[Машинное обучение] Принцип большой модели Qwen2, практика обучения и вывода
1. Введение
только что закончил писать[Машинное обучение] Qwen1.5-14B-Chat Обучение большим моделям и практика вывода Али Квен выпустил Qwen2. По сравнению с 8 моделями Dense 0,5B, 1,8B, 4B, 7B, 14B, 32B, 72B, 110B и 1 14B (A2.7B) моделью MoE в Qwen1.5, всего 9 моделей. , Qwen2 включает модели 0,5B, 1,5B, 7B, 57B-A14B и 72B, всего 5 моделей размеров. Что касается размера, то самым важным является выпуск более крупной модели MoE 57B-A14B. Некоторые спрашивают, почему был удален размер 14B, обычно используемый для видеопамяти 32 ГБ. На самом деле его можно получить путем обрезки. 57Б-А14Б.
2. Представление модели
2.1 Обзор модели Qwen2
Qwen2 против Qwen1.5:
- Размер модели: увеличьте размер модели Qwen2-7B и Qwen2-72B с 32 КБ до 128 КБ.
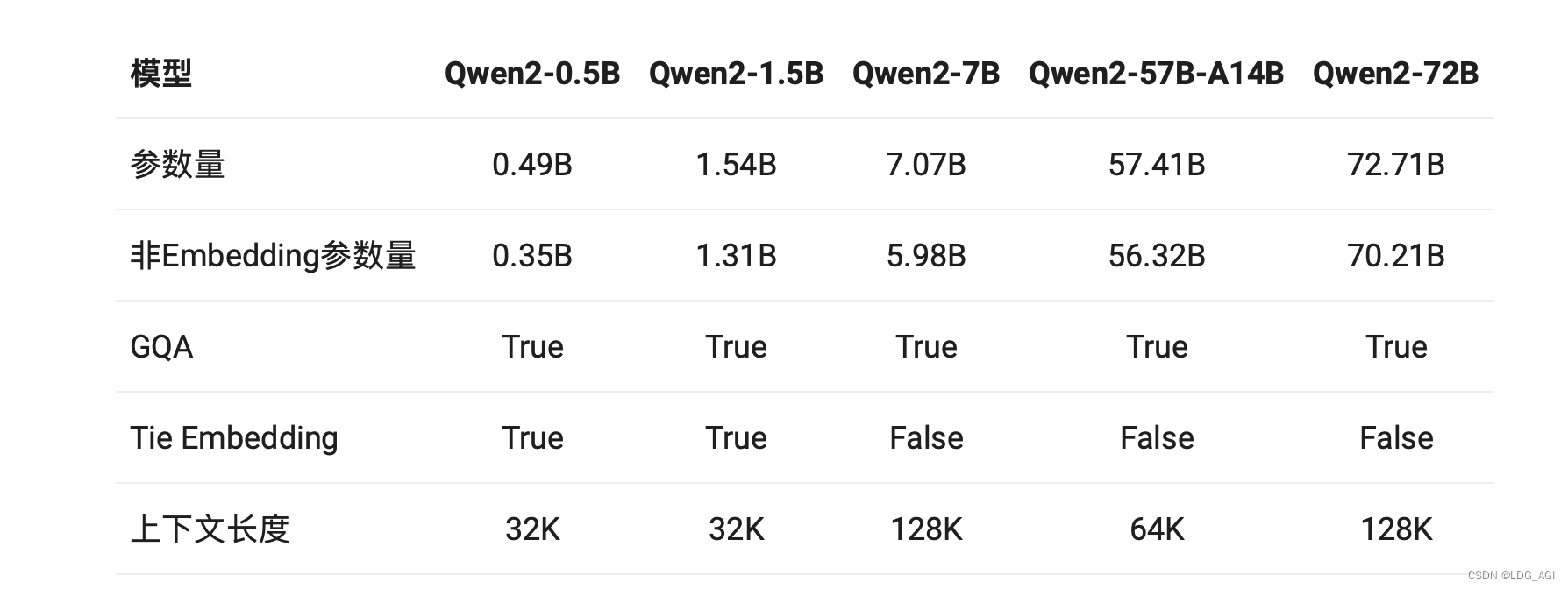
- GQA(Внимание группового запрос): В серии Qwen1.5 только модели 32B и 110B используют GQA. На этот раз модели всех размеров используют GQA, что обеспечивает ускорение вывода GQA и снижение использования видеопамяти.
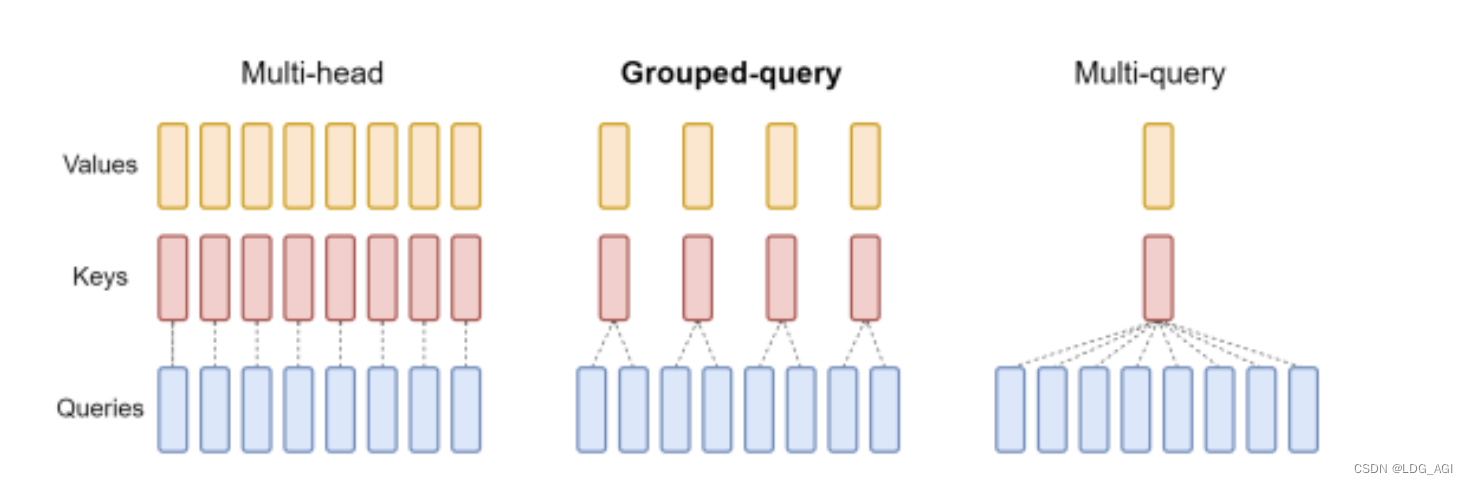
Внимание к групповым запросам — это метод интерполяции между вниманием к множественным запросам (MQA) и вниманием к множеству голов (MHA) в больших языковых моделях. Его цель — поддерживать скорость MQA при сохранении качества MHA.
- tie встраивание: для маленькой модели из-за большого количества параметров встраивания используется связь. метод встраивания допускает входную и выходную слой Общие параметры, увеличение доли невстраиваемых параметров
Сравнение эффектов:
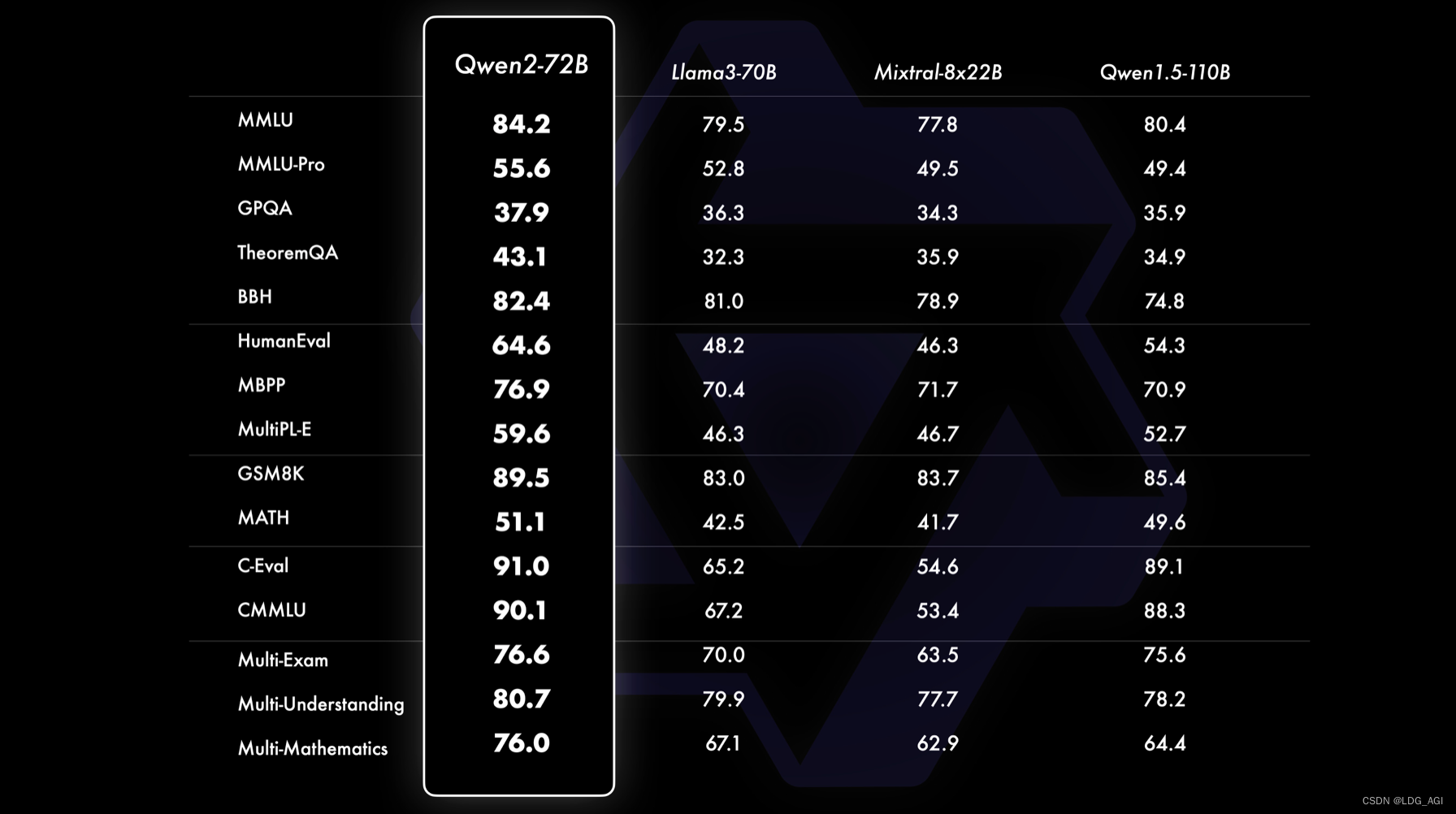
Qwen2-72B может окружать и подавлять Llama3-70B во всех направлениях. В то же время он также значительно улучшен по сравнению с более крупным Qwen1.5-110B. По словам чиновника, это связано с «оптимизацией данных предварительной подготовки и методов обучения». ."
2.2 Архитектура модели Qwen2
Qwen2 по-прежнему представляет собой типичную структуру большой модели преобразователя, состоящую только из декодера.,В основном включаютслой ввода текста、слой внедрения、слой декодера、выходной слойифункция потерь
проходитьAutoModelForCausalLMПроверятьQwen1.5-7B-ChatиQwen2-7B-Instructиз Модельструктура,Сравнивая config.json, мы обнаружили:

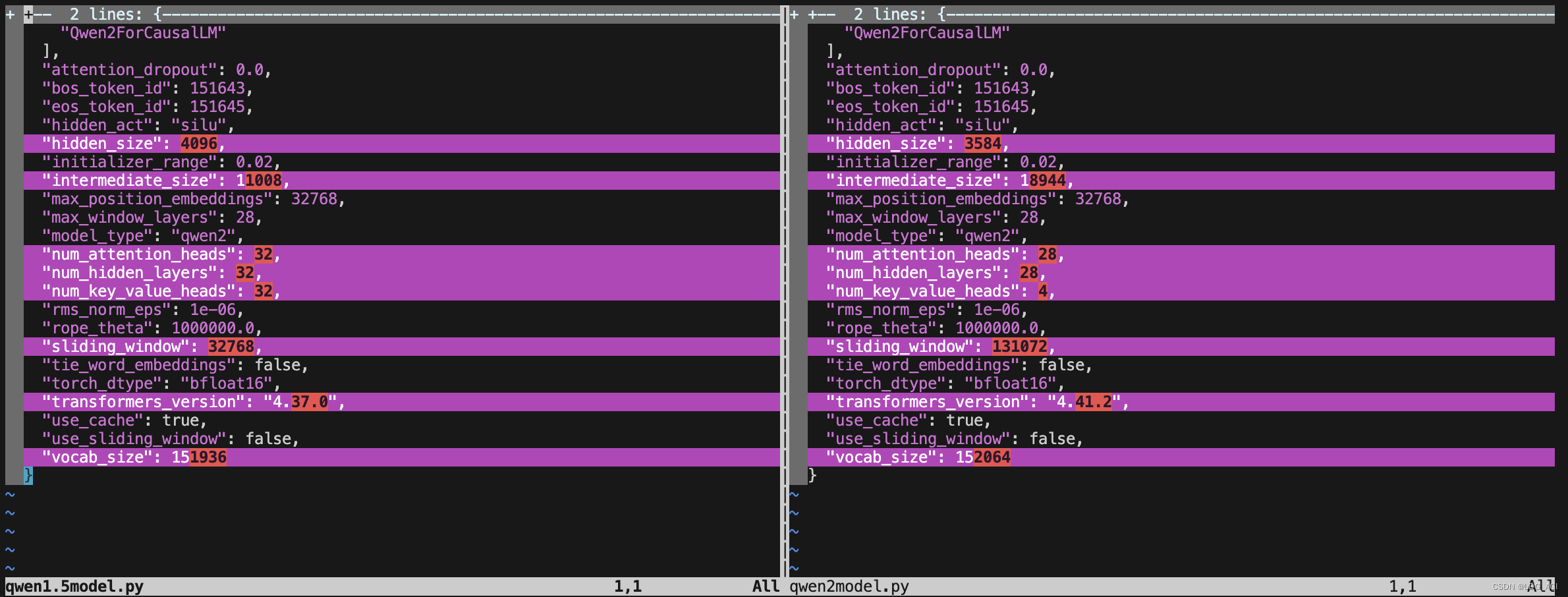
- структура сети: существенных изменений нет
- Слой CoreQwen2DecoderLayer: количество слоев уменьшено с 32 до 28 (72B — 80 слоев).
- Размер скрытого слоя Q, K, V, O: уменьшен с 4096 до 3584 (72B = 8192).
- внимание головы: уменьшено с 32 до 28 (72B = 64)
- КВ головы: уменьшено с 32 до 4 (72Б = 8)
- Скользящее окно (Размер модели): увеличено с 32768 (32К) до 131072 (128К) (как и 72Б)
- Список слов: увеличен с 151936 до 152064 (так же, как 72B).
- промежуточный_размер (межуровневый уровень MLP): увеличен с 11008 до 18944 (72B — 29568).
Вы можете видеть, что некоторые параметры увеличиваются, а некоторые уменьшаются. Предполагается:
- приведенные параметры,Это не уменьшит эффект модели.,Напротив, это может повысить эффективность обучения и вывода.,
- Увеличенные параметры: например, промежуточный_размер в MLP.,Чем больше параметров,Чем выразительнее Модель.
3. Обучение и вывод
3.1 Обучение модели Qwen2
существовать[Машинное обучение] Qwen1.5-14B-Chat Обучение большим моделям и практика вывода , мы используем веб-интерфейс LLaMA-Factory. Сегодня мы перейдем к методу командной строки. Для развертывания фреймворка LLaMA-Factory вы можете обратиться к моей предыдущей статье:
Эта статья занимает первое место в статье Baidu «Развертывание фабрики LLaMA»:
Предположим, что вы развернули контейнер llama_factory на основе вышеизложенного и запустили его в контейнере.
docker exec -it llama_factory bashСоздайте run_train.sh в каталоге app/.
CUDA_VISIBLE_DEVICES=2 llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path qwen/Qwen2-7B-Instruct \
--finetuning_type lora \
--template qwen \
--flash_attn auto \
--dataset_dir data \
--dataset alpaca_zh \
--cutoff_len 4096 \
--learning_rate 5e-05 \
--num_train_epochs 5.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 10 \
--save_steps 1000 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/Qwen2-7B-Instruct/lora/train_2024-06-09-23-00 \
--fp16 True \
--lora_rank 32 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target q_proj,v_proj \
--val_size 0.1 \
--evaluation_strategy steps \
--eval_steps 1000 \
--per_device_eval_batch_size 2 \
--load_best_model_at_end True \
--plot_loss Trueпотому чтоПредыдущая статьяСосредоточьтесь на ключевых моментахиз Просто внутреннийсетьсредаизLLaMA-Factoryразвертывать,Суть заключается в использовании источника модели modelscope вместо источника модели Huggingface Model.,После запуска этого скрипта,Указанная модель будет автоматически загружена из области видимости.,Вот «qwen/Qwen2-7B-Instruct»,Начать обучение после скачивания
Данные обучения можно настроить с помощью файла LLaMA-Factory/data/dataset_info.json, а формат относится к другим файлам данных в каталоге данных. Например, соберите его в формате типа LLaMA-Factory/data/alpaca_zh_demo.json.
Скопируйте копию в LLaMA-Factory/data/dataset_info.json для конфигурации:

3.2 Вывод модели Qwen2
Qwen2изОфициальная документацияРазличные рассуждения по оптимизации представлены вразвертыватьиз Способ,в том числе на базе ВЧ трансформаторы, vllm, llama.cpp, Ollama и методы квантования, такие как AWQ, GPTQ и GGUF, главным образом потому, что Qwen2 с открытым исходным кодом Qwen2-72B и Qwen1.5-110B намного больше, чем модели небольшого размера с открытым исходным кодом 10B, такие как GLM4 и Байчуань. Необходимо учитывать вопросы количественного анализа и распределенного рассуждения. Сегодня мы сосредоточены на внедрении ВЧ Qwen2-7B-Instruct в отечественную сетевую среду. Тест вывода трансформаторов, другие методы будут подробно описаны на отдельных страницах.
Отправьте минималистичный код, общий для glm-4-9b-chat и qwen/Qwen2-7B-Instruct:
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM
#model_dir = snapshot_download('ZhipuAI/glm-4-9b-chat')
model_dir = snapshot_download('qwen/Qwen2-7B-Instruct')
#model_dir = snapshot_download('baichuan-inc/Baichuan2-13B-Chat')
import torch
device = "auto" # Вы также можете указать графический процессор через «coda:2».
tokenizer = AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_dir,device_map=device,trust_remote_code=True)
print(model)
prompt = «Представляем модель большого языка»
messages = [
{"role": "system", "content": «Вы умный помощник.»},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
"""
gen_kwargs = {"max_length": 512, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**model_inputs, **gen_kwargs)
#print(tokenizer.decode(outputs[0],skip_special_tokens=True))
outputs = outputs[:, model_inputs['input_ids'].shape[1]:] #Удалить префиксы диалога, такие как система и пользователь
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
"""
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)Этот код имеет несколько особенностей:
- сеть:отmodelscopeскачать Модельдокумент,Решить проблему медленной загрузки hfМодель через заголовок AutoModelForCausalLMМодель.
- Универсальный:Применимо кglm-4-9b-chat、qwen/Qwen2-7B-Instruct
apply_chat_template():Уведомление! использоватьгенерировать() заменяет Chat() в старом методе. используется здесьapply_chat_template()Функция преобразует сообщение в формат, понятный Модели. из которыхadd_generation_promptПараметр используется для добавления подсказки сборки к входным данным, указывающей на<|im_start|>assistant\n。-
tokenizer.batch_decode():проходитьtokenizer.batch_decode()Функция декодирует ответ.
Результаты запуска:
В дополнение к этому минималистичному коду я изменил демонстрационный код, предоставленный официальным git для сетевого окружения:
cli_demo:
Используйте заголовки модели AutoModelForCausalLM и AutoTokenizer в modelscope, чтобы заменить заголовки модели, соответствующие преобразователям, для автоматической загрузки модели.
# Copyright (c) Alibaba Cloud.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
"""A simple command-line interactive chat demo."""
import argparse
import os
import platform
import shutil
from copy import deepcopy
from threading import Thread
import torch
from modelscope import AutoModelForCausalLM, AutoTokenizer
from transformers import TextIteratorStreamer
from transformers.trainer_utils import set_seed
DEFAULT_CKPT_PATH = 'Qwen/Qwen2-7B-Instruct'
_WELCOME_MSG = '''\
Welcome to use Qwen2-Instruct model, type text to start chat, type :h to show command help.
(Добро пожаловать в Qwen2-Instruct Модель, введите текст, чтобы начать разговор, :h Показать справку по команде. )
Note: This demo is governed by the original license of Qwen2.
We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, including hate speech, violence, pornography, deception, etc.
(Примечание: эта демонстрация ограничена лицензионным соглашением Qwen2. Мы настоятельно рекомендуем пользователям не распространять и не позволять другим распространять следующий контент, включая, помимо прочего, вредную информацию, связанную с разжиганием ненависти, насилием, порнографией и мошенничество.)
'''
_HELP_MSG = '''\
Commands:
:help / :h Show this help message Показать справочную информацию
:exit / :quit / :q Exit the demo Выйти из демо-версии
:clear / :cl Clear screen очистить экран
:clear-history / :clh Clear history Очистить историю разговоров
:history / :his Show history Показать историю разговоров
:seed Show current random seed Показать текущее случайное начальное число
:seed <N> Set random seed to <N> Установить случайное начальное число
:conf Show current generation config Показать конфигурацию сборки
:conf <key>=<value> Change generation config Изменить конфигурацию сборки
:reset-conf Reset generation config Сбросить конфигурацию сборки
'''
_ALL_COMMAND_NAMES = [
'help', 'h', 'exit', 'quit', 'q', 'clear', 'cl', 'clear-history', 'clh', 'history', 'his',
'seed', 'conf', 'reset-conf',
]
def _setup_readline():
try:
import readline
except ImportError:
return
_matches = []
def _completer(text, state):
nonlocal _matches
if state == 0:
_matches = [cmd_name for cmd_name in _ALL_COMMAND_NAMES if cmd_name.startswith(text)]
if 0 <= state < len(_matches):
return _matches[state]
return None
readline.set_completer(_completer)
readline.parse_and_bind('tab: complete')
def _load_model_tokenizer(args):
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path, resume_download=True,
)
if args.cpu_only:
device_map = "cpu"
else:
device_map = "auto"
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
torch_dtype="auto",
device_map=device_map,
resume_download=True,
).eval()
model.generation_config.max_new_tokens = 2048 # For chat.
return model, tokenizer
def _gc():
import gc
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
def _clear_screen():
if platform.system() == "Windows":
os.system("cls")
else:
os.system("clear")
def _print_history(history):
terminal_width = shutil.get_terminal_size()[0]
print(f'History ({len(history)})'.center(terminal_width, '='))
for index, (query, response) in enumerate(history):
print(f'User[{index}]: {query}')
print(f'QWen[{index}]: {response}')
print('=' * terminal_width)
def _get_input() -> str:
while True:
try:
message = input('User> ').strip()
except UnicodeDecodeError:
print('[ERROR] Encoding error in input')
continue
except KeyboardInterrupt:
exit(1)
if message:
return message
print('[ERROR] Query is empty')
def _chat_stream(model, tokenizer, query, history):
conversation = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
]
for query_h, response_h in history:
conversation.append({'role': 'user', 'content': query_h})
conversation.append({'role': 'assistant', 'content': response_h})
conversation.append({'role': 'user', 'content': query})
inputs = tokenizer.apply_chat_template(
conversation,
add_generation_prompt=True,
return_tensors='pt',
)
inputs = inputs.to(model.device)
streamer = TextIteratorStreamer(tokenizer=tokenizer, skip_prompt=True, timeout=60.0, skip_special_tokens=True)
generation_kwargs = dict(
input_ids=inputs,
streamer=streamer,
)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
for new_text in streamer:
yield new_text
def main():
parser = argparse.ArgumentParser(
description='QWen2-Instruct command-line interactive chat demo.')
parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,
help="Checkpoint name or path, default to %(default)r")
parser.add_argument("-s", "--seed", type=int, default=1234, help="Random seed")
parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")
args = parser.parse_args()
history, response = [], ''
model, tokenizer = _load_model_tokenizer(args)
orig_gen_config = deepcopy(model.generation_config)
_setup_readline()
_clear_screen()
print(_WELCOME_MSG)
seed = args.seed
while True:
query = _get_input()
# Process commands.
if query.startswith(':'):
command_words = query[1:].strip().split()
if not command_words:
command = ''
else:
command = command_words[0]
if command in ['exit', 'quit', 'q']:
break
elif command in ['clear', 'cl']:
_clear_screen()
print(_WELCOME_MSG)
_gc()
continue
elif command in ['clear-history', 'clh']:
print(f'[INFO] All {len(history)} history cleared')
history.clear()
_gc()
continue
elif command in ['help', 'h']:
print(_HELP_MSG)
continue
elif command in ['history', 'his']:
_print_history(history)
continue
elif command in ['seed']:
if len(command_words) == 1:
print(f'[INFO] Current random seed: {seed}')
continue
else:
new_seed_s = command_words[1]
try:
new_seed = int(new_seed_s)
except ValueError:
print(f'[WARNING] Fail to change random seed: {new_seed_s!r} is not a valid number')
else:
print(f'[INFO] Random seed changed to {new_seed}')
seed = new_seed
continue
elif command in ['conf']:
if len(command_words) == 1:
print(model.generation_config)
else:
for key_value_pairs_str in command_words[1:]:
eq_idx = key_value_pairs_str.find('=')
if eq_idx == -1:
print('[WARNING] format: <key>=<value>')
continue
conf_key, conf_value_str = key_value_pairs_str[:eq_idx], key_value_pairs_str[eq_idx + 1:]
try:
conf_value = eval(conf_value_str)
except Exception as e:
print(e)
continue
else:
print(f'[INFO] Change config: model.generation_config.{conf_key} = {conf_value}')
setattr(model.generation_config, conf_key, conf_value)
continue
elif command in ['reset-conf']:
print('[INFO] Reset generation config')
model.generation_config = deepcopy(orig_gen_config)
print(model.generation_config)
continue
else:
# As normal query.
pass
# Run chat.
set_seed(seed)
_clear_screen()
print(f"\nUser: {query}")
print(f"\nQwen2-Instruct: ", end="")
try:
partial_text = ''
for new_text in _chat_stream(model, tokenizer, query, history):
print(new_text, end='', flush=True)
partial_text += new_text
response = partial_text
print()
except KeyboardInterrupt:
print('[WARNING] Generation interrupted')
continue
history.append((query, response))
if __name__ == "__main__":
main()web_demo.py:
Как и выше, используйте модельную область вместо преобразователей, чтобы использовать AutoModelForCausalLM и AutoTokenizer для решения проблемы загрузки модели.
Входные параметры: добавьте -g, чтобы указать работающий графический процессор.
# Copyright (c) Alibaba Cloud.
#
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
"""A simple web interactive chat demo based on gradio."""
from argparse import ArgumentParser
from threading import Thread
import gradio as gr
import torch
from modelscope import AutoModelForCausalLM, AutoTokenizer
from transformers import TextIteratorStreamer
DEFAULT_CKPT_PATH = 'Qwen/Qwen2-7B-Instruct'
def _get_args():
parser = ArgumentParser()
parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,
help="Checkpoint name or path, default to %(default)r")
parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")
parser.add_argument("--share", action="store_true", default=False,
help="Create a publicly shareable link for the interface.")
parser.add_argument("--inbrowser", action="store_true", default=False,
help="Automatically launch the interface in a new tab on the default browser.")
parser.add_argument("--server-port", type=int, default=18003,
help="Demo server port.")
parser.add_argument("--server-name", type=str, default="127.0.0.1",
help="Demo server name.")
parser.add_argument("-g","--gpus",type=str,default="auto",help="set gpu numbers")
args = parser.parse_args()
return args
def _load_model_tokenizer(args):
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path, resume_download=True,
)
if args.cpu_only:
device_map = "cpu"
elif args.gpus=="auto":
device_map = args.gpus
else:
device_map = "cuda:"+args.gpus
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
torch_dtype="auto",
device_map=device_map,
resume_download=True,
).eval()
model.generation_config.max_new_tokens = 2048 # For chat.
return model, tokenizer
def _chat_stream(model, tokenizer, query, history):
conversation = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
]
for query_h, response_h in history:
conversation.append({'role': 'user', 'content': query_h})
conversation.append({'role': 'assistant', 'content': response_h})
conversation.append({'role': 'user', 'content': query})
inputs = tokenizer.apply_chat_template(
conversation,
add_generation_prompt=True,
return_tensors='pt',
)
inputs = inputs.to(model.device)
streamer = TextIteratorStreamer(tokenizer=tokenizer, skip_prompt=True, timeout=60.0, skip_special_tokens=True)
generation_kwargs = dict(
input_ids=inputs,
streamer=streamer,
)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
for new_text in streamer:
yield new_text
def _gc():
import gc
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
def _launch_demo(args, model, tokenizer):
def predict(_query, _chatbot, _task_history):
print(f"User: {_query}")
_chatbot.append((_query, ""))
full_response = ""
response = ""
for new_text in _chat_stream(model, tokenizer, _query, history=_task_history):
response += new_text
_chatbot[-1] = (_query, response)
yield _chatbot
full_response = response
print(f"History: {_task_history}")
_task_history.append((_query, full_response))
print(f"Qwen2-Instruct: {full_response}")
def regenerate(_chatbot, _task_history):
if not _task_history:
yield _chatbot
return
item = _task_history.pop(-1)
_chatbot.pop(-1)
yield from predict(item[0], _chatbot, _task_history)
def reset_user_input():
return gr.update(value="")
def reset_state(_chatbot, _task_history):
_task_history.clear()
_chatbot.clear()
_gc()
return _chatbot
with gr.Blocks() as demo:
gr.Markdown("""\
<p align="center"><img src="https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/logo_qwen2.png" style="height: 80px"/><p>""")
gr.Markdown("""<center><font size=8>Qwen2 Chat Bot</center>""")
gr.Markdown(
"""\
<center><font size=3>This WebUI is based on Qwen2-Instruct, developed by Alibaba Cloud. \
(книгаWebUIна основеQwen2-Instructстроить,Внедрить функционал чат-бота。)</center>""")
gr.Markdown("""\
<center><font size=4>
Qwen2-7B-Instruct <a href="https://modelscope.cn/models/qwen/Qwen2-7B-Instruct/summary">🤖 </a> |
<a href="https://huggingface.co/Qwen/Qwen2-7B-Instruct">🤗</a>  |
Qwen2-72B-Instruct <a href="https://modelscope.cn/models/qwen/Qwen2-72B-Instruct/summary">🤖 </a> |
<a href="https://huggingface.co/Qwen/Qwen2-72B-Instruct">🤗</a>  |
 <a href="https://github.com/QwenLM/Qwen2">Github</a></center>""")
chatbot = gr.Chatbot(label='Qwen2-Instruct', elem_classes="control-height")
query = gr.Textbox(lines=2, label='Input')
task_history = gr.State([])
with gr.Row():
empty_btn = gr.Button("🧹 Clear History (Очистить историю)")
submit_btn = gr.Button("🚀 Submit (отправлять)")
regen_btn = gr.Button("🤔️ Regenerate (Попробуйте еще раз)")
submit_btn.click(predict, [query, chatbot, task_history], [chatbot], show_progress=True)
submit_btn.click(reset_user_input, [], [query])
empty_btn.click(reset_state, [chatbot, task_history], outputs=[chatbot], show_progress=True)
regen_btn.click(regenerate, [chatbot, task_history], [chatbot], show_progress=True)
gr.Markdown("""\
<font size=2>Note: This demo is governed by the original license of Qwen2. \
We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, \
including hate speech, violence, pornography, deception, etc. \
(Примечание: эта демонстрация ограничена лицензионным соглашением Qwen2. Мы настоятельно рекомендуем пользователям не распространять и не позволять другим распространять следующий контент:\
Включая, помимо прочего, вредную информацию, связанную с разжиганием ненависти, насилием, порнографией и мошенничеством. )""")
demo.queue().launch(
share=args.share,
inbrowser=args.inbrowser,
server_port=args.server_port,
server_name=args.server_name,
)
def main():
args = _get_args()
model, tokenizer = _load_model_tokenizer(args)
_launch_demo(args, model, tokenizer)
if __name__ == '__main__':
main()4. Резюме
В этой статье сначала объясняется обзор модели Qwen2 и ее архитектура, затем проводится демонстрация обучения модели на основе командной строки llama_factory и, наконец, объясняется вывод модели на основе высокочастотных преобразователей. В процессе было несколько подводных камней, а представленный код гарантированно будет исполняемым в домашней сетевой среде.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
