Колонка для рисования AI: стабильная диффузия SDXL 1.0, изменяющая лицо руп easyphoto (24)
Следующее взято из официальной документации сайта.
Поддерживает использование моделей SDXL и некоторых опций для прямого создания больших изображений высокой четкости. Нет необходимости загружать шаблоны, требуется 16 ГБ видеопамяти.
SDXL--TXT2video
вторая версия
1. Руководство по установке и использованию 2.
Предисловие к изучению
В области визуального направления AIGC,AI-фото — надежное и проверенное решение,вместе сStableDiffusionполеСообщество открытого исходного кодабыстрое развитие,Подобные сообщества возникли FaceChain Это основано на Сообщество открытого исходного кода Modelscope объединяет diffusers Проект с открытым исходным кодом, помогающий пользователям быстро создавать личные портреты.
Однако для большого количества студентов AIGC, использующих SDWebUI, не существует подключаемого модуля с открытым исходным кодом, который был бы достаточно эффективен и за короткий период времени мог бы адаптироваться к функции реальных фотографий.
Для фотографии с искусственным интеллектом,Необходимо обратить внимание на два важных момента,Надо быть сИзображение пользователя,кроме того Один обязательнореальность。
Недавно я участвовал в проекте EasyPhoto, который может создавать соответствующие портреты пользователей на основе шаблонных изображений с помощью Stable. DiffusionиLoraМощная генерирующая способность,Создание изображений может сделать жилье относительно похожим и реалистичным.,Недавно он также был открыт в открытом доступе.
Адрес загрузки исходного кода
https://github.com/aigc-apps/sd-webui-EasyPhoto
Друзья, пожалуйста, поставьте мне звездочку, для меня это все равно очень важно!
Технический резерв (SD/Control/Lora)
StableDiffusion
StableDiffusion — это модель генерации изображений с открытым исходным кодом Stability-AI, обычно разделяемая на SD1.5/SD2.1/SDXL и другие версии. Это модель диффузии в сочетании с текстовым руководством путем обучения большого количества пар изображений и текста. В обученной модели посредством извлечения признаков выполняется входной текст, а модель распространения направляется для создания высококачественных изображений, соответствующих входной семантике, за несколько итераций. Изображение ниже — их эффект, опубликованный на официальном сайте Stable Diffusion.
EasyPhoto AI основан на богатом сообществе StableDiffusion с открытым исходным кодом и мощных возможностях генерации для создания реалистичных и естественных портретов AI.

ControlNet
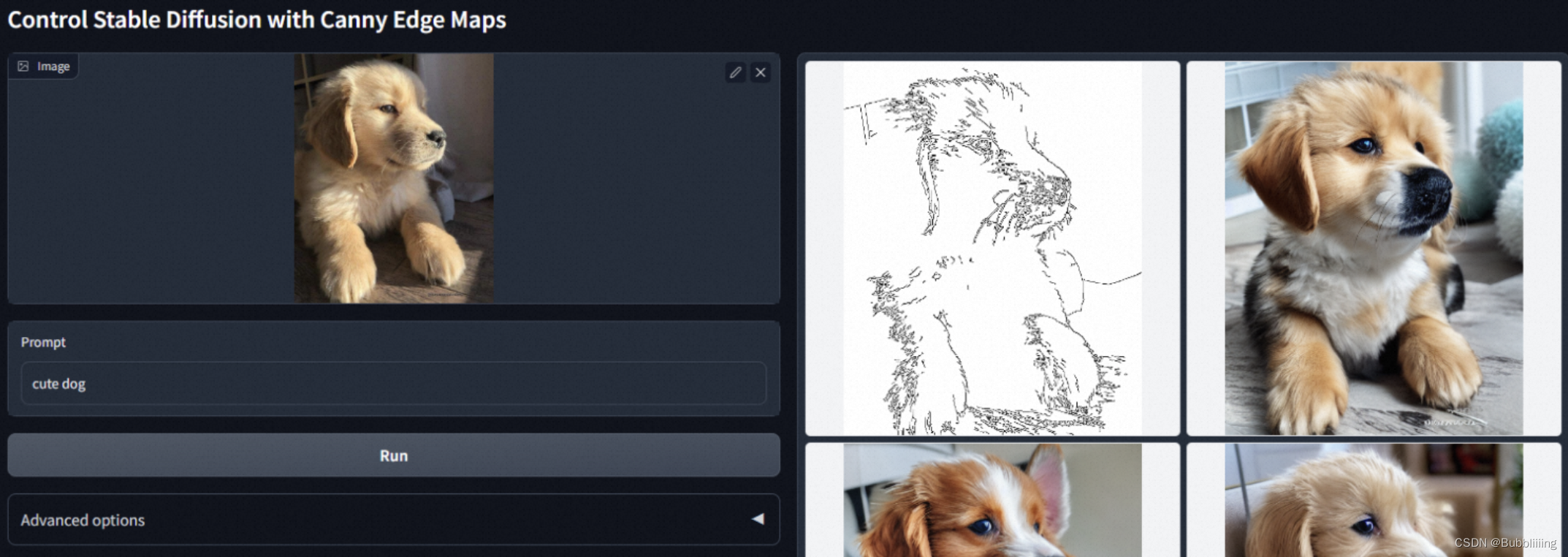
ControlNet предлагается в разделе «Добавление условного управления к моделям диффузии текста в изображение» путем добавления некоторых обученных параметров для расширения модели StableDiffsion для обработки некоторых дополнительных входных сигналов, таких как карты скелета/карты краев/карты глубины/изображения положения человеческого тела и другие входные данные используются для завершения использования этих дополнительных входных сигналов, чтобы направлять модель диффузии для создания контента изображения, связанного с сигналами. Например, как мы видим в официальном репо, край Canny используется в качестве сигнала для управления выходным щенком.
Основываясь на мощных возможностях управления нескольких сетей Controlnet, EasyPhoto создает очень естественные фотоизображения, сохраняя при этом характеристики исходного шаблона (такие как цвет, освещение и контур).
Lora
Из «Лора: Low-Rank Adaptation of Large Language Models》 Предложен метод тонкой настройки малого числа параметров для моделей с большими параметрами на основе матриц низкого ранга, широко цитируемый в различных крупных публикациях. дальнейшее использование модели. Портреты реальных людей с помощью ИИ должны гарантировать, что окончательно сгенерированное изображение будет похоже на человека, которого мы хотим создать, что требует от нас использования Lora. Технология, проведем простое обучение на небольшом количестве входных картинок, чтобы мы могли получить небольшое обозначенное лицо (Face идентификатор) модель.
Знакомство с плагином EasyPhoto
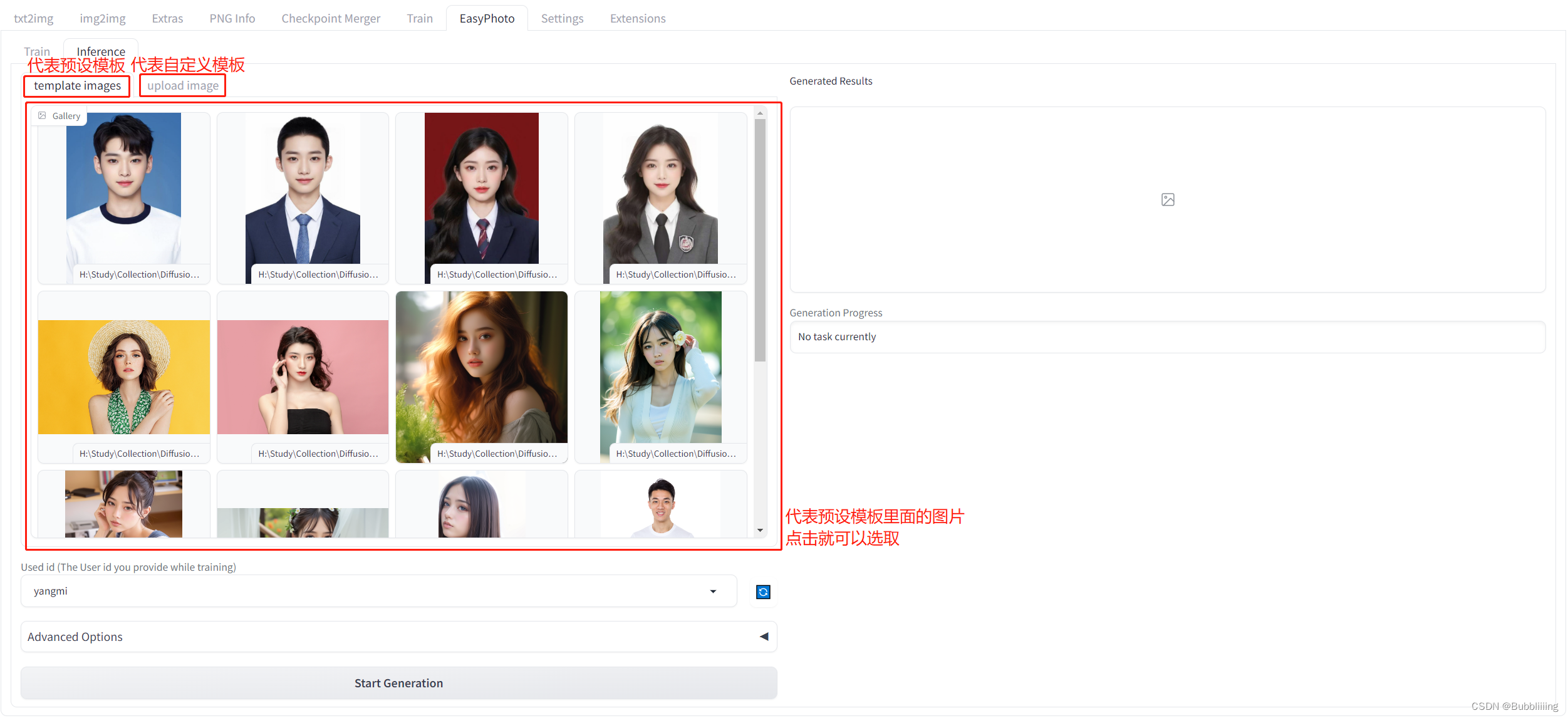
EasyPhoto — это плагин пользовательского интерфейса Webui для создания портретов с использованием искусственного интеллекта, а код можно использовать для обучения цифровых аватаров, связанных с пользователем. Для обучения рекомендуется использовать от 5 до 20 портретных изображений, желательно фото в пояс без очков (допустимо небольшое количество). После завершения обучения EasyPhoto может генерировать изображения в части вывода. EasyPhoto поддерживает использование предустановленных шаблонных изображений и загрузку собственных изображений для анализа.
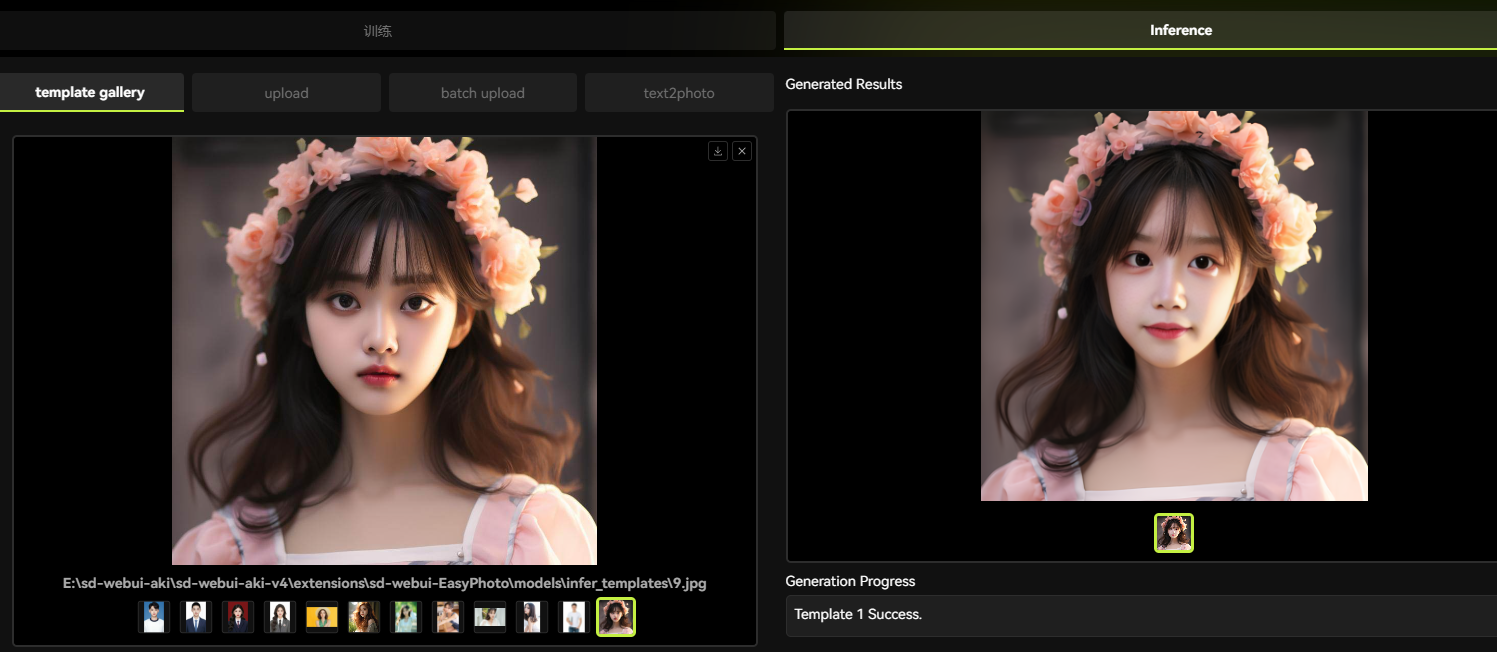
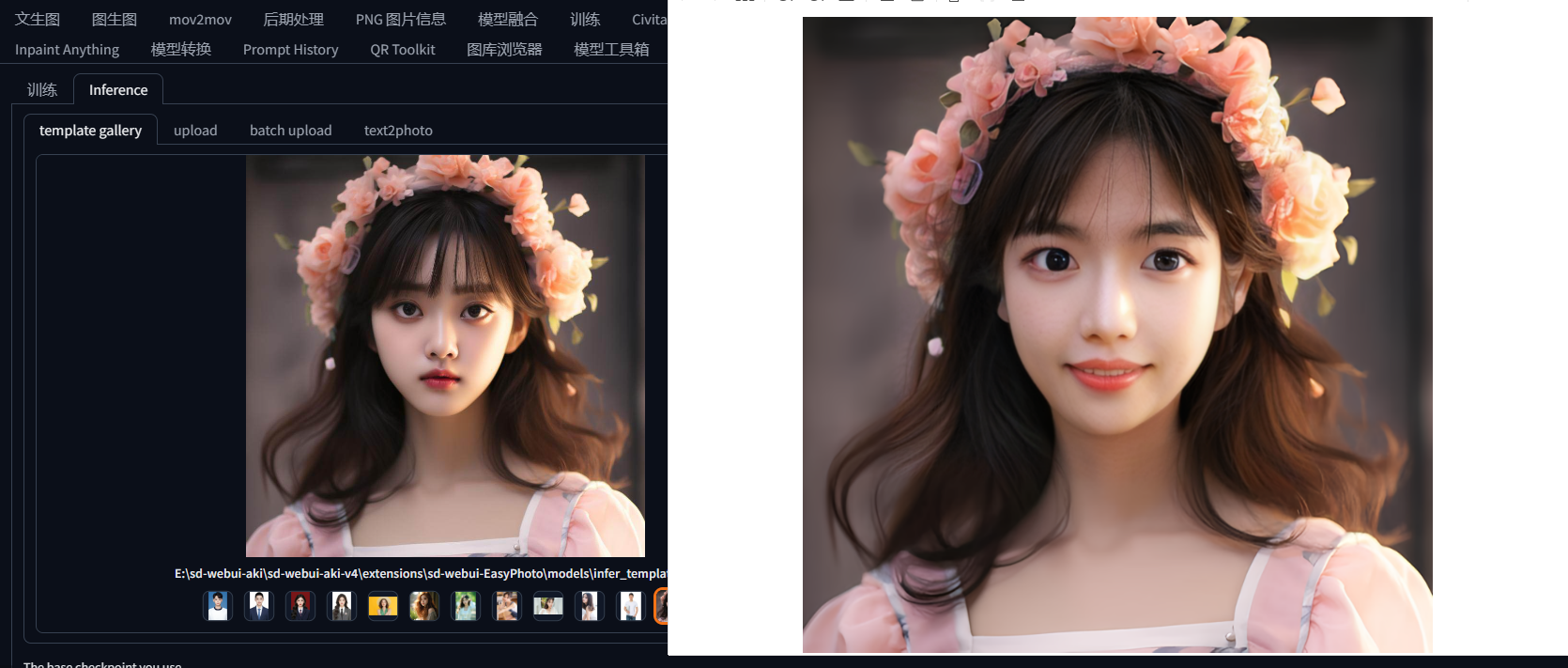
Вот результаты генерации плагина. Судя по результатам генерации, эффект генерации плагина по-прежнему очень хорош:

За каждым изображением стоит шаблон, и EasyPhoto изменит шаблон в соответствии с характеристиками пользователя. В плагине EasyPhoto некоторые шаблоны предварительно настроены на стороне вывода, и вы можете использовать предустановленные шаблоны плагина, чтобы испытать его, кроме того, EasyPhoto также может настраивать шаблоны, и на панели есть еще одна вкладка; Сторона вывода, которую можно использовать для загрузки индивидуальных шаблонов. Как показано ниже.
Перед прогнозированием вывода нам необходимо провести обучение. Обучение требует загрузки определенного количества личных фотографий пользователя. Результатом обучения является модель Лора. Эта модель Лоры будет использоваться для прогнозирования вывода.
Таким образом, процесс выполнения EasyPhoto очень прост: 1. Загрузите изображения пользователя и обучите модель Лоры, связанную с пользователем; 2. Выберите шаблон для прогнозирования и получите результаты прогнозирования.
Установка плагина EasyPhoto
Способ установки первый: установка интерфейса Webui (требуется хорошая сеть)
Процесс установки относительно прост. Если с сетью все в порядке, перейдите в раздел «Расширения» и выберите «Установить». from URL。 Введите https://github.com/aigc-apps/sd-webui-EasyPhoto.,Нажмите «Установить» ниже, чтобы установить,В процессе установки,Автоматически установит пакет зависимостей,Вам нужно терпеливо ждать этого.。После установки необходимо перезапустить WebUI.
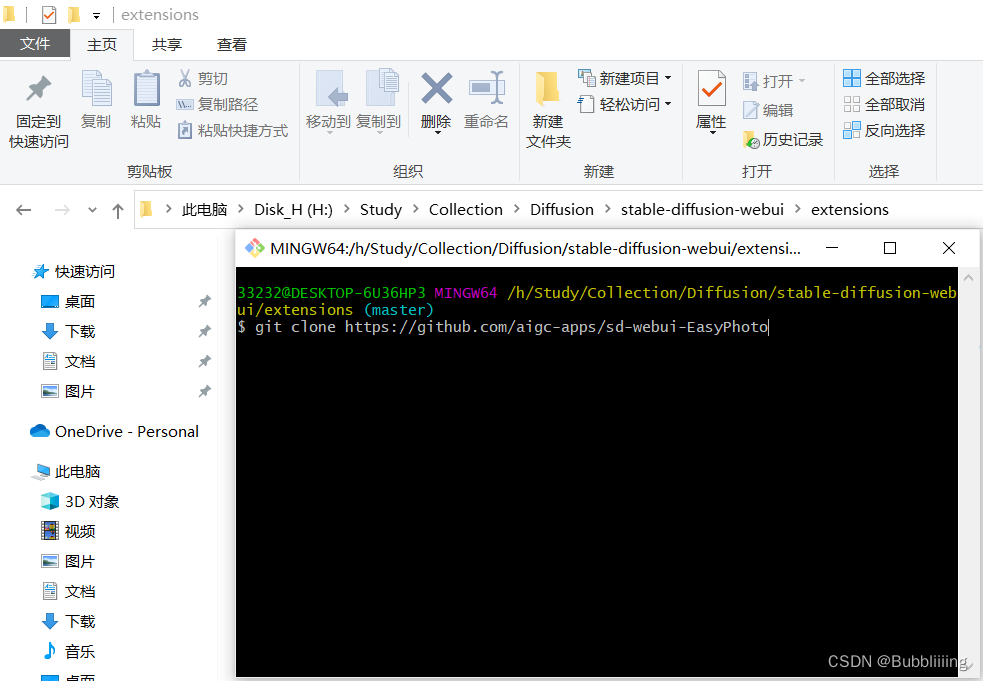
Второй способ установки: загрузка и установка клона Git (процесс клонирования будет отображать ход установки).
Перейдите непосредственно в папку расширений Webui, откройте инструмент git и клонируйте git. После завершения загрузки перезапустите webui, и необходимые библиотеки среды будут проверены и установлены.
Другая установка плагина: установка Controlnet
нам нужно использовать Controlnet делать выводы。Соответствующие источники программного обеспечения:Mikubill/sd-webui-controlnet。существоватьиспользовать EasyPhoto Прежде вам необходимо установить этот источник программного обеспечения.
Кроме того, нам нужно как минимум три Controlnets для рассуждения. Поэтому вам необходимо установить Multi ControlNet: Max models amount (requires restart)。
Обучение EasyPhoto
Интерфейс обучения EasyPhoto выглядит следующим образом:
- Слева — тренировочное изображение, прямо нажмите. Загрузить Фотографии, чтобы загрузить фотографии, нажмите Очистить Фотографии могут удалять загруженные изображения;
- Правая часть — параметры тренировки. Для первой тренировки настраивать параметры не нужно.
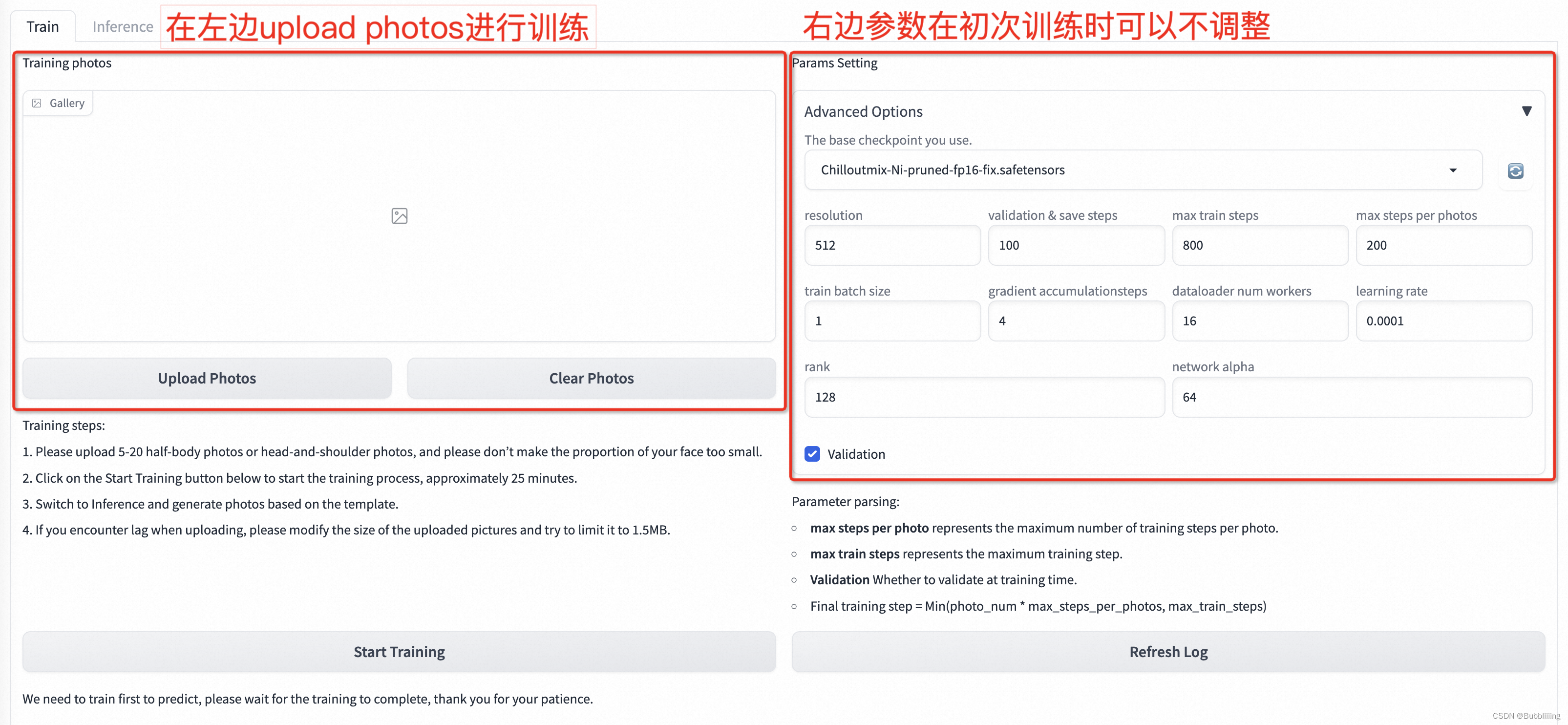
1. Загрузите фотографии
Нажмите Загрузить фотографии, чтобы начать загрузку фотографий.,Здесь лучше загрузить 5-15 фотографий, включая разные ракурсы и разные условия освещения. Я использовал 7 фотографий;,Лучше всего иметь несколько изображений без очков. Если все они являются очками, в сгенерированных результатах можно легко создать очки.。
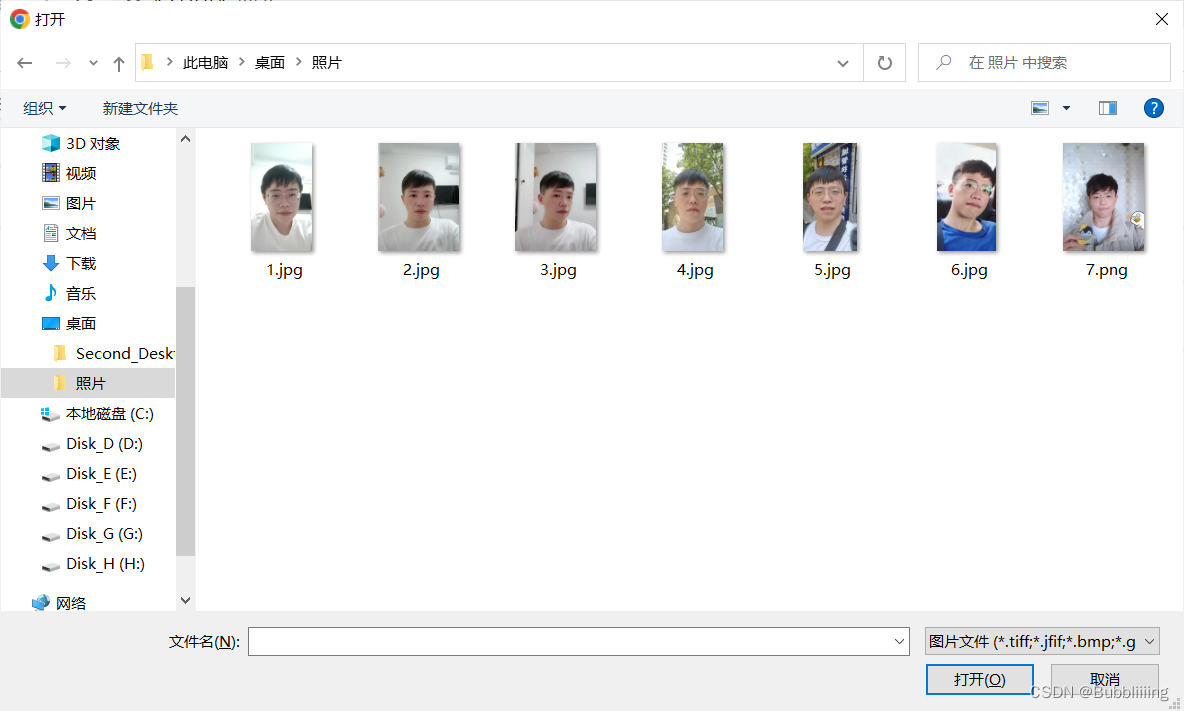
После завершения загрузки мы сможем увидеть загруженные изображения в интерфейсе!
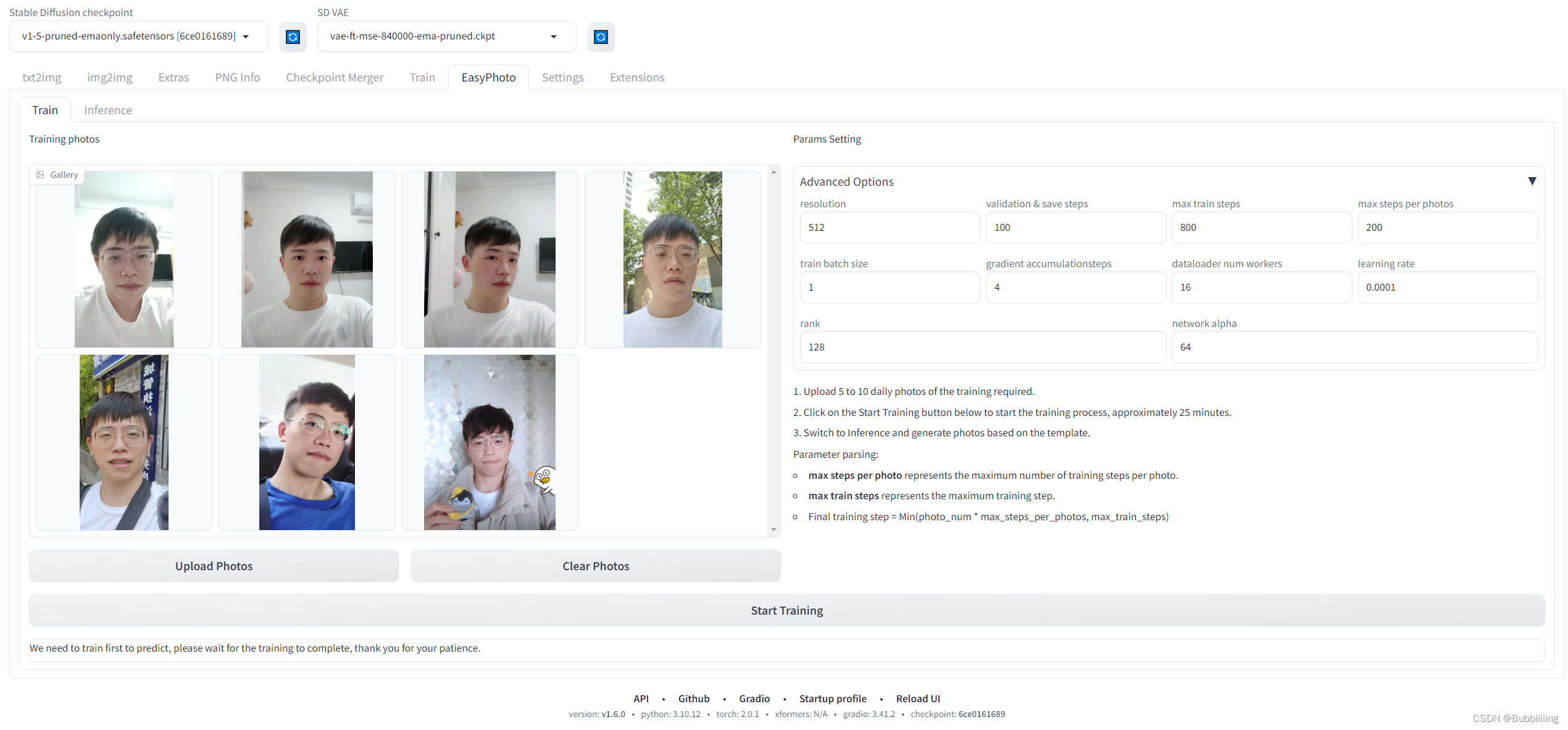
2. Настройки параметров (дополнительные параметры)
а. Анализ параметров по умолчанию.
Затем давайте посмотрим на раздел настройки параметров справа. Здесь можно настроить довольно много параметров. При первом обучении никаких настроек производиться не будет. Анализ каждого параметра выглядит следующим образом:
<!--br {mso-data-placement:same-cell;}--> td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
Имя параметра | значение |
|---|---|
resolution | Размер изображений, подаваемых в сеть во время обучения, значение по умолчанию — 512. |
validation & save steps | Количество шагов для проверки изображения и сохранения промежуточного веса. Значение по умолчанию — 100, что означает, что изображение проверяется и вес сохраняется каждые 100 шагов. |
max train steps | Максимальное количество шагов обучения, значение по умолчанию — 800. |
max steps per photos | Максимальное количество раз обучения для каждого изображения, по умолчанию — 200. |
train batch size | Размер пакета для обучения, значение по умолчанию — 1. |
gradient accumulationsteps | Следует ли выполнять накопление градиента, значение по умолчанию — 4, в сочетании с размером пакета поездов, каждый шаг эквивалентен подаче четырех изображений. |
dataloader num workers | Количество работ по загрузке данных не действует в Windows, поскольку будет сообщено об ошибке, если установлено, что Linux может установить его нормально. |
learning rate | Скорость обучения Лоры, по умолчанию 1e-4. |
rank Lora | Длина функции веса, по умолчанию — 128. |
network alpha | Параметр регуляризации для обучения Лоры, обычно половина ранга, по умолчанию 64. |
Формула расчета конечного количества шагов обучения также относительно проста: Последний шаг обучения = Min(photo_num * max_steps_per_photos, max_train_steps).
Чтобы просто понять, это: Когда количество изображений небольшое, количество шагов обучения равно photo_num. * max_steps_per_photos。 Когда количество изображений велико, количество шагов обучения равно max_train_steps.
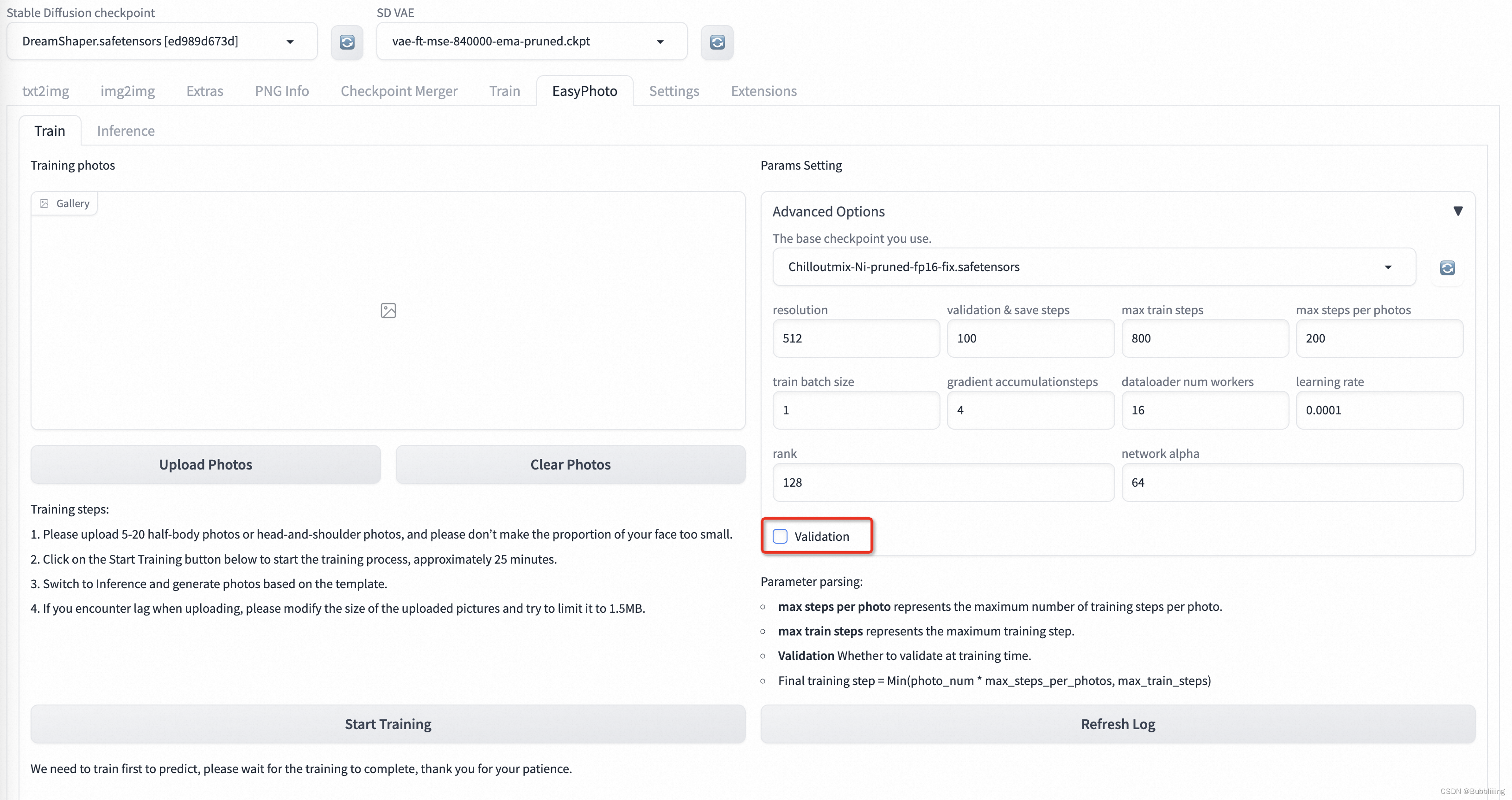
б. Включить или отключить проверку.
EasyPhoto по умолчанию проверит процесс обучения во время обучения, а затем объединит лучшие Lora на основе результатов проверки во время процесса обучения.
Но это проверять Это легко вызвать, когда видеопамяти недостаточно. застрявший,А поскольку частота проверки больше,Будет влиять на определенную скорость обучения,Если машина недостаточно сконфигурирована,Вы можете попробовать отключить проверку, чтобы ускорить обучение.
3. Начать обучение
а. Заполните идентификатор пользователя.
Затем мы нажимаем «Начать обучение» ниже. На данный момент нам нужно ввести указанный выше идентификатор пользователя, например имя пользователя, и тогда мы сможем начать обучение.

б. Вес загрузки
При запуске начального обучения часть весов будет загружена с oss. Нужно только терпеливо ждать. Вероятно, на загрузку уйдет около 10G ресурсов. Нужно следить за ходом загрузки терминала.
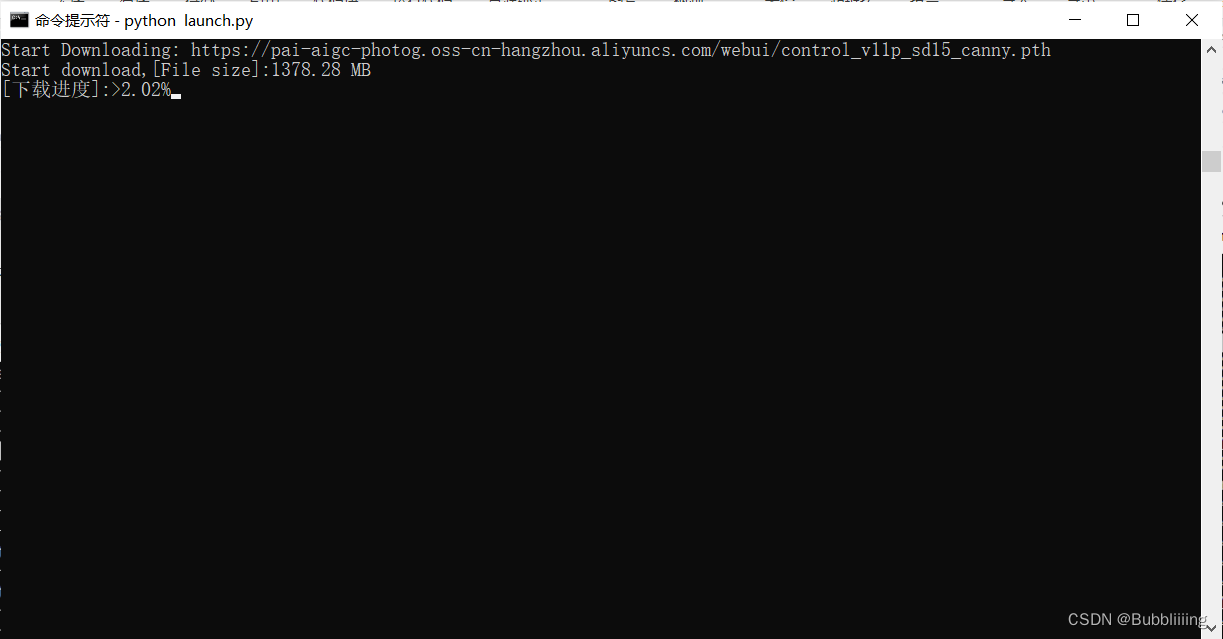
в.Начать обучение
После завершения автоматической предварительной обработки модель Лора начинает обучение. Нам просто нужно терпеливо дождаться завершения обучения!
d. Проверка очков
Когда терминал отобразит такое сообщение, обучение завершено. Последний шаг — вычислить идентификатор лица между проверяемым изображением и изображением пользователя. Это идеальный цифровой двойник для пользователя.
Вообще говоря, сходство оценки выше 0,50 является нормальным. Если оценка ниже 0,10, вам необходимо проверить среду, возможно, модель не обучена, поскольку среда неверна.
Прогноз EasyPhoto
1. Выбор идентификатора пользователя
После обучения нам нужно переместить вкладку на Inference. Из-за особенностей Gradio новая обученная модель не будет автоматически обновляться. Вы можете нажать синюю вращающуюся кнопку рядом с используемым идентификатором, чтобы обновить модель.
После обновления выберите модель, которую вы только что обучили.,Затем выберите соответствующий шаблон, чтобы начать прогнозирование.
2. Выбор шаблона
а. Шаблон по умолчанию (изображение шаблона)
В хранилище EasyPhoto есть несколько предустановленных шаблонов. Просто нажмите на изображение шаблона, чтобы выбрать шаблон для прогнозирования.
б. Загрузить шаблон (загрузить изображение).
Содержимое предустановленного шаблона относительно ограничено. Вы можете переключиться на загрузку изображения и напрямую загрузить шаблон для прогнозирования.
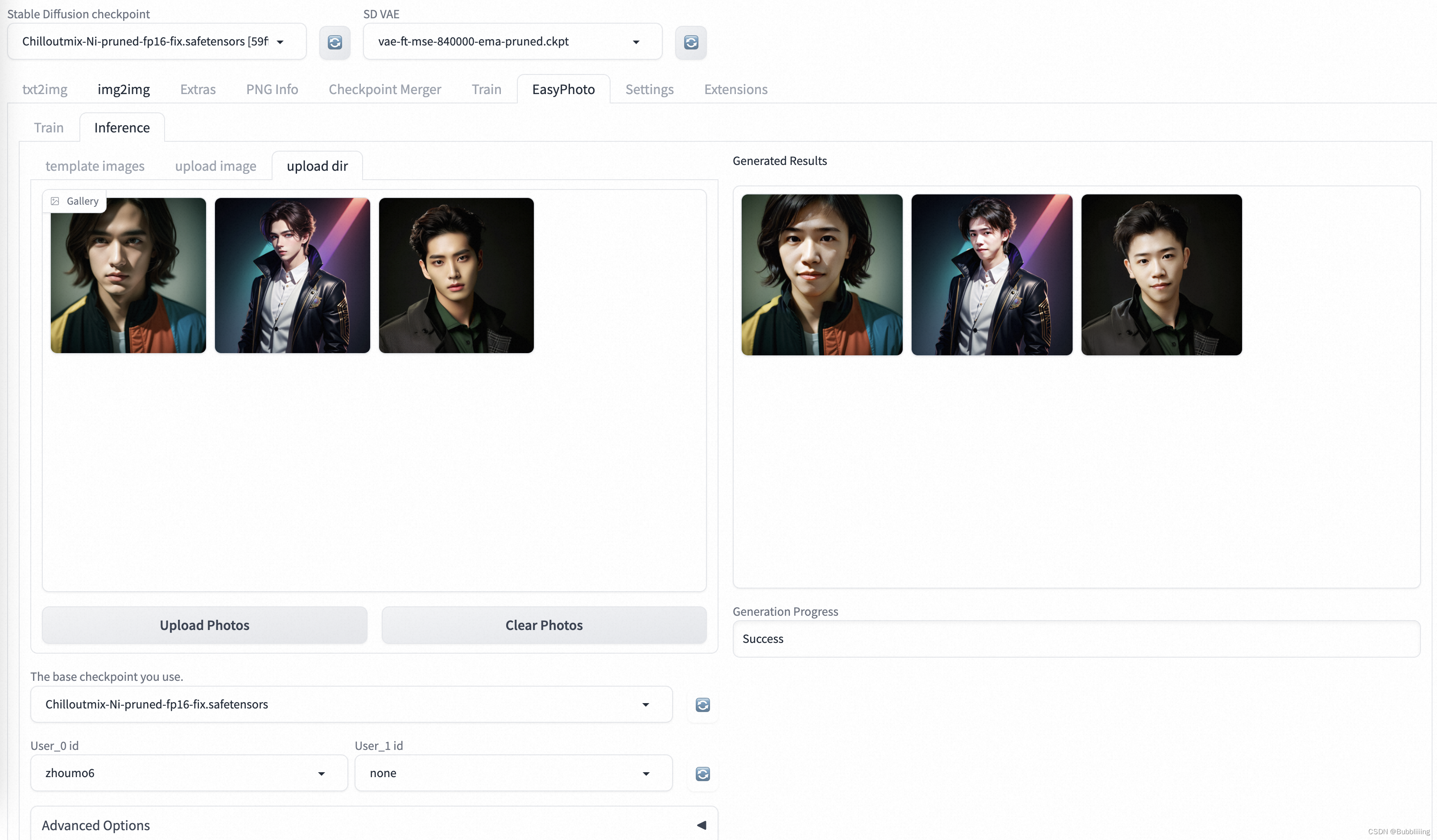
c. Загрузите несколько изображений для пакетного прогнозирования (каталог загрузки).
Нажмите «Каталог загрузки», чтобы загрузить несколько изображений для пакетного прогнозирования. После завершения загрузки нажмите «Начать генерацию», чтобы создать пакеты.
Генерация пакета занимает много времени, наберитесь терпения.
3. Дополнительные параметры (настройка параметров)
Расширенные параметры включают в себя различные параметры, которые можно установить в прогнозе. Вероятно, это следующие параметры. Настройте их в зависимости от ситуации.
<!--br {mso-data-placement:same-cell;}--> td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
Имя параметра | Объяснение параметра | Скорректированное воздействие |
|---|---|---|
Additional Prompt | Слова прямой подсказки будут переданы в модель стабильной диффузии для прогнозирования. | Вы можете настроить слово-подсказку в соответствии с элементами, которые хотите добавить. |
Seed | семенная ценность. | Он используется для обеспечения воспроизводимости результатов. Если он равен -1, исходное число будет выбрано случайным образом. |
Face Fusion Ratio Before | Сила первого слияния граней. | Корректировка повлияет на сходство персонажа. Вообще говоря, чем больше значение, тем выше сходство с тренировочным персонажем. |
Face Fusion Ratio After | Сила слияния второго лица. | Корректировка повлияет на сходство персонажа. Вообще говоря, чем больше значение, тем выше сходство с тренировочным персонажем. |
First Diffusion steps | Общее количество шагов для стабильной диффузии в первый раз. Первый Diffusion в основном регулирует область портрета, чтобы сделать портрет более естественным. | Регулировка повлияет на качество изображения и скорость вывода изображения. Как правило, чем больше значение, тем выше качество изображения и тем медленнее оно выводится. |
First Diffusion denoising strength | Впервые перерисовываю пропорции Стабильной Диффузии. | Регулировка повлияет на коэффициент перерисовки и скорость рендеринга изображения. Как правило, чем больше значение, тем значительнее изменение портрета. |
Second Diffusion steps | Общее количество шагов для второй стабильной диффузии. Второй Diffusion в основном корректирует область вокруг портрета, чтобы сделать изображение более гармоничным. | Регулировка повлияет на качество изображения и скорость вывода изображения. Как правило, чем больше значение, тем выше качество изображения и тем медленнее оно выводится. |
Second Diffusion denoising strength | Второй раз перерисовываю пропорции Стабильной Диффузии. | Регулировка повлияет на коэффициент перерисовки и скорость рендеринга изображения. Как правило, чем больше значение, тем больше изменений вокруг портрета. |
Crop Face Preprocess | Обрезать ли портрет перед обработкой. | Рекомендуется включить эту функцию. Если входное изображение представляет собой большое изображение, сначала будет обрезана область портрета, а затем результат настройки будет более точным. |
Apply Face Fusion Before | Следует ли выполнять первое слияние граней. | После настройки это повлияет на необходимость выполнения первого слияния лиц и сходства портрета. |
Apply Face Fusion After | Следует ли выполнять второе слияние граней. | После настройки это повлияет на необходимость выполнения слияния второго лица и сходства портрета. Если портрет кажется слабым, отмените слияние. |
Apply color shift first | Следует ли выполнять коррекцию цвета после первого DIffusion. | Регулировка повлияет на естественность портрета на снимке. |
Apply color shift last | Следует ли выполнять коррекцию цвета после второго DIffusion. | Регулировка повлияет на естественность портрета на снимке. |
Background Restore | Следует ли выполнять фоновую реконструкцию. | После его включения можно реконструировать фон за пределами портретной области, что может сделать всю картинку более гармоничной при использовании анимированных моделей. |
4. Прогноз для одного человека
После выбора пользователя После ввода идентификатора и шаблона нажмите «Старт». generationНачать прогнозировать。Для первого прогноза вам необходимо загрузить несколько моделей modelscope.,Просто подождите терпеливо.
Подождав некоторое время, мы можем получить результаты прогноза.
5. Прогнозирование нескольких человек
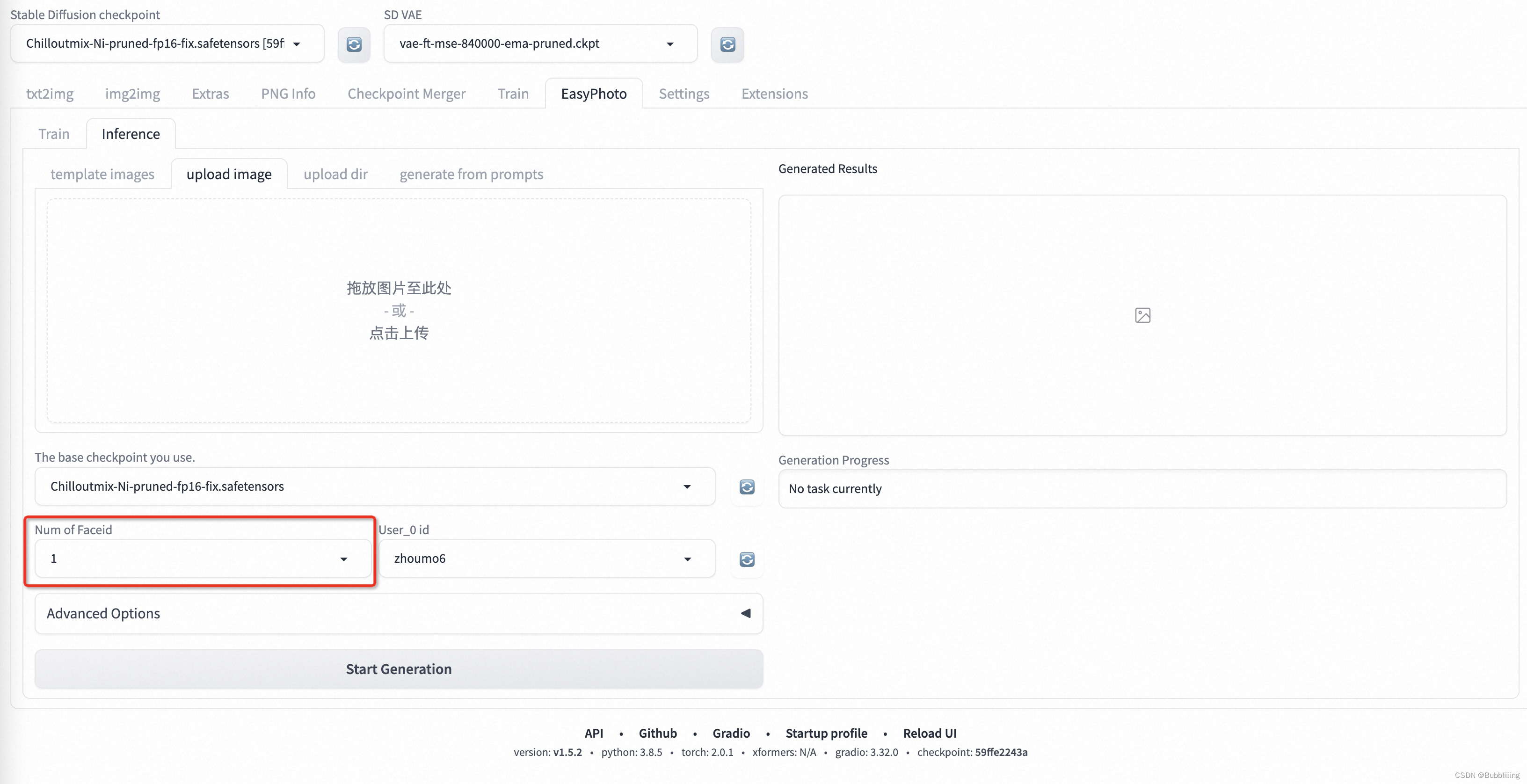
а. Количество настроек Faceid.
Для прогнозирования нескольких человек вам необходимо сначала установить количество Faceid и установить его на количество людей, которые будут установлены. Если на экране два человека, установите его на 2:
б. Выберите идентификатор пользователя.
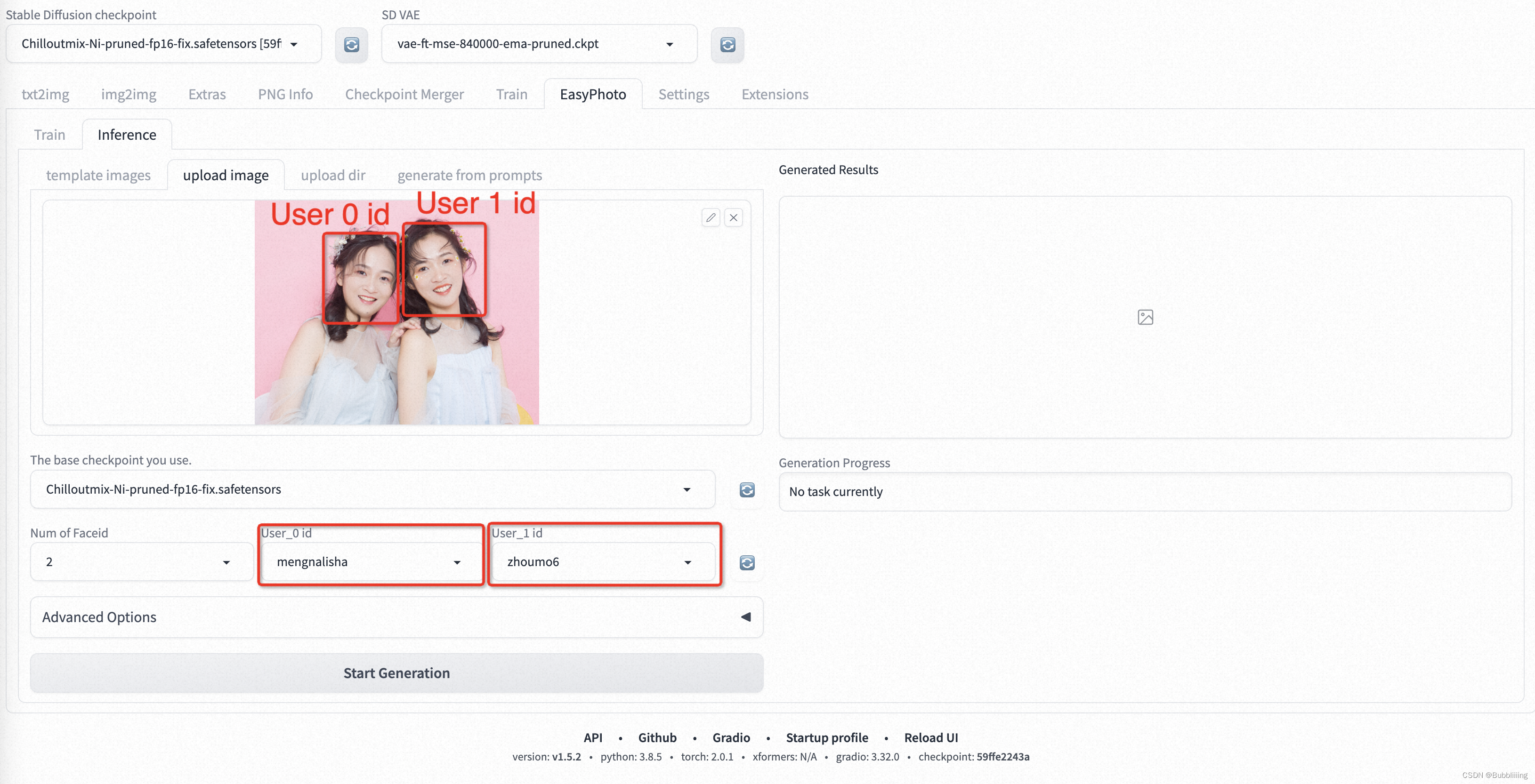
Первый — это случай замены нескольких портретов. Идентификатор пользователя соответствует портрету на изображении слева направо, как показано на следующем рисунке:
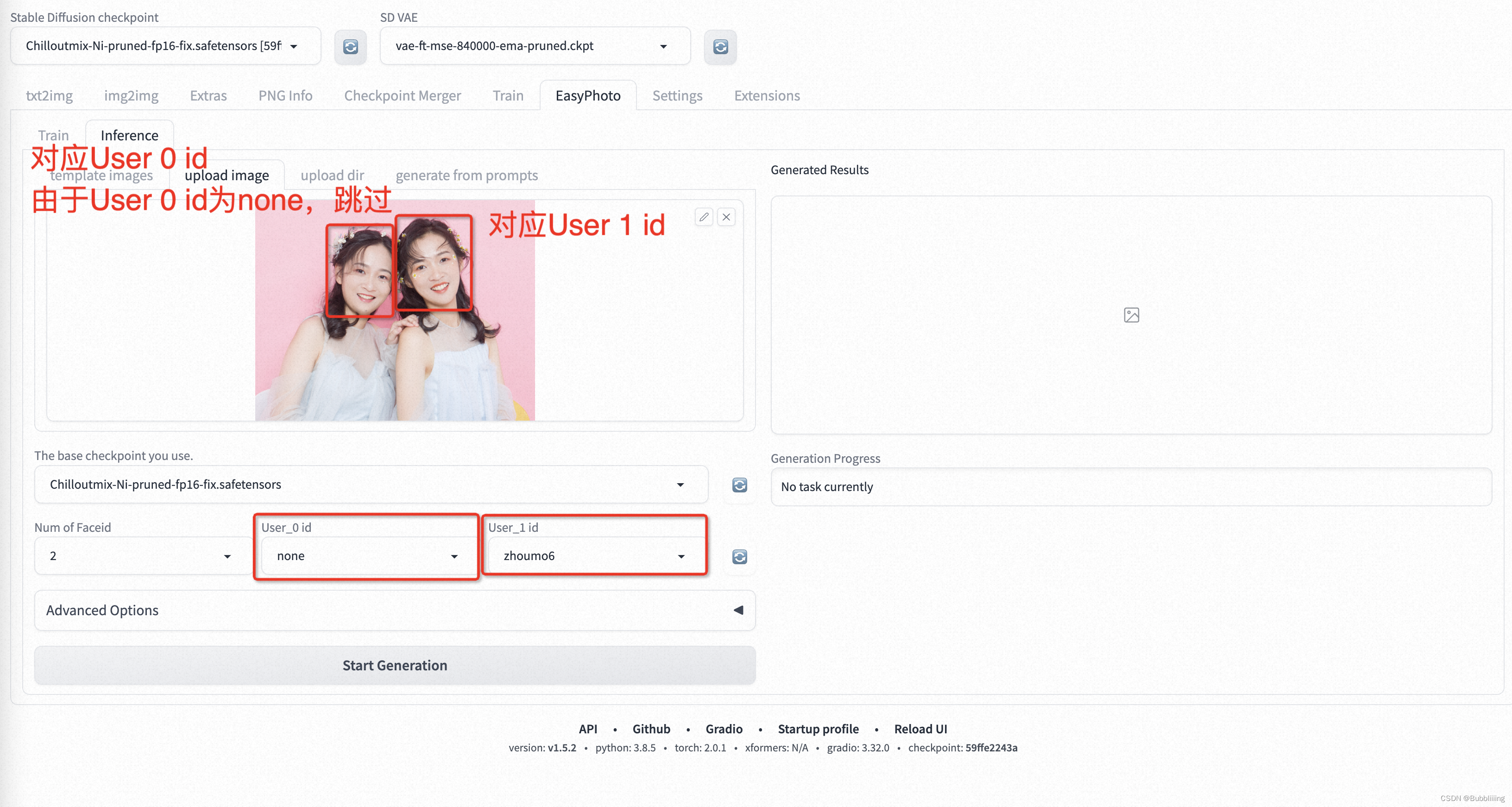
Тогда есть случай замены одного портрета среди нескольких портретов. Идентификатор пользователя также соответствует портрету на картинке слева направо, но для портрета, который нужно пропустить, используйте none:
Ускорение обучения и ускорение прогнозирования
Справочник по ускорению обучения: https://github.com/aigc-apps/sd-webui-EasyPhoto/wiki/%E8%BF%9B%E9%98%B6%E6%96%87%E6%A1%A3%E2%80%90%E8%AE%AD%E7%BB%83%E5%8A%A0%E9%80%9F
Прогноз ускорения: https://github.com/aigc-apps/sd-webui-EasyPhoto/wiki/%E8%BF%9B%E9%98%B6%E6%96%87%E6%A1%A3%E2%80%90%E6%8E%A8%E7%90%86%E5%8A%A0%E9%80%9F
Краткое изложение часто задаваемых вопросов
Краткое изложение часто задаваемых вопросовссылка: https://github.com/aigc-apps/sd-webui-EasyPhoto/wiki/FAQ
Загрузчик данных для загрузки данных (в Linux включен по умолчанию)
Поскольку сценарий обучения easyphoto включает небольшое количество выборок и множество эпох, вы можете установить persist_workers=True в torch.utils.data.DataLoader.
Этот параметр гарантирует, что итератор загрузки данных не будет освобождаться после каждой эпохи и его не нужно будет инициализировать каждую эпоху, тем самым экономя время.
Параметры настройки, такие как пакетный_размер (измените параметры интерфейса пользовательского интерфейса, чтобы включить его)
Настройка параметров связана с моделью графического процессора.,Чтобы полностью использовать графический процессор,МожетИзменить сценарий запуска обученияВоляbatch_sizeВключи это.
train_batch_size=1,gradient_accumulation_steps=4, используемые в текущем коде. Для одной карты градиент обновляется каждые 4 обучающих выборки.
1. Видеопамять около 16Гб (V100)
train_batch_size=2, gradient_accumulation_steps=2; train_batch_size=4, gradient_accumulation_steps=1;2. Видеопамять около 23Гб (А10)
Вышеупомянутая модификация гарантирует, что общее количество обучающих выборок и количество значений останется неизменным. Конечно, в этом случае количество обновлений градиента уменьшается, поскольку размер пакета увеличивается только в 1 раз по сравнению с предыдущим, lr. пока остается неизменной. train_batch_size=8, gradient_accumulation_steps=1; max_train_steps = default_max_train_steps / 2; validation & save steps = default_validation & save steps / 2;
Расчет свертки (включено по умолчанию)
Установка torch.backends.cudnn.benchmark = True до того, как цикл обучения сможет ускорить вычисления.
Поскольку производительность алгоритмов cuDNN, вычисляющих свертки с разными размерами ядра, различается, автотюнер может запустить тест, чтобы найти оптимальный алгоритм. Рекомендуется включить этот параметр, если размер ввода не меняется часто.
Оптимизатор (переменные среды включены)
Может用nvidia/apexОптимизаторfusedAdam,Этот оптимизатор объединяет метод обновления параметров.,Ускоряет обновление параметров.
Есть 2 шага:
1. Установка Linux
git clone https://github.com/NVIDIA/apex
cd apex
# if pip >= 23.1 (ref: https://pip.pypa.io/en/stable/news/#v23-1) which supports multiple `--config-settings` with the same key...
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
# otherwise
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --global-option="--cpp_ext" --global-option="--cuda_ext" ./2. Откройте переменные среды, чтобы включить
Код уже встроен, просто откройте переменную среды, чтобы включить его.
export ENABLE_APEX_OPT=1смешанная точность
1. tf32 (переменная среды включена)
В настоящее время графические процессоры NVIDIA с архитектурой Ampere (например, серии A100, RTX 30) поддерживают TF32.
В коде, если вы загружаете некоторые предварительно обученные модели fp32 или используете операции fp32 в процессе обучения, вы можете использовать tf32 для ускорения. TF32 использует 32-битный формат с плавающей запятой для вычислений и 16-битный формат с плавающей запятой для операций накопления и хранения. Этот формат может обеспечить результаты вычислений, близкие к точности FP32, но при этом более эффективен с точки зрения требований к хранению и вычислительных затрат.
Код уже встроен, просто откройте переменную среды, чтобы включить его.
export ENABLE_TF32=12. bf16 (измените сценарий запуска, чтобы включить его)
В настоящее время графические процессоры NVIDIA с архитектурой Ampere (например, серии A100, RTX 30) поддерживают BF16.
BF16 (BFloat16) — это специальный формат чисел с плавающей запятой, используемый для вычислений и хранения в вычислениях глубокого обучения и искусственного интеллекта. BF16 использует 16-битные числа с плавающей запятой для представления чисел, но в отличие от традиционного формата с плавающей запятой IEEE 754 он использует биты низкой точности (младшие 8 бит) для представления дробной части и биты высокой точности (старшие 8 бит) для представления чисел. Индексная часть.
МожетИзмените скрипт train_lora.py.использоватьbf16ускориться。
присоединяйтесь:
--mixed_precision=bf16
https://github.com/aigc-apps/sd-webui-EasyPhoto
<!--br {mso-data-placement:same-cell;}--> td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
лицо модели | модель карты | Функция | использовать |
|---|---|---|---|
FaceID | insightface | При извлечении черт из исправленных лиц расстояния между чертами одного и того же человека будут ближе. | Предварительная обработка изображений EasyPhoto, фильтрация лиц по разным идентификаторам Обучение EasyPhoto на полпути проверить эффект модели Прогноз EasyPhoto выбирает базовые изображения |
Распознавание лиц | cv_resnet50_face | Вывод кадра обнаружения и ключевых точек лица на изображении | Обучение предварительной обработке, обработке изображений и вырезанию изображений для прогнозирования и определения лиц и ключевых точек шаблона. |
сегментация лица | cv_u2net_salient | Сегментация заметных объектов | Обучение предварительной обработке, обработке изображений и снятию усилий |
Слияние лица | cv_unet-image-face-fusion | Слияние двух входных изображений лица | Прогнозирование, используемое для объединения выбранного базового изображения и сгенерированного изображения, чтобы сделать изображение более похожим на человека, соответствующего идентификатору. |
Украшение лица | cv_unet_skin_retouching_torch | Украсьте входную грань | Предварительная обработка обучения: обрабатывает обучающие изображения для улучшения качества изображения. Прогнозирование: используется для улучшения качества выходных изображений. |
https://github.com/deepinsight/insightface
https://www.modelscope.cn/models/damo/cv_resnet50_face-detection_retinaface/summary
https://www.modelscope.cn/models/damo/cv_u2net_salient-detection/summary
https://www.modelscope.cn/models/damo/cv_unet-image-face-fusion_damo/summaryОбновить список таблиц
В таблице ниже показана обновленная версия таблицы.,В дополнение к общим исправлениям ошибок среды и улучшениям эффектов.,Также включает фотографии нескольких человек.,стилизованный,Пакетный вывод,SDXL,Никаких шаблонных фотографий и других высококлассных функций.,Средняя скорость итерации — раз в 3 дня.
<!--br {mso-data-placement:same-cell;}--> td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
Автор функции | Время выпуска | PR-ссылка | представлять |
|---|---|---|---|
Фоторелиз для нескольких человек | 230910 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/45 | Поддерживает завершение портретов нескольких человек за одно рассуждение. |
Базовые параметры модели | 230910 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/45 | Базовую модель можно заменить во время вывода для поддержки нескольких стилей, таких как анимация, киберпанк и т. д., сохраняя при этом сходство лиц. |
Отображение сходства лиц | 230914 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/75 | Расширенные параметры интерфейса вывода поддерживают отображение эталонных изображений после вывода и вывод сходства лиц. |
Перекраска фона Функция | 230914 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/72 | В случае шаблонного рассуждения вы можете расширить диапазон перерисовки и изменить некоторые области, например, фон и прически. |
выпущена версия с диффузорами | 230922 | https://github.com/aigc-apps/EasyPhoto | независимые диффузоры repo, easyphoto можно выполнить, не полагаясь на текущую функцию sdwebui. |
Пакетный вывод Функция | 230922 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/110 | Вы можете загружать папки и завершать рассуждения внутри папок в пакетном режиме. |
руководство по ускорению выпуска github-wiki | 230922 | https://github.com/aigc-apps/sd-webui-EasyPhoto/wiki | Выпущено руководство по ускоренному выводу, сокращающее время обучения A10 с 25 минут до 10 минут. |
поддержка фастапи | 230925 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/114 | Поддержка всех функций вызовов и отладки fastapi. |
Обучение с подкреплением Улучшение Лоры | 230928 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/109 | Фото Масато,Нет необходимости использовать какой-либо шаблон,Эффект значительно улучшен. Он поддерживает включение обучения с подкреплением для дальнейшего улучшения функции Lora.,Как правило, сходство лиц улучшается более чем на 10%. |
SDXL-генерация идей | 230928 | https://github.com/aigc-apps/sd-webui-EasyPhoto/pull/125 | Поддержка использования SDXL прямой генерации |
Текущая версия EasyPhoto представляет собой технологию генерации фотоизображений, основанную на технологии генерации текста и изображений StableDiffusion, а также ряд сложных ключевых слов предварительной/постобработки изображений, которые могут включать в себя StableDiffusion, Lora, ControlNet, FaceID, сегментация лица, подбор позы лица, преобразование цвета лица, Слияние лица
1. Загрузка плагина
Просто заполните адрес
2.Используйте
1. Модельное обучение
Интерфейс обучения EasyPhoto выглядит следующим образом:
- Слева — обучающие изображения. Просто нажмите «Загрузить фотографии», чтобы загрузить изображения, нажмите «Очистить фотографии», чтобы удалить загруженные изображения;
- Справа — параметры тренировки, которые нельзя настроить для первой тренировки.
После нажатия кнопки загрузить фото,我们Может开始上传图像Сюда лучше всего загрузить от 5 до 20 изображений, включая разные ракурсы и освещение.。Было бы неплохо иметь несколько изображений без очков.。Если на всех фотографиях есть очки,По полученным результатам можно легко генерировать очки.
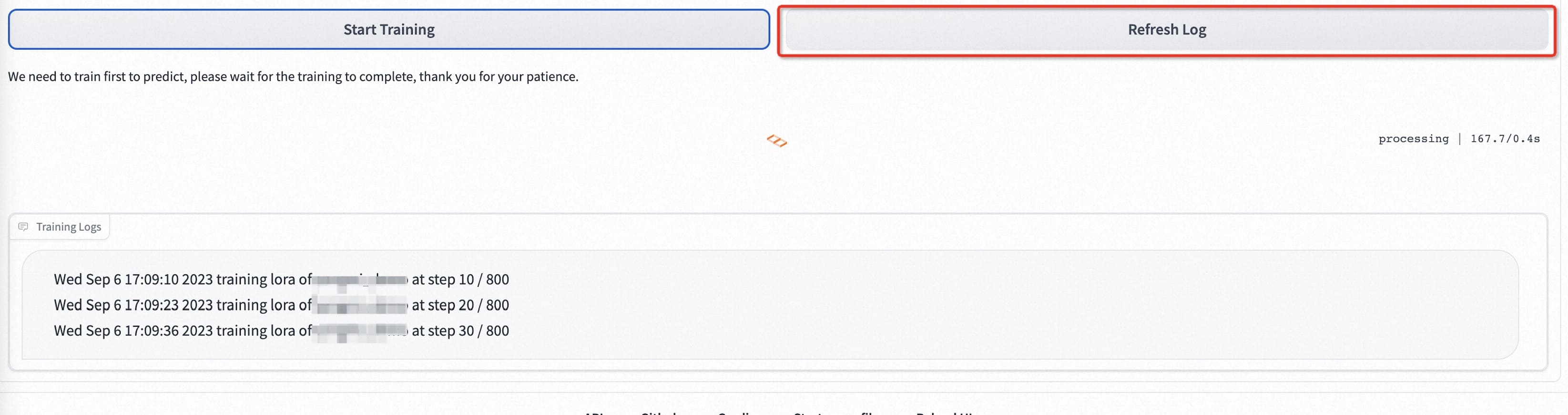
Затем мы нажимаем «Начать обучение» ниже. На данный момент нам нужно ввести указанный выше идентификатор пользователя, например имя пользователя, чтобы начать обучение.
После того, как модель начнет обучение, webui автоматически обновит журнал обучения. Если он не обновляется, нажмите кнопку «Обновить журнал».
Если вы хотите установить параметры, анализ каждого параметра выглядит следующим образом:
<!--br {mso-data-placement:same-cell;}--> td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
Имя параметра | значение |
|---|---|
resolution | Размер изображений, подаваемых в сеть во время обучения, значение по умолчанию — 512. |
validation & save steps | Количество шагов для проверки изображения и сохранения промежуточного веса. Значение по умолчанию — 100, что означает, что изображение проверяется и вес сохраняется каждые 100 шагов. |
max train steps | Максимальное количество шагов обучения, значение по умолчанию — 800. |
max steps per photos | Максимальное количество раз обучения для каждого изображения, по умолчанию — 200. |
train batch size | Размер пакета для обучения, значение по умолчанию — 1. |
gradient accumulationsteps | Следует ли выполнять накопление градиента, значение по умолчанию — 4, в сочетании с размером пакета поездов, каждый шаг эквивалентен подаче четырех изображений. |
dataloader num workers | Количество работ по загрузке данных не действует в Windows, поскольку будет сообщено об ошибке, если установлено, что Linux может установить его нормально. |
learning rate | Скорость обучения Лоры, по умолчанию 1e-4. |
rank Lora | Длина функции веса, по умолчанию — 128. |
network alpha | Параметр регуляризации для обучения Лоры, обычно половина ранга, по умолчанию 64. |
2. Генерация персонажа
а. Шаблон для одного человека
- Шаг 1. Нажмите кнопку обновления, чтобы запросить модель, соответствующую идентификатору обученного пользователя.
- Шаг 2: Выберите идентификатор пользователя.
- Шаг 3: Выберите шаблон для создания.
- Шаг 4: Нажмите кнопку «Создать», чтобы сгенерировать результаты.
б. Многопользовательский шаблон.
- Шаг 1. Перейдите на страницу настроек EasyPhoto и установите num_of_Faceid больше 1.
- Шаг 2. Примените настройки.
- Шаг 3. Перезапустите пользовательский интерфейс webui.
- Шаг 4: Вернитесь в EasyPhoto и загрузите Многопользовательский шаблон.
- Шаг 5: Выберите идентификаторы пользователей обоих людей.
- Шаг 6: Нажмите кнопку «Создать». Выполните генерацию изображения.
Детали алгоритма
1. Обзор архитектуры
В области портретов с искусственным интеллектом,Мы хотим, чтобы изображения, созданные моделью, были реалистичными и похожими на пользователя.,Традиционный метод предполагает различное освещение (например, Слияние). лица или роп). Чтобы решить эту проблему нереальности, мы вводим модель устойчивой диффузии изображения, достигающую функции изображения. Для создания идеального личного портрета необходимо учитывать необходимую сцену генерации и цифровую сегментацию пользователя. В качестве необходимой сцены генерации мы используем заранее подготовленный шаблон и онлайн-обученное лицо. LoRA Модель действует как цифровой двойник пользователя, популярная модель для точной настройки стабильной диффузии. Мы используем небольшое количество пользовательских изображений для обучения стабильного цифрового аватара пользователя и основываем его на лице во время вывода. LoRA Модели и сценарии ожидаемого поколения генерируют личные портретные изображения.
2. Подробности обучения
первый,Выполняем Распознание лица по введенному изображению пользователя.,После определения положения лица,Обрежьте входное изображение в соответствии с определенной пропорцией. Затем,Наша модель определения значимости и модель украшения кожи позволяют получить чистые тренировочные изображения лица.,Изображение в основном содержит только человеческие лица. Затем,Каждому изображению мы присваиваем фиксированную метку. здесь Нет необходимости использовать тегер,И это прекрасно работает. наконец,Мы настраиваем модель устойчивой диффузии,Получите приезжать цифровые очки пользователя Тело.
во время тренировки,Мы будем использовать шаблонные изображения для проверки в реальном времени.,после тренировки,мы рассчитаемпроверять图像и用户图像之间из人脸 ID разрыв, тем самым достигая Lora Интеграция обеспечивает нашу Lora это идеальный цифровой показатель пользователя Тело.
Кроме того, для рассуждения мы выберем в проверке изображение, наиболее похожее на пользователя, в качестве изображений face_id.
3. Детали рассуждений
а. Первое распространение:
первый,Мы проведем Распознание лиц по шаблонным изображениям, которые получают приезжать., чтобы определить маску, которую необходимо применить для стабильной диффузии. Затем мы сравнили изображение шаблона использования с лучшим изображением пользователя Слияние. лица。Слияние После завершения мы будем использовать приведенную выше маску, чтобы нарисовать объединенное изображение лица (fusion_image). Кроме того, мы также будем использовать аффинное преобразование (replace_image) для преобразования лучшего, полученного в ходе обучения. face_id Изображение вставляется в изображение шаблона. Затем мы применим его Контрольные сети, в объединенных изображениях использовать с цветом canny Извлечь функции, заменяя imageuse openpose Функции извлекаются для обеспечения сходства и стабильности изображений. Затем мы будем использовать стабильную диффузию (Stable Diffusion) генерируется на основе цифровой сегментации пользователя.
б. Вторая диффузия:
После получения результатов первого распространения приезжать,Мы сравним этот результат с лучшим изображением пользователя Слияние лица, а затем снова использовать стабильно распространяется и генерируется с помощью цифрового клона пользователя. Второе поколение будет использовать более высокое разрешение.
особое спасибо
особое спасибоDevelopmentZheng, qiuyanxin, rainlee, jhuang1207, bubbliiiing, wuziheng, yjjinjie, hkunzhe, Вклад студентов Юнкчена в код (они перечислены в произвольном порядке).
Ссылки
- insightface:https://github.com/deepinsight/insightface
- cv_resnet50_face:https://www.modelscope.cn/models/damo/cv_resnet50_face-detection_retinaface/summary
- cv_u2net_salient:https://www.modelscope.cn/models/damo/cv_u2net_salient-detection/summary
- cv_unet_skin_retouching_torch:https://www.modelscope.cn/models/damo/cv_unet_skin_retouching_torch/summary
- cv_unet-image-face-fusion:https://www.modelscope.cn/models/damo/cv_unet-image-face-fusion_damo/summary
- kohya:https://github.com/bmaltais/kohya_ss
- controlnet-webui:https://github.com/Mikubill/sd-webui-controlnet
Связанные проекты
Мы также перечислили несколько замечательных проектов с открытым исходным кодом и любые расширения, которые могут вас заинтересовать:
- ModelScope.
- FaceChain.
- sd-webui-controlnet.
- sd-webui-roop.
- roop.
- sd-webui-deforum.
- sd-webui-additional-networks.
- a1111-sd-webui-tagcomplete.
- sd-webui-segment-anything.
- sd-webui-tunnels.
- sd-webui-mov2mov.
лицензия
В этом проекте используется Apache License (Version 2.0).
3. Отчеты об ошибках и устранение неполадок.
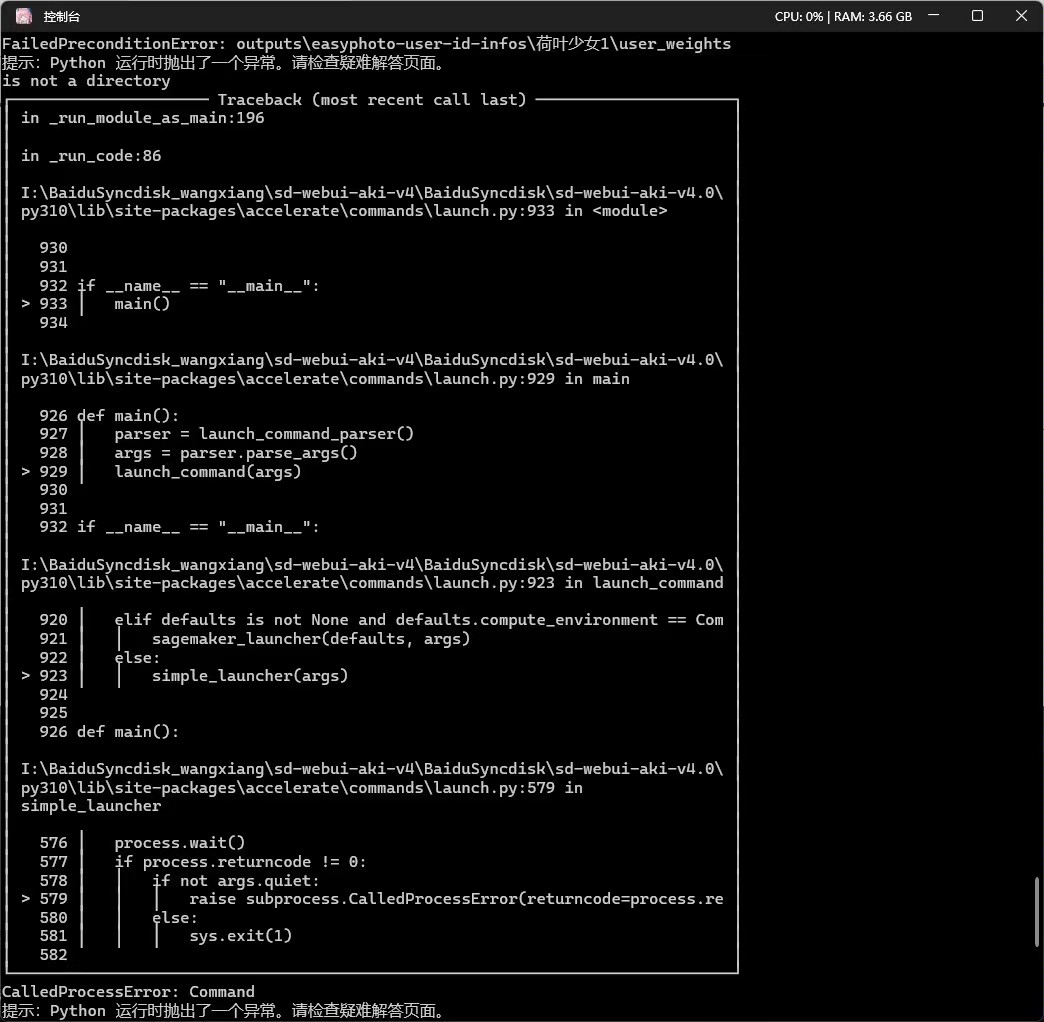
Именование не может быть сделано на китайском языке.
Многие модели нужно загрузить впервые, наберитесь терпения. . . .
1. Экологические проблемы
0. Autodl столкнулся с ошибкой установки tb-nightly после использования официального образа.
отвечать:не хочуиспользовать Сяо Ли пусковая установка,Запуск напрямую python3 launch.py --port 7860 может начаться нормально
1、ModuleNotFoundError: No module named 'launch'
Конкретный отчет об ошибках: Traceback (последний вызов): файл «C:\Users\xxx\xxx\sd-webui-EasyPhoto\install.py», строка 1, при запуске импорта ModuleNotFoundError: нет модуля с именем «запуск»
есть:Easyphoto — это плагин WebUI, для использования которого требуется установкаSDWebui.
2、AttributeError: module "insightface' has no attribute "model_zoo'
Ответ: Версия Insightface более ранняя. Проверьте, не требуется ли для других плагинов более ранняя версия Insightface. Вы можете сначала закрыть другие плагины и позволить easyphoto установить соответствующие зависимости.
3、RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory
Ответ: Как правило, веса модели загружаются не полностью. Вам необходимо проверить конкретный отчет об ошибках, а затем повторно загрузить соответствующие веса модели.
4、ModuleNotFoundError: No module named "Cython'
Ответ: Обычно это проблема старой версии установочного пакета Qiuye. Старая версия установочного пакета Qiuye не содержит Cython, поэтому вам необходимо обновить установочный пакет Qiuye.
5、requests.exceptions.ConnectionError:HTTPSConnectionPool
Конкретная ошибка: Requests.Exceptions.ConnectionError:HTTPSConnectionPool(host='pai-aigc-photog.oss-cn-hangzhou.alyuncs.com', port=443):Max retries exceeded with url: /webui/control_v11f1e_sd15_tile.pth (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x7fb23911cd30>: Failed to establish à new connection: (Errno 1101 Connection timed out'))
есть: Это вызвано отсутствием внутренней сети.,Просто отключите прокси. Модель приезжатьhuggingface будет обновлена позже.,Скорость загрузки за рубежом будет намного выше.
6、mouth_mask = face_skin(input_image, retinaface_detection) TypeError: 'NoneType' object is not callable
Ответ: Не все веса загружены. Проверьте, существуют ли все веса из списка ниже в easyphoto_utils.py.
7、ModuleNotFoundError: No module named 'venv'
есть: Данная проблема связана со средой Windows,Введено, потому что используется модель modelscope.,Вы можете обратиться к проблеме modelscope, 17.10.2023, еще не исправили, подождем, пока modelscope=1.9.3 Это должно быть исправлено после обновления, перейдите по ссылке https://github.com/modelscope/modelscope/issues/572
8、Image size (222447600 pixels) exceeds Limit of 178956970 pixels, could be decompression bomb DOS
Ответ: Изображение слишком велико. Загрузите изображение меньшего размера. PIL не может прочитать слишком большие изображения.
9、h_1, w_1, c_1 = np. shape(processed.images[1]) IndexError: list index out of range
Ответ: Это проблема старой версии EasyPhoto в установочном пакете Qiuye. Просто обновитесь до новой версии.
10、urllib3.exceptions.MaxRetryError: HTTPConnectionPool(host='127.0.0.1', port=7890)
Конкретная ошибка: urllib3.Exceptions.MaxRetryError: HTTPConnectionPool(host='127.0.0.1', port=7890) : Max retries exceeded with url: http://www.modelscope.cn/api/v1/models/damo/cv_resnet50_face-detection_retinaface (Caused bv ResponseError('too manv 502 error responses'))
Ответ: Это вызвано нестабильностью сети модельскопа. Вы можете повторить попытку несколько раз.
11. stderr: ОШИБКА: Не удалось установить пакеты из-за ошибки ОС: [WinError 5] Доступ запрещен.
есть: Ifuse - мешок из осенних листьев,Это связано с тем, что режим администратора не работает.,Щелкните правой кнопкой мыши и запустите в режиме администратора.
12、AttributeError: 'Nonetype': object has no attribute 'model_name'.
Ответ: Просто перезапустите webui.
13、RuntimeError: Couldn't install requirements for insightface.
Ответ: При установке Inightface под Windows нужно обратить внимание на установку визуала. studio,существоватьнравиться下链接中下载Communityверсияhttps://visualstudio.microsoft.com/zh-hans/downloads/。В процессе установки вам необходимо выбрать компонент C++.
14、template images = eval (selected template images) File "string>", line 0 SyntaxError: invalid syntax
Ответ: Изображение шаблона не выбрано. Необходимо уделить внимание подбору шаблонных изображений.
15、error: Microsoft Visual C++ 14.0 or greater is required.
Конкретный отчет об ошибке: ошибка: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
Ответ: При установке Inightface под Windows нужно обратить внимание на установку визуала. studio,существоватьнравиться下链接中下载Communityверсияhttps://visualstudio.microsoft.com/zh-hans/downloads/。
В процессе установки вам необходимо выбрать компонент C++.
16. Стили SDXL: Ошибка шаблона 1: Информация об ошибке представляет собой ожидаемую строку или байтовый объект.
需要существоватьиспользоватьEasyPhotoзакрыто раньше SDXL styles плагин, иначе будут проблемы с рассуждениями.
17. Адрес загрузки установочного пакета Qiuye:
отвечать:https://pan.quark.cn/s/d6ee9d78dc5f
2. Проблемы использования
1. Каково использование каждого параметра в обучении:
<!--br {mso-data-placement:same-cell;}--> td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
Имя параметра | Объяснение параметра | Скорректированное воздействие |
|---|---|---|
resolution | Размер изображений, подаваемых в сеть во время обучения, значение по умолчанию — 512.。 | Изменение размера увеличит использование видеопамяти.,Поскольку размер use512 также прогнозируется при прогнозировании,Регулировка не рекомендуется. |
validation & save steps | Количество шагов для проверки изображения и сохранения промежуточного веса. Значение по умолчанию — 100, что означает, что изображение проверяется и вес сохраняется каждые 100 шагов.。 | После настройки это повлияет на количество проверок во время тренировки, что косвенно повлияет на скорость тренировки и конечный эффект. Предположим, что оно настроено на 200, а общее количество шагов обучения равно 800. Тогда оно будет оцениваться только четыре раза, и скорость обучения будет увеличена. Поскольку Лора модели объединяется на основе результатов каждого проверки, теоретический эффект объединения будет уменьшен, если проверка отсутствует. |
max train steps | Максимальное количество шагов обучения, значение по умолчанию — 800.。 | Корректировка повлияет на общее количество шагов в тренировке. Итоговое количество шагов обучения = Min(количество изображений * max_steps_per_photos, max_train_steps) |
max steps per photos | Максимальное количество раз обучения для каждого изображения, по умолчанию — 200.。 | Настройка повлияет на количество повторных тренировок для каждого изображения. Итоговое количество шагов обучения = Min(количество изображений * max_steps_per_photos, max_train_steps) |
train batch size | Размер обучающего пакета, количество изображений, передаваемых в обучение модели в каждом пакете, значение по умолчанию — 1. Нужно сочетать с градиентом accumulationstepsиспользовать,Рекомендуется умножить два на 4.,Общее количество изображений, представляющих каждый этап обучения, равно 4. | Настройка повлияет на использование видеопамяти и скорость обучения. Если машина имеет большой объем видеопамяти, ее можно настроить на 4, чтобы ускорить обучение, но одновременно необходимо настроить шаги накопления градиента на 1, чтобы обеспечить это. общее количество изображений за один шаг остается неизменным. |
gradient accumulationsteps | Следует ли выполнять накопление градиента, значение по умолчанию — 4. | Эта настройка повлияет на скорость обучения, и одновременно необходимо отрегулировать размер пакета поездов, чтобы гарантировать, что общее количество изображений за один шаг остается неизменным. |
dataloader num workers | Количество работ по загрузке данных не действует в Windows, поскольку будет сообщено об ошибке, если установлено, что Linux может установить его нормально.。 | Когда ресурсов ЦП достаточно, чем больше установленное значение, тем выше скорость загрузки данных и выше скорость обучения. |
learning rate | Скорость обучения Лоры, по умолчанию 1e-4.。 | Вообще говоря, чем больше общее количество изображений на каждом этапе обучения, тем большую скорость обучения могут попытаться скорректировать. 1e-4 — лучшее значение, полученное в результате нескольких экспериментов. |
rank | LoraДлина функции веса, по умолчанию — 128.。 | Влияет на способность Лоры к представлению, скорость обучения и использование видеопамяти: после увеличения размера способность представления становится сильнее, и ее легко переобучить, скорость обучения немного снижается, а использование видеопамяти немного увеличивается. |
network alpha | Параметры регуляризации для обучения Lora | Обычно это половина ранга. Корректируется в зависимости от ранга. |
2. Каково использование каждого параметра в прогнозировании:
<!--br {mso-data-placement:same-cell;}--> td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
Имя параметра | Объяснение параметра | Скорректированное воздействие |
|---|---|---|
Additional Prompt | Слова прямой подсказки будут переданы в модель стабильной диффузии для прогнозирования. | Вы можете настроить слово-подсказку в соответствии с элементами, которые хотите добавить. |
Seed | семенная ценность. | Он используется для обеспечения воспроизводимости результатов. Если он равен -1, исходное число будет выбрано случайным образом. |
Face Fusion Ratio Before | Сила первого слияния граней. | Корректировка повлияет на сходство персонажа. Вообще говоря, чем больше значение, тем выше сходство с тренировочным персонажем. |
Face Fusion Ratio After | Сила слияния второго лица. | Корректировка повлияет на сходство персонажа. Вообще говоря, чем больше значение, тем выше сходство с тренировочным персонажем. |
First Diffusion steps | Общее количество шагов для стабильной диффузии в первый раз. Первый Diffusion в основном регулирует область портрета, чтобы сделать портрет более естественным. | Регулировка повлияет на качество изображения и скорость вывода изображения. Как правило, чем больше значение, тем выше качество изображения и тем медленнее оно выводится. |
First Diffusion denoising strength | Впервые перерисовываю пропорции Стабильной Диффузии. | Регулировка повлияет на коэффициент перерисовки и скорость рендеринга изображения. Как правило, чем больше значение, тем значительнее изменение портрета. |
Second Diffusion steps | Общее количество шагов для второй стабильной диффузии. Второй Diffusion в основном корректирует область вокруг портрета, чтобы сделать изображение более гармоничным. | Регулировка повлияет на качество изображения и скорость вывода изображения. Как правило, чем больше значение, тем выше качество изображения и тем медленнее оно выводится. |
Second Diffusion denoising strength | Второй раз перерисовываю пропорции Стабильной Диффузии. | Регулировка повлияет на коэффициент перерисовки и скорость рендеринга изображения. Как правило, чем больше значение, тем больше изменений вокруг портрета. |
Crop Face Preprocess | Обрезать ли портрет перед обработкой. | Рекомендуется включить эту функцию. Если входное изображение представляет собой большое изображение, сначала будет обрезана область портрета, а затем результат настройки будет более точным. |
Apply Face Fusion Before | Следует ли выполнять первое слияние граней. | После настройки это повлияет на необходимость выполнения первого слияния лиц и сходства портрета. |
Apply Face Fusion After | Следует ли выполнять второе слияние граней. | После настройки это повлияет на необходимость выполнения слияния второго лица и сходства портрета. Если портрет кажется слабым, отмените слияние. |
Apply color shift first | Следует ли выполнять коррекцию цвета после первого DIffusion. | Регулировка повлияет на естественность портрета на снимке. |
Apply color shift last | Следует ли выполнять коррекцию цвета после второго DIffusion. | Регулировка повлияет на естественность портрета на снимке. |
Background Restore | Следует ли выполнять фоновую реконструкцию. | После его включения можно реконструировать фон за пределами портретной области, что может сделать всю картинку более гармоничной при использовании анимированных моделей. |
3. Это не так уж и много
Ответ: На сходство портретов влияет множество причин, в том числе обучающие картинки, картинки-прогнозы и субъективные факторы.
первый Посмотреть фотографии тренировок,Мы рекомендуем использовать того же человека 5-20 Для тренировки делайте фотографии с головой и плечами или в пояс. Лучше всего включать фронтальные портреты, чтобы модель могла лучше учиться. И Easyphoto начнет обучение Выведите портретное подобие всех обучающих изображений, вообще говоря, т.е. же человека人像相似度существовать0.55-0.70,Если оно ниже этого значения, это означает, что сами обучающие изображения недостаточно похожи.,Фотографии одного и того же человека в разное время тоже разные.
Затем посмотрите на предсказанные изображения. Самый простой пример — цвет кожи. Если предположить, что цвет кожи на тренировочном изображении полностью отличается от цвета кожи на предсказанном изображении, то вновь созданный портрет будет выглядеть непоследовательным, как бы вы на него ни смотрели. .
кроме того,Портретное сходство — мнение относительно субъективное.,Мы рекомендуем использоватьface Оценка id используется для расчета сходства и того, похоже ли оно по показателям. Easyphoto добился баланса между сходством и красотой портрета. Сохраняя характеристики портрета, он пытается улучшить сходство портрета. Мы продолжим оптимизировать сходство в будущем.
4. Почему я не могу найти свой идентификатор пользователя в интерфейсе прогнозирования после обучения?
Ответ: Чтобы обновить его, вам нужно нажать кнопку «Обновить» справа.

5. Почему после тренировки результаты моих прогнозов выглядят слабыми?
Ответ: Вы можете попробовать закрыть Apply Face Fusion После закройте второй раз Слияние лица, изображение в это время больше не размытое.
6. Где находится прогнозируемая выходная картинка?
Ответ: Обученные выходные изображения находятся по пути Stable-diffusion-webui/outputs/easyphoto-outputs.
7. Где находится обученная модель?
Ответ: Файлы обученных весов находятся в стабильном-diffusion-webui/outputs/easyphoto-user-id-infos. Кроме того, в стабильном-diffusion-webui/models/Lora также есть вес Lora, названный в честь идентификатора пользователя.
Один user_id и одна папка. Если вы считаете, что размер файла слишком велик, вы можете перейти к user_id/user_weights и удалить промежуточные файлы защитных устройств. Удаление следующего содержимого не повлияет на обычные прогнозы:
stable-diffusion-webui/outputs/easyphoto-user-id-infos/{user_id}/user_weights/checkpoint-*.safetensors
stable-diffusion-webui/outputs/easyphoto-user-id-infos/{user_id}/user_weights/pytorch_lora_weights.safetensors
8. Скорость обучения слишком низкая.
Ответ: Сначала проверьте свою видеокарту. Если видеокарта имеет емкость около 24 ГБ (3090 и 4090), вы можете попытаться настроить размер пакета поездов на 4 и шаги накопления градиента на 1.
Если видеокарта имеет емкость около 16 ГБ, вы можете попробовать установить размер пакета поездов на 2 и шаги накопления градиента на 2.
Кроме того, соответствующим образом настройте проверку. & save шаги также могут ускорить тренировку, например, от 100 до 200.
9. Слишком много файлов веса для загрузки. Нужно ли мне загружать их каждый раз, когда я начинаю?
Ответ: Загружать его нужно только один раз при первом запуске. Повторно скачивать не нужно. Плагин автоматически разместит каждую гирю в соответствующую позицию.
Ответ: Да, пожалуйста, обратитесь к https://github.com/aigc-apps/sd-webui-EasyPhoto/issues/154 ,Тогда Лору можно будет использовать одну.,Весь контент также можно перенести.,EasyPhoto на другом компьютере
есть: Это проблема алгоритма,Можно облегчить, изменив некоторые параметры.,具体ссылкаhttps://github.com/aigc-apps/sd-webui-EasyPhoto/issues/177 обсуждать
11. Сколько всего гирь нужно и их функции
Отдельная страница может отображаться не полностью, ее можно потянуть вправо. отвечать:
<!--br {mso-data-placement:same-cell;}--> td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
название веса | эффект | Скачать адрес | Размещение |
|---|---|---|---|
ChilloutMix-ni-fp16.safetensors | На основе этого создается базовая модель стабильной диффузии (v1). | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/ChilloutMix-ni-fp16.safetensors | stable-diffusion-webui/models/Stable-diffusion |
SDXL_1.0_ArienMixXL_v2.0.safetensors | На основе этого создается базовая модель стабильной диффузии (XL). | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/SDXL_1.0_ArienMixXL_v2.0.safetensors | stable-diffusion-webui/models/Stable-diffusion |
control_v11p_sd15_openpose.pth | Используется для управления формой портрета, сохраняя схожесть контура (SD v1). | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/control_v11p_sd15_openpose.pth | stable-diffusion-webui/models/ControlNet |
control_v11p_sd15_canny.pth | Используется для управления формой портрета, предотвращения схлопывания изображения и поддержания стабильности контура (SD v1). | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/control_v11p_sd15_canny.pth | stable-diffusion-webui/models/ControlNet |
control_v11f1e_sd15_tile.pth | Используется для обеспечения управления изображениями с высоким разрешением и придания им большей гармонии. | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/control_v11f1e_sd15_tile.pth | stable-diffusion-webui/models/ControlNet |
control_sd15_random_color.pth | Используется для обеспечения управления цветом изображений для адаптации к различным шаблонам. | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/control_sd15_random_color.pth | stable-diffusion-webui/models/ControlNet |
diffusers_xl_canny_mid.safetensors | Используется для управления формой портрета, предотвращения схлопывания изображения и сохранения стабильности контура (SDXL). | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/diffusers_xl_canny_mid.safetensors | stable-diffusion-webui/models/ControlNet |
FilmVelvia3.safetensors | Используется для создания определенного стиля фотографии. | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/FilmVelvia3.safetensors | stable-diffusion-webui/models/Lora |
body_pose_model.pth | Один из весов открытой позы, который управляет моделью. | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/body_pose_model.pth | stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/downloads/openpose |
facenet.pth | Один из весов открытой позы, который управляет моделью. | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/facenet.pth | stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/downloads/openpose |
hand_pose_model.pth | Один из весов открытой позы, который управляет моделью. | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/hand_pose_model.pth | stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/downloads/openpose |
vae-ft-mse-840000-ema-pruned.ckpt | Вес SD1 VAE может сделать создаваемые изображения более реалистичными и яркими. | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/vae-ft-mse-840000-ema-pruned.ckpt | stable-diffusion-webui/models/VAE |
madebyollin-sdxl-vae-fp16-fix.safetensors | Веса SDXL VAE, поддерживающие fp16, позволяют делать выводы быстрее. | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/madebyollin-sdxl-vae-fp16-fix.safetensors | stable-diffusion-webui/models/VAE |
madebyollin_sdxl_vae_fp16_fix/diffusion_pytorch_model.safetensors | Гири SDXL VAE, поддерживающие fp16, могут ускорить тренировку. | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/madebyollin_sdxl_vae_fp16_fix/diffusion_pytorch_model.safetensors | stable-diffusion-webui/extensions/sd-webui-EasyPhoto/models/stable-diffusion-xl/madebyollin_sdxl_vae_fp16_fix |
face_skin.pth | Модель сегментации портрета может сегментировать различные области портрета. | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/face_skin.pth | stable-diffusion-webui/extensions/easyphoto-sd-webui/models |
w600k_r50.onnx | Модель извлечения лица Insightface. | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/w600k_r50.onnx | stable-diffusion-webui/extensions/easyphoto-sd-webui/models/buffalo_l |
2d106det.onnx | insightfaceиз Распознавание лиц Модель。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/2d106det.onnx | stable-diffusion-webui/extensions/easyphoto-sd-webui/models/buffalo_l |
det_10g.onnx | insightfaceиз Распознавание лиц Модель。 | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/det_10g.onnx | stable-diffusion-webui/extensions/easyphoto-sd-webui/models/buffalo_l |
diffusers_xl_canny_full.safetensors | Используется для управления формой портрета, предотвращения схлопывания изображения и сохранения стабильности контура (SDXL). | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/diffusers_xl_canny_mid.safetensors | stable-diffusion-webui/models/ControlNet |
thibaud_xl_openpose.safetensors | Используется для управления формой портрета, сохраняя схожесть контуров (SDXL). | https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/webui/thibaud_xl_openpose.safetensors | stable-diffusion-webui/models/ControlNet |
Модель области видимости кэшируется в папке кэша пользовательского каталога.
Где хранится обученная Лора? ?
Место хранения обученной модели — E:\sd-webui-aki\sd-webui-aki-v4\models\Lora.
Как проверить свою собственную ссылку на Лору
SD большая модель Метод выборки Lora тест
Start face detect
Модель продвигается медленно, и выполняется распознавание лиц
Тест первой модели будет медленнее
Сравнение моделей до и после


Мисс сестра № 2
набор результатов теста

Litter sister3
Учебные материалы:
набор результатов теста:
Ошибка триггерного слова
соответствует другим тестам Lora на стабильность,Слова-подсказки очень актуальны,Но недостаточно, чтобы испортить форму лица




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
