Машинное обучение-11-Поиск текста изображения на основе мультимодального объединения функций
Подвести итог
Эта серия представляет собой серию курсов по машинному обучению, которые в основном знакомят с технологией поиска текста по изображениям в машинном обучении. Эта технология сочетает в себе обработку естественного языка и обработку изображений.
ссылка
2024 (12-е место) Конкурс по интеллектуальному анализу данных "Teddy Cup"
Цели этого курса
Завершите весь процесс применения алгоритма в конкретной отрасли:
Понимание бизнеса + умение выбирать подходящие алгоритмы + обработка данных + обучение алгоритмам + настройка алгоритмов + объединение алгоритмов. +Оценка алгоритма+Постоянная оптимизация+Инжиниринговая реализация интерфейса
Определение машинного обучения
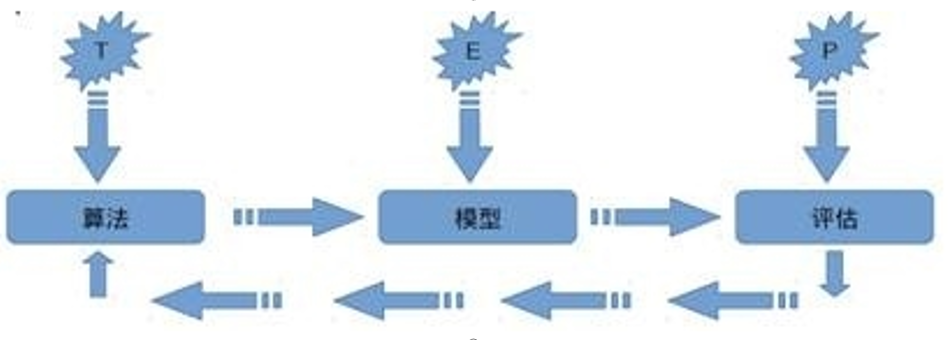
Об определении машинного обучения Том Michael Широко цитируются слова Митчелла: дляОпределенный тип задачи ТиПоказатель производительностиP,Если компьютерная программаЕго показатели P на T улучшаются с опытом E.,Затем мы называем эту компьютерную программуУчитесь на опытеE。
Извлечение текста изображения на основе мультимодального объединения функций
Эта статья взята из2024 (12-е место) Конкурс по интеллектуальному анализу данных "Teddy Cup"Bвопрос。
1. Предыстория проблемы
Благодаря быстрому развитию интеллектуальных терминальных устройств и мультимедийных платформ социальных сетей в последние годы наблюдается тенденция массового роста мультимедийных данных. Сегодняшние основные платформы социальных сетей наводнены огромными мультимодальными медиа-данными, такими как текст и изображения, что также приводит к увеличению количества мультимедийных данных. понимание людьми разных вещей. Растет потребность во взаимном поиске модальных данных. Эффективный поиск и анализ информации может значительно улучшить использование мультимодальных данных на платформе и улучшить взаимодействие с пользователем. Однако между различными модальностями существует значительный семантический разрыв, который значительно ограничивает анализ массивных мультимодальных данных и эффективный анализ информации. . Таким образом, достижение точного поиска кросс-модальной информации в массивных данных стало важной задачей, стоящей перед сегодняшним академическим сообществом. Изображения и текст — две распространенные модальности в процессе передачи информации. Интерактивный поиск между ними может не только эффективно преодолеть семантический разрыв и барьеры распределения между зрением и языком, но также способствовать развитию многих приложений, таких как кросс-модальный поиск. , аннотация изображения, визуальный ответ на вопрос и т. д.
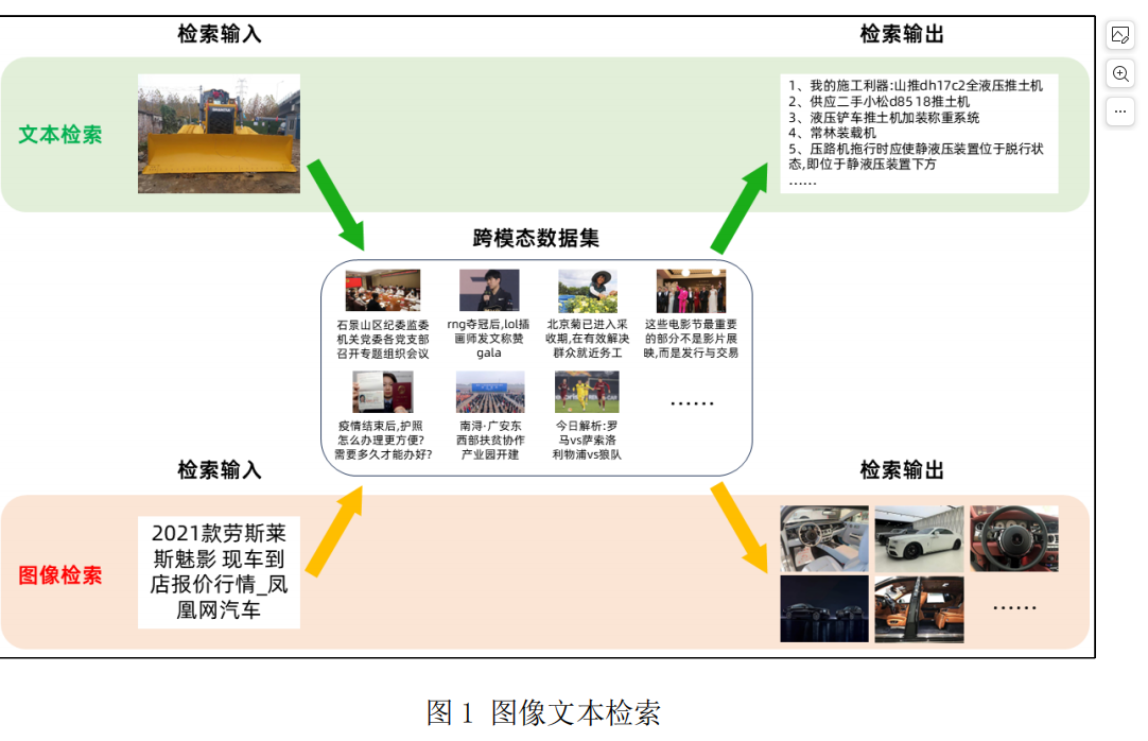
Под извлечением текста изображения подразумевается ввод данных в определенной модальности (например, изображений) и автоматическое получение данных в другой модальности (например, текста), которая наиболее релевантна для нее, через обученную модель. Он включает в себя поиск в двух направлениях, а именно на основе. Поиск текста по изображению и поиск текста на основе изображений, как показано на рисунке 1. Целью поиска изображений на основе текста является поиск изображений, соответствующих входному предложению, из базы данных в качестве выходного результата; при поиске текста на основе изображений на основе входного изображения модель автоматически извлекает из базы данных текст, который может точно описать. содержание изображения. Однако существуют присущие различия в распределении данных между функциями изображений и текста, также известные как «гетерогенный разрыв» между модальностями, что затрудняет измерение семантической корреляции между изображениями и текстом.
2. Решайте проблемы
Этот конкурсный вопрос заключается в том, чтобы использовать набор данных в Приложении 1 для выбора подходящих методов извлечения признаков изображения и текста на основе извлеченных данных о признаках, создать модель и алгоритм мультимодального объединения признаков, подходящие для поиска изображений, а также создать мультимодальную модель объединения признаков. модальная модель и алгоритм объединения функций, подходящие для поиска текста. Мультимодальные модели и алгоритмы объединения функций.
На основе установленной модели «поиск текста изображения с мультимодальным объединением функций» выполните следующие две задачи и отправьте соответствующие материалы.
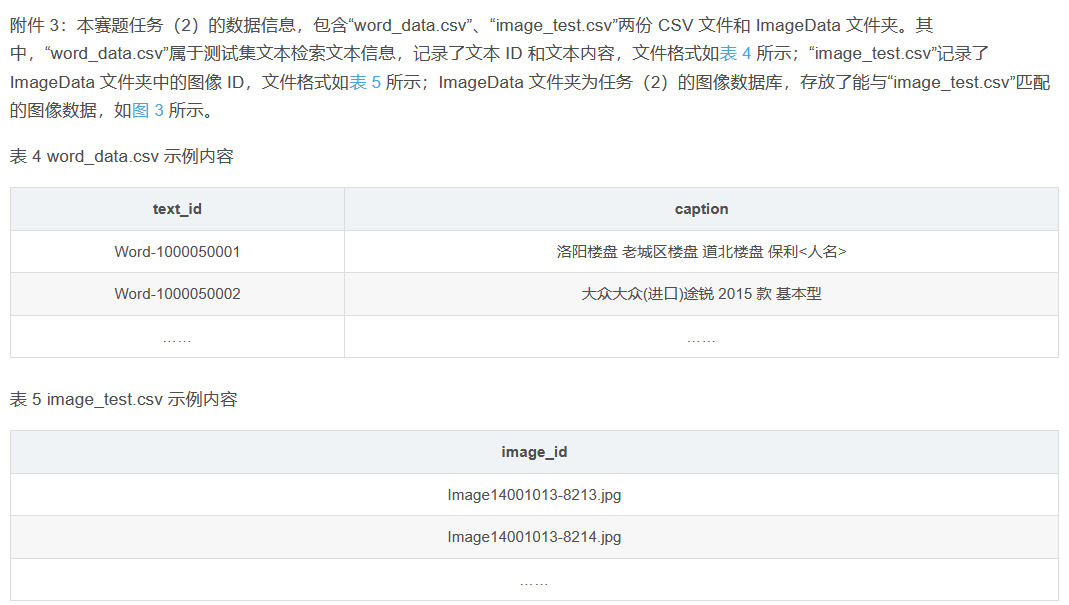
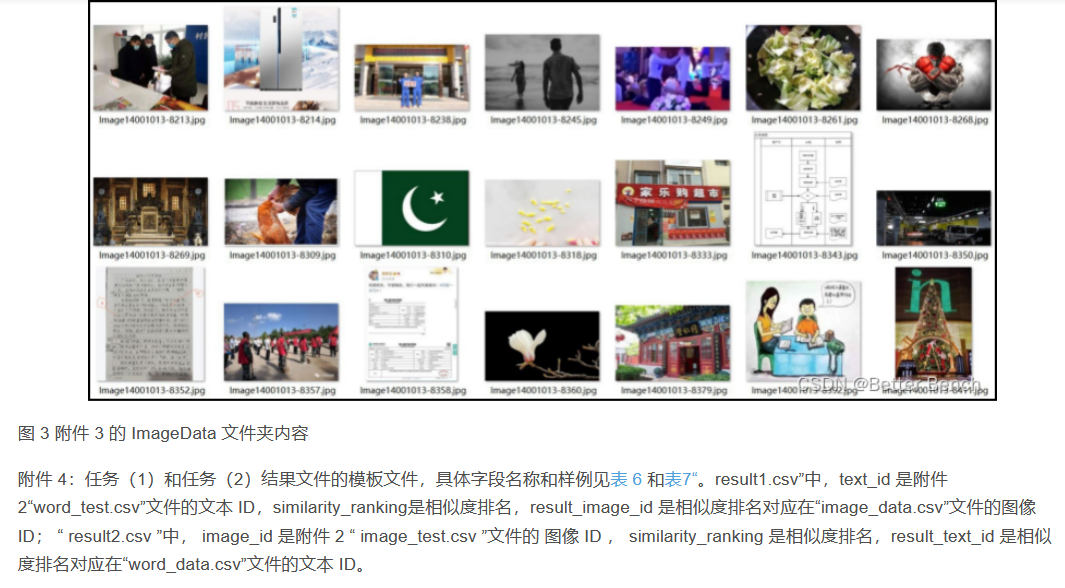
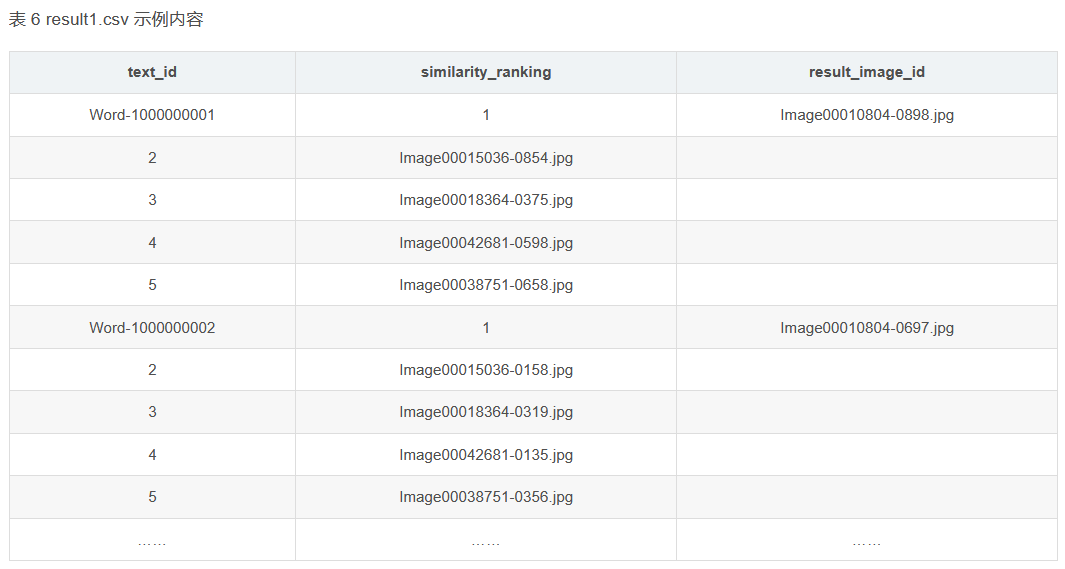
(1) На основе модели и алгоритма поиска изображений используйте текстовую информацию файла «word_test.csv» в Приложении 2, чтобы выполнить поиск изображений по изображениям в папке ImageData Приложения 2, и перечислите пять лучших изображений с более высокое сходство и сохраните результаты в файле «result1.csv» (подробную информацию о файле шаблона см. в разделе result1.csv в Приложении 4). Среди них идентификатор изображения в папке ImageData подробно описан в файле image_data.csv в Приложении 2.
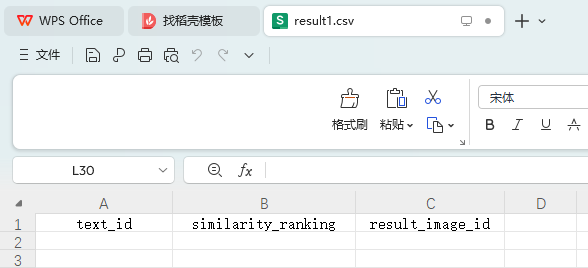
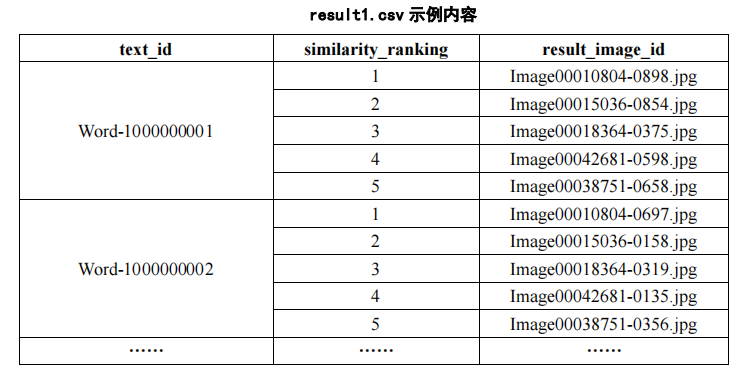
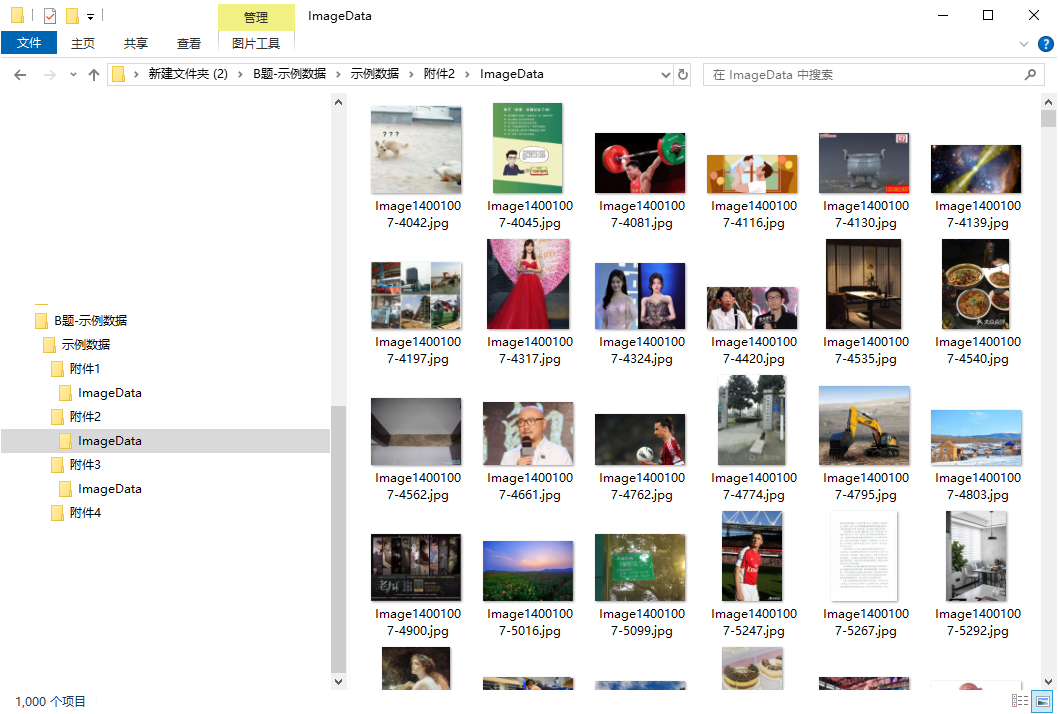
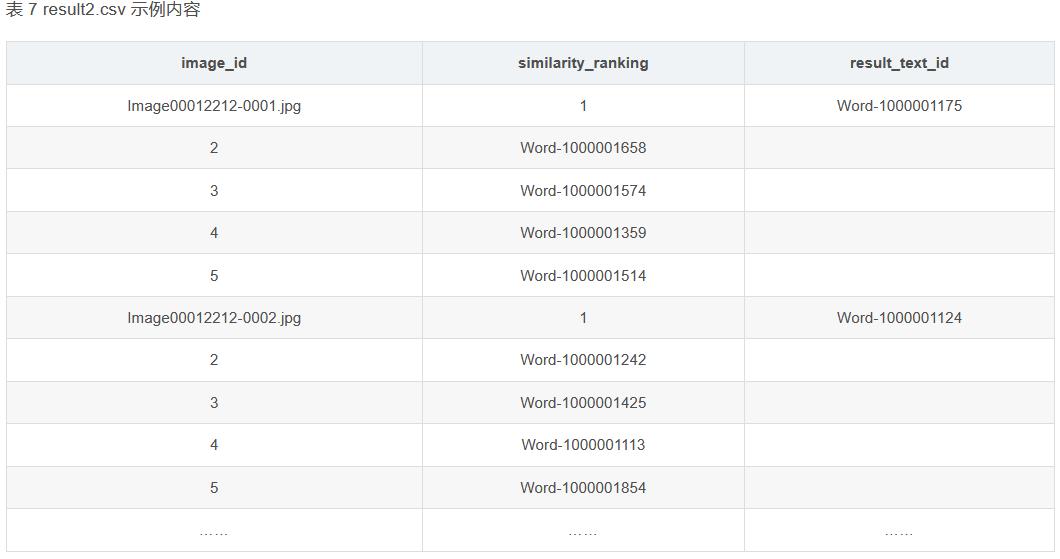
(2) На основе модели и алгоритма поиска текста используйте идентификатор изображения, указанный в файле «image_test.csv» в Приложении 3, для выполнения поиска текста в файле «word_data.csv» в Приложении 3, и перечислите самые популярные поисковые запросы. результаты с более высоким сходством. Пять фрагментов текста и сохраните результаты в файле «result2.csv» (файл шаблона см. в разделе result2.csv в Приложении 4). Среди них идентификатор изображения, указанный в файле «image_test.csv», и соответствующие данные изображения можно получить в папке ImageData в Приложении 3.
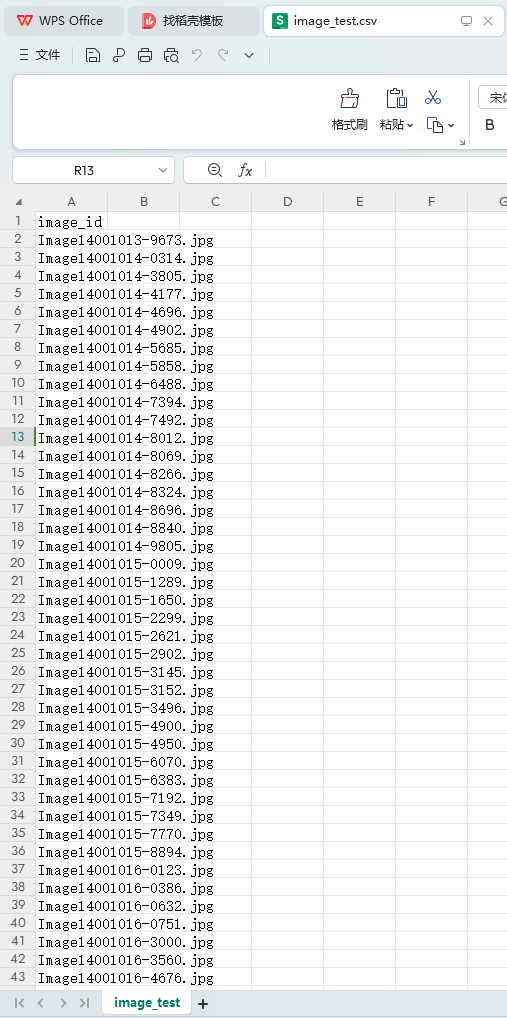
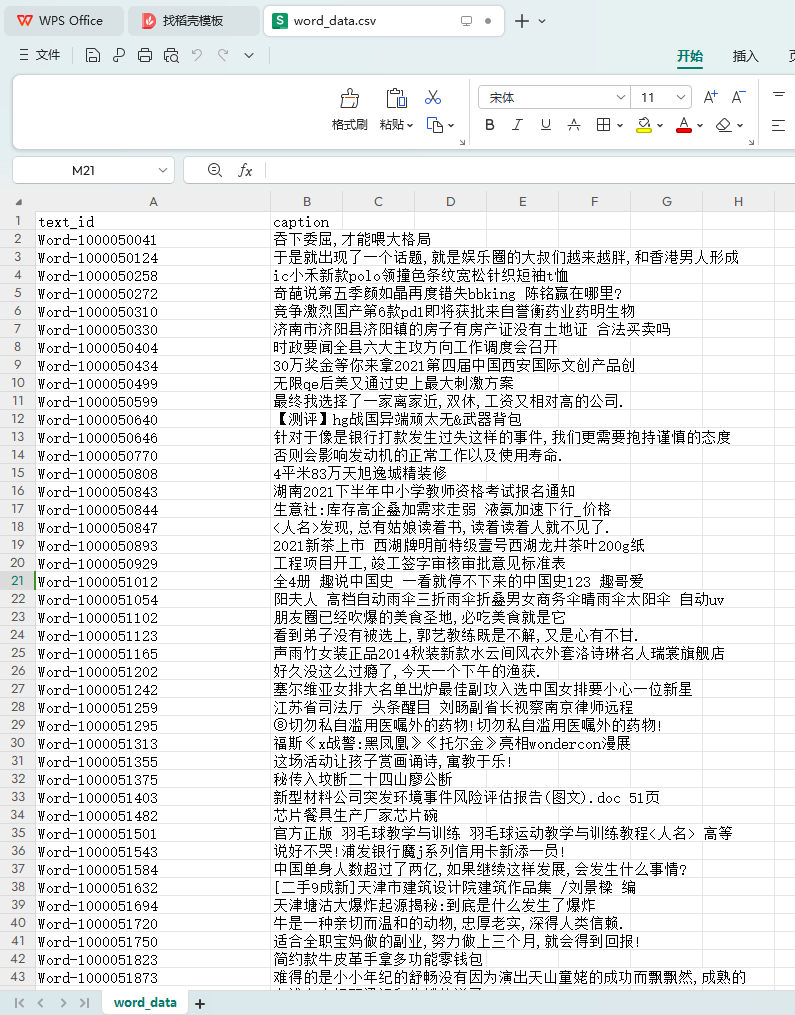
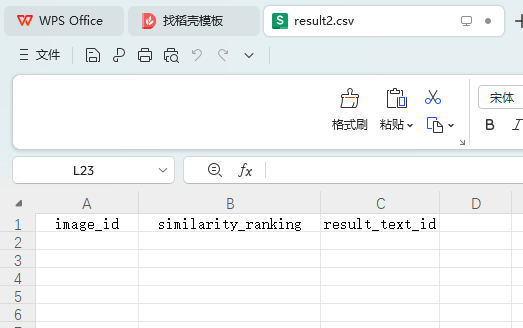
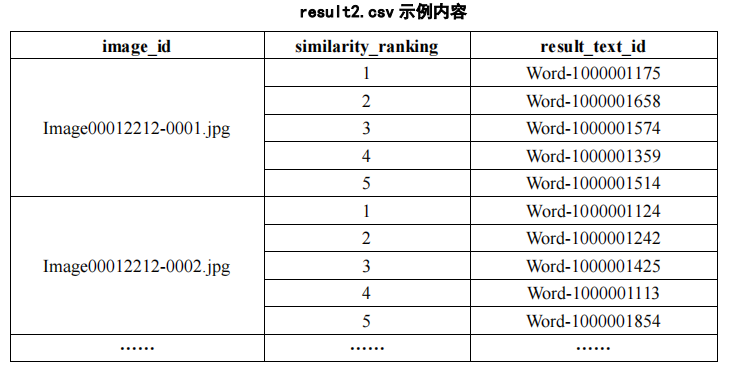
3. Критерии оценки

4. Анализ проблемы
Эта проблема разделена на две части для анализа: мультимодальная модель объединения признаков и алгоритм поиска изображений, а также мультимодальная модель объединения признаков и алгоритм поиска текста.
(1) Извлечение признаков изображения Прежде всего, вам необходимо выбрать подходящий метод для извлечения признаков из изображения. К распространенным методам извлечения признаков изображения относятся: SIFT (масштабно-инвариантное преобразование признаков), SURF (ускорение робастных признаков), HOG (гистограмма ориентированных градиентов). сеть CNN (сверточная нейронная сеть) и т. д.
(2) Извлечение текстовых объектов Для текстовых данных вы можете использовать традиционную модель «мешка слов» или более продвинутые модели внедрения слов (такие как Word2Vec, FastText и т. д.) для извлечения текстовых функций.
(3) Мультимодальные модели и алгоритмы объединения функций После получения характеристик изображений и текста соответственно создается мультимодальная модель объединения функций для интеграции этих функций. Общие модели включают в себя: векторную конкатенацию (Concatenation), двунаправленный кодер (Bi-Encoder), модель трансформатора, многослойный перцептрон (MLP), механизм внимания (Attention).
(4) Удельная функция потерь В мультимодальных моделях для обучения модели необходимо учитывать соответствующую функцию потерь (например, триплетную потерю, контрастную потерю и т. д.), чтобы модель могла лучше изучить способность представления мультимодального слияния признаков.
5. Мультимодальная отправка документов и кодов.
(1) «X-ModalNet: полупарная кросс-модальная сеть для обнаружения заметных объектов RGB-D» (2019) Для задачи обнаружения заметных объектов RGB-D предлагается полупарная кросс-модальная сеть (X-ModalNet). Сеть использует кросс-модальное перекрестное внимание для улучшения представления функций и объединения информации из разных модальностей. Код: https://github.com/CommonClimate/CCA?utm_source=catalyzex.com
(2)SMAN: Stacked multimodal attention network for cross-modal image–text retrieval
(3)Deep canonical correlation analysis with progressive and hypergraph learning for cross-modal retrieval
(4)Многоракурсный канонический корреляционный анализ с несколькими метками для кросс-модального сопоставления и поиска Место: https://github.com/Rushil231100/MVMLCA.
(5)Multi-scale image–text matching network for scene and spatio-temporal images
(6)Совмещенное перекрестное внимание для сопоставления изображения и текста Код: https://github.com/kuanghuei/SCAN
(7) Посмотрите, представьте и сопоставьте: улучшение текстуально-визуального кросс-модального поиска с помощью генеративных моделей Предлагается использовать генеративные модели для улучшения визуального кроссмодального поиска текста. Модель LIM сначала наблюдает за изображением, затем представляет визуальный контент, соответствующий тексту, и, наконец, сопоставляет соответствующие функции.
(8) Адаптивное распознавание текста посредством визуального сопоставления Доступ: https://github.com/tesseract-ocr/tessdoc
(9)LXMERT: Изучение представлений кросс-модального кодера от преобразователей Код: https://paperswithcode.com/paper/lxmert-learning-cross-modality-encoder
(10)Изучение богатых сенсорных представлений посредством кросс-модального самоконтроля Место: https://github.com/google-deepmind/deepmind-research
(11)CLaMP: Предварительная тренировка контрастного языка и музыки для кросс-модального поиска символической музыкальной информации Место: https://github.com/microsoft/muzic
(12)UniXcoder: унифицированное межмодальное предварительное обучение представлению кода Доступ: https://github.com/microsoft/CodeBERT
(13)mPLUG: Эффективное и действенное обучение визуальному языку с помощью кросс-модальных пропускных соединений Код: https://paperswithcode.com/paper/mplug-efficient-and-efficient-vision-language
6. Установленная модель «поиска текста изображения с мультимодальным объединением функций».
Задача 1. Идеи
1. Загрузка и предварительная обработка данных:
При чтении файла CSV загружается набор данных изображения и соответствующее текстовое описание. Устанавливает путь к папке изображений, используемой для загрузки файлов изображений.
2. Извлечение признаков:
Извлеките функции изображения, используя предварительно обученную модель VGG16. VGG16 — это широко используемая модель глубокого обучения, обученная на наборе данных ImageNet для извлечения семантических характеристик изображений высокого уровня.
Извлекайте текстовые функции, используя предварительно обученную модель Word2Vec. Word2Vec — это широко используемая векторная модель слов, которая может преобразовывать текст в плотное векторное представление и фиксировать семантические отношения между словами.
3. Слияние функций:
Извлеченные объекты изображения и текстовые объекты объединяются вместе, образуя мультимодальное представление объекта. В этом примере используется простой метод сращивания для прямого соединения объектов изображения и текстовых объектов в качестве входных данных модели.
4. Обучение и тестирование модели:
Разделите набор данных на обучающий набор и тестовый набор и используйте разделенные данные для обучения мультимодальной модели объединения функций. В этом примере в качестве классификатора используется машина опорных векторов (SVM), а в процессе обучения добавляется уменьшение размерности PCA, чтобы уменьшить размерность объекта.
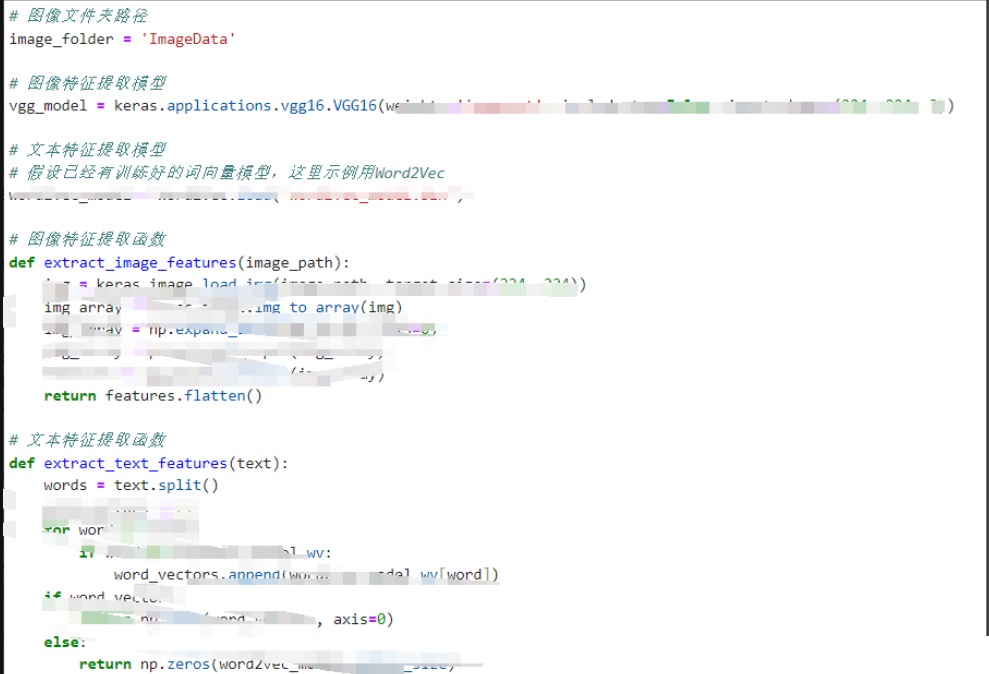

Извлечение признаков изображения:
Используйте предварительно обученные модели глубокого обучения (такие как VGG, ResNet, Inception и т. д.) для извлечения особенностей изображений. Эти модели обучаются на крупномасштабных наборах данных изображений и способны собирать семантическую информацию высокого уровня об изображениях. Признак, извлеченный из каждого изображения, должен представлять собой вектор фиксированной длины, представляющий семантическую информацию изображения.
Извлечение текстовых признаков:
Для обработки текстовых данных вы можете использовать модели встраивания слов (такие как Word2Vec, GloVe, BERT и т. д.) для преобразования текста в векторное представление. Для каждого текста векторное представление всего текста можно получить путем усреднения или взвешивания векторов слов.
Слияние функций:
Элементы изображения и текстовые элементы объединяются, образуя мультимодальное представление объектов. Fusion может использовать простое сращивание, взвешенное усреднение и т. д. Объединенный вектор признаков будет содержать семантическую информацию изображений и текстов, помогая лучше представлять мультимодальные данные.
Расчет сходства:
Используйте соответствующие методы расчета сходства (например, косинусное сходство, евклидово расстояние и т. д.), чтобы вычислить сходство между изображением и текстом. Расчет сходства должен основываться на объединенном векторе признаков. Для расчета сходства можно использовать алгоритм ближайшего соседа (например, k ближайшего соседа), метод на основе расстояния и т. д.
Идеи задачи 2
Основываясь на модели и алгоритме поиска текста, используйте идентификатор изображения, указанный в файле «image_test.csv» в Приложении 3, для выполнения поиска текста в файле «word_data.csv» в Приложении 3, и перечислите пять лучших текстов с более высоким значением. сходства поиска. Сохраните результаты в файле «result2.csv» (файл шаблона см. в разделе result2.csv в Приложении 4). Среди них идентификатор изображения, указанный в файле «image_test.csv», и соответствующие данные изображения можно получить в папке ImageData в Приложении 3 (см. полное вложение в конце статьи).
1.Извлечение текстовых признаков:
Выполните извлечение признаков текстовых данных в Приложении 3. Вы можете использовать предварительно обученные векторные модели слов (например, Word2Vec, GloVe и т. д.) для преобразования текста в векторное представление или использовать технологию внедрения текста (например, BERT, ELMo и т. д.) для получения семантических функций высокого уровня. текста.
2.Извлечение признаков изображения:
Загрузите данные изображения, соответствующие идентификатору изображения, из папки ImageData в Приложении 3. Затем методы обработки изображений (например, модели глубокого обучения) используются для извлечения представлений функций изображения.
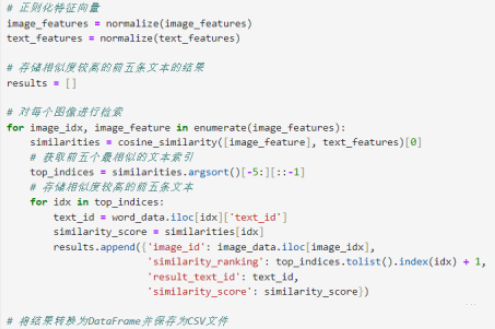
3. Слияние функций:
Объединение текстовых элементов и изображений для формирования мультимодального представления объектов. Их можно просто соединить вместе или объединить с помощью определенных моделей (таких как многослойные перцептроны, механизмы внимания и т. д.).
4.Расчет сходства:
Используйте соответствующие методы расчета сходства (например, косинусное сходство, евклидово расстояние и т. д.), чтобы измерить сходство между изображениями и текстом. Более высокое сходство указывает на более сильную смысловую корреляцию между изображением и текстом.
5. Отображение результатов:
Перечислите пять наиболее похожих текстов и сохраните результаты в указанном файле CSV для последующей отправки. Каждый идентификатор изображения будет иметь список связанных с ним текстовых идентификаторов.
7. реализация кода Python




Задача первая
Метод 1: обучение модели с 0
Требуется реализовать, чтобы для каждой строки текста в word_test.csv в Приложении 2 извлекались 5 наиболее похожих картинок из папки imageData в Приложении 2, сортировались по сходству и выражались по серийным номерам. Во-первых, вам необходимо использовать ImageWordData.csv в Приложении 1 и ImageData в Приложении 1 в качестве обучающего набора для обучения мультимодальной модели, а затем использовать его для тестирования данных в Приложении 2.
(1) Импортный пакет
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
import pandas as pd
import csv
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from gensim.models import Word2Vec,KeyedVectors
import jieba
import gensim
import os
import torch.nn.functional as F(2) Обработка текстовых обучающих данных.
# Обработка текстданных
text_df1 = pd.read_csv("Вложение 1/ImageWordData.csv")
# Определить функцию сегментации китайского слова
def Chinese_tokenizer(text):
return list(jieba.cut(text))
# Выполните сегментацию китайских слов в заголовке
text_data1 = text_df1['caption'].apply(Chinese_tokenizer).tolist()
# Поскольку загрузка word2vec занимает очень много времени, требуется векторная локализация.
file_path = "word2vec/train_vocabulary_vector.csv"
if os.path.exists(file_path):
# Чтение словаря - векторный словарь, csv в словарь
vocabulary_vector = dict(pd.read_csv("word2vec/train_vocabulary_vector.csv"))
# В это время необходимо восстановить данные типа вектора слов np.array в словаре до исходного типа для дальнейшего использования.
for key,value in vocabulary_vector.items():
vocabulary_vector[key] = np.array(value)
word2vec_model = KeyedVectors.load('hy-tmp/train_bio_word',mmap='r')
else:
# Прочитайте векторную модель слова на китайском языке (необходимо заранее скачать соответствующий файл Модель вектора слова)
word2vec_model = KeyedVectors.load_word2vec_format('hy-tmp/word2vec.bz2', binary=False)
word2vec_model.init_sims(replace=True)
word2vec_model.save('hy-tmp/train_bio_word')
# Постройте словарный запас из всего текста,words_cut Это список после сегментации слов, и каждый элемент отделяется пробелами изstr.
vocabulary = list(set([word for item in text_data1 for word in item]))
# Создание словарно-векторного словаря
vocabulary_vector = {}
for word in vocabulary:
if word in word2vec_model:
vocabulary_vector[word] = word2vec_model[word]
# Храните словарь-векторный словарь. Поскольку файлы json не могут хорошо сохранять пустые векторы слов, используйте CSV для их сохранения.
pd.DataFrame(vocabulary_vector).to_csv("word2vec/train_vocabulary_vector.csv")(3) Обработка данных изображения
# Обработка изображенийданные
image_df = pd.read_csv("Вложение 1/ImageWordData.csv")
image_data = image_df['image_id'].tolist()
# предварительная обработка и загрузка данных
transform = transforms.Compose([
transforms.Resize((224, 224)), # Изменение размера изображения по требованию Модельиз
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # Нормализация изображения в соответствии с требованиями Модельиз
])(4) Определить мультимодальные модели обучения и функции потерь.
class ImageEncoder(nn.Module):
def __init__(self, out_dim=128):
super(ImageEncoder, self).__init__()
self.cnn = models.resnet18(pretrained=True)
self.fc = nn.Linear(512, out_dim)
def forward(self, x):
with torch.no_grad():
x = self.cnn.conv1(x)
x = self.cnn.bn1(x)
x = self.cnn.relu(x)
x = self.cnn.maxpool(x)
x = self.cnn.layer1(x)
x = self.cnn.layer2(x)
x = self.cnn.layer3(x)
x = self.cnn.layer4(x)
x = F.adaptive_avg_pool2d(x, (1, 1))
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
class TextEncoder(nn.Module):
def __init__(self,embedding_dim):
super(TextEncoder, self).__init__()
self.rnn = nn.LSTM(embedding_dim, 128, batch_first=True)
def forward(self, x):
# x = x.to(device)
_, (x, __) = self.rnn(x)
x = x.squeeze(1)
return x
class MultimodalCnn(nn.Module):
...немного
return fusion
# Определите функцию контрастных потерь
class ContrastiveLoss(nn.Module):
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2, keepdim=True)
loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +
(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
# Определите евклидову функцию потери расстояния
class EuclideanDistanceLoss(nn.Module):
def __init__(self):
super(EuclideanDistanceLoss, self).__init__()
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2, keepdim=True)
loss = torch.mean(torch.pow(euclidean_distance - label, 2))
return loss
class CosineDistanceLoss(nn.Module):
def __init__(self, margin=0.5):
super(CosineDistanceLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
cos_sim = F.cosine_similarity(output1, output2)
loss = torch.mean((1 - label) * torch.pow(cos_sim, 2) + label * torch.pow(torch.clamp(self.margin - cos_sim, min=0.0), 2))
return loss(4) Модельное обучение
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Вес модели тренировки
image_encoder = ImageEncoder().to(device)
text_encoder = TextEncoder(embedding_dim=300).to(device)
model = MultimodalCnn(image_encoder, text_encoder).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Итеративное обучение Модель
num_epochs = 5
# Создание экземпляра функции контрастных потерь
# criterion = ContrastiveLoss(margin=2.0)
# Евклидова функция потери расстояния
# criterion = EuclideanDistanceLoss()
criterion = CosineDistanceLoss()
for epoch in range(num_epochs):
running_loss = 0.0
for i, (image, text) in enumerate(zip(image_data, text_data1)):
# Загрузить изображение
image_path = «Вложение 1/ImageData/» + image # Путь к папке с изображениями
img = Image.open(image_path)
if img.mode != 'RGB':
# Если изображение не в формате RGB, сначала преобразуйте его в формат RGB.
img = img.convert('RGB')
img = transform(img).unsqueeze(0).to(device)
# Загрузить текст
sentence_vec = [torch.tensor(vocabulary_vector[word], dtype=torch.float) for word in text if word in vocabulary_vector]
# Вычислите среднее значение каждого вектора сегментации слов в предложении и преобразуйте результат в тензор факела.
if len(sentence_vec)>0:
text_sequence = torch.stack(sentence_vec).unsqueeze(0).to(device)
optimizer.zero_grad()
# прямое распространение
...немного
# Обратное распространение ошибки и оптимизация
loss.backward() # Обратное распространение ошибки
optimizer.step() # Обновить веса
running_loss += loss.item()
else:
# Это не вектор из текста
print(text)
# Выведите потери для каждой эпохи
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss / len(image_data)}")
# Сохранить вес модели
torch.save(model.state_dict(), 'models/multimodal_cnn_weights.pth')
(5) Тестирование модели
# Обработка текстданных
text_df = pd.read_csv("Приложение 2/word_test.csv")
# Определить функцию сегментации китайского слова
def Chinese_tokenizer(text):
return list(jieba.cut(text))
# Выполните сегментацию китайских слов в заголовке
text_data = text_df['caption'].apply(Chinese_tokenizer).tolist()
# Поскольку загрузка word2vec занимает очень много времени, требуется векторная локализация.
file_path = "word2vec/test_vocabulary_vector.csv"
if os.path.exists(file_path):
# Чтение словаря - векторный словарь, csv в словарь
vocabulary_vector = dict(pd.read_csv("word2vec/test_vocabulary_vector.csv"))
# В это время необходимо восстановить данные типа вектора слов np.array в словаре до исходного типа для дальнейшего использования.
for key,value in vocabulary_vector.items():
vocabulary_vector[key] = np.array(value)
word2vec_model = KeyedVectors.load('hy-tmp/test_bio_word',mmap='r')
else:
# Прочитайте векторную модель слова на китайском языке (необходимо заранее скачать соответствующий файл Модель вектора слова)
word2vec_model = KeyedVectors.load_word2vec_format('hy-tmp/word2vec.bz2', binary=False)
word2vec_model.init_sims(replace=True)
word2vec_model.save('hy-tmp/bio_word')
# Постройте словарный запас из всего текста,words_cut Это список после сегментации слов, и каждый элемент отделяется пробелами изstr.
vocabulary = list(set([word for item in text_data for word in item]))
# Создание словарно-векторного словаря
vocabulary_vector = {}
for word in vocabulary:
if word in word2vec_model:
vocabulary_vector[word] = word2vec_model[word]
# Храните словарь-векторный словарь. Поскольку файлы json не могут хорошо сохранять пустые векторы слов, используйте CSV для их сохранения.
pd.DataFrame(vocabulary_vector).to_csv("word2vec/test_vocabulary_vector.csv")
# Обработка изображенийданные
image_df = pd.read_csv("Вложение 2/image_data.csv")
image_data = image_df['image_id'].tolist()
# Нагрузка и вес модели
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
image_encoder = ImageEncoder().to(device)
text_encoder = TextEncoder(embedding_dim=300).to(device)
model = MultimodalCnn(image_encoder, text_encoder).to(device)
model.load_state_dict(torch.load('models/multimodal_cnn_weights.pth')) # Загрузите предварительно подготовленные веса(6) Вычислить сходство между вектором текста и вектором изображения.
from collections import defaultdict
d2 = defaultdict(list)
# Сходство магазина
similarity_ranking = []
result_image_id = []
similarity_list = defaultdict(list)
k =1
# Получение изображения
for text_id,text in zip(text_df['text_id'],text_data):
print(f'{k}/{len(text_data)}')
k+=1
# Загрузить текст
sentence_vec = [torch.tensor(vocabulary_vector[word], dtype=torch.float) for word in text if word in vocabulary_vector]
# Вычислите среднее значение каждого вектора сегментации слов в предложении и преобразуйте результат в тензор факела.
text_sequence = torch.stack(sentence_vec).unsqueeze(0).to(device)
text_features = model.text_encoder(text_sequence)
text_features = text_features.to("cpu").detach().numpy()
for image_id in image_data:
image_path = е "Приложение 2/ImageData/{image_id}"
image = Image.open(image_path).convert('RGB')
image = transform(image).unsqueeze(0).to(device)
image_features = model.image_encoder(image)
image_features = image_features.to("cpu").detach().numpy()
similarity = cosine_similarity(text_features, image_features)
similarity_list[text_id].append(similarity)(7) Выберите пять наиболее похожих картинок.
# Выберите топ-5 самых похожих из картинок
result = []
for key, value_list in similarity_list.items():
sorted_value_list = sorted(value_list, reverse=True)
top_three_values = sorted_value_list[:5]
for value in top_three_values:
index = value_list.index(value)
id_value = image_data[index]
rank = top_three_values.index(value) + 1
result.append([key, id_value, rank])
result
(8) Сохраняется как result1.csv.
# Сохраните результаты в файле result1.csv.
result_df = pd.DataFrame(result, columns=['text_id', 'similarity_ranking', 'result_image_id'])
result_df.to_csv('result1.csv', index=False)Способ 2. Используйте предварительно обученную модель
Используя мультимодальную модель, предварительно обученную на Huggingface, при расчете с нулевой выборкой обрабатываются данные текста и изображения, вычисляется их сходство и выбираются 5 изображений с наибольшим сходством.
import os
import pandas as pd
from PIL import Image
import torch
import warnings
warnings.filterwarnings('ignore')
text_test_csv = «Пример данных/вложения 2/word_test.csv»
image_data_csv = «Пример данных/вложения 2/image_data.csv»
image_folder = "Примерные/Приложение 2/ImageData/"
output_csv = "result_data/result1.csv"
# Читать текст и изображенияданные
text_data = pd.read_csv(text_test_csv)
image_data = pd.read_csv(image_data_csv)
# Инициализируйте модель и процессор
model =...немного
processor = ...немного
# Обработка текста и создание функций
text_inputs = processor(text=text_data['caption'].tolist(),padding=True,return_tensors="pt")
with torch.no_grad():
text_features = model.get_text_features(**text_inputs).cpu()
# Обрабатывайте каждое изображение и генерируйте функции
image_features_list = []
for image_id in image_data['image_id']:
image_path = os.path.join(image_folder,image_id)
image = Image.open(image_path)
image_inputs = processor(images=image,return_tensors="pt")
with torch.no_grad():
image_features = model.get_image_features(**image_inputs).cpu()
image_features_list.append(image_features)
image_features = torch.vstack(image_features_list) # Объединены в один Тензор
# Нормализованный вектор признаков
image_features = image_features / image_features.norm(dim=1,keepdim=True)
text_features = text_features / text_features.norm(dim=1,keepdim=True)
# Вычислить сходство между текстом и изображением
similarity = text_features @ image_features.T
# Найдите пятерку наиболее похожих на из
result_records = []
for i,sims in enumerate(similarity):
top_indices = sims.topk(5).indices
for rank,idx in enumerate(top_indices):
result_records.append({
"text_id":text_data.iloc[i]['text_id'],
"similarity_ranking":rank + 1,
"result_image_id":image_data.iloc[int(idx)]['image_id']
})
# Сохранить в файл CSV
result_df = pd.DataFrame(result_records)
result_df.to_csv(output_csv,index=False)
print(f"Получение изображения Заканчивать,Результаты сохранены в {output_csv}").
result_df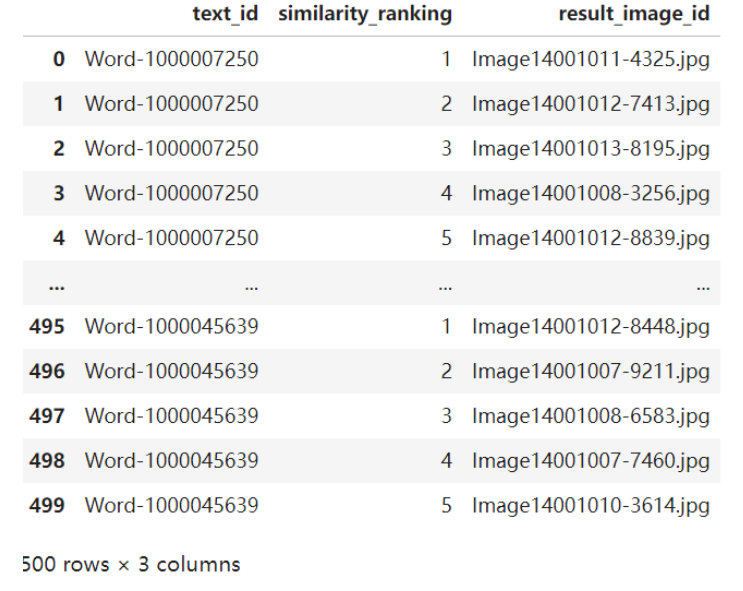
import pandas as pd
import os
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import warnings
warnings.filterwarnings('ignore')
font_path = '/Примерданные/SimHei.ttf'
prop = fm.FontProperties(fname=font_path)
# plt.rcParams['font.sans-serif'] = 'Microsoft YaHei'
result1_csv = "result_data/result1.csv"
# Чтение таблицы result_df
result_df = pd.read_csv(result1_csv)
# Чтение данных изображения 2 картинки в папке
image_folder = «Пример данных/Приложение 2/ImageData»
image_paths = [os.path.join(image_folder,f'{row["result_image_id"]}') for _,row in result_df.iterrows()]
images = [Image.open(image_path) for image_path in image_paths]
# Чтение файла word_test.csv из текстовой информации
text_df = pd.read_csv('Пример данных/Приложение 2/word_test.csv')
# Объединить текстовую информацию с таблицей result_df
result_df = result_df.merge(text_df,on='text_id')
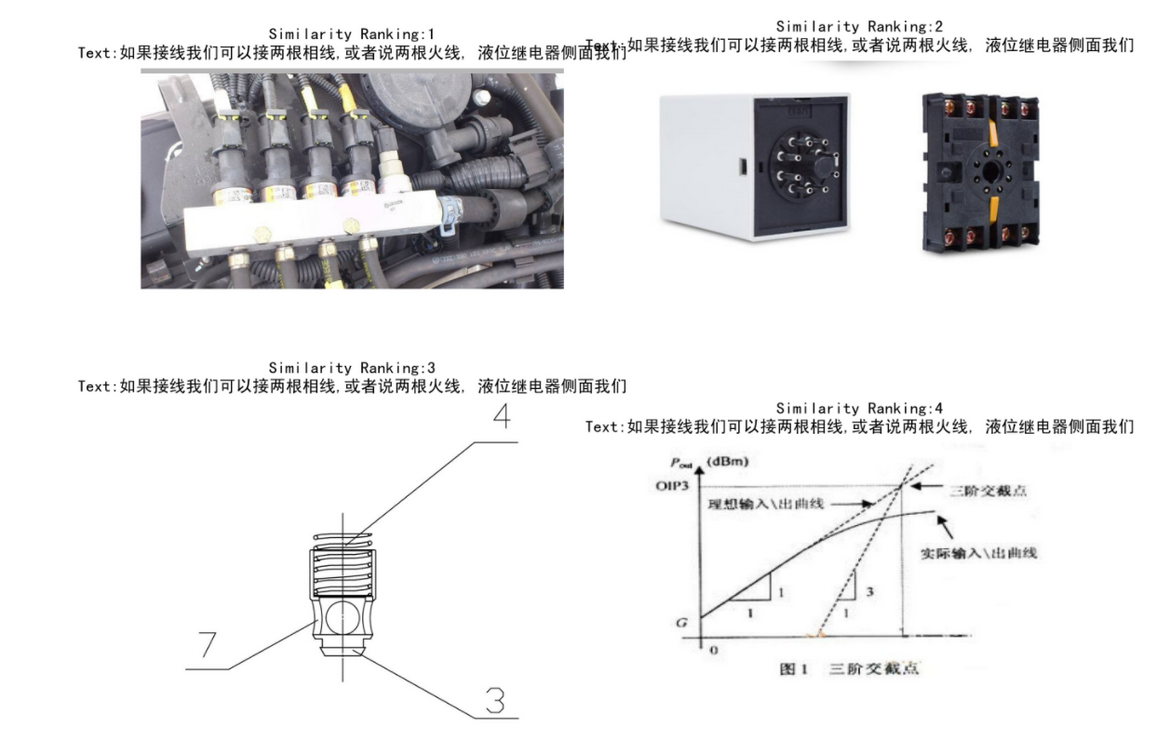
fig,axs = plt.subplots(5,2,figsize=(10,20))
for i in range(10):
row = result_df.iloc[i]
image = images[i]
text = row['caption']
ax = axs[i // 2,i % 2]
ax.imshow(image)
ax.set_title(f'Similarity Ranking:{row["similarity_ranking"]}\nText:{text}',fontproperties=prop)
ax.axis('off')
plt.savefig('result_data/result1.png',dpi=300)
plt.show()

Задача 2
import pandas as pd
from PIL import Image
import torch
import warnings
warnings.filterwarnings('ignore')
# Определение пути к файлу
image_test_csv = "/Примерданные/Приложение 3/image_test.csv"
word_data_csv = "/Примерданные/приложение3/word_data.csv"
image_folder = "/Примерданные/Приложение 3/ImageData/"
output_csv = "result_data/result2.csv"
# Загрузка модели
text_model = ...немного
vision_model = ...немного
processor = ...немного
# Чтение текстовых данных
word_data = pd.read_csv(word_data_csv)
word_data['caption'] = word_data['caption'].astype(str)
# Текст процесса
text_inputs = processor(text=word_data['caption'].tolist(),padding=True,return_tensors="pt",max_length=32,truncation=True).input_ids
# # Вычисление текстовых функций
with torch.no_grad():
text_features = text_model(text_inputs).pooler_output
text_features /= text_features.norm(dim=1,keepdim=True)
# Чтение идентификатора изображения
image_test = pd.read_csv(image_test_csv)
# Список результатов
results = []
# Перебирать каждое изображение
for image_id in image_test['image_id']:
# Загрузить изображение
image_path = f"{image_folder}{image_id}"
image = Image.open(image_path).convert("RGB")
# Обработка изображений
vision_inputs = processor(images=image,return_tensors="pt")
# Рассчитать характеристики изображения
with torch.no_grad():
vision_features = vision_model(**vision_inputs).pooler_output
vision_features /= vision_features.norm(dim=1,keepdim=True)
# Вычислить косинусное сходство между текстовыми изображениями
similarities = (vision_features @ text_features.T).squeeze(0)
# Получите 5 текстов с наибольшим сходством
top5_indices = similarities.topk(5).indices
# Хранить результаты
for rank,index in enumerate(top5_indices):
results.append({
"image_id":image_id,
"similarity_ranking":rank + 1,
"result_text_id":word_data.iloc[int(index)]['text_id']
})
print("Извлечение завершено")
result_df = pd.DataFrame(results)
# Сохраните результаты в CSV документ
result_df = pd.DataFrame(results)
result_df.to_csv(output_csv,index=False)
print("Результаты сохранены",output_csv)
result_df
import pandas as pd
import os
import matplotlib.pyplot as plt
from PIL import Image
import matplotlib.font_manager as fm
import cv2
font_path = '/Примерданные/SimHei.ttf'
prop = fm.FontProperties(fname=font_path)
result2_csv = "result2.csv"
word_data_csv = "/Примерданные/приложение3/word_data.csv"
image_folder = "/Примерданные/Приложение 3/ImageData/"
# Чтение таблицы result_df
result_df = pd.read_csv(result2_csv)
# Прочитать документ word_data.csv
word_data_df = pd.read_csv(word_data_csv)
# Предварительная обработка данных, обработка только первых 20 строк данных.
result_df = result_df.head(20)
# Установить размер артборда
plt.figure(figsize=(10,25))
# Пройдите первые 20 строк данных
for i in range(0,20,5):
# Получите путь к изображению и соответствующий text_id.
image_path = os.path.join(image_folder,result_df.iloc[i]["image_id"])
text_ids = result_df.iloc[i:i+5]['result_text_id']
# Читать картинки
image = Image.open(image_path)
# Создайте подграф (картинка слева, текст справа)
plt.subplot(5,1,(i//5) + 1)
# Показать изображение
plt.imshow(image)
plt.axis('off') # Не показывать оси
# Отобразить соответствующий текст
for j, text_id in enumerate(text_ids):
# Получить текстовый контент
caption = word_data.loc[word_data['text_id'] == text_id, 'caption'].values[0]
# Добавьте текст справа от изображения
plt.text(image.width + 10, image.height/ 6 * j, caption, va='top',fontproperties=prop)
# Отрегулируйте расстояние между фрагментами изображений
plt.tight_layout()
# Показать весь артборд
plt.show()
Из задачи Как вы можете видеть на картинке с первым результатом, использование Модели предварительного обучения дает идеальный эффект, но в Задача 2середина,Если Модель не выполняет точную настройку,Используйте напрямую,Эффект очень плохой. Требуется дальнейшая доработка модели.,Для переобучения используйте изданный набор в Приложении 1.
Процесс определения направления
Для студентов, у которых вообще нет фундамента 1. Определить, каковы области применения машинного обучения 2. Узнайте, каковы алгоритмы применения машинного обучения. 3. Определите область, которую вы хотите изучать, и соответствующий алгоритм. 4. Определить конкретные технологии с помощью веб-сайтов и документов по подбору персонала и т. д. 5. Понимать бизнес-процессы и находить данные 6. Воспроизведите классические алгоритмы 7. Постоянно оптимизируйте и старайтесь общаться с соответствующим персоналом компании. 8. Компания дает обратную связь



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
