Комбинация ChatGPT и Elasticsearch: использование ChatGPT для данных частного домена

Как объединить поисковую релевантность Elasticsearch с возможностями вопросов и ответов ChatGPT OpenAI для запроса ваших данных? В этом блоге вы узнаете, как использовать Elasticsearch для подключения ChatGPT к собственному хранилищу данных и создавать возможности вопросов и ответов для ваших данных.

Что такое ChatGPT?
В последние месяцы был большой энтузиазм по поводу ChatGPT, революционной модели искусственного интеллекта, созданной OpenAI. Но что такое ChatGPT?
Основанный на мощном GPT Архитектура, ЧатGPT Предназначен для понимания ввода текста и генерации ответов, подобных человеческим. GPT Представляет собой «Генеративный предтренировочный трансформатор». Pre-trained Transformer)”。Transformer это передовая модельная архитектура, которая революционизирует обработку естественного языка. (NLP) поле. Эти модели предварительно обучены на огромных объемах данных и способны понимать контекст, генерировать релевантные ответы и даже вести беседы. Чтобы узнать больше о transformer история модели и Elastic Stack некоторые из NLP базовые знания,Обязательно посмотрите КрутоизИнженер Elastic ML Джош Девинс из выступления。
Основная цель ChatGPT — облегчить значимое и увлекательное взаимодействие между людьми и машинами. Используя последние достижения в области NLP, модель ChatGPT может использоваться в широком спектре приложений: от чат-ботов и виртуальных помощников до генерации контента, завершения кода и многого другого. Эти инструменты на основе искусственного интеллекта быстро стали бесценным ресурсом во многих отраслях, помогая предприятиям оптимизировать процессы и улучшать качество услуг.
Однако, несмотря на невероятный потенциал ChatGPT, пользователям все равно следует знать об определенных ограничениях. Стоит отметить одно ограничение — срок получения знаний. В настоящее время ChatGPT обучается на данных по состоянию на сентябрь 2021 года, что означает, что он не осведомлен о событиях, разработках или изменениях, произошедших с тех пор. Поэтому пользователям следует помнить об этом ограничении, когда они полагаются на ChatGPT для получения самой последней информации. Это может привести к устаревшим или неправильным ответам при обсуждении быстро меняющихся областей знаний, таких как улучшения и функции программного обеспечения или даже мировые события.
ChatGPT, хотя и является впечатляющей языковой моделью искусственного интеллекта, иногда страдает от галлюцинаций в ответах, которые часто усугубляются, когда у него нет доступа к соответствующей информации. Эта чрезмерная самоуверенность может привести к неверным ответам или предоставлению пользователям вводящей в заблуждение информации. Важно помнить об этом ограничении и подходить к ответам, генерируемым ChatGPT, с долей скептицизма, перепроверяя и проверяя информацию, когда это необходимо, для обеспечения точности и надежности.
Еще одним ограничением ChatGPT является отсутствие знаний о контенте, специфичном для конкретного домена. Хотя он может генерировать последовательные и контекстуальные ответы на основе информации, на которой он был обучен, он не может получить доступ к данным, специфичным для предметной области, или предоставить персонализированные ответы, основанные на уникальной базе знаний пользователя. Например, у него может не быть глубокой информации о проприетарном программном обеспечении или внутренней документации организации. Поэтому пользователям следует проявлять осторожность, обращаясь за советом или ответами по таким темам непосредственно в ChatGPT.
Один из способов минимизировать эти ограничения — предоставить ChatGPT доступ к конкретным документам, относящимся к вашему домену и вопросу, а также включить возможности распознавания языка ChatGPT для генерации индивидуальных ответов.
Этого можно добиться, подключив ChatGPT к поисковой системе, такой как Elasticsearch.
Elasticsearch——you know, for search!
Elasticsearch — это эффективная поисковая система, предназначенная для поиска соответствующих документов, гарантирующая пользователям быстрый и точный доступ к необходимой им информации. Основная цель Elasticsearch — предоставить пользователям наиболее релевантные результаты, упростить процесс поиска и улучшить взаимодействие с пользователем.
Elasticsearch Содержит функции, обеспечивающие лучшую в своем классе производительность поиска, включая поддержку традиционного поиска по ключевым словам и текстового поиска. ( BM25 )и точныйсоответствоватьиприблизительныйkNNизAIвекторный поиск(k-Nearest Neighbor)。这些高级功能使 Elasticsearch Вы можете не только получать релевантные результаты, но также получать результаты для запросов, выраженных на естественном языке. Используя традиционный, векторный или гибридный поиск. (BM25 + kNN),Elasticsearch Он обеспечивает беспрецедентно точные результаты, помогая пользователям легко находить нужную информацию.
Одним из основных преимуществ Elasticsearch является его мощный API, который можно легко интегрировать с другими сервисами для расширения и улучшения его функциональности. Интегрируя Elasticsearch с различными сторонними инструментами и платформами, пользователи могут создавать мощные индивидуальные поисковые решения в соответствии со своими конкретными потребностями. Такая гибкость и масштабируемость делают Elasticsearch идеальным решением для компаний, стремящихся улучшить свои возможности поиска и оставаться впереди в конкурентной цифровой среде.
Работая с продвинутыми моделями искусственного интеллекта, такими как ChatGPT, Elasticsearch может предоставить ChatGPT наиболее релевантные документы для использования в своих ответах. Эта синергия между Elasticsearch и ChatGPT гарантирует, что пользователи получают фактические, контекстуальные и актуальные ответы на свои запросы. По сути, возможности поиска Elasticsearch в сочетании с возможностями понимания естественного языка ChatGPT обеспечивают беспрецедентный пользовательский опыт, который устанавливает новый стандарт для поиска информации и помощи на основе искусственного интеллекта.
Как использовать ChatGPT с Elasticsearch
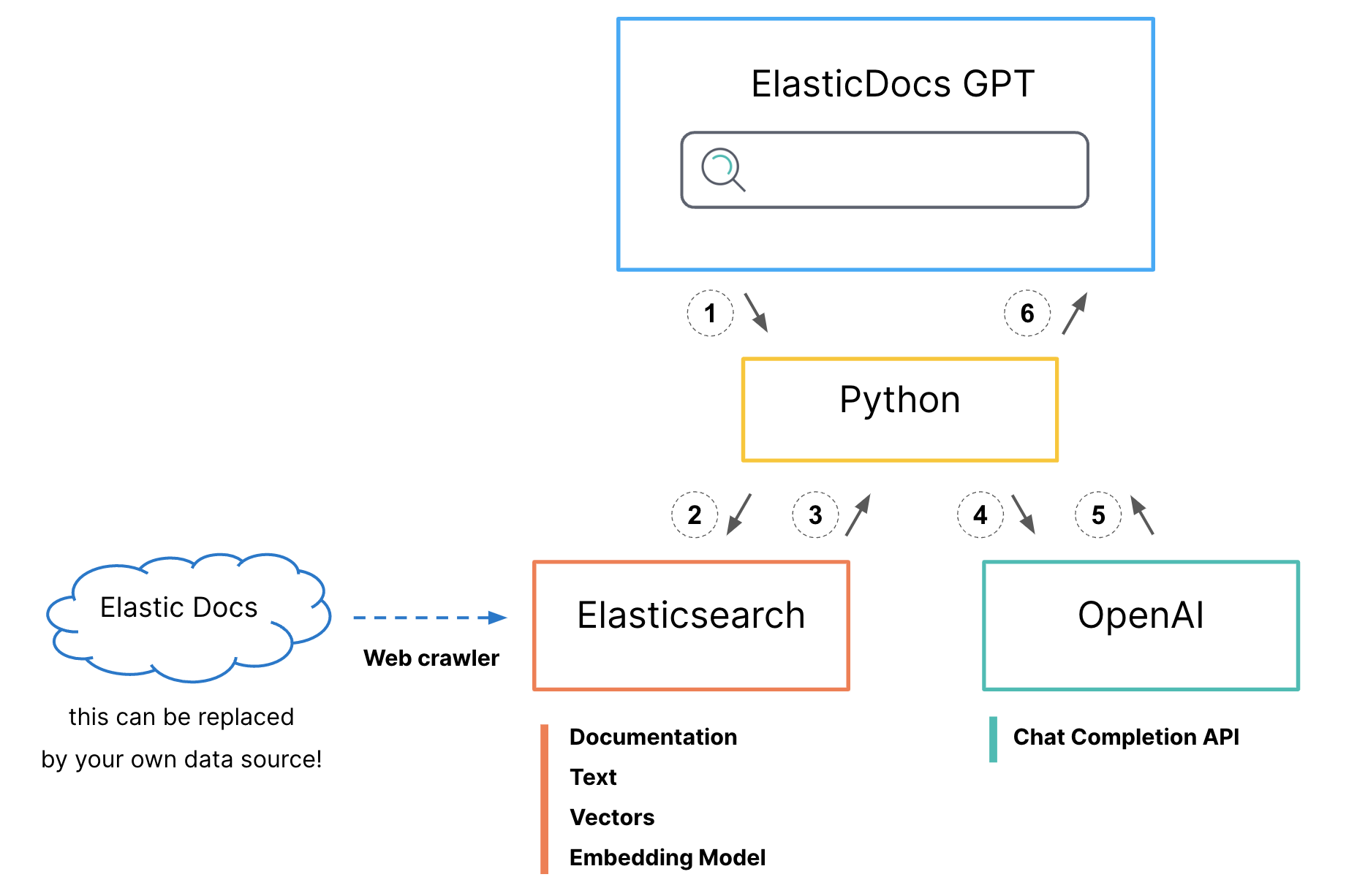
- API Python принимает вопросы от пользователей.
Генерация гибридных поисковых запросов для Elasticsearch
- В поле заголовка BM25 соответствовать
- kNN выполняет поиск в векторном поле заголовка
- Увеличьте результаты поиска kNN, чтобы выровнять результаты
- настраивать size=1 只возвращатьсянаивысший баллиздокумент
2. Поисковые запросы отправляются в Elasticsearch.
3. Тело документа и исходный URL-адрес возвращаются в приложение Python.
- Вызовите API OpenAI ChatCompletion:
- prompt:"answer this question <question> using only this document <body_content from top search result>"
- Генерация ответа начинается с Python.
- Python Воляоригинальныйдокумент源 url Добавляем к сгенерированному ответу и распечатываем его на экране для пользователя.
ElasticDoc ChatGPT использование процесса Python Интерфейс принимает вопросы пользователей и Генерация гибридных поисковых запросов для Elasticsearch, комбинированный BM25 и kNN Метод поиска из Найдите наиболее актуальную документацию в официальной документации Elastic, которая теперь доступна по адресу Elasticsearch Средняя подготовкаиндекс.но,Вам не обязательно использовать гибридный поиск или даже векторный поиск. Имейте гибкость в поиске шаблона, который лучше всего соответствует вашим потребностям и предоставляет наиболее релевантные результаты для вашего конкретного набора данных.。
После получения наилучших результатов программа OpenAI из ChatCompletion API 制делатьPrompt,указывает на то, что это толькоиспользоватьвыбранодокументсерединаизинформация для ответа пользователямизвопрос。этот提示是确保 ChatGPT Модель содержит только официальную информацию о документах, что является ключом к уменьшению галлюцинаций, создаваемых ChatGPT.
Наконец, программа показывает пользователю API Генерирует ссылки на ответы и исходные документы, обеспечивая бесперебойную и удобную работу, интегрируя взаимодействие с внешним интерфейсом, Elasticsearch. Запрос и OpenAI API использовать для эффективного использования вопросов и ответов.
пожалуйста, обрати внимание,Хотя для простоты мы получили только самый высокий результат из документа.,Но лучшая практика — это появление нескольких документов для ChatGPT Предоставьте больше контекста. Правильный ответ можно найти на нескольких страницах документа, или, если мы хотим, чтобы основной текст был сгенерирован для создания векторов, тогда эти более крупные текстовые тела, возможно, придется разбить на фрагменты и сохранить в нескольких экземплярах. Elasticsearch в документе. используя Elasticsearch Традиционные методы поиска позволяют выполнять совместный поиск в большом количестве векторных полей, и вы можете значительно повысить скорость поиска верхнего уровня.
Техническая настройка
Технические требования относительно низкие,Но необходимы некоторые шаги для того, чтобы все части сошлись воедино и стали существовать вместе. верно, этот пример,нас Воля КонфигурацияВеб-сканер Elasticsearchк摄取 Elastic документисуществовать При проглатываниидляtitleСоздать вектор。ты可к跟随本文икопироватьэтотнастраивать,Или используйте сами изданных. для Следуйте этой статье,мы должны:
- Кластер Elasticsearch
- Библиотека Эланда Python
- Аккаунт API OpenAI
- бегатьнасиз python Передняя часть и api Бэкэнд с сервера
Настройки эластичного облака
本节серединаиз Эти шаги предполагают, что выкогда Не раньшесуществовать Elastic Cloud серединабегатьиз Elasticsearch кластер. Если у вас уже есть один Elastic Cloud
из кластера вы можете перейти к следующей части.
зарегистрироваться
если у тебя нет Elasticsearch кластер,ты可к通过Elastic Cloudзарегистрироваться Бесплатная пробная версия。
Создать развертывание
После регистрации вам будет предложено создать первую развертку.
- для развертывания создайте имя.
- Вы можете принять регион облачного провайдера по умолчанию или нажать «Изменить настройки» и выбрать другое местоположение.
- щелкнуть Создать развертывание. Скоро Волядля вас настроится новая развертывание и вы Воля зайдете в Kibana。
Вернуться в облако
Прежде чем продолжить, нам нужно сделать несколько вещей в Cloud Console:
щелкнуть значок навигации в левом верхнем углу и выбрать «Управление этим развертыванием».

Добавьте узел машинного обучения.
- возвращаться Cloud Console,щелкнуть左侧导航栏серединаразвертыватьпод именемизEdit。

- Прокрутите вниз до поля «Экземпляры машинного обучения» и нажмите «+Добавить емкость».
- существоватьSize per zoneВниз,щелкнутьи选择 2 GB Размер оперативной памяти узла машинного обучения
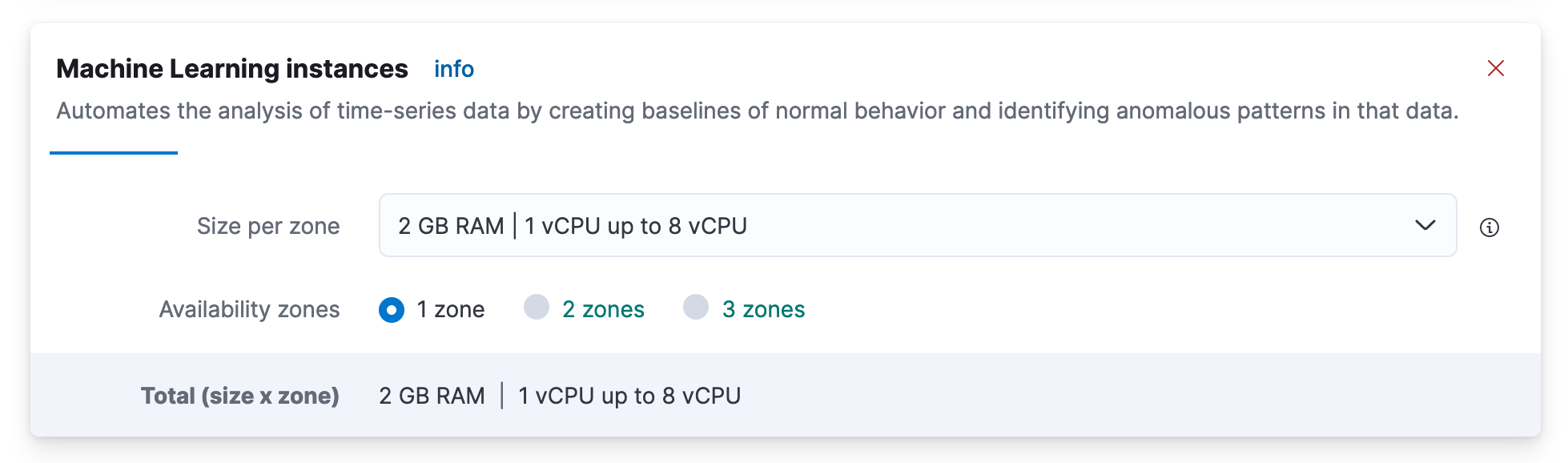
- Прокрутите вниз и нажмите «Сохранить»:

- существоватьнеожиданно возникнутьиз summarizing the architecture changes окне нажмите «Подтвердить».

- Через некоторое время у вас будет модель машинного обучения!

перезагрузить Elasticsearch развертыватьпользовательипароль:
- щелкнутьразвернуть из раздела Безопасность на левой панели навигации под вашим именем.
- Пароль и подтвердите. (Примечание: поскольку для — новый кластер, его не следует использовать в качестве эластичного пароля.)
- Скачать для "эластичного" пользователя новое создание пароля. (мы Воляиспользовать этоот Hugging Face иисиз python Загрузите нас в программу из Модель.)
Скопируйте идентификатор облака развертывания Elasticsearch.
- щелкнуть свое имя развертывания, чтобы перейти на страницу обзора.
- существоватьправая сторонащелкнутькопировать图标ккопироватьтыиз Cloud ИДЕНТИФИКАТОР. (Сохраните это на будущее. Подключитесь к Deployment。)

Eland
Далее нам нужно загрузить модель внедрения в Elasticsearch , используемый для создания векторов для заголовка нашего блога и для пользователей для векторов генерации поисковых вопросов. Мы Воляиспользовать по SentenceTransformers Обучены и размещены на Hugging Face Модельсередина心начальствоизмодель all-distilroberta-v1.существоватьэтот示例середина,Причина, по которой мы выбираем эту модель,Потому что он существует и охватывает широкий круг тем, обучаясь на очень большом наборе данных.,Подходит для общего использования. но,Нам не обязательно выбирать эту модель,верно для случаев использования векторного поиска,Точная настройка модели для вашего конкретного набора данных обычно обеспечивает наилучшую корреляцию.。
Для этого мы будем использовать Elastic создаватьизБиблиотека Python Eland.Должен Библиотека Предоставляет широкий спектризвозможности науки о данных,Но мы Воляиспользовать это делает для моста,Воля Модельот Hugging Face Центр моделей загружается в Elasticsearch, чтобы его можно было развернуть на узлах машинного обучения для вывода.
Eland может использоваться как python Сценарий, входящий в состав Project, также можно использовать в командной строке. Магазин Библиотека также хочет пойти по этому пути, предоставляя пользователям Docker контейнер。今天нас Волясуществоватьодинмаленький блокнот на питонесерединабегать Eland , он доступен бесплатно в вашем веб-браузере. Colab середина.
ОткрытьСсылка на программуищелкнутьвершинаиз“существовать Colab кнопка, чтобы открыть в Colab Запустите блокнот в формате .

переменная hf_model_id настройки для имени модели. Эта модель включена в пример кода, но если вам нужна другая модель, вы можете изменить ее самостоятельно:
hf_model_id='sentence-transformers/all-distilroberta-v1'- от Hugging Face скопировать название модели. Самый простой способ — использовать значок щелкнуть справа от названия модели.
Запустите раздел облачной аутентификации, и вам будет предложено:
- Cloud ID (вы можете найти его в консоли Elastic Cloud)
- Elasticsearch Имя пользователя (самый простой способ —использоватьсуществовать Создать развертывание создано пользователем «Elastic»)
- Elasticsearchизпароль
Выполните оставшиеся шаги:
- Это Воляот Hugging face Загрузите модель, разбейте ее и загрузите в Elasticsearch середина.
- Воля модели развернуть (запустить) на узел машинного обучения.
Индексирование Elasticsearch и сканирование веб-страниц
Дальше мы с Волей создаём новый из Elasticsearch Индекс для хранения наших из Elastic Документы, настройте веб-искатель для автоматического сканирования и индексирования этих документов и используйте конвейер приема для создания векторов для заголовков документов.
пожалуйста, обрати внимание,Вы можете продолжить этот шаг, используя свои собственные данные.,чтобы создать опыт вопросов и ответов, адаптированный к вашей области.
- Если вы еще не открыли его Kibana,пожалуйстаот Cloud Console Откройте его.
- существовать Kibana , перейдите к Предприятию Search -> Обзор. Нажмите Создать Elasticsearch индекс.

- использовать Web Crawler В качестве метода приема введите elastic-docs Что касается имени индекса. Затем,щелкнутьсоздаватьиндекс.

- щелкнуть“ingest Pipeline”вкладка。
- щелкнуть Ingest Pipeline серединаиз Copy and customize。
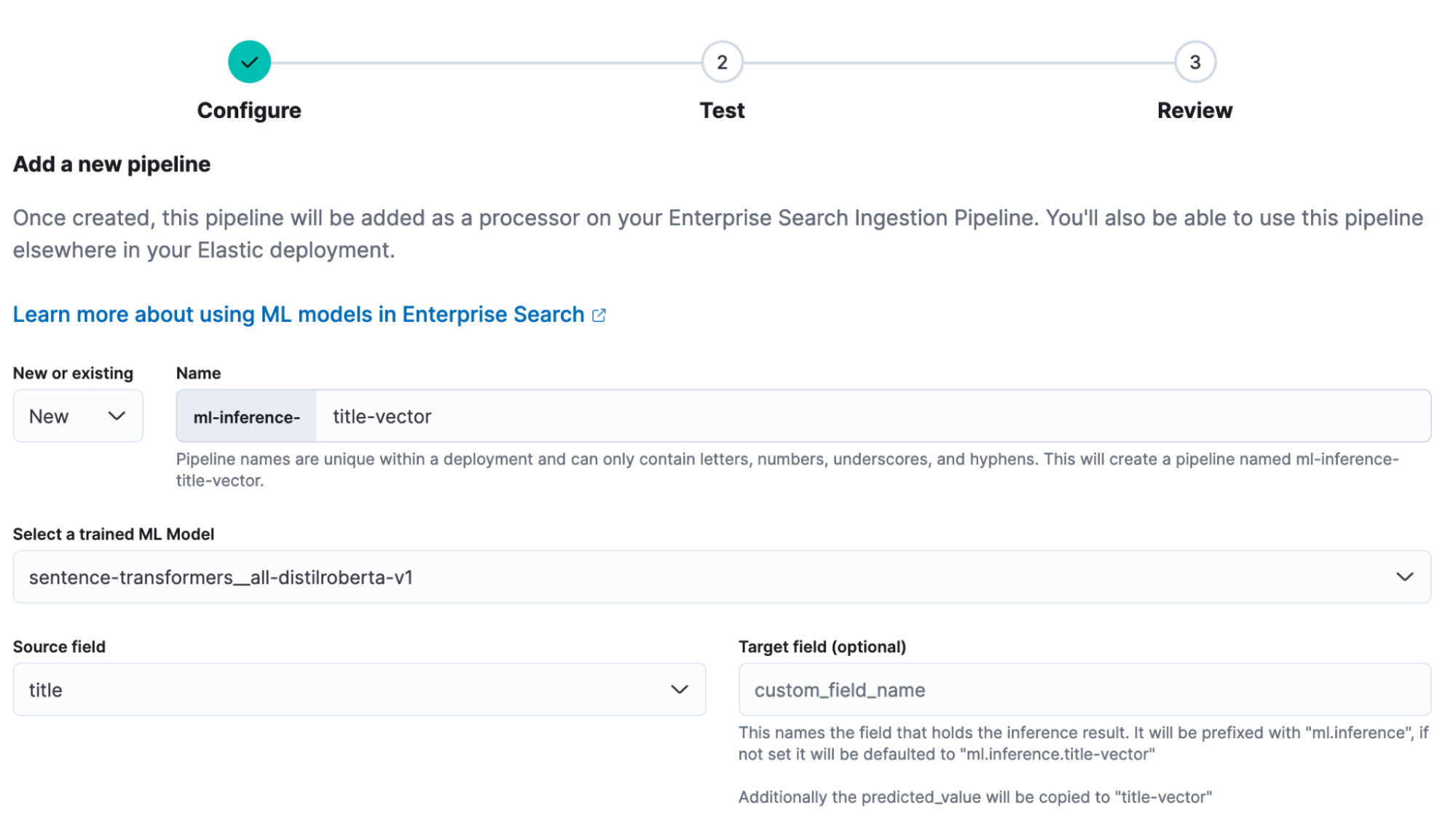
- щелкнуть Add Inference Pipeline

- Введите имя для нового конвейера elastic-docs_title-vector.
- Выберите свой вариант существования из Eland Загрузка поэтапно ML Модель.
- Выберите заголовок в качестве исходного поля.
- щелкнутьContinue,Затемсуществоватьснова этап тестированиящелкнутьContinue
- существовать Review щелчок по сцене Create Pipeline
возобновлять dense_vector Поле картографирования. (Примечание: верно Ю. Elasticsearch 8.8+ версии, этот шаг должен быть автоматическим. )
- существуют навигационное меню,щелкнуть Dev Tools。如果这是ты Нет.一次Открыть Dev Инструменты, возможно, вам придется существовать с всплывающим окном документа, нажав кнопку «Закрыть».
- существовать Console вкладка из Dev Tools середина,использоватьк Вниз代码возобновлять
dense_vectorцелевое полеизкартографирование。ты只需Воля Что粘贴到代码框середина,Затемщелкнуть Нет. 1 Справа от линии есть маленькая стрелка.
POST search-elastic-docs/_mapping
{
"properties": {
"title-vector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "dot_product"
}
}
}Узнать больше- В правой половине экрана вы должны увидеть следующий ответ:
{
"acknowledged": true
}- Эта воля позволяет нам позже существовать в поле заголовка для запуска векторного поиска kNN.
Настройте веб-искатель для сканирования официальных документов Elastic:
- Перейдите по меню еще раз щелкнуть, а затем щелкнуть. Enterprise Search -> Overview。
- существовать内容Вниз,щелкнутьиндекс.
- щелкнуть search-elastic-docs。

- щелкнуть“Manage Domains”вкладка。
- щелкнуть“Add domain”。
- входитьhttps://www.elastic.co/guide/en,Затем щелкнуть проверить домен.
- После проверки проекта,щелкнутьAdd domain。Затемщелкнуть Правила сканирования。
- Добавьте следующие правила сканирования одно за другим. начало снизу,Постепенно вверх. Правила оцениваются согласно первому соблюдениюруководства.
Disallow | Contains | release-notes |
|---|---|---|
Allow | Regex | /guide/en/.*/current/.* |
Disallow | Regex | .* |

- После того как все правила готовы,щелкнуть верхнюю часть страницы при сканировании. Затем,щелкнуть“ Crawl all domains on this index”。
Elasticsearch извеб-сканерсейчас существует Воля начал сканировать сайт документов,Вектор генерации поля заголовка,И верные документы векторного индекса построения.

Первое сканирование занимает некоторое время. В то же время мы можем установить OpenAI API Ваучер Python задняя часть.
Подключитесь к API OpenAI
к ChatGPT Отправьте вопрос по документам, он нам нужен OpenAI API Аккаунт и Ключ. если у тебя нет учетной записи, вы можете создать бесплатную учетную запись и получить начальное количество бесплатных баллов.
- Перейти кhttps://platform.openai.comи点击зарегистрироваться。ты可к通过电子邮件地址ипарольруководитьзарегистрироваться,Вы также можете войти в систему с помощью Google или Microsoft.
После создания учетной записи вам необходимо создать ключ API:
- щелкнутьAPI Key。
- щелкнуть Создать новый ключ.
- скопировать новый ключ и Воля сохранит его на безопасном месте,Потому что для вас Воля не может снова просмотреть ключ.

Настройки серверной части Python
Клонируйте или загрузите программу Python
- Требуется для установки python библиотека. Мы существуем в изолированной среде. Replit запустить пример программы. Если у вас существует ноутбук или VM начальствобегатьэто,Лучшая практикаНастройка VENV для Python。
- Запустите pip install -r require.txt
2.настройки аутентификации изоединять переменную среды (например, если она существует в командной строке: экспорт openai_api="123456abcdefg789")
- openai_api - OpenAI API Key
- cloud_id - Elastic Cloud ID
- cloud_user — пользователь кластера Elasticsearch.
- cloud_pass — пароль пользователя Elasticsearch
3. Запустите программуstreamlit. связанный streamlit из更多информация可ксуществовать Чтодокументсередина找到。
- Streamlit Создайте собственную команду запуска:streamlit run elasticdocs_gpt.py
- Это запустит веб-браузер и выведет URL-адрес в командную строку.
Пример ответа в чате
Как только все будет обработано и интерфейс запущен и заработает, вы можете начать задавать вопросы о Elastic Официальный документизвопрос.
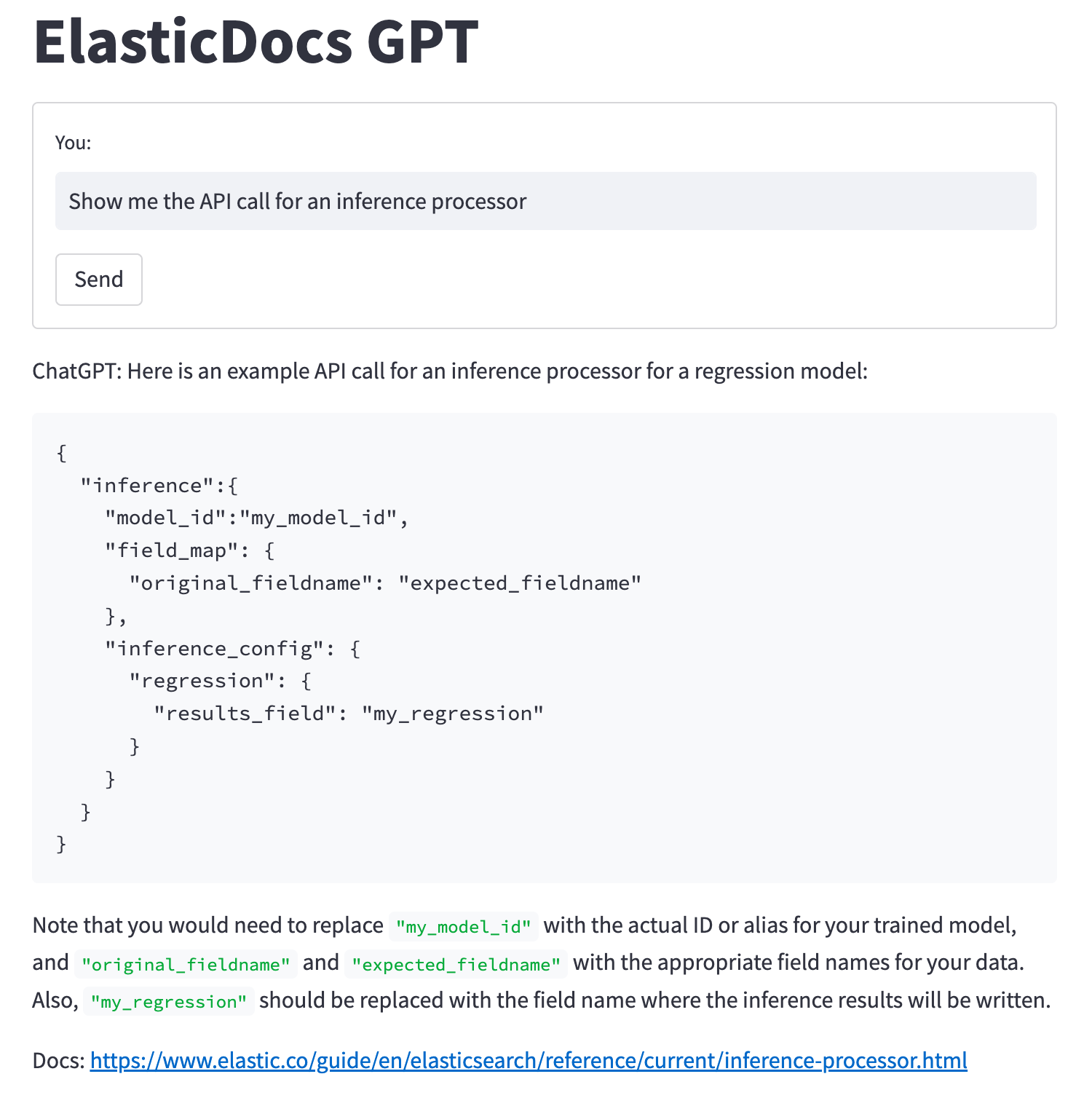
Спросите «Покажи me the API call for an inference процессор" теперь будет возвращать API вызовизпримери有关Конфигурациянастраиватьизинформация。
Спросите о новых интеграциях, добавляемых в Elastic Agent изшаг:

Как уже говорилось ранее, допускается ChatGPT Один из рисков ответов на вопросы, основанных исключительно на обученных данных, заключается в том, что это имеет тенденцию создавать иллюзию неправильных ответов. Одной из целей проекта является ChatGPT Предоставьте данные с нужной информацией и позвольте им сформулировать ответ.
Поэтому, когда мы даем ChatGPT Что происходит, когда издокумент не содержит правильной информации? Например, попросите его рассказать вам, как построить лодку (Эластик из Официальный документ не содержит такого содержания):
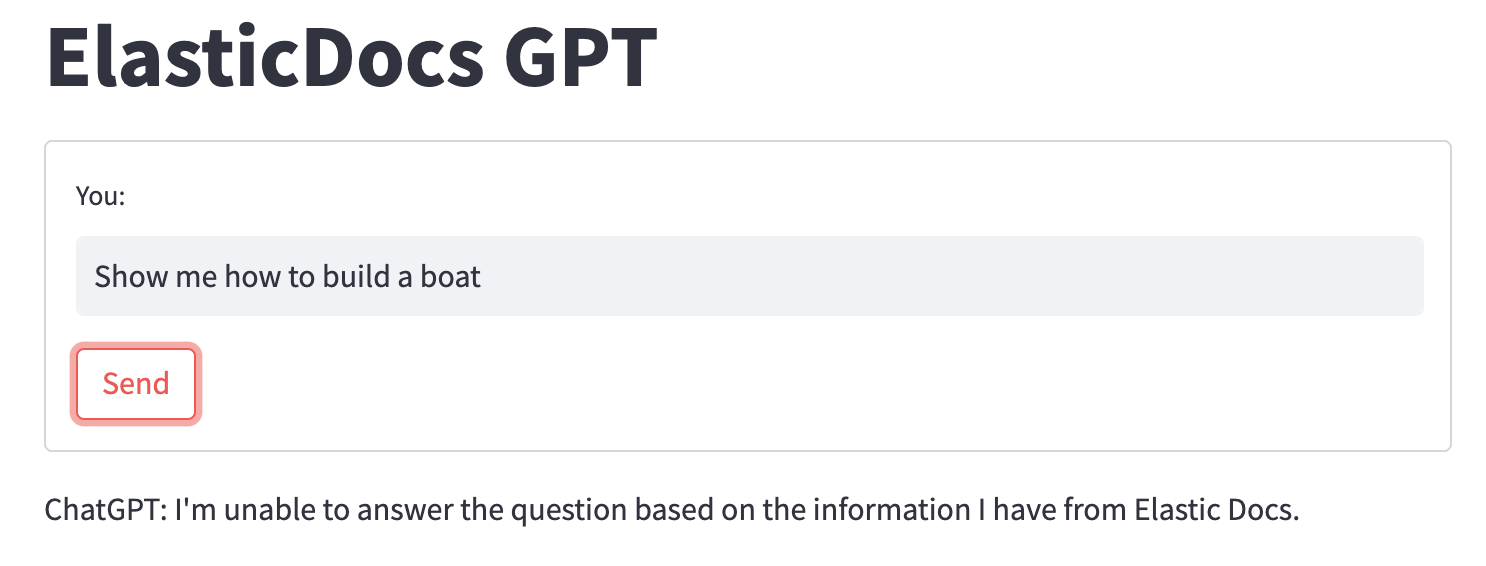
когда ChatGPT Если не удается найти ответ на вопрос, мы предоставляем документ, он возвращается к нашим быстрым инструкциям и просто сообщает пользователю, что не может ответить на вопрос.
Мощный поиск Elasticsearch + мощные функции ChatGPT
существуют В этом примере,Мы показываем, насколько сильна Воля Elasticsearch: возможности поиска по поиску, генерация модели GPT, последние разработки и интеграция ответов AI.,от И Воля пользовательский опыт продвигает на совершенно новый уровень.
Эти компоненты могут быть настроены в соответствии с вашими конкретными требованиямирукопривод.,И руководить настроенными, чтобы обеспечить наилучшие результаты. Хотя мы используем Elasticвеб-сканер для сбора общедоступных данных.,Но вы не ограничены этим методом. Не стесняйтесь попробовать другие модели встраивания,Особенно те, которые точно настроены под конкретные данные предметной области.
Вы можете опробовать все функции, обсуждаемые в этом блоге, уже сегодня! Чтобы построить свой собственный ElasticDocs GPT опыт,пожалуйстазарегистрироватьсяодинЭластичный пробный аккаунт,Затем查看этотПример базы кодак开始использовать。
Если вы хотите узнать больше о новых возможностях Elasticsearchсуществовать релевантность поиска, вы можете попробовать следующие два:



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
