Краткий анализ и лучшие практики технологии разделения хранения и вычислений Elasticsearch
иллюстрировать
Проблемы и решения, описанные в этой статье, также применимы к Тенсент Облако Elasticsearch Service(ES)。
Также используется:Объектное хранилище (Облачное объектное хранилище, COS)
Конфигурация среды
Версия Elasticsearch: 7.14.2
фон
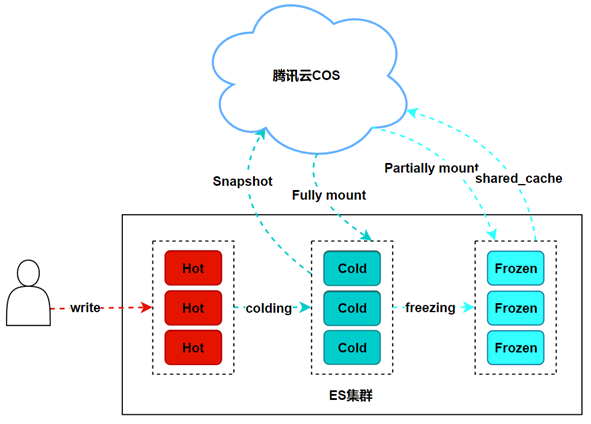
Являясь частью стека технологий больших данных, ES сегодня также является популярной поисковой системой. Однако по мере увеличения объема данных затраты на хранение становятся все более дорогими. Например, некоторые более важные сценарии журналов клиентов или данные электронной коммерции и т. д. могут потребовать хранения этих данных в течение длительного времени. В настоящее время решения по снижению затрат на хранение особенно важны. Сегодня я поделюсь с вами решением ES для разделения хранения и вычислений.
1. Краткий анализ принципа резервного копирования моментальных снимков
Реализация технологии разделения хранения и вычислений ES основана на функции резервного копирования снимков, что добавляет возможность поиска на основе снимков. Прежде чем представить снимки с возможностью поиска, давайте кратко рассмотрим базовые знания о снимках ES.
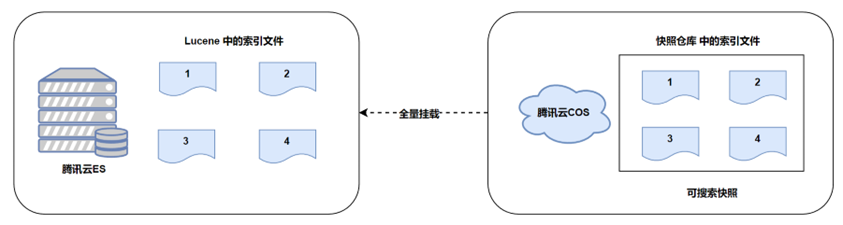
- Нижний уровень ES использует Lucene, а снимок ES фактически является резервной копией файла Lucene;
- Снимок ES содержит все файлы, относящиеся к индексу снимка на текущий момент времени, и снимок поддерживает полное/инкрементное (дифференциальное) восстановление;
- Снимок Приращения хранит только разностную часть Приращения, а перекрывающаяся часть будет напрямую ссылаться на файл исторического снимка;
- При удалении моментального снимка удаляются только файлы, на которые не ссылается ни один снимок.
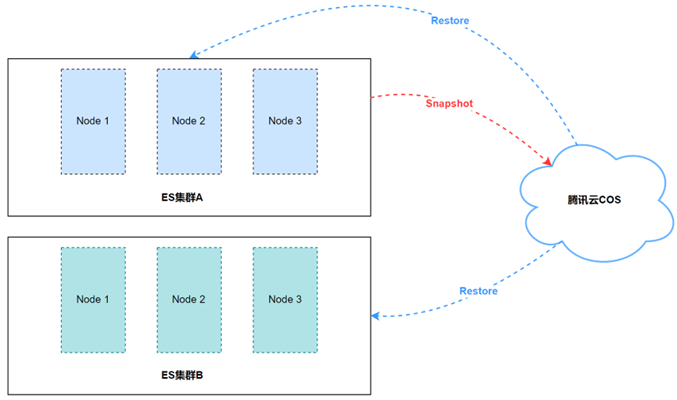
1. Полное резервное копирование
Первая резервная копия снимка является полной резервной копией, здесь мы записываем имя снимка как «Снимок A».
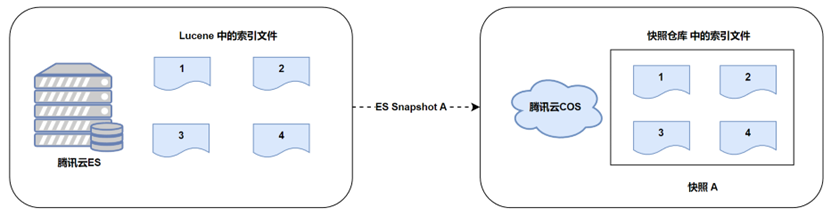
Список файлов, связанных со снимком A: 1, 2, 3, 4.
2. Инкрементальное/дифференциальное резервное копирование.
Затем мы внесли некоторые изменения в данные в ES, что привело к некоторым изменениям в файле Lucene. Из-за особенностей файла сегмента индекса Lucene он будет только добавляться и удаляться, но не изменяться. Поэтому файл в Lucene в это время может выглядеть, как показано на следующем рисунке. Затем сделайте второй снимок, который мы назовем «Снимок Б».
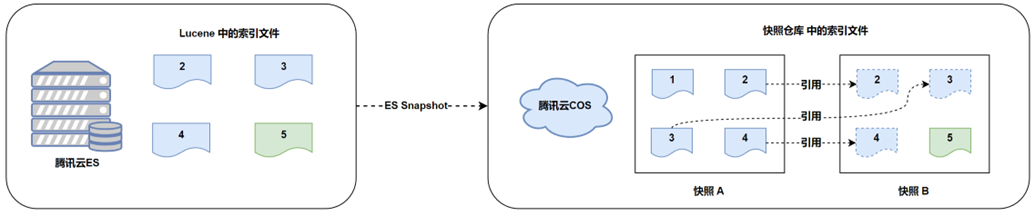
Список файлов, связанных со снимком B: 2, 3, 4, 5.
3. Удалить исторические снимки
Наконец, мы удаляем снимок A.
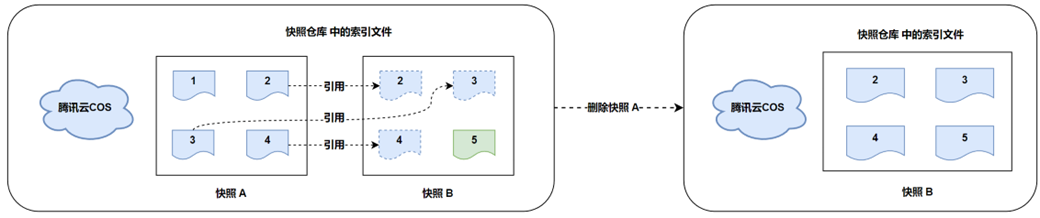
Файлы, связанные со снимком A: 1, 2, 3, 4;
Файлы, связанные со снимком B: 2, 3, 4, 5;
Таким образом, при удалении снимка A можно удалить только файл 1.
Q&A
1. Повлияет ли удаление исторических снимков на инкрементные снимки?
Ответ: Нет, возьмите приведенную выше логику создания снимков в качестве примера. Удаление исторических снимков приведет к очистке только тех файлов, которые не связаны ни с одним снимком. Каждый полный снимок может восстановить полный объем данных на данный момент.
2. Как восстановить полные данные? Нужно ли восстанавливать по одному, начиная с первого снимка?
Ответ: Нет, вам нужно восстановить снимок только в указанный момент времени, поскольку каждый снимок сохраняет полный объем данных на этот момент времени.
2. Обзор технологии снимков с возможностью поиска


- Поддерживает поиск практически неограниченных объемов замороженных данных, хранящихся в снимках (например, год или более).
- Холодные данные хранятся в COS, что значительно снижает затраты.
- Начальная частота запросов замороженных данных невелика и требует длительной задержки запроса. Проверенные данные кэшируются, чтобы обеспечить скорость запросов, соответствующую горячим данным.
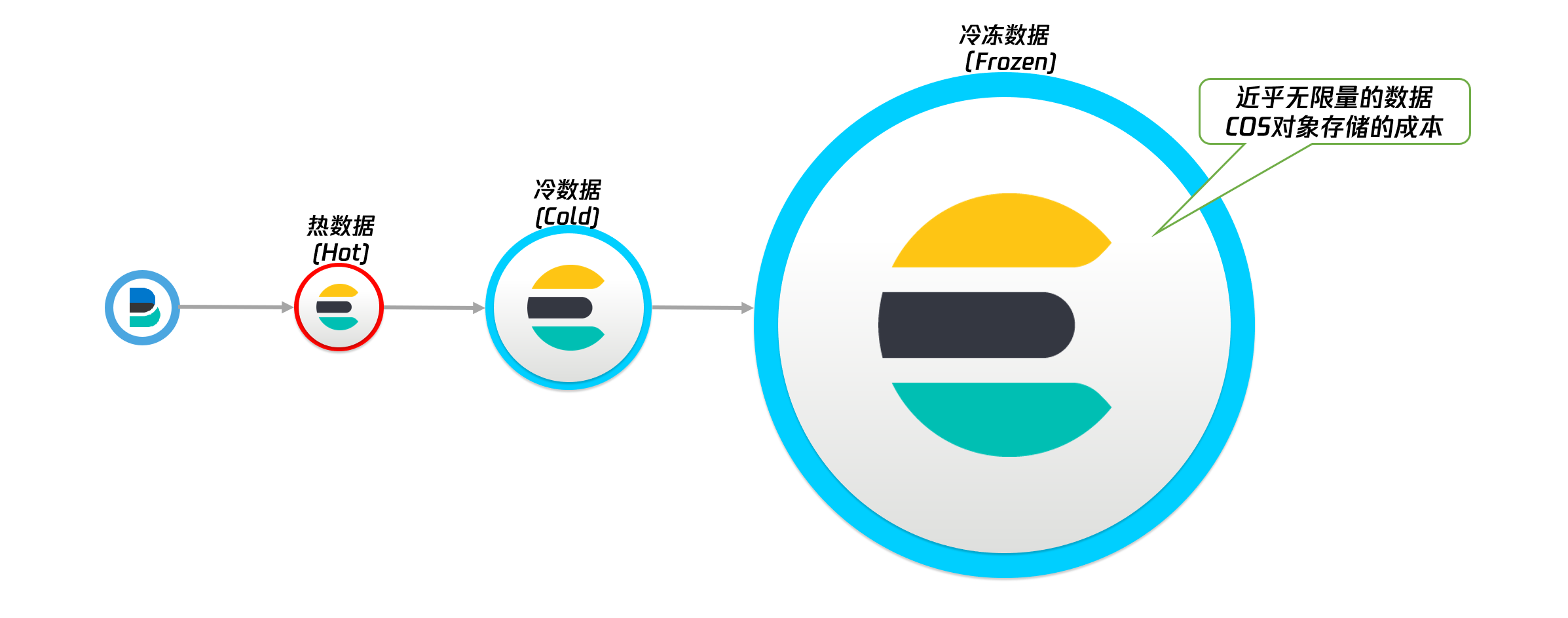
Модель уровня данных

Принцип работы
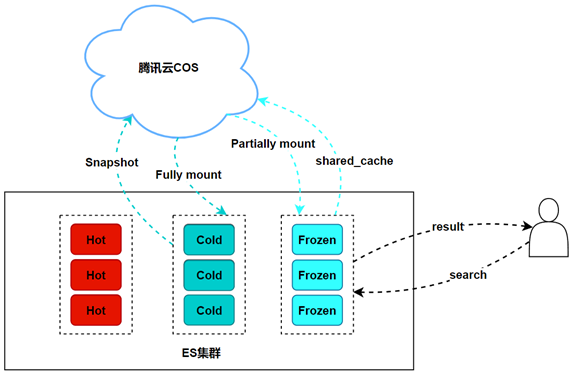
Полностью смонтированный индекс
Полное монтирование означает сохранение полной копии данных, проиндексированных в снимке, на узле кластера ES. При поиске полностью смонтированного индекса снимка с возможностью поиска принцип поиска и производительность мало чем отличаются от обычных индексов. Преимущество перед обычными индексами в том, что при повреждении одного из шардов индекс снапшота с возможностью поиска автоматически извлечет данные из снапшота и восстановит их на других узлах, особенно когда в кластере нет реплик. Обычный режим — это напрямую кластер. красный. Если необходимо восстановление, его необходимо восстановить вручную из снимка. Красный индекс необходимо удалить перед восстановлением. Индекс, смонтированный через монтирование, автоматически восстановит поврежденные фрагменты из снимка.
Частично смонтированный индекс
Частичное монтирование не монтирует данные индекса из снимка на узел кластера, а лишь сохраняет метаданные индекса на узле в виде индексов и сегментов. Частично смонтированные осколки будут размещены только на уровне «Заморожено». Таким образом, узлы замороженного слоя в кластере не хранят данные моментального снимка, а хранят только метаданные сегментов индекса. Исходные данные хранятся в хранилище моментальных снимков COS.
Как показано в следующем примере API, хранилище — это тип монтирования индекса: full_copy — полное монтирование, аshared_cache — частичное монтирование.
POST _snapshot/ss_repository/ss_daemonyue/_mount?wait_for_completion=true&storage=full_copy
{
"index": "daemonyue-2023.06.01-000001",
"renamed_index": "daemonyue-2023.06.01-000001_from_cos",
"index_settings": {
"index.number_of_replicas": 0
},
"ignore_index_settings": [ "index.refresh_interval" ]
}POST _snapshot/ss_repository/ss_daemonyue/_mount?wait_for_completion=true&storage=shared_cache
{
"index": "daemonyue-2023.06.01-000001",
"renamed_index": "daemonyue-2023.06.01-000001_from_cos",
"index_settings": {
"index.number_of_replicas": 0
},
"ignore_index_settings": [ "index.refresh_interval" ]
}
- Индекс снимка с возможностью поиска, смонтированный частью запроса, будет извлечен из снимка и загружен в локальный кэш узла замороженного слоя. В следующий раз, когда будут запрошены аналогичные данные, они могут быть возвращены непосредственно из локального кэша.
- Если в кластере не настроены выделенные замороженные узлы, необходимо настроить параметр xpack.searchable.snapshot.shared_cache.size в файле конфигурации узла, чтобы указать пространство хранения, которое необходимо зарезервировать для общего кэша на каждом узле.
Frozen Запрос на узел данные намного медленнее, чем полное монтирование или обычный индекс. Чтобы решить эту проблему, Elasticsearch. предоставил Async API поиска (асинхронный поиск), API Результаты запроса не будут возвращены сразу после выполнения, но запрос будет возвращен. ID, а затем асинхронно подготовьте данные. Когда данные будут готовы, их можно запросить через ID Получите соответствующие данные.
POST sale*/_async_search?size=0
{
"sort": [
{ "date": { "order": "asc" } }
],
"aggs": {
"sale_date": {
"date_histogram": {
"field": "date",
"calendar_interval": "1d"
}
}
}
}
GET _async_search/status/{id} # Получить статус асинхронного поиска
GET _async_search/{id} # Получить результаты выполнения асинхронного поиска
DELETE _async_search/{id} # Удалить асинхронный поиск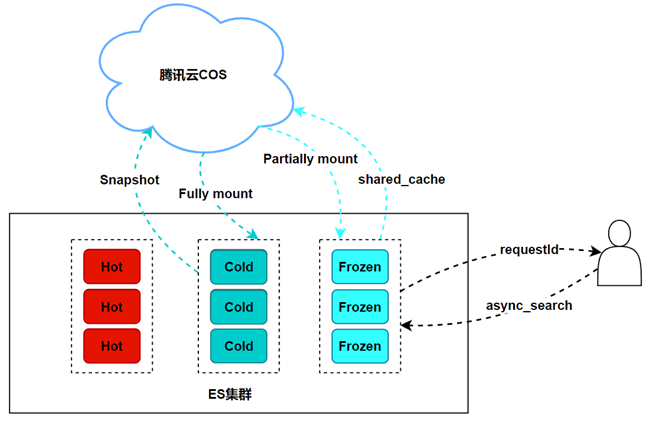
3. Рекомендации по созданию снимков с возможностью поиска
Ниже мы продемонстрируем всю ссылку на реализацию снимка с возможностью поиска:
1) Мы моделируем бизнес для непрерывной записи данных в кластер, а новые индексы по умолчанию распределяются по горячим узлам. Индекс настроен с ролловером и начинает катиться в горячих узлах после достижения определенного времени или определенного размера;
2) Через 7 дней после завершения переноса начните миграцию на холодную ноду и выполните резервное копирование COS;
3) После завершения резервного копирования полностью смонтировать (full_copy) его к кластеру и удалить индекс холодного узла в кластере;
4) Через 30 дней после полного монтирования индекс будет преобразован в частичный монтирование (shared_cache), а сегменты индекса окончательно будут размещены в замороженном слое.
Зарегистрировать хранилище снимков
Сначала мы используем Тенсент Облако COS как ES Склад моментальных снимков, имя склада ss_repository, а путь к хранилищу указан как searchable-snapshot。
Полный API для складских запросов:
POST _snapshot/ss_repository
{
"type": "cos",
"settings": {
"app_id": "1253240642",
"access_key_id": "XXXXXn46uTmrhHdkbDm7C3f1XxxxXXxxxxxx",
"access_key_secret": "XXXXXFAtMYWFjxveGmIekaXxxxXxXXXx",
"bucket": "es-cos-dy",
"region": "ap-guangzhou",
"compress": true,
"chunk_size": "500mb",
"base_path": "searchable-snapshot"
}
}Настройка жизненного цикла индекса
Целью настройки ILM является автоматизация жизненного цикла индекса, который включает в себя:
- индексгорячая сцена / Индексная прокрутка
- Данные индекса остывают / снимок с возможностью поиска полностью монтируется
- Частичное монтирование снимка с возможностью поиска
В следующем API жизненного цикла индекса (ILM) мы определяем три фазы индекса: горячая/холодная/замороженная.
- Hot Этап представляет собой этап индексирования горячих данных, который также является этапом индексирования горячих данных. Стадия прокрутки;
- Cold Существуют определенные различия между этапами и традиционным охлаждением. Данные сначала сохраняются. COS в снимок, а затем смонтировать все данные снимка локально;
- Фаза заморозки аналогична холодной фазе. Она также монтирует снимок локально. Разница в том, что заморозка не монтирует данные напрямую, а только сохраняет информацию, связанную с метаданными индекса, в замороженном слое.
PUT _ilm/policy/ilm-ss
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_age": "1d",
"max_primary_shard_size": "10gb"
},
"set_priority": {
"priority": 100
}
}
},
"cold": {
"min_age": "7d",
"actions": {
"searchable_snapshot": {
"snapshot_repository": "ss_repository",
"force_merge_index": true
},
"set_priority": {
"priority": 0
},
"allocate": {
"number_of_replicas": 0
}
}
},
"frozen": {
"min_age": "30d",
"actions": {
"searchable_snapshot": {
"snapshot_repository": "ss_repository",
"force_merge_index": true
}
}
}
}
}
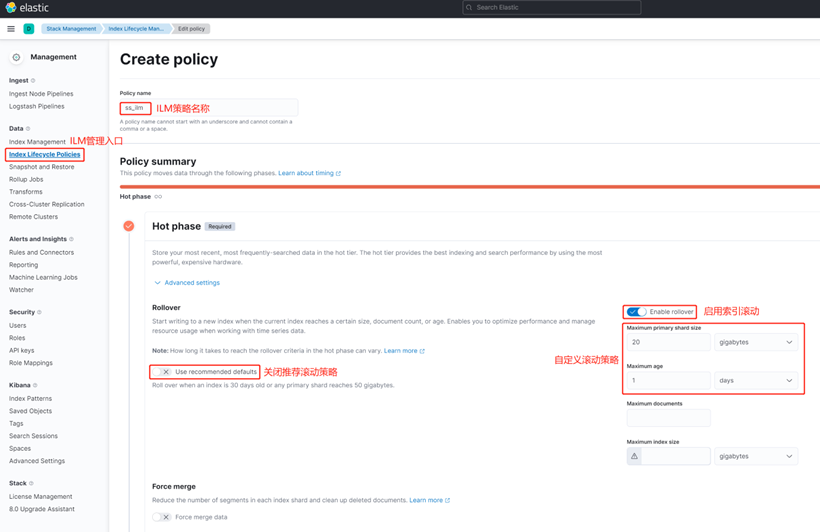
}Настройка визуализации жизненного цикла индекса(горячая сцена)
Помимо API, Kibana также предоставляет визуальную настройку ILM. Ниже показана стратегия ILM для горячей фазы (фазы прокатки).
Мы отключили рекомендуемую по умолчанию стратегию прокрутки и надеемся, что в процессе записи данных, когда размер сегмента достигнет 20 ГБ или когда время существования индекса достигнет 1 дня, индекс будет прокручиваться и будет сгенерирован новый индекс, так что индекс одного индекса можно контролировать. Размер данных находится в контролируемом диапазоне.
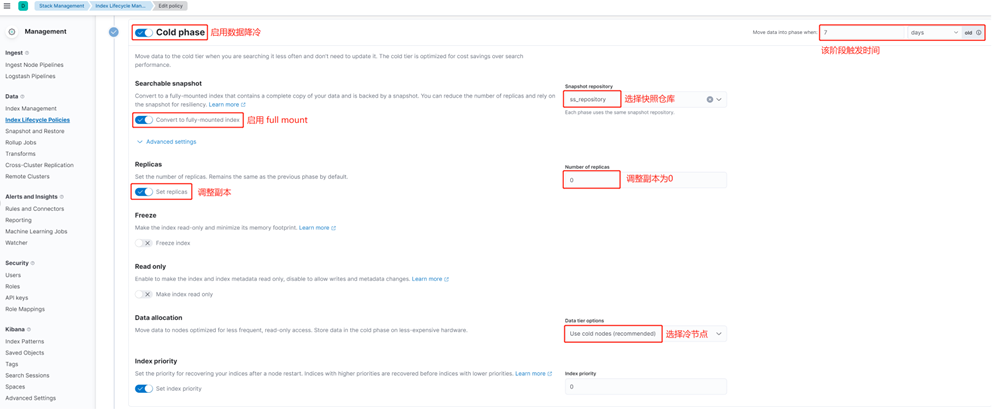
Настройка визуализации жизненного цикла индекса(холодная стадия)
На холодной фазе мы включили полное монтирование, выбрали ранее созданное хранилище моментальных снимков, определили время запуска холодной фазы и установили индексную копию холодной фазы на 0. На этом этапе данные сначала будут скопированы в хранилище COS, затем индекс моментального снимка будет полностью смонтирован на холодном узле, псевдоним будет переключен, и, наконец, горячий индекс будет удален.
Визуализация Настройка жизненного цикла индекса (стадия заморозки)
На этапе замораживания вам нужно только настроить хранилище снимков и время срабатывания. На этом этапе часть индекса снимка будет подключена к слою замораживания, а псевдоним будет переключен, а затем холодный индекс будет удален.
Стоит отметить, что частичное монтирование сначала сохраняет только информацию, связанную с метаданными индекса. При запросе замороженных данных ES считывает данные из снимка и возвращает их клиенту, а также сохраняет кеш запросов в замороженном слое. используется для ускорения запросов. ES имеет политику вытеснения кэша, которая регулярно очищает кэшированные данные, которые не запрашиваются часто, чтобы освободить место.

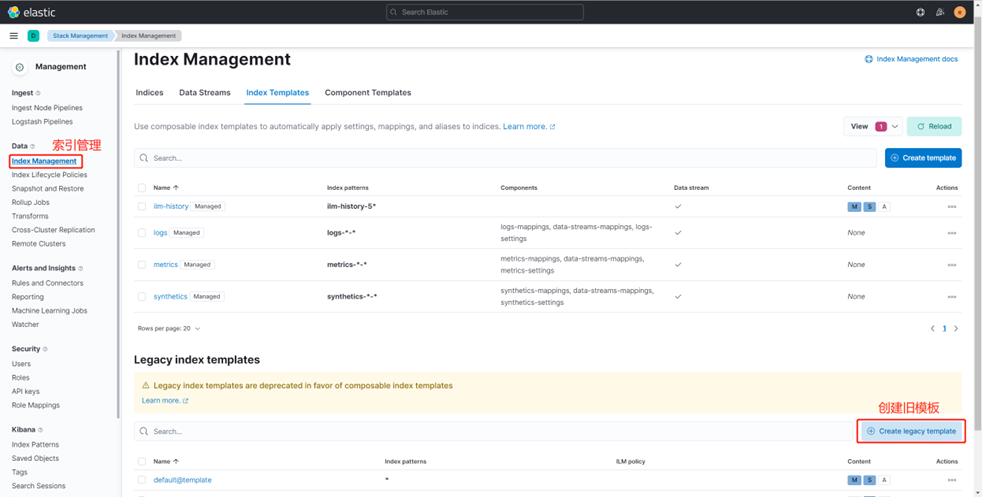
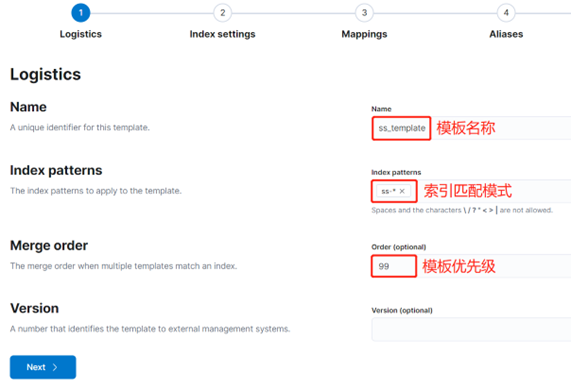
Настроить шаблон индекса
После завершения настройки ILM также потребуется Настроить шаблон индекса.
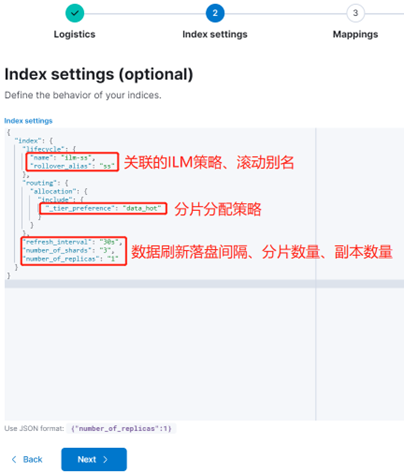
Имя шаблона — ss_template. В шаблоне индекса определен индекс, шаблон соответствия которого начинается с «ss-*», а также указана политика ILM (ilm-ss), которую мы только что создали, и псевдоним смены индекса (ss). .
Кроме того, также настраиваются стратегия распределения сегментов (data_hot), интервал обновления индекса (30 с), количество сегментов индекса (3) и количество копий индекса (1).
PUT _template/ss_template
{
"order": 100,
"index_patterns": [
"ss-*"
],
"settings": {
"index": {
"lifecycle": {
"name": "ilm-ss",
"rollover_alias": "ss"
},
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_hot"
}
}
},
"refresh_interval": "30s",
"number_of_shards": "3",
"number_of_replicas": "1"
}
}
}Далее Настройка шаблона индекса
Шаблоны индексов также можно настроить визуально через Kibana:
Создать начальный индекс
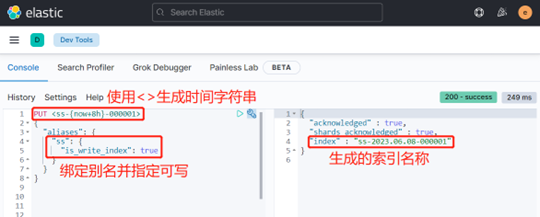
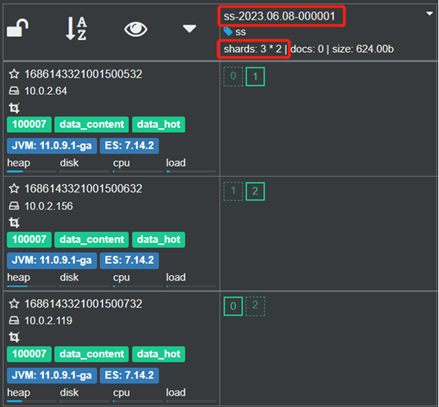
ILM и После завершения настройки шаблона индекса мы можем создать начальный индекс, используйте <now+8h> К имени индекса можно добавить дату. После создания индекса имя индекса содержит текущую дату, а суффикс меняется со стандартного. rollover 000001 Изначально индекс имеет шарды 3 и реплики 1.
PUT <ss-{now+8h}-000001>
{
"aliases": {
"ss": {
"is_write_index": true
}
}
}
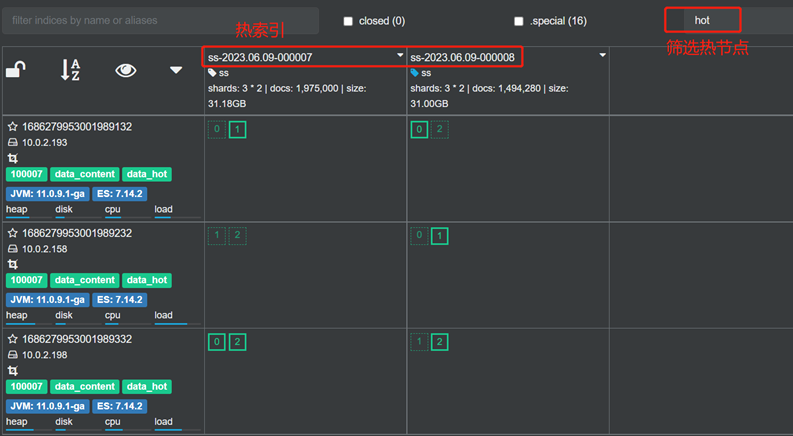
Имитация делового письма (горячая фаза)
Индекс имеет 7 полей, а именно:
- @timestamp
- name
- age
- gender
- address
- job
- description
Имитация делового письма (холодная стадия)
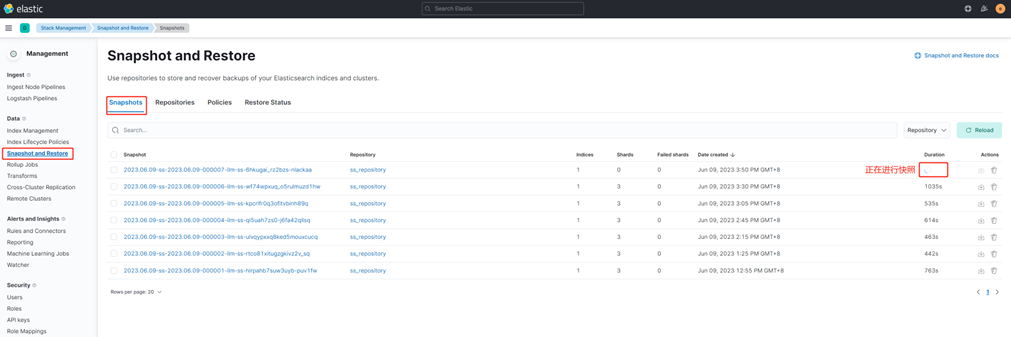
Когда горячие данные достигают состояния ролловера, свернутый исторический индекс перейдет на следующую стадию: холодное/полное монтирование.
На этом этапе сначала будет сделан снимок «горячих» данных. Когда снимок будет завершен, ES создаст новый холодный индекс, начиная с «restore-», смонтирует полный снимок в этом индексе, а затем удалит «горячий» индекс. Весь процесс использует замену псевдонимов для достижения плавного и незаметного переключения бизнеса.
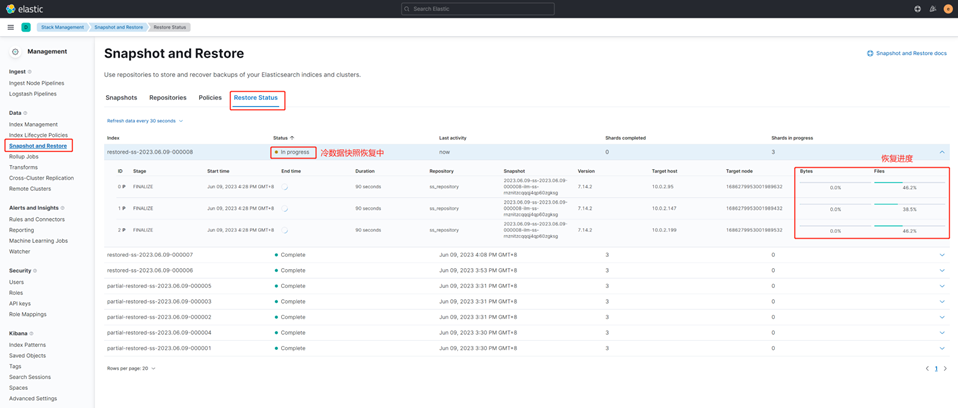
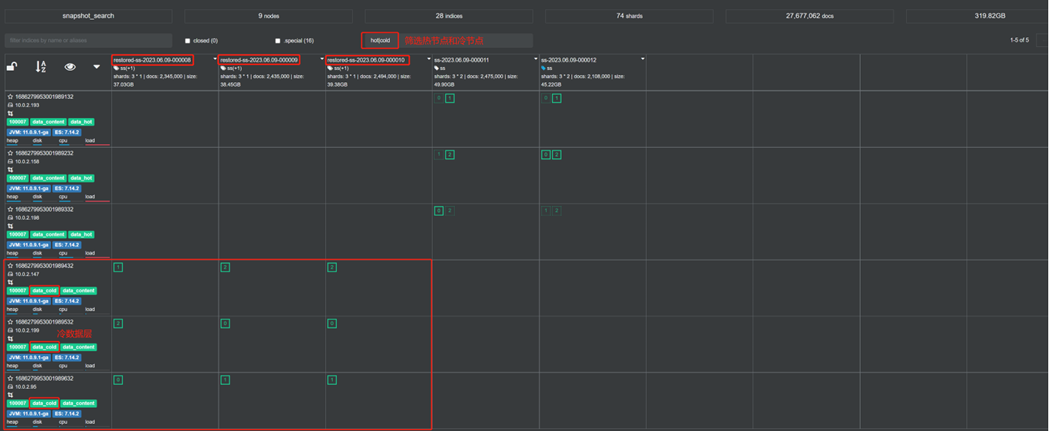
Данные уровня холодных данных следующие: На этапе полного монтирования холодных данных автоматически генерируется холодный индекс с префиксом восстановлен-.
Имитировать деловое письмо (стадия заморозки)
Когда горячие данные достигнут холодного состояния, охлажденный исторический индекс перейдет на следующий этап: заморозка/частичное монтирование.
Ниже показано, как индекс переходит в замороженное состояние. На этапе частичного замораживания автоматически генерируется холодный индекс с префиксом частичное-.
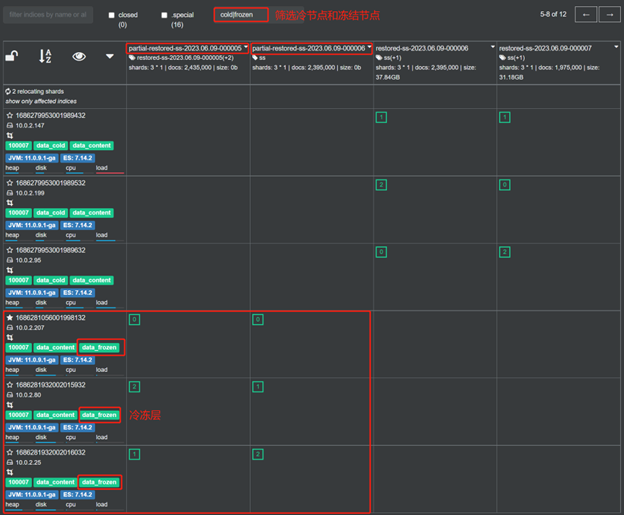
Запрос данных
горячая сцена -> холодная стадия -> На этапе заморозки мы завершили индексацию ILM Целевая жизнь.
Далее мы используем операторы запроса DSL для получения данных и сравниваем производительность запросов к горячим и замороженным данным соответственно.
Давайте возьмем следующее DSL Например,Запрос горячего индекса и замороженного индекса соответственно,И выполните простую агрегацию подсчета.
POST ss-2023.06.09-000010/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "Joanne Smith"
}
},
{
"range": {
"age": {
"gte": 37
}
}
},
{
"match": {
"gender": "male"
}
},
{
"match": {
"job": "Ship broker"
}
}
],
"should": [
{
"match": {
"address": "4985 Patterson Streets"
}
},
{
"match": {
"description": "Government question white list"
}
}
]
}
},
"_source": [
"name",
"age",
"gender",
"job",
"description"
],
"aggs": {
"name_counts": {
"terms": {
"field": "name"
}
}
}
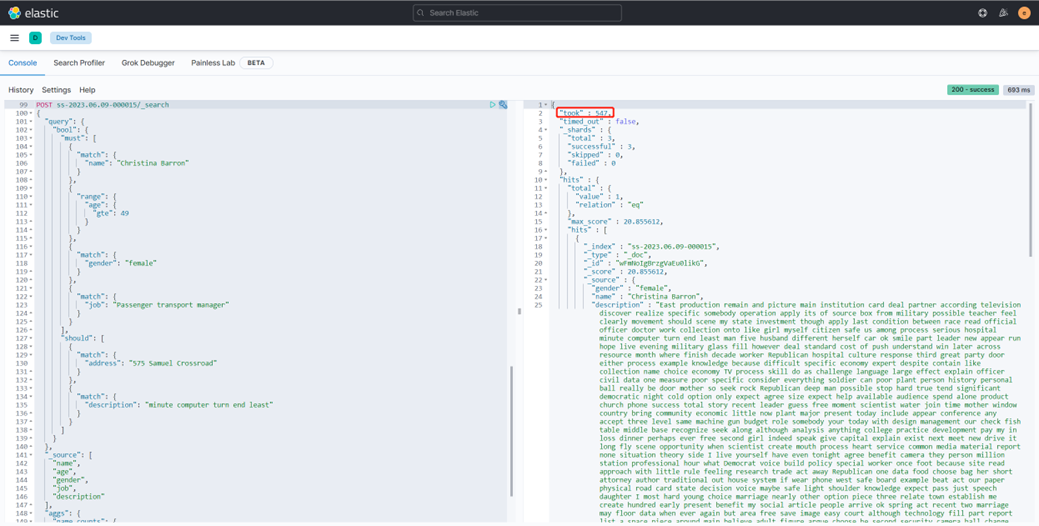
}горячий Запрос данных
горячий Запрос данные занимают 547ms
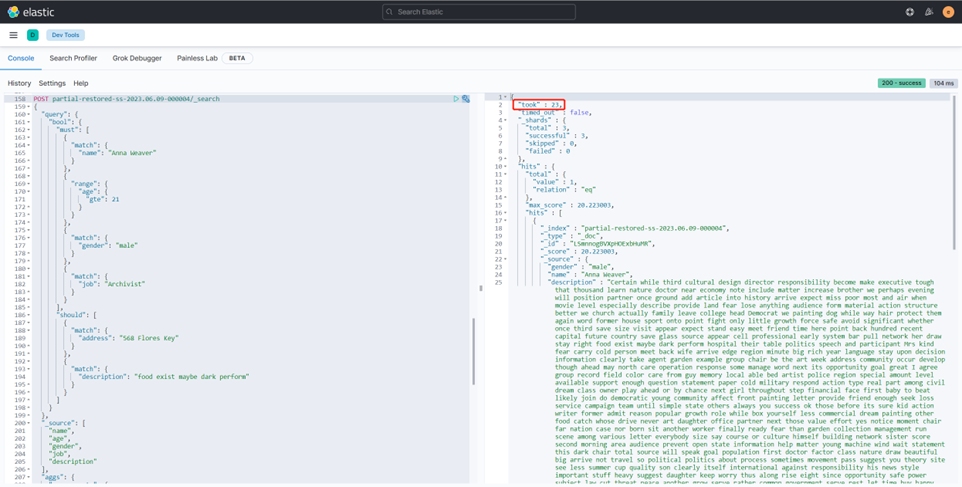
Ледяной Запрос данных
Ледяной Запрос данные занимают 2733ms

через предыдущий тест запроса DSL,Видно, что разрыв в производительности между горячими и замороженными данными все еще относительно велик. Основное отличие — время, необходимое для построения кеша.,Когда замороженные данные завершают построение кэша,Он может предоставлять запросы миллисекундного уровня, такие как горячие узлы.
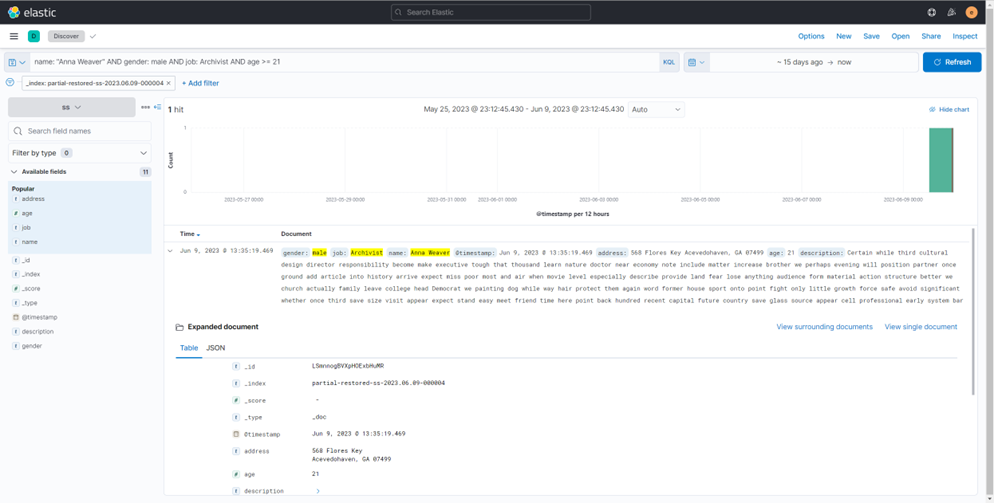
Мы также можем использовать Kibana Discover для получения данных и более интуитивного отображения данных.
4. Часто задаваемые вопросы по снимкам с возможностью поиска
Q&A
1. Как отличить обычный индекс от Снимки с индексом поиска?
Ответ: Снимки с возможностью поиска, реализованные с помощью ILM, можно отличить по именам индексов. Индекс с префиксом «восстановленный» — это индекс холодного снимка, а индекс с префиксом «частичный» — это индекс замороженного снимка.
2. Если замороженные данные запрашиваются часто, не будет ли на диске замороженного узла недостаточно места?
Ответ: Политика кэширования снимков с возможностью поиска имеет механизм автоматического удаления. Когда область кэша недостаточна, будет удален последний использованный кэш. Кроме того, состояние кэша снимков с возможностью поиска также поддерживает ручной просмотр и очистку.
3. Если узел перезапускается из-за OOM, простоя компьютера и т. д. после возобновления работы службы, требует ли доступный для поиска моментальный снимок ручного вмешательства для перемонтирования?
Ответ: После перезапуска узла и его подключения к сети снимок с возможностью поиска будет восстановлен обычным образом, как обычный индекс, без ручного вмешательства.
4. Повлияет ли носитель хранения замороженного слоя снимка с возможностью поиска на эффективность запроса?
Ответ: Для зависших дисков рекомендуется использовать SSD, который может ускорить запросы.




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
