Магия данных уже здесь! DB-GPT: универсальное средство генерации SQL, диагностики SQL и обработки данных!
Магия данных уже здесь! DB-GPT: универсальное средство генерации SQL, диагностики SQL и обработки данных!
Что такое DB-GPT?
С выпуском и итерацией больших моделей большие модели становятся все более интеллектуальными. В процессе использования больших моделей они сталкиваются с серьезными проблемами безопасности и конфиденциальности данных. В процессе использования возможностей больших моделей наши частные данные и среда должны находиться в наших собственных руках и полностью контролироваться, чтобы избежать любых утечек конфиденциальности данных и рисков безопасности. Основываясь на этом, мы запустили проект DB-GPT для создания полного набора частных решений для больших моделей для всех сценариев на основе баз данных. Поскольку это решение поддерживает локальное развертывание, его можно не только применять к независимым частным средам, но также можно независимо развертывать и изолировать в соответствии с бизнес-модулями, что делает возможности больших моделей абсолютно конфиденциальными, безопасными и управляемыми.
DB-GPT — это экспериментальный проект GPT с открытым исходным кодом, основанный на библиотеке данных.,Взаимодействуйте со своими данными и средой, используя локализованные большие модели GPT.,Нет риска утечки,100% Частное, 100% Безопасность。
Особенности с первого взгляда
В настоящее время мы выпустили множество ключевых функций. Здесь мы перечисляем одну за другой, чтобы показать реализованные в настоящее время возможности.
Демонстрация эффекта
Генерация SQL
- генерировать Создать оператор таблицы
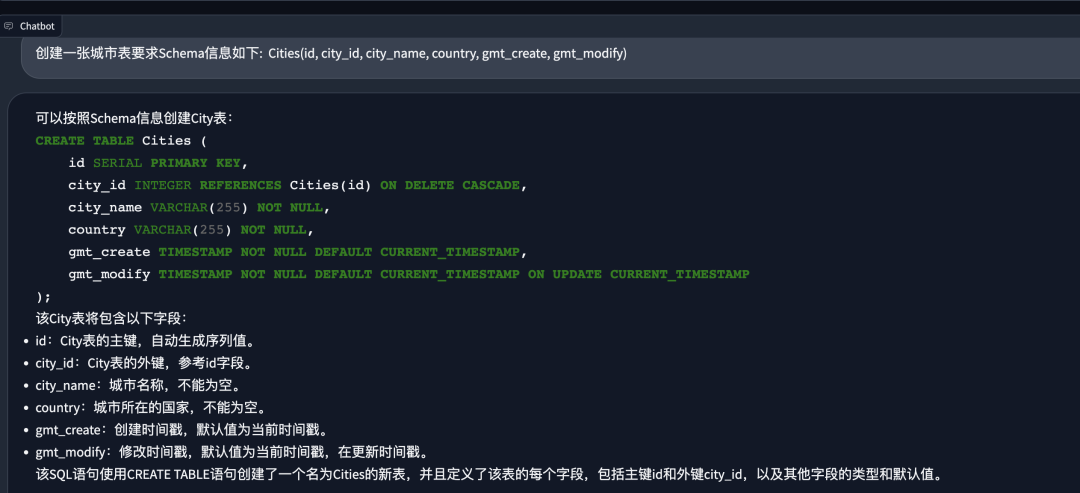
- генерировать МожетбегатьSQL Сначала выберите соответствующую библиотеку данных, Тогда модель может быть основана на соответствующей библиотеке данных. Schema информациягенерировать SQL, Эффект успешной операции показан ниже:
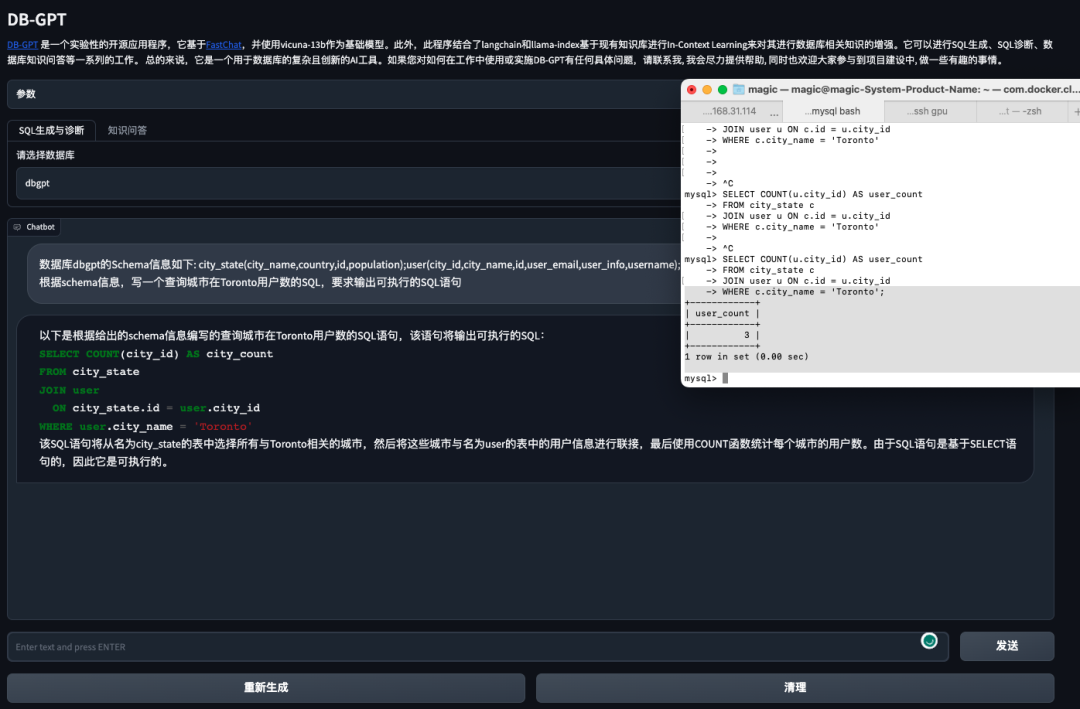
- Автоматически анализировать и выполнять SQL для вывода текущих результатов.
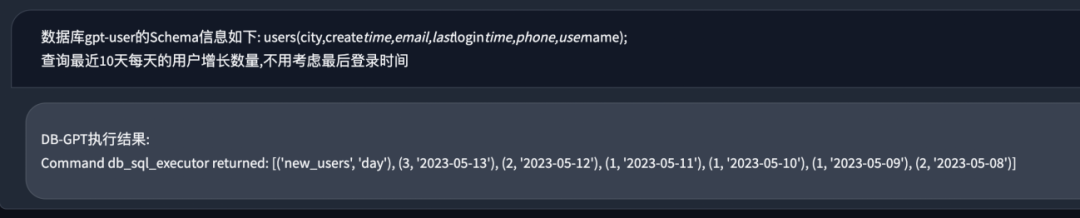
Вопросы и ответы по базе данных
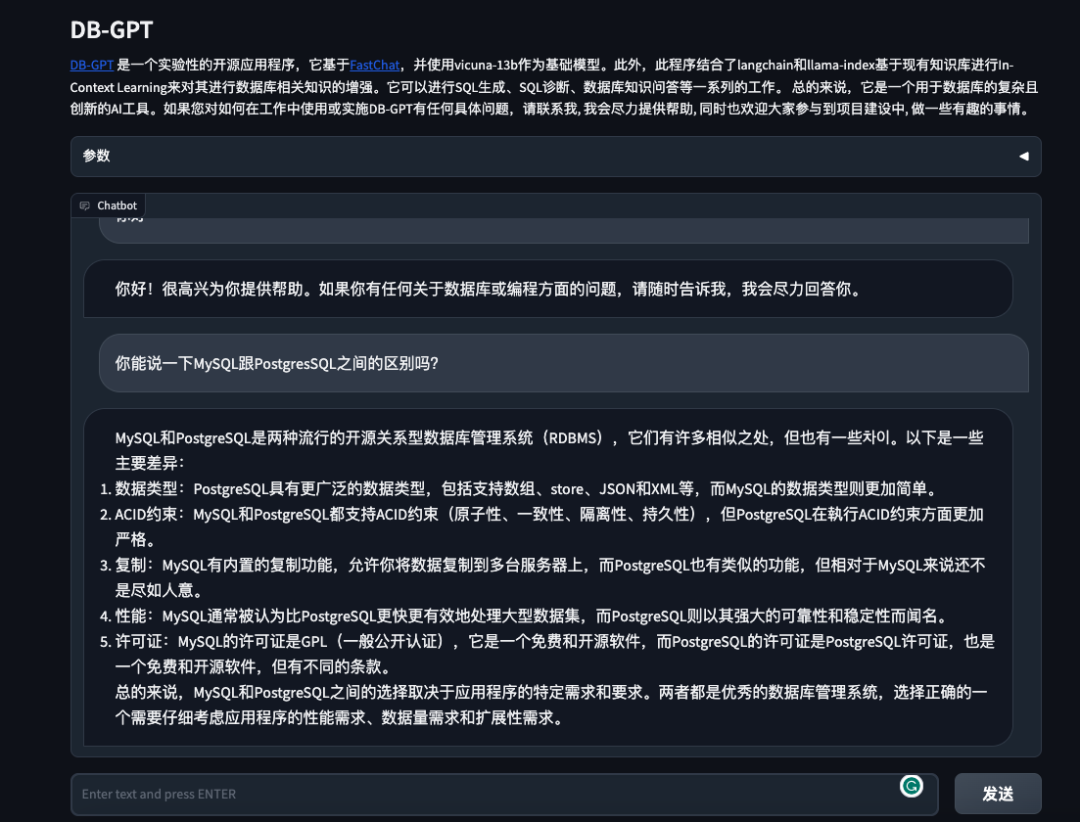
- Вопросы и ответы на основе встроенной базы знаний по умолчанию.
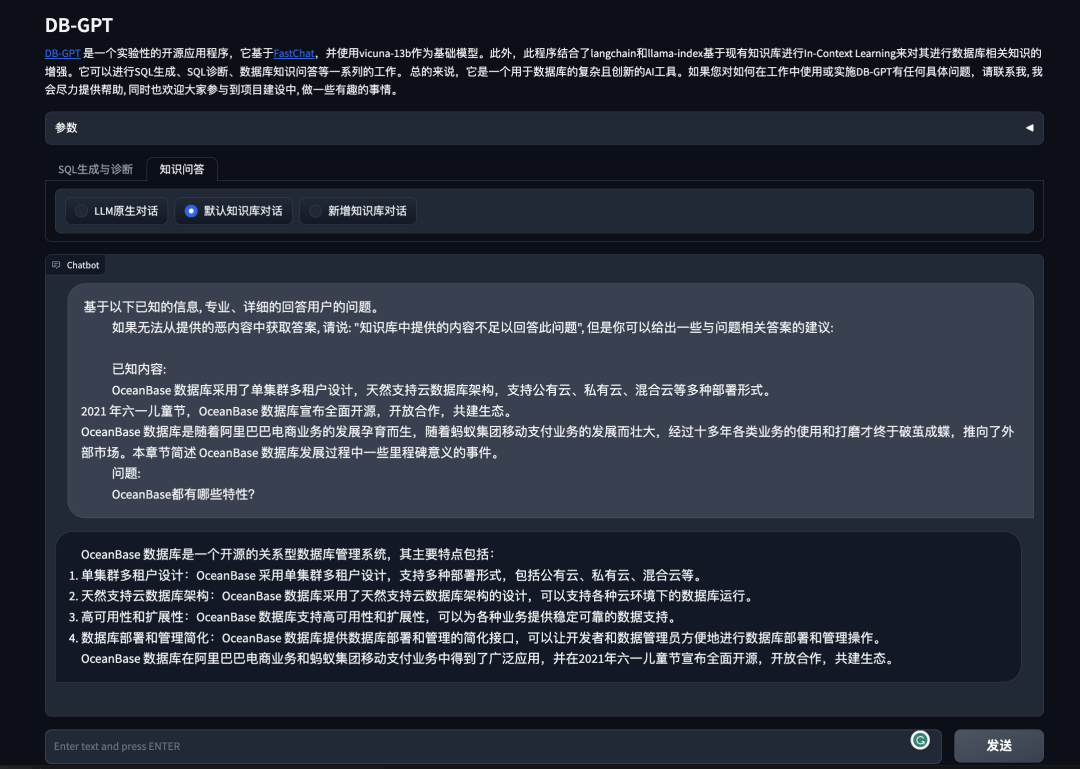
- Добавьте свою базу знаний

- Самостоятельное сканирование данных из Интернета, чтобы научиться
- TODO
Архитектурный план
DB-GPT создает среду запуска больших моделей на основе FastChat и предоставляет викунью в качестве базовой модели большого языка. Кроме того, мы предоставляем возможности вопросов и ответов в базе знаний частной области через LangChain. В то же время мы поддерживаем режим плагинов и изначально поддерживаем плагины Auto-GPT.
Вся архитектура DB-GPT показана на рисунке ниже.
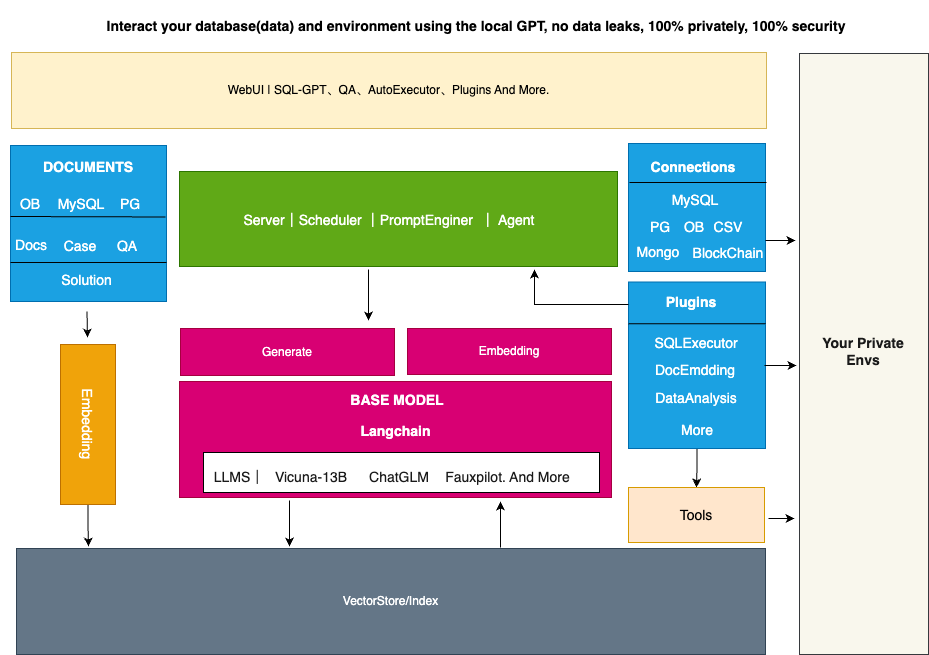
Основные возможности в основном включают в себя следующие части.
- Возможности базы знаний: поддержка вопросов и ответов в базе знаний частного домена.
- Большие возможности управления моделями: Обеспечивает большую рабочую среду модели на основе FastChat.
- Единое хранилище и индексация векторизации данных: обеспечивает унифицированный способ хранения и индексирования различных типов данных.
- Модуль подключения: используется для подключения различных модулей и источников данных для обеспечения потока данных и взаимодействия.
- Агенты и плагины: предоставляет механизмы агентов и подключаемых модулей, позволяющие пользователям настраивать и улучшать поведение системы.
- Оперативная автоматическая генерация и оптимизация: Автоматизация, высокое качество, оперативность,и оптимизировать,Повысьте эффективность реагирования системы.
- Многотерминальный интерфейс продукт: поддерживает множество различных клиентских продуктов, таких как веб-приложения, мобильные приложения и настольные приложения.
Вот краткое введение в каждый модуль:
возможности базы знаний
База знаний в настоящее время является наиболее требовательным сценарием для пользователей, и мы изначально поддерживаем создание и обработку баз знаний. В то же время этот проект также предоставляет различные стратегии управления базой знаний. нравиться:
- Встроенная база знаний по умолчанию
- Настройте новую базу знаний
- Различные сценарии использования, такие как самостоятельное получение и построение базы знаний с помощью подключаемых модулей.
Пользователям нужно только систематизировать документы знаний и использовать существующие возможности для создания возможностей базы знаний, необходимых для больших моделей.
Большие возможности управления моделями
В базовом доступе к большой модели открытый интерфейс предназначен для поддержки закрепления нескольких больших моделей. В то же время у нас действует очень строгий механизм контроля и проверки эффективности модели доступа. По сравнению с ChatGPT с точки зрения возможностей больших моделей, уровень точности должен соответствовать согласованности возможностей более 85%. Мы используем более высокие стандарты для проверки моделей в надежде, что предыдущие утомительные этапы тестирования и оценки можно будет опустить во время использования пользователем.
Единое хранилище и индексация векторизации данных
Чтобы облегчить управление векторизацией знаний, мы встроили различные механизмы векторного хранения, от Chroma на базе памяти до распределенного Milvus. Вы можете выбирать различные механизмы хранения в соответствии с вашими требованиями к сцене. Возможности искусственного интеллекта. Векторы, как промежуточный язык для взаимодействия человека с большими языковыми моделями, играют в этом проекте очень важную роль.
Модуль подключения
Для более удобного взаимодействия с приватной средой пользователя,Проект разработан Модуль подключения,Модуль подключения может поддерживать подключение к библиотеке данных, Excel, базе знаний и другим средам.,Реализуйте информационное взаимодействие с данными.
Агенты и плагины
Возможности агентов и плагинов определяют возможность автоматизации больших моделей.,В этом проекте,Встроенная поддержка режима плагина,Большие модели можно автоматизировать для достижения целей. В то же время, чтобы в полной мере использовать преимущества сообщества,Плагины, используемые в этом проекте, изначально поддерживают экосистему плагинов Auto-GPT.,То есть плагин Auto-GPT можно установить напрямую в наш проект.
Оперативная автоматическая генерация и оптимизация
Подсказка — очень важная часть процесса взаимодействия с большими моделями. В определенной степени подсказка определяет качество и точность ответов, генерируемых большой моделью. В этом проекте мы автоматически оптимизируем соответствующую подсказку на основе ввода данных пользователем. сценарии использования. Сделайте использование больших языковых моделей более простым и эффективным для пользователей.
Многотерминальный интерфейс продукта
TODO: На дисплее терминала мы предложим Многотерминальный интерфейс продукта。включатьPC、сотовый телефон、командная строка、Slack и другие режимы.
Руководство по установке
1. Описание оборудования
Поскольку наш проект обладает более чем 85% возможностями ChatGPT с точки зрения эффекта, у него есть определенные требования к оборудованию. Но, вообще говоря, мы можем завершить развертывание и использование проекта на видеокартах потребительского уровня. Конкретные инструкции по развертыванию оборудования следующие:
Модель графического процессора | Объем видеопамяти | производительность |
|---|---|---|
RTX4090 | 24G | Может вести разговорную речь плавно, без задержек. |
RTX3090 | 24G | Может рассуждать плавно, с ощущением запаздывания, но лучше, чем V100. |
V100 | 16G | Способен рассуждать в разговорной форме с явными задержками. |
2. Установка DB-GPT
Этот проект использует локальную службу базы данных MySQL. Вам необходимо установить ее локально. Рекомендуется установить ее напрямую с помощью Docker.
docker run --name=mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=aa12345678 -dit mysql:latest
По умолчанию мы используем базу данных памяти Chroma в качестве базы данных векторов, поэтому специальная установка не требуется. Если вам нужно подключиться к другим учащимся, вы можете воспользоваться нашим руководством по установке и настройке. На протяжении всего процесса установки DB-GPT мы использовали виртуальную среду miniconda3. Создайте виртуальную среду и установите пакеты зависимостей Python.
python>=3.10
conda create -n dbgpt_env python=3.10
conda activate dbgpt_env
pip install -r requirements.txt
3. Запускайте большие модели
Что касается базовой модели, вы можете синтезировать ее в соответствии с руководством по синтезу Викуны. Если у вас возникли трудности с этим шагом, вы можете напрямую использовать модель по этой ссылке в качестве альтернативы.
Запустить сервис модели
cd pilot/server
python llmserver.py
Запустить градиент через веб-интерфейс
$ python webserver.py
Уведомление: Прежде чем запустить веб-сервер, Нужно изменить .env MODEL_SERVER в файле = "http://127.0.0.1:8000", Установите адрес на адрес вашего сервера.
Используйте несколько моделей
существовать.env В файле конфигурации ИсправлятьLLM_MODELПараметры для переключения используемой модели。
Создайте свою собственную базу знаний:
1、Поместите файлы или папки личных знаний вpilot/datasetsв каталоге
2. Выполните сценарий базы данных знаний в каталоге инструментов.
python tools/knowledge_init.py
--vector_name : your vector store name default_value:default
--append: append mode, True:append, False: not append default_value:False
3. Добавьте в интерфейс новую базу знаний и введите название вашей базы знаний (если не указано, введите по умолчанию), и вы сможете задавать вопросы и ответы на основе вашей базы знаний.
Обратите внимание, что векторной моделью по умолчанию здесь является text2vec-large-chinese (модель относительно большая, если конфигурации персонального компьютера недостаточно, рекомендуется использовать text2vec-base-chinese), поэтому обязательно загрузите модель и установите он в каталоге моделей.
Если при использовании базы знаний вы столкнулись с ошибками, связанными с nltk, вам необходимо установить набор инструментов nltk. Более подробную информацию см. в документации nltk. Запустите интерпретатор Python и введите команды:
>>> import nltk
>>> nltk.download()
Ссылка на проект
https://github.com/csunny/DB-GPT



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
