Комплексный практический пример: подробное руководство по прогнозированию спроса на совместное использование велосипедов (с пошаговым описанием кода на Python)
представлять
Анализ спроса на совместные велосипеды относится к изучению факторов, влияющих на использование услуг совместного использования велосипедов и спроса на велосипеды в разное время и в разных местах. Цель этого анализа — понять закономерности и тенденции использования велосипедов и сделать прогноз относительно будущего спроса. В этой статье будет рассмотрено, как статистические методы машинного обучения анализируют данные.
В этой статье будет использоваться небольшая часть этого набора данных и основное внимание будет уделено только его особенностям. Обратите внимание, что при таком небольшом наборе данных вероятность неточностей высока. Вы можете использовать полный набор данных для анализа.
Цели обучения:
- Другие важные факторы, основанные на исторических данных.,Точно предскажите количество взятых напрокат велосипедов в определенный период времени и в определенном месте.
- Выявите и проанализируйте ключевые факторы, влияющие на спрос на прокат велосипедов, такие как погодные условия, праздники и мероприятия.
- Использовать технические разработки, такие как регрессионный анализ, анализ временных рядов и алгоритм машинного обучения для оценки прогноза. Модель, которая может эффективно прогнозировать спрос на прокат велосипедов.
- Используйте прогнозы для оптимизации запасов и ресурсов велосипедов, гарантируя, что компании по совместному использованию велосипедов смогут удовлетворить спрос клиентов и максимизировать доход.
- Непрерывный мониторинг и оценка точности прогнозов,идеальная модель,Повысьте точность и надежность.
Набор данных на Kaggle: https://www.kaggle.com/c/bike-sharing-demand
Что такое прогнозирование спроса на общие велосипеды?
Прогнозирование спроса на велопрокат предназначено для того, чтобы предоставить компаниям, занимающимся велопрокатом, информацию и инструменты, необходимые для принятия решений на основе данных и эффективного управления операциями.
Факторы, которые часто учитываются при анализе спроса на совместное использование велосипедов, включают погодные условия, сезонность, дни недели, праздники и события. Демографическая информация о пользователях, такая как возраст, пол и доход. Его можно использовать для понимания моделей использования.
Методы, используемые для анализа спроса на общие велосипеды, включают анализ временных рядов, регрессионный анализ, алгоритмы машинного обучения и другие статистические модели. Компании по совместному использованию велосипедов могут использовать результаты аналитики для оптимизации своих операций, дистрибуции, стратегий ценообразования и маркетинговых кампаний. Кроме того, полученные результаты могут помочь градостроителям при разработке инфраструктуры и политики, связанной с велосипедами.
Почему стоит выбрать систему совместного использования велосипедов?
В последние годы системы совместного использования велосипедов становятся все более популярными благодаря своим многочисленным преимуществам, в том числе:
- Доступный и устойчивый транспорт:совместное использование велосипедовсистема Обеспечивает доступное и устойчивое средство передвижения.,Особенно для коротких поездок. Они являются недорогой альтернативой личному велосипеду.,Помогите снизить зависимость от личных и совместных автомобилей.,тем самым оказывая положительное влияние на окружающую среду.
- Здоровье и комфорт:совместное использование велосипедовсистема Поощряйте физическую активностьиупражнение,Положительное влияние на здоровье и комфорт. Регулярная езда на велосипеде может помочь снизить риск сердечно-сосудистых заболеваний, инсульта и других хронических заболеваний.
- Удобство:общие велосипедысистема Часто расположены в густонаселенных городских районах.,Он стал удобным видом транспорта для путешествий на короткие расстояния. Они легко доступны,Это гибкий и удобный выбор для пассажиров и туристов.
- Уменьшите пробки на дорогах:совместное использование велосипедовсистема Может предоставить альтернативные варианты транспорта для коротких поездок.,Это помогает уменьшить пробки на дорогах. Это окажет положительное влияние на городскую мобильность.
Таким образом, системы совместного использования велосипедов обеспечивают множество преимуществ, включая доступный и устойчивый транспорт, здоровье и комфорт, удобство, снижение заторов на дорогах, а также туризм и экономическое развитие. Эти преимущества способствовали популярности систем проката велосипедов во многих городах по всему миру.
постановка задачи
постановка для нужд велопроката задачи Это зависит от погоды、день неделииодин деньвтакие факторы, как время, чтобы предсказать данное время изсовместное использование велосипедовсистема Количество арендованных велосипедов。Цель: построить прогноз.Модель,Спрос на аренду велосипедов можно точно предсказать,оптимизировать конфигурацию велосипеда,Повысьте общую эффективность совместного использования велосипедов.
постановка задачи может включать в себя ответы на конкретные вопросы, например:
- Каков ожидаемый спрос на велосипеды в часы пик, в будние или выходные дни?
- Как погода (например, ветер, температура, осадки) влияет на спрос на прокат велосипедов?
- Есть ли определенные места или маршруты, где спрос на велосипеды выше или ниже?
- Как мы можем оптимизировать общие велосипеды для удовлетворения меняющихся потребностей и минимизировать эксплуатационные расходы?
- Можно ли расширить или улучшить систему совместного использования велосипедов?,Чтобы лучше удовлетворять потребности пользователей и продвигать устойчивый транспорт?
Постановка задачи Анализ спроса на общие велосипеды обычно включает в себя прогнозирование спроса на аренду велосипедов и оптимизацию распределения велосипедов для повышения эффективности и устойчивости системы общих велосипедов.
Руководство компании надеется:
- Использовать Доступные аргументы создают спрос на общие велосипеды. Модель.
- Модель, созданная с помощью использования, учитывает динамику спроса на рынке.
Чтение и понимание данных
Чтобы построить общий прогноз спроса на велосипеды, мы должны сначала Чтение и понимание данные. Ключевыми этапами этого процесса являются загрузка, исследование, очистка, предварительная обработка и Предварительный просмотр. данные. Выполнив эти шаги,аналитики данных могут получить более глубокое понимание данных,и определить любые проблемы, которые необходимо решить, прежде чем строить модель прогноза спроса на совместное использование велосипедов. Это помогает гарантировать точность и надежность модели.,Это имеет решающее значение для оптимизации операций по прокату велосипедов.
import pandas as pd
bikeshare_df = pd.read_csv("day.csv")
print(bikeshare_df.head())
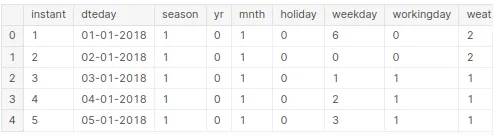
bike_sharing.info()
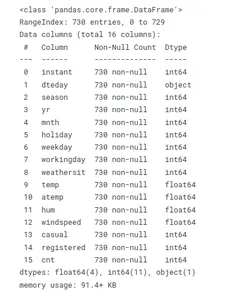
bike_sharing.describe()
Визуализация данных
Визуализация данных — важный шаг в процессе прогнозирования спроса на совместное использование велосипедов. Это может помочь выявить закономерности и тенденции, которые могут быть не сразу очевидны в необработанных данных.
import matplotlib.pyplot as plt
import seaborn as sns
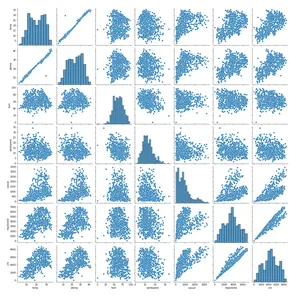
#Plotting pairplot of all the numeric variables
sns.pairplot(bike_sharing[["temp","atemp","hum","windspeed","casual","registered","cnt"]])
plt.show()
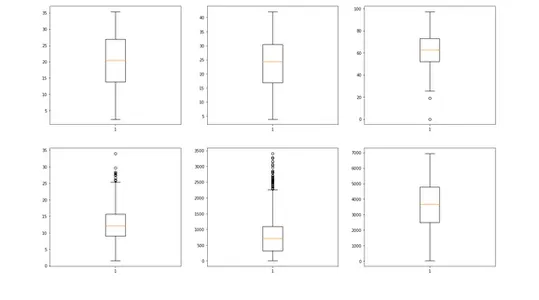
#Plotting box plot of continuous variables
plt.figure(figsize=(20, 12))
plt.subplot(2,3,1)
plt.boxplot(bike_sharing["temp"])
plt.subplot(2,3,2)
plt.boxplot(bike_sharing["atemp"])
plt.subplot(2,3,3)
plt.boxplot(bike_sharing["hum"])
plt.subplot(2,3,4)
plt.boxplot(bike_sharing["windspeed"])
plt.subplot(2,3,5)
plt.boxplot(bike_sharing["casual"])
plt.subplot(2,3,6)
plt.boxplot(bike_sharing["registered"])
plt.show()
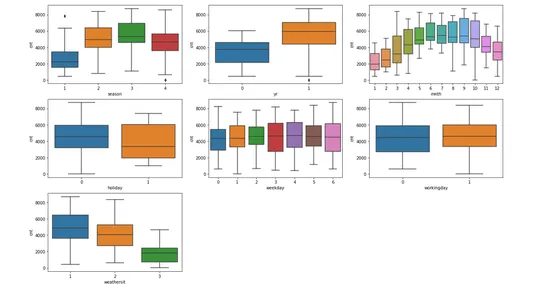
Визуализация категориальных переменных
#Plotting box plot of categorical variables
plt.figure(figsize=(20, 12))
plt.subplot(3,3,1)
sns.boxplot(x = 'season', y = 'cnt', data = bike_sharing)
plt.subplot(3,3,2)
sns.boxplot(x = 'yr', y = 'cnt', data = bike_sharing)
plt.subplot(3,3,3)
sns.boxplot(x = 'mnth', y = 'cnt', data = bike_sharing)
plt.subplot(3,3,4)
sns.boxplot(x = 'holiday', y = 'cnt', data = bike_sharing)
plt.subplot(3,3,5)
sns.boxplot(x = 'weekday', y = 'cnt', data = bike_sharing)
plt.subplot(3,3,6)
sns.boxplot(x = 'workingday', y = 'cnt', data = bike_sharing)
plt.subplot(3,3,7)
sns.boxplot(x = 'weathersit', y = 'cnt', data = bike_sharing)
plt.show()
Подготовка данных
Подготовка данных — ключевой шаг в прогнозировании спроса на общие велосипеды.,Потому что это включает в себя очистку, преобразование и организацию данных, чтобы сделать их пригодными для анализа. Подготовив данные таким образом,Аналитики могут гарантировать, что данные подходят для анализа.,И в данныхв любые отклонения или ошибки можно устранить. Это приводит к более точным и надежным прогнозам Модель,Помогаем компаниям по прокату велосипедов оптимизировать операции и лучше удовлетворять потребности клиентов.
Удалите ненужные столбцы: мгновенный, дневной, случайный и зарегистрированный.
- Instant – порядковый номер строки
- день дня – не требуется, поскольку столбцы года и месяца уже существуют.
- случайный – эту переменную невозможно предсказать.
- зарегистрировано — эту переменную невозможно предсказать.
bike_sharing.drop(columns=["instant","dteday","casual","registered"],axis=1,inplace =True)
bike_sharing.head()

фиктивная переменная
season_type = pd.get_dummies(bike_sharing['season'], drop_first = True)
season_type.rename(columns={2:"season_summer", 3:"season_fall", 4:"season_winter"},inplace=True)
season_type.head()
weather_type = pd.get_dummies(bike_sharing['weathersit'], drop_first = True)
weather_type.rename(columns={2:"weather_mist_cloud", 3:"weather_light_snow_rain"},inplace=True)
weather_type.head()
#Concatenating new dummy variables to the main dataframe
bike_sharing = pd.concat([bike_sharing, season_type, weather_type], axis = 1)
#Dropping columns season & weathersit since we have already created dummies for them
bike_sharing.drop(columns=["season", "weathersit"],axis=1,inplace =True)
#Analysing dataframe after dropping columns
bike_sharing.info()
Создайте производную переменную для категориальной переменной месяца.
#Creating year_quarter derived columns from month columns.
#Note that last quarter has not been created since we need only 3 columns to define the four quarters.
bike_sharing["Quarter_JanFebMar"] = bike_sharing["mnth"].apply(lambda x: 1 if x<=3 else 0)
bike_sharing["Quarter_AprMayJun"] = bike_sharing["mnth"].apply(lambda x: 1 if 4<=x<=6 else 0)
bike_sharing["Quarter_JulAugSep"] = bike_sharing["mnth"].apply(lambda x: 1 if 7<=x<=9 else 0)
#Dropping column mnth since we have already created dummies.
bike_sharing.drop(columns=["mnth"],axis=1,inplace =True)
bike_sharing["weekend"] = bike_sharing["weekday"].apply(lambda x: 0 if 1<=x<=5 else 1)
bike_sharing.drop(columns=["weekday"],axis=1,inplace =True)
bike_sharing.drop(columns=["workingday"],axis=1,inplace =True)
bike_sharing.head()
#Analysing dataframe after dropping columns weekday & workingday
bike_sharing.info()

#Plotting correlation heatmap to analyze the linearity between the variables in the dataframe
plt.figure(figsize = (16, 10))
sns.heatmap(bike_sharing.corr(), annot = True, cmap="Greens")
plt.show()
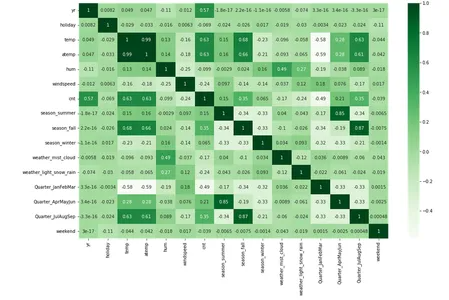
#Dropping column temp since it is very highly collinear with the column atemp.
#Further,the column atemp is more appropriate for modelling compared to column temp from human perspective.
bike_sharing.drop(columns=["temp"],axis=1,inplace =True)
bike_sharing.head()
Разделите данные на обучающие и тестовые наборы.
Это ключевой шаг в прогнозировании спроса на общие велосипеды. Это позволяет аналитикам оценить эффективность своей модели прогноза на основе невидимых данных. Общий подход состоит в том, чтобы обучить Модель на исторических данных, а затем протестировать производительность Модели на отдельном наборе резервных данных.
#Importing library
from sklearn.model_selection import train_test_split
# We specify this so that the train and test data set always have the same rows, respectively
np.random.seed(0)
bike_sharing_train, bike_sharing_test = train_test_split(bike_sharing, train_size = 0.7, test_size = 0.3, random_state = 100)
Кадр обучающих данных масштабируется с использованием функции масштабирования MinMax после сегментации для достижения оптимальных бета-коэффициентов для всех функций.
#importing library
from sklearn.preprocessing import MinMaxScaler
#assigning variable to scaler
scaler = MinMaxScaler()
# Applying scaler to all the columns except the derived and 'dummy' variables that are already in 0 & 1.
numeric_var = ['atemp','hum','windspeed','cnt']
bike_sharing_train[numeric_var] = scaler.fit_transform(bike_sharing_train[numeric_var])
# Analysing the train dataframe after scaling
bike_sharing_train.head()
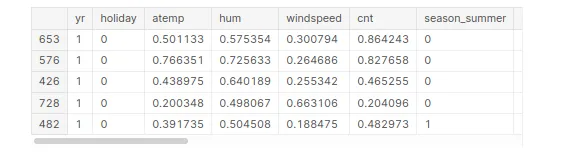
Разделив данные на обучающие и тестовые наборы, аналитики могут оценить эффективность своих прогнозных моделей на невидимых данных и убедиться, что модели устойчивы и надежны. Это может помочь компаниям по прокату велосипедов оптимизировать операции и лучше удовлетворять потребности клиентов.
y_train = bike_sharing_train.pop('cnt')
X_train = bike_sharing_train
print (y_train.head())
print (X_train.head())

Постройте линейную модель
Построение линейной модели для прогнозирования спроса на общие велосипеды включает в себя создание модели, которая использует линейную регрессию для прогнозирования спроса на прокат велосипедов на основе набора входных переменных.
Модель линейной регрессии обучается с использованием обучающего набора, а входные переменные используются для прогнозирования целевой переменной (спрос на аренду велосипедов). Модель оптимизирована для минимизации ошибки между прогнозируемым и фактическим спросом в обучающем наборе.
Используйте функцию LinearRegrade и рекурсивное исключение признаков (RFE) в SciKit Learn:
# Importing RFE and LinearRegression
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
# Running RFE with the output number of the variable equal to 12
lm = LinearRegression()
lm.fit(X_train, y_train)
rfe = RFE(lm, 12) # running RFE
rfe = rfe.fit(X_train, y_train)
list(zip(X_train.columns,rfe.support_,rfe.ranking_))

Построив линейную модель для прогнозирования спроса на совместные велосипеды, аналитики могут разработать простую, но эффективную систему прогнозирования для оптимизации операций с совместными велосипедами и повышения удовлетворенности клиентов.
Однако стоит отметить, что линейные модели могут иметь ограничения при определении более сложных закономерностей и взаимосвязей в данных, поэтому другие методы моделирования, такие как деревья решений или нейронные сети, могут делать более точные прогнозы.
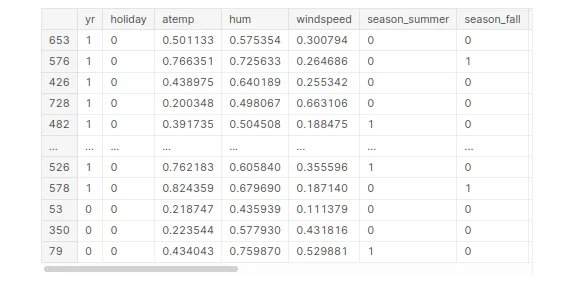
# Creating X_test dataframe with RFE selected variables
X_train_rfe = X_train[columns_rfe]
X_train_rfe
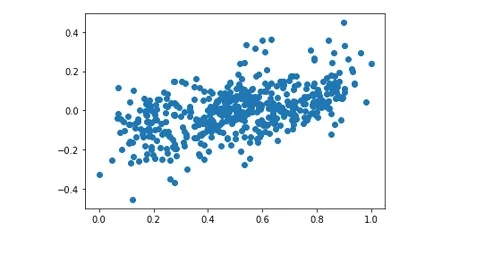
Остаточный анализ обучающих данных
Остаточный анализ — важный шаг в оценке эффективности линейных моделей для прогнозирования спроса на совместное использование велосипедов. Остатки — это разница между прогнозируемым спросом и фактическим спросом, и анализ этих остатков может помочь выявить любые закономерности или отклонения в прогнозах модели.
#using the final model lr5 on train data to predict y_train_cnt values
y_train_cnt = lr5.predict(X_train_lr5)
# Plotting the histogram of the error terms
fig = plt.figure()
sns.distplot((y_train - y_train_cnt), bins = 20)
fig.suptitle('Error Terms', fontsize = 20)
plt.xlabel('Errors', fontsize = 18)

plt.scatter(y_train,(y_train - y_train_cnt))
plt.show()
Прогнозирование с использованием окончательной модели lr5
Чтобы спрогнозировать с использованием окончательной линейной модели для прогнозирования спроса на долю велосипедов (lr5), вы предоставляете значения для входных переменных и используете модель для создания прогнозов для целевой переменной (спрос на аренду велосипедов).
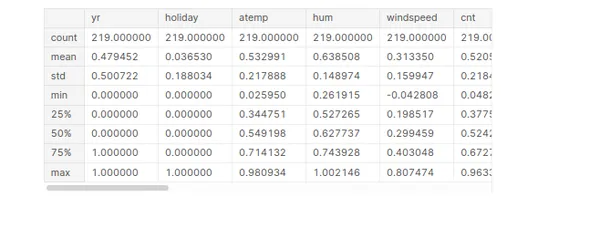
#Applying the scaling on the test sets
numeric_vars = ['atemp','hum','windspeed','cnt']
bike_sharing_test[numeric_vars] = scaler.transform(bike_sharing_test[numeric_vars])
bike_sharing_test.describe()
Разделен на X_test и y_test.
y_test = bike_sharing_test.pop('cnt')
X_test = bike_sharing_test
# Adding constant variable to test dataframe
X_test_lr5 = sm.add_constant(X_test)
# Updating X_test_lr5 dataframe by dropping the variables as analyzed from the above models
X_test_lr5 =X_test_lr5.drop(["atemp", "hum", "season_fall", "Quarter_AprMayJun", "weekend","Quarter_JanFebMar"], axis = 1)
# Making predictions using the fifth model
y_pred = lr5.predict(X_test_lr5)
Оценка модели
Оценка Модель является ключевым шагом в оценке эффективности прогнозирования спроса на совместно используемые велосипеды. Модель. Используйте различные метрики для оценки производительности модели, включая среднюю абсолютную ошибку. (MAE), среднеквадратическая ошибка (RMSE) и коэффициент детерминации (R квадрат).
# Plotting y_test and y_pred to understand the spread
fig = plt.figure()
plt.scatter(y_test, y_pred)
fig.suptitle('y_test vs y_pred', fontsize = 20)
plt.xlabel('y_test', fontsize = 18)
plt.ylabel('y_pred', fontsize = 16)
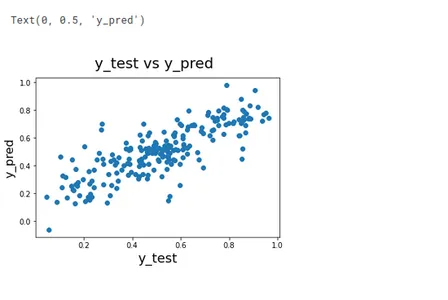
Для оценки производительности вашей модели следует использовать такие показатели, как MAE, RMSE и R-квадрат. MAE и RMSE измеряют средний размер ошибки между прогнозируемыми и фактическими значениями. R-квадрат измеряет долю дисперсии целевой переменной, которая объясняется входными переменными.
#importing library and checking mean squared error
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_test, y_pred)
print('Mean_Squared_Error :' ,mse)
#importing library and checking R2
from sklearn.metrics import r2_score
r2_score(y_test, y_pred)


в заключение
Это исследование направлено на улучшение деятельности по совместному использованию велосипедов Capital Bikeshare и поддержку изменения городских транспортных систем. Комплексный исследовательский анализ общедоступных данных помогает нам понять и проанализировать основные закономерности и характеристики сетей совместного использования велосипедов, а также использовать эти данные для достижения результатов, основанных на данных.
Мы проанализировали рост популярности велосипедов для совместного использования в период с 2011 по 2012 год, а также влияние сезонных и повседневных факторов на модели катания. Влияние сезонных и погодных параметров было изучено, чтобы понять структуру пешеходного движения в Вашингтоне, округ Колумбия. Анализ данных рейсов помогает понять особенности районов расположения станций.
Учитывая эти следствия, мы можем предложить следующее:
- Большинство велосипедов напрокат используются для ежедневных поездок на работу и в колледж. Поэтому CaBi следует открыть больше станций рядом с этими достопримечательностями, чтобы охватить своих ключевых клиентов.
- При планировании большего количества станций проката велосипедов необходимо учитывать часы пиковой нагрузки: с 7 до 9 утра и с 17 до 18 часов.
- Котировки не должны быть фиксированными. Вместо этого следует поощрять использование велосипедов осенью и зимой в соответствии с сезонными изменениями.
- Данные о наиболее часто используемых маршрутах могут помочь в строительстве дорог/полос, предназначенных для велосипедистов.
- Поскольку в ночное время использование велосипеда снижается, лучше проводить техническое обслуживание велосипеда ночью. Уборка части велосипедов с улиц в ночное время не создаст проблем для клиентов.
- Превратите зарегистрированных клиентов выходного дня в обычных клиентов, предлагая им скидки и купоны.
Часто задаваемые вопросы
Q1. Что такое прогнозирование спроса на общие велосипеды?
A. Прогнозирование спроса на совместные велосипеды относится к процессу прогнозирования количества совместных прокатов велосипедов в течение определенного периода времени, распределения вспомогательных ресурсов и оптимизации системы.
Вопрос 2. Какова тенденция совместного использования велосипедов?
Ответ: Тенденция совместного использования велосипедов неуклонно растет во всем мире: все больше и больше городов реализуют программы совместного использования велосипедов для продвижения экологически чистого транспорта и уменьшения заторов на дорогах.
В3. Можно ли зарабатывать деньги, обмениваясь велосипедами?
Ответ: Рентабельность системы совместного использования велосипедов может варьироваться в зависимости от таких факторов, как спрос пользователей, эксплуатационные расходы, стратегии ценообразования и партнерские отношения с местными предприятиями. Тщательное планирование и эффективное управление имеют решающее значение для долгосрочной прибыльности.
Вопрос 4. Почему совместные велосипеды так популярны?
Ответ: Совместное использование велосипедов популярно по нескольким причинам. Он обеспечивает удобный и гибкий вид транспорта, способствует физической активности и здоровому развитию, снижает выбросы углекислого газа, уменьшает заторы на парковках и обеспечивает доступную альтернативу поездкам на короткие расстояния по городу.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
