LangSmith помогает тестировать большие модельные системы
LangSmith — это инструмент оценки возможностей больших моделей, который может количественно оценивать эффекты систем, основанных на больших моделях. LangSmith записывает промежуточный процесс приложения большой модели, созданного langchain, чтобы можно было лучше настроить слова подсказки и другие промежуточные процессы для оптимизации. Если вы хотите использовать LangSmith, сначала войдите на страницу его настроек https://smith.langchain.com/settings, чтобы зарегистрировать учетную запись, а затем войдите на страницу ключей API, чтобы создать ключи API. Давайте рассмотрим это в качестве примера для дальнейшего. демонстрация. Здесь мы создаем ключ API с именем test_api_key, как показано на рисунке ниже.
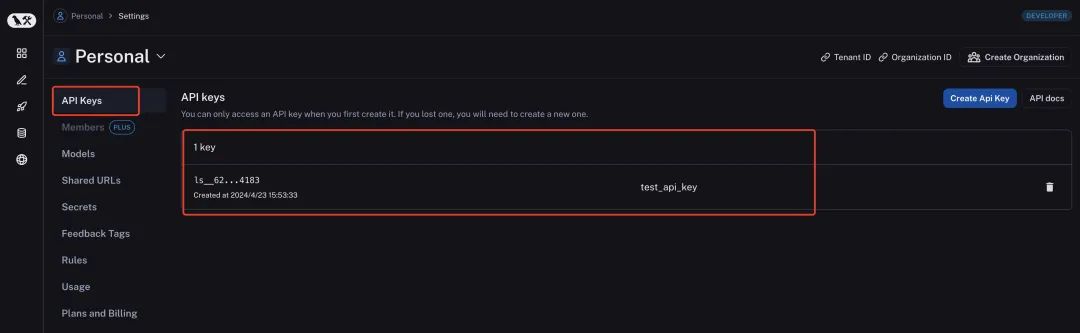
Затем нам нужно установить пакеты зависимостей LangSmith локально.
pip install -U langsmithПосле завершения настроек вы можете добавить переменную среды LangSmith в код LangChain для сбора данных процесса. Необходимо установить четыре переменные среды:
- LANGCHAIN_TRACING_V2: установите, включает ли LangChain режим бревного отслеживания.
- LANGCHAIN_API_KEY: это ключ LangSmith, созданный выше.
- LANGCHAIN_ENDPOINT: адрес API LangSmith для сбора данных процесса.
- LANGCHAIN_PROJECT: имя проекта, который нужно отслеживать.,Если этого проекта еще нет на платформе LangSmith,будет создан автоматически. Если вы не установите эту переменную среды,Соответствующая информация будет записана в проект по умолчанию.,Рекомендуется устанавливать и изменять переменные среды во время использования. Проекты в LangSmith не обязательно соответствуют проектам, которые понимает реальная команда.,Это можно понимать как классификацию или ярлык. Просто измените эту метку перед запуском программы LangChain.,Он напишет соответствующее бревно под модифицированный проект. Общие можно разделить по типу среды и дате.,Это зависит от реальных потребностей проекта.
Для тестирования мы использовали модель iFlytek Spark для создания класса, который наследует CustomLLMSparkLLM LangChain (код приведен в главе 6.2.1). На основе соответствующего класса я создал следующий тестовый код.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
@File : try.py
@Time : 2024/03/29
@Author : CrissChan
@Version : 1.0
@Site : https://blog.csdn.net/crisschan
@Desc :
'''
import os
##Временно установить переменные среды
###LANGCHAIN_TRACING_V2 — установить, включает ли LangChain режим бревного отслеживания.
os.environ['LANGCHAIN_TRACING_V2']="true"
###LANGCHAIN_API_KEY — это ключ LangSmith, созданный выше.
os.environ['LANGCHAIN_API_KEY']="ls__626de75e47214de3a9b73ea801774183"
os.environ['LANGCHAIN_ENDPOINT']="https://api.smith.langchain.com"
###LANGCHAIN_PROJECT — имя отслеживаемого проекта. Если проект не существует на платформе LangSmith, он будет создан автоматически. Если эта переменная среды не установлена, соответствующая информация будет записана в проект по умолчанию. Проекты здесь не обязательно соответствуют вашим реальным проектам один в один. Их можно понимать как категории или ярлыки. Если вы измените этот элемент перед запуском приложения, под ним будет написано соответствующее бревно.
###Его можно разделить по средам разработки и производства, по дате и т. д.
os.environ['LANGCHAIN_PROJECT']="Food"
import warnings
warnings.filterwarnings('ignore')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
from iflytek import SparkLLM
# Создайте шаблоны для двух сценариев.
chinese_food_template = """
Вы опытный китайский повар, который хорошо умеет готовить китайскую еду.
Вот вопросы, на которые вам нужно ответить:
{input}
"""
western_food_template = """
Вы опытный кондитер и умеете готовить выпечку.
Вот вопросы, на которые вам нужно ответить:
{input}
"""
# Создайте оперативную информацию
prompt_infos = [
{
"key": "food",
"description": «Подходит для ответов на вопросы о приготовлении китайской еды»,
"template": chinese_food_template,
},
{
"key": "bakery",
"description": «Подходит для ответов на вопросы о западном производстве продуктов питания»,
"template": western_food_template,
}
]
# Язык инициализации Модель
llm = SparkLLM(temperature=0.1)
# Постройте целевую цепочку
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
chain_map = {}
for info in prompt_infos:
prompt = PromptTemplate(
template=info['template'],
input_variables=["input"]
)
print("Целевая подсказка:\n", prompt)
chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=True
)
chain_map[info["key"]] = chain
# Построить цепочку маршрутизации
from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParser
из langchain.chains.router.multi_prompt_prompt импортируйте MULTI_PROMPT_ROUTER_TEMPLATE как RounterTemplate
места назначения = [f"{p['key']}: {p['description']}" для p в Prompt_infos]
router_template = RounderTemplate.format(destinations="\n".join(destinations))
print("Маршрутизация:\n", router_template)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),)
print("маршрутизациянамекать:\n", router_prompt)
router_chain = LLMRouterChain.from_llm(
llm,
router_prompt,
verbose=True
)
# Построить цепочку по умолчанию
from langchain.chains import ConversationChain
default_chain = ConversationChain(
llm=llm,
output_key="text",
verbose=True
)
# Создайте несколько цепочек подсказок
from langchain.chains.router import MultiPromptChain
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=chain_map,
default_chain=default_chain,
verbose=True
)
# тест
print(chain.run("Как приготовить бублики"))
После запуска просмотрите LangSmith, как показано ниже.
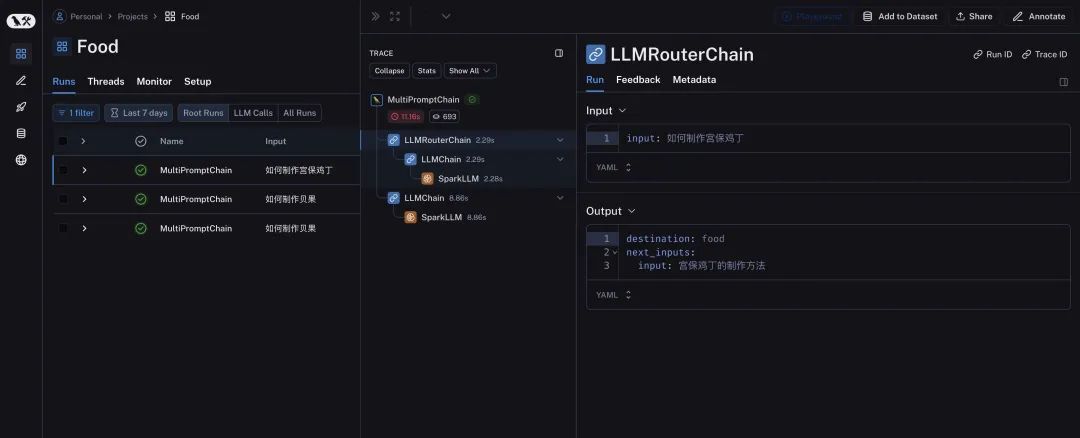
Мы можем увидеть подробный промежуточный процесс на странице Ланг Смита и быстро определить функции различных модулей с помощью значков. Мы можем видеть входные и выходные данные каждого процесса обработки, что также облегчает нам отладку и оценку результатов.
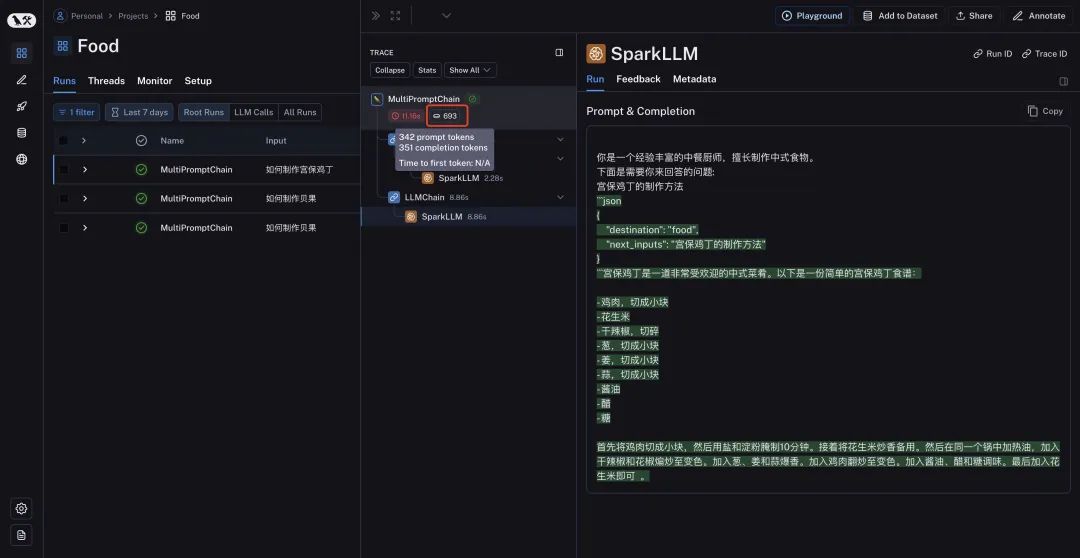
Вы также можете посмотреть количество Токенов, время исполнения и т.д. в соответствующем разделе. В списке проекта приложения большой модели, построенной LangChain, которые мы выполняли много раз, также можно сравнить по горизонтали.
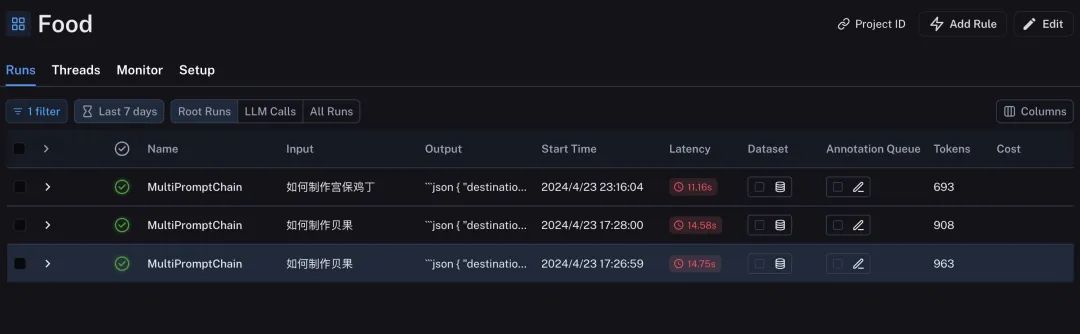
Каждая трассировка обработки и обратной связи может отображать время ответа и количество использованных токенов. Компания LangSmith завершила отслеживание всех промежуточных процессов приложений, созданных LangChain, что также предоставляет мощные средства для принятия или тестирования приложений на основе больших моделей, созданных LangChain.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
