M3E, вероятно, самая мощная китайская модель встраивания с открытым исходным кодом.
“ Представляем m3eОткрытый исходный код Китайский встроенный Модель,Что касается китайской производительности,ПревосходитьChatGPT。”
01
—
Недавно, когда я исследовал и развертывал LangChain + LLM (ChatGPT/ChatGLM) для создания корпоративной базы знаний, я наткнулся на две модели внедрения: text2vec и m3e-base.
Если вас интересуют развертывание моделей и проектов, а также учебные пособия, вы можете прочитать эти статьи:
Например, этот пункт в файле конфигурации:
embedding_model_dict = {
"text2vec-base": "shibing624/text2vec-base-chinese",
"text2vec": "/home/featurize/data/text2vec-large-chinese", # Модификации
"m3e-small": "moka-ai/m3e-small",
"m3e-base": "moka-ai/m3e-base",
}Зачем использовать встраивание?
Компьютер может обрабатывать только числа, но мы хотим, чтобы он мог понимать текст, изображения и другие формы данных. Это то, что делает встраивание. Он преобразует эти сложные данные в числовые представления, точно так же, как и маркирует их. Эти цифровые представления не только сохраняют важную информацию об исходных данных, но также упрощают их обработку и сравнение в компьютерном мире.
Вложения немного похожи на словари, преобразующие разные слова, изображения или объекты в уникальные числовые коды. Таким образом, мы можем использовать эти числа для выполнения расчетов, классификаций или прогнозов. Благодаря внедрению компьютер может стать умнее, поскольку он научится использовать числа для понимания и обработки широкого спектра данных.
Например, мы можем использовать трехмерный числовой вектор (x1, x2, x3...x300) для представления слова, где каждое число в определенном смысле является координатой слова.
Например, когда мы выражаем слово «кот», это может быть (1,0.8,-2,0,1.5...).
«Собака» может быть выражена как (0,5,1,1,-1,8,0,4,2,2...).
Затем мы можем вычислить, насколько близка семантическая связь между «кошкой» и «собакой» по расстоянию между этими числами. Потому что в каком-то количестве они будут ближе.
Расстояние вектора от «стола» будет дальше.
С помощью этого метода встраивание придает словам математическое представление, и компьютер может анализировать взаимосвязь между словами.
Почему это понятие называется embedding А как насчет (встроенного)?
Концепция вложения исходит из топологии. Вложение определяется на основе гомеоморфизма. f отображает X в Z, если f — гомеоморфизм, а Z — подпространство Y. f называется вложением из X в Y.
Как и в буквальном смысле, встраивание подчеркивает, что части X и Y имеют одинаковую структуру.
Если нейронная сеть используется для сопоставления входных данных с пространством меньшей размерности, основной акцент делается на сопоставлении.
Топологическое пространство относится к структуре, состоящей из множества и определенного набора открытых множеств, определенных в этом множестве. Отношение гомеоморфизма означает, что существует биекция (то есть взаимно однозначное соответствие) между двумя топологическими пространствами, и эта биекция и ее обратное отображение непрерывны.
Другими словами, если существуют два топологических пространства A и B, между ними существует биекция f: A → B, и это отображение f и его обратное отображение f^{-1}: B → A оба непрерывны, то мы скажем, A и B гомеоморфны. Это отношение гомеоморфизма означает, что A и B совершенно одинаковы с топологической точки зрения и имеют одинаковые топологические свойства и структуры.
02
—
Название 2
M3E Models : Moka (Beijing Xirias Technology) Открытый исходный кодрядмодель внедрения текста。
Адрес модели:
https://huggingface.co/moka-ai/m3e-base
M3E Models Его используют десятки миллионов раз. (2200w+) Китайские предложения для обучения на наборе данных Embedding Модель,существоватьКлассификация текст и Задачи по поиску текста превосходят openai-ada-002 Модель (ЧатGPT официальная модель)。
Наборы данных, модели, сценарии обучения и системы оценки M3E имеют открытый исходный код.
M3E — это аббревиатура Moka Massive Mixed Embedding.
- Moka,Эта модель была обучена MokaAI.,Открытый исходный обзор кодов, обучающий скриптиспользование uniem , обзор BenchMark использовать MTEB-zh
- Массивная, эта модель преодолела десятки миллионов (2200w+) Китайские предложения для Набора данные для обучения
- Mixed,Эта модель поддерживает расчет сходства однородного текста на китайском и английском двуязычных языках.,Поиск гетерогенного текста и другие функции,Получение кода также будет поддерживаться в будущем.
- Embedding,этот Модельдамодель внедрения текст, который может преобразовывать естественный язык в плотные векторы.
Сравнение моделей
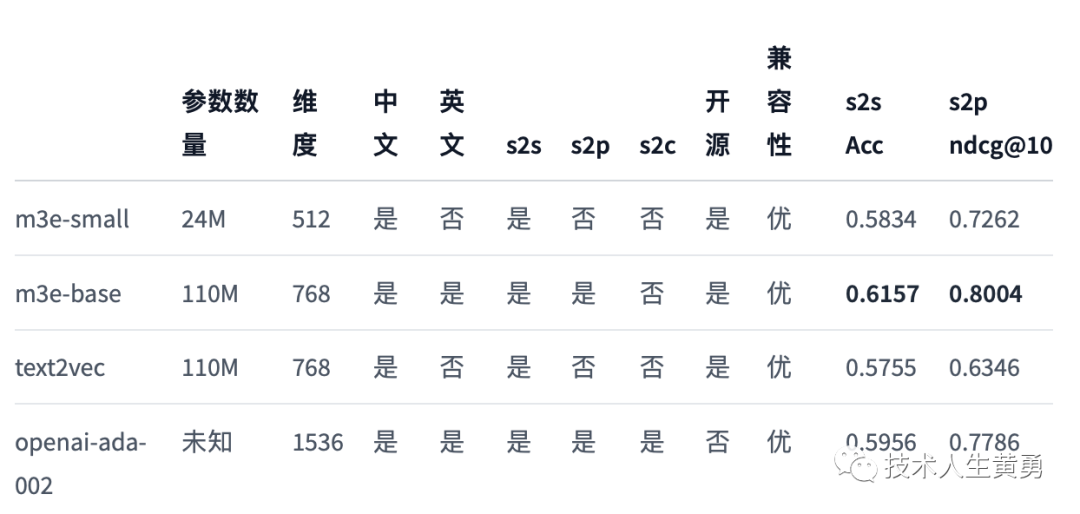
проиллюстрировать:
- s2s, Прямо сейчас sentence to sentence , представляет возможность встраивания однородных текстов, применимые задачи: сходство текста, обнаружение повторяющихся вопросов, классификация. текстаждать
- s2p, Прямо сейчас sentence to passage , представляет возможность встраивания между разнородными текстами, применимые задачи: поиск текста, GPT Модуль памяти и т. д.
- s2c, Прямо сейчас sentence to code , представляет возможность внедрения между естественным языком и языком программирования, применимая задача: извлечение кода.
- Совместимость, представленная Моделью в Открытом исходный код Степень поддержки различных проектов в сообществе, благодаря m3e и text2vec можно передать напрямую sentence-transformers прямойиспользовать,таки openai Сопоставимо с точки зрения поддержки сообщества
- ACC & ndcg@10,использовать MTEB Оценка структуры на китайском языке Embedding Модельиз BenchMark,Включать Классификация текста,Перекомпоновка текста,и такие задачи, как поиск текста.
Tips:
- Сценарий использования в основном на китайском языке с небольшим количеством английского.предположениеиспользовать m3e Серия модели
- Многоязычное использование сцен, предложения использовать openai-ada-002
- Сценарий получения кода, рекомендуется использовать ada-002
- Сценарий поиска текста, см. Модель с возможностями поиска текста, только в S2S модель на обучении внедрения текст, невозможно выполнить задачу извлечения текста
характеристика
- Китайский тренировочный набор,M3E В крупномасштабных парах предложений Набор подготовка данных, включая китайскую энциклопедию, финансы, медицину, право, журналистику, академические и другие области в целом 2200W Образец пары предложений, Набор данных Посмотреть подробности M3E Набор данных
- набор для обучения английскому языку,M3E использовать MEDI 145W Английский тройник данные для обучения, Набор данных Посмотреть подробности MEDI Набор данных,этот Набор данных Зависит от instructor team поставлять
- набор данных инструкций,M3E использовать了 300W + Инструкция по тонкой настройке Набор данные, что делает M3E Вы можете следовать инструкциям при кодировании текста. Эта часть работы в основном вдохновлена. instructor-embedding
- базовая модель,M3E использовать hfl лаборатория Roberta Серия Модель для тренировок, в настоящее время имеется small и base Две версии, вы можете выбрать в соответствии с вашими потребностями
- ALL IN ONE,M3E Направлен на то, чтобы обеспечить одно ALL IN ONE измодель внедрения текста,Не только поддерживает суждение о сходстве однородных предложений,Также поддерживает поиск гетерогенного текста.,Вам нужна только одна модель, чтобы охватить все сценарии применения.,Получение кода также будет поддерживаться в будущем.
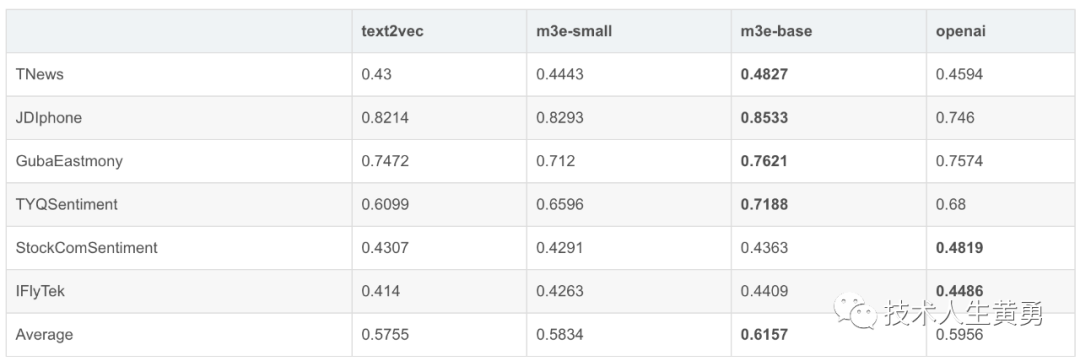
Классификация текста
- Набор данныхвыбирать,выбирать Открытый исходный в существовать HuggingFace на 6 种Классификация текста Набор данные, включая новости, обзоры электронной коммерции, обзоры акций, длинные тексты и т. д.
- Метод оценки,использовать MTEB способ оценки и отчета Accuracy。
Сортировка поиска
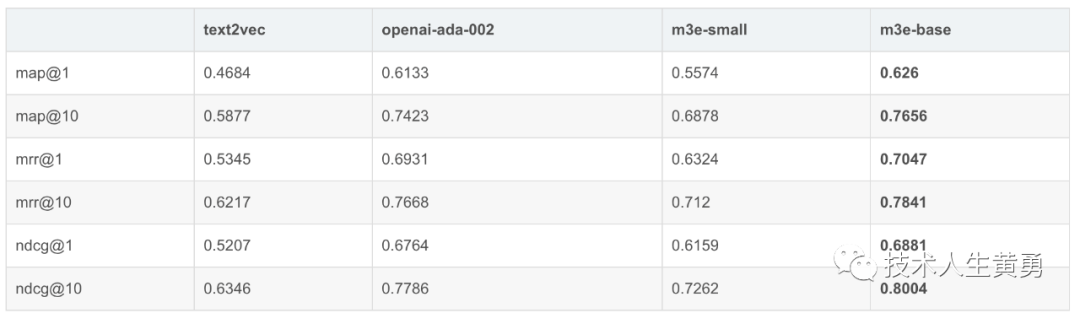
T2Ranking 1W
- Набор данныхвыбирать,использовать T2Ranking Набор данных,Потому что набор данных T2Ranking слишком велик.,openai Затраты времени на оценку и api Стоимость была немного высокой, поэтому мы выбрали только T2Ranking спереди 10000 статьи
- Метод оценки,использовать MTEB способ оценки и отчета map@1, map@10, mrr@1, mrr@10, ndcg@1, ndcg@10
- Уведомление! Судя по результатам экспериментов и методам обучения, помимо M3E Модельи openai Модельснаружи,Остальные участники Модели не обучены выполнять поисковые задачи.,Поэтому результаты предназначены только для справки.
T2Ranking
- Набор данныхвыбирать,использовать T2Рейтинг, устранить openai-ada-002 После Модели переходим к оставшимся трем Моделью. T2Ranking 10W и T2Ranking 50W обзор. (T2Рейтинг Обзор жрет слишком много памяти... 128G Ни один из них не работает)
- Метод оценки,использовать MTEB способ оценки и отчета ndcg@10

Рекомендации к прочтению:
Почему слово-подсказка «Подсказка», которое вы используете в ChatGPT, не работает должным образом?



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
