[Колонка обзора] Приложение для интеллектуального производства с большой языковой моделью
В научных исследованиях с методологической точки зрения следует «видеть лес раньше деревьев». В настоящее время научные исследования в области искусственного интеллекта находятся на подъеме, и технологии быстро развиваются. Можно сказать, что тысячи деревьев конкурируют за процветание и меняются с каждым днем. Что касается практиков ИИ, только систематически разбираясь в контексте огромного леса знаний, мы сможем лучше понять тенденции. С этой целью мы отобрали отличные обзорные статьи в стране и за рубежом и открыли «Колонку обзоров», так что следите за обновлениями.

Адрес: https://arxiv.org/abs/2312.06718
Хотя искусственный интеллект, особенно глубокое обучение, добился значительных улучшений в различных аспектах интеллектуального производства, эти технологии страдают от плохих возможностей обобщения, трудностей с созданием высококачественных наборов обучающих данных и неудовлетворительной производительности методов глубокого обучения. Проблемы все еще существуют. для широкого применения. Появление крупномасштабных базовых моделей (LSFM) вызвало волну в области искусственного интеллекта, превратив модели глубокого обучения из однозадачных, одномодальных и ограниченных шаблонов данных в охватывающие несколько задач, многомодальностей и больших объемов данных. Масштабные наборы данных Парадигма для предварительного обучения. Хотя LSFM продемонстрировали сильные возможности обобщения, возможности автоматического создания высококачественных наборов обучающих данных и отличную производительность в различных областях, применение LSFM в области интеллектуального производства все еще находится в зачаточном состоянии. Систематического обзора этой темы не хватает, особенно относительно того, какие проблемы глубокого обучения могут быть решены с помощью LSFM и как эти проблемы могут быть систематически решены. Чтобы восполнить этот пробел, в данной статье систематически рассматривается текущий статус LSFM и их преимуществ в контексте интеллектуального производства, а также проводится всестороннее сравнение с проблемами, с которыми сталкиваются современные модели глубокого обучения в различных приложениях интеллектуального производства. Мы также наметим план действий по использованию LSFM для решения этих проблем. Наконец, тематическое исследование применения LSFM в реальных сценариях интеллектуального производства показывает, как LSFM могут помочь отрасли повысить эффективность.
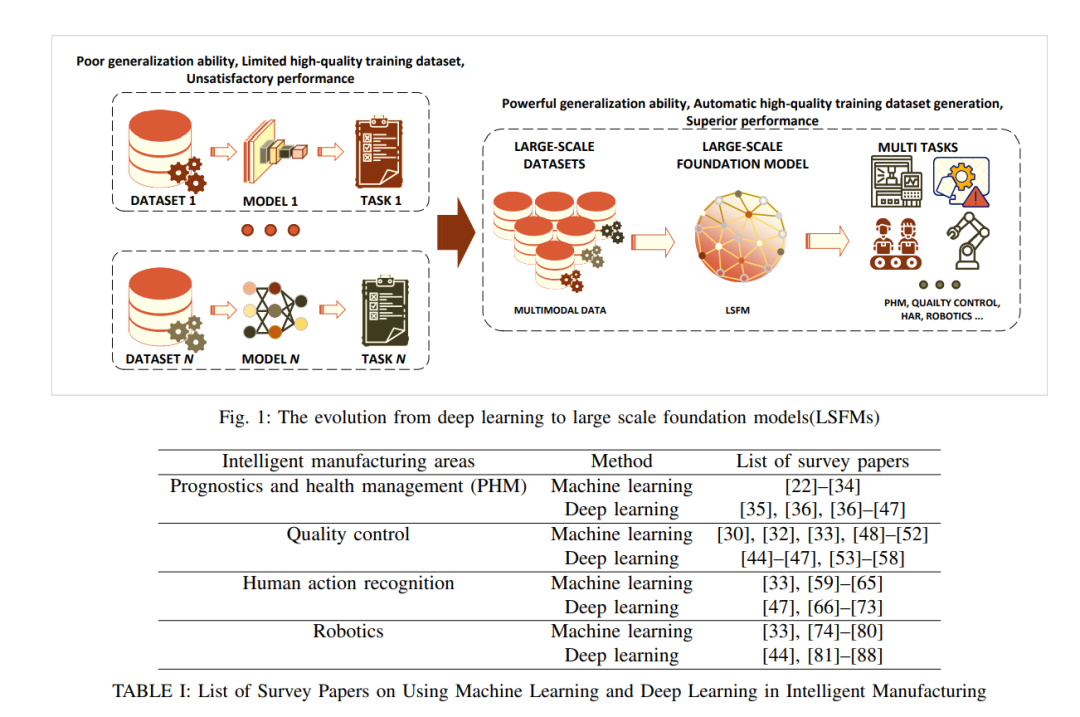
Производство является одним из столпов национальной экономики, и несколько стран объявили о стратегических планах содействия применению новых производственных технологий и обеспечения лидерства в этой области, таких как «Индустрия 4.0» в Германии [1] и «умное» производство в США. Коалиция (SMLC) [2] и «Сделано в Китае 2025» [3]. За последние несколько десятилетий производство стало умнее за счет внедрения новых технологий, таких как датчики, Интернет вещей (LOT), роботы, цифровые двойники и киберфизические системы (CPS) [4]–[15], среди которых беспрецедентные объемы данных продолжают генерироваться и фиксироваться на всех этапах процесса. Поэтому эффективные алгоритмы обработки данных крайне необходимы для обеспечения эффективной диагностики неисправностей и профилактического обслуживания, контроля качества, человеческих операций, оптимизации процессов и многих других интеллектуальных решений, необходимых для интеллектуального производства [16]–[20]. Статистика показывает, что 82% промышленной деятельности с использованием интеллектуальных производственных технологий достигли повышения эффективности и производительности [16], [21]. Эти улучшения в интеллектуальном производстве в основном связаны с внедрением различных алгоритмов машинного обучения, которые увеличились с масштабом и сложностью производственных данных. Многие передовые методы, основанные на данных, были исследованы и внедрены для достижения крупномасштабных возможностей обработки данных. высокая эффективность и сильные способности принятия решений, которые часто необходимы в сложной производственной деятельности. В табл. 1 приведены некоторые обзорные статьи в этой области [22]–[88].
Традиционные методы машинного обучения, такие как машины опорных векторов, K ближайших соседей, наивный Байес и т. д., могут в определенной степени улучшить эффективность принятия решений в обрабатывающей промышленности [89]–[91], планирование производственной линии [92] , [93], планирование технического обслуживания машин [94], [95], прогнозирование отказов [96]–[98], оценка качества [99], [100] и обнаружение дефектов [101], [102]. Однако они чрезмерно полагаются на ручную разработку функций для представления данных со знанием предметной области и не имеют возможности обрабатывать сильно нелинейные отношения в крупномасштабных данных, что ограничивает их применение в интеллектуальном производстве [103], [104].
Являясь передовым методом машинного обучения, глубокое обучение может автоматически извлекать функции и выявлять закономерности из многомерных нелинейных необработанных данных с помощью архитектуры многоуровневой нейронной сети, что делает его более подходящим для сложной обработки данных в интеллектуальном производстве. В последнее десятилетие методы глубокого обучения стали основными методами, основанными на данных, в различных областях интеллектуального производства, таких как управление здравоохранением (PHM) [105]–[125], контроль качества [126]–[142] и робототехника. [143]–[149] и распознавание деятельности человека [66], [150]–[165].
Хотя глубокое обучение в значительной степени способствовало развитию интеллектуального производства, демонстрируя возможности абстрактного выражения высокого уровня для изучения функций, отличные возможности сквозных моделей принятия решений и значительно снижая потребность в рабочей силе, оно по-прежнему сталкивается со значительными трудностями в своей работе. приложение [45], [166]–[169]. Во-первых, производительность небольших моделей глубокого обучения, адаптированных для конкретных условий и целей, ограничена. Эти модели имеют такие проблемы, как ограниченная способность к обобщению, плохая интерпретируемость и уязвимость к атакам, и не могут удовлетворить потребности предприятий в интеллектуальном производстве и управлении, особенно в сложных задачах с разнообразными данными [170]–[175]. Более того, они могут решать отдельные задачи только децентрализованно и слабосвязанно [176]–[178]. Во-вторых, требования к увеличению размера данных и затраты на создание набора данных ограничивают производительность моделей глубокого обучения. В качестве подхода, основанного на данных, модели глубокого обучения полагаются на подходящие отношения между входными и выходными данными, где количество и качество наборов обучающих данных играют ключевую роль [166]. Хотя новые технологии, такие как датчики и Интернет вещей, позволяют эффективно собирать большие объемы данных [179]–[184], эти данные часто распределены неравномерно, зашумлены, не имеют меток и содержат большие объемы неструктурированных данных. Следовательно, этих данных недостаточно для обучения хорошей модели глубокого обучения. В то же время модели глубокого обучения недостаточно эффективны при обработке крупномасштабных данных. Недавно появившиеся крупномасштабные базовые модели [185]–[189] часто обучаются посредством обширного самостоятельного обучения и демонстрируют сильные возможности обобщения, отличную производительность с нулевым выстрелом и впечатляющие возможности мультимодального слияния, что было продемонстрировано их успехом. в различных последующих задачах, таких как обработка естественного языка и компьютерное зрение [190]–[197]. Хотя усилия по использованию LSFM для решения проблем интеллектуального производства только начались, некоторый прогресс был предпринят. [198], [199] обсуждали потенциальные применения LSFM в промышленном производстве, но ограничивались конкретными промышленными задачами или конкретными LSFM. Джи и др. [200] представили количественное сравнение производительности базовых моделей машинного зрения с современными моделями глубокого обучения в скрытых сценах. Огундаре и др. [201] представили исследование устойчивости и эффективности систем промышленной автоматизации и управления, созданных с помощью больших языковых моделей (LLM).
Хотя LSFM продемонстрировали большой потенциал в интеллектуальном производстве, где очень популярны сильные возможности обобщения, автоматическая генерация высококачественных наборов обучающих данных и отличная производительность, исследования в этой области все еще находятся на ранней стадии, и информации о LSFM мало. интеллектуальные производственные приложения еще не появились. В этом документе предлагается технологическая дорожная карта для использования LSFM в интеллектуальном производстве, особенно там, где методы глубокого обучения сталкиваются со значительными препятствиями. Наша работа направлена на предоставление направлений и дискуссий, чтобы помочь понять, как LSFM могут принести пользу интеллектуальному производству.
Оставшаяся часть этой статьи организована следующим образом. Во второй части описываются проблемы, с которыми сталкиваются модели глубокого обучения в интеллектуальном производстве. В разделе 3 мы сначала даем краткий обзор текущего прогресса LSFM, а затем обсуждаем технические преимущества LSFM в интеллектуальном производстве, которые решают проблемы, с которыми сталкивается глубокое обучение. В разделе 4 объясняется план применения LSFM в интеллектуальном производстве. Наконец, в разделе 5 мы проиллюстрируем, как LSFM могут добиться прогресса в интеллектуальном производстве, на примере нескольких примеров, которые мы применили в реальных производственных сценариях.
Прогресс в разработке крупномасштабных моделей фундамента (LSFM)
Базовая модель предназначена для обучения на крупномасштабных наборах данных, т. е. с миллиардами и сотнями миллиардов параметров, и впервые была названа недавно [185]. Эти модели могут быть предварительно обучены с фиксированием большинства параметров и точной настройкой для адаптации к широкому спектру последующих приложений. Фактически, крупномасштабные базовые модели (LSFM) добились революционного прогресса в таких областях, как обработка естественного языка [292] и компьютерное зрение [293].
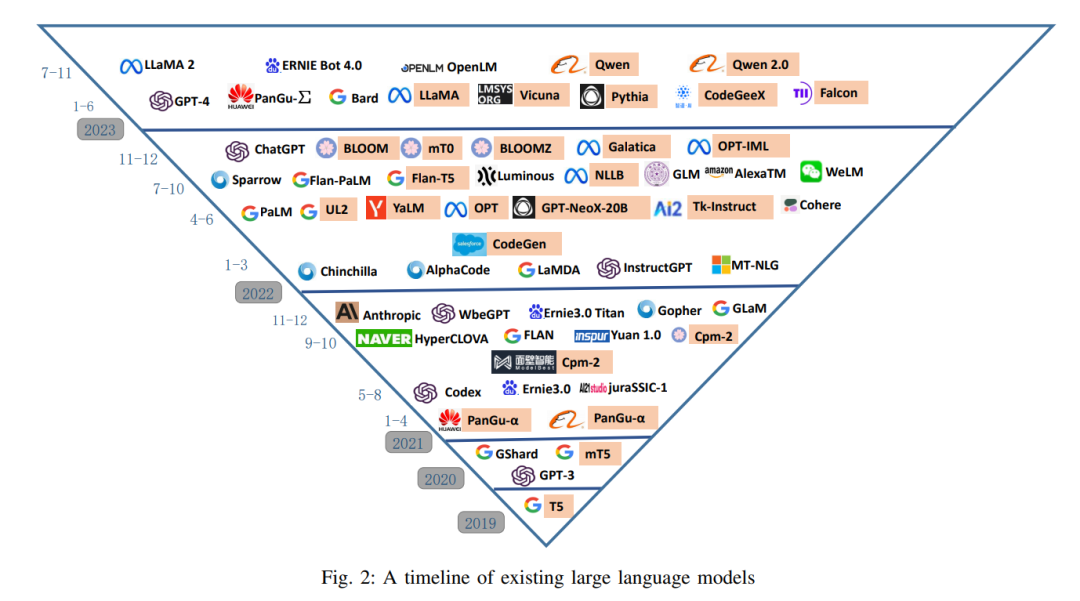
Как показано на рисунке 2, в области моделей больших языков (LLM) наблюдаются многочисленные впечатляющие достижения [294]–[297]. Среди них серии GPT [292], [294], [298], [299], несомненно, являются наиболее известными и эталонными среди LLM. Последняя версия семейства GPT, GPT-4 [292], поддерживает мультимодальный ввод, принимает изображения и текст и генерирует текстовый вывод. Это модель на основе Transformer, предварительно обученная для прогнозирования следующего слова в документе. Последующий процесс тонкой настройки может повысить его фактическую точность и гарантировать, что его производительность соответствует желаемому поведению. GPT-4 продемонстрировал производительность на человеческом уровне в различных профессиональных и академических тестах, особенно в таких областях, как взаимодействие человека и компьютера, образование, медицина и право. Модель LlaMA [300] в настоящее время является самой популярной моделью LLM с открытым исходным кодом и доступна в четырех размерах: 7B, 13B, 30B и 65B. Поскольку LlaMA предварительно обучается на корпусе английского языка, при использовании его обычно необходимо дорабатывать с помощью инструкций или данных на целевом языке, в результате чего получается серия расширенных моделей [301]–[303], которые составляют семейство LlaMA. .
Дорожная карта LSFM в интеллектуальных производственных приложениях
A. Дорожная карта по улучшению возможностей обобщения
- Предварительное обучение в сочетании с тонкой настройкой: когда параметры и размер модели превышают определенный порог.,Эти модели не только демонстрируют невероятную производительность.,Также появились функции, которых не хватало мелкосерийной модели.,такие как способность к логическому рассуждению [294], [340]。существовать Умное В производстве LSFM сочетают предварительное обучение и тонкую настройку, предоставляя множество возможностей для решения традиционных мелкомасштабных задач глубокого освоения. Проблемы, возникающие при методе обучения. LSFM предварительно обучаются на разнообразном наборе общих данных, что снижает зависимость от ограниченного набора данных для конкретной задачи и тем самым снижает риск переобучения, несмотря на большое количество параметров в Модели. Кахатапития и др. [341], учитывая ограниченную доступность данных о сопоставлении видео-текста, применили предварительно обученную Модель изображения-текста к видеодомену для сопоставления видео-текста вместо обучения с нуля. Кроме того, конкретная стратегия тонкой настройки может повысить способность Модели к обобщению, чтобы в дальнейшем избежать чрезмерной подгонки Модели, которая может произойти в процессе точной настройки при обучении на небольшой выборке. Сонг и др. [342] предложил метод, называемый выравниванием дискриминантов признаков (FD Выровнять) метод точной настройки,Улучшите способность к обобщению модели, поддерживая согласованность псевдофункций.,Эффективность демонстрируется как при распределении (ID), так и при распределении (OOD).
- Создание структурированных данных с помощью LSFM: LSFM можно использовать для извлечения и понимания сложных неструктурированных данных.,и закодировать его в управляемый структурированный формат,Например,Обработка неструктурированных текстов в заявке [343]. Модель глубокого поколения (DGM) и такие программы, как VIT. Такая модель, как [304], направлена на обнаружение сложных многомерных распределений вероятностей из неструктурированных данных для извлечения более абстрактных и сложных функций. Оливейра и др. [344] Выделены четыре типа DGM: энергетическая Модель (EBM), Генеративно-состязательная. сеть (GAN), вариационные автоэнкодеры (VAE) и авторегрессионная модель.,и как они применяются к оптимизации управления цепочками поставок (SCM).
- Внедрение знаний посредством подсказок. После того как экспертные знания закодированы, их можно объединить с входными текстовыми или графическими элементами, тем самым повышая точность выходных данных. [345]. Многие LSMF, такие как ChatGPT и SAM, по своей сути включают ручное кодирование подсказок, что позволяет объединять знания предметной области с помощью подсказок без изменений. Например, Моделью может быть сложно описать абстрактную человеческую деятельность за один раз. Поэтому его можно направить на то, чтобы сначала сформировать описания предметной деятельности, выделяя ключевые объекты, отличающие схожие виды деятельности. Затем он может определить категории деятельности человека и помочь интерпретировать контекст. [346]. Кроме того, LSFM могут даже собирать соответствующие знания в предметной области, собирая тематические исследования в процессе обучения. [347]。
- Использование мультимодальных LSFM: Умное Обычно производятся различные формы данных, включая бесплатные текстовые журналы обслуживания, изображения, аудио- и видеозаписи. Присущее этим данным разнообразие очень важно для глубокого Использование одной модальности в обучении Модель представляет собой огромную проблему. Например, Visual-GPT [348] и ImageBind [318] Подобные LSFM стали жизнеспособным решением. Эти модели хороши для одновременного кодирования ряда данных, включая изображения, текст, звук, глубину, тепловую энергию, данные IMU и данные сигналов временных рядов. [349], [350]. Эта расширенная возможность не только обогащает Умное Диапазон данных, захватываемых при производстве, также может наделить LSFM уникальными функциями, такими как кросс-модальный поиск, модальное объединение посредством арифметических операций, а также кросс-модальное обнаружение и генерация. Использование этого широкого спектра LSFM облегчает точную обработку неструктурированных данных и синтез различных источников структурированных данных. В сложных промышленных условиях с множеством характеристик помех LSFM сравнивают с традиционными одномодовыми глубоководными. Метод обучения показывает более высокую надежность, чем другие методы.
- Регуляризация и ансамблевое обучение: LSFM могут решить проблему переобучения с помощью таких методов, как регуляризация и ансамблевое обучение. Регуляризация может ограничить сложность модели.,Обрезка удаляет ненужные узлы и связи.,Ансамблевое обучение может объединить результаты прогнозирования нескольких моделей, чтобы улучшить способность модели к обобщению. Хотя многие LSFM,нравитьсяGPT-3иPaLMсуществовать Не во время тренировкииспользоватьdropout [351], но оно по-прежнему оказывает важное влияние на LSFM. Например, используя отсев во время обучения, Galactica [296] Достигнута модель с параметром 120 миллиардов без переобучения. Более того, чтобы смягчить замедление скорости обучения LSFM из-за отсева, постепенное введение отсева в процессе обучения может дать результаты, сравнимые с постоянным использованием отсева. [352]。
- Непрерывное обучение/Обучение на протяжении всей жизни: Больше всего сейчас в Умном производствовглубокое Модель обучения предполагает, что нормальный шаблон остается неизменным. Однако в производственной среде часто происходят изменения. Непрерывное обучение/обучение на протяжении всей жизни предполагает приобретение и выявление новых знаний при сохранении ранее полученных знаний. LSFM обладают сильной способностью постоянно учиться, собирая результаты прошлых задач в качестве опыта. Благодаря этому процессу LSFM используют предыдущие знания для постоянного самосовершенствования. [347], [353]. Характеристики непрерывного обучения LSFM позволяют им постоянно накапливать новые знания в ходе фактического производственного процесса, чтобы адаптироваться к потенциальным изменениям в сложных реальных условиях. [347], [353]. Эта способность помогает предотвратить переобучение Модели, обученной по фиксированному шаблону. Наложение конкретных ограничений на этот процесс может еще больше улучшить производительность и стабильность Модели. [354]。
- Построение графа знаний с помощью LSFM: Граф знаний — это форма выражения знаний, полученная путем понимания структуры графа. [355]. Однако разработка графов знаний (KGE) требует глубокого понимания структуры графов, логики и содержания знаний, поэтому рабочая нагрузка огромна. глубоко Возможности контекстного понимания и представления обучающего подхода неудовлетворительны, особенно при встрече с совершенно новыми или редкими знаниями. Используя возможности понимания знаний и передовые навыки рассуждения студентов LLM, можно автоматически создавать карты знаний в профессиональных областях. [356] и, как ожидается, улучшит понимание Моделью знаний конкретной предметной области за счет объединения графов знаний с предварительно обученным языком Модели. [357]。
B. Дорожная карта по автоматизированному созданию высококачественных наборов обучающих данных
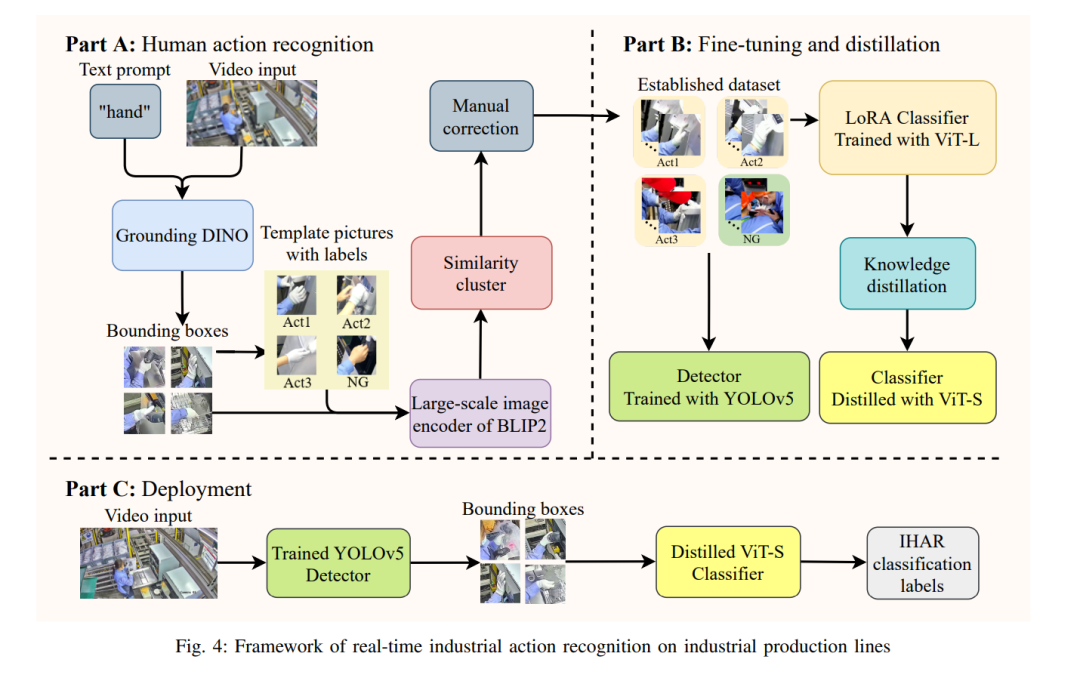
- Создание наборов данных более высокого качества: Создание модели, такой как модель диффузии, может способствовать созданию высококачественных синтетических данных более эффективно, чем традиционные методы синтеза данных. [315]. Используйте модель диффузии текста в изображение, чтобы создавать реалистичные варианты изображений для улучшения данных. В отличие от простых методов улучшения, таких как сращивание, вращение и переворот, улучшение на основе диффузии может изменить семантические атрибуты более высокого уровня, например покраску грузовика. [358]. Чтобы решить проблему, заключающуюся в том, что для обучения самой Модели диффузии требуется большое количество данных, Ван и его коллеги преобразовали двумерную Модель диффузии в трехмерную, используя цепное правило, что позволило генерировать данные трехмерных объектов. [359]. Кроме того, преобразования можно использовать для взвешенного среднего значения или оценки результатов нескольких прогнозов, а также для изучения и моделирования исторических прогнозов для получения более точных прогнозов. В разделе 5 мы покажем, как использовать LSFM для реализации недорогого автоматизированного аннотирования данных для распознавания действий на промышленных производственных линиях.
- Улучшение качества данных: высококачественные данные для обучения Модели и Умного. Принятие решений в производстве имеет решающее значение, и исходные данные часто имеют такие проблемы, как пропущенные значения, выбросы и повторяющиеся значения. LSFM можно использовать для автоматического удаления примесей из данных, уменьшения ошибок прогнозирования и улучшения качества данных. Например, БЛИП [309] Использование промежуточного обучения Модель автоматически удаляет плохо совпадающие пары изображение-текст из набора данных во время обучения и улучшает текстовые аннотации для определенных изображений. Лин и др. [360] Предлагается динамический алгоритм выбора участников цепочки поставок на основе условных генеративно-состязательных сетей (CGAN). Чтобы гарантировать, что производительность классификации не ухудшится, метод классификации участников в цепочке может успешно уменьшить размерность и сложность данных в процессе классификации.
- Нулевые образцы и малое количество образцов. Основная проблема при обнаружении промышленных дефектов — отсутствие аномальных образцов. Аномалии в промышленных продуктах часто разнообразны и непредсказуемы. LSFM может эффективно обеспечить обнаружение с нулевой выборкой или обнаружение с небольшим количеством выборок. Гу и др. [324] исследовали использование крупномасштабной визуально-лингвистической модели (LVLM) для решения проблем обнаружения промышленных аномалий и предложили новый метод обнаружения промышленных аномалий на основе LVLM — AnomalyGPT. В наборе данных для обнаружения аномалий MVTec AnomalyGPT может достичь точности 86,1 %, AUC на уровне изображения 94,1 % и AUC на уровне пикселей 95,3 %, используя только один нормальный образец. Этот метод приложения больше не требует сбора аномальных образцов или создания наборов данных для каждой задачи для обучения конкретной модели и требует лишь небольшой точной настройки данных для достижения хороших результатов обнаружения. Например, в области прогнозного обслуживания Leite et al. [361] использоватьLLMsКлассифицировать сигналы достоверности,Эти сигналы часто используются для оценки достоверности прогнозов. Метод на основе LLM превосходит современные классификаторы по двум наборам дезинформационных данных.,Нет необходимости в каких-либо настоящих этикетках.
- Предварительное обучение в сочетании с тонкой настройкой: Несмотря на некоторую предварительную работу для Умного сцена производства предлагает эпизоды данных, такие как HAR [362]–[364], контроль качества [365]–[367] и ПХМ [368], [369], но эти наборы данных характеризуются небольшим масштабом, узким охватом, одной сценой, простыми условиями эксплуатации и неравномерным распределением данных. LSFM предварительно обучены работе с широким спектром данных и могут определять общие характеристики объектов реального мира, что обеспечивает точное и гибкое Умное в средах с ограниченным объемом данных. производство предлагает эффективные решения [294]. Предварительно обученная Модель, обученная на крупномасштабных данных, затем настраивается на мелкомасштабных данных, чтобы повысить точность Модели и возможности обобщения. Например, Сан и др. [370] BERT использовался для медицинских текстов и достиг хороших результатов, используя только небольшие наборы данных для точной настройки. Аналогично, Рэдфорд и др. [299] Он демонстрирует возможности трансферного обучения GPT в различных задачах.
C. Дорожная карта достижения совершенства в производительности
- Улучшение с помощью советов: обычно,После завершения обучения,глубокое Обучение Модель больше не получает «руководства», а вместо этого делает выводы на основе обученных параметров. Однако LSFM обладают отличными возможностями интеграции данных и могут повысить производительность вывода за счет использования различных форм сигналов. Джи и др. [321] Было обнаружено, что качество сигналов оказывает существенное влияние на точность LSFM. Чтобы решить проблему неоптимальной сегментации SAM в небольших масштабах и с неровными границами, можно использовать несколько подсказок для получения более точных результатов сегментации на основе распределения. [371]. В частности, Дэн и др. [372] Прогнозируемое распределение SAM оценивается с использованием моделирования Монте-Карло параметров предыдущего распределения. Этот подход позволяет оценивать произвольные неопределенности, рассматривая несколько прогнозов для одного изображения. Альтернативно, сеть также может использоваться для получения расширенных сигналов, генерации улучшенных сигналов путем ввода исходных сигналов для создания масок, а затем вывода улучшенных сигналов. Производительность сегментации можно повысить, объединив эти признаки с новыми. [373]. К разделению генерации маски и внедрению подсказок также следует относиться с осторожностью, чтобы предотвратить негативное влияние вводящих в заблуждение подсказок на генерацию маски. [370]。
- Расширенные входные данные: в LSFM,Термин «базовый» указывает на то, что LSFM могут легко служить основой для комбинации с другими алгоритмами. Это гарантирует, что даже если LSFM будут работать плохо при использовании отдельно,Хорошая производительность по-прежнему может быть гарантирована за счет комбинирования с другими алгоритмами.производительность。Например,Модель визуального языка (VLM) демонстрирует высокую устойчивость к различным типам повреждений.,но некоторый ущербнравиться Повреждения, связанные с неоднозначностью, могут привести к Модельпроизводительностьотклонить [374]. Кроме того, ЗРК оказался недостаточным в скрытных и замаскированных сценариях. [200], [375]. К счастью, существует множество исследований по устранению размытия. [376]–[378] и технические исследования по обнаружению целей в скрытых и замаскированных местах [379], [380]。какLSFMsХарактеристикии Одно из преимуществ,VLM можно легко комбинировать с другими моделями.,Используйте предварительно обработанные данные в качестве входных данных или поля обнаружения других детекторов объектов в качестве подсказок.
- Кросс-модальное предварительное обучение: LSMF преодолевают глубокие препятствия Ограничение одной задачи и одной модальности в обучении позволяет реализовать многозадачные и многомодальные приложения за счет унификации модели после кросс-модального предварительного обучения. [381]. Распознавание и обнаружение объектов открытого набора может быть достигнуто за счет использования контрастных потерь во время обучения для установления ассоциаций между функциями изображения и текста. [310]–[312]. Это предотвращает ограничение задач при обучении предопределенными категориями. Чтобы достичь удовлетворительной производительности перед обучением, успех зависит от размера кросс-модального набора данных. [381], [382] А Модель использует способность слабо выравнивать данные. [383]. Ли и др. [384] использоватьпредварительная подготовка Модель Слабо контролируемая классификация видео по меткам в промышленных системах,для измерения семантического сходства видео. Добавив расширенный кросс-модальный модуль Transformer,Они максимально используют интерактивную информацию между функциями видео и текстур.
- Предварительная тренировка в сочетании с тонкой настройкой: с глубоким По сравнению с неудовлетворительной точностью, достигаемой при ограниченных данных и сложных конвейерах, крупномасштабное предварительное обучение не только дает LSFM сильные возможности обобщения, но также дает им потенциал для более высокой точности. [294], [340]. Хотя непосредственное использование предварительно обученных LSFM не всегда может превосходить специально разработанные глубокие нейронные сети. [321], но со специфическим Умным data набор полей данных data Эффективная точная настройка может повысить их точность. [385], [386], потенциально превосходя существующие глубоководные обучение Модель。картинаP-Tuning [387]、Lora [388]、QLora [389] и другие технологии облегчают процесс тонкой настройки LSFM.
- Кроме того, глубокое обучается на наборе данных ансамбля. обучение Модель увеличивает риск утечки данных. Использование предварительно обученных LSFM в качестве решения может повысить безопасность данных и снизить риски конфиденциальности, вызванные большим количеством данных, необходимых для обучения Модели с нуля. Эти предварительно обученные модели позволяют получать эффективные результаты с минимальной тонкой настройкой, тем самым уменьшая воздействие конфиденциальных данных. На этапе тонкой настройки необходимо настроить ограниченные части сети LSFM и внедрить технологию дифференциальной конфиденциальности. В частности, Абади и др. [390] Предложенная методика была применена в процессе доводки. Эти меры могут сохранить конфиденциальность процесса тонкой настройки LSFM и обеспечить более безопасную среду обучения.
- Внедрить распределенное обучение: данные в производстве не так доступны, как естественный язык и другие области, поэтому применяется подход распределенного обучения. [391] Ибо в Умном LSFM, используемые в производстве, могут иметь преимущества как с точки зрения обучения, так и с точки зрения безопасности, поскольку данные обучения можно получить с разных производственных линий, заводов и даже стран. Методы распределенного обучения, такие как федеративное обучение, включают локальную обработку данных для каждой стороны, при этом для обновлений модели агрегируются только промежуточные результаты (например, градиенты). Это позволяет клиентам (устройствам или организациям) совместно обучать Модель машинного обучения, не раскрывая ее данные, что значительно повышает эффективность использования данных. [392], [393]. Сочетание этих технологий позволяет LSFM не только превосходить традиционные методы с точки зрения производительности, но и обеспечивать более безопасную среду обработки при работе с конфиденциальной промышленной информацией.
- Объясните, используя результаты самого LSFM: поскольку процесс принятия решений очень абстрактный и неинтуитивный, Модель обучения часто называют «черным ящиком». LSFM, особенно LLM, демонстрируют превосходное понимание контекста в задачах, поэтому потенциально возможно попытаться использовать LLM для объяснения Модели. В исследовании Бубека и др. [274] обнаружили, что LLM демонстрируют высокую согласованность результатов в своих результатах, а это означает, что Модель следует фиксированному шаблону «мышления». Таким образом, задавание вопросов GPT в чате, таких как «пожалуйста, объясните причины ваших прогнозов», оказалось эффективным, особенно после разумных предварительных вопросов. Эту идею также можно применить к модели, основанной на структуре кодера. [394] устраняют ограничения AE, выполняя анализ смещения реконструированных входных признаков для получения объяснений. [395]。
- использоватьLLMобъясни другое Модель:LLMsс мощнымтекстспособность,Знания, полученные от LLM, можно использовать для интерпретации других нейронных сетей. чтобы добиться этого,LLMsиспользуется для обобщенияи Рейтинг для анализа Модель Выход [396]. Кроме того, LLM можно использовать для создания или сопоставления контрфактических данных, моделирования или оценки различных вариантов событий или действий, чтобы лучше понять прогнозируемые результаты Модели. [397]. В качестве альтернативы, встраивание LLM непосредственно в обучение Модели может обеспечить эффективный вывод, одновременно обеспечивая хорошую интерпретируемость. [398]。
- Визуализация текущего процесса: извлечение карт промежуточных признаков из выходных данных нейронной сети может помочь понять Модельсосредоточиться. Что касается функций, даже эти карты функций могут оставаться очень абстрактными. Используя механизм самообслуживания и связь токенов в своей архитектуре, визуальное внимание может дать более интуитивное объяснение, чем карты объектов. Силу связи внимания можно интуитивно рассматривать как показатель вклада каждого токена в классификацию. Визуальное внимание помогает понять интересную часть Модели. [399]. Учитывая, что LSFM в основном основаны на структурах преобразователей, многообещающе визуализировать вывод внимания, чтобы улучшить интерпретируемость LSFM.
в заключение
LSFM демонстрируют сильную способность к обобщению, способность автоматически генерировать высококачественные наборы обучающих данных и превосходную производительность, а также могут преобразовать искусственный интеллект из одномодальной, однозадачной и ограниченной парадигмы обучения данных в многомодальную, многозадачную, масштабная Модель предварительной подготовки данных и их последующей точной настройки определенно приведет к новой волне изменений в интеллектуальном производстве. Ввиду проблемы, связанной с тем, что исследования по применению LSFM в интеллектуальном производстве все еще находятся в зачаточном состоянии и им не хватает систематического направленного руководства, в этой статье обобщаются прогресс и проблемы глубокого обучения в интеллектуальном производстве, а также прогресс и потенциальные преимущества LSFM в интеллектуальном производстве. интеллектуальные производственные приложения. Исходя из этого, в данной статье всесторонне обсуждается, как создать систему LSFM, подходящую для области интеллектуального производства с точки зрения универсальности, данных и производительности, а также рассматривается фактическое применение производственной линии Midea Group в качестве примера, чтобы проиллюстрировать, как применение LSFM могут помочь предприятиям повысить эффективность и сократить расходы.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
