицы A и B рядом с исходными весами и умножают две матрицы A и B перед и после этого первая матрица A отвечает за уменьшение размерности, вторая матрица B отвечает за повышение размерности, а размерность среднего слоя равна r, чтобы восстановить размерность. Предположим, что исходный размер равен d, что уменьшает d*d до d*r+r*d.
- Обучение: обновите только два новых параметра небольшой матрицы A и B.
- Рассуждение: сложите исходную матрицу W и произведение BA двух маленьких матриц A и B в результате h=Wx+BAx=(W+BA)x. Для рассуждения дополнительные ресурсы не добавляются.
Код очень простой, это по-прежнему файл конфигурации LoraConfig:
from peft import LoraConfig,get_peft_model
config = LoraConfig(
r=32,
lora_alpha=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj","down_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
print(model)- Эталонная библиотека peft (Parameter-Efficient Fine-Tuning)
- КонфигурацияLoraКонфигурациядокументLoraConfig
- Примените LoraConfig к модели с помощью метода get_peft_model, инкапсулированного peft.
Глядя на структуру модели, вы обнаружите исходную структуру Linear4bit, например q_proj:
(q_proj): Linear4bit(in_features=3584, out_features=3584, bias=True)стал:
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=3584, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=3584, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)На основе Linear4bit, новый
- lora_dropout: используется для предотвращения переобучения
- ModuleDict Lora_A и Lora_B: Out_features A такие же, как in_features B, оба имеют r = 32.
- Слой внедрения Lora_A и Lora_B
Полная структура модели после квантования 7 Linear4bits ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"] и т. д. выглядит следующим образом.
PeftModelForCausalLM(
(base_model): LoraModel(
(model): Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(152064, 3584)
(layers): ModuleList(
(0-27): 28 x Qwen2DecoderLayer(
(self_attn): Qwen2SdpaAttention(
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=3584, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=3584, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(k_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=512, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=512, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(v_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=512, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=512, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(o_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=3584, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=3584, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(rotary_emb): Qwen2RotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=18944, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=18944, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(up_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=18944, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=18944, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(down_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=18944, out_features=3584, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=18944, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=3584, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm()
(post_attention_layernorm): Qwen2RMSNorm()
)
)
(norm): Qwen2RMSNorm()
)
(lm_head): Linear(in_features=3584, out_features=152064, bias=False)
)
)
)2.3.2 QLoRA
Умные люди уже подумали, что объединение упомянутой выше Квантизации с Лорой и есть QLoRA.
- Во время тренировки Модель,Преобразование линейного слоя в Linear4bit
- верноLinear4bitКоличественная оценка добавляет две небольшие матрицы A и B с низким рангом r.
- Веса этих двух маленьких матриц передаются Количественной Оценка Обратное распространение градиента весов для точной настройки
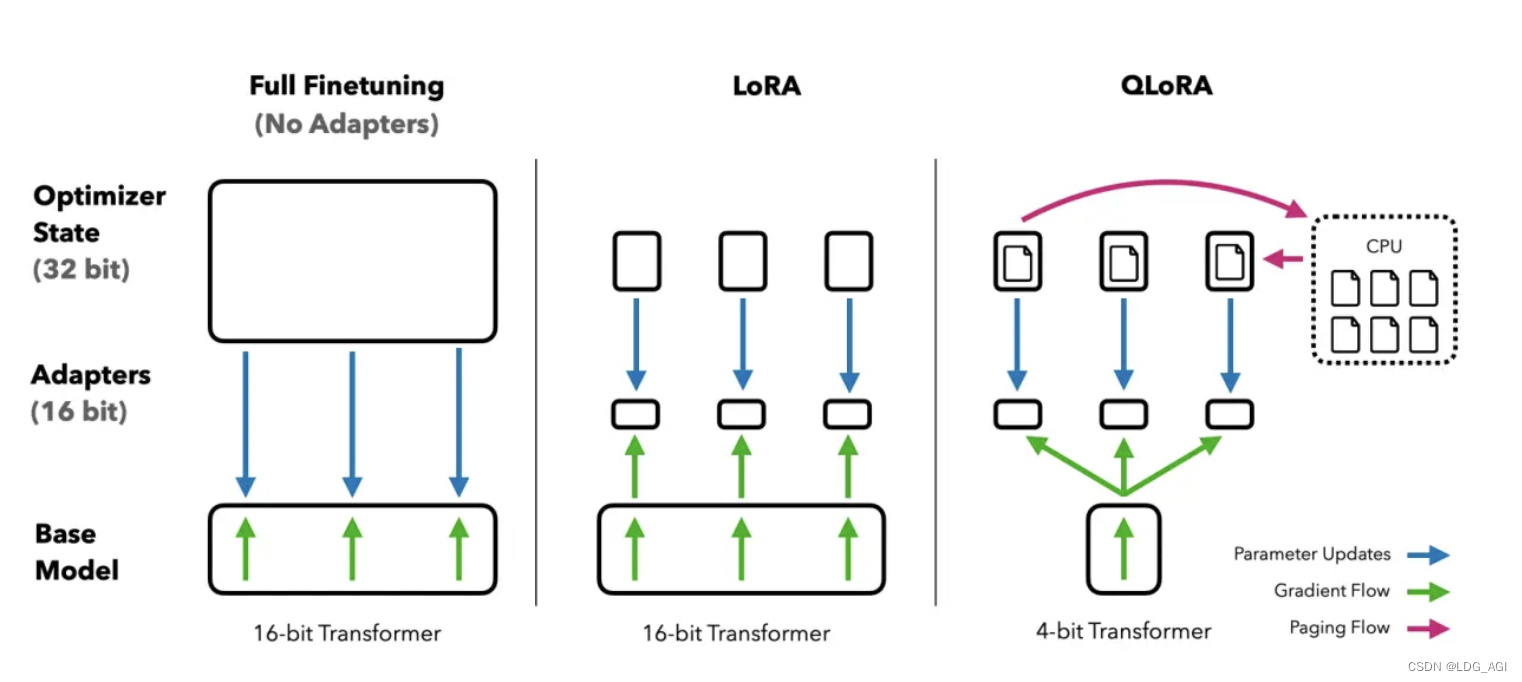
На основе LoRA компания QLoRA внесла три ключевые инновации:
- NF4(4bit NormalFloat): улучшенная 4-битная Количественная оценка Закон,Убедитесь, что каждый Количественная Оценка Количество значений в бункерах одинаковое.
- пара Количественная оценка:вернопервый Количественная Эти константы после калибровки выполняются снова Количественная уменьшить место для хранения.
- Оптимизатор подкачки: используйте подкачку памяти Nvidia для использования вычислений ЦП, когда ресурсов графического процессора недостаточно.
Вспомните код BitsAndBytesConfig в части количественной оценки выше, он вам очень знаком:
quantization_config = BitsAndBytesConfig(
load_in_4bit=True, # или load_in_8bit=True, установите по мере необходимости
#llm_int8_threshold=6.0,
#llm_int8_has_fp16_weight=False,
llm_int8_enable_fp32_cpu_offload=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",#Добавить nf4Конфигурацию, удалить ее в fp4
bnb_4bit_use_double_quant=True,#Добавить nf4Конфигурацию, удалить ее в fp4
)3. Количественная оценка и точная настройка. Практическое упражнение: возьмите Qwen2 в качестве примера и настройте свою первую большую модель ИИ своими руками.
3.1 Предварительная обработка модели — установка зависимостей, импорт пакета библиотеки, загрузка модели.
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen2-7B-Instruct')
import torch
import torch.nn as nn
import transformers
from datasets import load_dataset,load_from_disk
from transformers import AutoTokenizer, AutoModelForCausalLM,BitsAndBytesConfig
from peft import LoraConfig,get_peft_model,prepare_model_for_kbit_trainingВсе еще здесь
- Загрузите модель с помощью modelscope,
- Для обработки Модели используйте автоматический токенизатор преобразователей (AutoTokenizer), автоматическую библиотеку моделей (AutoModelForCausalLM), Количественную настройку конфигурации (BitsAndBytesConfig) и т. д.,
- Используйте набор данных для обработки данных,
- Используйте peft для загрузки конфигурации lora и ее точной настройки.
- И неотделимый факел.
Вспомним, как установить среду conda и пакеты зависимостей pip.
conda create -n train_llm python
conda activate train_llm
pip install transformers,modelscope,peft,torch,datasets,accelerate,bitsandbytes -i https://mirrors.cloud.tencent.com/pypi/simple3.2 Предварительная обработка модели — загрузка количественной модели
Используйте BitsAndBytesConfig для настройки параметров квантования и используйте AutoModelForCausalLM для загрузки параметров квантования.
device = "auto" # the value needs to be a device name (e.g. cpu, cuda:0) or 'auto', 'balanced', 'balanced_low_0', 'sequential'
###int4Количественная оценка Конфигурация
quantization_config = BitsAndBytesConfig(
load_in_4bit=True, # или load_in_8bit=True, установите по мере необходимости
#llm_int8_threshold=6.0,
#llm_int8_has_fp16_weight=False,
llm_int8_enable_fp32_cpu_offload=True,
bnb_4bit_compute_dtype=torch.float16,#Хотя мы загружаем и сохраняем Модель в 4 битах, при необходимости мы частично реверсируем Количественную откалибровать его и рассчитать в 16-битной точности.
bnb_4bit_quant_type="nf4",#nfКоличественная тип оплаты
bnb_4bit_use_double_quant=True,#пара重Количественная оценка,Количественная оценкаснова Количественная оценка, дальнейшее решение проблемы видеопамяти
)
model = AutoModelForCausalLM.from_pretrained(model_dir,device_map=device,trust_remote_code=True,torch_dtype=torch.float16,quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True,padding_side="right",use_fast=False)
print(model)3.3 Предварительная обработка модели — загрузка сети LoRA
from peft import LoraConfig,get_peft_model,prepare_model_for_kbit_training
model = prepare_model_for_kbit_training(model)
config = LoraConfig(
r=32,
lora_alpha=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj","down_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
print(model)- Используйте подготовленную_модель_фор_кбит_тренинг для нормы и LM Слой головы обрабатывается для повышения стабильности обучения (очень нужно, иначе будет выдано сообщение об ошибке нехватки видеопамяти):
- layer norm Слой зарезервирован FP32 Точность
- слой внедрения, а также LM head Выходной слой зарезервирован FP32 Точность
- Используйте get_peft_model, чтобы добавить слой Лоры в Модель.
3.4 Предварительная обработка данных — загрузка и обработка данных.
Здесь используется набор данных Abirate/english_quotes на HuggingFace. Из-за сетевой среды я вручную загрузил и сохранил его в каталоге ./.
data = load_dataset('json',data_files="./quotes.jsonl")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
print(data)Пример набора данных (вот пример для отладки, замените свой собственный набор данных):
Данные в каждой строке цитаты сегментируются на input_ids с помощью токенизатора и data.map. Результат:

3.5 Обучение модели
После импорта пакета, количественной оценки модели, лора модели и предварительной обработки данных важным шагом является шаг 5: обучение модели.
trainer = transformers.Trainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=10,
max_steps=50,
learning_rate=3e-4,
fp16=True,
logging_steps=1,
output_dir="outputs/checkpoint-1"+time_str,
optim="paged_adamw_8bit",
save_strategy = 'steps',
save_steps = 10,
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
trainer.save_model(trainer.args.output_dir)Используйте тренажер преобразователей для ввода модели Qlora, данных, параметров обучения, сборщика данных и других параметров, чтобы начать обучение.
Модель Qwen2-7B-Instruct занимает около 20ГБ видеопамяти для обучения по вышеуказанным параметрам.

3.6 Объединение моделей и вывод
Выше приведен фрагмент кода теста вывода слияния моделей, который в основном включает в себя
- Импортируйте класс Модель PeftModel и класс Конфигурация PeftConfig в peft.
- Получите каталог модели точной настройки peft_model_dir через тренер.args.output_dir
- Получите точно настроенную Модель Конфигурацияconfig.
- Загрузка базы Модель
- Объединить базовую модель с моделью счетчика через PeftModel.from_pretrained(model,peft_model_dir)
- Модельрассуждение,То же, что и при использовании базовой Модели!
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_dir = trainer.args.output_dir
config = PeftConfig.from_pretrained(peft_model_dir)
print(config)
model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path, return_dict=True, device_map=device,
torch_dtype=torch.float16, quantization_config=quantization_config
)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
# Load the Lora model
model = PeftModel.from_pretrained(model, peft_model_dir)
print(model)
# Имитировать верный разговор
prompt = «Подробно представить модель большого языка и оценить различия между ней и глубоким обучением»
messages = [
{"role": "system", "content": «Вы умный помощник.»},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
gen_kwargs = {"max_length": 512, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**model_inputs, **gen_kwargs)
outputs = outputs[:, model_inputs['input_ids'].shape[1]:] #Удалить системный, пользовательский и другие верные префиксы
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Видеопамять, используемая для вывода: около 15 ГБ

Результаты вывода (эта статья предназначена только для прохождения процесса и не предоставляет каких-либо соответствующих данных, связанных с бизнесом. Вы можете заменить часть данных в 3.4 в соответствии с вашей реальной ситуацией):
3.7 Приложение: Полный код
from datetime import datetime
now = datetime.now()
time_str = now.strftime('%Y-%m-%d %H:%M:%S')
print(time_str)
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen2-7B-Instruct')
import torch
import torch.nn as nn
import transformers
from datasets import load_dataset,load_from_disk
from transformers import AutoTokenizer, AutoModelForCausalLM,BitsAndBytesConfig
device = "auto" # the value needs to be a device name (e.g. cpu, cuda:0) or 'auto', 'balanced', 'balanced_low_0', 'sequential'
###int4Количественная оценка Конфигурация
quantization_config = BitsAndBytesConfig(
load_in_4bit=True, # или load_in_8bit=True, установите по мере необходимости
#llm_int8_threshold=6.0,
#llm_int8_has_fp16_weight=False,
llm_int8_enable_fp32_cpu_offload=True,
bnb_4bit_compute_dtype=torch.float16,#Хотя мы загружаем и сохраняем Модель в 4 битах, при необходимости мы частично реверсируем Количественную откалибровать его и рассчитать в 16-битной точности.
bnb_4bit_quant_type="nf4",#nfКоличественная тип оплаты
bnb_4bit_use_double_quant=True,#пара重Количественная оценка,Количественная оценкаснова Количественная оценка, дальнейшее решение проблемы видеопамяти
)
model = AutoModelForCausalLM.from_pretrained(model_dir,device_map=device,trust_remote_code=True,torch_dtype=torch.float16,quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True,padding_side="right",use_fast=False)
model.gradient_checkpointing_enable
print(model)
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
from peft import LoraConfig,get_peft_model,prepare_model_for_kbit_training
model = prepare_model_for_kbit_training(model)
config = LoraConfig(
r=32,
lora_alpha=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj","down_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
print(model)
print_trainable_parameters(model)
# Verifying the datatypes.
dtypes = {}
for _, p in model.named_parameters():
dtype = p.dtype
if dtype not in dtypes:
dtypes[dtype] = 0
dtypes[dtype] += p.numel()
total = 0
for k, v in dtypes.items():
total += v
for k, v in dtypes.items():
print(k, v, v / total)
"""### Training"""
data = load_dataset('json',data_files="./quotes.jsonl")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
print(data)
trainer = transformers.Trainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=10,
max_steps=50,
learning_rate=3e-4,
fp16=True,
logging_steps=1,
output_dir="outputs/checkpoint-1"+time_str,
optim="paged_adamw_8bit",
save_strategy = 'steps',
save_steps = 10,
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
trainer.save_model(trainer.args.output_dir)
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_dir = trainer.args.output_dir
config = PeftConfig.from_pretrained(peft_model_dir)
print(config)
model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path, return_dict=True, device_map=device,
torch_dtype=torch.float16, quantization_config=quantization_config
)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
# Load the Lora model
model = PeftModel.from_pretrained(model, peft_model_dir)
print(model)
# Имитировать верный разговор
prompt = «Подробно представить модель большого языка и оценить различия между ней и глубоким обучением»
messages = [
{"role": "system", "content": «Вы умный помощник.»},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
gen_kwargs = {"max_length": 512, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**model_inputs, **gen_kwargs)
outputs = outputs[:, model_inputs['input_ids'].shape[1]:] #Удалить системный, пользовательский и другие верные префиксы
print(tokenizer.decode(outputs[0], skip_special_tokens=True))4. Резюме
В этой статье сначала анализируются принципы количественной оценки и тонкой настройки, а затем на примере Qwen2-7B вы шаг за шагом проведете тонкую настройку вашей собственной большой модели на основе QLoRA и PEFT. Руководство по тонкой настройке network peft + qlora, шаг за шагом, давайте учиться Даже если сетевая среда не позволяет этого, вы можете плавно начать путь тонкой настройки больших моделей.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
