Легкий инструмент преобразования Excel в Markdown, построенный на чистом Python.
@toc
Используйте Python для создания инструмента CLI для преобразования Excel в Markdown.
На работе нам часто приходится конвертировать таблицы Excel в формат Markdown для совместного использования в документах, блогах или других платформах, поддерживающих Markdown. Однако некоторые редакторы Markdown неоптимально поддерживают контент, скопированный и вставленный из Excel, что приводит к путанице в форматировании после преобразования. Кроме того, если вам необходимо часто обрабатывать файлы одного и того же типа, преобразование вручную становится затруднительным. Поэтому я решил создать инструмент CLI, который автоматизирует этот процесс преобразования.
идеи дизайна
Чтобы убедиться, что этот инструмент прост в использовании и портативен, я решил написать этот инструмент CLI на Python. Поскольку я хотел, чтобы мои коллеги могли легко использовать этот инструмент, я решил свести к минимуму зависимости от сторонних библиотек, чтобы упростить развертывание инструмента.
Анализ структуры файла Excel
Прежде чем мы начнем писать код, нам нужно понять Excel Структура файла. После небольшого исследования мы обнаружили Excel На самом деле файл представляет собой ZIP Сжатый пакет, содержащий серию XML документ. В частности, мы уделяем особое внимание sharedStrings.xml и sheet1.xml Два файла. Первый содержит строки из таблицы, а второй — фактические данные таблицы.
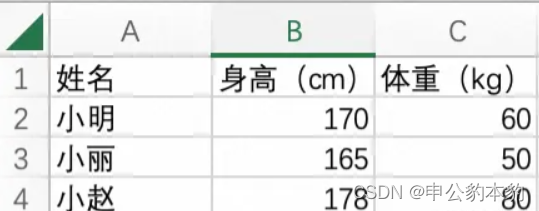
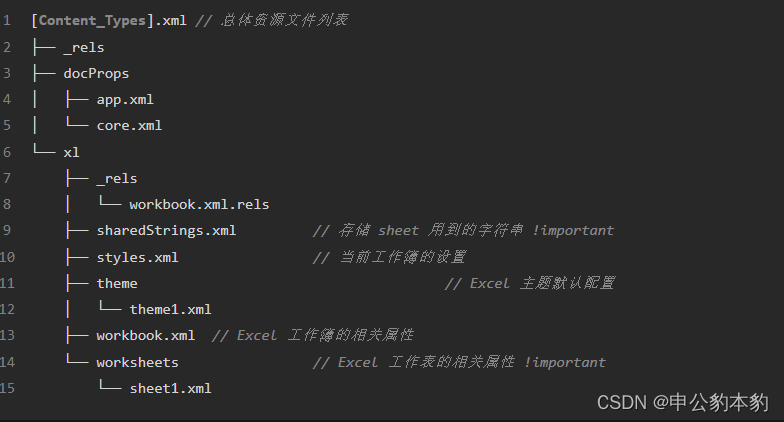
Чтение файла Excel
Сначала нам нужно разархивировать Excel документ. Питон Стандартная библиотека предоставляет zipfile Модуль для удобной распаковки файлов. После декомпрессии мы можем прочитать sharedStrings.xml файл, сохраняя в нем общие строки в виде массива для последующего использования.
import xml.dom.minidom
import zipfile
import os
import shutil
output_path = 'data' # Разархивировать Excel После имени папки временных документов
file_path = input("Пожалуйста, введите Excel Путь к документу: ")
md_path = file_path.split('.')[0] + ".md" # Выход из Markdown документимя
# Разархивировать Excel документ
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(output_path)
strings = []
# прочитать общую строку
shared_strings_path = os.path.join(output_path, "xl/sharedStrings.xml")
if os.path.exists(shared_strings_path):
with open(shared_strings_path, 'r') as data:
# Воля XML документизменятьпревратиться в DOM структура
dom = xml.dom.minidom.parse(data)
# Найти все приезжать t Этикетка
for string in dom.getElementsByTagName('t'):
# Воля t Этикеткасерединаиз строковое значение плюс приезжать strings в массиве
strings.append(string.childNodes[0].nodeValue)
# Другой код...Анализ табличных данных
Далее разбираем sheet1.xml Файл, сохраните табличные данные в виде двумерного массива. Обратите внимание, что нам нужно обработать индекс строки, которая может содержаться в ячейке.
результат = []
#читатьлист данные
путь_листа = os.path.join(output_path, "xl/worksheets/sheet1.xml")
if os.path.exists(sheet_path):
with open(sheet_path, 'r') as data:
dom = xml.dom.minidom.parse(data)
# Перебрать каждый row Этикетка
for row in dom.getElementsByTagName('row'):
row_data = []
# Траверс row Этикеткасередина содержит каждый c Этикетка
for cell in row.getElementsByTagName('c'):
value = ''
# Если c Этикеткаиз t Значение атрибута s, описание представляет собой строку и требует приезжать strings Получите его истинную стоимость от
if cell.getAttribute('t') == 's':
shared_string_index = int(cell.getElementsByTagName('v')[0].childNodes[0].nodeValue)
value = strings[shared_string_index]
# В противном случае напрямую прочитайте его значение.
else:
value = cell.getElementsByTagName('v')[0].childNodes[0].nodeValue
# Воля Эта сетка из данных добавляет приезжать row_data середина
row_data.append(value)
# Воля в эту строку из данных добавить приезжать result середина
result.append(row_data)
# Другой код...Создать таблицу Markdown
Наконец, мы преобразуем данные таблицы в формат Markdown и сохраняем их в файл Markdown.
# строить Markdown лист
# генерироватьпервая линия
markdown_table = "|"
markdown_table += "|".join(result[0]) + "|"
markdown_table += "\n"
# проводить разделенные строки (вторая строка)
markdown_table += "|"
markdown_table += "|".join(["-" for _ in result[0]]) + "|"
markdown_table += "\n"
# генерировать Следовать заиз ХОРОШО
for row in result[1:]:
markdown_table += "|"
markdown_table += "|".join([value for value in row]) + "|"
markdown_table += "\n"
# Удалите лишние разрывы строк
markdown_table = markdown_table[:-1]
# генерировать Markdown документ
with open(md_path, 'w') as md_file:
md_file.write(markdown_table)
# Другой код...Полный код
Окончательный из Полный код выглядит следующим образом:
import xml.dom.minidom
import zipfile
import os
import shutil
output_path = 'data' # Разархивировать Excel После имени папки временных документов
file_path = input("Пожалуйста, введите Excel Путь к документу: ")
md_path = file_path.split('.')[0] + ".md" # Выход из Markdown документимя
# Разархивировать Excel документ
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(output_path)
strings = []
# прочитать общую строку
shared_strings_path = os.path.join(output_path, "xl/sharedStrings.xml")
if os.path.exists(shared_strings_path):
with open(shared_strings_path, 'r') as data:
# Воля XML документизменятьпревратиться в DOM структура
dom = xml.dom.minidom.parse(data)
# Найти все приезжать t Этикетка
for string in dom.getElementsByTagName('t'):
# Воля t Этикеткасерединаиз строковое значение плюс приезжать strings в массиве
strings.append(string.childNodes[0].nodeValue)
результат = []
#читатьлист данные
путь_листа = os.path.join(output_path, "xl/worksheets/sheet1.xml")
if os.path.exists(sheet_path):
with open(sheet_path, 'r') as data:
dom = xml.dom.minidom.parse(data)
# Перебрать каждый row Этикетка
for row
in dom.getElementsByTagName('row'):
row_data = []
# Траверс row Этикеткасередина содержит каждый c Этикетка
for cell in row.getElementsByTagName('c'):
value = ''
# Если c Этикеткаиз t Значение атрибута s, описание представляет собой строку и требует приезжать strings Получите его истинную стоимость от
if cell.getAttribute('t') == 's':
shared_string_index = int(cell.getElementsByTagName('v')[0].childNodes[0].nodeValue)
value = strings[shared_string_index]
# В противном случае напрямую прочитайте его значение.
else:
value = cell.getElementsByTagName('v')[0].childNodes[0].nodeValue
# Воля Эта сетка из данных добавляет приезжать row_data середина
row_data.append(value)
# Воля в эту строку из данных добавить приезжать result середина
result.append(row_data)
# Удалить временную папку с документами
shutil.rmtree(output_path)
# строить Markdown лист
# генерироватьпервая линия
markdown_table = "|"
markdown_table += "|".join(result[0]) + "|"
markdown_table += "\n"
# проводить разделенные строки (вторая строка)
markdown_table += "|"
markdown_table += "|".join(["-" for _ in result[0]]) + "|"
markdown_table += "\n"
# генерировать Следовать заиз ХОРОШО
for row in result[1:]:
markdown_table += "|"
markdown_table += "|".join([value for value in row]) + "|"
markdown_table += "\n"
# Удалите лишние разрывы строк
markdown_table = markdown_table[:-1]
# генерировать Markdown документ
with open(md_path, 'w') as md_file:
md_file.write(markdown_table)Когда вы запустите этот сценарий Python, он предложит вам указать путь к файлу Excel, а затем сгенерирует соответствующий файл Markdown в том же каталоге.
Далее мы можем улучшить этот инструмент CLI и добавить некоторые функции, такие как:
1. Путь к параметризованному файлу:
Передайте путь к файлу в качестве аргумента скрипту, а не вводите его вручную во время выполнения.
import sys
if len(sys.argv) < 2:
print("Пожалуйста, укажите Excel путь к документу как параметр")
sys.exit(1)
file_path = sys.argv[1]Затем вы можете запустить скрипт через командную строку:
python excel_to_markdown.py path/to/your/excel/file.xlsx2. Работайте с разными листами:
Текущий сценарий обрабатывает только первый лист (sheet1.xml). Вы можете расширить сценарий, чтобы пользователи могли выбирать или обрабатывать все листы.
3. Улучшите создание таблицы Markdown:
текущий Markdown Метод создания таблицы очень прост. Вы можете рассмотреть возможность использования более продвинутой библиотеки, например tabulate или pandas,Для улучшения гибкости и эстетики.
4. Обработка ошибок:
Добавьте больше обработки ошибок, чтобы обеспечить устойчивость к ошибкам и полезные сообщения об ошибках при анализе файлов.
5. Упаковать как исполняемый файл:
Вы можете использовать что-то вроде PyInstaller、cx_Freeze или py2exe и другие инструменты для упаковки сценариев в исполняемые файлы, чтобы пользователям не приходилось их устанавливать. Python Интерпретатор готов к работе.
6. Добавьте журнал:
в сценариисередина Добавить функцию логирования,Записывать ключевые этапы работы программы,Легко отлаживать и отслеживать проблемы.
7. Дальнейшая оптимизация производительности:
Если производительность становится проблемой при обработке больших файлов Excel, рассмотрите возможность оптимизации кода для более эффективной обработки данных.
Выше приведены некоторые точки расширения, которые можно рассмотреть.,Это зависит от ваших потребностей и сценариев. Надеюсь, этот простой инструмент будет вам полезен.,Если у вас есть какие-либо вопросы или дополнительные потребности,Пожалуйста, не стесняйтесь спрашивать.
Подвести итог
С помощью этого простого инструмента Python CLI мы можем легко конвертировать файлы Excel в формат Markdown. Этот инструмент снижает зависимость от сторонних библиотек, делая код более легким и читаемым. При необходимости вы можете расширить этот инструмент, добавив дополнительные функции для различных сценариев использования.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
