[Машинное обучение | ARIMA] Лучшие практики определения порядка ARIMA для классических моделей временных рядов. Вы уверены, что хотите взглянуть?

🤵♂️ Персональная домашняя страница: @AI_magician 📡Адрес домашней страницы: Об авторе: CSDN-контент-партнер, качественный создатель в сфере full-stack. 👨💻Видение: стремление расти вместе с большим количеством партнеров, которые любят компьютеры! ! 🐱🏍 🙋♂️заявление:Сейчас я учусь на втором курсе колледжа,Научные интересы Искусственный интеллект&аппаратное обеспечение(虽然аппаратное обеспечение还没开始玩,Но мне всегда было интересно! Надеюсь, вы мне поможете)

[Глубокое обучение | Основные понятия] Вы уверены, что хотите взглянуть на те основные концепции, которые вам необходимо пройти на пути к глубокому обучению? (1) Автор: Computer Magician Версия: 1.0 (2023.8.27)
Аннотация: Целью этой серии является популяризация основных концепций, которые необходимо передать на пути к глубокому обучению. Содержание статей собрано и написано блоггерами. Добро пожаловать на поддержку Sanlian! Эта серия будет постоянно обновляться, и основная концептуальная серия будет постоянно обновляться! Приветствую всех подписавшихся
Эта статья содержит столбцы [✨— «Углубленный анализ машинного обучения: комплексное руководство от принципов к приложениям» —✨]
@toc
Решение для заказа ARIMA
имя | представлять | Преимущества и недостатки |
|---|---|---|
Автокорреляционная функция (ACF) и частичная автокорреляционная функция (PACF) | Порядки AR и MA определяются путем наблюдения за цензурой и хвостами изображений ACF и PACF. | Преимущества: Простой и интуитивно понятный, простой для понимания и реализации. Недостатки: для сложных временных рядов интерпретация изображения может быть неясной, поэтому требуется субъективное суждение о положении усечения и хвоста; |
Информационные критерии (AIC, BIC) | Используйте AIC (информационный критерий Акаике) или BIC (байесовский информационный критерий), чтобы выбрать лучший порядок модели. | Преимущества: На основе статистических принципов порядок модели может выбираться автоматически. Недостатки: Для крупномасштабных наборов данных требуются большие вычислительные затраты. |
поиск по сетке | Перебирайте комбинации параметров нескольких моделей ARIMA и выбирайте лучшую модель посредством перекрестной проверки или производительности набора проверок. | Преимущества: Возможность найти наилучшую комбинацию параметров. Недостатки: накладные расходы на вычисления велики, необходимо опробовать несколько комбинаций параметров, а вычислительные ресурсы могут быть ограничены; |
Автоматическая АРИМА (auto.arima) | Автоматически выбирайте порядок модели ARIMA и выполняйте поиск и выбор модели на основе критерия AIC. | Преимущества: Автоматизированный процесс, исключающий необходимость ручного выбора заказа модели. Недостатки: Для сложных временных рядов лучшая модель может быть не найдена. |
ACF & PACF Определите порядок
Используйте **Автокорреляционную функцию (ACF) и автокорреляционную функцию (PACF)**, чтобы определить порядок AR и MA. ACF представляет собой корреляцию между наблюдениями и версиями с задержкой, а PACF представляет собой прямую корреляцию между наблюдениями и версиями с задержкой.
Ниже приведены функции рисования и описания ACF (функция автокорреляции) и PACF (функция частичной автокорреляции), а также соответствующий код шаблона.
имя | иллюстрировать | код шаблона |
|---|---|---|
plot_acf | Постройте автокорреляционную функцию (ACF) | plot_acf(x, lags=None, alpha=0.05, use_vlines=True, title='Autocorrelation', zero=False, vlines_kwargs=None, ax=None) |
plot_pacf | Постройте функцию частичной автокорреляции (PACF) | plot_pacf(x, lags=None, alpha=0.05, method='ywunbiased', use_vlines=True, title='Partial Autocorrelation', zero=False, vlines_kwargs=None, ax=None) |
функцияпараметриллюстрировать:
x:Для расчета автокорреляции или частичной автокорреляции данных последовательности。lags:Порядок задержки для построения графика。По умолчаниюNone,Указывает на построение всех порядков задержки.alpha:Доверительный уровень доверительного интервала。По умолчанию0.05,представляет собой уровень достоверности 95%.use_vlines:Следует ли использовать вертикальные линии на графиках для обозначения доверительных интервалов.。По умолчаниюTrue。title:Название рисунка。По умолчанию"Autocorrelation"(автокорреляция)или"Partial Автокорреляция» (частичная автокорреляция).zero:Включить ли нулевую задержку в график(lag)Проволока。По умолчаниюFalse。vlines_kwargs:用于控制垂直Проволока属性的可选параметр。ax:используется для рисования графикиmatplotlibобъект оси。По умолчаниюNone,Указывает на создание нового объекта оси.
Пример кода:
Для классических данных временных рядов вы можете получить их с помощью других специализированных библиотек, например. pandas-datareader、yfinance、Alpha Vantage ждать.
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import pandas as pd
from statsmodels.datasets import get_rdataset
from statsmodels.tsa.arima.model import ARIMA
# Получить набор данных AirPassengers
#data = get_rdataset('AirPassengers').data # Not do stationate
# Пример данных
data = [0, 1, 2, 3, 4, 5,6,7,8,9,10,11,12,13]
# 定义绘制автокорреляция图&частичная корреляцияфункция
def draw_acf_pcf(ts):
sample_size = len(ts)
max_lags = sample_size // 2 - 1 # Установите максимальное количество лагов на уровне 50 % от размера выборки.
plt.figure(facecolor='white', figsize=(10, 8))
plot_acf(ts)
plot_pacf(ts,lags = max_lags)
plt.title('График автокорреляции')
plt.show()При расчете частных коэффициентов корреляции обычно нужно обращать внимание на установку значения количества лагов (nlags), чтобы оно не превышало 50% размера выборки. Это связано с тем, что вычисление частного коэффициента корреляции требует оценки обратной ковариационной матрицы, а вычисление обратной матрицы может стать нестабильным, если количество лагов слишком велико. По умолчанию здесь 50% - 1.
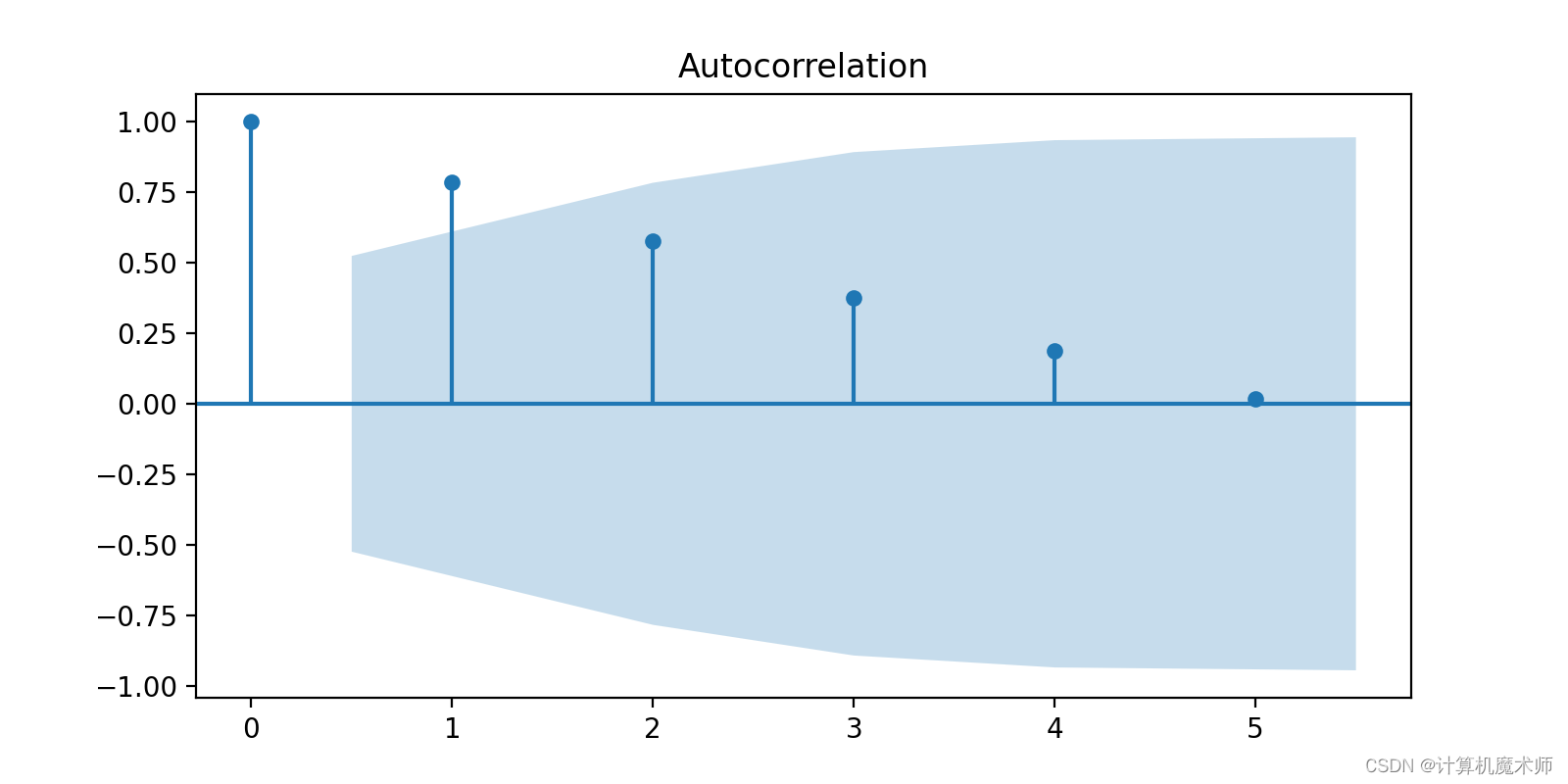
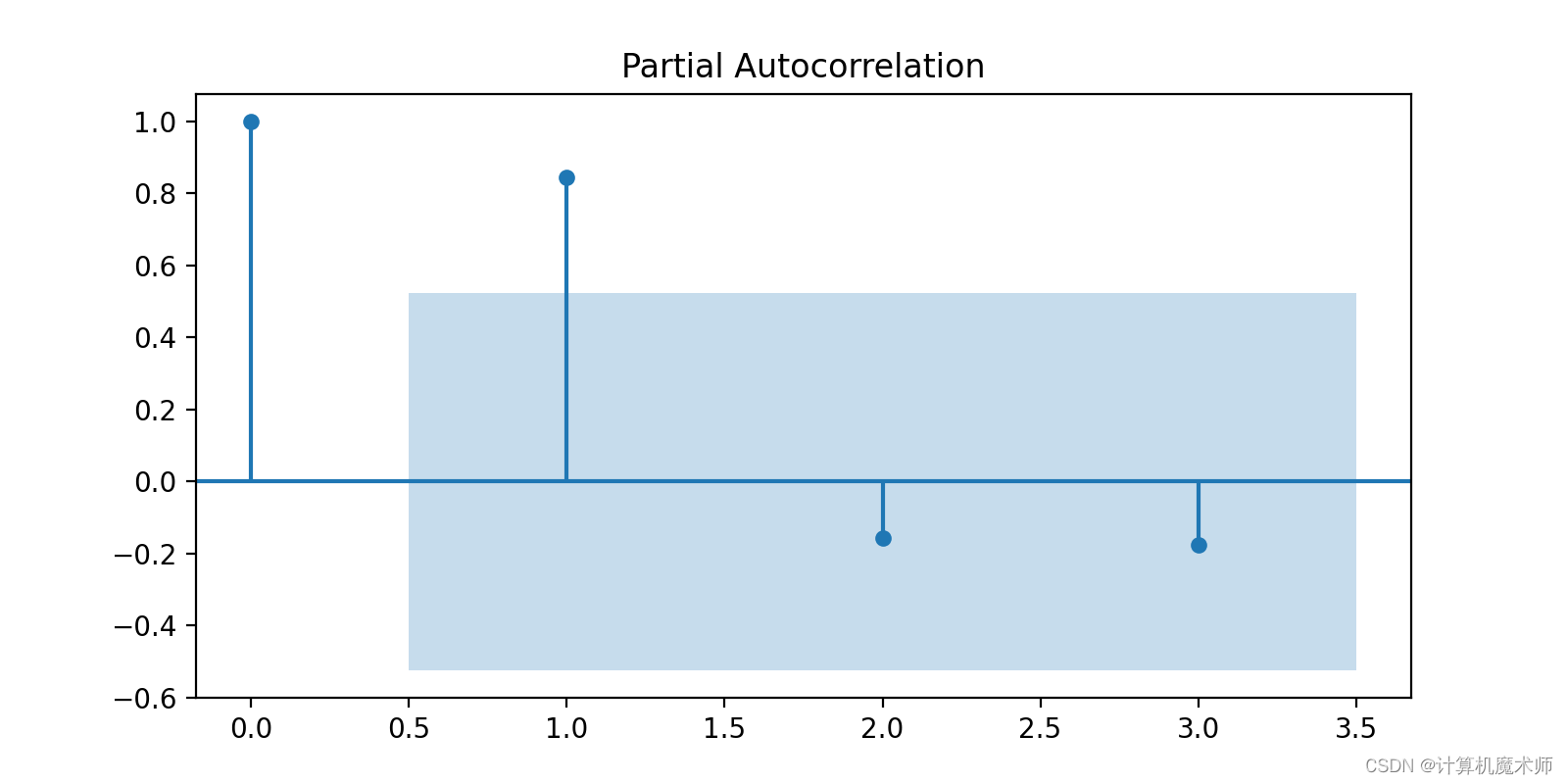
- Обратите внимание на характеристики диаграмм ACF и диаграмм PACF: Сначала,Обратите внимание на характеристики диаграмм ACF и PACF. На диаграмме АКФ,Если коэффициент автокорреляции постепенно затухает и приближается к нулю после порядка запаздывания,Это говорит о том, что можно рассмотреть возможность использования авторегрессии.(AR)Модель(хвостохранилище)。существоватьPACFНа картинке,Если частный коэффициент корреляции равен Цензура после порядка лага и стремится к нулю,Это говорит о том, что можно рассмотреть модель скользящего среднего (MA).(Цензура)
- Обратите внимание на характеристики диаграмм ACF и диаграмм PACF: Сначала,Обратите внимание на характеристики диаграмм ACF и PACF. На диаграмме АКФ,Если коэффициент автокорреляции постепенно затухает и приближается к нулю после порядка запаздывания,Это говорит о том, что можно рассмотреть модель авторегрессии (AR). На диаграмме PACF,Если частный коэффициент корреляции равен Цензура после порядка лага и стремится к нулю,Это говорит о том, что можно рассмотреть модель скользящего среднего (MA).
- Определите порядок ARМодель: В соответствии со свойством Цензура графа ACF определите порядок ARМодель. Порядок можно определить на основе первого порядка задержки на графике ACF, который превышает доверительный интервал.
- Определите порядок MAМодель: В соответствии со свойством Цензура графа PACF определите порядок MAМодель. Порядок можно определить на основе первого порядка задержки на графике PACF, который превышает доверительный интервал.
- Определите порядок модели ARMA: если и график ACF, и график PACF имеют свойства Цензура.,Рассмотрите возможность использования модели ARMA. Порядок может быть определен совместно на основе информации диаграммы ACF и диаграммы PACF.
- Определите порядок ARМодель: В соответствии со свойством Цензура графа ACF определите порядок ARМодель. Порядок можно определить на основе первого порядка задержки на графике ACF, который превышает доверительный интервал.
- Определите порядок MAМодель: В соответствии со свойством Цензура графа PACF определите порядок MAМодель. Порядок можно определить на основе первого порядка задержки на графике PACF, который превышает доверительный интервал.
- Определите порядок модели ARMA: если и график ACF, и график PACF имеют свойства Цензура.,Рассмотрите возможность использования модели ARMA. Порядок может быть определен совместно на основе информации диаграммы ACF и диаграммы PACF.
Видно, что график автокорреляции имеет хвосты, а график корреляции смещения цензурируется во втором порядке, поэтому выбирается ARIMA(2, K, 1).
Информационные критерии (AIC, BIC)Определите порядок
Информация Критерии) — выбор Модели и Определите. порядок(model selection and model order статистические методы определения. Двумя наиболее часто используемыми информационными критериями являются AIC (Akaike Information критерий) и BIC (байесовский Information Criterion)。它们的目标是существоватьПринимая во внимание качество подгонки модели, наказывайте сложность модели.,Избегайте переобучения.
AICиBICпринципы основаны натеория информации。теория информацииэто изучение передачи информации、压缩и表示的数学理论,один из нихВажным понятием является информационная энтропия.(Information Энтропия). Информационная энтропия измеряет неопределенность или информационное содержание случайной величины.
Формула расчета AIC: AIC = 2k - 2ln(L), где k — количество параметров модели, а L — максимальное значение функции правдоподобия. Принцип AIC состоит в том, чтобы подогнать данные путем максимизации функции правдоподобия, а затем наказать за точность соответствия количеством k параметров модели. Чем меньше значение AIC, тем лучше соответствие модели.
Формула расчета BIC: BIC = k * ln(n) - 2ln(L), где k — количество параметров модели, n — размер выборки, а L — максимальное значение функции правдоподобия. Принцип BIC заключается в введении штрафа к размеру выборки n на основе AIC. Чем меньше значение BIC, тем лучше соответствие модели.
Ниже приведен простой пример, иллюстрирующий применение AIC и BIC:
Предположим, у вас есть простая модель линейной регрессии. Порядок модели (т. е. количество переменных) выбирается на основе набора данных.
Предположим, у нас есть следующий набор данных:
X = [1, 2, 3, 4, 5] Y = [2, 4, 6, 8, 10]
Порядки модели, которые мы можем рассмотреть: 1, 2, 3 и 4. Для каждого заказа мы подгоняем соответствующую модель линейной регрессии и рассчитываем значения AIC и BIC.
Когда порядок равен 1, модель Y = β0 + β1X Когда порядок равен 2, модель Y = β0 + β1X + β2X^2 Когда порядок равен 3, модель Y = β0 + β1X + β2X^2 + β3X^3 Когда порядок равен 4, модель Y = β0 + β1X + β2X^2 + β3X^3 + β4X^4
Для каждой модели мы можем рассчитать максимальное значение функции правдоподобия (метод наименьших квадратов), а затем ввести формулы расчета AIC и BIC, чтобы получить соответствующие значения. Предположим, что результаты расчета следующие:
AIC = 10,2, BIC = 12,4 для заказа 1 AIC = 8,5, BIC = 12,0 для заказа 2 AIC = 7,8, BIC = 12,8 для заказа 3 AIC = 9,1, BIC = 15,6 для заказа 4
По значениям AIC и BIC мы можем выбрать в качестве оптимальной модель модель с наименьшими значениями AIC и BIC. В этом случае модель с порядком 3 имеет наименьшие значения AIC и BIC, поэтому мы выбираем модель с порядком 3 как оптимальную.
Этот случай иллюстрирует AIC и BIC в Модели и Определите. порядокпроцесс подачи заявления в。они считают Модель的拟合优度и复杂度,Помогите нам выбрать лучшую модель.,Избегайте переобучения.
Ниже приведена реализация с использованием библиотеки:
# Модель Определите по BIC Matrix порядок
data_w = data_w.astype(float)
pmax = 3 # Можно выбрать по картинке
qmax = 3
bic_matrix = [] # Инициализировать матрицу BIC
for p in range(pmax+1):
tmp = []
for q in range(qmax+1):
try:
tmp.append(ARIMA(data_w, (p, 2, q)).fit().bic)
except:
tmp.append(None)
bic_matrix.append(tmp)
bic_matrix = pd.DataFrame(bic_matrix)
# Найдите минимальную позицию
p, q = bic_matrix.stack().idxmin()
print('Когда BIC минимальный, значения p и q равны: ', p, q)Ниже приведена конкретная реализация кода. Просмотрите детали, чтобы лучше понять принцип.
import numpy as np
from sklearn.linear_model import LinearRegression
from scipy.stats import norm
def calculate_aic(n, k, rss):
aic = 2 * k - 2 * np.log(rss)
return aic
def calculate_bic(n, k, rss):
bic = k * np.log(n) - 2 * np.log(rss)
return bic
# генерировать Пример данных
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
Y = np.array([2, 4, 6, 8, 10])
# Рассчитать значения AIC и BIC для Модели
n = len(X) # размер выборки
aic_values = []
bic_values = []
for k in range(1, 5): # Попробуйте разные уровни
model = LinearRegression()
model.fit(X[:, :k], Y)
y_pred = model.predict(X[:, :k])
rss = np.sum((Y - y_pred) ** 2) # Остаточная сумма квадратов
aic = calculate_aic(n, k, rss)
bic = calculate_bic(n, k, rss)
aic_values.append(aic)
bic_values.append(bic)
# Выберите порядок оптимальной Модели.
best_aic_index = np.argmin(aic_values)
best_bic_index = np.argmin(bic_values)
best_aic_order = best_aic_index + 1
best_bic_order = best_bic_index + 1
print("AIC values:", aic_values)
print("BIC values:", bic_values)
print("Best AIC order:", best_aic_order)
print("Best BIC order:", best_bic_order)Фактически, в машинном обучении в качестве значений потерь используются параметры и остатки, и выбирается тот, у которого значение потерь наименьшее.

🤞Здесь, если у вас остались вопросы🤞
🎩Присылайте блоггерам личные сообщения с вопросами, и блоггеры постараются ответить на ваши вопросы! 🎩
🥳Если вам было полезно, то ваш лайк – лучшая поддержка для блогера! ! 🥳


Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
