Краткое обсуждение принципа диффузионной модели модели генерации изображений.
Можете ли вы сначала Нажмите ссылку ниже,Попросите лайков Нажмите like ❥(^_-) Дай мне попробовать Model и Пространство, посмотрите на следующий текст~~: Model 、 Space
………………………………………………………………
в последние годы,изображение Технологии генерации быстро развиваются,Все больше и больше людей начинают обращать внимание наи Изучите различные изображения Создать модель。и Diffusion Model Являясь одним из них, он имеет большое значение для создания высококачественных изображений. В этом обмене мы обсудим Diffusion Model изпринципи реализации. Я надеюсь, что этот обмен информацией поможет каждому глубже понять технологии и методы в этой области и вдохновит вас на дальнейшие исследования.
1. Что такое диффузионная модель и как она генерирует изображения?
Представляем Diffusion Model Прежде, давайте сначала поймем Создать модель. С точки зрения непрофессионала, Создать модель — это алгоритм искусственного интеллекта.,Основная идея заключается в том,Пусть компьютер автоматически выучит некоторые данные по статистическим законам,И использовать эти законы для создания новых изданных,Например, изображение, аудио и т. д. Эта технология широко используется,Например, его можно использовать при создании текста, изображений, видео и других областях. и Diffusion Model Это относительно новый вид изображения Создать. модель, ее самая большая характеристика есть可以генерировать高质量изизображение。этоизгенерироватьпринципочень интересно,на самом деле,Diffusion Model Это генерация изображений, основанная на технологии шумоподавления. Denoise Model。это означает,В процессе создания изображенияизсередина,этона самом компания постоянно устраняет шум, случайность и влияние,Из и мы постепенно получаем все более реальное, все более изысканное изображение.
1.1 Принцип диффузионной модели
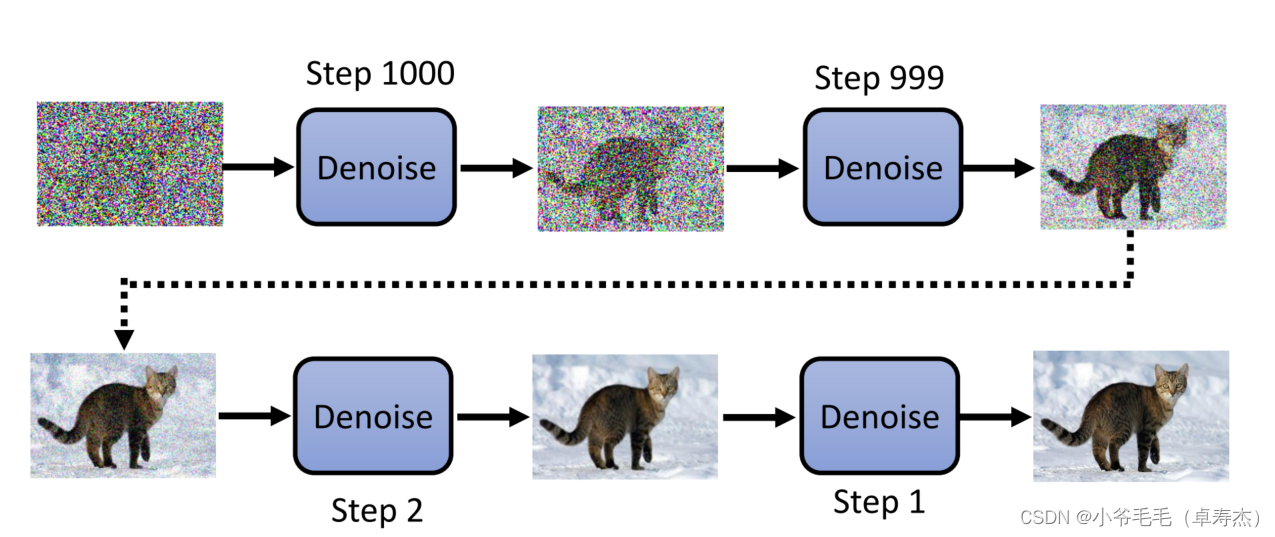
- Во-первых, Денойз Model В качестве входных данных требуется начальное изображение шума.。этот шумизображение Может быть совершенно случайнымиз,Это также может быть какой-то конкретныйизмодель(нравиться Гауссово распределение)или форма。
- Далее, с denoise По мере продолжения процесса подробности будут постепенно появляться. Этот процесс немного похож на проявку фотографии. Каждый раз, когда вы ее проявляете, постепенно проявляются детали и цвета фотографии. шумоподавление Чем больше раз используется из, тем четче и тоньше получается изображение.
- Наконец, Денойз Model Конечный результат будет основан на потребностях пользователя.

Denoise процесссередина,использоватьиз ВсеТа же модель шумоподавления。чтобы позволить Diffusion Model Знайте, где вы сейчас находитесь Step Входное изображение будет изменено во время фактической операции. Step Числа передаются в качестве входных данных в модель.。так,Модель может судить об уровне шума на основе тока из Step,Выполните более детальные операции по шумоподавлению из è.
1.2 Внутри модели шумоподавления
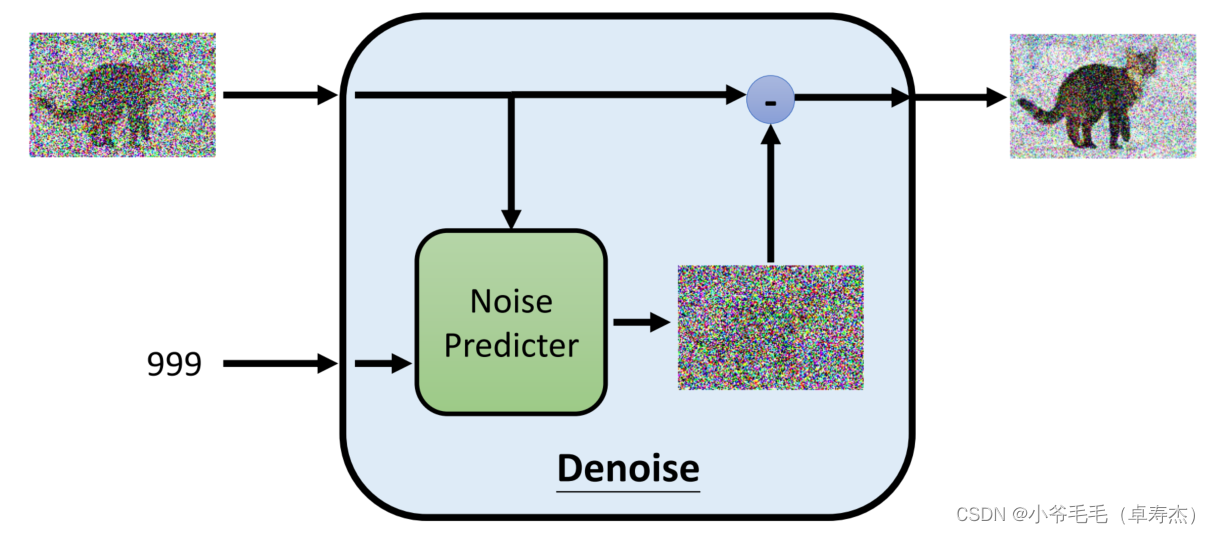
Фактически, Denoise Model делает несколько очень интересных вещей внутри себя для создания высококачественных изображений. Прежде всего, поскольку модели сложно напрямую предсказывать изображения с шумоподавлением, модель Denoise делает две вещи:
- первый,Он преобразует шумовую картину в текущий шаг, введенный вместе в файл с именем Noise Predicter из модуля середина.,Этот модуль будет прогнозировать текущий шум изображения.
- Следующий,Модель исправит предварительное изображение с шумоподавлением.,для достижения эффекта шумоподавления. Конкретно,Модель дополнительно удалит шум, вычитая шум из значений пикселей.
1.3 Как обучить Noise Predictor?
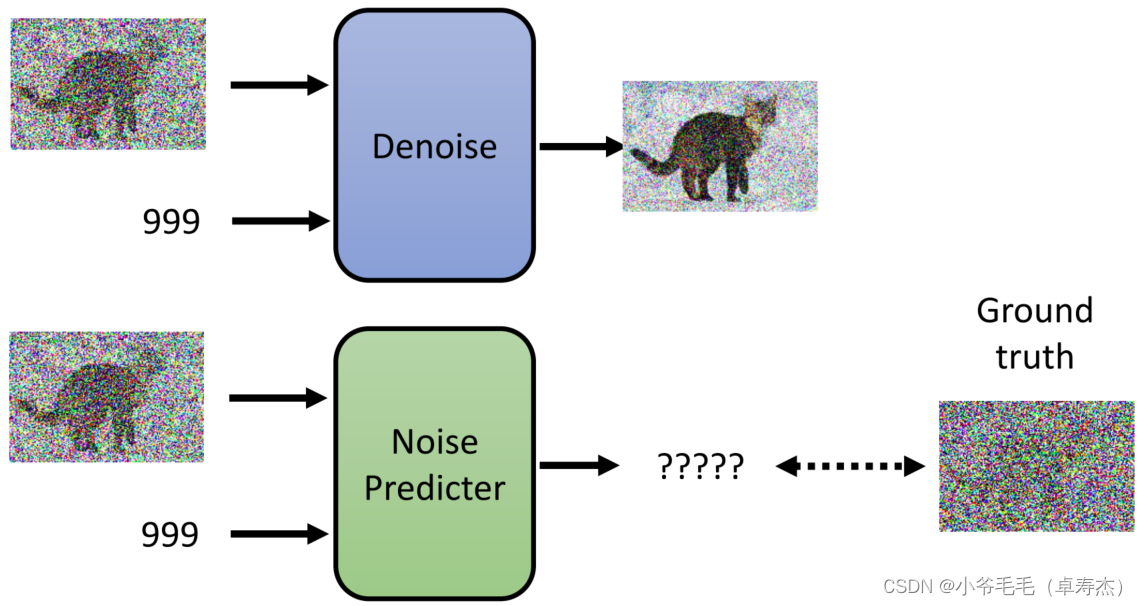
нужно тренироваться Noise Predictor,наснужно иметь основной истинный шум как ярлык для контролируемого обучения。Так,каждый Step из Ground truth Откуда это взялось?
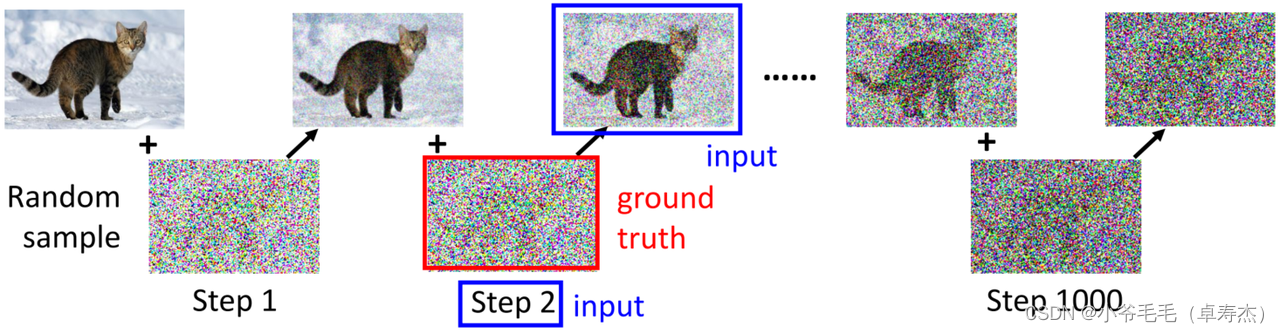
нас可以проходитьСлучайно генерировать шум для моделирования процесса диффузии (Diffusion Process)。Конкретно,Начинаем с исходного изображения,Постоянное добавление случайного шума,Получите серию добавленного шума после изображения. После добавления шума изображение в настоящее время отсутствует. Step то есть Denoise Model из ввода и добавление шума Ground truth。нас可以использовать这些 Ground truth данные для обучения Noise Предиктор, чтобы он мог лучше предсказать текущий шум.
1.4 Text-to-Image
Некоторые студенты спросили: Я видел из Diffusion Модель представляет собой преобразование текста в изображение. Генератор, генерирует изображения на основе текста. Почему у вас нет ввода текста?

Действительно, некоторые Diffusion Model Он генерирует изображения на основе текста, а это означает, что мы можем генерировать изображения, используя текст в качестве входных данных.
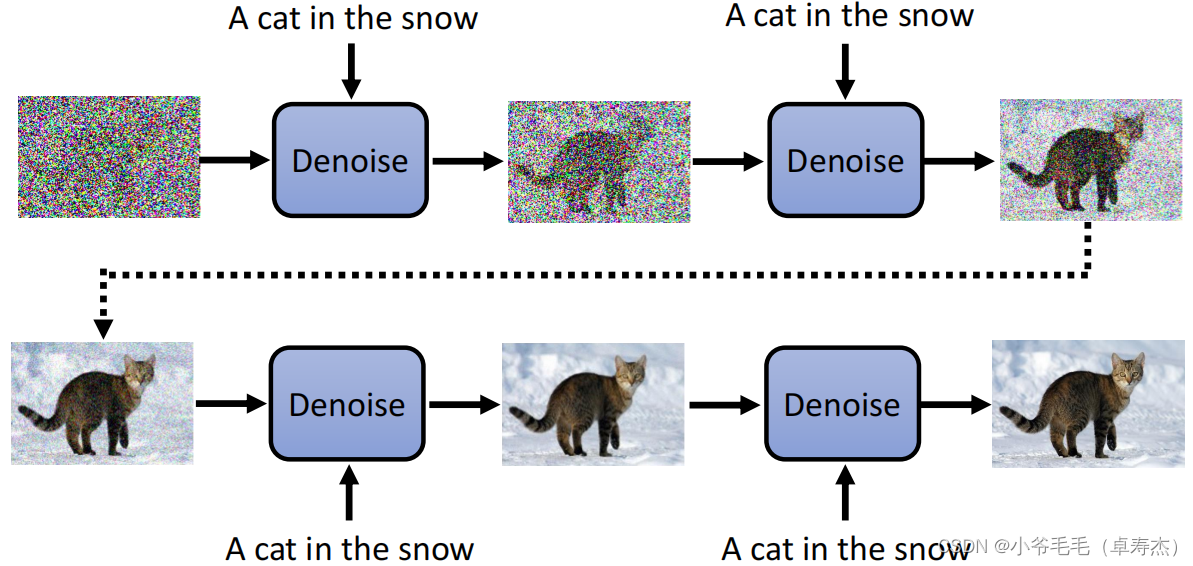
каждый шаг, текст можно использовать как Denoise Model из Вход,Это позволяет Модели знать, какое изображение должно быть сгенерировано в данный момент.
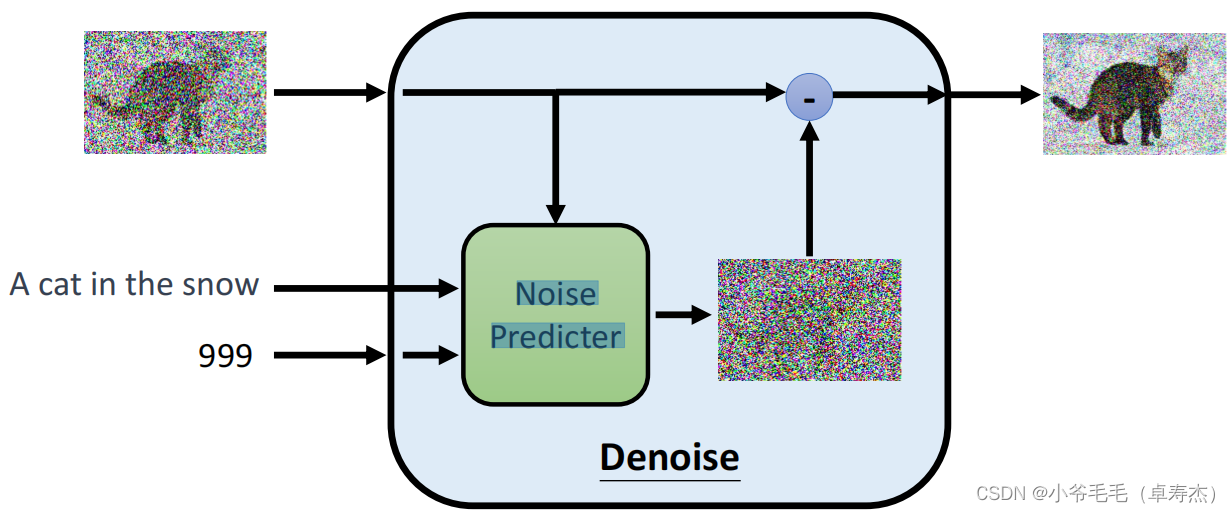
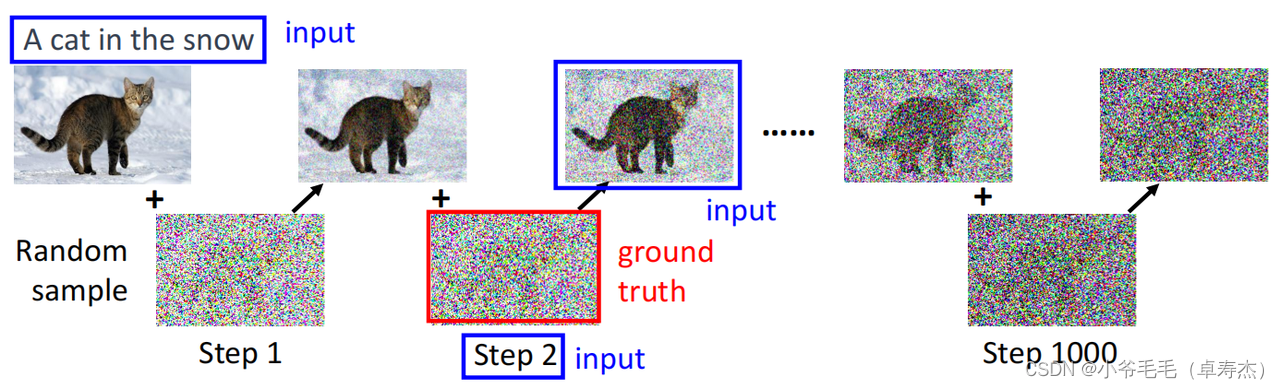
Конкретно,нас可以将Ввод текста в Noise Predictor,Для того, чтобы предугадать шум и убрать его.
2. Какова общая формула стабильной диффузии, DALL-E и Imagen?
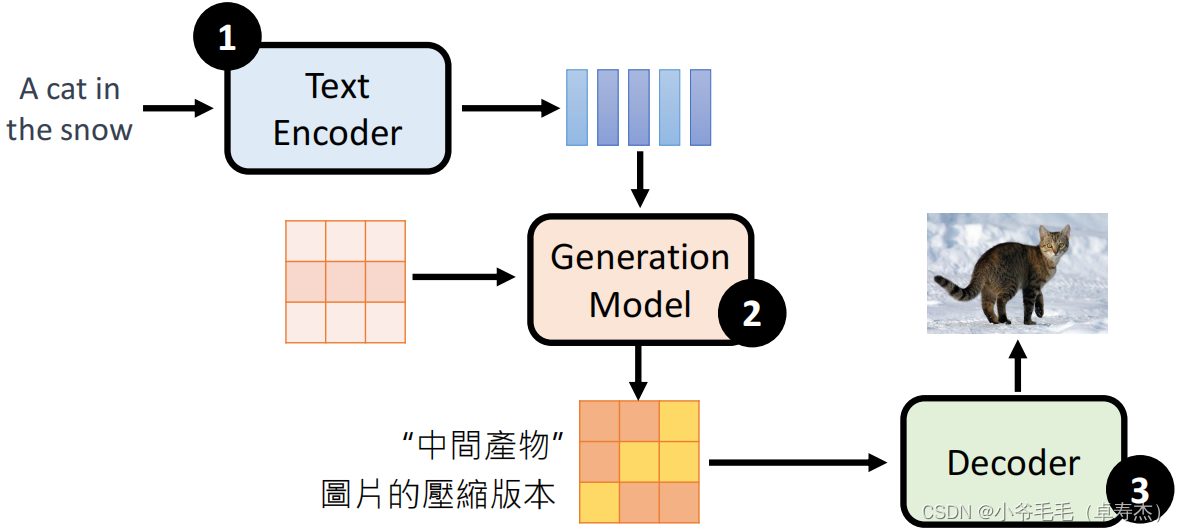
Stable Diffusion, DALL-E, Imagen, эти Модели объединяет то, что все они используют три модуля для создания изображения:
- первый,использовать модуль Text Encoder, кодирует вводимый текст в вектор представления。
- Затем, Модуль «Модель генерации» будет использовать этот вектор представления для создания вектора представления изображения, который можно рассматривать как сжатую версию изображения.。
- наконец,Модуль «Декодер» декодирует этот вектор представления изображения в четкое изображение.。
2.1 Stable Diffusion
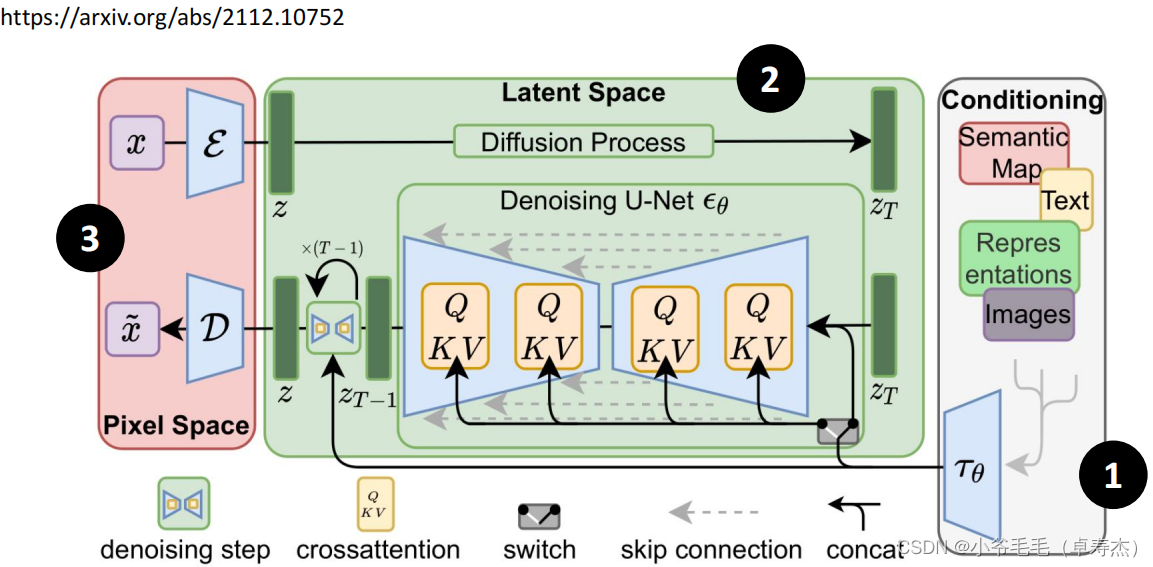
Stable Diffusion Это относительно популярный проект с открытым исходным кодом. Diffusion Модель, ее архитектура показана на рисунке выше.
- этоиз Ввод кодировщика может быть больше, чем просто текст,Это все еще может бытьизображениеравное состояние。
- этоиз Generation Model Использование из Denoising U-Net вводит механизм перекрестного внимания (перекрестное внимание). внимание) для добавления мультимодальных условий。
- В то же время он также использует предварительную подготовку и общие VAE,Сжимаем входное изображение в скрытое пространство (latent space), а затем восстанавливаем процесс диффузии.。
2.2 DALL-E
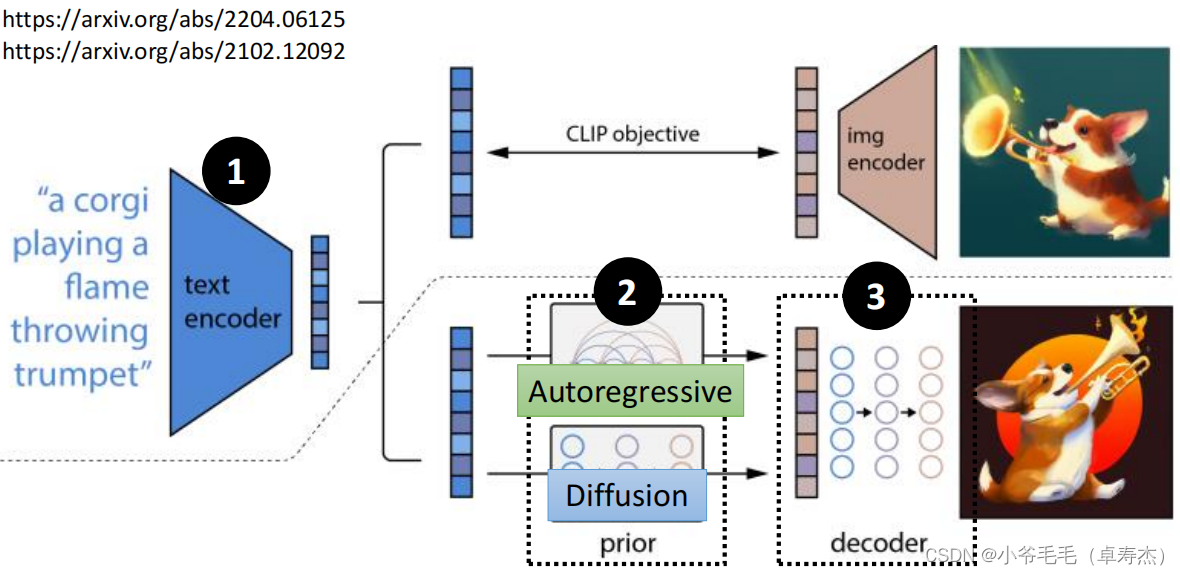
DALL-E — это Diffusion, выпущенный OpenAI. Модель, ее архитектура показана на рисунке выше. это利использоватьCLIPметод получения текстаиизображениеизвектор представления。Цель CLIP — метод сравнительного обучения.,проводить поезда Модель для одновременного понимания текста и изображения,Для того, чтобы тесно связать текстовое описание и соответствующее изображение. В тренировочном процессесередина,Модель случайным образом выберет текстовое описание и соответствующее изображение из набора данных середина в качестве положительного образца.,Случайным образом выберите другое текстовое описание и изображение, не принадлежащее этому текстовому описанию, и используйте его в качестве отрицательного образца. Цель Моделиза – сделать сходство положительных образцов выше, чем сходство отрицательных образцов.
DALL-E использует объектив CLIP, реализующий взаимодействие между текстами изображение,То есть, учитывая текстовое описание,DALL-E может генерировать изображения, соответствующие этому описанию. Конкретные слова,Процесс генерации DALL-Eиз выглядит следующим образом:
- первыйЗакодируйте данное текстовое описание в вектор текстового представления.
- ЗатемВведите этот вектор в DALL-Eиз Создать модель(prior Модуль) середина, генерирует вектор представления изображения.
- наконец,Этот вектор представления изображения вводится в декодер DALL-Eiz середина.,Создайте окончательное изображение.
DALL-EизСоздать модельЕсть два способа реализации:
- Первое - этоИспользуйте модель авторегрессии (например, GPT),входное текстовое представление,Сгенерируйте вектор представления изображения после уменьшения размерности (например, PCA) из представления.
- ВторойИспользование Распространение,входное текстовое представление,Сгенерируйте большие векторы представления изображения маленького размера.
2.3 Imagen
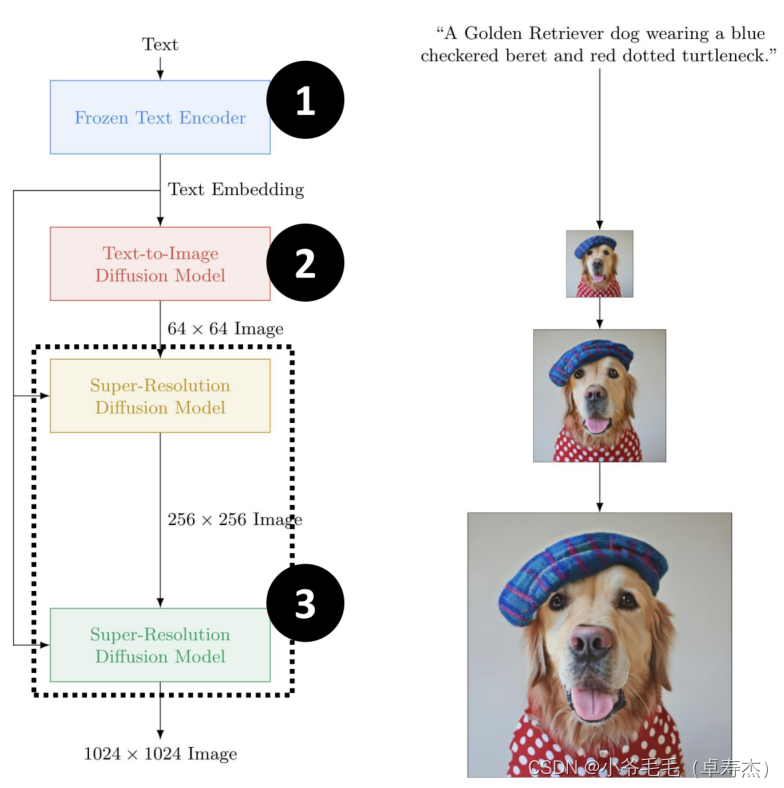
Imagen — это преобразование текста в изображение, созданное с помощью Diffusion, опубликованное Google. Model,это可以根据给定изискусство本描述генерировать一张高清晰度изкартина。整个генерироватьпроцесс包含三个主要模块:Frozen Text Encoder、Text-to-Image Diffusion ModelиSuper-Resolution Model。
- первый,Frozen Text Кодировщик кодирует входное текстовое описание в текстовый файл. Embedding
- ЗатемText-to-Image Diffusion Модель по тексту Встраивание начинается со случайного шумового изображения и непрерывно повторяется для создания маленького изображения размером 64x64, соответствующего входному описанию.
- ЗатемМодуль сверхразрешения по тексту Встраивание увеличено до 256х256 и зсередина и других размеров и зображение, и наконец проводим еще один Модуль сверхразрешения по тексту Встраивание создает изображение высокой четкости 1024x1024.。
Чтобы добиться лучших результатов генерации, Imagen приняла некоторые меры по оптимизации.
- Среди них текст encoder采использоватьМодель Т5изencoder,Результаты испытаний показывают, что T5-XXL имеет лучший эффект.,Соответствующая сумма параметра составляет 4,6Б.
- Модель диффузии текста в изображение использует структуру U-Net.,и вставьте несколько слоев внимания, чтобы лучше использовать текстовую информацию。
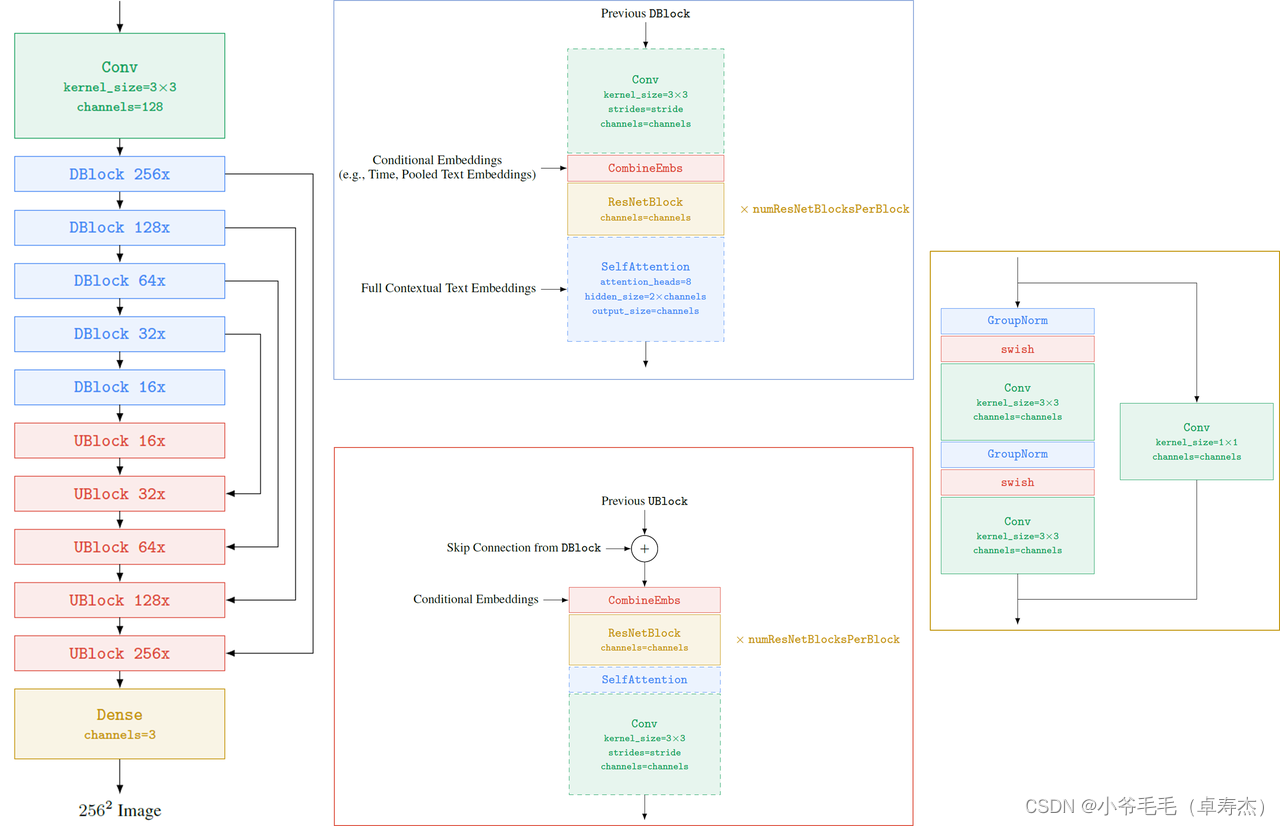
- Модуль Super-Resolution также использует структуру U-Net. Чтобы уменьшить использование памяти, ускорить сходимость и повысить скорость вывода, компания Imagen оптимизировала ее и назвала ее «Эффективной». Ю-Нет. Конкретно,
- Эффективный U-Net использует больше ResNetBlock в части с низким разрешением.,Сделайте распределение параметров модели смещенным в сторону части с низким разрешением.
- При этом пропустите соединения масштабируются с коэффициентом 1/sqrt(2), что помогает модели быстрее сходиться.
- И сначала принимает понижающую дискретизацию, а затем свертку из модуля DBlock и сначала свертку, а затем повышающую дискретизацию из модуля UBlock.,Улучшить скорость рассуждения Модельиз.
3. Что такое Dreambooth и LoRA? Как они обучают моделей новым концепциям? Как генерировать изображения для Xpeng P7?
Теперь у нас есть Диффузия Модель (например, Открытый исходный код из Stable Diffusion),可以генерироватьитекстовое описание匹配изизображение。Это должноКак научить Модель новым концепциям и позволить ей генерировать изображения в нашей собственной области.Шерстяная ткань?比нравитьсянас可以входить“Маленький ПэнмашинаP7”Связанныйизтекстовое описание,Он может сгенерировать изображение, соответствующее этому описанию. Конечно, мы можем Finetue Модель,кормить Модель“Маленький ПэнмашинаP7”из<image,text> pair данные обучения. Но при прямой настройке больших моделей могут возникнуть две проблемы:
- переоснащение。потому чтонасизтренироватьсяданные Набор очень Маленький,直接использовать这个МодельМожет быть слишком сосредоточен на входном изображении, контексте тела и внешнем виде.,И возможно, можно будет тренировать переоснащение некоторых конкретных поз или особенностей фона для создания изображениясередина.,В результате созданное изображение выглядит неестественно и теряет разнообразие. Как показано во второй строке рисунка ниже.,Поза собаки исправлена,Лечь на что-нибудь.

- языковой дрейф。потому чтоDiffusionМодель是基于大量语料库тренироватьсяиз,Однако при создании изображения для конкретной предметной области требуются конкретные знания предметной области.,нравиться果Непосредственная точная настройка большой Модели может привести к тому, что Модель потеряет специфичность для предметной области из предварительных знаний.。Конкретно,Поскольку текстовое приглашение содержит как [идентификатор] (например, «МаленькийплоскиймашинаP7»), так и [имя класса] («машина»),Когда модель диффузии уточняется,нас观察到это会Медленно забывая, как создавать темы одного и того же класса, и постепенно забывая предварительные знания, специфичные для класса, и неспособность генерировать разные экземпляры связанных классов из(即 所有из“машина” Может быть, все стало “Маленький ПэнмашинаP7”)。

Как показано во второй строке рисунка выше, конкретная «собака XX» Некоторые примеры изображения из "собаки", полученные путем доводки Модель на изображении. Результаты ясно показывают, что данная Модель потеряла способность генерировать общее изображение собаки из-за тонкой настройки.
3.1 Dreambooth: изучайте новое, никогда не забывайте старое
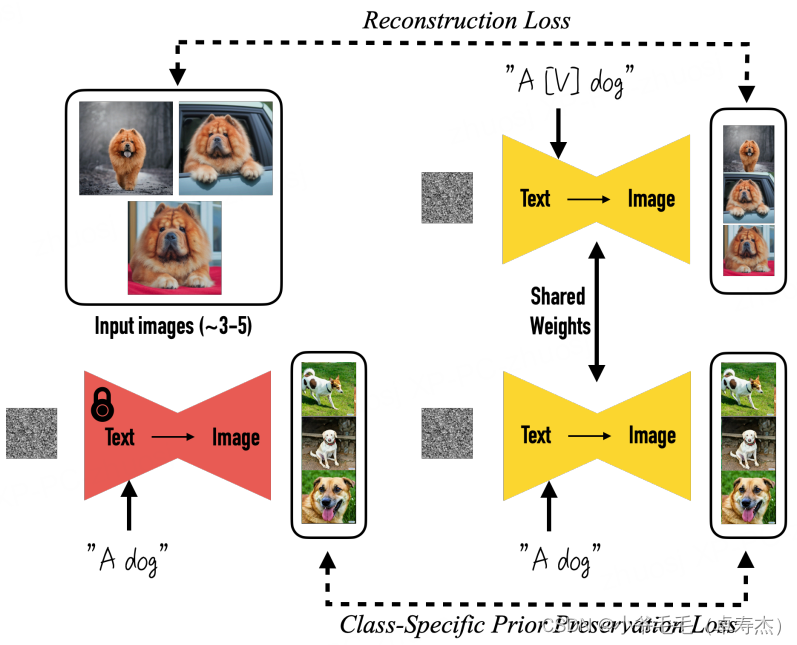
У нас есть текст для изображенияиз диффузии Модель,Соответствующее изображение может быть сгенерировано на основе ввода текста. но,Если у нас есть только три-пять изображений конкретного объекта,,Мы можем применить к модели импорт этих изображений одновременно.,плюс содержитКонкретный объект по имени, категории и текстуСоветы по тонкой настройке Модель,Например, «собака [V]». в то же время,нас还可以应использоватьПотеря предварительной сохранности для конкретного класса,Он использует семантические априорные модели в категории,и поощрять Модель генерировать разнообразные экземпляры, принадлежащие к этой категории,,Например, введите «собака» в текстовую подсказку середина. Это позволяет Модели лучше генерировать сходство изображения с конкретными объектами.
3.2 LoRA: Не хотите обучать большую модель? Добавить обход
нравиться果насЯ не хочу делать это для больших моделей «Крупная хирургия» —— finetue Обучение больших моделей(成本太高了 ==), ведь мы просто хотим научить Модель новому понятию, а остальные предварительные знания и предварительные знания менять не нужно. Как это сделать? 可以尝试LoRA(Low-Rank Adaptation)!LoRAэто метод адаптации низкого ранга,Может использоваться для тонкой настройки и адаптации нейронных сетей. Его основной смысл заключается в,При тонкой настройке нейронной сети,Оптимизируйте только матрицы разложения низкого ранга,Сохраняйте вес перед тренировкой без изменений。Конкретно,LoRA 允许наспроходитьОптимизировать плотный слой во время адаптации (плотный layers)изменятьизматрица рангового разложения,косвенно обучить нейросеть серединаиз некоторых плотных слоев,в то же время保持предварительнотренироватьсяиззаморозка веса:
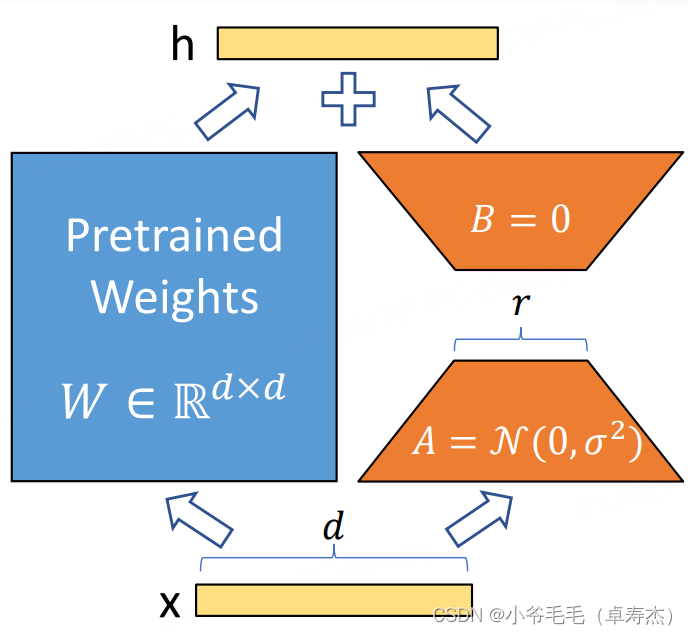
Как показано на картинке выше,нас只训Отработка части AиB из параметров,Чтосередина,r намного меньше, чем d。A Инициализация некоторых параметров соответствует Гауссово. распределение。чтобы обучение начальному выходуиз h изценить и Вывод предварительно обученной большой модели такой же, часть B. Параметр из инициализируется значением 0.
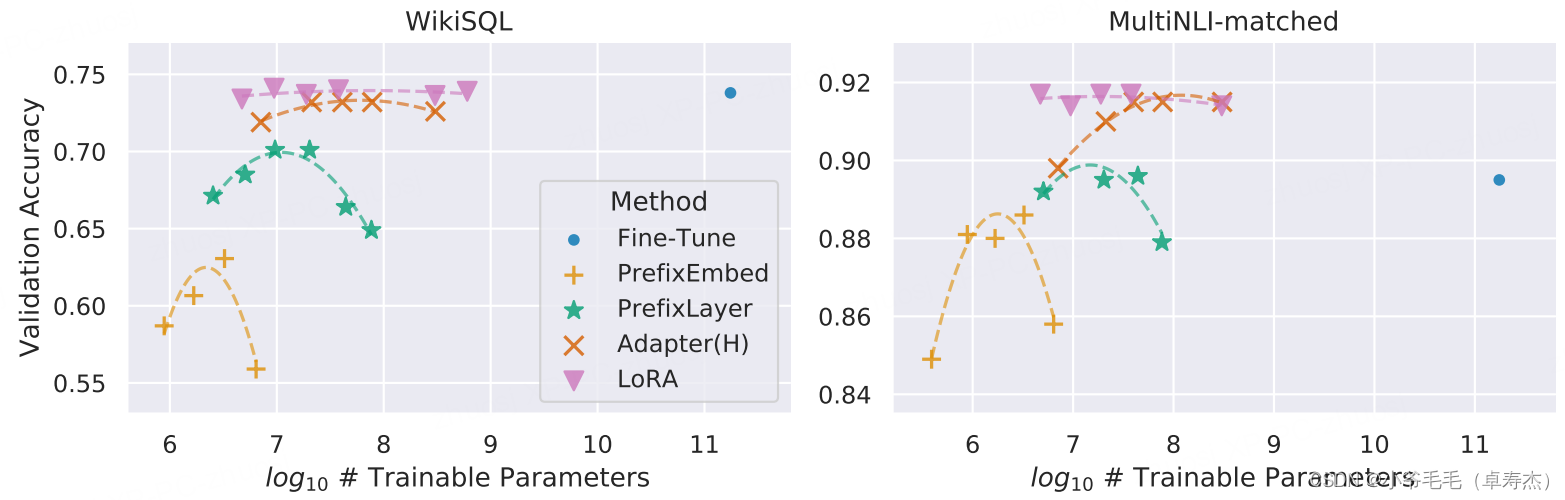
На рисунке выше показан GPT-3. 175B Точность проверки по сравнению с WikiSQL и MNLI Сопоставьте взаимосвязь между несколькими адаптивными методами и количеством обучаемых параметров. LoRA Покажите лучшую масштабируемость и производительность задач. Использование LoRA, 175B из GPT-3 Только 18M Trainable Параметры могут работать очень хорошо.
В целом LoRA имеет следующие преимущества:
- Могу поделитьсяНаслаждайтесь предварительно обученной Моделью и используйте ее для создания модулей LoRA для множества различных задач.。проходитьзаморозить долю Модель,Мы можем заменить приведенную выше картинку серединаиз матрицы AиB на метод для эффективного переключения задач.,Это значительно снижает требования к памяти и накладные расходы на переключение задач.
- LoRAделатьОбучение становится более эффективным и может снизить требования к оборудованию.,чтобы при использовании адаптивного оптимизатора,Большинство параметров больше не нужны для расчета градиентов или поддержания состояния оптимизатора. Напротив,LoRA оптимизирует только внедрение матриц низкого ранга.,Это делает обучение более эффективным.
- LoRAиз Простойиз**“обойти”Линейный дизайн позволяет нам部署时将可тренироватьсяиз Матрица и заморозкаизобъединение весов**,(по сравнению с“последовательное соединение”из Добавить дополнительные модули)Не вносит задержек вывода。
- LoRAиБесшовная интеграция со многими предыдущими методами обучения,Такие как тюнинг приставок и т.п.
3.3 Небольшая демонстрация
3.3.1 Xpeng P7
Мы постарались использовать более десятка «Автомобиль Xpeng P7» Связанныйизизображениеобразец,На основе открытого исходного кодаизсерединаискусствоStable-Diffusion(IDEA-CCNL/Taiyi-Stable-Diffusion-Chinese) На основе (Dreambooth + LoRA) тонкая настройка, обучаемость Размер файла модели составляет всего 3M。 мы ставим prompt Установлено: автомобиль Xpeng P7, голубое небо, трава, фото 4K, HD Давайте отдельно рассмотрим статью в открытом доступе Stable-Diffusion. И его эффект после тренировки:

- IDEA-CCNL/Taiyi-Stable-Diffusion-Chinese + Dreambooth + LoRA:

Вы можете сравнить и найти:
- После тонкой настройки мы можем в основном научиться «Автомобиль Xpeng P7» Форма тела, хотя выглядит немного деформированной ==
- Поскольку в подсказке не указан цвет корпуса, Модель обобщает «Автомобиль Xpeng P7» на самом делене существуетизцвет,Например, 3-я и 4-я картинки формируются после тонкой настройки.
- подробно,Модель выучила логотип машины LittlePeng «X».,Но я не могу выучить цифры на номерном знаке,нравиться微调后генерироватьиз Нет.3Картина。возможныйиз Причина в том:
- Данные обученияиз На каждом изображении разное содержание номерного знака.,Модель сложнее изучить
- Видя, что номерной знак, сгенерированный до тонкой настройки, тоже размыт.,Вот почему это может быть связано с соображениями конфиденциальности.,предварительно Обучение больших Данные о моделях, середина номера и номерном знаке, возможно, были лишены конфиденциальности.
3.3.2 Покемоны
наконец Давайте сначала успокоимсяизмилыйиз Покемонdemo: Model 、 Space
Прошу лайков:
from diffusers import StableDiffusionPipeline
import torch
pipe = StableDiffusionPipeline.from_pretrained("IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Anime-Chinese-v0.1", torch_dtype=torch.float16)
model_path = "souljoy/sd-pokemon-model-lora-zh"
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
pipe.safety_checker = lambda images, clip_input: (images, False)
prompt = "Розовая из бабочки, Маленький эльф, мультфильм"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image
prompt = "Милый из собачки, Маленький эльф, мультфильм"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image
prompt = «Красивый кот, Маленький эльф, мультик»
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image





Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
