Ле Кун начал драку, ЛЛМ вообще не умеет рассуждать! «Появление» больших моделей в конечном итоге неотделимо от контекстного обучения.

Новый отчет мудрости
Монтажер: Беги Лаян
【Шин Джиген Введение】некоторое время назад,LeCun переслал 2 длинные статьи,Основное внимание уделяется происхождению способностей LLM к планированию и неожиданным способностям. Автор считает,LLM сам по себе не обладает возможностями планирования и рассуждения.,И способность, которая появляется,Все коренные причины должны быть результатом контекстуального обучения.
Могут ли большие языковые модели рассуждать? Каковы источники различных появившихся способностей?
Некоторое время назад Ле Кун сделал репост нескольких статей в своем Твиттере, посвященных этому вопросу:
«Авторегрессионный LLM не может строить планы (и не может рассуждать)».
Во втором документе, представленном Ле Куном, обсуждались возможности LLM.

В исходном твите говорилось, что независимо от того, верят ли все в возможность появления LLM, эту статью стоит прочитать:
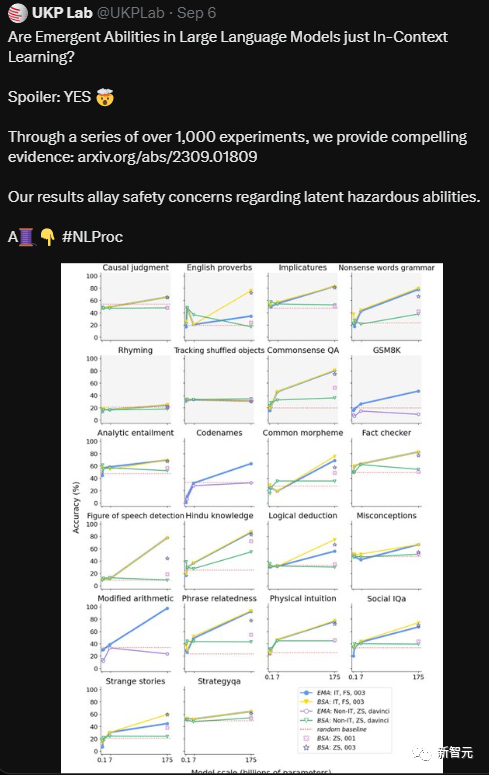
«После серии из более чем 1000 экспериментов мы доказали, что так называемые возникающие способности больших языковых моделей на самом деле являются всего лишь контекстным обучением».
Может ли LLM действительно рассуждать и планировать?
В статье Суббарао Камбхампата говорится, что утверждение в Интернете о том, что LLM может рассуждать и планировать, не очень обосновано, однако академическое сообщество также начало проводить серьезные исследования по этому вопросу.
По крайней мере, если судить по его предыдущим исследованиям GPT-3, идея о том, что большие языковые модели могут рассуждать и планировать, представляет собой большую проблему.

https://arxiv.org/pdf/2206.10498.pdf
Мы предлагаем масштабируемую систему оценки для проверки способности LLM рассуждать о действиях и изменениях, что является ключевым аспектом человеческого интеллекта. Мы предоставляем несколько тестовых примеров, которые более сложны, чем любой ранее установленный тест, и каждый из них оценивает различные аспекты рассуждений о действиях и изменениях. Результаты для GPT-3 (davinci), Instruct-GPT-3 (text-davinci-002) и BLOOM (176B) показывают плохую производительность при выполнении таких задач на рассуждение.
Что касается недавно запущенного GPT-4, команда профессора также расширила предыдущие исследования, пытаясь выяснить, добилась ли новая самая совершенная модель большого языка нового прогресса в возможностях рассуждения и планирования.

https://arxiv.org/pdf/2206.10498.pdf
Мы проводим систематическое исследование, создавая набор примеров аналогично тому, как это используется в международных соревнованиях по планированию, и оцениваем LLM в двух разных режимах: автономном режиме и эвристическом режиме. Наши результаты показывают, что LL.M. весьма ограничены в своих возможностях самостоятельно генерировать исполняемые планы, при этом GPT-4 достигает среднего показателя успеха ~12% по всем доменам. Однако результаты эвристической модели кажутся более многообещающими. В эвристическом режиме мы демонстрируем, что планы, сгенерированные LLM, могут улучшить процесс поиска базового рационального планировщика, а также показываем, что внешний верификатор может помочь обеспечить обратную связь по сгенерированным планам и дать LLM обратную подсказку для создания более эффективных планов.
В статье используется интересная картинка, чтобы объяснить читателям, что, по-видимому, основная причина способности к рассуждению, проявляемой LLM, заключается в том, что задача относительно проста, и человек, задающий вопрос, уже знает ответ на вопрос.
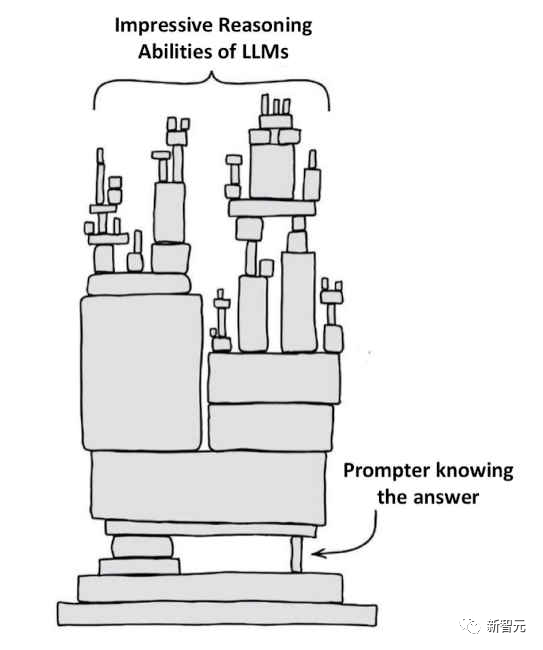
Для задач планирования и рассуждения на уровне соревнований, таких как задача «Мир блоков» на Международном конкурсе планирования (IPC), производительность LLM не является удовлетворительной.
Предварительные результаты показывают, что при переходе от GPT-3 к GPT3.5, а затем к GPT-4 точность создаваемых планов этажей в определенной степени улучшилась. GPT-4 достигает эмпирической точности 30% в Blocks World (хотя и в других). поля еще ниже).
Исследовательская группа профессора считает, что способность LLM к выполнению многих задач планирования может быть обусловлена только тем, что он прошел обучение в особенно широком диапазоне и, таким образом, «помнит» содержание планирования.
Таким образом, исследовательская группа снизила эффективность приблизительного поиска, путая названия действий и объектов в задаче планирования, не позволяя большим языковым моделям извлечь «содержание планирования», которое они запомнили.
Перед лицом таких проблем эмпирические характеристики GPT-4 резко падают.
Что касается ограничения, связанного с тем, что LLM не может напрямую и автономно планировать, исследовательская группа улучшила его двумя способами:
Первым шагом была точная настройка модели. Однако после того, как команда профессора доработала модель, они так и не обнаружили, что способность модели к планированию улучшилась.
Также считается, что даже если возможности планирования модели улучшаются за счет точной настройки модели, она все равно преобразует задачу планирования в поиск на основе памяти и не может доказать, что большая языковая модель может выполнять автономное планирование.
Второй способ улучшить возможности планирования модели — постоянно предлагать LLM улучшить свой первоначальный план.
Однако для этого метода, особенно для подсказок, которые постоянно позволяют модели самостоятельно генерировать мнения об улучшении, по сути, модели разрешено генерировать предположения, или подсказчик решает, какие предположения могут лучше улучшить план. Это не означает, что модель сама по себе. улучшает способность планирования.
В чем проблема с докладами на главной конференции, которые утверждают, что демонстрируют возможности планирования LLM?
Скептически настроенные читатели теперь могут спросить, а как насчет тех статей на громких конференциях по искусственному интеллекту, которые утверждают, что демонстрируют возможности планирования LLM?
Для анализа этих претензий прежде всего необходимо понять, что решение задач планирования требует:
1. Обладать необходимыми знаниями в области планирования.
2. Уметь объединить эти знания планирования в исполняемый план, отвечающий за выполнение подцелей или взаимодействие с ресурсами.
Первый элемент можно назвать приобретением знаний, а второй элемент можно назвать рассуждением/планированием.
Многие статьи, утверждающие, что LLM обладает возможностями планирования, при ближайшем рассмотрении путают общие знания по планированию с выполнимыми планами, извлеченными из LLM.
Если исследователи ищут абстрактные планы, такие как «свадебные планы», без намерения фактического выполнения этих планов, их легко можно спутать с полными выполнимыми планами, что делает невозможным точную оценку возможностей планирования LLM.
После тщательного изучения нескольких статей, утверждающих, что LLM обладает возможностями планирования, команда профессоров обнаружила, что LLM либо выполняет работу по планированию в областях/задачах, где взаимодействия подцелей можно безопасно игнорировать (планирование бессмысленных задач или неважных задач), либо доверяет рассуждения проблему для людей в циклическом процессе (посредством повторяющихся подсказок и планов «коррекции»).
Без этих предположений или буферов план, полученный на основе LLM, может показаться разумным непрофессионалам, но приведет к множеству проблем во время выполнения.
Например, существует большое количество книг с планами путешествий. Содержание этих книг в основном автоматически генерируется LLM. Однако читатели, покупающие эти книги, ошибочно принимают их за исполняемые планы, что в конечном итоге приводит к очень неутешительным для читателей результатам.
LLM не обладает способностями к планированию и рассуждению.
В целом, профессор считает, что ничто из того, что он прочитал, проверил или сделал, не дает ему убедительных оснований полагать, что LLM рассуждает/планирует в общепринятом понимании.
Содержание исследований, в которых предполагается, что LLM обладает способностями к рассуждению/планированию, на самом деле эквивалентно поиску в ходе крупномасштабного обучения, и иногда его ошибочно принимают за способности к рассуждению.
LLM действительно хорош в генерировании идей для любых задач, в том числе связанных с рассуждениями, и это можно эффективно использовать для поддержки рассуждений/планирования. Другими словами, LLM уже обладает достаточно удивительными возможностями приблизительного поиска, и мы можем в полной мере использовать эту возможность, не приписывая LLM возможности ложного рассуждения/планирования.
Если вас интересует этот вопрос, вы также можете обратиться к лекции профессора.
Еще одна статья о новых возможностях больших языковых моделей направлена на способность контекстного обучения.
Новые возможности? Не существует!

https://arxiv.org/pdf/2309.01809.pdf
Проще говоря, исследователи обнаружили, что LLM плохо работает при выполнении задач, которые не обучены явно и требуют сложных способностей к рассуждению.
Эта способность оказывает значительное влияние на будущие направления исследований НЛП. Поскольку LLM продолжают расти, сценарии их применения в обозримом будущем будут становиться все более распространенными.
Но проблема в том, что когда исследователи оценивают возможности LLM, им мешают некоторые факторы, что приводит к путанице.
Например, некоторые возможности могут быть реализованы с помощью оперативных технологий. Примерами могут служить контекстное обучение и следование инструкциям.
Эти ситуации также будут увеличиваться по мере дальнейшего увеличения размера модели.
Поэтому исследовательская группа, работающая над этой статьей, всесторонне изучила эти возможности, принимая во внимание некоторые потенциальные факторы смещения, которые могут повлиять на оценку модели.
Исследователи тщательно протестировали набор из 18 моделей с параметрами LLM от 60 до 175 миллиардов на 22 задачах.
После более чем 1000 экспериментов исследователи предоставили достаточно доказательств, чтобы доказать, что так называемые возникающие способности в основном возникают в результате контекстуального обучения.
Исследователи также заявили, что не нашли никаких доказательств того, что LLM обладает способностями к рассуждению.
Экспериментальные методы
В частности, исследователи последовательно изучали следующие вопросы:
· Чтобы устранить возможные последствия контекстного обучения и точной настройки инструкций, исследователи выбрали условие нулевой выборки и использовали модель тонкой настройки без инструкций.
· Изучите взаимодействие между возможностями контекстного обучения и точной настройкой инструкций и поймите, следует ли использовать возможности рассуждения для объяснения некоторых дополнительных возможностей модели тонкой настройки инструкций. Для этого исследователи сравнили возможности моделей без тонкой настройки инструкций и моделей разных размеров, которые в разной степени были доработаны инструкциями.
· Вручную проверьте способность LLM к функциональному языку, способность к формальному языку и способность запомнить задачу.
Чтобы оценить истинные масштабы способностей LLM, исследователи тщательно разработали экспериментальную структуру, чтобы свести к минимуму вводящие в заблуждение факторы.
Кроме того, экспериментальный дизайн команды был сосредоточен на том, чтобы не активировать возможности контекстного обучения модели. Например, точная настройка инструкций преобразует инструкции по обучению модели в образцы, что может привести к контекстному обучению.
Поэтому экспериментальная группа использовала модель тонкой настройки, не требующую обучения, чтобы избежать такой возможности.
На рисунке ниже представлена модель, выбранная исследователями.
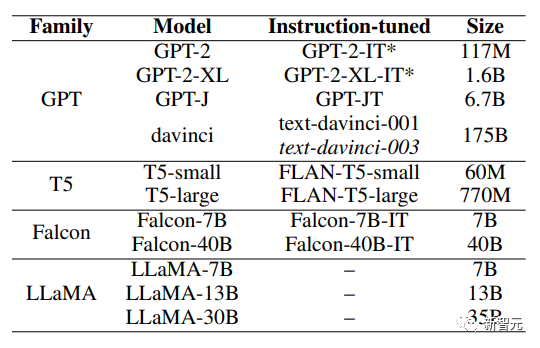
Исследователи оценили ряд моделей разных размеров из четырех семейств моделей, включая GPT, T5, Falcon и LLaMA.
Эти модели были выбраны потому, что ранее было обнаружено, что GPT и LLaMA обладают новыми возможностями, а Falcon находится на вершине рейтинга LLM.
Исследователи также выбрали T5, потому что это модель кодера-декодера, а ее версия с точной настройкой инструкций (Flan) была обучена с использованием большого набора данных для точной настройки инструкций.
В серии GPT исследователи использовали версии GPT-2 и GPT-3 с точной настройкой инструкций и без инструкций, в серии T5 исследователи использовали T5 и его аналог с точной настройкой инструкций FLAN-T5;
Аналогично, исследователи использовали версии Falcon3 с настраиваемыми и ненастраиваемыми инструкциями. Что касается LLaMA, поскольку она не была точно настроена на инструкции, исследователи не смогли получить версию модели с точной настройкой инструкций.
Кроме того, исследователи оценили GPT-3 text-davinci-003, модель InstructGPT. Модель InstructGPT изначально подвергается точной настройке на основе подсказок, написанных аннотаторами, и соответствующего ожидаемого поведения. Затем модель используется для сбора ранжированных наборов данных, выводимых другими моделями, а затем настраивается с использованием обучения с подкреплением и обратной связью от человека (RLHF).
Доказано, что этот метод обучения улучшает производительность модели.
Среди них модель Т5, выбранная исследователями намеренно, имеет номер параметра ниже 1B, поскольку способность к эмерджентности не наблюдалась в такой маленькой модели, которая играла ключевую контрольную роль в экспериментах исследователей.
Среди моделей, выбранных исследователями, GPT-3 davinci (тонкая настройка без обучения), GPT-3 textdavinci-001 (тонкая настройка с обучением) и GPT-3 textdavinci-003 (InstructGPT) — все модели, в которых возникающие возможности наблюдались ранее. Этот выбор был в первую очередь основан на соображениях доступности модели.
Другие семейства моделей, продемонстрировавшие новые возможности, включают PaLM, Chinchilla, Gopher и LaMDA, но исследователи не оценивали их, поскольку не существует соответствующих интерфейсов прикладного программирования.
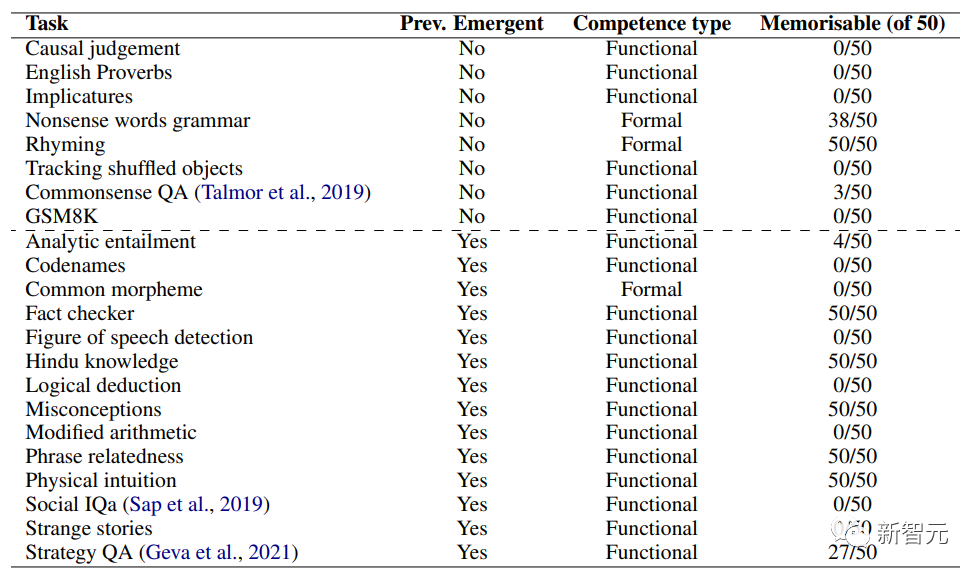
На фото выше представлен список задач, использованных в эксперименте, информация о том, были ли задачи ранее идентифицированы как эмерджентные, а также классификация характера способностей, необходимых для решения задач.
Эта классификация была определена путем ручной проверки данных и использования структуры классификации, предоставленной Mahowald et al. Исследователи оценили память для 50 примеров в каждой задаче, предполагая, что данные задачи не были утеряны.

В таблице выше подробно описана общая экспериментальная установка, включая различные протестированные модели, различные задачи, используемые в экспериментах, и принятые настройки оценки.
Учитывая, что целью команды было оценить новые возможности LLM независимо от других факторов, исследователи оценили каждую из 12 моделей, выбранных из серий T5 и GPT, по всем 22 выбранным задачам.
Для каждой ситуации исследователи использовали одну и ту же стратегию оперативного реагирования: закрытое и закрытое противостояние. Чтобы учесть вариативность ответов, исследователи проводили каждый эксперимент трижды и усредняли результаты. Все эксперименты проводились на графическом процессоре NVIDIA A100 с температурой 0,01 и размером пакета 16.
Для модели параметров GPT-3 175B (davinci, text-davinci-001 и text-davinci003) команда использует официальный API для оценки только один раз, а температура равна 0. Это связано с тем, что исследователи в этой статье также установили температуру на 0, гарантируя повторяемость результатов и сводя к минимуму возможность галлюцинаций.
Кроме того, они выбрали шесть моделей из серий LLaMA и Falcon и оценили их по 4 из 22 выбранных ранее задач.
Выбирая эти четыре задачи, исследователи гарантировали, что две задачи ранее были идентифицированы как неотложные, а две другие задачи были определены как несрочные. Затем команда снова протестировала их, используя закрытые и состязательные стратегии, проводя каждый эксперимент трижды, чтобы учесть возможные различия.
Учитывая, что некоторые задачи оценки имеют разное количество релевантных вариантов, исследователи построили базовый уровень для каждой задачи, случайным образом выбирая варианты вопросов в этой задаче несколько раз и усредняя баллы.
Результаты экспериментов
Что касается первого вопроса исследования: учитывая, что контекстное обучение оказывает определенное потенциальное влияние на возникающие способности в LLM, в отсутствие контекстного обучения (включая тонкую настройку инструкций), какие способности являются действительно возникающими способностями?
Исследовательская группа впервые продемонстрировала производительность модели GPT-3 с параметрами 175B без точной настройки инструкций в условиях нулевой выборки.
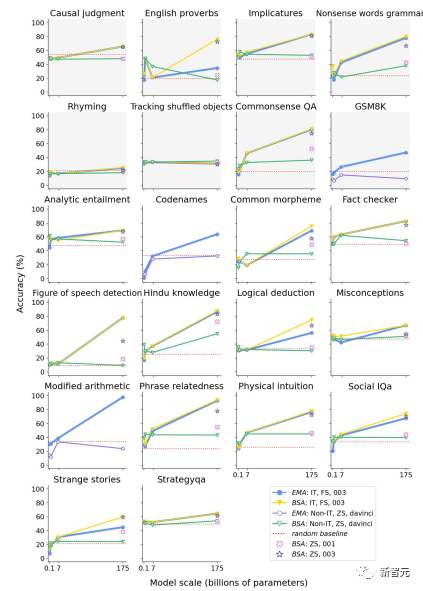
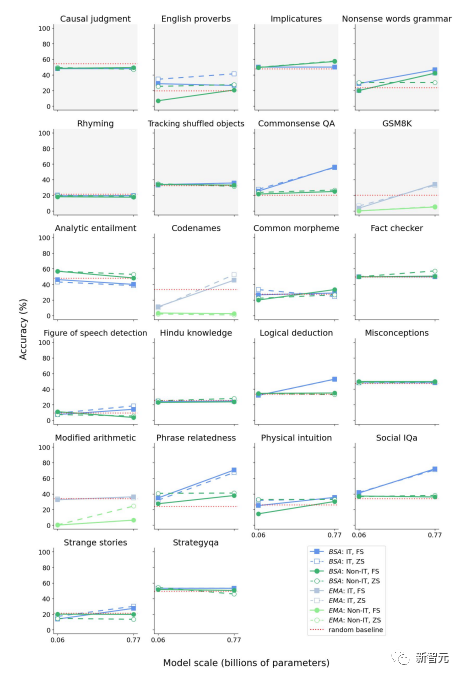
На рисунке выше показана производительность моделей серии GPT при выполнении различных задач в рамках стратегии закрытых подсказок.
Исследовательская группа использовала точность BERTScore (BSA) и точность соответствия (EMA) для сравнения модели корректировки инструкций (IT) и модели корректировки без инструкций (non-IT) при малой выборке (FS) и нулевой выборке (ZS). ) была произведена оценка.
Синий цвет представляет результаты модели точной настройки инструкций в условиях небольшого количества выборок, что сопоставимо с результатами, описанными в предыдущей литературе.
Желтый цвет представляет производительность, измеренную с использованием BSA при тех же настройках, а красный представляет результаты BSA в условиях нулевой выборки модели с точной настройкой без инструкций. Другими словами, это условие представляет результаты без влияния контекстного обучения.
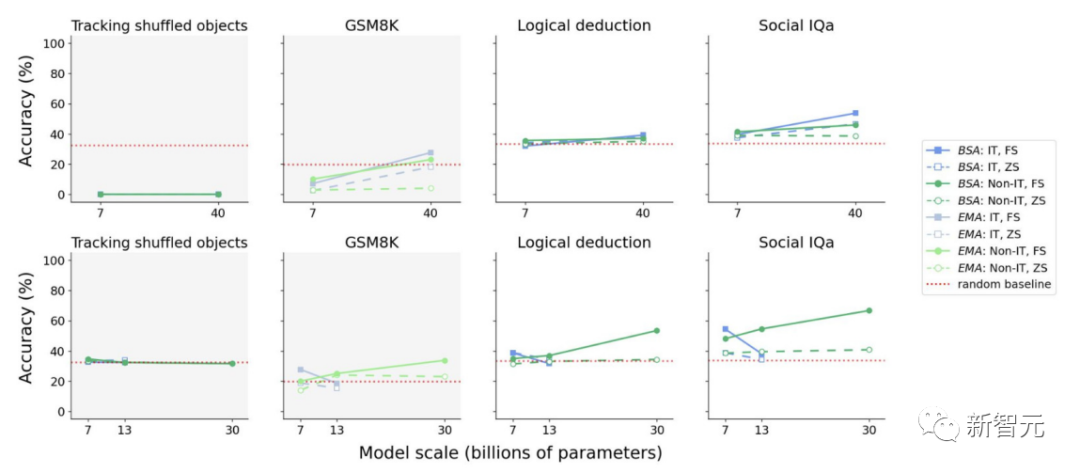
На рисунке выше представлена схематическая диаграмма производительности моделей Falcon (верхняя часть) и LLaMA (нижняя часть) на выбранном подмножестве задач в условиях нулевой выборки без настройки инструкций, что указывает на то, что в отсутствие контекстного обучения модель всегда не хватает так называемых эмерджентных способностей.
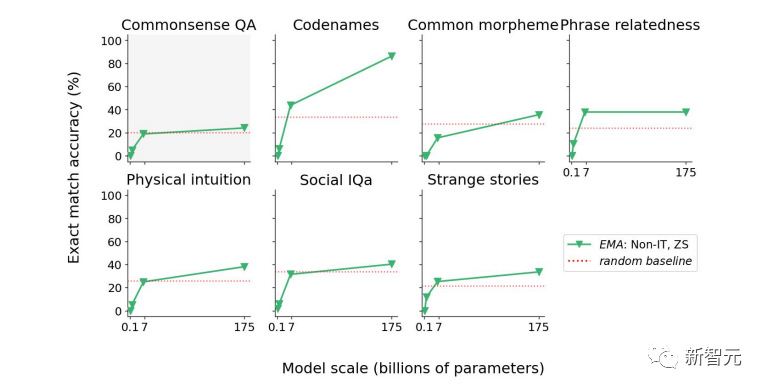
На рисунке выше показана производительность модели GPT с точной настройкой без инструкций в состязательной среде. В этих подмножествах задач производительность GPT выше, чем случайный базовый уровень. Результаты выполнения некоторых задач предсказуемы и поэтому не считаются возникающими способностями.
В остальных задачах улучшение производительности было относительно небольшим по сравнению со случайным базовым уровнем.
Что касается второго вопроса: демонстрируют ли модели, которые были точно настроены с помощью инструкций, способности к рассуждению, или точная настройка инструкций с большей вероятностью сделает эти модели более эффективными и действенными в контекстном обучении?
Следует отметить, что суть тонкой настройки инструкций заключается в установлении взаимосвязи между инструкциями и образцами, что является характеристикой контекстного обучения, поэтому этот процесс, вероятно, действительно инициирует контекстное обучение.
Гипотеза исследователей означает, что точная настройка инструкций дает LLM возможность переводить инструкции в образцы, которые затем мобилизуют их возможности контекстного обучения.
На рисунке ниже показана производительность моделей серии T5 в различных условиях.
Ссылки:
https://arxiv.org/abs/2309.01809



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
