Легкий король MobileNetV4 с открытым исходным кодом | Топ-1 точность 87%, скорость вывода мобильного телефона 3,8 мс, взлет на месте!

Авторы представляют последнее поколение MobileNets под названием MobileNetV4 (MNv4), которое имеет общую и эффективную архитектуру, разработанную для мобильных устройств. По своей сути мы представляем блок поиска «Универсальное перевернутое узкое место» (UIB), унифицированную и гибкую структуру, которая сочетает в себе «Обратное узкое место» (IB), ConvNext, сети прямой связи (FFN) и новый вариант блока поиска повышенной глубины (ExtraDW). . Параллельно с UIB мы предлагаем Mobile MQA — блок внимания, разработанный специально для мобильных ускорителей и обеспечивающий значительное ускорение на 39%. В то же время авторы также представляют метод поиска оптимизированной нейронной архитектуры (NAS), который повышает эффективность поиска MNv4. Интеграция UIB, Mobile MQA и усовершенствованных методов NAS делает серию моделей MNv4 практически оптимальной по Парето для мобильных процессоров, DSP, графических процессоров и специализированных ускорителей, таких как Apple Neural Engine и Google Pixel Edge TPU — это функции, недоступные в других тестовых моделях. . Наконец, для дальнейшего повышения точности введен новый метод дистилляции. Благодаря этой технологии модель MNv4-Hybrid-Large достигла точности 87 % на ImageNet-1K и времени работы всего 3,8 мс на Pixel 8 EdgeTPU. Подпишитесь на официальный аккаунт и отправьте личное сообщение «Получить код», чтобы получить все модели MobileNetV4!
1 Introduction
Авторский подход к двухэтапному поиску по архитектуре нейронной сети (NAS), который отделяет грубый поиск от мелкозернистого поиска, значительно повышает эффективность поиска и облегчает создание значительно более крупных моделей, чем предыдущие современные модели. Кроме того, в сочетании с наборами данных автономной дистилляции шум в измерениях вознаграждения NAS снижается, тем самым улучшая качество модели.
Путем интеграции UIB, MQA и улучшенных формул NAS автор запустил серию моделей MNv4, добившись в основном оптимальной по Парето производительности на различных аппаратных платформах, включая CPU, DSP, GPU и профессиональные ускорители. Модельный ряд автора охватывает от чрезвычайно компактной конструкции MNv4-Conv-S (с 3,8M параметров и 0,2GMAC), которая обеспечивает точность ImageNet-1Ktop-1 73,8% за 2,4 миллисекунды на процессоре Pixel6, до MNv4-Hybrid-L высокого класса. вариант, устанавливающий новый стандарт точности мобильных моделей со временем вычислений 3,8 миллисекунды на Pixel 8 Edge TPU. Новый рецепт дистилляции авторов смешивает наборы данных с различными дополнениями и добавляет сбалансированные однородные данные, что улучшает обобщение и еще больше повышает точность. Благодаря этой технологии, несмотря на в 39 раз меньше MAC-адресов, MNv4-Hybrid-L по-прежнему достиг впечатляющей точности ImageNet-1Ktop-1 — 87 %: всего на 0,5 % ниже, чем у его модели-учителя.
2RelatedWork
Оптимизация точности и эффективности модели — хорошо изученный вопрос.
Мобильные сверточные сети: ключевые работы включают в себя MobileNetV1, использующий глубинно-разделимые свертки для повышения эффективности, MobileNetV2, представляющий линейные узкие места и инвертированные остатки, MnasNet, интегрирующий облегченные механизмы внимания в узких местах, и MobileOne, инвертирующий узкие места во время вывода. Добавление и перепараметризация линейных ветвей в .
Эффективные гибридные сети. Это направление исследований объединяет механизмы свертки и внимания. MobileViT сочетает в себе преимущества CNN с ViT посредством глобальных блоков внимания. MobileFormer обрабатывает MobileNet и Transformer параллельно и устанавливает двусторонний мост между ними для объединения функций. FastViT добавляет внимание на последнем этапе и использует большие ядра свертки в качестве замены механизма самообслуживания на ранних этапах.
Эффективное внимание: исследовательские усилия были сосредоточены на повышении эффективности MHSA. EfficientViT и MobileViTv2 предлагают методы аппроксимации с самообслуживанием для достижения линейной сложности с небольшим влиянием на точность. EfficientFormer-V2 снижает дискретизацию Q, K и V для повышения эффективности, тогда как CMT и NextViT уменьшают дискретизацию только K и V.
Аппаратно-ориентированный поиск по нейронной архитектуре (NAS). Еще одним распространенным методом является использование аппаратно-ориентированного поиска по нейронной архитектуре (NAS) для автоматизации процесса проектирования модели. NetAdapt использует эмпирическую таблицу задержек для оптимизации точности модели при целевых ограничениях задержки. MnasNet также использует таблицы задержек, но применяет обучение с подкреплением для аппаратного NAS. FBNet ускоряет многозадачный аппаратный поиск с помощью дифференцируемого NAS. MobileNetV3 оптимизирован для процессоров мобильных телефонов за счет сочетания аппаратного обеспечения NAS, алгоритма NetAdapt и архитектурных улучшений. MobileNetMultiHardware оптимизирует одну модель для нескольких аппаратных целей. Раз и навсегда разделяет обучение и поиск для повышения эффективности.
3Hardware-IndependentParetoEfficiency
Модели крыши. Чтобы модель была эффективной в целом, она должна быть в состоянии найти баланс между теоретической вычислительной сложностью и реальной производительностью оборудования.
Отличная производительность на аппаратных объектах, имеющих узкие места, которые сильно ограничивают производительность модели. Эти узкие места в первую очередь определяются самой высокой вычислительной производительностью оборудования и самой высокой пропускной способностью памяти.
Для этого авторы используют модель крыши, которая оценивает производительность заданной рабочей нагрузки и предсказывает, ограничена ли она узким местом в памяти или вычислительных ресурсах. Короче говоря, он игнорирует конкретные детали оборудования и учитывает только интенсивность рабочей нагрузки (LayerMAC).
/(WeightBytes
+ ActivationBytes
) до теоретических пределов аппаратных процессоров и систем памяти. Операции с памятью и вычисления примерно выполняются параллельно, поэтому более медленный из двух примерно определяет узкое место задержки. Чтобы применить модель линии крыши к
Для индексированного слоя нейронной сети автор может рассчитать задержку вывода модели ModelTime следующим образом:
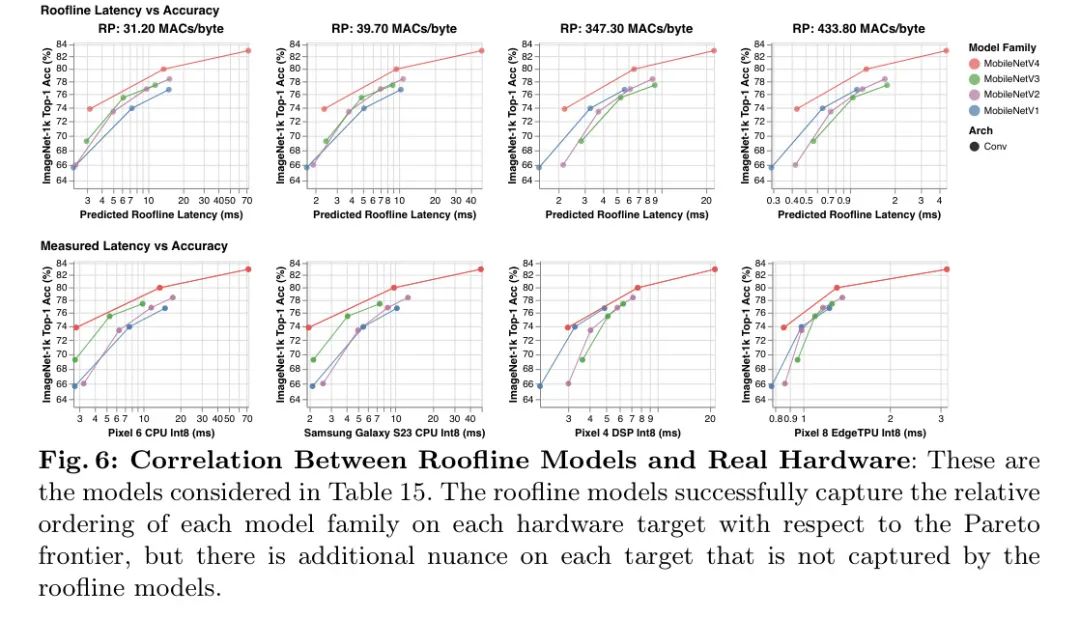
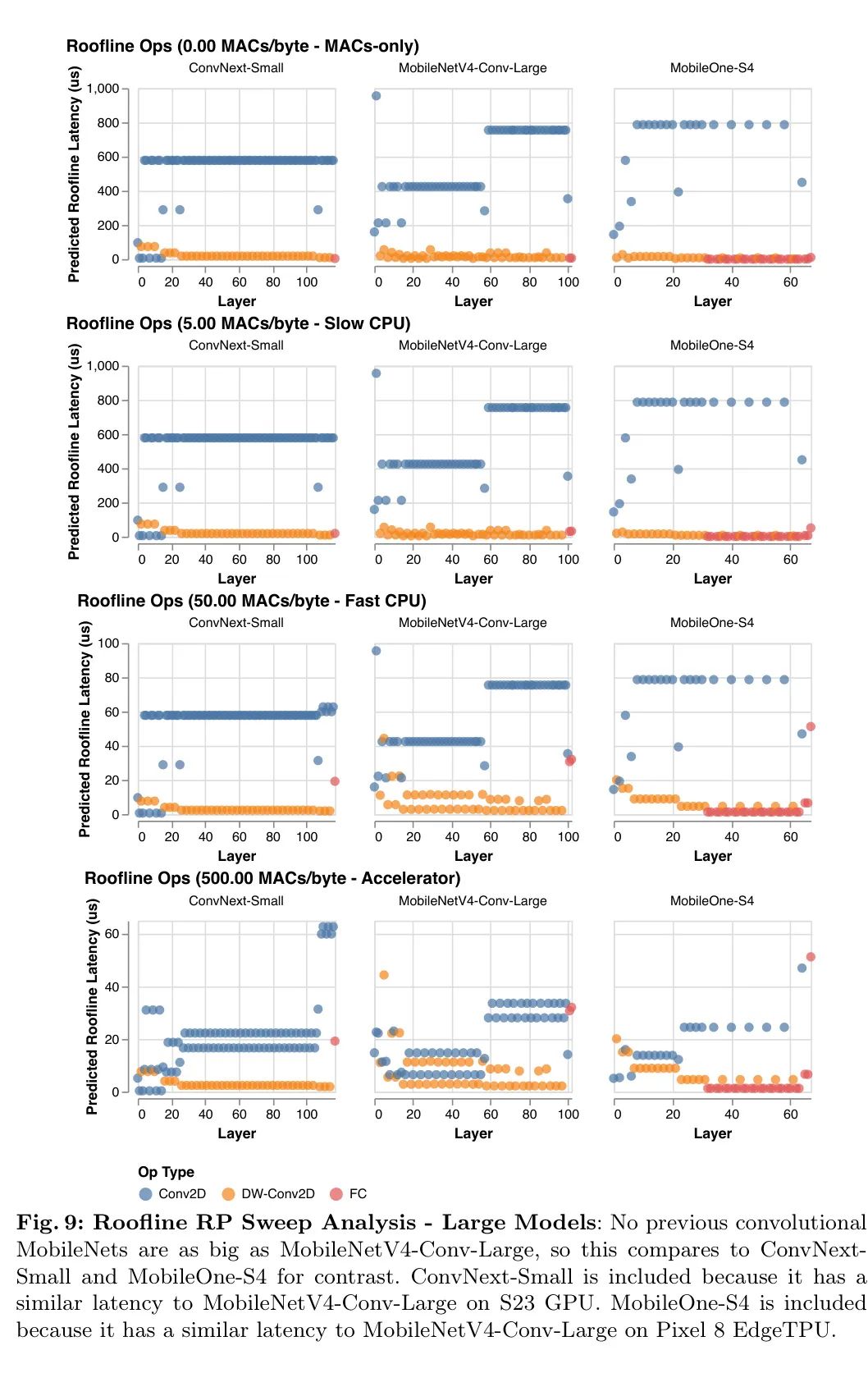
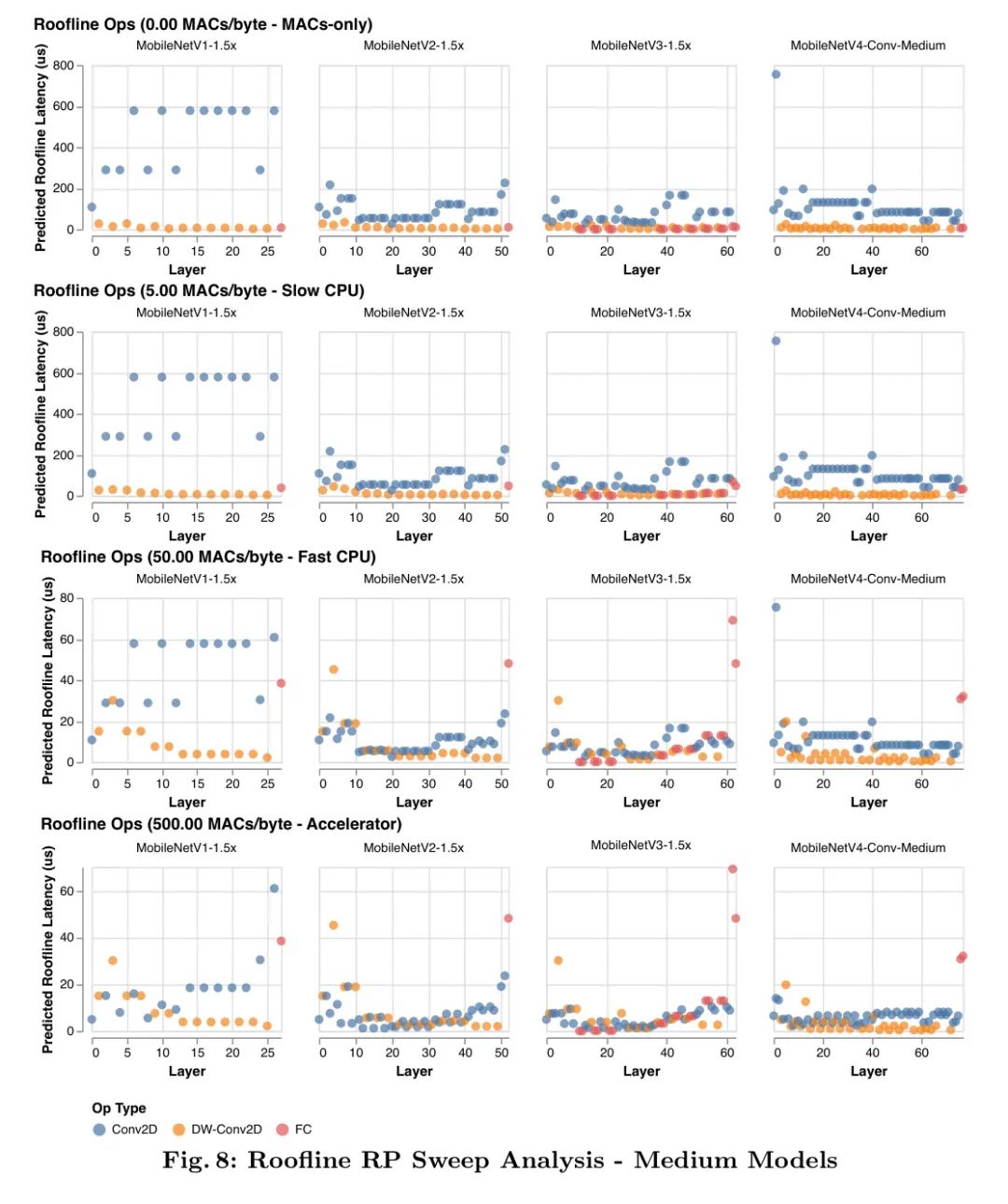
В модели линии крыши поведение оборудования суммируется с помощью точки гребня (RP), которая представляет собой отношение пиковых значений MAC оборудования к его пиковому значению MemBW. То есть это минимальная интенсивность работы, необходимая для достижения максимальной производительности. 2 Чтобы оптимизировать оборудование с различными узкими местами, как показано на рисунках 2 и 3, автор сканирует от наименьшего ожидаемого значения RP (0MAC/байт) до самого высокого значения (500MAC/байт), чтобы проанализировать задержку авторского Алгоритм — Более подробную информацию см. в Приложении F. Модель крыши полагается исключительно на соотношение передачи данных и вычислений, поэтому все оборудование с одинаковой RP ранжирует рабочую нагрузку одинаково по задержке. 3 Это означает, что анализ линии крыши сканирования-RP (см. следующий параграф) также применим к будущему аппаратному и программному обеспечению, если RP новой цели включен в диапазон сканирования.
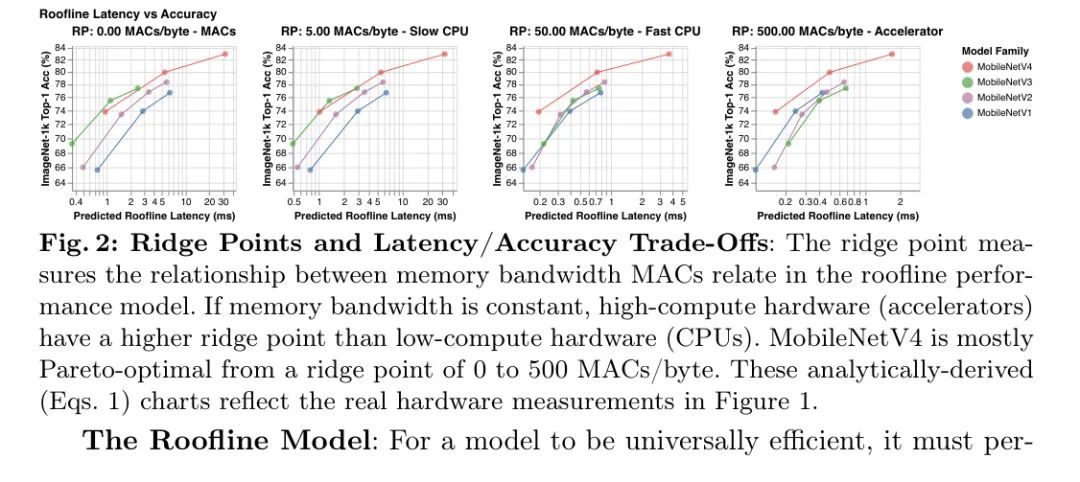
Анализ сканирования гребня: Как показано на рисунках 2 и 3, модель линии крыши показывает, как модель MobileNetV4 достигает аппаратно-независимой, почти оптимальной по Парето производительности по сравнению с другими сверточными сетями MobileNet. На оборудовании с низкой производительностью (например, ЦП) модели с большей вероятностью будут привязаны к вычислениям, чем к памяти. Следовательно, чтобы улучшить задержку, общее количество MAC следует свести к минимуму даже за счет увеличения сложности памяти (как в MobileNetV3Large-1.5x). На высокомагистральном оборудовании перемещение данных является узким местом, поэтому MAC не будет существенно замедлять модель, но может увеличить емкость модели (например, MobileNetV1-1.5x). Таким образом, модели, оптимизированные для низких шипов, работают медленно на высоких шипах, поскольку полносвязные уровни (FC) с интенсивным использованием памяти и низким MAC-адресом ограничены пропускной способностью памяти и не могут использовать преимущества высокодоступного пикового MAC-адреса.
Конструкция MobileNetV4: MobileNetV4 инвестирует в балансировку MAC-адресов и пропускной способности памяти для достижения максимальной отдачи при минимальных затратах, уделяя особое внимание началу и концу сети. В начале сети MobileNetV4 использует большие и дорогие первые несколько уровней, чтобы значительно увеличить пропускную способность модели и точность передачи данных. Эти начальные уровни в основном состоят из большого количества MAC, поэтому они стоят дороже только на оборудовании с низким RP. В конце сети все варианты MobileNetV4 используют одинаковый размер последнего полностью подключенного уровня (FC) для максимизации точности, хотя это приводит к тому, что варианты MNV4 меньшего размера страдают от более высокой задержки FC на оборудовании с высоким RP. Поскольку большие начальные сверточные уровни являются дорогостоящими на оборудовании с низким RP, но не дорогими на оборудовании с высоким RP, а окончательные полносвязные уровни являются дорогостоящими на оборудовании с высоким RP, но не дорогими на оборудовании с низким RP, модель MobileNetV4 не будет страдать от обоих замедлений при в то же время. Другими словами, модель MNV4 может использовать дорогие слои, которые повышают точность, но не несет одновременно совокупной стоимости этих слоев, обеспечивая почти оптимальную производительность по Парето во всех точках гребня.
4UniversalInvertedBottlenecks
Автор предлагает модуль Universal Inverted Bottleneck (UIB), адаптируемый строительный блок для эффективного проектирования сети, который имеет возможность гибко адаптироваться к различным целям оптимизации, не вызывая при этом резкого увеличения сложности поиска.
Модуль Inverted Bottleneck (IB), предложенный MobileNetV2, стал стандартизированным строительным блоком для эффективных сетей.
Основываясь на наиболее успешных элементах MobileNet — разделяемой глубокой свертке (DW) и точечном расширении (PW) и инвертированной структуре узкого места, в этом документе представлен новый строительный блок — блок универсального инвертированного узкого места (UIB), как показано на рисунке 4. Его структура довольно проста. Автор вводит два дополнительных DW в блоке перевернутого узкого места: один перед слоем расширения, а другой между слоем расширения и слоем проекции. Наличие или отсутствие этих DW является частью процесса оптимизации поиска архитектуры нейронной сети (NAS), что приводит к созданию новых архитектур. Хотя эта модификация проста, новый строительный блок авторов прекрасно объединяет несколько важных существующих блоков, включая исходный блок IB, блок ConvNext и блок FFN в ViT. Кроме того, UIB также представляет новый вариант: блок Extra Deep Convolution IB (ExtraDW).
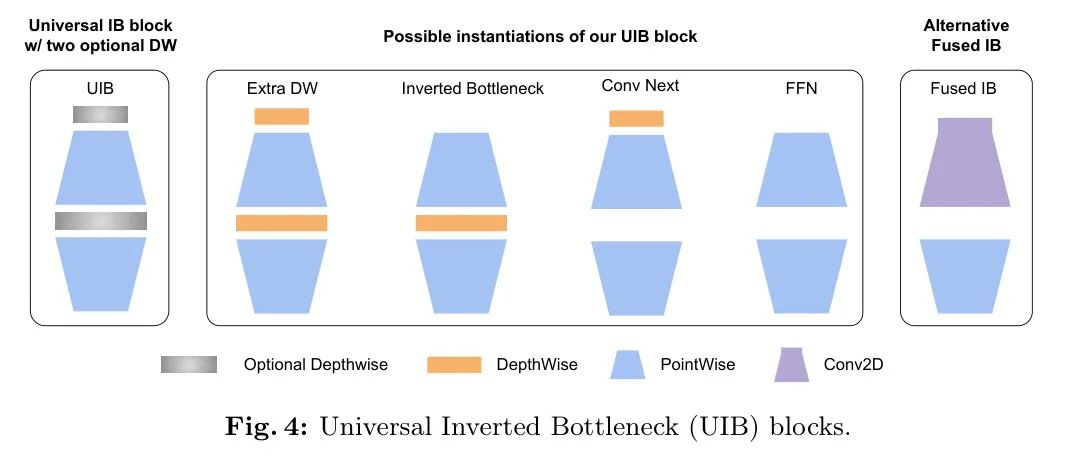
Помимо обеспечения гибких структур промежуточного уровня (IB) во время поиска архитектуры нейронной сети (NAS), авторы избегают любых надуманных правил масштабирования, таких как те, которые используются в EfficientNet, и вместо этого предоставляют отдельную структуру Optimize. Чтобы предотвратить взрывной рост размеров суперсетей NAS, авторы поделились общими компонентами (точечное расширение и проекция) и просто добавили отделимые по глубине свертки (DW) в качестве дополнительной опции поиска. В сочетании с алгоритмом поиска сетевой архитектуры на основе суперсети этот подход позволяет совместно использовать большинство параметров (более 95%) между различными экземплярами, что делает NAS чрезвычайно эффективным.
Создание экземпляра UIB Существует четыре возможных способа создания двух дополнительных сверток глубины в блоке UIB (рис. 4), что приводит к различным компромиссам.
Перевернутое узкое место (IB) — пространственное смешивание при активации расширенных функций для обеспечения большей емкости модели за счет увеличения стоимости.
ConvNext обеспечивает более дешевое пространственное смешивание с использованием ядра большего размера, выполняя пространственное смешивание перед расширением.
ExtraDW — это новый вариант, предложенный в этой статье, который позволяет дешево увеличить глубину и зону приема сети. Это обеспечивает следующие преимущества:
Сочетает в себе преимущества ConvNext и IB.4.
FFN состоит из двух точечных сверток (PW) 1x1, между которыми добавлены слои активации и нормализации. PW — одна из наиболее удобных для ускорителя операций, но ее лучше всего использовать в сочетании с другими модулями.
На каждом этапе сети UIB обеспечивает гибкость для:
- Достигните мгновенного компромисса между пространственным и канальным микшированием.
- Расширяйте свое восприимчивое поле по мере необходимости.
- Максимизируйте использование вычислительных ресурсов.
5MobileMQA
В этом разделе авторы представляют MobileMQA, новый блок внимания, оптимизированный для ускорителей, который обеспечивает повышение скорости вывода более чем на 39%.
Важность интенсивности операций. В недавних исследованиях визуальных моделей большинство людей сосредоточилось на сокращении арифметических операций (MAC) для повышения эффективности. Однако настоящим узким местом производительности мобильных ускорителей часто являются не вычисления, а доступ к памяти. Это связано с тем, что вычислительная мощность, обеспечиваемая ускорителем, намного превышает пропускную способность памяти. Следовательно, простое минимизация MAC может не привести к повышению производительности. Вместо этого авторы должны учитывать интенсивность операций, то есть соотношение арифметических операций и обращений к памяти.
MQA эффективен в гибридных моделях: MHSA проецирует запросы, ключи и значения в несколько пространств для сбора различных аспектов информации. Multi-Query Attention (MQA) [37] упрощает это за счет использования общих ключей и значений во всех головках. Хотя необходимы несколько заголовков запроса, большие языковые модели могут эффективно совместно использовать заголовки для отдельных ключей и значений без ущерба для точности [25]. Использование общего заголовка для ключей и значений может значительно снизить требования к доступу к памяти, когда количество токенов в пакете невелико по сравнению с размерностью функции, тем самым значительно повышая интенсивность операций. Это часто относится к моделям гибридного видения, ориентированным на мобильные приложения, где внимание используется только на поздних стадиях с низким разрешением и большими размерами функций, а размер пакета обычно равен 1. Эксперименты авторов подтвердили преимущества MQA в гибридных моделях. Как показано в таблице 1, по сравнению с MHSA, MQA обеспечивает ускорение более чем на 39% на Edge TPU и графическом процессоре Samsung S23 с незначительной потерей качества (-0,03%). MQA также снижает MAC и параметры модели более чем на 25%. Насколько известно автору, автор первым применил MQA в мобильном зрении.

Принять асимметричное пространственное понижение разрешения. Вдохновленный MQA, который использует асимметричные вычисления между запросом, ключом и значением, автор интегрирует внимание к уменьшению пространства (SRA) [45] в оптимизированный авторский модуль MQA, чтобы уменьшить разрешение ключа и значения, сохраняя при этом высокое разрешение. Запрос. Эта стратегия основана на наблюдаемой корреляции между пространственно соседними маркерами в модели смеси, которая приписывается сверточным фильтрам пространственной смеси в ранних слоях. Благодаря асимметричной пространственной субдискретизации авторы поддерживают одинаковое количество токенов между входом и выходом, сохраняя высокое разрешение внимания и значительно повышая эффективность. В отличие от AvgPooling, авторский метод заменяет AvgPooling сверткой глубины 3x3 с шагом 2, обеспечивая экономичный способ увеличения емкости модели.
Mobile MQA Здесь автор предлагает авторский мобильный MQA модуль:
В этом тексте
Представляет сокращение пространства, которое в дизайне автора относится к разделимой по глубине свертке (DW) с шагом 2 или к функции идентичности, когда сокращение пространства не используется. Как показано в Таблице 2, в сочетании с асимметричной пространственной понижающей дискретизацией это может повысить эффективность более чем на 20% с минимальной потерей точности (-0,06%).
6DesignofMNv4Models
Философия дизайна автора: простота и эффективность. При разработке новейших мобильных сетей основной целью авторов было достижение оптимальности по Парето на различных мобильных платформах. Для достижения этой цели авторы сначала провели обширный корреляционный анализ существующих моделей и оборудования. Путем эмпирического тестирования авторы нашли набор компонентов и параметров, который не только обеспечивает высокую корреляцию между моделями затрат (прогнозирование затрат на задержку) на различных устройствах, но и приближается к фронту Парето по производительности.
Исследование авторов выявило некоторые ключевые выводы:
Проблемы эффективности многопутевого распространения. Групповые свертки и аналогичные конструкции многопутевого распространения, несмотря на меньшее количество операций с плавающей запятой (FLOPcounts), могут быть менее эффективными из-за сложности доступа к памяти.
Аппаратная поддержка важна: продвинутые модули, такие как Squeeze и Excite (SE) [21],
Поддержка GELU и LayerNorm на DSP не очень хорошая, LayerNorm также медленнее, чем BatchNorm, а производительность SE на ускорителях также медленнее.
_Сила простоты_: традиционные компоненты — глубокая и точечная свертка, ReLU, пакетная нормализация и простые механизмы внимания (например, MHSA) — демонстрируют превосходную эффективность и аппаратную совместимость.
На основании этих выводов авторы установили ряд принципов проектирования:
Стандартные компоненты: авторы отдают приоритет широко поддерживаемым элементам для беспрепятственного развертывания и эффективности оборудования.
Гибкий модуль UIB: новые строительные блоки UIB с возможностью поиска поддерживают адаптируемое пространственное и канальное микширование, настройку восприимчивого поля и максимальное использование вычислительных ресурсов посредством поиска сетевой архитектуры (NAS), обеспечивая баланс между эффективностью и сбалансированным компромиссом по точности.
Использование механизма прямого внимания: авторский механизм MobileMQA отдает приоритет простоте для оптимальной производительности.
Эти принципы делают MobileNetV4 оптимальным по Парето в большинстве случаев на всех оцениваемых аппаратных средствах. Ниже авторы подробно описывают улучшенный рецепт NAS для поиска модели UIB, описывают конкретные конфигурации поиска для различных размеров модели MNv4-Conv и объясняют процесс построения гибридной модели.
RefiningNASforEnhancedArchitectures
Для эффективного создания экземпляров блоков UIB авторы использовали TuNAS, настроенный для повышения производительности.
Стратегия расширенного поиска. Подход авторов смягчает предвзятость TuNAS в пользу меньших фильтров и коэффициентов расширения из-за совместного использования параметров за счет реализации двухэтапного поиска. Эта стратегия решает проблему различия количества параметров между уровнем глубины UIB и другими параметрами поиска.
Грубозернистый поиск. Первоначально авторы сосредоточились на определении оптимального размера фильтра, сохраняя при этом фиксированные параметры: обратный блок узкого места с коэффициентом расширения по умолчанию 4 и ядром с разделением по глубине 3x3.
Детальный поиск: на основе предварительных результатов поиска авторы искали две глубоко стратифицируемые конфигурации UIB (включая их наличие и размер ядра 3x3 или 5x5), сохраняя при этом коэффициент расширения постоянным, равным 4.
Таблица 3 демонстрирует повышение эффективности и качества модели, достигнутое авторами двухэтапного поиска по сравнению с традиционным одноэтапным поиском, исследующим единое пространство поиска за один проход TuNAS.

Улучшение TuNAS для надежного обучения Успех TuNAS зависит от точной оценки качества архитектуры, что имеет решающее значение для расчета вознаграждения и изучения политики. Первоначально TuNAS использовал ImageNet-1k для обучения суперсети оценке архитектуры. Однако этот подход игнорирует шум и возмущения, с которыми сеть может столкнуться в практических приложениях. Для решения этой проблемы авторы рекомендуют добавлять в тренировочный процесс тренировки на устойчивость. В частности, автор ввел в обучающий набор различные методы увеличения данных и состязательные образцы, чтобы повысить надежность модели. Таким образом, TuNAS может лучше оценить производительность архитектуры в шумной среде, тем самым улучшая качество окончательной изученной сетевой архитектуры.
Network, однако на производительность модели в ImageNet существенно влияют увеличение данных, регуляризация и выбор гиперпараметров. Учитывая, что образцы архитектуры TuNAS постоянно развиваются, найти стабильный набор гиперпараметров непросто.
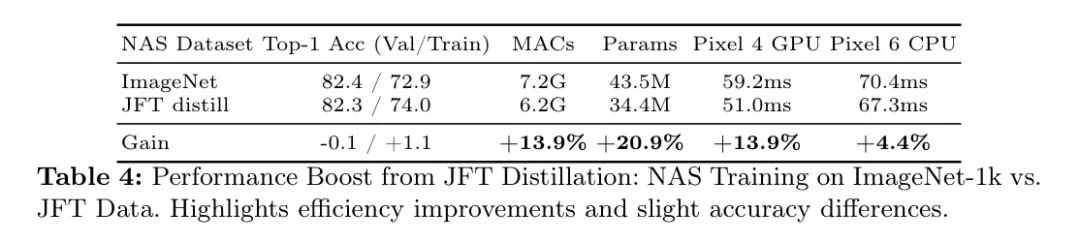
Авторы решают эту проблему, используя автономный дистиллированный набор данных, который устраняет необходимость в дополнительных методах дополнения и снижает чувствительность к настройкам регуляризации и оптимизации. Набор данных дистилляции JFT, описанный в разделе 8, который использовался авторами для обучения TuNAS, демонстрирует значительные улучшения в Таблице 4. Учитывая, что модель с масштабированием по глубине превосходит модель с масштабированием по ширине в расширенных сеансах обучения, авторы расширили обучение TuNAS до 750 эпох, что привело к созданию более глубокой и более качественной модели.
Автор построил MNv4-ConvМодель на основе оптимизированных для NAS блоков UIB.,и адаптировать его к конкретным ограничениям ресурсов. Более подробную информацию см. в Приложении 0.A. Совместим с другими смесями Модель,Авторы обнаружили, что добавление механизма внимания на последний этап Модели свертки наиболее эффективно. В MNv4-Гибридная Модель,Автор чередовал использование блоков MobileMQA и блоков UIB для повышения производительности. Подробные характеристики модели,Пожалуйста, дайте ссылку на Приложение 0.D.
7Results
В этом разделе автор продемонстрирует почти оптимальную производительность по Парето модели MobileNetV4 (MNv4) при классификации ImageNet-1K и обнаружении объектов COCO.
ImageNetclassification
Экспериментальная установка: Чтобы оценить производительность архитектуры модели, авторы следовали стандартному протоколу обучения, используя только обучающие разделения ImageNet-1k и измеряя точность Top-1 на проверочных разделениях. Анализ задержки, проведенный автором, охватывает широкий и репрезентативный выбор разнообразного мобильного оборудования, включая процессор ARM Cortex (Pixel 6, Samsung S23), Qualcomm Hexagon DSP (Pixel 4), графический процессор ARM Mali (Pixel 7), Qualcomm Snapdragon (графический процессор S23), Apple Neural Engine и Google Edge TPU. Полная авторская настройка обучения подробно описана в Приложении 0.C.
В тестах авторы сравнили свою модель с ведущими моделями эффективности, включая гибридные (MiT-EfficientViT, FastViT, NextViT) и сверточные (MobileOne, ConvNext и ранее MobileNet).
Авторы выбрали эти версии на основе заявленной точности Top-1 и оценки задержки авторов ([19][36][18]). Стоит отметить, что авторы улучшили серию MobileNet (V1, V2, V3), используя современные методы обучения, что привело к значительному улучшению точности: MobileNetV1 улучшилась на 3,4% до 74,0%; V2 улучшилась на 1,4% до 73,4%; на 0,3% до 75,5%. Эти улучшенные базовые показатели MobileNets используются в данной статье для выделения архитектурных достижений.
результат:
Результаты авторов, показанные на рисунке 1 и подробно описанные в таблице 5, показывают, что модель MNv4 достигает оптимальности по Парето в большинстве случаев в диапазоне целевых показателей точности и мобильного оборудования, включая ЦП, DSP, графический процессор и специализированные ускорители, такие как Apple Neural Engine и Гугл Эдж ТПУ.
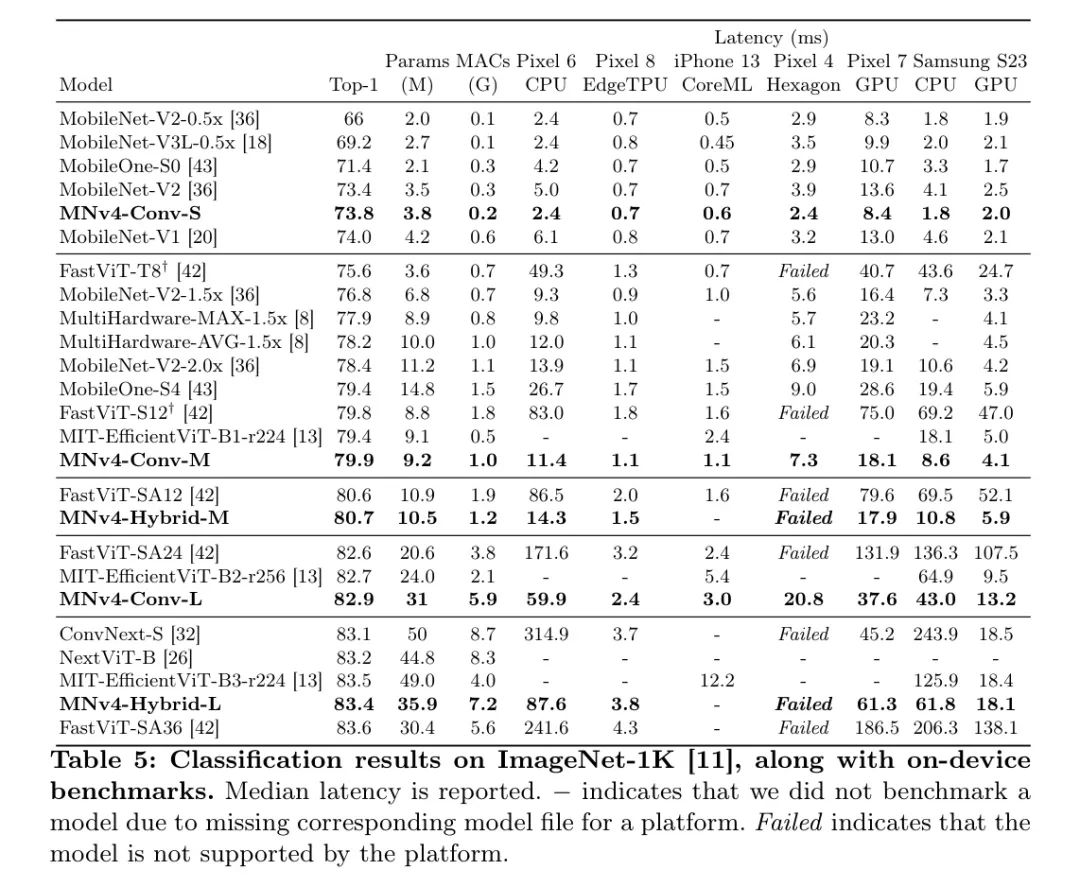

По процессору модель MNv4 значительно превосходит другие модели, будучи примерно в два раза быстрее, чем MobileNetV3, и в несколько раз быстрее, чем другие модели с той же целевой точностью. На EdgeTPU модель MNv4 в два раза быстрее MobileNetV3 при том же уровне точности. В частности, модель MNv4-Conv-M более чем на 50 % быстрее, чем MobileOne-S4 и FastViT-S12, при этом улучшая точность Top-1 MobileNetV2 на 1,5 % при сопоставимой задержке. На S23GPU и iPhone13CoreML(ANE) большинство моделей MNv4 находятся на границе Парето. На графическом процессоре S23 ближайший конкурент, MIT-EfficientViT, работает быстрее, чем MIT.
При той же точности задержка MNv4 вдвое выше, чем у CoreML. FastViT, оптимизированный для AppleNeuralEngine, занял второе место на CoreML, но имел задержку более чем в пять раз большую, чем MNv4 на графическом процессоре S23. Как и многие гибридные модели, гибридная модель MNv4 несовместима с DSP. Тем не менее, модели MNv4-Conv по-прежнему лучше всего работают с DSP, что подчеркивает их лучшую совместимость и эффективность на различных аппаратных платформах. Модель MNv4-Conv обеспечивает превосходную аппаратную совместимость и эффективность. Этот успех подчеркивает мощь авторских блоков UIB, улучшенную рецептуру NAS и хорошо продуманное пространство поиска. MNv4-Hybrid обеспечивает отличную производительность на процессоре и ускорителе, демонстрируя кроссплатформенную эффективность авторской разработки MobileMQA.
Обобщаемость имеет решающее значение для мобильных моделей, что требует от них достижения оптимальной производительности на различных аппаратных платформах. Оценка авторов подчеркивает проблемы, с которыми сталкиваются существующие модели при достижении этой цели. MobileNetV3 хорошо работает с процессорами, но не справляется с EdgeTPU, DSP и графическими процессорами. FastViT хорошо показал себя на Neural Engine от Apple, но имел проблемы с процессором и графическим процессором. EfficientViT работает лучше на графическом процессоре, но его производительность на Apple Neural Engine неудовлетворительна. Напротив, модель MNv4-Conv демонстрирует исключительно хорошую совместимость и обеспечивает практически универсальную производительность, оптимальную по Парето, на широком спектре оборудования, включая процессоры, графические процессоры, Apple Neural Engine и TPU Google Edge. Такая универсальность гарантирует, что модель MNv4-Conv может быть беспрепятственно развернута в мобильных экосистемах без каких-либо корректировок для конкретной платформы, устанавливая новый стандарт повсеместного распространения мобильных моделей.
COCOObjectDetection
Экспериментальная установка: автор оценил эффективность сети MNv4Backbone в задаче обнаружения объектов на наборе данных COCO17. Авторы сравнили магистральную сеть MNv4 размера M с эффективной магистральной сетью SOTA с аналогичным количеством MAC-адресов. Для каждой Backbone-сети авторы построили детектор объектов с использованием фреймворка RetinaNet. Авторы добавляют 256-мерный декодер FPN и 256-мерную головку прогнозирования с 4 сверточными слоями к конечным точкам P3-P7. Как и в случае с детектором движения, авторы используют свертки с разделением по глубине, чтобы уменьшить вычислительную сложность декодера FPN и головки прогнозирования ограничивающего прямоугольника. Все модели автор тренировал на тренировочном комплексе COCO17 на 600 патронов.
Все изображения изменены до размера
и улучшено с помощью случайного горизонтального переворота, случайного масштабирования и Randaug. Авторы исключили улучшения сдвига и вращения из Randaug, поскольку эти деформации уменьшали бы AP для обнаружения небольших целей. Для обучения используется размер пакета 2048, оптимизатор Адама и затухание веса L2 0,00003. Авторы используют косинусный график скорости обучения с 24-периодной разминкой и настраивают скорость обучения для каждой модели индивидуально. Для всех базовых показателей авторы установили множители фильтра примерно на сопоставимые значения MAC. После экспериментов по классификации сеть MobileNetV4Backbone обучается с использованием случайного коэффициента отсева 0,2. Все MobileNetBaselines обучаются с использованием официальной реализации TensorflowModelGarden. Автор повторно реализовал EfficientFormer, используя Tensorflow.
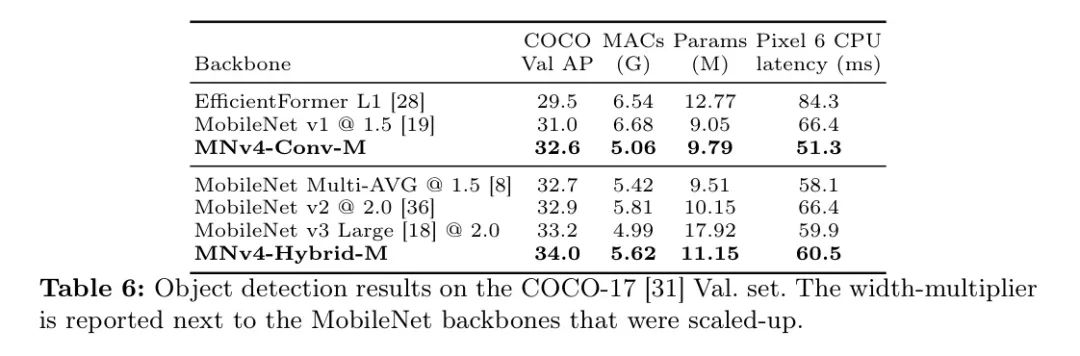
результат: В таблице 6 представлены результаты экспериментов. существовать
При входном разрешении весь детектор используется для расчета параметров, MAC и эталонов. Детектор MNv4-Conv-M только со свертками среднего размера достигает 32,6% AP, аналогично MobileNetMulti-AVG и MobileNetv2. Однако задержка этой модели на процессоре Pixel6 на 12 % ниже, чем у MobileNetMulti-AVG, и на 23 % ниже, чем у MobileNetv2. При увеличении задержки процессора Pixel6 на 18 % добавление блока MobileMQA улучшило точку доступа детектора MNv4-Hybrid-M на +1,6 % по сравнению с MNv4-Conv-M, продемонстрировав эффективность MNv4 в его гибридной форме в таких задачах, как обнаружение пола и эффективность.
8Enhanceddistillationrecipe
Дополняя архитектурные инновации, дистилляция является мощным инструментом повышения эффективности машинного обучения. Его преимущества особенно значительны для мобильных моделей, поскольку потенциально обеспечивают повышение эффективности в несколько раз при строгих ограничениях развертывания. На основе надежного эталонного теста дистилляции PatientTeacher авторы представляют две новые технологии для дальнейшего повышения производительности.
Динамическое смешивание наборов данных. Увеличение данных имеет решающее значение для производительности извлечения. Хотя предыдущие методы основывались на фиксированных последовательностях увеличения, авторы обнаружили, что динамическое смешивание нескольких наборов данных с различными стратегиями увеличения приводило к лучшим результатам извлечения. Авторы провели эксперименты с тремя ключевыми наборами данных для извлечения:
: применить InceptionCrop к 500 репликам ImageNet-1k, а затем RandAugment l2m9.
: использование InceptionCrop с последующим методом Extreme Mixup на 1000 репликах ImageNet-1k (имитация метода терпеливого учителя).
:
: Во время тренировочного процесса
и
динамическое смешивание.
Результаты автора в таблице 7 показывают, что
Превосходит точность учащихся
(84,1% против 83,8%). Однако динамически смешанные наборы данных (
+
) увеличил точность до 84,4% (+0,3%). Этот вывод предполагает, что смешивание наборов данных расширяет пространство для улучшенных изображений, увеличивая сложность и разнообразие, что в конечном итоге приводит к улучшению успеваемости учащихся.

Увеличение данных JFT: чтобы увеличить объем обучающих данных, автор повторно выбирает набор данных JFT-300M так, чтобы каждая категория содержала 130 000 изображений (всего 130 миллионов изображений), добавляя данные, сбалансированные по доменам. Следуйте протоколу NoisyStudent и используйте EfficientNet-B0, обученный на ImageNet-1K.
Порог выше 0,3. Для категорий с большим объемом данных мы выбираем первые 130 тыс. изображений; для редких категорий мы дублируем изображения, чтобы сохранить баланс. Этот набор данных был реплицирован 10 раз. Из-за сложности JFT авторы применили более слабый метод улучшения (начальное кадрирование + RandAugmentl2m5). Это формирует набор данных дистилляции
. Таблица 7 показывает, что использование только JFT (
) приведет к снижению точности на 2%. Однако объединение JFT с данными ImageNet привело к улучшению на 0,6%, что продемонстрировало ценность дополнительных данных для обобщения.
Авторский метод уточнения: авторский комплексный метод уточнения динамических смешанных наборов данных
,
и
для достижения различных улучшений,и использовать сбалансированные по классам данные JFT. Как показано в Таблице 7 и Таблице 8.,По сравнению с предыдущей SOTA,Метод авторов последовательно повышает точность топ-1 более чем на 0,8%. Обучение студента MNv4-Conv-L Модель для 2000 эпох,Была получена точность топ-1 85,9%. Это доказывает эффективность авторского метода: Модель ученика в 15 раз меньше по параметрам, чем ее учитель Модель EfficientNet-L2,В 48 раз меньше на MAC,Но точность упала всего на 1,6%. В сочетании с предварительной тренировкой по JFT для совершенствования,MNv4-Conv-Hybrid достиг первой точности 87,0%.

9Conclusion
В этой статье авторы предлагают MobileNetV4, семейство эффективных моделей общего назначения, предназначенных для эффективной работы во всей мобильной экосистеме. Авторы воспользовались многочисленными достижениями, чтобы MobileNetV4 достигла оптимальности по Парето практически на всех мобильных процессорах, графических процессорах, DSP и выделенных ускорителях — функция, которой нет ни в одной другой модели.
Автор протестировал различные Модели. Автор представляет новое универсальное узкое место инверсии — Мобильное. MQAслой,И в сочетании с методом улучшенного поиска нейронной архитектуры (NAS). Сочетание их с новым, современным методом дистилляции.,Автор достиг точности ImageNet-1K 87% с задержкой 3,8 мс на Pixel8EdgeTPU.,Прогресс в области мобильного компьютерного зрения. также,Автор также предлагает теоретическую основу и аналитический метод.,понять, что делает Модель универсальной для гетерогенных устройств,Это указывает путь для будущих проектов. Авторы надеются, что эти новые разработки и аналитические основы будут способствовать дальнейшему развитию мобильного компьютерного зрения.
Строительство поискового пространства:
_Исправлен начальный слой:_Автор сначала использует слой Conv2D (ядро 3x3,Размер шага 2) для быстрого уменьшения разрешения.,За этим последовал оптимизированный для NAS объединенный блок IB на втором этапе (размер шага 2).,Чтобы сбалансировать эффективность и точность.
_Оптимизация на основе NAS: _Процесс NAS точно определяет количество блоков UIB и создание экземпляров параметров на оставшихся четырех этапах, обеспечивая оптимальную структуру производительности.
Фиксированный слой заголовка: автор использует ту же конфигурацию слоя заголовка, что и MobileNetV3.
Замечено, что точечные свертки внутри блоков UIB имеют тенденцию демонстрировать меньшую вычислительную интенсивность при высоких разрешениях.,Автор отдает приоритет использованию более вычислительно интенсивных операций на начальном уровне.,Чтобы сбалансировать эффективность и точность.
Цели оптимизации автора:
MNv4-Conv-S: двойная цель — 285MMAC и задержка 0,2 мс (Pixel6EdgeTPU, вход 224 пикселей).
MNv4-Conv-M: задержка 0,6 мс (Pixel6EdgeTPU, входное разрешение 256 пикселей).
MNv4-Conv-L: целевая двойная задержка: 2,3 мс (Pixel6EdgeTPU) и 2,0 мс (Pixel7EdgeTPU) для ввода 384 пикселей.
Следует отметить, что, ограничив пространство поиска автора компонентами с хорошими коррелирующими моделями стоимости между устройствами, автор обнаружил, что оптимизация задержки EdgeTPU может напрямую создать в целом эффективную модель, которая подробно продемонстрирована позже.
Appendix0.BBenchmarkingmethodology
Авторы применяют последовательную стратегию сравнительного анализа на различных мобильных платформах.,Исключение сделано для Apple Neural Engine. с целью повышения эффективности,Модель конвертирована в формат TensorFlowLite.,И количественно соответствует INT8 для мобильных процессоров и Hexagon и Edge TPU.,Мобильные графические процессоры используют FP16. Автор запускает каждую Модель 1000 раз.,И возьмите среднюю задержку этих запусков. Затем,Автор повторяет процесс 5 раз для каждой Модели.,и сообщите медианное значение среднего значения. Для оптимизации производительности,Автор выставляет привязку ЦП к самому быстрому ядру,И используйте бэкэнд XNNPACK для оценки ЦП. В сравнении,Сравнительный тест Apple Neural Engine (анализ производительности на iPhone13 с iOS16.6.1, CoreMLTools7.1 и Xcode15.0.1),Модель PyTorch конвертируется в формат MLProgram CoreML.,Take Float16Точность,Используйте ввод MultiArray с плавающей запятой16, чтобы минимизировать дублирование ввода.
Appendix0.CTrainingsetupforImageNet-1kclassification
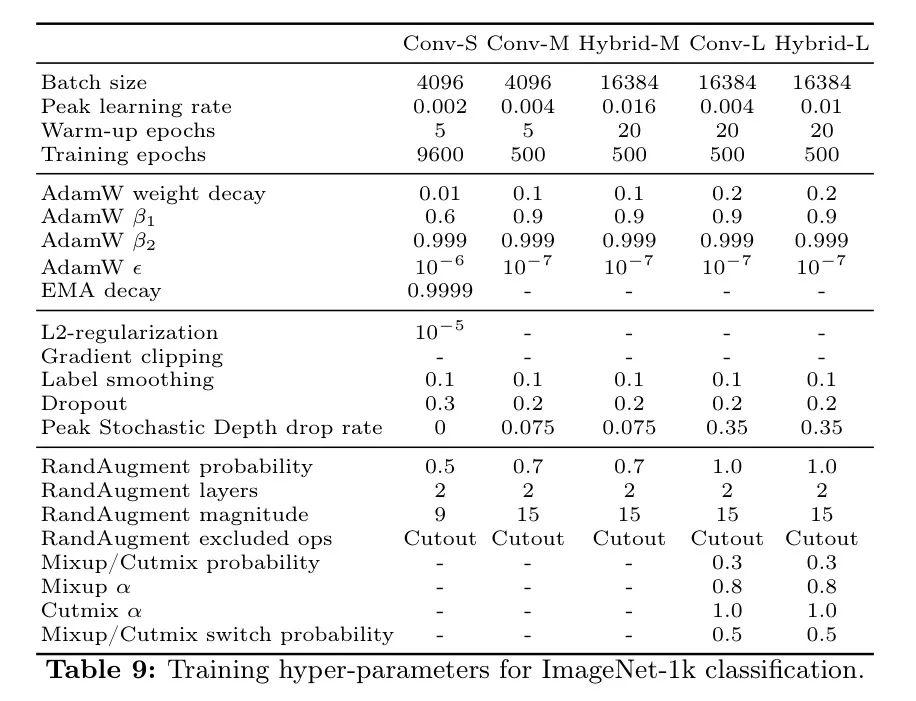
Чтобы улучшить производительность модели,Метод обучения автора включает широко распространенные методы увеличения данных и методы регуляризации. С точки зрения увеличения данных,Автор использует обрезку Inception.,Перевернуть по горизонтали,RandAugment,Mixup,и Кат Микс. В плане регуляризации,Автор применил нормализацию L2 и случайное выпадение глубины. Сила армирования и регуляризации регулируется в зависимости от размера Модели.,Подробную информацию см. в Таблице 9.
Appendix0.DModeldetails
Детали архитектуры авторской модели MNv4 описаны в таблицах 10–14.
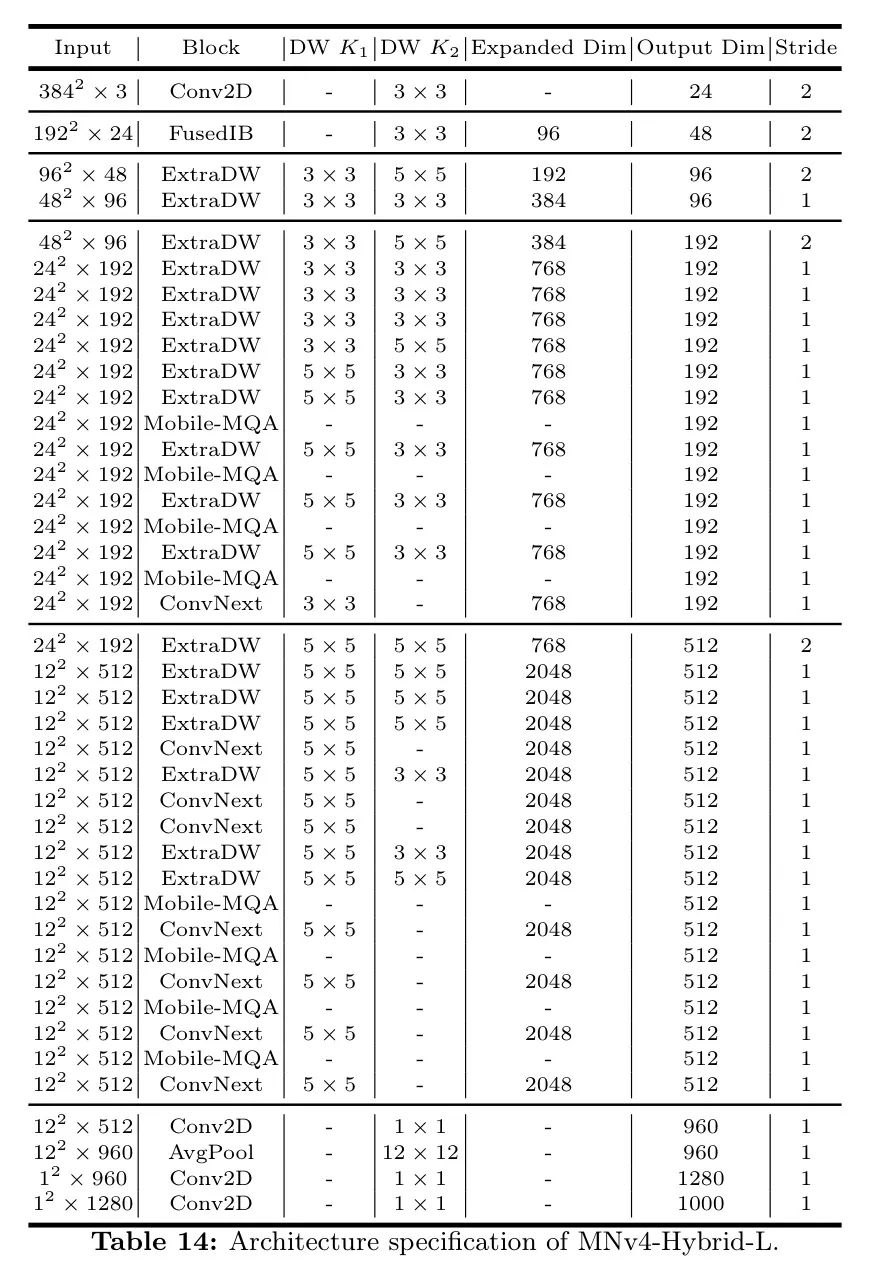

Сейчас,Позвольте автору подробно рассмотреть оптимизированную для TuNAS модель MNv4-ConvModel. Оптимизированная макроархитектура TuNAS стратегически объединяет четыре экземпляра UIB: ExtraDW, ConvNext, IBиFFN. Эта комбинация демонстрирует гибкость UIB и важность использования разных блоков создания экземпляров на разных этапах сети. Конкретно,В начале каждого возможного этапа,Где пространственное разрешение значительно снижается,ExtraDW становится первым выбором. Дизайн разделительных слоев двойной глубины в ExtraDW помогает расширить поле восприятия.,Улучшите пространственное смешивание,Эффективно минимизируйте потерю разрешения. такой же,по тем же причинам,ExtraDW также часто выбирается на ранних стадиях MNv4-ConvModel. для финального слоя,Поскольку предыдущие слои уже выполняли большое количество пространственных смешиваний.,FFNиConvСледующий выбранный,Потому что микширование каналов обеспечивает больший выигрыш.
Таблица 12:* Архитектурные характеристики МНв4-Гибрид-М.


ссылка
MobileNetV4- UniversalModelsfortheMobileEcosystem



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
