LoRS — это прорыв в мультимодальном извлечении данных, разрушающий ограничения одной модальности!

Хотя в последние годы уточнение наборов данных быстро развивалось, уточнение мультимодальных данных, таких как пары «изображение-текст», ставит уникальные и еще предстоит глубоко изучить проблемы. В отличие от одномодальных данных, данные контрастного обучения изображениям и текстам (ITC) не имеют собственной классификации, и больше внимания следует уделять соответствию между модальностями. в этой работе,Авторы предлагают мультимодальный вариант.данныеизысканныйнизкий рангДобыча сходства(LoRS),Он одновременно уточняет Землю с помощью пар изображение-текст. Матрица истинного сходства использует разложение низкого ранга для повышения эффективности и масштабируемости. Предложенный метод вносит существенные улучшения по сравнению с существующими алгоритмами и вносит важный вклад в область извлечения визуально-лингвистических наборов данных. Автор выступает за принятиеLoRSкак изображение-текстданныеизысканный基础合成данныенастраивать。Код автора доступен по адресу https://github.com/silicx/LoRS_Distill.。
1 Introduction
Дистилляция набора данных позволяет синтезировать меньший и более компактный набор данных, сохраняя при этом его основную информацию и производительность обучения модели. Благодаря высокой степени сжатия он представляет особый интерес в контексте машинного обучения и данных крупномасштабных моделей. Однако применение современных алгоритмов в области изображений ограничено, и лишь немногие исследования включают другие одномодальные данные, такие как текст (Li and Li, 2021), видео (Wang et al., 2023) или графические данные (Xu et al., 2023) или графические данные (Xu et al., 2023). др., 2023б). Поскольку визуально-лингвистические предварительно обученные модели (VLP) и мультимодальные модели большого языка (MLLM) (Li et al., 2023; Liu et al., 2023a) стали доминирующими, авторы обратили свое внимание на парные изображения-текстовые данные.
В качестве основы VLP авторы сосредотачиваются на данных контрастного обучения изображения и текста (ITC) и стремятся эффективно выполнить дистилляцию набора данных изображения и текста, что может повысить эффективность мультимодальных моделей и способствовать их исследованиям.
Рис. 1. Традиционная фильтрация набора данных может применяться к данным изображения и текста, но страдает от фиксированных пар данных (« Baseline ") ограничения. Автор предлагает Добыча сходства, извлекая при этом реальную матрицу сходства и передавая ее ранг Оптимизируйте для достижения справедливогоданные Размер параметра(LoRS)。
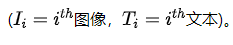
Однако дистилляция пар изображение-текст гораздо сложнее, чем одномодальные данные:
(1) Алгоритм должен не только сжимать каждую модальность отдельно, но и правильно изучать соответствие между модальностями;
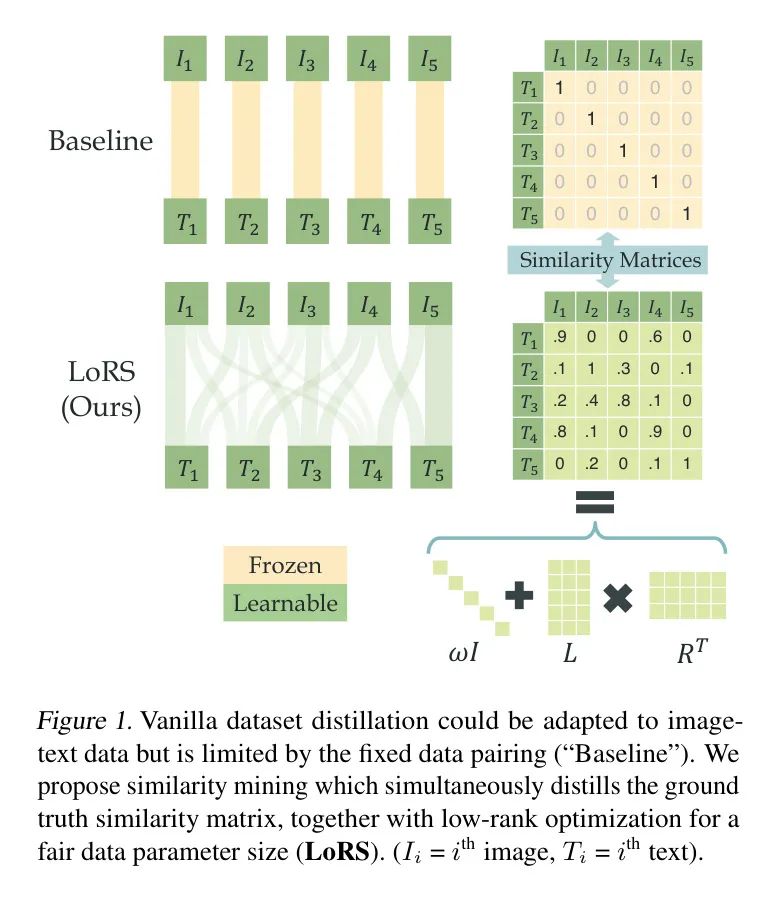
(2) Унимодальные данные имеют категории и распределены по кластерам, но данные пары изображение-текст неклассифицированы и редко распределены, что может привести к высокой дисперсии выборки при дистилляции набора данных.
Как отмечалось в предыдущей работе, это делает существующие алгоритмы, такие как сопоставление градиентов и сопоставление распределений, неэффективными. Хотя первая работа по дистилляции набора изображений и текста (Wu et al., 2023) достигла хороших результатов с использованием обычного многозадачного преобразователя (MTT) (Cazenavette et al., 2022), в ней не хватало знаний о конкретных данных изображения и текста. адаптация и использование.
Таким образом, в предложении автора упор делается на изучение модальных соответствий, а не на обобщение шаблонов данных каждой категории. Как показано на рисунке 1, общие алгоритмы дистилляции набора данных используют фиксированные соответствия изображения и текста.
Одновременное изучение сходства изображения и текста в качестве вспомогательной информации в процессе дистилляции набора данных.,Прямо сейчасДобыча сходства。Извлеченную матрицу сходства можно использовать для любого изображения.-текст对比学习Модельсередина,Требуются лишь небольшие изменения в функции контрастных потерь.
Этот метод расширяет обычные методы дистилляции, чтобы узнать полное соответствие между синтетическими изображениями и текстом, что можно грубо представить как расширение пары изображение-текст до пары парных данных. Поэтому авторы обогащают информацию синтетическими данными, не увеличивая накладные расходы модели. Авторы выступают за принятие анализа сходства в качестве фундаментальной алгоритмической настройки при дистилляции набора данных изображения и текста.
Чтобы подтвердить рациональность и осуществимость этого метода, автор демонстрирует рациональность анализа сходства с точки зрения обучения модели:
(1) Добыча отрицательной выборки:обычное изображение-текст对比(ITC)Модель Предполагается, что образцы в каждой партии разные, поэтому в качестве истинной матрицы сходства используется матрица идентичности (только сам образец положителен, остальные образцы отрицательны), но иногда между образцами партии имеется скрытое сходство (Шриниваса и др., 2023), анализ сходства может найти эти образцы и автоматически исправить штраф за ошибку.
(2) Гибкое сравнительное обучение Anchor точка:ITCЭто можно рассматривать как встраивание функций и Anchor Притяжение и отталкивание между точками. Анализ сходства расширяет возможности Anchor момент явно расширяет возможности гибкости, так что определенные Anchor Точки можно эквивалентно объединить без изменения динамики обучения, что значительно улучшит степень сжатия при дистилляции набора данных. Подробно они будут обсуждаться в разделе 3.3.

Вклад этой работы включает в себя:
(1) Для очистки наборов данных «изображение-текст» авторы предлагают новую парадигму изучения матриц сходства как части синтетических данных, которая хорошо обоснована с точки зрения обучения ITC.
(2) Авторы предлагают новую и осуществимую реализацию анализа подобия, которая включает разложение низкого ранга.
(3) Авторский метод существенно превосходит Baseline метод.
2 Related Work
За последнее десятилетие глубокое обучение вызвало революцию в компьютерном зрении, добившись крупных прорывов в таких задачах, как классификация изображений, обнаружение объектов и сегментация изображений.
В последние годы развитие глубоких нейронных сетей смещается от традиционных задач распознавания к более сложным и трудным задачам, таким как визуальный ответ на вопросы и генерация изображений.
Dataset Distillation
Целью Dataset Distillation (DD) является синтез небольшого набора данных из крупномасштабного набора данных, который может заменить исходный набор данных для обучения, сохраняя при этом производительность.
Существующие алгоритмы можно разделить на: (1) сопоставление метамодели。
Оптимизируйте потерю опыта для всего набора данных, сохраняя возможность переноса очищенных данных. После первоначальной работы над DD (Wang et al., 2018) было предложено множество методов. KIP (Nguyen et al., 2020) объединяет гребневую регрессию для снижения вычислительной сложности и в дальнейшем распространяется на сети бесконечной ширины (Nguyen et al., 2021). RFAD (Loo et al., 2022) использует замену ядра гауссовского процесса нейронной сети в KIP. FRePo (Zhou et al., 2022) делит сеть на экстракторы признаков и классификаторы для оптимизации. RCIG (Loo et al., 2023) использует неявные градиенты для расчета метаградиентов.
(2) Градиентные методы。
DC выравнивает обучающие градиенты реальных и синтетических данных. IDC (Ким и др., 2022) улучшает DC за счет хранения синтетических данных с более низким разрешением. MTT (Cazenavette et al., 2022) сопоставляет параметры после нескольких этапов обучения, что можно рассматривать как долгосрочное сопоставление градиента. TESLA (Cui et al., 2023) снижает потребление памяти MTT. Шин и др. сопоставляют резкость потерь реальных и синтетических данных, что аналогично градиентам.
(3) методы, основанные на признаках。
DM (Чжао и Билен, 2023) сопоставляет распределение между реальными и синтетическими данными, а CAFE (Wang et al., 2022) вводит послойное выравнивание объектов. IDM (Чжао и др., 2023) еще больше расширяет DM за счет регуляризации и моделирования очередей.
(4) Метод разложения。
Эти методы разлагают данные на базы и галлюцинации, что позволяет снизить нагрузку на хранилище и увеличить разнообразие синтетических данных. HaBa использует сверточную сетевую галлюцинацию, а LinBa использует линейную галлюцинацию. KFS обеспечивает эффективный обмен информацией между сгенерированными сэмплами и обеспечивает лучший баланс между степенью сжатия и качеством. Также было принято разложение в частотной области.
Многие другие подходы выходят за рамки этих категорий и привносят инновации в DD. Чтобы оптимизировать существующие методы, некоторые исследования сосредоточены на совершенствовании данных или моделей (Чжао и Билен, 2021; Чжан и др., 2023) для улучшения способности DD к обобщению, в то время как в некоторых исследованиях используется выборка для достижения эффективного DD или расширенного применения.
Генеративные модели используются в качестве генераторов синтетических изображений. SRe2L (Yin et al., 2023) предлагает трехэтапную парадигму обучения, которая более эффективна для больших наборов данных. Байесовский вывод также можно использовать для дистилляции набора данных. Ву и др. предложили первую работу по дистилляции набора текстовых данных изображений (Wu et al., 2023), которая добилась хороших результатов за счет сопоставления траекторий кодировщиков изображения и текста, но не внесла конкретных изменений в соответствие текстовых данных изображения.
Image-text Contrastive Learning
Контрастное обучение изображением и текстом является ключевой основой мультимодального обучения. CLIP (Radford et al., 2021) является первым, кто использует контрастное обучение изображения и текста, которое выравнивает характеристики, полученные различными модальными кодировщиками. Модель обучается на крупномасштабных данных для достижения «эффекта масштаба» и возможности переноса открытого словаря. ALIGN (Jia et al., 2021) и Flava (Singh et al., 2022) были одними из первых исследований, предложивших методы контрастного обучения. CHiLS (Novack et al., 2023) исследует богатые вложения с иерархиями меток.
ФИЛИП (Яо и др., 2021) исследует сходство между двумя модальностями по токенам. ALBEF (Li et al., 2021) и CoCa (Yu et al., 2022) фокусируются на кросс-модальном внимании. BLIP и BLIP сочетают в себе мультимодальные методы обучения и работают хорошо. Есть также несколько недавних работ, посвященных мягким меткам в моделях, подобных CLIP. SoftCLIP обеспечивает мягкое кросс-модальное выравнивание путем создания внутримодальных сходств. Андонян и др. (2022) используют пошаговую самодистилляцию для изучения надежных моделей на основе зашумленных данных.
3 Methodology
Preliminary


Similarity Mining for Image-Text Distillation



Justification of Similarity Mining
Сходство технологии добычи полезных ископаемых можно объяснить с двух точек зрения:
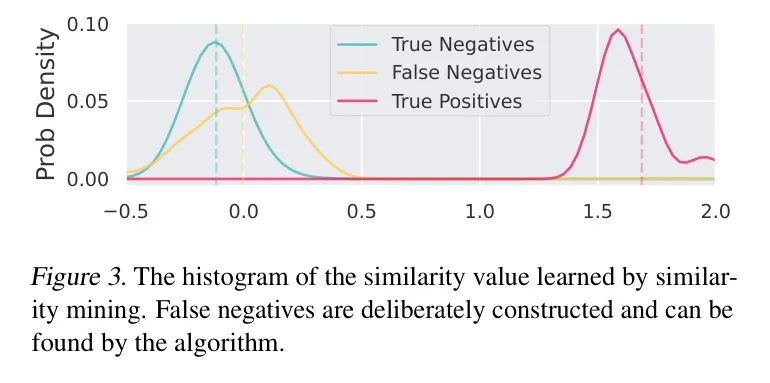
Ложноотрицательный майнинг。стандартныйITCМодель(нравитьсяCLIP)假设不同样本середина的картина像итекст是负对,Но из-за возможности использования одинаковых или похожих выборок данных в сетевых шумах,Это предположение может быть нарушено. Для таких продуктов, как YFCC100M (Thomee et al.,2016) или LAION (Schuhmann et al.,2022) для такого масштабного набора данных,Эти потенциально значимые пары можно игнорировать.,Потому что истинных положительных и отрицательных пар представлений Воли достаточно, чтобы направить их в правильное положение. Однако,Небольшой размер синтезированных данных приводит к меньшей устойчивости к ложноотрицательным результатам.,Для этого требуется более точное подобие GT.
Таким образом, парадигма анализа сходства может смягчить влияние ложноотрицательных результатов, поскольку она может навязывать ненулевое сходство для потенциальных отрицательных пар. Автор провел простой эксперимент на Flickr30k. Авторы инициализируют 100 синтетических пар 50 реальными парами данных и их копиями так, чтобы в процессе дистилляции образцы и были похожими, но считались отрицательными парами.
Наконец, существует 100 истинно положительных пар, 100 ложноотрицательных и 9800 истинно отрицательных пар. Авторы показывают нормализованную гистограмму четкого сходства на рисунке 3. Метод анализа сходства действительно находит ложноотрицательные результаты, изучая относительно большие значения сходства.
Гибкое сравнительное обучение Anchor точка。автор Воля更深入地探讨картина像текст对比学习,Сначала проанализируйте градиент потери контраста. Для краткости,Следующее обсуждение предполагает, что изображения и текстовые представления стандартизированы.,без потери общности,Авторы обсуждают только градиенты при представлении изображений.
Low Rank Similarity Mining
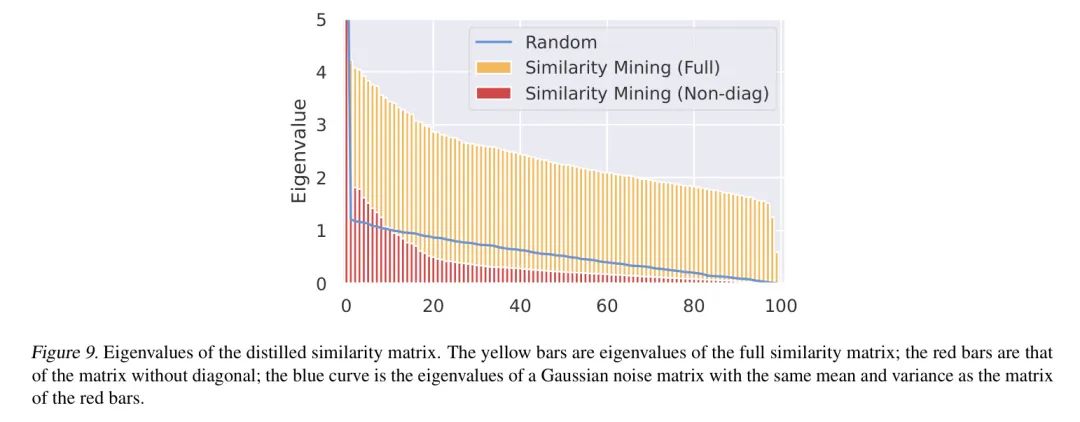
Хотя анализ сходства может помочь в задачах очистки набора данных, когда объем данных велик, размер дополнительной хранимой матрицы сходства будет увеличиваться квадратично и может даже превышать размер хранилища изображений и текста. Большие матрицы сходства также могут быть сложными для оптимизации, и для полного обучения матрицы потребуется больше итераций обучения. Поэтому авторы используют свойство низкого ранга матрицы сходства для уменьшения нагрузки на хранение.
Из ошибки Добыча отрицательной С точки зрения выборки, матрица сходства должна быть низкой. Ранги: Если две выборки схожи, согласно неравенству треугольника, две строки или два столбца в матрице сходства также будут схожими, что приводит к низкому значению ранга. Матрица подобия рангов (Приложение Раздел В.1). Однако это не относится к изученной матрице сходства, и мы надеемся, что наш метод сможет моделировать все матрицы сходства разных рангов, включая простейшую, но полноранговую тождественную матрицу сходства. Поэтому авторссылка(Hu et al., 2021) предложил применять к остаточной матрице сходства низкоранговую аппроксимацию, то есть автор разлагает матрицу сходства на обучаемую диагональную и низкоранговую остаточную матрицу:


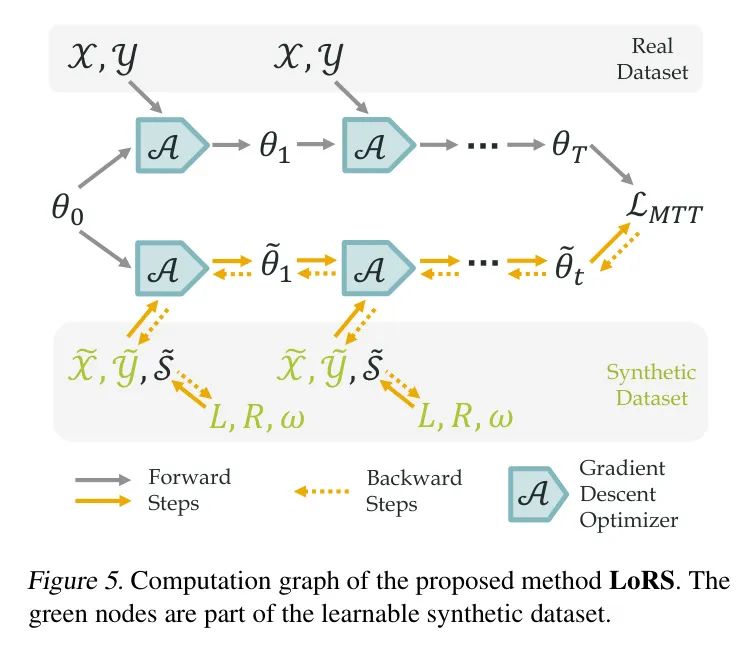
в общем,автор提出了用于картина像-текстданныесобраны и очищенынизкий ранг Добыча сходства(LoRS)технология。Этот подход вводит попарные мультимодальныеданныеновый компонент,Но его можно легко встроить во все алгоритмы мультимодального контрастного обучения. На рисунке 5 также показан обзор вычислительного графа. Обучаемые параметры для синтеза данных:,которые сначала объединяются в синтетическую матрицу сходства,Затем он используется для обновления параметров сети синтетической траектории. Синтетические траектории совпадают с реальными траекториями за счет потери MTT.,И обновите 5 параметров посредством обратного распространения ошибки. алгоритм также обобщается как Алгоритм 1,Возьмем, к примеру,И дает метод использования синтетических данных, сгенерированных LoRS.,Видетьалгоритм2。

Алгоритм 1 низкий ранг Добыча сходства(LoRS)
4 Experiments
Dataset and Metrics
Автор следит за использованием МТТ Сила алгоритмов Baseline Методы в Flickr30k и COCO (Лин и др.,Метод автора был проверен на наборе данных в 2014 году. Flickr30k и COCO — это наборы данных подписей к изображениям с 31 КБ и 123 КБ изображений соответственно.,Каждое изображение сопровождается пятью подписями.。Модельпроизводительностьобычно черезtop-KКоэффициент запоминаемости поиска(R@K)измерить:Учитывая модальный Query ,автор从另一种模态середина检索最接近的kспички и измерить их точность。автор Волятекст到картина像检索表示为IR@K,Волякартина像到текст检索表示为TR@K。
Baselines and Proposed Method
Авторы сравнили различные базовые методы, в том числе:
(1) выбор основного набора:случайный(случайный选择данныеподмножество),Herd (Welling, 2009), К-центр (Farahani and Hekmatfar, 2009) и забывчивость (Тонева et al., 2018)。
(2) Уточнение набора данных:MTT-VL (Wu et al., 2023) Воля MTT (Cazenavette et al., 2022) Адаптируйтесь к парам изображение-текст (или MTTNCE). ТЕСЛА (Cui et al., 2023) Это эффективная реализация МТТ, поэтому автор Воля TESLA Адаптируйтесь к мультимодальным данным и используйте взвешенные потери BCE (TESLawBCE).
В сравнении,автор Воляавтор的 LoRS Техника, применяемая с взвешенными потерями BCE TESLA (Cui et al., 2023) Алгоритм (LoRSwBCE).
Implementation Details
После установки MTT Strong Baseline (Wu et al., 2023) авторы используют NormalizerFree ResNet (NFNet) (Brock et al., 2021), предварительно обученную ImageNet (Deng et al., 2009), в качестве кодировщика изображений. и предварительно обученный. База BERT (Девлин и др., 2018) служит кодировщиком текста. Добавьте линейный слой после кодировщика текста.
Как на этапе дистилляции, так и на этапе обучения загружаются предварительно обученные веса, а текстовая сеть замораживается для повышения эффективности.
Автор непосредственно синтезирует встраивание текста, а не заголовок. Авторы используют TESLA (Cui et al., 2023) в качестве базового алгоритма дистилляции без обучения меткам.
Авторы обучили сеть на полном наборе реальных данных за 10 эпох, повторенных 20 раз в качестве экспертных траекторий. Эксперименты проводились на графическом процессоре RTX 4090 и продемонстрировали эффективность этого метода.
На этапе дистилляции размер изображения изменяется до 224224 размеров, а встраивание текста — до 768 размеров. Синтетические данные изучаются с использованием SGD и импульса 0,5. Изображения и текст инициализируются случайными выборками истинной информации. Остальные гиперпараметры (включая скорость обучения и параметры LoRS) различаются в зависимости от разных наборов данных и размеров синтетических данных, и из-за ограничений места эти параметры перечислены в разделе F Приложения.
в частности,для честного сравнения,Автор уменьшил количество синтетических пар LoRS.,сохранить параметры синтеза,Например,Для эксперимента с парами=500,У автора ВоляLoRS количество пар уменьшено до 499,для сохранения параметров,Это поддерживает максимальный ранг. на практике,для эффективности,Автор использует меньший ранг,Обычно меньше 50.
Results
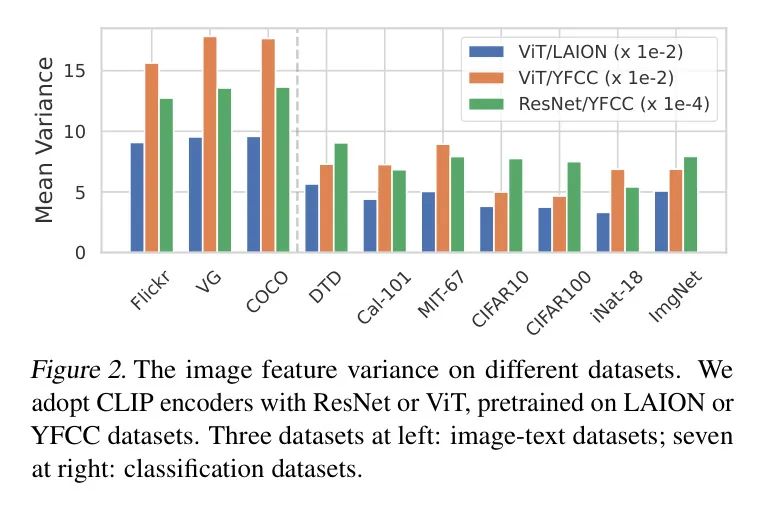
Таблица 2: Результаты на Flickr30k (Плуммер и др., 2015). Производительность модели, обученной на полном наборе данных, следующая: IR@1=27,3, IR@5=57,1, IR@10=69,7, TR@1=33,9, TR@5=65,1, TR@10=75,2; .
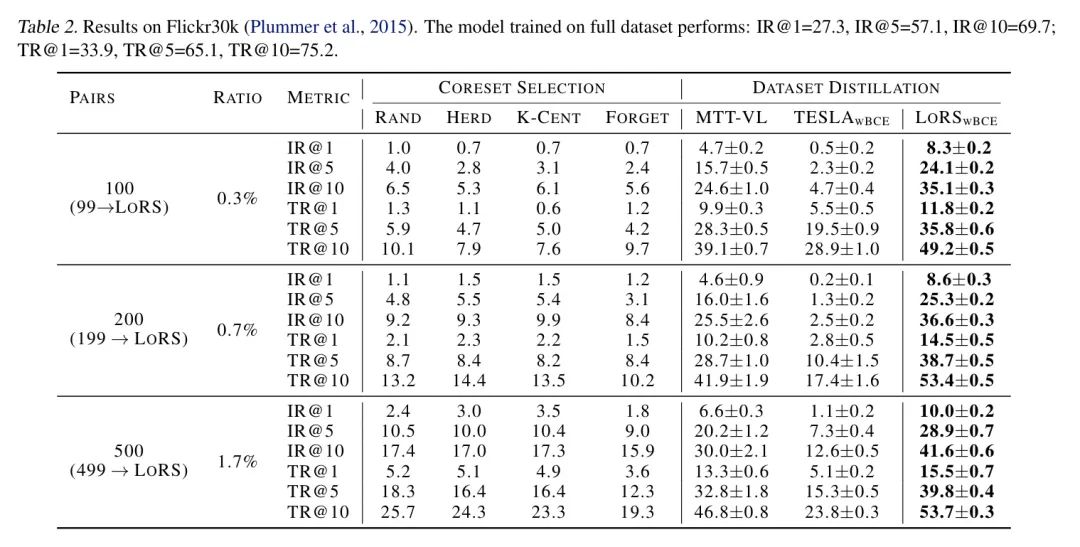
Рисунок 6: Пример инициализации и синтеза пар изображение-текст.

Результаты на Flickr30k и COCO показаны в Таблице 2 и Таблице 3 соответственно. LoRS улучшает алгоритм дистилляции изображения и текста и может принести относительные улучшения до ~ 50% по сравнению с базовым уровнем. Интересно, что на Flickr30k LoRSwBCE, использующий 100 пар, значительно превосходит MTT Baseline, использующий 500 пар, демонстрируя большую степень сжатия метода анализа подобия. Стоит отметить, что хотя LoRS меняет структуру данных, он приводит к незначительным затратам памяти (0,3%) и времени обучения (0,8%). Более подробную информацию об анализе эффективности см. в разделе D.3 приложения. А производительность алгоритма на Flickr30k более значительна, поскольку объем данных COCO в 3 раза больше, чем у Flickr30k, и имеет более сложные взаимосвязи между данными. ###Кросс-архитектурное обобщение
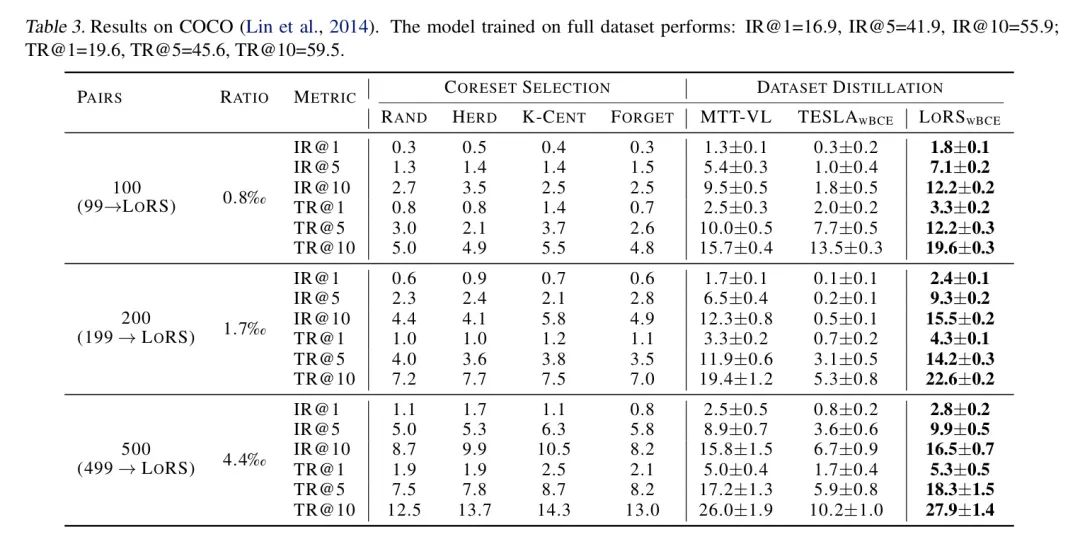
Следуя MTT (Cazenavette et al., 2022), авторы проводят межархитектурные оценки для изучения способности к обобщению синтетических данных. Авторы использовали NFNet+BERT для обработки данных и оценивали их с использованием других сетей, включая RegNet (Радосавович и др., 2020) и ResNet50 (He и др., 2016). Поскольку авторы заморозили кодировщик текста, необходимости проверять генерализирующую способность текстовой сети не было. Результаты в Таблице 4 показывают, что наши очищенные данные способны обобщаться по сетям (значительно больше, чем метод выбора основного набора в Таблице 2) и превосходят базовую модель. Важно отметить, что снижение производительности также частично связано с производительностью самой архитектуры (например, ResNet или RegNet, обученные на полных данных, достигают примерно IR@1=28% и TR@1=22%, тогда как NFNet достигает примерно IR@11=33% и TR@1=27%).
Ablation Study
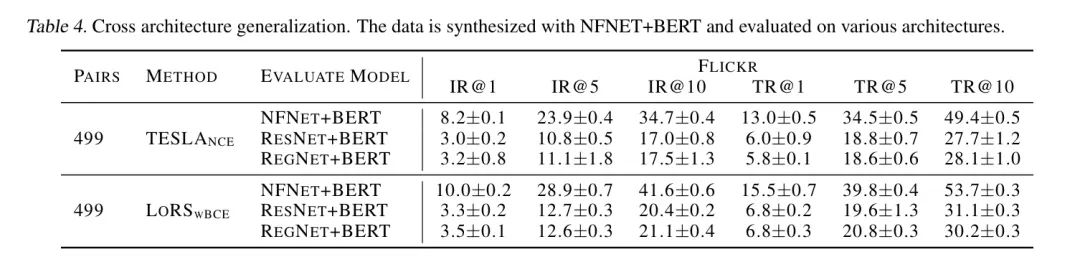
В таблице 5 показаны результаты исследования абляции.
Изучите полную матрицу сходства (под номерами 1–3). Авторы реализовали анализ сходства с полной обучаемой матрицей сходства (без низкоранговых методов и параметров). Полный анализ сходства показывает сравнимую производительность с LoRS, что указывает на то, что низкоранговая аппроксимация матрицы сходства осуществима.
Функция потерь (номера 4-6). Среди функций потерь несколько лучше и значительно лучше обычных, главным образом, благодаря их сбалансированному характеру. Объединив сравнения в Таблице 2 и Таблице 3, автор рекомендует выбирать между LoRS и LoRS.
Ранг (номера 7-11). Пока он не слишком мал, он оказывает минимальное влияние на производительность и здесь вполне достаточен.
Компоненты в разложении низкого ранга (номера 12-13). Удаление компонентов низкого ранга ухудшает производительность, но все равно превосходит эксперимент с использованием единичной матрицы (№13).
Таблица 4: Обобщение кросс-архитектуры. Данные синтезируются с помощью NFNET+BERT и оцениваются на различных архитектурах.
Таблица 3: Результаты COCO (Lin et al., 2014). Производительность модели, обученной на полном наборе данных, составляет: IR@1=16,9, IR@5=41,9, IR@10=55,9, TR@1=19,6, TR@5=45,6, TR@10=59,5;
Фиксированное изображение или текст (номера 14-16). Замораживание изображений или текста во время дистилляции значительно снизит производительность данных, а эксперименты показывают, что изучение текста более важно для дистилляции. Удивительно, но на Flickr30k эксперимент (номер 16), изучающий только матрицу сходства, может превзойти случайную модель.
Сходство с предварительно обученным CLIP (№17). Вместо изучения матрицы сходства авторы напрямую используют предварительно обученный CLIP для расчета матрицы сходства. Однако рассчитанная матрица сходства не подходит для очищенных изображений и текстов, что приводит к низкой производительности поиска. Это явление согласуется с общим выводом при дистилляции данных: данные, подходящие для обучения сети, могут быть неестественными для людей.
Visualization
Авторы представляют 200 пар синтетических изображений, текстов и матриц сходства из набора данных Flickr30k для представления очищенных данных.
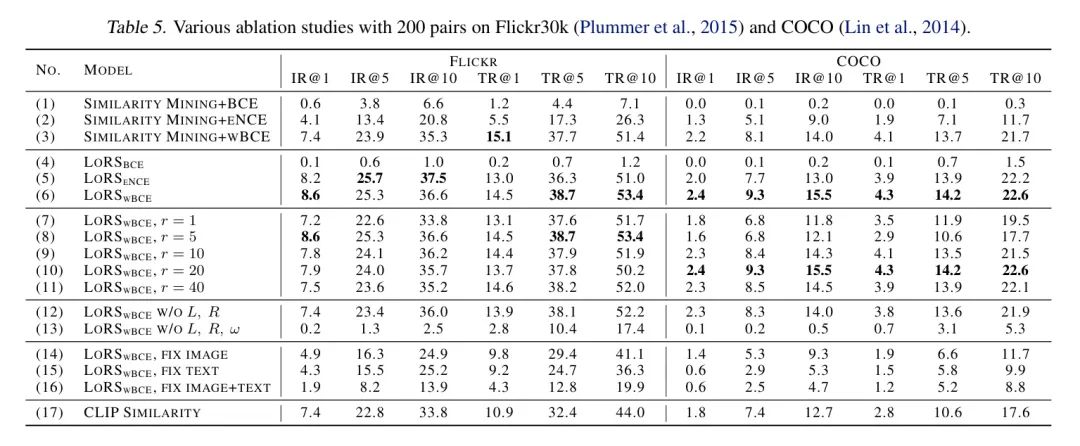
Составные изображения и текст. картина6Показано перед дистилляцией(исходный)и蒸馏后的картина像итекст。изображение показываетDeepDreamстиль(ZeilerиFergus,2014),Это обычное явление при дистилляции набора данных. Текст извлекается путем поиска заголовка в обучающем наборе, который наиболее близок к дистиллированному внедрению.,Следуя (Ву и др.,2023). Дополнительные примеры приведены в Приложении E.
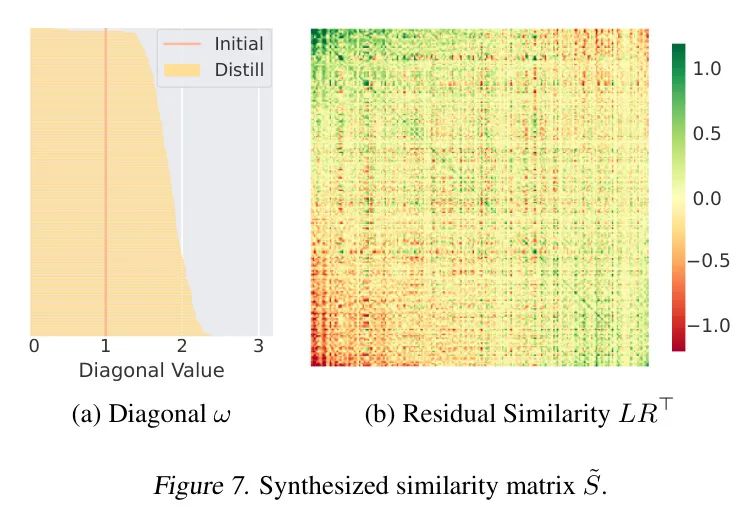
Выученная матрица сходства для наглядности,Автор показывает диагональную и остаточную матрицы соответственно на рисунке 7. Метод автора имеет тенденцию изучать большие диагональные значения.,Потому что это пары положительных образцов. LoRS также может обнаруживать ложноотрицательные образцы, изучая конкретные показатели сходства. Авторы визуализируют некоторые пары образцов с различным синтетическим сходством на рисунке 8. Образцы с большими значениями сходства, присвоенными LoRS, также похожи с точки зрения человека (третья пара слева на рисунке).,у вас похожие люди, прошлое и т. д.),Обычный CLIP будет неправильно считать их отрицательными парами.

5 Conclusions
В этой работе автор представил Анализ сходства низкого ранга (LoRS) как текст изображения Уточнение набора Эффективное решение для данных. LoRS также использует пары изображение-текст для извлечения GT матрица сходства с помощью разложения низкого ранга для повышения эффективности и масштабируемости.
Подход авторов показывает значительные улучшения по сравнению с существующими алгоритмами. Авторы выступают за использование LoRS в качестве базовой настройки синтетических данных для уточнения набора текстовых данных изображений.
ссылка
[1].Low-Rank Similarity Mining for Multimodal Dataset Distillation.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
