Комплексный источник данных случая (2) в реальном времени на основе Flume+Kafka+Hbase+Flink+FineBI
04: Источник данных
Цель:Понимание формата источников данных и создание данных моделирования
путь
- step1:Формат данных
- step2:Генерация данных
осуществлять
Формат данных
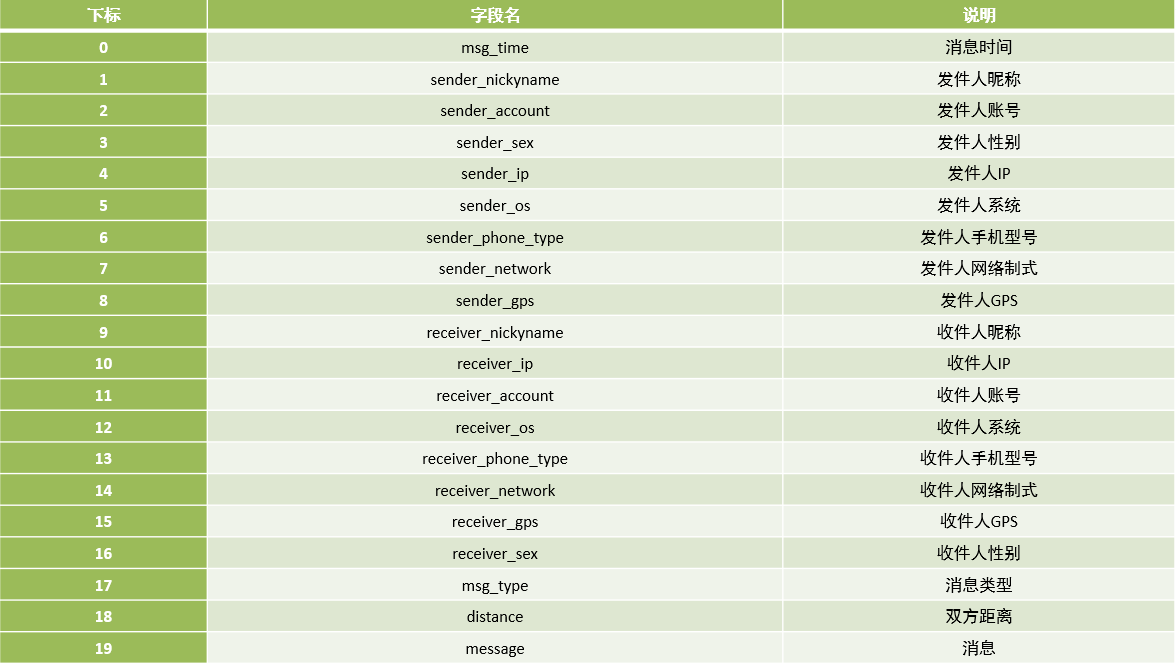
время сообщения | Ник отправителя | Счет отправителя | Пол отправителя | IP-адрес отправителя | система отправителя | Модель мобильного телефона отправителя | Формат сети отправителя | Отправитель GPS | Ник получателя | IP-адрес получателя | Счет получателя | Система получателя | Модель мобильного телефона получателя | Формат сети получателя | GPS получателя | Пол получателя | Тип сообщения | Расстояние между двумя сторонами | информация |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
msg_time | sender_nickyname | sender_account | sender_sex | sender_ip | sender_os | sender_phone_type | sender_network | sender_gps | receiver_nickyname | receiver_ip | receiver_account | receiver_os | receiver_phone_type | receiver_network | receiver_gps | receiver_sex | msg_type | distance | message |
2020/05/08 15:11:33 | Гу Бойи | 14747877194 | мужской | 48.147.134.255 | Android 8.0 | Сяоми Редми К30 | 4G | 94.704577,36.247553 | Лейю | 97.61.25.52 | 17832829395 | IOS 10.0 | Apple iPhone 10 | 4G | 84.034145,41.423804 | женский | TEXT | 77.82KM | Блуждание по краям света,Пастух переплывает реку. Поклоняюсь перед троном Будды,Я просто хочу провести сто лет вместе. |
Генерация данных
Создать исходный каталог файлов
mkdir /export/data/momo_initЗагрузите программу данных моделирования
cd /export/data/momo_init
rz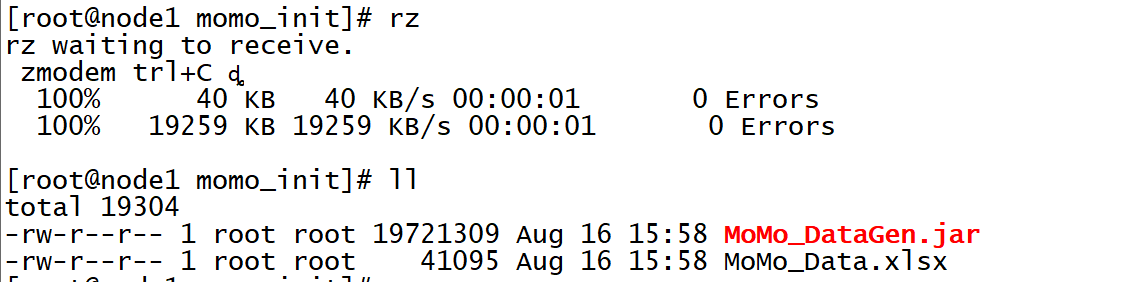
Создать каталог данных моделирования
mkdir /export/data/momo_dataЗапустите программу для генерации данных
грамматика
java -jar /export/data/momo_init/MoMo_DataGen.jar оригинальныйданныепуть моделированиеданныепуть Случайно генерировать интервал данных, мс времяТест: генерировать фрагмент данных каждые 500 мс.
java -jar /export/data/momo_init/MoMo_DataGen.jar \
/export/data/momo_init/MoMo_Data.xlsx \
/export/data/momo_data/ \
500Результат: создается файл данных моделирования MOMO_DATA.dat, а разделитель полей в каждой части данных равен \001.
краткое содержание
- Понимание формата источников данных и создание данных моделирования
05: Техническая архитектура и выбор технологий
- Цель:Освоить техническую архитектуру и выбор технологий для случаев реального времени
- путь
- step1:нуждатьсяанализировать
- step2:Выбор технологии
- step3:Техническая архитектура
- осуществлять
- нуждатьсяанализировать
- Автономные вычисления с хранилищем
- Предоставить оффлайн Т + 1статистикаанализировать
- Обеспечить мгновенный запрос Оффлайнданных
- вычисления в режиме реального времени
- Предоставить в реальном временистатистикаанализировать
- Автономные вычисления с хранилищем
- Выбор технологии
- Оффлайн
- данныеколлекция:Flume
- Автономное хранилище: Hbase
- Оффлайнанализировать:Hive:Сложные расчеты
- Мгновенный запрос: Phoenix: эффективные запросы
- в реальном времени
- данныеколлекция:Flume
- в реальном временихранилище:Kafka
- в реальном временивычислить:Flink
- в реальном время Приложение: MySQL + FineBI или Redis + JavaВеб Визуализация
- Оффлайн
- Техническая архитектура
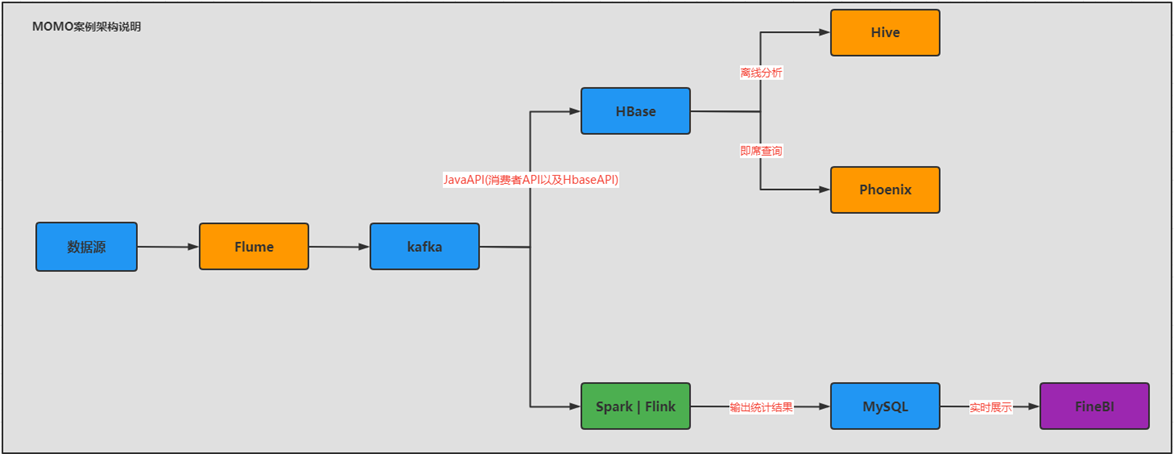
- Почему бы не передать данные Flume напрямую в Hbase, а равномерно передать их в Kafka, а затем передать из Kafka в Hbase?
- Избегайте высокой нагрузки на компьютер, вызванной высокой степенью одновременной записи, обеспечьте развязку архитектуры и добейтесь асинхронной эффективности.
- Обеспечьте согласованность данных
- нуждатьсяанализировать
- краткое содержание
- Освоить техническую архитектуру и выбор технологий для случаев реального времени
06: Проверка и установка лотка
Цель:Обзор базового использования и реализации установки Flume. лотка тест
путь
- Шаг 1: Проверка лотка
- step2:Установка лотка
- step3:тест Флюма
осуществлять
Обзор флюма
- Функция: в реальном время выполнять мониторинг и сбор потока данных в файле или сетевом порту
- Сцена: Сбор файлов в первое время
- развивать
- Шаг 1: Сначала создайте файл конфигурации: свойства [K=V]
- шаг 2: Запустите этот файл
- композиция
- Агент: Агент — это программа Flume.
- Источник: отвечает за мониторинг источника данных.,Превратите динамические данные источника данных в данные каждого события.,Поместите Eventданные потоки в Channel
- Канал: отвечает за временное хранение информации, отправленной источником для приемника для получения информации.
- Приемник: отвечает за получение данных из канала и запись их в Цель.
- Событие: представляет объект данных.
- глава: Коллекция карт [КВ]
- body:byte[]
Установка лотка
Загрузить установочный пакет
cd /export/software/
rz
Разархивируйте и установите
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /export/server/
cd /export/server
mv apache-flume-1.9.0-bin flume-1.9.0-binИзменить конфигурацию
#Интегрируйте HDFS и скопируйте файлы конфигурации HDFS
cd /export/server/flume-1.9.0-bin
cp /export/server/hadoop/etc/hadoop/core-site.xml ./conf/
#Изменить переменные среды Flume
cd /export/server/flume-1.9.0-bin/conf/
mv flume-env.sh.template flume-env.sh
vim flume-env.sh #Изменить строку 22
export JAVA_HOME=/export/server/jdk1.8.0_65
#Изменить строку 34
export HADOOP_HOME=/export/server/hadoop-3.3.0Удалите собственный пакет гуавы Flume и замените его пакетом Hadoop.
cd /export/server/flume-1.9.0-bin
rm -rf lib/guava-11.0.2.jar
cp /export/server/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar lib/Создать каталог
cd /export/server/flume-1.9.0-bin
#Каталог хранения файлов конфигурации программы
mkdir usercase
#Taildir Каталог хранения данных в юанях
mkdir positionтест Флюма
Требования: собирать данные чата и писать в HDFS.
анализировать
- Источник: Taildir: динамический мониторинг нескольких файлов. реальном времениданныеколлекция
- Канал: mem: кэшировать данные в памяти.
- Sink:hdfs
развивать
vim /export/server/flume-1.9.0-bin/usercase/momo_mem_hdfs.properties# define a1
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define s1
a1.sources.s1.type = TAILDIR
#Указываем файл записи метаданных
a1.sources.s1.positionFile = /export/server/flume-1.9.0-bin/position/taildir_momo_hdfs.json
#Преобразуйте все источники данных, которые необходимо отслеживать, в группу
a1.sources.s1.filegroups = f1
#Укажите, кто такой f1: контролировать все файлы в каталоге
a1.sources.s1.filegroups.f1 = /export/data/momo_data/.*
#Укажите, что заголовок данных, собранных f1, содержит пару KV
a1.sources.s1.headers.f1.type = momo
a1.sources.s1.fileHeader = true
#define c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
#define k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/momo/test/daystr=%Y-%m-%d
a1.sinks.k1.hdfs.fileType = DataStream
#Укажите создание файлов по времени, обычно закрытых
a1.sinks.k1.hdfs.rollInterval = 0
#Укажите размер файла для создания файла, обычно 120 ~ Количество байтов, соответствующее 125M
a1.sinks.k1.hdfs.rollSize = 102400
#Указываем количество событий для создания файла, обычно закрытого
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = momo
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#bound
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1Запустить HDFS
start-dfs.shЗапустить Флюм
cd /export/server/flume-1.9.0-bin
bin/flume-ng agent -c conf/ -n a1 -f usercase/momo_mem_hdfs.properties -Dflume.root.logger=INFO,consoleЗапуск смоделированных данных
java -jar /export/data/momo_init/MoMo_DataGen.jar \
/export/data/momo_init/MoMo_Data.xlsx \
/export/data/momo_data/ \
100Посмотреть результаты
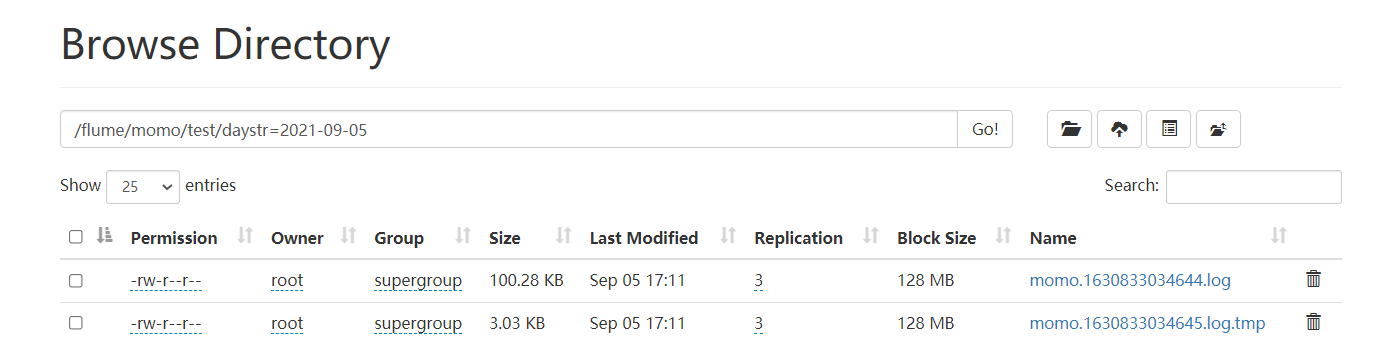
краткое содержание
- Обзор базового использования и реализации установки Flume. лотка тест
07: Разработка программы сбора Flume
Цель:Пример реализации программы сбора Flume
путь
- step1:нуждатьсяанализировать
- step2:программаразвивать
- step3:Тестовая реализация
осуществлять
нуждатьсяанализировать
Требования: собирать данные чата и записывать их в Kafka в режиме реального времени.
Source:taildir
Channel:mem
Sink:Kafka sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappyпрограммаразвивать
vim /export/server/flume-1.9.0-bin/usercase/momo_mem_kafka.properties# define a1
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#define s1
a1.sources.s1.type = TAILDIR
#Указываем файл записи метаданных
a1.sources.s1.positionFile = /export/server/flume-1.9.0-bin/position/taildir_momo_kafka.json
#Преобразуйте все источники данных, которые необходимо отслеживать, в группу
a1.sources.s1.filegroups = f1
#Укажите, кто такой f1: контролировать все файлы в каталоге
a1.sources.s1.filegroups.f1 = /export/data/momo_data/.*
#Укажите, что заголовок данных, собранных f1, содержит пару KV
a1.sources.s1.headers.f1.type = momo
a1.sources.s1.fileHeader = true
#define c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
#define k1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = MOMO_MSG
a1.sinks.k1.kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092
a1.sinks.k1.kafka.flumeBatchSize = 10
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 100
#bound
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1Тестовая реализация
Запустить Кафку
start-zk-all.sh
start-kafka.sh Создать тему
kafka-topics.sh --create --topic MOMO_MSG --partitions 3 --replication-factor 2 --bootstrap-server node1:9092,node2:9092,node3:9092перечислять
kafka-topics.sh --list --bootstrap-server node1:9092,node2:9092,node3:9092Начать потребитель
kafka-console-consumer.sh --topic MOMO_MSG --bootstrap-server node1:9092,node2:9092,node3:9092Запустите программу Flume
cd /export/server/flume-1.9.0-bin
bin/flume-ng agent -c conf/ -n a1 -f usercase/momo_mem_kafka.properties -Dflume.root.logger=INFO,consoleЗапустить данные моделирования
java -jar /export/data/momo_init/MoMo_DataGen.jar \
/export/data/momo_init/MoMo_Data.xlsx \
/export/data/momo_data/ \
50Наблюдения
краткое содержание
- Пример реализации программы сбора Flume



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
