Краткая история развития алгоритмов обнаружения целей
Предисловие
По сравнению с распознаванием изображений технология генерации изображений теперь более привлекательна. Однако, если вы хотите заняться технологией AIGC, в первую очередь не рекомендуется обращаться к тем зрелым веб-сайтам с интерфейсом с закрытым исходным кодом, которые упакованы и предоставлены вам. . Вы будете использовать других. Можете ли вы назвать себя AIGC, создав несколько изображений из своей модели? Это настоящий движитель, и он самый дешевый. Технология генерации изображений более развита и основана на некоторых базовых технологиях обработки изображений. Изучая самые базовые технологии обработки изображений, вы можете понять, что такое генерация изображений. В последнее время я прочитал много статей и блогов об обнаружении целей, а также изучаю технологию AIGC: от базовых функций, разработанных вручную, до современных моделей глубокого обучения, можно сказать, что история развития этих двух технологий относительно схожа.
В этой статье мы рассмотрим историю развития алгоритмов обнаружения объектов, от ранних традиционных методов, основанных на искусственно созданных функциях, до развития технологий глубокого обучения и великих достижений обнаружения объектов в различных областях. Мы рассмотрим этот долгий и увлекательный путь, обсудив важные алгоритмы и методы на каждом этапе, а также их ценность в практических приложениях.
1. Обзор обнаружения целей
Обнаружение цели делает не что иное, как две вещи: первая — определение местоположения цели на изображении или видео и ее категории. Второй — определить местоположение и категории всех целей на изображениях с несколькими целями. Итак, чтобы первая проблема была решена, мы можем понять, что именно нужно сделать.
1. Позиционирование и классификация
Прежде всего, мы знаем, что изображения состоят из бесчисленного количества пикселей, а видео также можно понимать как последовательное формирование изображений в каждом кадре, то есть соотношение точек с линиями и линий с поверхностями. Проблема позиционирования и классификации представляет собой задачу перехода от классификации к обнаружению цели, от простой задачи классификации изображений к указанию местоположения цели, к категории и местонахождению нескольких целей.

Что касается проблемы классификации, мы знаем, что, пока существуют соответствующие функции, обнаруженные цели имеют некоторые общие характеристики в разных сценах. Чтобы уточнить, форма комбинации пикселей в определенной степени поддается классификации. Мы можем использовать эти функции классификации. . Что касается проблемы позиционирования, модель должна вернуть внешний прямоугольный блок, в котором расположена цель, то есть четверка (x, y, w, h) цели. Объединив их, мы можем понять это как результат одновременного использования классификации и регрессии для получения классификации и позиционирования, за исключением того, что регрессия представляет собой проблему позиционирования и возвращает четыре значения.

2. Обнаружение цели
Для обнаружения целей необходимо получить положения и категории всех целей на изображении. Обычно мы думаем об использовании метода скользящего окна для последовательного обнаружения изображений, но нам нужно спроектировать скользящую рамку того размера, чтобы решить проблему и как. сколько раз в среднем нам нужно его обнаружить? Очевидно, что этот расчет очень велик и не соответствует ожидаемым результатам. Есть ли способ быстро обнаружить цель?
Многие эксперты в этой области разработали здесь множество алгоритмов. Более известным методом является метод выборочного поиска, который может выбирать потенциальные кадры-кандидаты объектов (области интереса, рентабельность инвестиций) из изображения. При использовании метода получения рентабельности окончательные результаты обнаружения целей могут быть получены путем классификации и объединения.

Логику алгоритма можно разделить на следующие этапы. Проблемы с обнаружением целей с использованием методов скользящего окна, например: разные размеры, размеры и положения скользящего окна генерируют очень большой объем вычислений.

2. Обзор алгоритмов обнаружения целей
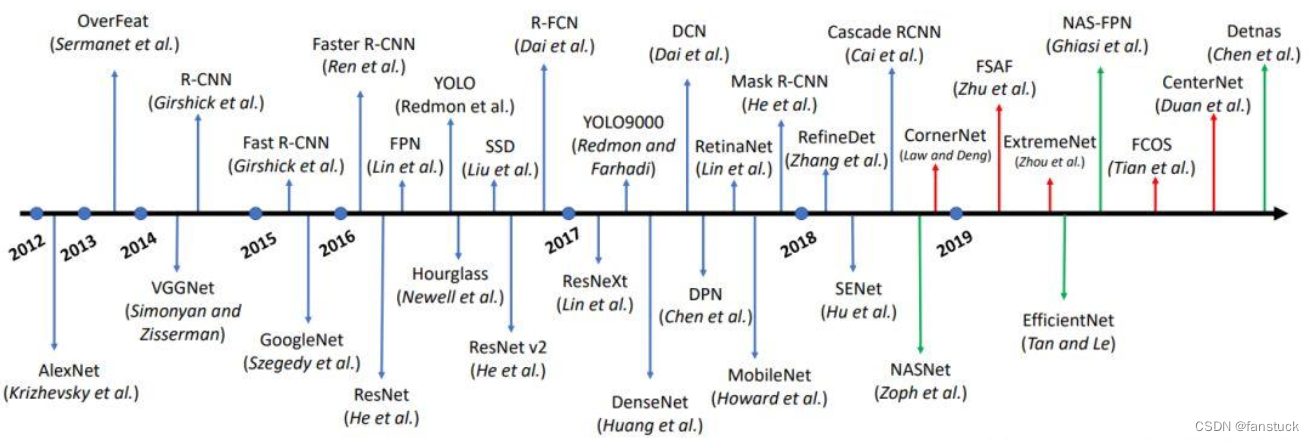
1. История развития алгоритмов обнаружения целей
Начало традиционных методов (1990-е - начало 2000-х годов):
- 1990-е годы: ранние методы обнаружения целей в основном полагались на разработанные вручную экстракторы функций (такие как функции Хаара, функции SIFT и т. д.) в сочетании с классификаторами на основе скользящих окон для определения местоположения цели.
- 2001: Алгоритм Виолы-Джонса обеспечивает эффективное обнаружение лиц за счет использования интегральных изображений и надежных классификаторов (Каскад классификаторов).
Методы машинного обучения (2000-е – начало 2010-х годов):
- 2000-е годы: появились методы использования алгоритмов машинного обучения (таких как машины опорных векторов, случайные леса и т. д.) для обнаружения целей, и выбор функций постепенно сместился от ручного проектирования к обучаемым функциям.
- 2005: Фельценсвальб и др. предложили метод обнаружения целей, основанный на сегментации изображений, который может обнаруживать цели разных размеров и форм.
Инновации в области глубокого обучения (с 2010-х годов по настоящее время):
- 2010-е: С развитием глубокого обучения, особенно с успехом сверточных нейронных сетей (CNN), обнаружение объектов добилось значительного прогресса.
- 2012: AlexNet выиграл конкурс по классификации изображений ImageNet, что ознаменовало рост глубокого обучения в области компьютерного зрения.
- 2013: RCNN (Сверточные нейронные сети на основе регионов) впервые применила сверточные нейронные сети для обнаружения целей, превратив задачу позиционирования цели в задачу предложения региона.
- 2015: Faster R-CNN предложил метод совместного обучения экстракторов целевых областей и целевых классификаторов, обеспечивая более высокую скорость и точность.
- 2016: Алгоритм YOLO (You Only Look Once) представил идею однократного прямого распространения для достижения обнаружения цели в реальном времени.
Детализированная и мультимодальная разработка обнаружения объектов:
- В последние годы исследователи начали на Меткое обнаружение целей (например, обнаружение позы человека, обнаружение частей объекта и т. д.) и мультимодальное обнаружение целей (в сочетании с、текст、голос и другая информация).
Обнаружение целей в режиме реального времени и на конечной стороне:
- С усовершенствованием аппаратных технологий и разработкой алгоритмов оптимизации обнаружение целей в реальном времени и на границах стало широко использоваться во встроенных устройствах и периферийных вычислениях.
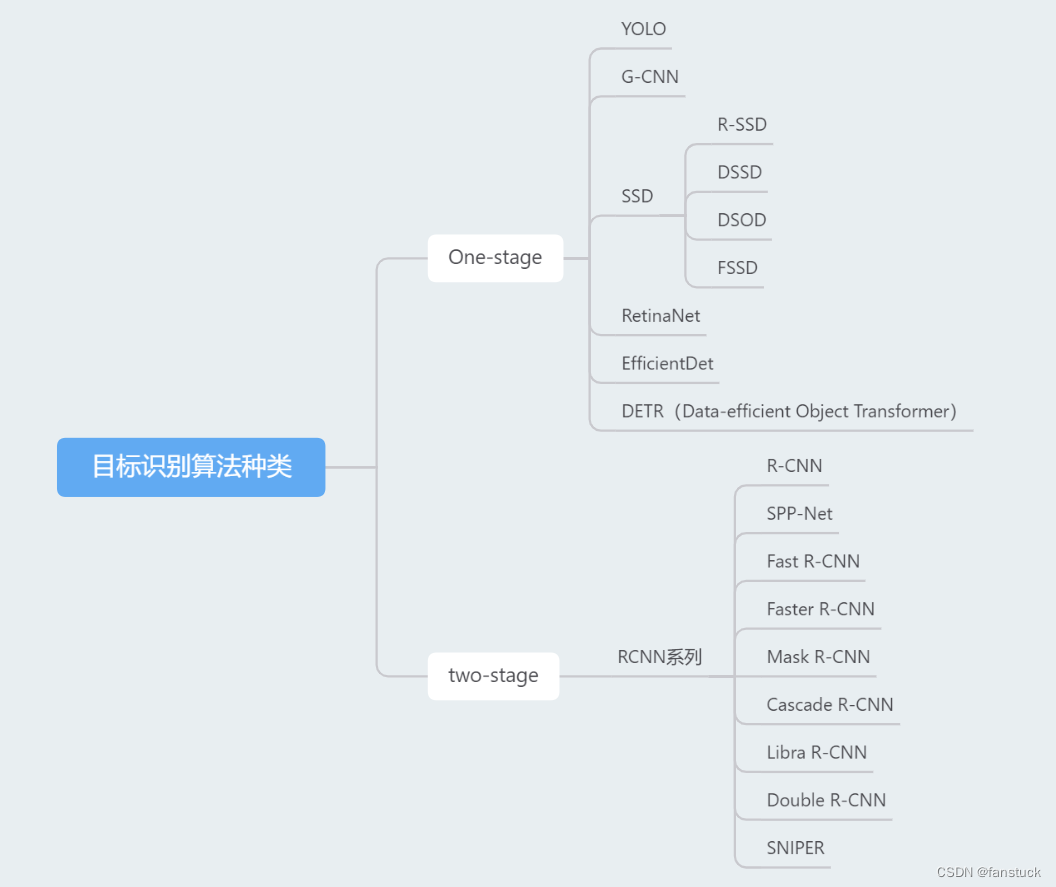
2. Категории алгоритмов обнаружения целей
Основные алгоритмы обнаружения целей условно делятся на две категории: одноэтапные и двухэтапные.,бывшийОдноступенчатый детектор объектов,Этот тип метода позволяет одновременно позиционировать и классифицировать цель.,Обычно плотные раздвижные окна или анкерные коробки (анкерные коробка) для обнаружения. ЙОЛО(Ты Only Look Один раз) и SSD (одиночный Shot Multibox Detector) — представительный однокаскадный детектор.
последнийДвухступенчатый детектор объектов,Этот тип метода сначала генерирует области-кандидаты целевой цели.,Затем каждый регион классифицируется и настраивается для получения окончательных результатов обнаружения.。Классические методы включают в себяRCNNряд(нравитьсяFast R-CNN、Faster Р-CNN). Такие методы обычно имеют более высокую точность, но могут принести в жертву некоторую скорость. Они обычно способны точно обнаруживать и идентифицировать цели. Выбор подходящего двухступенчатого детектора целей зависит от конкретного сценария применения и требований к производительности.
3. Алгоритм R-CNN
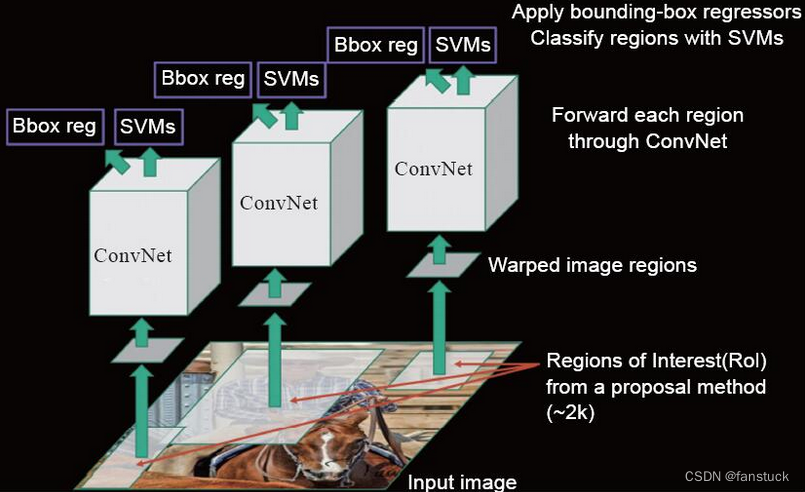
Можно сказать, что R-CNN является революционным алгоритмом обнаружения целей. Идеи последующих двухступенчатых детекторов целей в основном основаны на принципах алгоритма R-CNN. Процесс обучения R-CNN можно разделить на четыре этапа. В качестве примера мы возьмем обучение R-CNN на наборе данных ImageNet:
(1).Выберите потенциальных целевых кандидатов (ROI).
Во многих статьях, таких как объектность, выборочный поиск, предложения объектов, не зависящих от категории, и т. д., описывается этот алгоритм. R-CNN использует метод выборочного поиска для выбора 2000 потенциальных кадров-кандидатов ROI (область интереса).
ROI означает «Область интереса», то есть область интереса. ROI обычно относится к области изображения, которая, как считается, может содержать целевой объект. В двухэтапном детекторе объектов (например, в серии RCNN) потенциальные области интереса сначала генерируются через сеть предложений регионов (RPN). Эти регионы-кандидаты будут использоваться для последующей классификации и точной настройки местоположения. Выбор области интереса является ключевым шагом в процессе обнаружения цели. Он может помочь алгоритму сосредоточиться на области, которая может содержать цель, тем самым повышая эффективность и точность обнаружения.
(2). Экстрактор функций обучения.
Извлечение признаков можно выполнить с помощью AlexNet, VGGNet, GoogLeNet и т. д. Чтобы получить лучший экстрактор функций, он будет скорректирован на основе предварительно обученной модели ImageNet. Единственное изменение — изменить выходные данные 1000 категорий в ImageNet на выходные данные (C + 1), где C — фактическая потребность. количество прогнозируемых категорий, 1 — фоновая категория. Новые функции обучаются с использованием стохастического градиентного спуска, который аналогичен методу обучения обычных нейронных сетей, представленному в предыдущих главах.
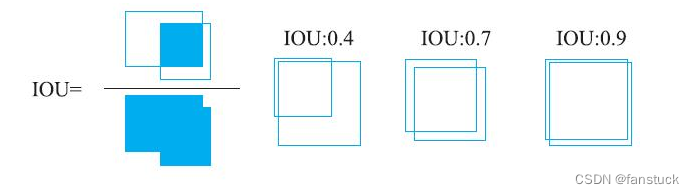
упомянутое обучение,Должны быть положительные образцы и отрицательные образцы.,Вот индикатор, используемый для измерения перекрытия двух прямоугольников: пересечение объединения на самом деле является пересечением площадей двух прямоугольников, разделенных объединением.,Обычно,Когда долговая расписка>=0.5час,Можно считать, что два прямоугольника в основном пересекаются.,Итак, в этой задаче,Предположим, что в двух прямоугольных ящиках,1 прямоугольник представляет рентабельность инвестиций,Другой представляет собой настоящую прямоугольную коробку.,Итак, когда окупаемость инвестиций и долговая расписка настоящей прямоугольной коробки>=0.5час则认为да正样本,Остальные образцы отрицательные.
Следует отметить, что необходимо отбирать отрицательные выборки, поскольку слишком малое количество выборок в обучающих данных приведет к квартальному дисбалансу положительных и отрицательных выборок. В конечном итоге на этом этапе получается экстрактор признаков сверточной нейронной сети, признаком которого является 4096-мерный вектор признаков.
(3). Обучите окончательный классификатор.
Инициатор R-CNN провел эксперимент по выбору оптимального порога долговой расписки и, наконец, выбрал прямоугольный прямоугольник с истинным значением в качестве положительного образца. Существуют правила выбора положительных и отрицательных образцов. И Fast R-CNN, и Faster R-CNN выбирают положительные и отрицательные образцы в зависимости от размера долговой расписки.
(4). Модель регрессии поезда.
Обучите модель регрессии для каждого класса, чтобы точно настроить отклонение между рентабельностью инвестиций и положением и размером реального прямоугольного блока:

Метод расчета индикатора IOU:
def calculate_iou(box1, box2):
# Формат box1 и box2: (xmin, ymin, xmax, ymax)
# Вычислить диапазон координат пересечения
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[2], box2[2])
y2 = min(box1[3], box2[3])
# Вычислить площадь пересечения
intersection_area = max(0, x2 - x1 + 1) * max(0, y2 - y1 + 1)
# Вычислить площадь двух ограничивающих рамок
area_box1 = (box1[2] - box1[0] + 1) * (box1[3] - box1[1] + 1)
area_box2 = (box2[2] - box2[0] + 1) * (box2[3] - box2[1] + 1)
# Вычислить площадь союза
union_area = area_box1 + area_box2 - intersection_area
# Рассчитать стоимость долговой расписки
iou = intersection_area / union_area
return iouСтадию прогнозирования можно разделить на:
- Используйте метод выборочного поиска, чтобы сначала выбрать 2000 ROI.
- Все ROI корректируются в соответствии с входным размером, необходимым для сети извлечения признаков, и извлечение признаков выполняется для получения 2000 4096-мерных векторов признаков, соответствующих 2000 ROI.
- Введите 2000 векторов признаков в SVM соответственно, чтобы получить прогнозируемую категорию каждой рентабельности инвестиций.
- Точная настройка положения рентабельности инвестиций с помощью регрессионной сети
- Наконец, метод немаксимального подавления (NMS) используется для объединения ROI одной и той же категории для получения окончательного результата обнаружения. Принцип NMS заключается в получении оценки (доверительности) прямоугольного ящика каждого человека. Если долговая расписка двух прямоугольных ящиков превышает указанное значение, будет сохранен только прямоугольный ящик с большей оценкой.
Все еще видно, что у R-CNN есть много проблем. Например, обучение в соответствии с описанным выше процессом займет много времени.
4.Fast R-CNN
Быстрый R-CNN, предложенный Фиршиком и др. в 2015 году, который очень умно решает несколько основных проблем RCNN.
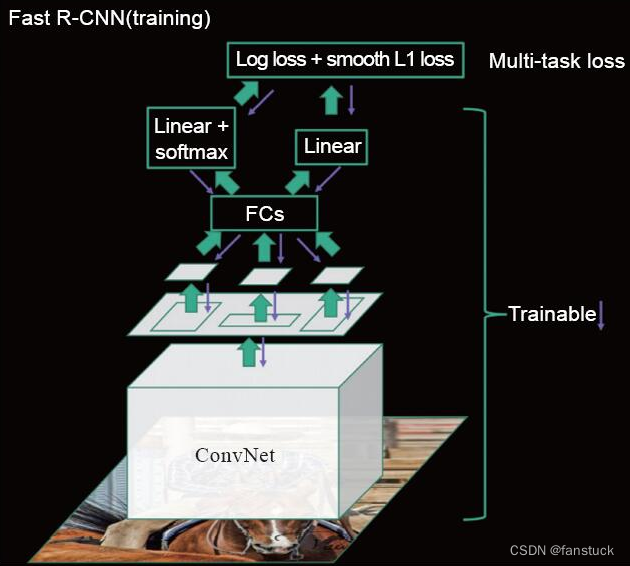
1) Непосредственно введите все изображение и ROI в полностью сверточную CNN, чтобы получить векторный слой и ROI, соответствующий функциональному слою (информация об ROI векторного слоя может быть получена из его геометрического положения плюс формулы координат свертки).
2) Подобно R-CNN, чтобы обеспечить равномерное обучение ROI разных размеров, Fast R-CNN настраивает каждую область-кандидат на указанное M * N с помощью метода объединения. В это время скорректированный векторный слой будет ROI. служит обучающими данными для классификатора. В отличие от R-CNN, задачи классификации и регрессии объединяются для обучения, таким образом каскадируя весь процесс. Диаграмма объединения Fast R-CNN показана на рисунке 9-11. То есть все изображение сначала обрабатывается с помощью сверточной нейронной сети, а затем позиция, соответствующая рентабельности инвестиций, находится на слое объектов и извлекается, а затем извлекается. полученная рентабельность инвестиций объединяется (здесь существует множество методов объединения). После объединения все 2000 обучающих данных M*N проходят через полностью связанный слой и две головки соответственно: классификацию softmax и регрессию L2. Окончательная функция потерь представляет собой взвешенную сумму функций потерь классификации и регрессии. Таким образом, можно добиться непрерывного обучения.
Быстрый R-CNN значительно повышает скорость обучения и прогнозирования обнаружения целей, как показано на рисунке 9-12. С картинки:
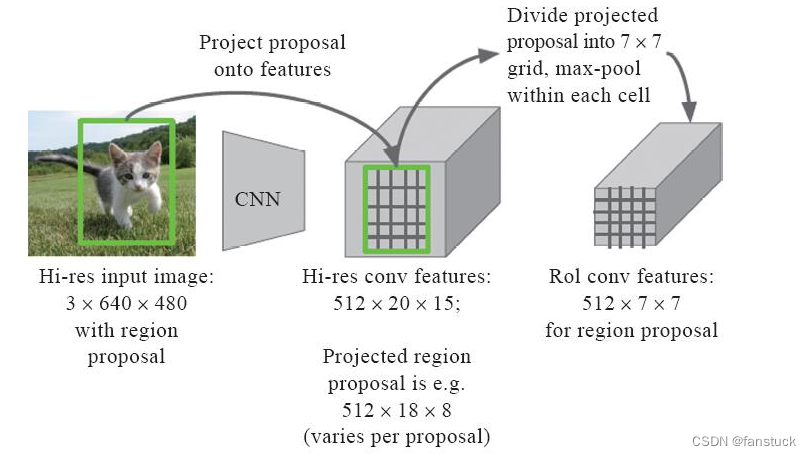
Мы видим, что Fast R-CNN сокращает время обучения с 84 часов R-CNN до 8,75 часов, а среднее общее время прогнозирования каждого изображения сокращается с 49 секунд до 2,3 секунды. С картинки:
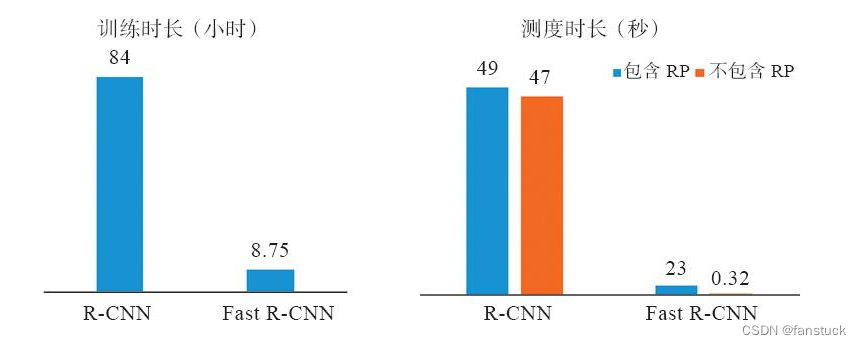
Мы также можем видеть, что из 2,3 секунды, прогнозируемых Fast R-CNN, реальный процесс прогнозирования составляет всего 0,32 секунды, в то время как предложение региона занимает подавляющее большинство времени.
5.YOLO
Поскольку в серии алгоритмов R-CNN необходимо получить большое количество предложений, но между предложениями существует большое перекрытие, это потребует много повторной работы. YOLO [5] меняет идею прогнозирования на основе предложений, делит входное изображение на небольшие сетки S*S, делает прогнозы в каждой маленькой сетке и, наконец, объединяет результаты.
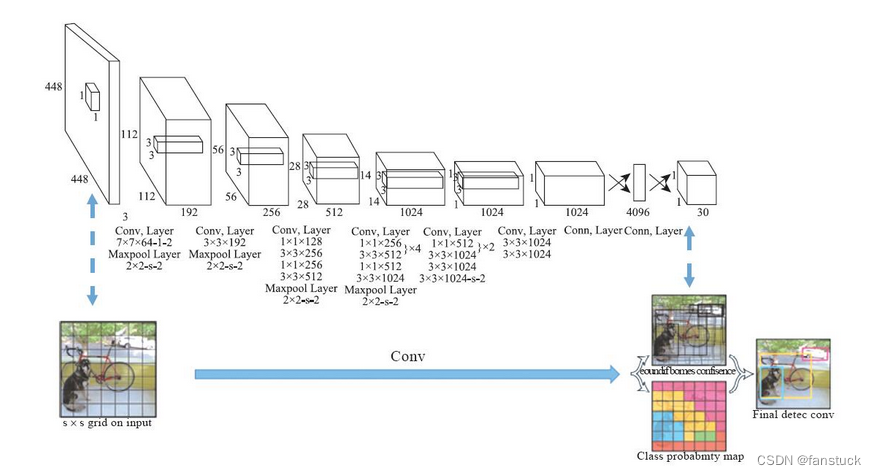
YOLOv1(You Only Look Once)
Шаги и принципы:
- Разделить изображение на сетку: YOLOv1 делит входное изображение на S x S ячейки сетки. Каждая ячейка сетки отвечает за обнаружение объектов в этой области.
- Создание прогнозов: Каждая ячейка сетки отвечает за прогноз B Ограничительная рамка Box) и достоверность каждой ограничивающей рамки (Confidence Оценка) и вероятность класса.
- Вычислить положение ограничивающей рамки: Информация о местоположении ограничивающей рамки представлена координатами, шириной и высотой относительно ячейки сетки. Эта информация преобразуется сигмовидной функцией, чтобы гарантировать, что они находятся в диапазоне от 0 до 1.
- Рассчитать достоверность и вероятности классов: Достоверность указывает, существует ли целевой объект внутри ограничивающего прямоугольника, а вероятность категории указывает, к какой категории принадлежит объект.
- Вычислить функцию потерь: YOLOv1 использует комплексную функцию потерь для балансировки прогнозов достоверности, местоположения и вероятности класса, которая включает потерю классификации, потерю локализации и потерю уверенности.
- Немаксимальное подавление (NMS): Используйте немаксимальное подавление, чтобы удалить большие перекрывающиеся ограничивающие рамки, сохраняя наиболее точные прогнозы.
YOLOv2/v3(YOLO9000)
YOLOv2 (Darknet-19) и YOLOv3 — это усовершенствованные версии серии YOLO, вносящие некоторые важные улучшения:
- Сеть Даркнет-19:YOLOv2Представляем более глубокую нейронную сеть(Darknet-19)как экстрактор функций,Улучшенные возможности выражения функций.
- Anchor Boxes:Представлены якорные коробки(Anchor Концепция Boxes позволяет модели лучше адаптироваться к целям разных масштабов и соотношений сторон.
- Многомасштабное обнаружение:YOLOv3В выходном слое используются три карты объектов разного масштаба для повышения эффективности обнаружения небольших объектов.。
- YOLO9000:YOLOv2иv3Представлено обнаружение нескольких категорий,Возможность обнаружения по более широкому спектру категорий.
YOLOv4/v5
- Магистральная сеть:YOLOv4Представлена более мощная сеть извлечения признаков.,Например, CSPDarknet53.
- Улучшения данных и методы:引入了一ряд的数据增强и训练技巧,Производительность модели еще больше улучшена.
- YOLOv5:YOLOv5даYOLOряд的最新版本,Представлены некоторые инновационные разработки и оптимизация архитектуры модели.
В целом, серия алгоритмов YOLO достигает цели обнаружения целей в реальном времени путем преобразования задачи обнаружения целей в одно прямое распространение. Благодаря обновлениям версий и усовершенствованию алгоритмов серия YOLO продолжает совершать прорывы в производительности и скорости, становясь одним из важных направлений исследований в области обнаружения целей.
Развитие технологии обнаружения целей неотделимо от неустанных усилий и инноваций бесчисленных исследователей, а также от развития аппаратных технологий и использования большого количества наборов аннотированных данных.
Это все по этому вопросу. Меня зовут фанат. Если у вас есть вопросы, оставьте сообщение для обсуждения. Увидимся в следующем выпуске.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
